基于集成SVM数据流分类算法的公司微博金融事件检测方法
2021-08-12夏千姿倪丽萍倪志伟朱旭辉
夏千姿 倪丽萍 倪志伟 朱旭辉 李 想
(合肥工业大学管理学院 安徽 合肥 230009)(合肥工业大学过程优化与智能决策教育部重点实验室 安徽 合肥 230009)
0 引 言
随着近年来自媒体与社交网络不断发展,社交平台成为报道公司新闻和重要活动的主要媒介之一,且由于其信息传播速度远快于传统媒体,成为人们接收信息的重要来源。Petrovic等[1]指出,在报道与政治和商业有关的事件时,推特平台报道速度遥遥领先。由于金融市场对金融事件的突发较为敏感,因此从与特定公司相关的微博中识别公司金融事件具有重要意义,可以帮助投资者了解企业动态,明确竞争对手策略,预估可能引起的市场变动,以此作出有价值的投资决策。
从微博平台上进行金融事件检测的本质是社交平台事件检测的一个特定应用,虽然近年来社交平台事件检测研究取得了一定的进展,学者提出了多种针对社交平台特点的事件检测方法。从微博平台中检测金融事件仍存在如下三个方面的挑战。
(1) 虽然事件检测技术已经发展了很长时间,但是过去研究主要集中在热点事件或突发事件检测方法上,这些事件往往没有针对某个具体领域,因此针对特定领域的事件检测在方法和应用上仍不成熟,对于金融事件目前在定义上尚没有一个广泛认可的标准。如何通过分析与公司相关的微博信息特点,抽取有效的金融事件类型是值得进一步研究的。
(2) 社交媒体平台所报道的事件信息主要为非结构化文本信息,不能简单地利用传统定量数据算法来计算,需要先将非结构化文本进行表征。而传统的表征方法主要利用统计方法如词频、TF-IDF等进行,没有真正考虑到文本的语义信息,影响了后续分析的准确率。因此有必要从文本结构化表征的角度研究与公司相关的微博信息表征方法。
(3) 社交平台信息具有实时性和动态性,针对这一特性研究者往往通过考虑数据到达的时间顺序以解决动态性问题。然而这些方法仍存在计算成本较高及对概念漂移适应能力不强的问题。其次,社交平台中的信息更新速度快,信息量大,存在信息过载现象。因此如何优化算法提高抗噪能力是非常重要的。
针对上述挑战,本文从文本表示及文本数据流分类两个方向来对基于微博的金融事件检测方法进行研究。本文中文本表示主要是结合词向量及触发词对非结构化文本进行语义层面信息提取,以实现较少信息丢失的短文本结构化表示;数据流分类主要是提出一种基于集成SVM的数据流分类算法,该算法能对微博信息中的金融事件类型进行动态分类,且能有效检测概念漂移。
1 方法概述
本文所考虑的事件检测方法主要利用数据驱动的监督分类算法实现。其基本原理为:首先确定已标注的训练语料,其次利用特征工程对训练语料进行表示,最后利用监督分类算法进行训练并对金融事件类型进行预测识别。具体分为金融事件类型定义、文本预处理与金融事件检测3个步骤。
1.1 金融事件类型定义
对于金融事件类型的定义,针对不同的研究角度,已有学者给出了不同的定义,如表1所示。Hogenboom等[2]主要研究从异构新闻中提取金融事件,定义了涉及十种不同相关公告涉及的事件主体(如关于首席执行官的公告)的金融事件;Han等[3]则从商业事件的角度,参考了ACE[4]事件语料库的构建,针对中文在线新闻的特点,为商业行为定义了8种事件类型和16种事件子类型;Zhang等[5]考虑从在线社交媒体数据中提取公司行为事件信息,定义了六种事件类别;Shi等[6]利用金融时间序列数据进行金融事件识别,侧重于识别四种类型的股票事件。本文在综合上述文献和公司微博中报道的与金融相关的主要事件特点基础上,拟将公司金融事件类型定义为七类。

表1 金融事件类型相关研究
1.2 文本表示方法
文本预处理是信息检索、文本挖掘、自然语言处理等研究的基础,目的是将非结构化原始文本转换为可由计算机处理的数据形式[7],在文本挖掘中起着关键作用,并且极大地影响了最终的实验效果[8]。传统的文本挖掘方案通过利用BT、TF、TF-IDF来表示单词的权重并建立文档项矩阵[9]。Wu等[10]指出模式匹配是表示推特文本的最佳方式,通过词频获得单词权重,再利用NLTK计算相似度,并执行特征处理。但由于公司微博中的信息通常为短文本单词数量有限,且金融文本中专业术语多样化,导致词频信息无法有效使用[11]。Shi等[6]则先提取文本主题句,然后利用哈尔滨工业大学社会计算与信息检索研究中心开发的触发词提取算法,提取12个与事件类型相关的文本特征来实现特征处理。该方法更适用于具有严谨结构和语法的长文本,且需要利用较多的领域知识,通过手工构建金融领域的事件标注语料库,不适用于公司微博金融事件检测中。
本文考虑到微博中所发布的信息量大、短句多、具有随机性和口语化且非严格语法等特征,使用NLPIR工具对社交媒体数据流短文本进行词性标注,从中提取动词,通过构造的噪声词典消除噪声动词,并通过构造扩充触发词典来挖掘触发金融事件的动词,最终对整篇文章进行加权向量化表示以转化为计算机可识别的结构化数据形式。
1.3 金融事件检测方法
关于从文本中检测事件,主要是指从文本中检测出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与者等[12]。事件抽取任务最基础的部分包括识别事件触发词及事件类型,抽取事件元素同时判断其角色,然后抽出描述事件的词组或句子。事件抽取方法主要有流水线方法和联合抽取方法,本文的方法属于前者,这种流水线方法一般将事件抽取任务转化为多阶段的分类问题:事件触发分类器、元素分类器、元素角色分类器、属性分类器和可报告性分类器;后者主要包括多模型联合推理、利用结构化预测(概率图模型、马尔可夫逻辑网络)的联合建模,以及近年来发展的深度学习方法[13-15]。
在金融事件检测中,大多数的研究关注于从网络新闻或公司年报中检测金融事件。例如,Jacobs等[16]基于英文新闻提出了一种有监督的分类方法来检测公司金融事件。Hájek[17]从美国公司的年报中提取情绪与词袋信息,然后使用多层感知神经网络对可能引起异常股票收益的公司行为进行分类。Arendarenko等[18]提出了一种基于本体(约200条手工制作的语法规则)的商业事件信息提取框架。Daniel等[19]研究了推特平台上事件的影响性,然而其重点不在于检测事件,而是通过分析推特的情绪来获取事件对市场的影响。在金融事件分类检测方法上,常用的有监督分类检测方法有支持向量机[6](SVM)、朴素贝叶斯[3,20-21]和基于模型的方案[3,10]等。其中SVM表现出特别突出的性能[22],是金融领域最广泛应用的数据挖掘技术[7]。而集成学习在提高学习系统泛化能力方面具有显着优势,且已被证明是提高预测准确性和将复杂且困难的学习问题分解为更易解决子问题的有效方法[23]。Wang等[24]使用集成SVM进行自动模糊分类,通过与单个SVM分类器及其他分类方法进行比较,实验表明所提出的集成SVM分类器性能优越。Shan等[25]提出了一种基于混合标记策略的漂移数据流在线主动学习集成的新框架,包括集成分类器和非固定标记算法,动态对分类器和决策阈值调整,也表现出较好的实验结果。但集成学习的缺点是构造方案复杂,需要大量标记数据,以及具有高时间复杂度。本文考虑使用集成学习来解决数据流问题,为解决构造的复杂性问题,结合社交平台所带来的动态数据环境伴随瞬时数据流及概念漂移等特征,提出一种基于滑动时间窗口模型的集成SVM分类算法,大大减少训练数据,形成更易构建的集成算法。
综上,本文考虑到微博数据的非结构化、低维、数据量大及更新迅速等特征,提出一种词嵌入和触发词典的短文本表示方案,以准确掌握数据特征;并提出一种DSESVM算法,由多个SVM基分类器组成的集成分类模型以提升算法分类效果;结合短文本表示方案与DSESVM算法,形成对公司金融事件进行检测的框架。本文框架利用滑动窗口模型,检测概念漂移。
2 公司金融事件检测模型
2.1 事件检测框架
本文提出了一个事件检测框架,可用于检测来自微博的潜在公司金融事件。该框架分为公司金融事件类型预定义、触发词典构造、文档向量化和事件类型分类检测几个部分,如图1所示。

图1 事件检测框架
本文框架的具体步骤如下:
步骤1定义公司金融事件类型。
步骤2根据触发词典获取事件中的触发词。触发词是最清楚地表达事件发生的关键词,通常是动词,本文使用监督学习来更好地识别事件触发词。根据七类事件类型,邀请专家将10%的微博文本标记为事件检测的种子事件。为确保标注质量和一致性,对该数据进行比较和讨论,最终输出统一的标注结果。其余的原始数据被分成三部分,由专家分别进行标记。然后,对已标记的种子微博文本进行分词及词性标注,抽取其中动词文本。其次,利用词频对提取的动词进行排序,根据专家给定阈值提取触发词及噪声词。这里的噪声词是指某些动词频繁出现在种子微博中,但对公司的金融事件行为没有触发意义。最后,通过词嵌入算法扩充原始触发词构造成为触发词典,噪声词构成噪声词典。
步骤3由噪声词典对文档去噪,并由触发词典进行加权向量化表示。
步骤4利用基于DSESVM的数据流分类算法识别微博文本的潜在事件类型。
为了解释事件检测的流程步骤,给出示例如图2所示。
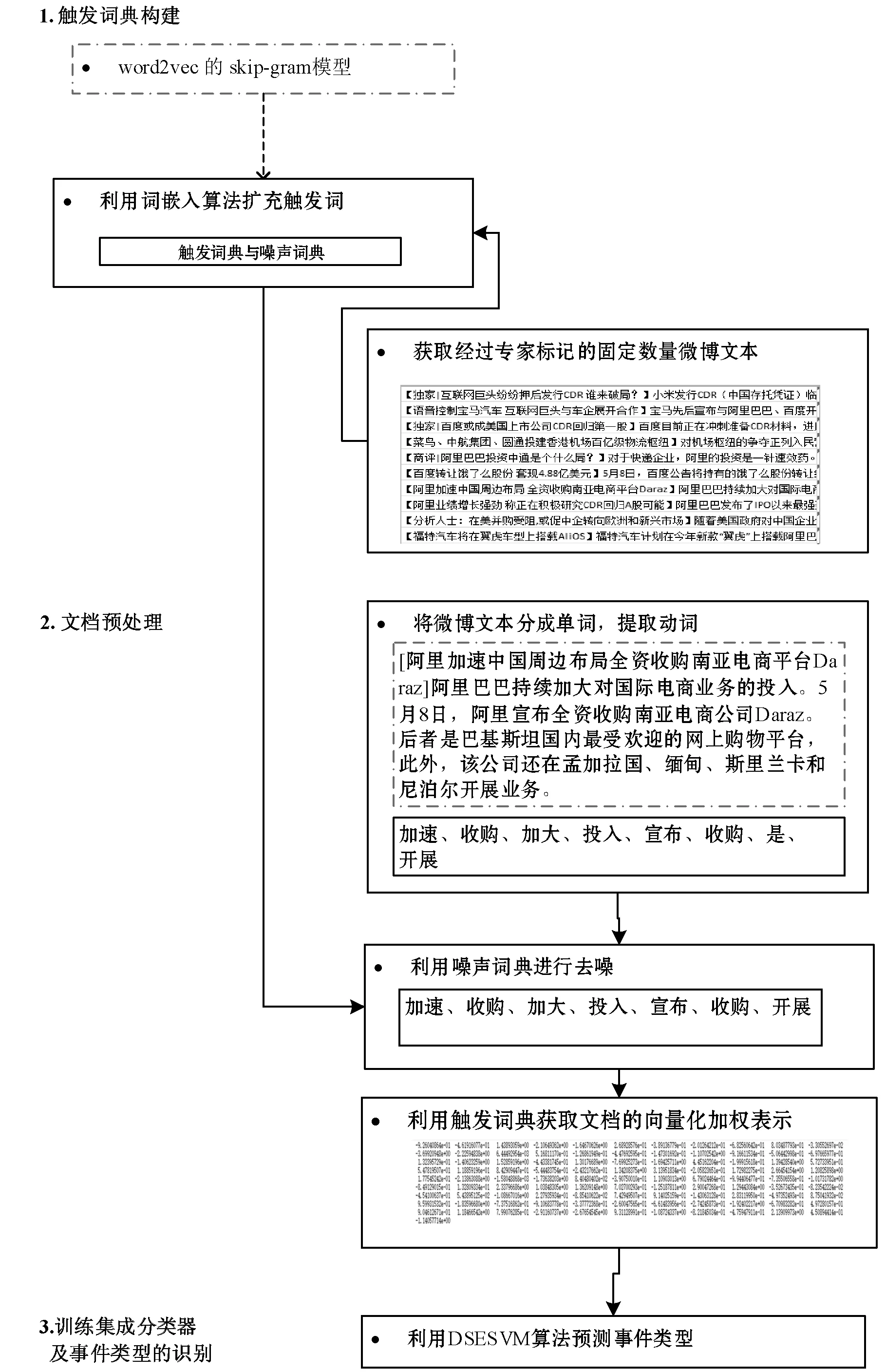
图2 公司金融事件检测案例
对于图2中文档预处理中的文档,首先提取文档中的动词,得到“加速、收购、加大、投入、宣布、收购、是、开展”;然后根据噪声词表进行去噪处理,明确噪声词“是”,得到去噪后的触发词“加速、收购、加大、投入、宣布、收购、开展”;其次利用词嵌入算法进行向量化表征,并根据扩充后的触发词典进行加权处理,得到对文档的向量化表征;最后利用DSESVM算法对文档进行预测,得出事件类别。该事件的正确类别应为融资并购。
2.2 公司金融事件分类
本文综合现有文献及公司微博中信息的特点,将公司金融事件类型定义为七类,具体事件类型及描述如表2所示。
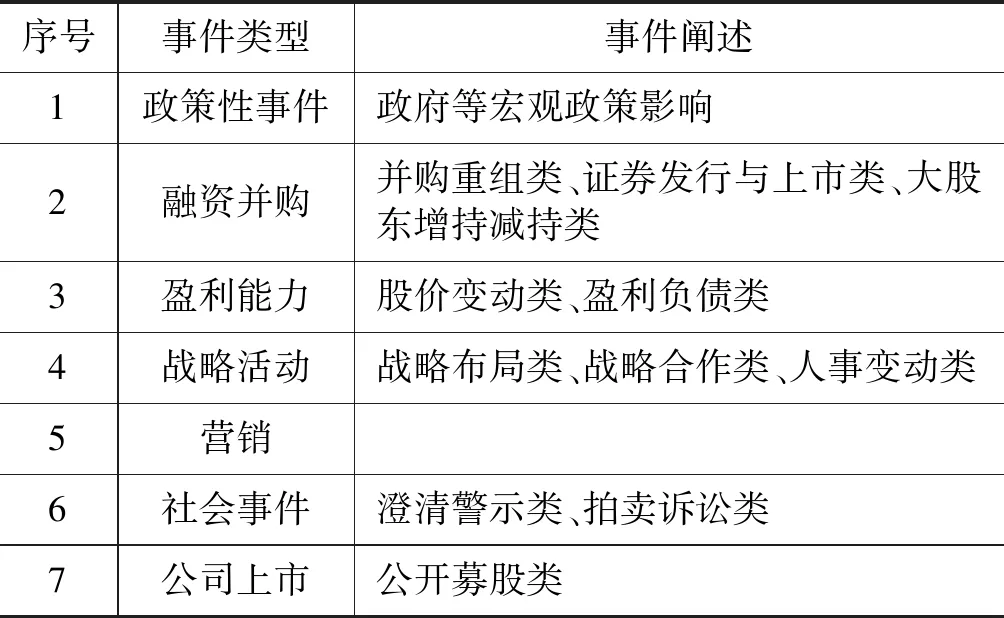
表2 公司金融事件类型
2.3 触发词典构建
触发词是事件检测中最重要的元素,代表着事件类型。本文认为扩展触发词具有重要意义,原因在于:首先,同一个事件可以由不同的触发词表示,并且这些触发词通常具有相似的含义;其次,种子语料库在整个文件中占比较小;最后,在不同的时间阶段,同一个单词在微博文本中的语义可能不同。本文中,Word2vec的Skip-Gram模型用于对触发词基于语义的向量化表示,并可据其计算得到同义词以扩展为触发词典。Word2vec算法是基于类似情境的单词具有相似含义的假设,通过神经网络模型获得单词的低维实数向量表示,将离散词映射到N维真实空间,以表达丰富的语义信息,解决词袋模型的向量稀疏性问题,挖掘词语间的语义关联性。Word2vec可在语义上表达单词映射至高维空间,因此可使用单词距离来衡量词义的相似性。本文利用Google提供的开源词向量化工具Word2vec来训练基于Skip-gram模型的单词向量,使用余弦相似度计算单词间的语义差异。若单词间语义差距小于阈值,意味着语义相似度较高,有较大可能进行触发词典扩展。
2.4 文档向量化
文档的向量化表示是数据处理的第一步,常用方法包括TF-IDF、BOW等。本文采用基于触发词的文档表征方案,在提取文档特征时,仅考虑潜在触发词,消除大量对文档分类无意义常用单词的影响。并根据触发词典,对文档特征进行加权以增加触发词在文档表示中的影响力。
假设B是时间窗口[1,T]微博文本中的数据流:
B={B1,B2,…,Bi,…,BT}
(1)
每个时间窗口Bi中的数据流由n个文本组成:
Bi={Pi1,Pi2,…,Pij,…,Pin}
(2)
对每篇文档Pij提取动词:
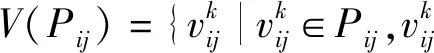
(3)
利用噪声词典N去噪,以获得降噪后的动词:
(4)
利用Word2vec获得文档Pij的一组单词向量:
(5)
利用触发词典E加权,以获得每篇文档向量化表示:
(6)
2.5 DSESVM算法
本文提出的集成SVM的数据流挖掘算法(DSESVM算法)是由多个SVM基分类器组成的集成分类器。其中,数据流检测框架基于CDSMM算法[21];基分类器权重通过计算当前数据块的分类精度得出;并通过假设检验检测概念漂移,动态调整基分类器以适应概念变化;利用错误分类与被替换基分类器训练集重新构建新训练集,以训练得到新基分类器,对较低准确度的基分类器予以替换,以提升整体分类精度。该算法可有效增强概念漂移实例对新分类器训练的影响,使算法能够快速检测概念漂移并适应新实例。DSESVM算法中符号定义如表3所示。

表3 DSESVM算法符号定义
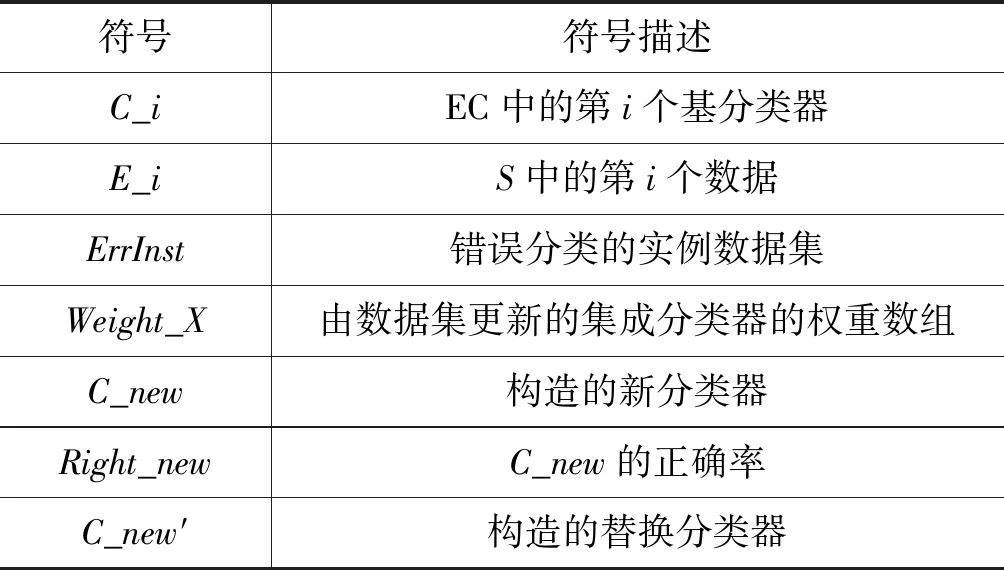
续表3
算法流程如下:
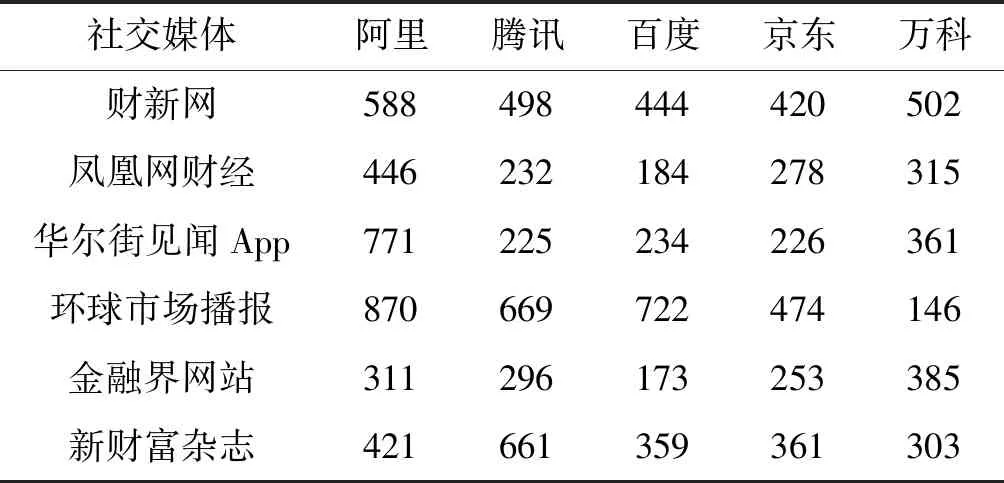
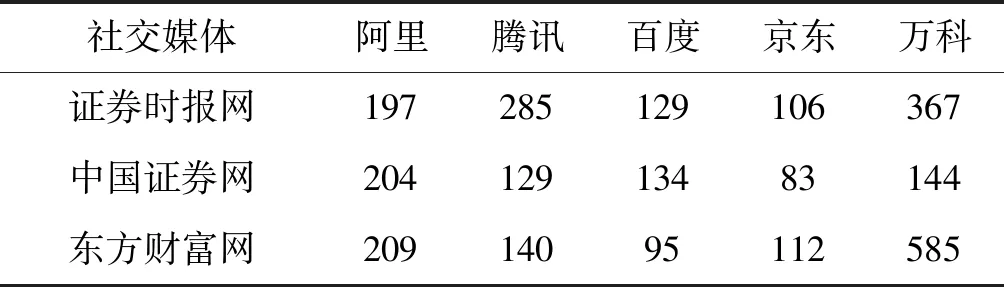
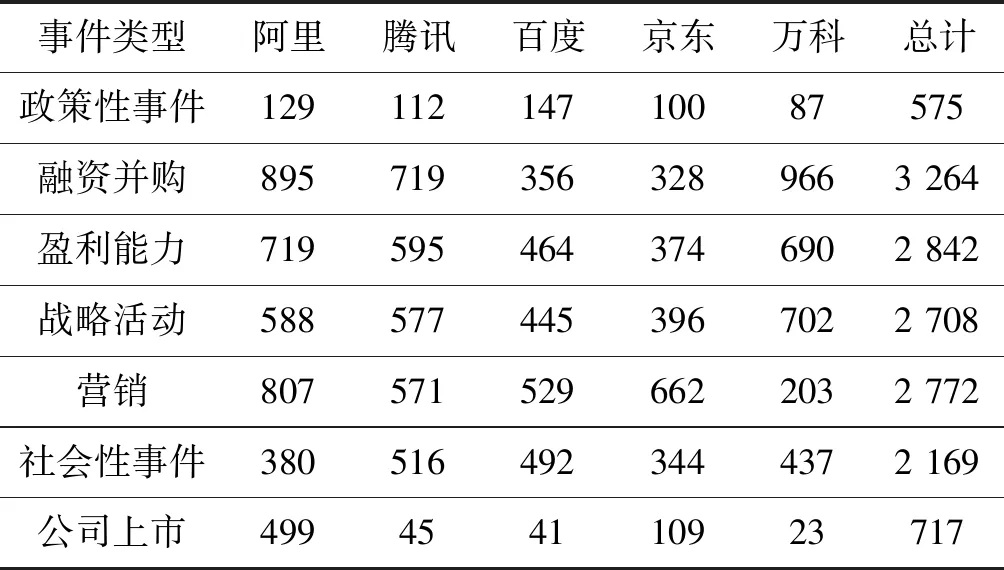
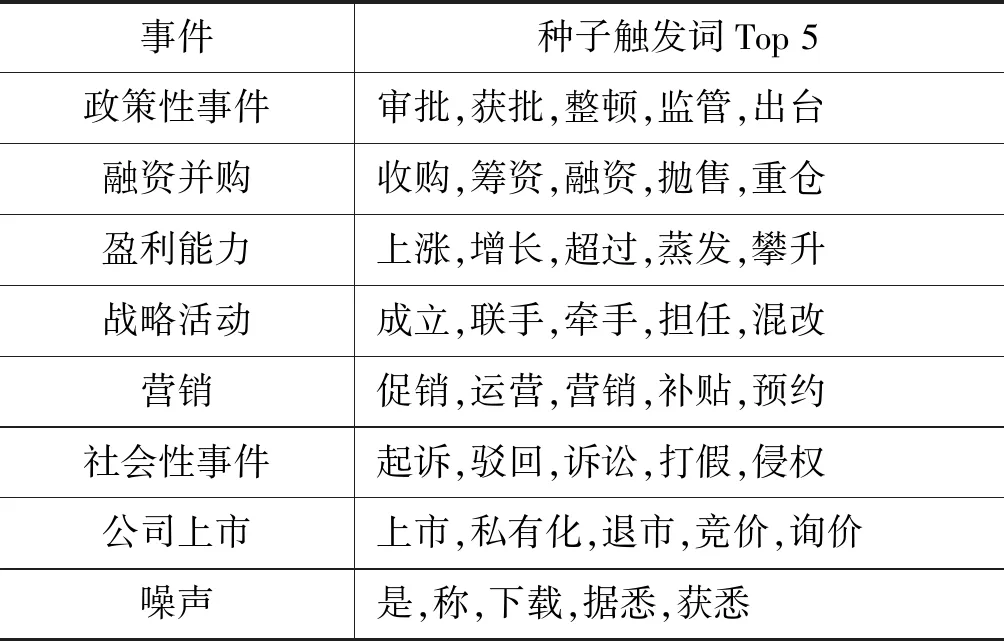
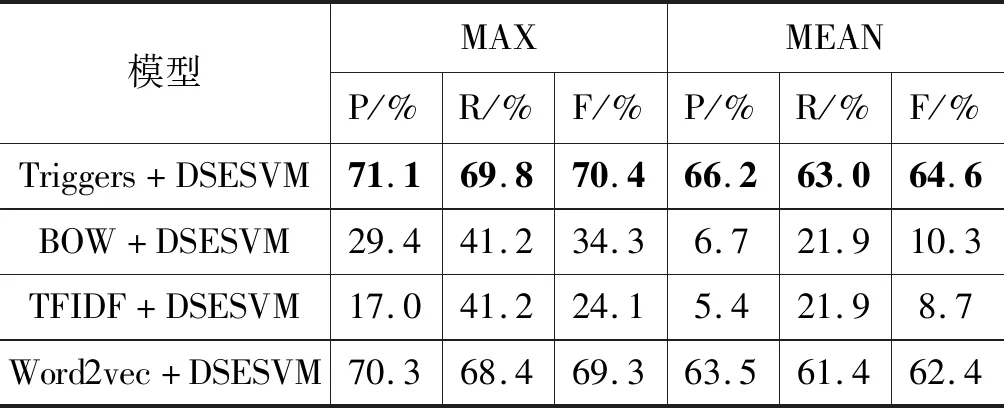
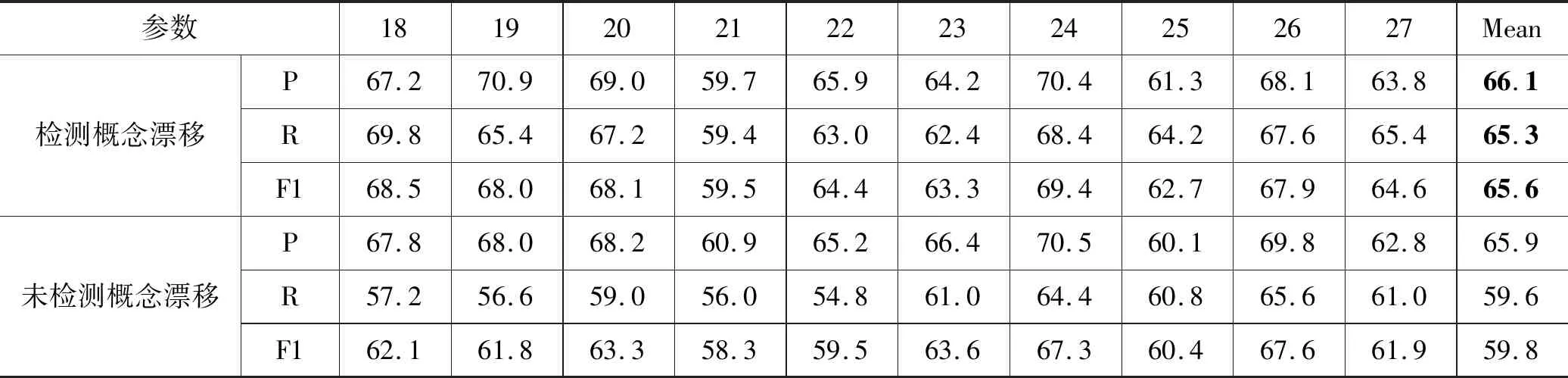
步骤1构造集成分类器EC:当S中的实例数达到d时,如果num 步骤2噪声过滤:用EC对S中的每个实例进行分类,如果被EC错误分类,则将其添加到数据集ErrInst中。 步骤3权重更新:用S更新EC中各基分类器的权重,表示为Weight_S。 步骤4概念漂移检测:计算EC上对数据块S的分类错误率,并使用该值检测概念漂移。 步骤5分类器调整与更新:一旦检测到漂移并且集成分类器中基分类器的数量达到K,则使用错误分类缓冲器ErrInst构造新的分类器C_new,分类正确率为其权重。并利用ErrInst更新EC权重,记为Weight_E。计算权重数组Weight_S和Weight_E的均值,记为Weight_ave,替换EC的权重。如果新分类器C_new权重大于Weight_ave中的最小权重,则用ErrInst中的实例与Weight_ave中的最小权重相对应的基分类器C_k训练集来组成训练数据,训练得到替换分类器C_new′及其权重Right_new。利用其替换基分类器C_k和权重以获得更新的EC。 DSESVM算法伪代码如算法1所示。 算法1DSESVM算法 输入:集成分类器EC=Null,数据流DS,集成分类器的容量K,训练集的大小d。 输出:已训练的集成分类器EC。 开始 1.While(新数据到达){ 2.读取d个数据形成当前数据块S; 3.If(num 4.C_num=getNewClassifier(S); 5.EC=AddBaseClassifier(EC,C_num); 6. //利用S训练新分类器C_num,并 //将其添加到EC中 7.num++; 8.Else 9.For(E_j∈S) 10.If(EventType(E_j)≠getpredict(EC,E_j)); //E_j被EC错分类 11.ErrInst=AddInstance(ErrInst,E_j); //将E_j加入ErrInst 12.End if 13.End for 14.Weight_S=UpdateWeight(EC,S); 15.err=getErrorRate(EC,S); //利用S更新EC权重,并计算其错误率 17.If(U>μα&&num==K) //概念漂移检测 18.C_new=getNewClassifier(ErrInst); //利用ErrInst训练得到新基分类器 19.Right_new=getAccuracy(C_new,S); //计算C_new的正确率 20.Weight_Err=UpdateWeight(EC,ErrInst); //更新EC权重 21.Weight_Ave=getMean(Weight_S,Weight_Err) //u利用Weight_S与Weight_Err计算平均权重数组 22.If(Right_new>min(Weight_Ave)) 23.C_k=getBaseClassifier(EC,min(Weight_Ave)); //找到Weight_Ave中所对应最小权重的基分类器C_k 24.C_new′=getNewClassifier(ErrInst+ getTrainData(C_k)); //利用ErrInst与C_k训练构成替换基分类器C_new′ 25.EC=UpdateBaseClassifier(EC,C_k,C_new′); //更新EC 26.End if 27.End if 28.End if 29.End while 下面详细解释数据流分类算法的一些重要部分: (1) 基分类器的选择。本文面向公司微博进行关于金融事件的分类,SVM是金融领域中使用最广泛的数据挖掘技术,实验已证明其具有较好的预测能力[22]。因此,选择SVM作为基分类器。 (2) 概念漂移检测。以分类错误率作为度量指标,利用假设检验检测数据流中的概念漂移[21]。 对当前数据块上的分类错误率进行假设检验,μ_0为常数,初始化为前五个数据块的分类错误率均值。给定显著置信性水平α=95%,如果式(7)成立,则表明错误率发生较大变化,且发生了概念漂移,反之,则认为概念分布是稳定的。 (7) (3) 替换基分类器选择规则。选定当前数据块和错误分类实例中分类效果最差的基分类器为被替换的基分类器。通过更新当前数据块和错误分类实例的权重数组,计算平均权重数组,选择对应于最小权重的基分类器作为分类效果最差的基分类器。 (4) 新分类器的训练原理。该算法应用于数据流中,各基分类器训练集无重复。当选择替换的分类器时,新分类器将由错误分类的实例与被替换的分类器训练集共同训练得到。 (5) 集成分类器EC分类预测策略。集成分类器EC采用加权投票机制进行分类预测。对未知实例进行分类时,具有最多加权投票的类别为未知实例的预测类别。 本次实验选取微博平台关注度超过一百万的新闻媒体博主发布的关于中国五家知名上市公司的相关微博信息,如表4所示。数据从2012年1月至2018年7月,总数为20 000条,通过删除重复和无意义数据,最终获得15 000条实验数据,具体5家公司相关的微博数据量分布如表5所示。微博格式包括标题、发布人、发布时间、内容及由三位专家给定的标签,最终公司金融事件的分布如表6所示。 表4 微博新闻媒体博主详表 表5 微博的数据量表 续表5 表6 公司金融事件类型分布表 本文用于评估事件检测性能的评估指标为精度(P)、召回值(R)和F1值(F1),其中:P度量所有提取事件中正例的比例;R度量在所有正例中预测正确的正例比例;F1是精确率和召回率的调和平均值,相当于精确率和召回率的综合评价指标。相关的计算公式如下: (8) (9) (10) 本文将公司金融事件分为七类,对于每类事件,将随机选取的200条数据标记为种子微博,从其中提取动词,结合词频排序与领域知识,获取每个类的关键特征触发词与噪声。最终,得到315个触发词与7个事件类型的52个噪声词,如表7所示。 表7 种子触发词表 Word2vec算法用于获取种子触发词的同义词。若扩展较多,会导致扩展词汇超出原始单词同义词范畴;若扩展范围较小,则会忽略某些同义词。因此,在本文中选择与触发词的相似度在前十位的单词,以将触发词扩展为触发词典。最终,七类事件获得38 256个触发词,如表8所示。 表8 公司金融微博触发词表 为了评估文档向量化结果,使用相同的分类算法DSESVM来显示不同表示方法下的实验结果差异。通过将BOW、TF-IDF、Word2dvec和Triggers分别与DSESVM相结合,形成四种实验方案。本文根据时间顺序将15 000个实验数据分成每个时间窗口500条,并在总数为30的时间窗口的数据流下进行预测实验。分类模型将当前时间窗口的数据视为测试集,将之前时间窗口的数据视为训练集。即文档中的动词首先分别由TF-IDF、BOW、Word2vec和触发词典分别进行文档表示,然后利用DSESVM算法在第10到第30个时间窗口分别进行分类预测,其中DSESVM算法中基分类器个数设为9。 实验结果如表9所示,“MAX”表示最佳实验结果,“MEAN”表示实验结果平均值。在第10到30个时间窗口中,可以看出基于相同分类方法DSESVM,触发词典的文档表示明显优于其他三种表示方案,精度为66.2%,召回率为63.0%,F1值为64.6%。BOW+DSESVM、TFIDF+DSESVM、Word2vec+DSESVM仅获得10.3%、8.7%、62.4%的F1值。通过对实验结果的分析,可以得出与BOW、TF-IDF和Word2vec相比,基于触发词典的文档表示能获得更好的语义表征,有助于模型获得更好的结果。 表9 文档向量化性能比较表 为了进一步说明DSESVM算法的学习效果,通过触发词典对文档进行向量化表征,并利用Bagging、Random Forest、AdaBoost[26]三种常用的集成分类算法对表示结果进行分类比较。当模型训练及分类结束后,获得当前时间窗口的预测结果。表10为四种分类模型的各时间窗口内最佳与平均的实验结果。图3详细展示了四种分类算法与本文提出的触发词表示方法结合下的分类准确率。本文算法精度为66.2%,召回率为63.0%,F1值为64.6%。与其他三种分类预测算法相比,最优F1值增加了4.1~5百分点,平均F1值增加了5.6~7.2百分点。与AdaBoost、Bagging和Random Forest相比,该算法使用较少的训练数据并获得了更好的实验结果。 表10 公司金融事件检测算法性能比较表 (a) 精度 为了进一步说明考虑动态数据流内概念漂移检测的必要性,本文进行概念漂移检测对比实验。如图4所示,本文所提模型在时间窗口10、11、12、13、15、16、17、28、29和30中检测到概念漂移。该模型使用概念漂移检测机制调整更新基分类器,以确保模型能够适应概念漂移后的数据特征,从而确保模型对未来数据检测性能的稳定性。例如,当模型从时间窗口10到17检测到概念漂移时,调整更新模型中的分类器,在第18个窗口中的F1值明显高于第17个窗口中的F1值,并在第19至27窗口中获得更稳定的实验结果。 图4 Triggers-DSESVM的实验结果 为了显示概念漂移检测对实验结果的影响,进行检测概念漂移和未检测概念漂移的进一步对比实验。如表11所示,概念漂移检测的实验结果平均F1值增加了5.8百分点,明显优于未概念漂移检测的结果。综上,概念漂移检测对实验结果具有显著影响,进一步证实在动态数据内进行概念漂移检测的必要性。 表11 概念漂移检测对比结果 % 模型Triggers-DSESVM的部分参数参考李燕等[21]的参数设置。如数据块尺寸d设置为500,集成分类器的基分类器个数K设置为9,错误分类缓冲实例的阈值e设置为100。 3.6.1Word2vec维度选择 Word2vec的维度选择对模型的复杂性和有效性有一定的影响。若维度较小,则表示的单词将无法在语义上区分;若维度较大,则模型的时间复杂度和空间复杂度急剧增加,且模型的学习效率将降低。在此基础上,进行维度选择实验,通过改变维度观察模型的性能变化。实验结果如表12所示。 表12 不同词向量维度的实验结果表 % 可以看出,当维度从50增加到200时,F1值略微增加,然后开始衰减。因此,本模型的Word2vec维度选择为200维。 3.6.2文档向量化表示的权重选择 在文档中取出动词后,将根据噪声词典和触发词典执行去噪和加权处理。该方法可以消除噪声的影响,增强文档表示中触发词的权重,并最终使文档得到更好的语义表示。若权重太小,触发词的影响将被削弱,且触发词在表示中的效果将会降低;而过大的权重设置将导致过分强调已知的触发词,忽略未知潜在触发词在文档表示中的影响。实验结果如表13所示。 表13 不同权重设置下实验结果表 % 可以看出,去除噪声的实验效果明显优于未经处理的实验效果。当权重设为1.4时,平均P与F1具有最佳实验结果。因此,该模型选择去噪,并将权重值设为1.4。 传统的金融事件检测方法存在短文本语义表示及动态分类检测效果不理想等问题;传统的文本表示方法存在高维、稀疏、语义信息丢失等;传统分类检测方法无法适用于具有概念漂移、数据量大、短句多和口语化等特征的社交媒体数据中。因此,本文提出了一种应用于微博文本的公司金融事件检测模型。为提高公司金融事件检测性能,本文首先结合Word2vec与触发词对文档进行表示,其次提出DSESVM集成分类算法来处理大量的微博文本流,以达到实时检测事件的目的,来自微博的实际数据实验结果证明了文档向量化和集成数据流分类方法的有效性。 后续研究将从以下两个方面进一步完善提出的事件检测模型:(1) 关注多标签数据分类问题,同一条微博信息可能与多种类型的金融事件有关,因此如何解决这个问题是后续研究重点;(2) 目前算法中使用固定时间窗口且数据块大小固定。由于实验中流入时间窗的数据量导致实验语料规模受限,会影响分类结果,因此将研究如何优化算法以提高算法对数据规模的自适应能力。
3 实 验
3.1 数据集与评估指标

3.2 公司金融微博触发词典构建

3.3 文档向量化表征算法评估
3.4 公司金融事件检测模型评估


3.5 概念漂移检测评估

3.6 参数分析


4 结 语
