基于高斯混合模型的一种工业供应链销售预测方法
2021-08-12戎荷婷杨佳云高福祥
戎荷婷 姚 兰 杨佳云 高福祥
(东北大学计算机科学与技术学院 辽宁 沈阳 110819)
0 引 言
随着计算机技术不断革新,工业供应链中的产品销售相关数据可以被采集、存储,并且正在以前所未有的速度增长。大数据实时分析推动学术界和业界不断深入研究与探讨更有效的分析工具与方法。针对大数据的数据结构及人工智能分析系统受到越来越多研究者的关注,其中人工智能延伸出来的机器学习理论,是从样本中寻找规律对未来样本或无法观测的数据进行预测输出的一种理论方法,其将非结构化数据或半结构化数据变换成结构化数据,并进行建模分析,由此成为当前研究热点。
现有的工业供应链销售系统中的成交预测方法大都是通过定性的方法进行销售预测,这些方法大都理论性强、可操作性弱,预测结果往往达不到客户与企业的心理预期。以机电产品销售系统为例,其销售数据往往存在数据量大、特征值较多、数据不整齐等特征,无法明确哪些特征值对预测结果有较大参考价值。对此,传统方法采用定性的销售预测分析,不仅对人力财力物力消耗大、要求高,而且难以将市场、不同用户群体等因素全面考虑进去,从而导致预测结果误差较大。
因此,本文提出了一种基于高斯混合模型(GMM)的工业供应链销售预测方法。通过处理销售系统中历史业务数据,分析客户消费习惯和消费能力,在此基础上,用GMM对销售数据集进行预测训练,评估不同特征值和聚类簇数下的模型性能,生成较为成熟的模型,最终实现销售预测。
1 相关工作
文献[1]指出销售预测是企业供应链管理的关键环节,通过销售预测,企业可以制定科学合理的原材料采购计划、生产计划、人员配备计划、库存计划及营销计划。因此,销售预测决策支持系统对企业的经营决策具有重要的研究意义。销售数据是一种动态的、非线性的、不规则的时间序列数据,受季节气候、突发事件、经销商的销售能力、下级经销商的数量等各种因素的影响。在早期,销售预测都是销售人员基于产品市场以及销售经验人为判别,这种方法人工成本较高且领域可移植性较差。后来,随着大数据和数据处理技术急剧发展,越来越多的国内外学者对各行各业销售预测方法展开了更多深入研究。
其中应用较为广泛的方法主要有神经网络预测法、聚类预测法等。文献[2-4]提出了基于神经网络的销售预测模型,为企业制定销售策略提供了依据。文献[5-6]对基于神经网络的销售预测方法进行改进。其中:文献[5]基于遗传算法对BP神经网络优化,并用某超市一段时间的真实销售数据进行实验,结果表明该方法可较好地解决BP神经网络易陷入局部最优的缺陷及预测结果精度较低的问题,一定限度上提高了销售预测的准确率;文献[6]提出一种自适应和声算法与遗传算法混合优化BP神经网络权值和阈值的算法,通过对机票销量的预测实验表明该算法在一定限度上解决了神经网络易陷入局部最优值与收敛速度慢的问题。
虽然国内外学者不断致力于解决神经网络的局部最优值与收敛问题,并取得了一定进展,但在面对庞大销售数据时,依旧不能高性能地完成销售预测。因此,越来越多的学者开始从聚类方法的角度对销量预测做进一步研究。文献[7]提出了一种基于销售数据的产品重分类预测模型,该模型利用K-means聚类方法,就销量特征的共性表现对产品进行聚类,在此基础上利用时间序列预测方法与隐马尔可夫预测方法,分别对产品销量进行定性与定量预测,以某电商网站的某单品类真实销售数据作为实验数据,结果表明该预测模型在一定程度上实现了对电商产品的销量预测功能。文献[8]从服装企业的管理者角度出发,提出了一种聚类分析和CAST决策树算法相结合的销售预测模型,进一步探究影响服装销售额的因素,在此基础上对销售额进行预测,通过实证分析表明该方法在一定程度上对于预测营业额是有效果的。K-means聚类算法不仅在销售预测中应用较多,在相似的推荐系统问题中也被越来越多的国内外学者研究分析。文献[9]指出推荐系统旨在分析用户的兴趣,主动为用户推荐合适的资源,常用的算法为协同过滤算法。文献[10]提出了一种基于用户项目类偏好值的聚类的电子商务推荐方法,该方法用于解决目标用户对未评分商品的兴趣程度的预测,采用开源数据集MovieLens作为实验数据,结果表明该方法较好地解决了由于用户空间增大而导致推荐系统性能下降的问题。
随着国内外学者对聚类算法的深入研究,GMM作为一种使用概率进行描述数据点分类的算法,因其严谨性开始引起学者们的关注,并逐渐被应用在文本聚类、预测问题、推荐系统等方面。文献[12]基于GMM对相似度高的音乐特征文本进行聚类,实现音乐推荐的个性化服务。文献[13]提出了一种基于GMM的文本聚类方法,实现对电商产品的品牌实体归一化。文献[14]提出了一种基于GMM的轨迹预测算法,通过大量真实轨迹数据集的实验,结果表明,与相同参数设置下的传统算法相比,该算法的预测准确性和时效性显著增强。文献[15]则面向稀疏数据构建基于GMM的位置推荐框架,通过GMM预测用户在不同地区出现的概率,进而实现位置推荐,用真实的数据集进行实验,结果表明该方法能有效地提高稀疏数据中位置推荐的准确度。文献[16]基于GMM的方法对社交网络中的用户兴趣进行预测,并用真实的实验数据集进行实验验证,结果表明GMM具有良好的预测精度。文献[17]基于GMM对传统推荐系统使用的协同过滤算法进行了改进,并用公开数据集MovieLens对算法进行验证,结果表明该算法有更强的预测准确率。文献[18]提出一种基于GMM的知识推荐系统以预测用户对知识项的评分,进而实现对用户个性化知识推荐,用开源数据集fisheriris和MovieLens进行实验,结果表明该方法的预测准确率较高。
目前将GMM应用于销售价格预测的研究较少,但很多相关研究已表明GMM在处理预测问题方面具有良好的性能,因此针对数据量大、数据属性值较为复杂且包含较大信息量的机电产品销售数据,本文选择GMM作为处理方法,并采用人工神经网络和卷积神经网络作为对比。
2 方法设计
因其较大的置信区间和数值化的概率值预测结果,高斯分布常被应用于预测问题中。本文的实验数据较为复杂,特征数较多且数据分布不服从单一高斯分布,需使用多个单高斯模型的混合。GMM理论上可以拟合任意分布的样本,适用于本文的实验数据。基于GMM的用户模型构建过程包括4个步骤。
2.1 用户数据获取与处理
本文以加拿大某机电产品销售公司的真实销售数据作为数据源,经过脱敏处理后保留了418 282条原数据作为实验的标准数据集。
2.1.1数据分析
本文的原始数据集中包含的数据特征有id(交易记录编号)、RFQ(企业与顾客协议记录的编号)、ACCT(顾客编号)、Coverage、SKU、SKU_Category、EB_Flag、RFQ_TYPE(企业与顾客所协议的产品类型)、List_Price(产品的标价)、RFQ_Price(企业与顾客所协议的产品价格)、RFQ_Qty(企业与顾客所协议的产品数量)、Order_Qty(顾客最终订购产品的数量)。本文先计算出数据集各特征的均值、最大值、最小值、中位数等,了解数据不同特征的数值分布情况。然后计算数据各个特征间的相关性,比较特征的重要程度,为后续工作提供依据。
2.1.2数据清洗
数据清洗规则主要包括填充缺省值、平滑噪声数据和识别离群点。缺省值、噪声数据和离群点普遍存在于真实数据集中,销售系统故障、数据记录失误、数据库数据更新异常等多种原因都会产生这些异常数据。因此,首先需要通过对数据的可视化查看是否存在噪声数据,然后进一步检查所获数据中是否存在缺省值或离群点。
2.1.3数据转化
经过以上工作,本文对数据进行归一化处理,即将数据处理为0~1的浮点型数据,表示该特征在所有特征中所占的权重比率。具体转化过程如下:数据文件中包含的id用于标记每条记录,可作标签处理为从1之后逐步递增的顺序自然数;RFQ、ACCT、coverage、SKU、sku_category、EB_flag、RFQ_TYPE 可处理为在该特征的所有记录中的频率;list_price、rfq_price、rfq_qty、order_qty可按照公式(x-xmin)/(xmax-xmin)做归一化处理。
2.1.4数据集成
基于以上对数据集的分析处理,本文为防止过拟合,在实验过程中采用交叉验证以形成所需的训练集和测试集。
2.2 用户模型构建
本文用GMM描述不同特征对交易成功的影响概率。似然函数表示为各高斯模型和权重相乘的和,如式(1)所示,本文的目的即为求出相应的参数使得似然函数达到最大值,从而实现向用户推荐成交率最高的成交价格:
(1)
式中:N(x|μk,σk)为高斯混合模型中的第k个模型(component);μk与σk为第k个的高斯模型均值与方差;πk为混合系数,即权重。πk需满足:
(2)
本文在使用该似然函数的过程中,输入为用户×(特征+是否成交)矩阵的任意一行,输出为用户隶属于各个聚类簇的概率矩阵。
2.3 用户模型训练
本文用所构建的模型对数据进行训练,进而得到似然函数中的各参数值。训练过程包括最优成分数量确定和参数估计两部分。
2.3.1最优成分数量确定
在进行参数估计问题时,需要在模型复杂度与模型对数据集描述能力之间寻求一个最佳的平衡。对GMM而言,该问题的核心就落在确定最优成分数量上。本文通过比较不同聚类簇数和特征数的组合下模型的性能指标来确定最佳聚类簇的数量,实验过程中进行十次交叉检验以防止过拟合。
2.3.2参数估计
高斯混合模型的似然函数中的参数估计过程使用的是EM算法[19]。其基本思路为:随机初始化一组参数Ф(0),根据后验概率P(Y|X;Ф(0))来更新Y的期望E(Y),然后用E(Y)代替Y求出新的模型参数Ф(1),如此迭代直到Ф趋于稳定。
首先,本文基于式(1)建立了最大似然函数:
(3)
在高斯混合模型的似然函数中,单个点的概率很小,进行连乘操作之后数据会更小,容易造成浮点数下溢,影响之后的计算,因此EM算法在进行计算时对似然函数进行了取对数操作,实现了式(3)所示的似然函数。
用EM算法确定参数包括E步(Exception)和M步(Maximization)两部分。
1) E步,即计算每个数据(即每条记录)由每个单高斯模型产生的概率。对于每个数据xi而言,它由第k个component生成的概率为:
(4)
由于式(4)中的μk和σk也是需要估计的值,所以在采用迭代法计算时,需对μk和σk赋初值,并在迭代的过程中,将上一次迭代取得的值作为计算值。
2) M步,即估计E步中的参数,进而求得最大似然函数。通过E步可以得到每个数据xi由第k个component生成的概率,接下来需具体到每个component,求解参数。由于每个component都是一个标准的高斯分布,因此很容易求得最大似然函数所对应的各参数值:
(5)
(6)
(7)
(8)
重复E步和M步,直到数值收敛,并将最终得到的参数代入到目标函数中完成模型。
2.4 用户模型预测
本文用EM算法训练的模型对测试集中的数据进行预测,检验该模型预测的准确率等性能。
3 实 验
3.1 数据预处理
本文采用的性能评估指标包括准确率、召回率和F值,采用的数据集是加拿大某机电产品销售公司的真实销售记录数据,数据特征不明确,无法直接应用于模型进行训练,需要进一步分析处理。因此,本文首先对数据本身进行分析,计算不同特征值下的均值方差等,结果如表1所示。接着在此基础上对原始数据集进行清洗,消除噪声数据。然后进一步分析数据特征,对数据各特征间相关性进行分析,结果如表2所示。最后实现对数据集的预处理。本文对表1中的结果进行分析,可知:(1) 各特征的数据类型及数值上下界差别较大,为了便于后续利用模型进行训练预测,数据预处理过程中需进行归一化处理。(2) 数据集中含有噪声数据,如Order_Qty中最小值为负数,后期数据预处理过程中需进行异常值检测及替换。(3) 结合表1、表2中的结果,部分噪声数据被可视化显示,因此后续需要对数据进一步清洗、检测和去除异常数据。(4) 数据集的数据标签为Order_Qty,分析其各项结果显示成交量为0的样本数要远大于非0的样本数,后期进行实验划分训练集和测试集时,需分别考虑成交样本和非成交样本。

表1 实验数据集分析

表2 各特征间相关性分析
本文通过决策树回归模型进行特征相关性计算,即逐个移除特征,用其余特征预测被移除的特征,通过对预测结果进行评分实现特征间相关性的计算。相关性程度大小顺序为:数值为负数的特征>数值在0到1间的特征>数值为1的特征。其中,数值在0到1间特征的相关性会随着数值靠近0而增大。
3.2 实验结果与性能评估
3.2.1高斯混合模型不同特征数和聚类数对比
本文通过准确率、召回率和F值进行方法性能评估,并通过计算比较不同聚类簇数和特征数组合下三个指标的数值进一步确定本文所要采用的数据集特征数以及聚类簇的数目。
表3为不同特征数下的三个指标的数值,通过分析发现,特征值为7时,准确率、召回率和F值三个指标的值最大,即方法性能最优。特别地,不同特征值下的三指标数值是基于聚类簇数由2到10中的最大值得到的。

表3 不同特征值下的准确率、召回率、F值
在确定数据集的特征值后,本文就不同的聚类簇数目进行实验,找到最优聚类簇数。结合如图1所示的数据结果,本文确定最优聚类簇数目为7。
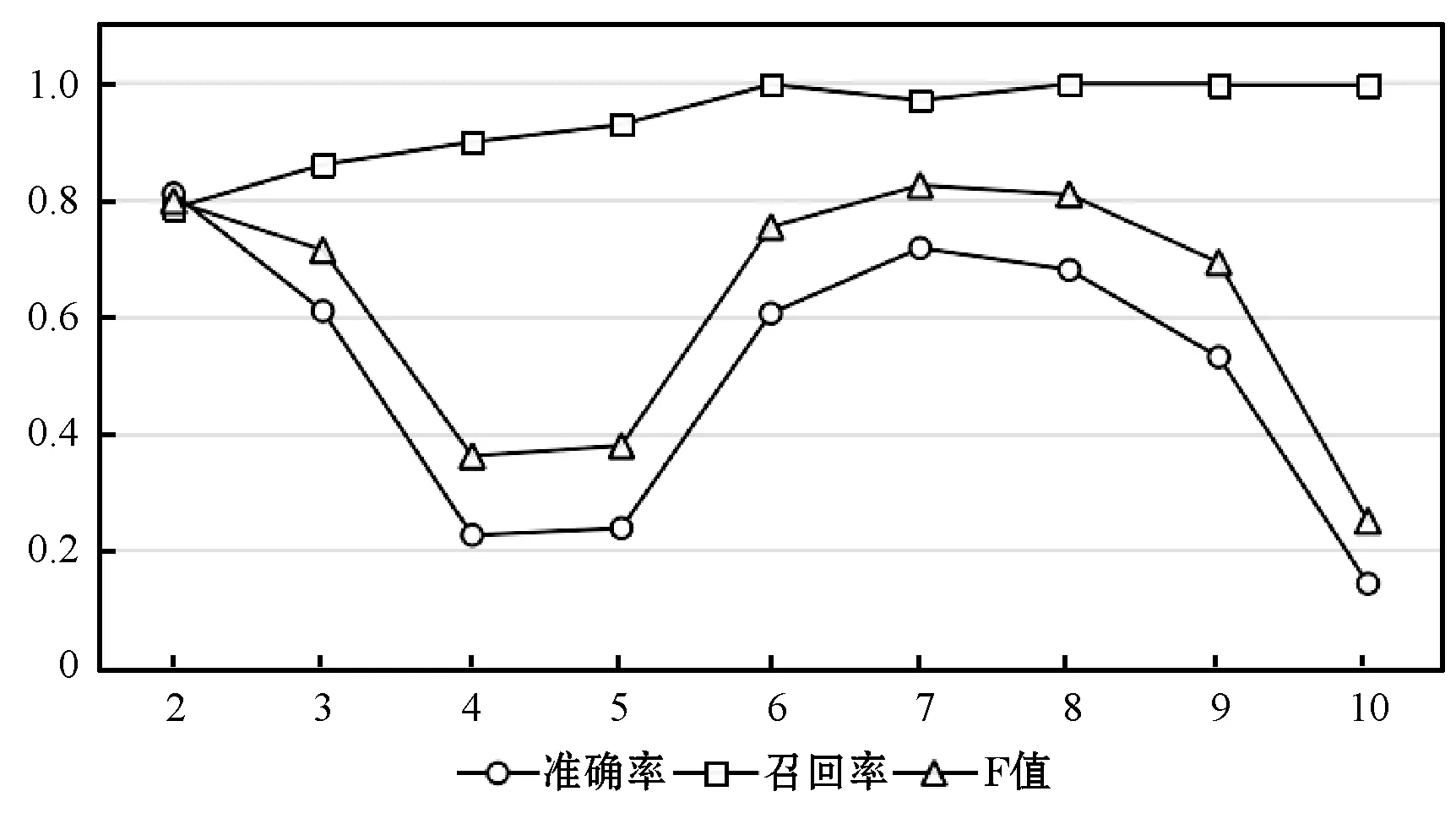
图1 不同聚类簇下的准确率、召回率、F值图
就本文数据集而言,当特征值为7、GMM的聚类簇数设置为7时,预测结果的准确率为0.717 16,召回率为0.969 72,F值为0.824 53。
3.2.2高斯混合模型与神经网络模型对比
为进一步验证高斯混合模型可有效预测销售成交情况,本文分别采用擅长处理数据信息的人工神经网络和较为先进的卷积神经网络对相同数据集进行销售预测,绘制如图2、图3所示的ROC曲线。并据此计算得到人工神经网络模型的预测结果:准确率为0.372 03,召回率为0.396 42,F值为0.383 83;卷积神经网络模型的预测结果:准确率为0.780 22,召回率为0.151 27,F值为0.253 41。F值是综合准确率和召回率的结果,用于解决二者发生矛盾的情况,F值越高,则说明模型性能越好。比较三个模型实验结果,本文发现高斯混合模型的F值高于人工神经网络模型和卷积神经网络模型,因此基于高斯混合模型的工业供应链销售预测方法能很好地预测销售成交情况。

图2 人工神经网络ROC曲线图

图3 卷积神经网络ROC曲线图
4 结 语
本文提出了一种基于高斯混合模型的工业供应链销售预测方法。首先分析工业供应链原始销售数据的特点,生成特征值相关性排序向量。接着,对高斯混合模型的聚类簇数等参数进行预测。然后,在不同聚类簇数和特征数组合的基础上进行高斯混合聚类,通过比较预测结果的准确率、召回率和F值三个指标确定可实现较好预测结果的特征值与聚类簇数目。本文将高斯混合模型与人工神经网络模型和卷积神经网络模型在同一工业供应链原始销售数据集上进行实验对比。结果表明,基于高斯混合模型的工业供应链销售预测方法能很好地预测销售成交情况。
