基于谱聚类的虚假评论群组检测
2021-08-12叶子成王帮海
叶子成 王帮海
(广东工业大学计算机学院 广东 广州 510006)
0 引 言
国内外大量研究表明,阅读对某一事物的网络评论是当前人们获得信息的重要途径之一,评论很大程度会影响其对某一事物的看法。在电商平台中,不良商家为了获得更大的利益,会利用虚假评论对消费者的消费决策进行误导。在网络媒体中,个别媒体团队会利用虚假评论控制舆论、获取流量并从中受益。
随着网络社交平台的兴起,一种由关键意见领袖[1]进行宣传,运营团队同时对商品发表不真实评论的模式随之流行。关键意见领袖负责在单群组或多群组中进行有效的信息传播,推动粉丝在短时间内发布大量评论,使目标商品在短时间内获得许多真假混杂的评论,增大虚假评论群组的检测。虚假评论群组[2-3]指的是多个评论者通过组织协同地对同一个或同一组商品发表虚假评论。发布虚假评论的用户共同构成虚假评论群组,群组内的个体之间不一定有直接关联,但通过领导者的组织策划,虚假评论群组可以有规模地针对多种商品协同发布虚假评论。虚假评论群组的危害性远远大于虚假评论者个体的危害性,群组通过组织者的策划在一段时间内发表大量虚假评论,可以控制目标商品的评论风向,影响正常用户的消费决策。
现有的针对虚假评论群组检测的研究工作多采用频繁项挖掘或聚类算法获得候选群组,再通过具备领域知识的专家进行人工标注得到候选群组的类别或对群组的联系及内部特征进行分析。Jindal等[4]利用一种排序模型确定虚假评论群组的可疑程度。Lim等[5]认为在同一个群组中评论者们在行为上有以下共性:(1) 更可能集中在一个时间段内对某一个商品发表评论;(2) 群组中的成员对一个商品的评分与真实用户给出的评分存在偏差,即群组偏差(Group Deviation),群组偏差反映了群组欺诈行为的程度;(3) 虚假评论群组在某一个商品中发表评论越早,越能控制商品的评价风向,发表虚假评论的动机也更充足。Xu等[6]在FraudInformer排序算法中利用多组特征(pairwise features)对评论者进行打分和排序,并根据行为特征对反映的信息判定两个虚假评论者是否强相关,若强相关,则二者属于一个虚假评论群组的可能性更高。Xu等[7]基于文献[6]提出的特征对,用改进的KNN聚类算法和图分类算法进行聚类。在改进的KNN聚类算法中研究者选择k个最相似的评论,然后使用投票法判断通过聚类分类的群组是否属于虚假评论群组。而在图分类算法中则通过对目标函数求最优解获得给每一个评论者所属的标签,并未对群组有进一步分析。Ye等[8]引入了网络足迹分(Network Footprint Score, NFS)的概念用于量化一个商品是否成为虚假评论群组目标的可疑程度以及评论者行为的反常程度,随后用其所提出的GroupStrainer算法对由可疑商品和可疑评论者构成的2-hop子图进行层次聚类,从而检测到虚假评论群组。Mukherjee等[2]使用频繁项挖掘方法找到一组候选群组,再运用GSRank模型对候选群组属于虚假评论群组的概率进行计算。张琪等[9]根据虚假评论者的行为指标构建带权评论图,对可疑子图进行筛选,确定嫌疑较大的评论者,再使用Louvain社群发现算法[10]将可疑评论者进行分类。
已有的研究主要针对虚假评论群组的三个方面进行研究:基于群组内容和行为特征的检测方法,基于群组结构的检测方法,基于网络结构的检测方法[11]。本文提出的一种基于评论者相似度矩阵的谱聚类群组检测算法(Spectral Clustering Group Detection Algorithm based on Reviewer Similarity Matrix,SCGDA),并对检测出来的候选群组进行分析和研究,补足了文献 [2,4,9]的不足。与文献[9]相似的是,SCGDA同样使用带权评论者图作为谱聚类的相似度矩阵。本文工作与其最大的不同之处在于,文献[9]通过设置阈值基本筛选出可疑用户,再进行群组结构发现和分析;而本文工作强调先对群组进行检测,再根据候选群组的内部特征进一步判断所属类别。此外,文献[9]在对实验数据预处理阶段删除了不活跃的用户和产品数据,本文认为移除部分数据虽然有利于降低算法的时间复杂度,考虑到电子商务平台会对违规账号进行封禁,虚假评论群组不得不使用多批账号发布虚假评论,这些账号很大可能就是刚注册的账号或是不活跃账号,同时,移除部分数据会改变数据集的结构,无法有效体现出算法的鲁棒性。另外,在关键意见领袖模式下,一些基于文本分析进行检测的算法[12-13]或利用评论爆发性进行检测的算法[2,7-8,14-15]表现不佳。SCGDA利用用户发布评论的行为特征检测不同群组,适合对以关键意见领袖为核心的虚假评论群组进行检测。下面将介绍用户相似度度量指标的选择和带权评论者图的构建过程,并利用带权评论者图的邻接矩阵作为相似度矩阵,通过谱聚类的方法完成群组检测。之后,本文将对不同候选群组进行分析,根据不同群组特征来度量候选群组的可疑程度,并与其他群组检测算法进行比较。
1 用户相似度度量指标
许多研究者[4,7,9,16]提出了一些能够反映虚假评论者或虚假评论群组异常程度的指标,这些指标被广泛应用于检测虚假评论或检测虚假评论者的不同模型中[2,8-9,16-17]。本文使用的带权评论者图以用户作为节点,因此从用户的互动行为和自身行为两个方面选择了能够反映评论者异常程度的5个指标:共同评论次数,同一商品的评分相似度,用户互动次数,积极评分比例和消极评分比例。
共同评论次数是两个用户对相同商品进行过评分的次数,该指标越高,表示两个用户在相同商品发表过评论的次数越多,这两个用户的行为越可疑。
同一商品的评分相似度用于度量两个用户在共同评论过的相同商品上给出评分的相似程度。当两个用户有过多次共同评论相同商品的经历时,该指标可以进一步反映用户的异常程度。
用户互动次数指的是两个用户所发表的评论收到的互动行为(如认为该评论“有用”)的次数。虚假评论群组的成员为了提高虚假评论的可信度和曝光率,会采用点赞、认为“有用”等方式进行互动。由于群组大小不同,不同群组成员的互动次数差异较大,但同一群组成员的互动次数则比较相近,因此该指标可以反映用户互动行为的相似程度。
积极(消极)评分比例是用户给出积极(消极)评分次数占所有已给出评分次数的比例,虚假评论者为了抬高或降低商品的平均分,因此给出极端评分的概率远远高于普通用户。利用该指标可以度量极端评分比例,进一步地,利用欧氏距离度量两个用户在积极(消极)评分比例上的相似程度。
由于虚假评论群组中的成员具有共谋性,互动行为指标能够捕获不同用户的关联行为。对已产生关联的可疑用户,再进一步结合用户行为指标可以度量两个用户自身行为的相似程度。总之,上述5个指标涵盖了用户的互动行为和自身行为,能准确地反映用户间的相似程度,在这5个指标中得分越相近的用户在行为上越相似,更可能被认为属于同一群组。
1.1 互动行为指标
互动行为指标反映的是一个用户的行为与其他用户的行为的关联程度。本节将对共同评论次数(Co-Reviewing Times, CRT)[9]、同一商品的评分相似度(Similarity of Rating on Same Product, SRSP)[3,9]和用户互动次数(Interaction Times, IT)进行介绍。
1.1.1共同评论次数
文献[5,9]认为,两个评论者对同一个商品发表评论的次数越多,二者越有可能是同属一个群组的虚假评论者。由于虚假评论群组的协同性,在同一群组内的成员有更多相同的评论目标,而正常的用户因用户性别、年龄、收入和兴趣爱好等不同而有不同的消费行为,两个正常的用户往往不会出现多次对同一商品均进行评论的现象。因此,本文选择共同评论次数[9]作为用户相似度度量指标。
CRT(n1,n2)=|P1∩P2|
(1)
式中:n1、n2为两个不同的评论者;P1、P2分别为n1、n2发表过评论的商品集合。
1.1.2同一商品的评分相似度
同一虚假评论群组的成员往往有共同褒扬或贬低同一商品的目标,因此,属于同一群组的成员不仅仅在相同商品上有较多的评论次数,即CRT更高,而且对相同商品会给出更相近的评分。本文在文献[3,9]的基础上提出同一商品的评分相似度。
(2)
式中:n1、n2为两个不同的评论者;SP1i、SP2j分别为n1、n2对商品P发表第i或第j条评价的评分;N1、N2分别为n1、n2在商品P上发表的评论数。
1.1.3用户互动次数
虚假评论群者通常会在电商平台上进行互动,如进行给已发表的虚假评论点赞、评论等互动行为,从而提高评论的可信度和账号的活跃度。由于虚假评论者往往一人操纵多个账号,因为操纵者的个人习惯,虚假评论账号的互动次数有相似的互动频率和互动次数。在此基础上,本文定义用户互动次数(Interaction Times, IT) 来衡量不同账号间互动行为的相似程度,计算式为:
(3)
式中:C1i、C2i分别表示n1、n2第i种互动行为的次数。数据集中共有N种互动行为。本实验中,N取3,三种不同的互动行为分别为“发表的评论被其他用户认为有用”“发表的评论被其他用户认为很酷”“发表的评论被其他用户认为有趣”。
1.2 用户行为指标
用户行为指标反映的是用户自身的行为特征,如最大日评论数(Maximum Number of Reviews, MNR)[18]指的是用户在单日发表最多评论的数目,这是一个异常的用户行为特征;极端评分比例(Extreme Rating, EXT)[18]指的是用户给出的极端评分数量占给出评分数量的比例。由于虚假评论者的目的往往是大幅提高或降低某个商品的平均分,因此虚假评论者给出的极端评分比例会远远高于普通用户。
本文认为一个群组内的评论者有相同的目标,因此虚假评论者给出的好评或差评数量也会相近。本文对两个用户的好评占比和差评占比进行统计,并分别计算两个用户给出的好评(差评)比例的相近程度。评分的区间为[1,5],认为1、2分为差评,4、5分为好评。则用户的积极评分比例(Positive Rating Ratio, PR)定义为:
(4)
式中:|·|表示该评分出现的次数。
消极评分比例(Negative Rating Ratio, NR)定义为:
(5)
用欧氏距离度量两个用户PR和NR的相似度:
(6)
式中:rn表示为评论者n的PR或NR。
2 虚假评论群组检测算法
2.1 带权评论者图
异构评论图(Heterogeneous Review Graph)[19]以用户、评论和商品作为三种不同类型的节点,当两个不同类型的节点发生关联后则相应地在两个节点之间产生一条边来描述节点间的关系。不同于异构评论图,张琪等[9]仅以用户作为节点,以用户之间的相似程度作为权重构建了带权评论图。本文在其工作的基础上增加了用户互动次数、用户行为指标计算边的权重,构建带权评论者图。构建过程如下:
(1) 将每个评论者作为一个节点添加到图中,构成图G=(V)。
(2) 利用第1节中提到的用户相似度度量指标构建图的边。由于两名虚假评论者属于同一群组,则其必然在相同商品中发表过评论,因此在构建图的边时先对图G=(V)中两两节点的所有组合进行遍历,当且仅当两两评论者共同评论过至少一个商品,即共同评论次数大于0时,在代表这两个评论者的节点之间建立一条边,构成无权图G=(V,E),其中:V表示点集;E表示边集。
(3) 对所有边(vi,vj)∈E,分别计算节点vi、vj之间的共同评论次数(CRT)、同一商品评分相似度(SPSR)、用户互动次数(IT),以及用户积极(消极)评分比例相似度。
(4) 利用各项度量指标计算所有边(vi,vj)∈E的权值。张琪等[9]选用的2个造假行为特征各占0.5的权重;Dematis等[20]提出的模型根据选用的各项评分指标的取值范围来确定各指标的权重,最终令各项指标在式中占据相近的比例。本文选用的各度量指标分别衡量节点不同维度下的相似程度,可以认为各指标的重要性相同。由于各指标的取值区间不同,因此将其归一化至[0,1]后取相同权重用于计算权值ω,即:
SimilarityNRij)
(7)
式中:k=5。
2.2 利用谱聚类进行群组检测
谱聚类[21]是一种从图论演化而来的聚类算法。它的核心思想是对带权图进行切割,使得切图后不同子图之间边的权重之和尽可能低,同一子图内边的权重之和尽可能高。文献[22]指出谱聚类算法是用图所对应的矩阵特征向量表示图的结构特征关系,再对这些特征采用经典聚类算法实现聚类。本文算法利用多分类正则切的谱聚类[23]方法对2.1节中构建的带权评论者图进行切割。具体地,利用谱聚类进行群组检测的基本流程如算法1所示。
算法1谱聚类检测群组
输入:带权评论者图G(V,E),检测簇的个数n。
输出:n个候选群组C=(c1,c2,…,cn)。
1. 由带权评论者图G计算邻接矩阵A、度矩阵D以及拉普拉斯矩阵L=D-A。
2. 根据式(8)获得标准化的拉普拉斯矩阵NL:
NL=D-1/2(D-A)D-1/2=D-1/2LD-1/2
(8)
3. 计算NL最小的k个特征值及其对应的特征向量f,k取检测簇的个数n。
4. 将各自对应的特征向量f组成v×k大小的特征矩阵f并按行标准化,v为样本数,即图G节点的个数。
5. 利用K-means方法对f按行进行聚类,检测得到n个候选群组C=(c1,c2,…,cn)。
3 实验及结果分析
3.1 数据集
Mukherjee等[17]从美国最大点评网站Yelp上分别爬取了芝加哥地区85家酒店和130家餐厅的评论数据分别构成Yelp-Hotel和Yelp-Restaurant数据集。随着多年的发展,Yelp的虚假评论过滤算法具有足够高的准确率,且在Yelp网页上,被过滤算法识别出的虚假评论会被置于虚假评论区,而过滤算法认为正常的评论将被置于常规页面。Mukherjee等将从商品(酒店或餐厅)的虚假评论区中爬取的评论数据置为正类标签“Y”,将从商品的常规页面爬取的评论数据置为负类标签“N”。此外还从评论者主页中爬取每一个评论者发表过的评论(不限于酒店、餐厅商品类别),将没有出现在常规页面的评论认为是被过滤的虚假评论并置为正类标签“YR”,否则置为负类标签“NR”。从评论者主页爬取的数据极大丰富了以“用户”为中心的评论信息,由于爬取的许多用户曾发表过虚假评论,因此该数据集(涵盖Y、YR、N、NR四类标签)是一个不平衡的数据集。本文对数据集中具有不同虚假评论程度的群组进行检测,文献[9,24]表明虚假评论占比超过10%的用户有较大可能性是虚假评论者,因此虚假评论更多的不平衡数据集有利于不同层次群组检测工作的进行。此外,该数据集的虚假评论多以“用户”为中心进行爬取,因此也适合对聚类后的群组进行内部特征分析。
本文在带权评论者图构建阶段,选择了酒店数据集中的评论者ID、商品ID、评论评分和评论被认为是“有用的”次数、评论被认为是“有趣的”次数、评论被认为是“很酷的”次数对边上权值的计算。由于虚假评论群组中会因账号异常等原因而更换所控制的账号,本实验不做删除不活跃用户的预处理,即采用完整的数据集进行实验,数据集共有5 132位评论者、688 329条评论、283 291件评论者发表过评论的商品。
3.2 聚类结果分析
SCGDA可以将数据集中5 132位评论者聚类到n个不同的簇中。由于在后续的工作中需要对群组特征进一步分析,为了更好地体现群组内部特征,本文将选取个体大于10的群组进行分析。本文计算了聚类后个体小于10的群组占比,作为簇个数n的选择指标,各聚类簇数下获得成员数小于10的群组数量及所占比例如表1所示。
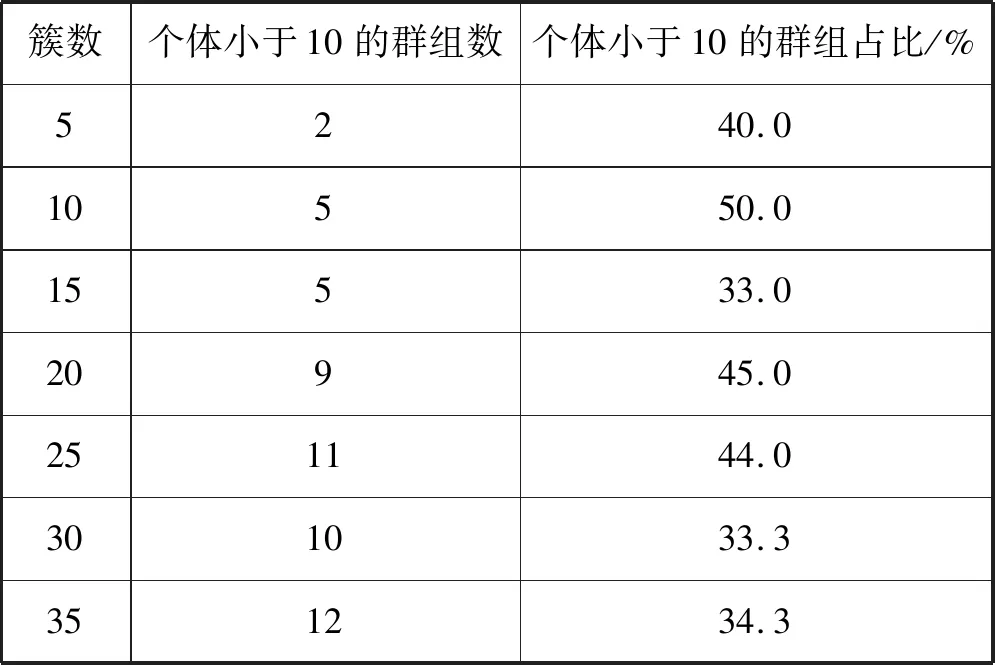
表1 不同簇数下聚类获得个体小于10的群组数
根据个体小于10的群组占比,本文选择了簇数n=15进行群组检测。
现有的研究对于虚假评论占一个虚假评论者发表评论的比例的定义尚不明确。Li等[24]认为被大众点评(dianping.com)网站检测出虚假评论占已发表评论10%以上的用户为虚假评论者。张琪等[9]检测出来的12个虚假评论群组中,共有6个群组成员所有成员虚假评论占比为10%以上,所有群组的平均占比达到94.8%;成员占比为15%以上的,所有群组平均占比为86.1%;成员占比为20%以上的,所有群组平均占比为77.8%。综合上述文献的研究结果,可以认为发表虚假评论占发表评论10%以上的用户有较高的可能性是虚假评论者,发表虚假评论占发表评论20%以上的用户可以基本确定是虚假评论者。本文分别对检测获得的15个群组中发布了10%、15%、20%以上虚假评论的人数进行计算,群组检测情况以及发布不同比例虚假评论人数占比如表2所示。

表2 群组检测情况及发布不同比例虚假评论人数占比
可以看出,除了人数小于10的群组外,至少有90%的成员发表虚假评论占比超过10%的群组共有四个,所有群组的大部分成员均发布了至少10%以上的虚假评论。此外,除了10号和12号群组,其他群组成员发布的虚假评论均占到所有发布评论的30%以上,情况十分可疑。考虑到本文使用的数据集是一个不平衡的数据集,可以认为检测出来的群组是活跃度不相同的虚假评论群组。
3.3 群组特征分析
本节主要介绍用于分析群组特征的几个指标并利用这些指标对检测得到的群组进行分析,同时本文选择K-means、层次聚类两个经典聚类算法,以及Louvain算法这一常用于虚假评论群组检测的算法对带权评论者图进行群组检测对照实验,以验证本文算法的有效性。其中:K-means和层次聚类算法取与本文算法相同的簇数n=15;Louvain算法是一种基于模块度的社区发现算法,无法预设其检测群组的数量。本文通过对该算法的参数调整使其检测的群组数量最接近本文算法选择的簇数,Louvain算法检测获得13个群组。
3.3.1极端评分比(ExtremeRatingRatio,ERR)
Mukherjee等[18]认为虚假评论者更倾向于发布极端的评分(在[1,5]的评分区间中给出1分或5分将被视为极端评分)以控制商品的平均分朝着目标方向变化,因此提出了极端评分(Extreme Rating, EXT)的概念。张琪等[9]利用该指标计算一个群组成员的平均极端评分比作为衡量群组检测好坏的指标之一。本文对四种方法检测出的虚假评论群组分别计算极端评分比,其降序排列结果如表3所示。

表3 不同方法检测的各虚假评论群组极端评分比
可以发现,Louvain算法和SCGDA对比K-means算法及层次聚类算法均有较好的表现,Louvain算法检测出来的虚假评论群组中有7个ERR更高,而SCGDA检测出来的群组中有11个群组ERR更高,从图1可以直观地看出Louvain算法和SCGDA划群组的ERR趋势。
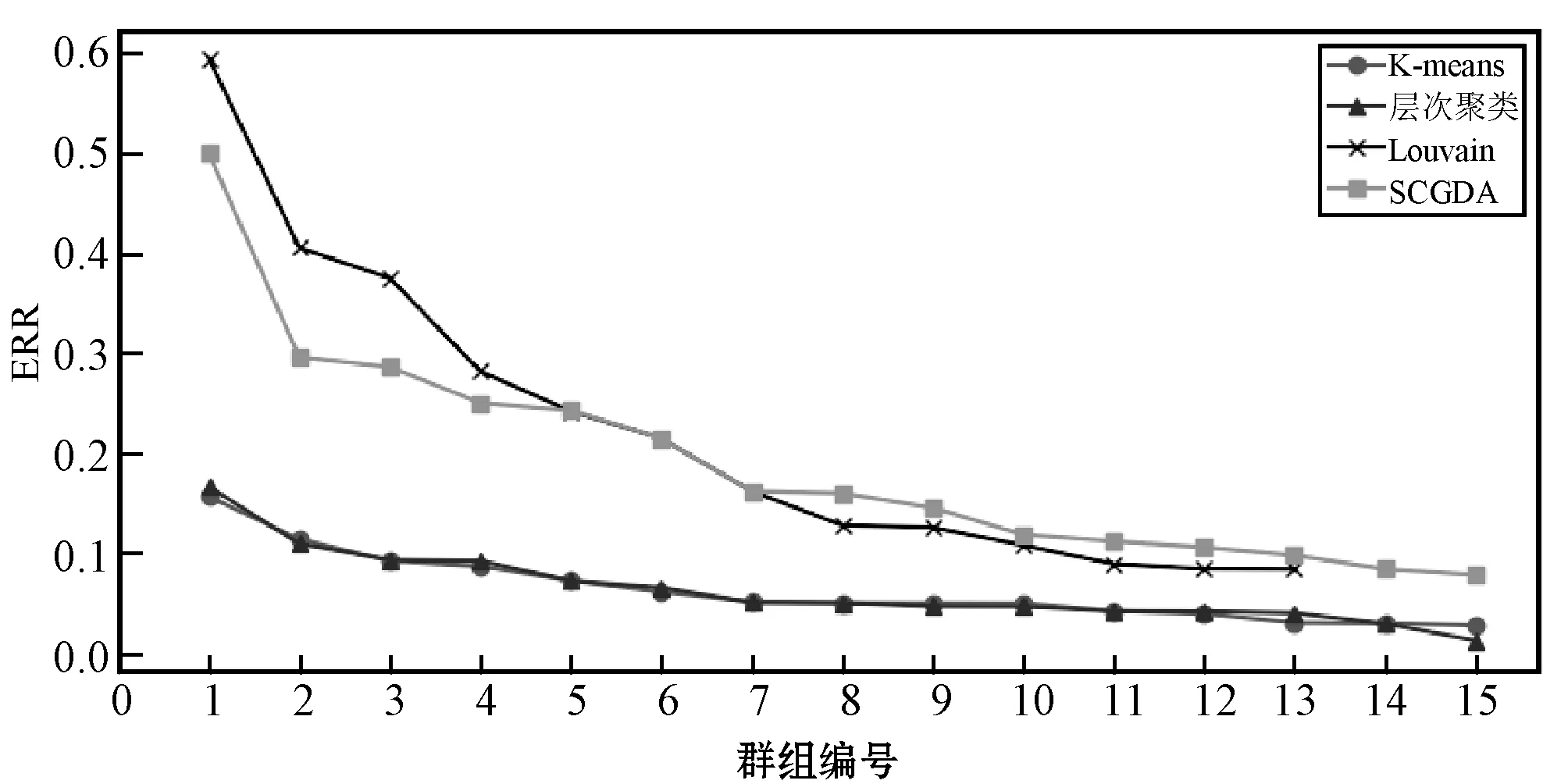
图1 不同方法检测的各虚假评论群组极端评分比
可以认为,即使Louvain算法可检测得15个群组,SCGDA的第14、第15号群组ERR值更高。更高的ERR值意味着群组的可疑程度更高,在该指标下SCGDA表现更好。
3.3.2重复评论比(RepeatedCommentRatio,RCR)
文献[15]研究认为同一ID在相同商品中发表多次评论是一种可疑的、不正常的行为。本文将检测出的虚假评论群组进行统计,重复评论比指的是同一群组中,同一用户对同一商品进行的重复评论占该群组所有发布评论的比例。每个群组的重复评论比如图2所示。
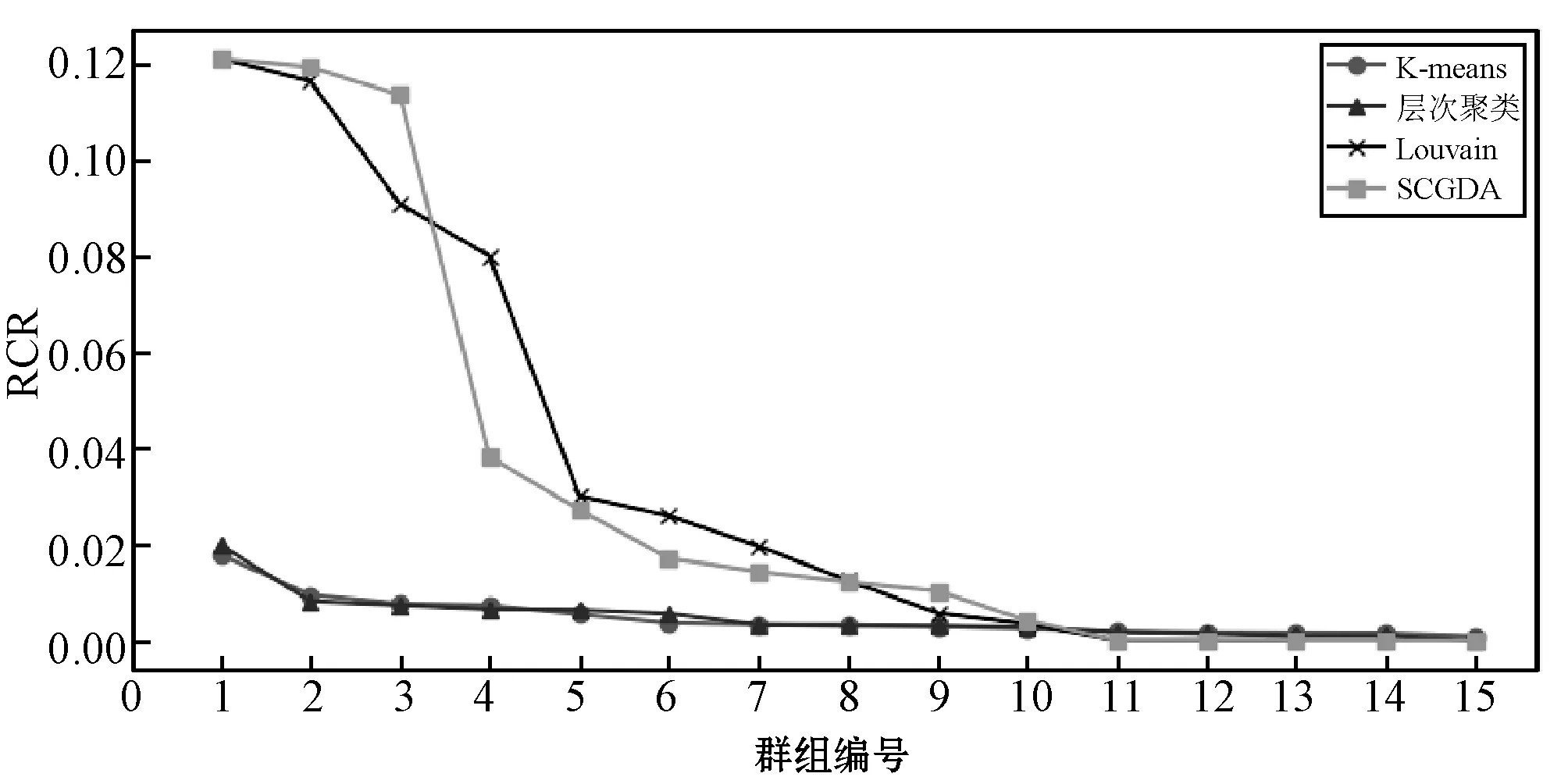
图2 不同方法检测的各虚假评论群组重复评论比
可以看出,本文算法与Louvain算法表现更好,而其他算法的表现较差。可以认为,SCGDA检测的群组中,有3个群组超过10%的评论都是在进行“刷评论”的行为,在实验中每一种算法都检测出RCR值趋于0的群组,这是由于这些群组规模都特别小,发表评论数量不多,因此在同一商品上重复评论的可能性也较低。
3.4 评分偏差(Rating Deviation, RD)
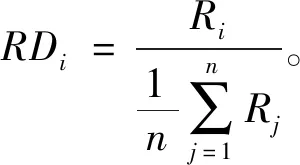
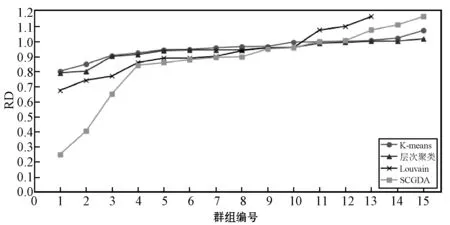
图3 不同方法下检测的各虚假评论群组评分偏差
在评分偏差值较小的前段,本文算法表现明显优于其他算法;在中段各算法的表现差距不明显,本文算法略优于其他算法;在RD值较高的后段,SCGDA及Louvain均略逊于两类经典算法,然而本文算法的表现仍比Louvain算法略优。整体而言,本文算法的表现较好。
4 结 语
本文提出的SCGDA将优化后的带权评论者图和谱聚类算法结合,并以此完成在Yelp数据集中的群组检测工作,即先针对元数据选择特征,再构建带权评论者图,最后利用谱聚类算法对其进行检测获得不同候选群组。本文选择了3个常用于群组检测工作的算法在同一带权评论者图上进行群组检测作为对照实验,并在“极端评分比”“重复评论比”“评分偏差”三个虚假群组指标上进行比较。实验结果表明,本文算法的群组检测效果整体上要优于其他方法。
实际中,评论的正面或反面倾向与被评论对象的形象之间往往有一定的关系,但用户个体的下一条评论是正例或是反例具有不确定性,且受限于数据集,难以对个体是否属于欺诈者定性说明。未来的工作考虑从评论的正反面和被评论对象的关系进行挖掘,并对带权评论者图的构建过程和谱聚类方法进行进一步完善,考虑用户间的潜在联系以进一步提升群组检测的准确度,从而提高本文算法的群组检测效果。
