基于HMM算法的英语形音匹配可视分析
2021-08-12段青青
段 青 青
(中国石油大学(华东)计算机科学与技术学院 山东 青岛 266500)
0 引 言
英语作为一种信息交流的载体,在国家之间的交流学习中具有非常重要的作用,为了更好适应时代的发展需求,提高自身英语水平,快速掌握发音规则成为高效学习英语的一个突破口[1]。然而英语中吸收了大量的外族语言,并以大胆的观念与灵活的方式借用或创造新词,导致英语发音规则出现多样性和混沌性的特征,复杂的发音模式成为英语学习者学习英语的一大障碍。
针对上述问题,多位学者进行了相关研究:Chiappe等[2]研究发现形音匹配(Grapheme-phoneme correspondence)在英语学习中可起到积极作用,所谓形音匹配,它的核心是字素-音素转换(Grapheme-to-phoneme, G2P)过程,相对于其他学习方式,其在阅读和拼读陌生单词方面表现出更大的优势;Hanna等[3]统计了10 000个高频单词的字素-音素特征,并根据特征重复概率为单词列表建立难度指数,通过直接向学习者提供形音匹配模式和难度指数来指导其对单词的拼读学习。近年来,随着计算机自然语言处理技术的发展,形音匹配模式的量化统计早已通过计算机实现。G2P技术在机器音译[4]和文字发音预测中表现出极大优势,从而得以广泛应用。例如:百度基于G2P研发的文本语音转换(Test To Speech, TTS)系统Deep Voice[5],相比于传统的多级处理模式,具有处理速度快、音素预测准确、音域适应性强等优点。文献[5]研究表明由于字素和音素的基数相对较小,在发音预测工作中,具有对齐信息的双向神经网络模型对G2P有更好的适应性,该模型的发音预测准确率高达94%,较传统方式有所提升。
前人研究表明了形音匹配规则和字素-音素转换不仅适用于英文学习者的拼读学习,而且适用于机器的文字发音预测。然而其中多数研究为单纯的数据量化,复杂的统计信息不仅不利于学习者的记忆,反而易使其失去学习兴趣。
针对上述问题,本文结合英语学习与发音预测两个领域的研究成果,以形音匹配为中心,选取字素和音素作为共享单元[6]进行探究,使用隐马尔可夫算法模型对单词的形音匹配与发音模式进行分析,探究字素发音受窗口长度与方向影响的影响程度。除此之外,针对传统研究方法中量化数字复杂、理解性差等缺陷,如图1所示,本文采用可视化图形界面以直观、形象、可交互的方式将量化数据呈现给用户,在激发学习者探究兴趣的同时,帮助其快速、形象地理解字素-音素模式,从而有效地提高学习者的英语能力。

图1 系统主界面
本文主要工作如下:
(1) 提出一种基于时序与模式的可视分析方法,探索了窗口大小和方向对不同字素发音稳定性的影响。
(2) 根据模式对字素进行聚类。相似的上下文模式在表示空间中具有更近距离,模式相似的字素会成簇出现。
(3) 统计单个字素在不同模式下的发音数量,探究字素对应发音受不同位置字素的影响情况,分析字素结合发音的稳定性。
(4) 统计单个或多个字素在不同模式下的发音数量,比较多个字素之间在不同模式下的发音稳定性与共有模式数量。探究其准确率对字素在形音匹配模式上的相近关系。
1 相关工作
1.1 英语发音
神经网络技术已经逐渐应用到多个领域,在语音识别技术方面也表现出比较大的优势。神经网络技术主要模拟了人类的神经元活动原理,将人类所特有的自主学习、想象能力综合到英语语音识别中,为语音识别开辟了一道新的途径。自主学习需要人为给予智能系统一个固定的规则,使其通过学习后对输入的信息根据规则进行改造,从而输出人类想要的结果[7]。例如,基于TensorFlow的循环神经网络构建的发音预测系统、基于Keras 开发的英语单词发音预测LSTM模型均能通过端到端的训练得到更为准确的结果。
目前较为成熟的智能系统多以形音匹配关系为核心,借助字素-音素的转换模式可进行文字发音预测、文本语音转换等工作。Deep Voice系统就是利用字素和音素之间的匹配模式加快了深度神经网络的训练速度,解决了TTS系统开发耗费大量人力与时间的问题,也满足了系统应用的实时性要求。该系统的核心是使用连接时序分类器分割音素边界,将文本转换为音素序列后对序列进行重音、持续时间和基频的标注。这些音素的标注信息更加贴近人类对语言的表达机制,因此形音匹配法更加适用于解决语音合成、语音识别和翻译问题[8]。
然而,目前而言,神经网络模型蕴含的量化数据较为复杂,难以深入理解,而英语学习者则希望知道模型究竟从数据中学到何种知识,从而产生最终的决策。因此,本文将采用可解释、易于接受的可视化交互方法对英语的发音模式进行展示。
1.2 可视化分析
尽管前人已经在形音匹配模式上做了许多研究,但发音模式的数据可视化分析研究相对较少。研究表明人类从外界获得的信息中80%以上都来自于视觉系统[9],且数据正在变得无处不在、触手可及,但数据创造的真正价值在于能否进一步提供数据分析[10]。
可视化在数据分析和信息理解中具有重要作用,数据可视化也早已应用到人类社会活动中,如约翰·斯诺制作的伦敦霍乱地图、拿破仑进攻俄罗斯军事分析图、卫报数据中的世界烟草地图集,以及《卫报》制作的伊拉克战争报道等,均使用可视化对数据进行展示。数据可视化一方面可更加准确地对信息进行梳理,让受众易获得信息;另一方面通过图表的表现形式,帮助受众获取文本无法直观获取到的信息[11]。
随着计算机运算能力的提升,数据分析的效率大大提高,但是数据分析仍离不开机器和人的相互协作与优势互补。在分析数据时要以人作为需求主体,得出符合人类的认知规律的方法,需将形象的可视分析与认知抽象的机器分析相结合,帮助受众洞悉数据背后隐藏的信息并转化为可运用的知识[12-13]。目前,综合认知理论、科学、信息可视化及人机交互技术的数据挖掘技术被广泛用于数据分析领域。
综上所述,符合人类的认知习惯的分析和表现方法,可以辅助人们更为直观、高效、形象地洞悉大数据背后的信息、知识与智慧[14]。因此,本文采用数据可视化的形式将分析结论以交互图表的形式进行展示。
1.3 Hidden Markov Model(HMM)算法
隐马尔可夫模型HMM用于描述统计现象,这些现象可被视为产生可观察符号的隐藏状态序列[15]。
一个HMM包含一个可观察层和一个隐藏层。可观察层是待识别的观察序列,用观察值输出概率描述;隐藏层是一个马尔可夫过程,用状态转移概率进行描述。HMM模型主要解决评估、学习和解码问题[16]。一阶HMM中计算状态转移概率时,假设状态序列中的每一个状态只与前一个状态有关;计算观察值的输出概率时,假设任意时刻观察输出概率只依赖于系统当前时刻所处的状态,其过程由矩阵A、B和向量π组成。矩阵A包含隐藏状态的转移概率,矩阵B包含给定隐藏状态的观测符号出现的概率,向量π包含隐藏状态的初始概率[17]。
本文将隐马尔可夫模型理论应用于形音匹配过程,将系统使用语言的拼写作为输入(隐藏状态序列),将自然语言的发音作为系统的输出(观察),由此探究自然语言的词内特征与隐马尔可夫模型的对应关系[15]。与深度学习的不可解释性相比,隐马尔可夫模型具有良好的数据透明性,因此本文没有采用深度学习模型进行分析。
1.4 数据降维方法
针对字素在多个模式下发音的状态观测矩阵维数过高和无特征的特点,对其降维方法展开研究。
基于t-SNE的降维算法,是一种非监督降维算法, 无须预先传入项目的分类标签信息。与PCA、SVD 等线性映射降维算法相比,t-SNE可以更好地在低维空间内表达高维变量之间复杂非线性关系[18]。其算法核心思想是在对高维空间中的点构建概率分布的同时,在低维空间中映射这些点的概率分布,两个概率分布之间尽可能相似,从而达到降维的目的。
本文使用t-SNE降维方法所得状态观测矩阵低维空间的映射点有明显的聚类表现,并且在多个样本上的降维结果显现出一定的规律性[19]。
2 数据处理流程
本节首先描述了数据集的分解流程,在此基础上阐述了隐马尔可夫算法在不同窗口下的处理流程。
2.1 字素音素分解流程
(1) 根据目的所需,获取朗文字典中的词汇的拼写、音标以及词性等相关属性。
(2) 根据词性以及词汇的大小写情况对词汇的缩写以及专有名词进行剔除。
(3) 将剔除后的数据,根据威尔逊阅读系统解码、编码规则将词汇和音标进行拆分,形成字素-音素联合单元。对于一个给定的字素,其对应的音素通常是不唯一的。由于划分过程中存在两个相同的字素相连的情况,无法精准确定发音由前后哪个字素所得,因此在划分时将相邻相同字素进行了合并。通常,字素和音素序列长度相等,且一一对应。在这些排列中,一个字素可能对应一个没有发音的空音素、一个单一的音素或一个复合音素。复合音素是两个音位的连接。
(4) 将词汇中的特例额外划分,保证划分的准确性。
2.2 HMM窗口处理
HMM根据窗口值大小w大于1与等于1两种情况做区分处理,其区别在于:
(1) 在t+1时刻的状态qt+1的转移概率依赖于w-1个状态的影响。例如,窗口大小w=2(L/R=1/0)时,t+1时刻的状态qt+1依赖于t时刻的状态qt和t-1时刻的状态qt-1,其中L/R中的L和R分别表示观察字素左侧和右侧的字素长度。
(2) 在t时刻释放观察值Oi的输出概率,不仅依赖于系统当前所处的状态Si,同时依赖于系统前一时刻所处的状态Si-1。
图2表示的是窗口大小w=2(L/R=1/0)时的HMM模型。
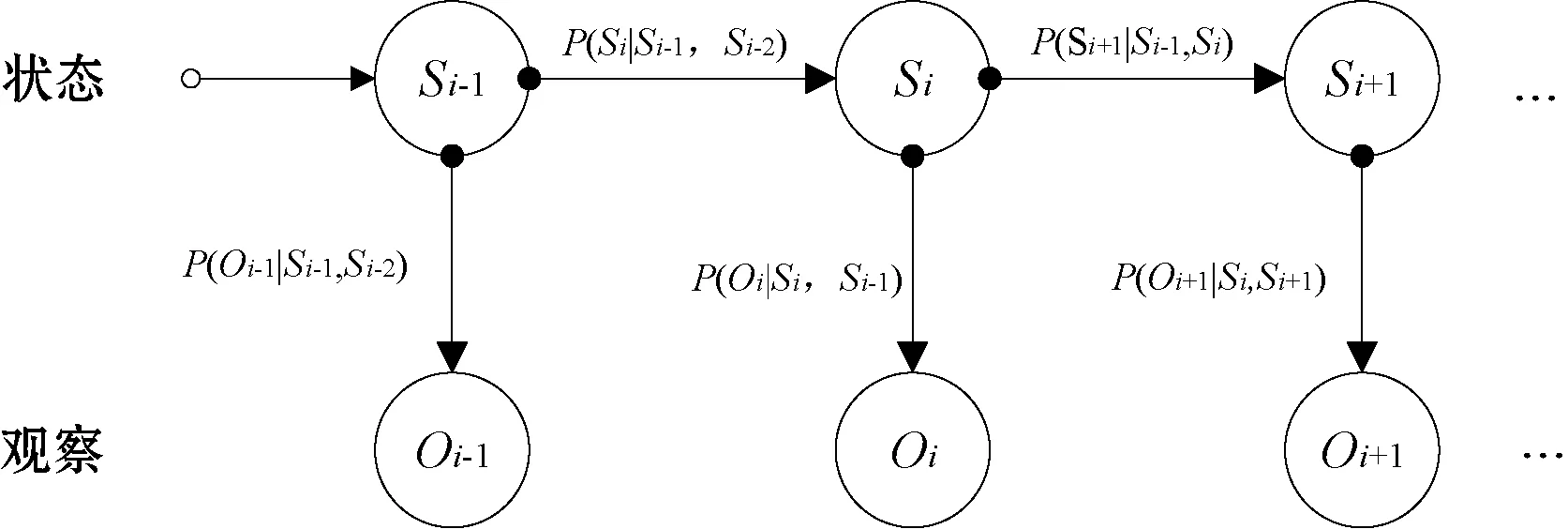
图2 HMM在w=2(L/R=1/0)时的模型
3 可视化分析
本文首先根据数据的窗口大小,对字素发音的整体影响音素进行统计分析,然后根据任务和设计目标, 提出并实现了一个基于形音匹配的可视分析系统。系统包含字素稳定性分析视图、词云分析视图、模式关联图、模式对比图。可视分析以数据集中全部字素的总览为起点,对词云中字素进行筛选探索并对比较词云中相邻字素的发音变化和相似规律,最后对单个字素的发音模式根据窗口大小的变化进行模式分析,以得出邻接字素对目标字素发音的影响规律。
3.1 窗口大小解析
本文对《朗文高阶美语词典》中经过筛选的28 073个词汇(对应192 283个字素)进行隐马尔可夫模型发音预测。针对不同窗口大小w、左右两边不同数量的相邻字素L/R、预测准确发音的单词数量#word与其占总词汇数量的比例pword、匹配准确音素的字素数量#pron与其占总匹配对数量的比例ppron以及在相同窗口不同位置的相邻字素影响下音素匹配准确的单词数量#wordw和概率pw情况进行数据分析,分析所得结果表1所示。

表1 受不同数量的邻近字素影响时概率变化表

续表1
通过观察表1中研究结果可以发现,词汇发音预测准确率主要受两个方面的影响:① 窗口大小。当观察字素两边分布相对一致时,随着w增加,实验所得发音准确的词汇数量以及正确匹配对的数量均呈上升趋势。例如:w=2(L/R=1/0)与w=5(L/R=4/0)相比,准确匹配音素的概率从70.82%上升到86.84%,准确预测词汇发音的概率从15.77%上升到41.05%。② 字素与待匹配字素相对位置关系。窗口大小不变时,受影响字素与待匹配字素的相对位置不同,获取到词汇的准确发音数量存在明显差异。例如w=4(L/R=1/2)与w=4(L/R=3/0)相比,前者准确匹配音素的概率为91.09%,而后者仅有83.56%。
3.2 发音规律分析
英语在字素的发音上不存在完全精准的模式,因此对于多个字素,即使其随窗口大小增加,发音模式稳定性也无法达到100%。例如,字素在从窗口大小w=2时对应的所有音素准确率为98.50%;当窗口增加到5时,字素对应的所有音素准确率增加到99.01%,准确率仅提高了0.51%。
前文分析已得出,随着窗口大小的增加,音素准确率呈增长趋势。然而窗口长度的过分增加,不仅对音素准确率的提升效果不明显,反而对大脑记忆增添负担,复杂的记忆工作会直接降低学习者学习英语的积极性。因此,应当合理选取窗口进行可视化呈现,以获取音素准确率与记忆成本间的最大平衡。
3.3 字素稳定性分析视图
字素稳定性分析视图采用对称条形图的不同柱状长度呈现字典中所有字素在不同窗口大小和方向下的音素准确率。
图中以纵坐标轴为界,左半部分表示不同窗口大小下受左侧字素影响强度不弱于右侧时匹配的准确率情况,右半部分表示不同窗口大小下受右侧字素影响强度不弱于左侧时匹配的准确率情况。字素稳定性分析视图的计算基于隐马尔可夫算法,视图中所有字素均可结合窗口大小进行对比分析。图中柱状长度由窗口大小与字素在窗口中的分布位置决定。
对多个字素的匹配准确率进行对比分析,总结出字素发音稳定性情况呈现以下几种类别:相同窗口大小下受左侧字素的影响程度强于右侧、相同窗口大小下受右侧字素的影响程度强于左侧、字素匹配准确率随窗口大小的增加而显著提升、字素匹配准确率不受窗口大小影响而基本持平。
3.4 字素词云分析视图
词云分析视图是学习形音匹配模式的入口,图中信息包括数据集中字素的二维分布与字素在模式上的相近关系。字素在词云中的相对位置反映了字素之间模式的相似程度。字素的位置由数据集中字素的模式通过t-SNE降维方式获取,对于模式差距较大的字素,在视图中的距离也会偏大。在探究字素之间的关系时,用户可以根据降维可视化形成的簇进行对比分析。
3.5 字素模式关联图
分析字素模式关联图可得单个字素的发音情况,视图中根节点为所选字素,与根节点相连接的是该字素的所有发音情况,字素的发音由叶子节点和中心字素共同决定。叶子节点的大小与对应字素的数量成正比,当同一个叶子节点连接到不同的音素时(如图中、
3.6 字素模式对比图
字素在不同模式下发音对比图,对词云中选取的字素进行统计分析。本视图主要针对多个字素的所有模式进行分析,在横坐标排布上服从先共有模式,后私有模式。用户可以从视图中直观地比较多个字素之间在不同模式下发音的稳定性情况。研究发现,两个字素存在共有模式数量及其准确率对字素在形音匹配模式上的相近关系起决定作用。
本文通过该可视分析系统的四个交互图表直观体现了字素间的音素匹配模式,从而帮助用户高效地学习英语形音匹配模式。
3.7 可视化交互
本系统通过可交互视图集与可视化展示视图集进行数据联动的方式(可交互视图集:字素稳定性分析视图、词云分析视图;可视化展示视图集:模式关联图、模式对比图),提供丰富的交互功能,满足用户的学习及研究需求。
用户可在字素稳定性分析视图选择待分析的字素,点击待分析字素后,模式关联图区域数据更新,变更为选定字素的模式关联图,向用户展示当前字素的详细模式信息,帮助用户学习字素发音规律,提高用户拼读能力;用户可在词云分析视图选择单个或多个字素,选中或退选字素后,模式对比图区域进行相应数据更新,模式对比图中会增加选中的字素分析曲线,删除退选的字素分析曲线,最终呈现全部已选择字素的发音模式,将字素间发音模式的相似程度直观展示给用户,辅助用户关联记忆或探索研究。鼠标悬停可以显示相应数据的详细信息。
4 案例分析
虽然目前已有许多关于字素的发音模式研究, 但利用可视化技术进行的相关研究相对较少。而且目前针对上下文字素对观察字素发音影响的研究以及字素之间模式相似性的研究并不详细。因此本文采用可视化技术,通过可视交互图表对观察字素进行发音模式分析和相似性对比。
本文通过两个案例来介绍系统的可用性与效率。案例一选取字素
4.1 案例1:字素的发音分析
选取字素之后时发/yu/音;(2) 4.1.1纵览字素 进入字素的可视分析系统界面,从字素稳定性分析视图(图1)中点击对应的字素 图3 图3中使用对称条形图展示所有窗口下准确匹配音素的概率,概率分布基本符合随着窗口大小增加,准确率增加的情况。在窗口方向上,为了与自然拼读法中的模式进行对比,本文选取受左侧字素影响的情况进行分析。 条形图左右对比可得,右侧模式的影响强度普遍高于左侧。当窗口长度为2时,形音匹配准确率可达80%以上,相较于窗口大小为1时显著提升,但窗口大小增至为3时变化不明显。因此,选取窗口大小为2进行字素发音模式分析最有效率。 4.1.2模式分析 模式关联图可直观地展示出该字素发音存在三种情况。如图4所示,分别是/u/、/yu/和//,其中音素/u/占比最大。当查看单个发音情况时,可以清晰了解到受影响字素的情况以及占比大小。当字素发音为/yu/时不仅满足字素 图4 字素 进一步研究表明,字素 选取多个字素发音模式进行对比。该案例选择的字素列表为[ 4.2.1[ 通过词云分析视图选取列表中的字素,已选字素在词云颜色加深显示,在选取过程中,可根据字素在二维平面内的相对位置了解字素之间的相近程度。图1词云分析视图中字素 借助前文得出的结论,本文同样保持窗口长度为2,分别统计 图5 [ 4.2.2[ 对于字素列表[ 图6 [ 本系统的研发过程中,与多位英语专家进行了为期半年的沟通合作,不断获取反馈,并进行系统迭代。最后由多位专家与不同英语能力层次的高校学生进行实际操作与深入使用,对系统做出最终评价。 本系统设计目标明确、易用性强,使用者在了解各个视图的设计目标、交互方式、功能意义后,很快熟悉整个系统并开始使用。 通过分析多名使用者对本系统的操作反馈,得出结论:该系统可以帮助零基础使用者迅速获取字素发音模式的相关知识,帮助有基础的使用者提高自然拼读法水平或掌握更多形音匹配模式,帮助专业英语研究者寻找具备发音模式相似性的字素,从而更深层次研究字素之间的关系,甚至可以引申至英语乃至印欧语系形音匹配发展的研究。 使用者认为该系统功能丰富、交互性强,通过在多种维度上进行统计分析,充分提取有效信息,可以满足各类人群的不同需求,对英语学习者和英语研究者都有巨大的意义。 使用者们对本系统的多个可视图表设计表达了见解,对于模式关联图,学生们表示该图信息丰富,从字素前后模式角度对字素音素匹配模式进行分析,直观表达既定窗口下的模式及其影响力,同时可以通过字素稳定性分析视图来调整窗口大小,由此提取更深入的形音匹配模式;对于词云分析视图,学生们表示词云的关联交互功能可以通过模式对比图分析字素发音模式的相似度。该系统创新性地将模式用可视化的方式展示,极大缩短了相似度分析所需的时间。 专家对完善的可视化界面与丰富的交互功能作出了总体肯定,同时提出本系统过于注重字素音素的形音匹配而忽视读音的轻重音节意义的问题,并对该问题提出了改进意见。 本文通过使用隐马尔可夫模型将字典中所有词汇的字素、音素进行量化统计,考虑窗口方向与大小后选取合理窗口值对量化数据进行降维与可视化;用简单易懂的可视化形式将复杂枯燥的统计结果展示给英语学习者,学习者可以通过自身需求,借助系统的交互功能选取字素进行发音学习。系统在发音规律方面可给予英语学习者明确有效的指导,从根本上解决了词汇拼读难等问题,从而大幅提升学习者的阅读能力。 但本系统与目前获取的量化数据在英语学习的简化上还有很大的提升空间,需要进一步探索。实验中对于部分单元音字素,在窗口大小达到w=4时依然未能达到80%的准确率,而且单元音字素对应的音素数量相对较大。通过本文所用方法来进行音素匹配过于繁琐,该问题仍需合理的方案进行解决。
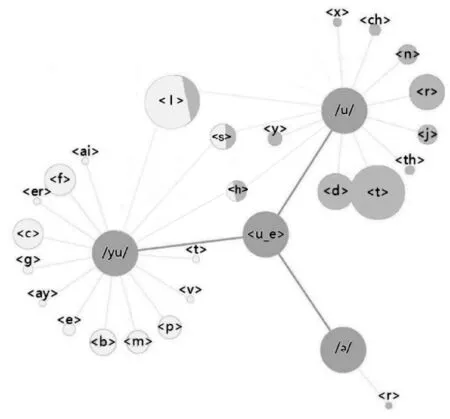
影响时,其发音存在不稳定现象,该字素同时连接音素/u/、/yu/,此时无法确定4.2 案例2:多字素发音模式对比


5 用户反馈
5.1 系统设计
5.2 可视与交互设计
6 结 语
