藏文古籍数字化出版探索
2021-08-09德庆央珍
德庆央珍


摘 要 由于多种原因,以多维关联及结构化的智能知识服务体系,对民文古籍进行保护及再利用的深度加工产品较为少见。但藏文古籍丰富的藏存量、藏文信息处理技术的发展水平及良好的国内外学术交流环境等因素,使其数字化工作在向知识服务型发展(即深层次开发)方面,进行着较为超前和有益的探索。文章以明清古籍藏汉审音辞书《西番译语》为例,探讨了小众型藏文古籍在线出版应用的可能性,以期能够在更广泛层面发挥其学术应用价值,更好地服务于学术研究及古籍保护工作。
关键词 藏文古籍 数字传播 在线词典
一、 古籍数字化层次与民文古籍概述
古籍数字化最实质的目的是保护及利用。其对古籍文献的再生性保护作用、对文本深度挖掘的性能、对构建数据资源库以飨共享的知识服务平台的优势等,使其在古籍保护及传播工作方面的能力无出其右。深度加工后的古籍内容,更以跨学科的“知识图谱”形式辅助人们阅读与研究,产生二次价值,是以被称为“高效率的知识内容”。古籍根据数字化加工及开发的程度,有存储、检索、交互、知识服务型数据库构建等形式。就开发的层次,有学者概括为“表层数字化”和“深层数字化”: 前者是图像或文本的简单存储,后者则是古籍内部知识元的标注,以及在知识元间设计建立关联的原则等,是“内容和意义层面”的开发。(马创新,曲维光,陈小荷2014)104据2007年的国家普查摸底数据,全国汉文古籍藏量总数达20万种50万个版本,至2016年已数字化约10万种15万个版本。(张贺2016)而民文由于受信息技术发展水平、标准及规范缺乏统一、经济投入能力相对较弱、需求不旺盛等综合条件的制约,民文古籍的数字化工作主要是图片数据库(古籍扫描或影印)和文本数据库(全文文本录入)的建立,数字资源的开发层次较低。知识服务型数据库,即利用数字技术,应用文献学、信息学等学科的方法,将古籍所涉及的各类专门学科间的知识,以跨学科的方式进行“知识元”间的多元组合,构成结构化的、多维关联的智能知识网络体系的形式,在民文古籍数字化产品中极为少见。目前,我国民文古籍的数字化,主要由教学科研机构和图书馆完成,商业介入极少,开发层次也多在表层,但藏文古籍数字化工作,在向知识服务型发展(即深层次开发)方面,进行着较为超前和有益的探索。
二、 藏文古籍数字化出版具备良好的客观条件
(一) 文献占有量庞大为规模化的数字库建设提供了丰富的信息元
文獻的丰富程度,不仅决定着数据库的规模,更与其可进行数字加工的深度成正比。“信息元”,即数据对象越丰富,数据库可构建的多维知识体系越强大,则可提供的知识服务的能力就越强大。因此文献作为建立古籍数据库的信息基础,占有量越大,对其进行结构化、智能化知识集合的空间就越大。我国藏文古籍文献藏量仅次于汉文,据2016年的官方统计,全国藏文古籍文献约有200万函,(王海磐2017)具备建立数字资源库的良好条件。
浩如烟海的历史文献是藏文出版的不竭宝藏,古籍文献的出版更是藏文出版的一大品类和特色。由于藏文古籍的巨大藏量及其珍贵的价值含量,党和政府高度重视藏文古籍数字化保护及相关成果的出版工作,从政策、经济等各方面予以大力的支持。西藏自治区政府也不断将古籍数字化出版工作写入各项规划中,如连续两期的“五年规划”、文化产业发展规划等。具体项目方面,如自2019年起,国家将分10年,累计划拨3亿元专款为布达拉宫做贝叶经及古籍文献的保护工作,在“可预防性保护、抢救性保护修复、数字化保护、展示利用”4项工作中,数字化保护是重中之重。随着编目、录入、存储及深加工工作的展开,相关数字出版产品将陆续面世。国外,以美国的藏传佛教资源中心TBRC(Tibetan Buddhist Resource Center)为例,收藏了12万余函藏文珍本和孤本文献[1],每一页已数字化并建立了共享数据库,被称为“世界上最大的藏文数字图书馆”,每年有12万人次下载文本,并被哈佛大学图书馆收入其数据库,(苗炜2014)由此亦可见,藏文古籍数字文献在国际范围内也具有较高的关注度和需求度。
(二) 藏文信息技术处理的相对优势为藏文古籍数字化提供了技术保障
信息处理技术是每一种语言文字古籍数字化的最基本要素。在国内各少数民族文字中,藏文信息处理技术具有以下三个方面的优势: 其一,藏文是我国少数民族文字中第一个通过国际编码(UNICODE)的语言文字,这为数字藏文内容的可流通性提供了保障;其二,藏文输入输出在WINDOWS、iOS和ANDROID等全球三大操作系统中均已得到系统级别的实现,为各类应用软件处理藏文内容奠定了基础;其三,涉及人工智能领域的一些基础技术及应用有了显著的进步,如藏语文自然语言处理研究、藏文文字及语音识别等。在藏文互联网内容检索领域,还出现了诸如“云藏”这样的搜索引擎,使得藏文大数据研究及应用成为可能,为藏文古籍数字化的深层次加工提供了技术保障。再如2016年西藏大学开发的“藏文图书期刊数据库及资源管理及检索平台”,就研发完成了集藏文文献数字化加工、管理、发布、统计、多文种全文检索等多功能为一体的数字平台管理系统。(赵越2017)
不仅如此,基于西藏大学研发平台的技术基础,西藏大学、西藏自治区藏医院等单位已从几年前开始,与技术公司合作,把其所藏存的藏医药文献进行数字化加工,做藏医药“知识图谱”,为科学研究工作提供多方位的服务。比如天文历算部分的内容,通过在计算机中输入运算规则,联合专家进行天文历法的计算,在比照测试中,它已查出某单位所制一套大型“万年历”(全套300余本,未正式出版)中的几百处错误。此类加工的最终目的是实现藏医药的深度分析,并通过海量数据的知识挖掘,推送最高效的科研文献信息。同时,基于上述工作,我国藏医藏药的基于内容级分析的基础情报基本在2020年制作完成,其意义十分重大。[2]此类对文献的数字化加工,实现了真正意义上的超越于文本的“知识服务”。
(三) 藏文古籍数字化的研究及应用具有良好的国际学术环境
藏学作为显学受到世界性的关注,在数十个国家中建有藏学研究机构,海外对藏学数字文献的搜集、对文本数字化的加工处理等工作也取得了不小的成绩,使得藏文文献研究的国际间交流具有广泛的环境基础。
综上,藏文古籍文献丰富的藏存量、藏文信息技术的发展水平及国际学术交流环境,为藏文古籍数字化的出版应用提供了良好的保障。
三、 《西番译语》的版本价值及在线辞书可开发的功能
据统计,我国古籍藏量约5000万部,其中20万种50万个版本值得全部数字化,然而由于资金及缺乏国家统一标准等原因,目前已数字化的体量不足一半,而书的老化及藏存安全问题,令古籍数字化具有较强的紧迫性。(张贺2016)由此,受客观条件所限,数字化古籍需要有优先级,而优先级的数字化加工对象应首选价值较高的古籍版本。
(一) 《西番译语》作为民汉双语注音类辞书,具有很高的版本价值
1. 权威性——明清官方语料文献。《西番译语》是明清两代朝廷编写的汉藏对照词典,为朝廷公文翻译及译员培养之需而作,由官方在语言调查的基础上,筛选出公文常用词、日常交流常用词、具有民族地区特点的特殊词等,多数为高频词,以统一的汉语单词作为源语,收集不同地区方言填注藏语单词,并用汉文标注藏语发音,是两朝官方使用的语料工具书,具有很高的权威性。
2. 典范性——钦定译语范例。古代民族语文与汉语的双语注音类辞书,以明朝洪武本《華夷译语》为典范,清代传习并完善了明朝这一审音传统,继续对各类民文及外文译语进行编写与修订。又遵乾隆谕旨,以《西番译语》为体例,勘校及编写其他译书:“如海外诸夷,并苗疆等处……照西番体例,将字音与字义,用汉文注于本字之下,缮写进呈,交馆勘校,以昭同文圣治。”[3]“既有成编,宜广为搜辑,加之核正,悉准西番书例,分门别类,汇为全书。”(任小波2009)即编写的译书以及四译馆所存各类译语,均须以《西番译语》为范例,可见其对清代官修译语版本所起的重大作用。它不仅在汉藏对译辞书编纂史上,同时也在民汉双语对译辞书编纂史上具有重要地位。
3. 独特性——从语料的角度,为多种学科提供珍贵的研究素材。明代《西番译语》各本中,收录词条最多者为942条。(聂鸿音,孙伯君2010)2,7故宫所藏清抄本《西番译语》,收词2103条。(施向东2019)3本文所用底本为国家图书馆的9种晒蓝本,清乾隆年间四译馆编写,以义聚类,分20门740个单词[也有学者提出此版本为明代刻本之误断(任小波2009)],是诸多译语中门类完善、语料最丰富的品种之一。这些内容对明清历史、两朝汉语、藏语的语言史、方言及两种语言的比较研究,双语辞书研究、都具有重要的文献价值。
2011年,国家图书馆馆藏的《西番译语》晒蓝本,入选我国第一次文化产业专项规划“文化产业振兴规划·中华字库”工程,也体现出《西番译语》在少数民族古籍文献,乃至浩繁的中国古籍文献中的重要性。因此,无论是从版本还是学术价值的角度,选择《西番译语》作为数字深加工的对象,具有充足的合理性。
(二) 《西番译语》兼具古籍与辞书的双重性质,从数字化应用层面具有极大的开发潜力
对《西番译语》的数字化,即从根本上解决了为了保护版本而“重藏轻用”的现象,同时也在检索、动态编写、音频资料补充、跨库链接等多方面发挥数字辞书支持学术研究的功能。
在古籍分类上,“译语”列“小学”之末[4]。作为语文类辞书,《西番译语》以天文、地理、时令、人物等20门划分类别,以对译加注音的形式做汉藏双语释义,单本300余页,一套合计达数千页之多,不设索引,故而查找十分不便。而辞书的数字化,是适应用户阅读方式变革的转换,可以从词条释义的单一功能,转向智能化的知识服务。
1. 检索便捷高效
高效率检索是数字文献具有的一般功能。本文所用国家图书馆版《西番译语》,是《西番译语》的“杂字”部分,体例上,每本词典的正文前,都有约200字的序言介绍该方言区的行政归属、长官吏员等重要的历史信息。对此,在线辞书可通过全文检索与原版图像结合的方式,提供模糊查询、双语双向查询等强大的检索功能。
2. 开放性能,可实现不同版本的堪比
明清《西番译语》的版本及藏存现状复杂,除国内故宫馆藏等外,异常珍贵的传本多流落于海外,如德国国家图书馆、法国国家图书馆、日本东洋文库所藏版本等,且重要传本目前尚未系统整理,(任小波2009)在线辞书的开放性能,可以允许资源所有者参与编写,扩充资源库,以此吸收愿意分享的流散本古籍的内容,包括《西番译语》中除《西番馆杂字》外的《西番馆来文》部分。在程序中预留相应接口,使愿意分享的用户在程序上自行上传,汇集尽可能多的版本,建立不同版本间的关联,实现多版本的堪比,进而为多学科研究提供丰富的原始资料。并基于计算机计算、统计等功能提供更为强大的智能知识服务。
3. 音频材料,以增添古籍的语料库素材
在线词典超越纸媒的优势之一,是可以嵌入相关的视频、音频、图像等多媒体资料。以音频为例,通过对所检索的词条、例句等进行朗读或相关声音采集的办法,帮助读者建立立体认知。《西番译语》是有汉语注音的藏汉双语词典,本文所述版本,记载了明清两代四川藏区9种藏语方言(其他版本方言种类数量略有差异)。简言之,它本身就是一套学习语音的工具书,在研究明清时期藏汉两种语言通语及方言中具有重要的价值。特别是该文献中有不少藏语是非规范书写,或者汉文注音与藏文拼写的读音完全不符,如“(冬)”被注为“查跨”;“(星)”被注为“墨治”[5],等等。学界尚不能对此释疑,只是“估计”在川西北地区可能流行三种文字使用方式: 普通藏文、训读、借用(用藏文书写另外民族的语言,也读以另外的民族语言),“这三种情况有时会交织在一起,为研究者深入理解当地的语言造成困难”(聂鸿音,孙伯君2010)2,7。故而,音频材料的应用,即将《西番译语》所涉700余词汇在当代各方言区的藏语发音分别进行采集、归类、关联,将发音与文字注音形象化地关联比对,无疑会为解开某些学术谜题提供重要研究资料,以当代语音材料为古籍补充动态对照素材,将对该文献增添跨时代的学术价值。
4. 与其他数据库的跨库链接
《西番译语》只是众多汉藏古籍辞书资料库中的一种,它与其他资源库,比如敦煌汉藏对译文献或其他相关文献,在知识层面上会有不同程度的关联。因此,与其他开放型数据库建立跨库链接,将有助于建立多维立体的知识体系。
此外,字词频统计、自动卡片生成、繁简体转换等其他辅助功能,也将支持学术研究。
综上所述,通过建立《西番译语》数据库并将其制作成在线辞书,将对古籍保护及其内容的二次利用等方面具有积极意义。
四、 《西番译语》在线辞书的文本处理原则
其一,汉字异形字、通假字、繁体字,均改为通用简体汉字。
其二,藏文拼写的问题及处理原则: 《西番译语》的编写年代是明清两代,历经几百年的语言发展,文献所载的一些藏文,其拼写或所标注发音与当代藏语或有差异,加之前文所述的非规范书写的“学术难题”等,文献中“不规范”或已无法辨析缩写规则的书写,如“”(译语: 图报,注音: 斗巴)[6]等,将保留原貌。
其三,线装书造成个别扫描本出现藏文字符的亡佚现象,在在线词典中,亡佚部分字母用“■”替代。
其四,晒蓝本底色不匀造成的汉字或藏文无法辨识的单字,均用“■”替代。
其五,因书写问题,藏文中有不少如“”“”,“”“”,“”“”“”,“”“”,“”“”难以区分的现象,此类问题,均以在前括号中列出疑似字或元音的方式标注。
五、 基于互联网的《西番译语》在线词典设计构想
(一) 目标用户
根据文献内容及规模分析预判,《西番译语》并不具备成为汉藏两个语言群体日常工具书的可能,其潜在的使用者应该集中在汉藏语言学及历史学研究群体中。尽管目前已有学界专家研究并出版了部分版本的校录及汇编书籍,作为古籍文献,原始内容的数字化呈现应该是该领域研究者们的共同期待。《西番译语》数字内容的目标用户群体的特征提示我们设计系统应该关注的几个重要原则: 内容的完备性、交互的简洁性和平台的开放性。对于特定领域的科研工作者,完备性是数字内容服务的先决条件,简洁性是人机交互环节的必然选择,而开放性则是平台内容集聚的客观要求。
(二) 用户场景
作为一个特殊历史时期有限词汇的汉藏对意对音工具书,对现代社会生活中的群体不足以产生日常应用的引力,因此数字化的《西番译语》除了电子书这种常见的形态外,可检索的电子词典在移动端的使用前景是不明朗的。学者群体在其科研工作中更多地还是会选择基于PC的在线查询模式。因此,我们确立了一种基于浏览器的互联网在线工具书系统模型进行设计及DEMO研发工作。
(三) 功能概述
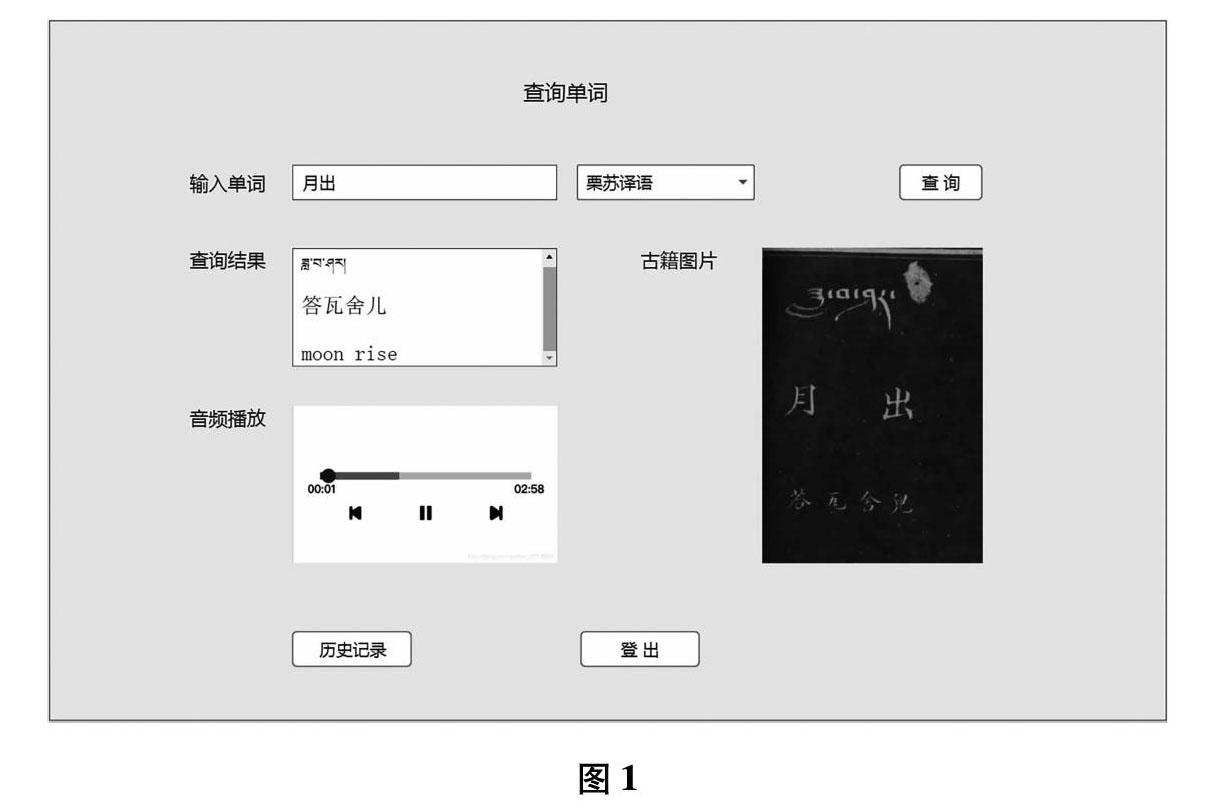
《西番译语》多方言在线词典以汉文和标准藏文作为检索关键词,用户输入查询目标词汇,选择查询目标方言,服务器端返回结果并通过浏览器进行呈现。除了这种常规的定向方言查询功能,系统还应该提供一对多的查询及反馈机制,此间的多目标可以是1至9种方言(上限9种仅仅是基于本文涉及的9种藏语方言)的任意组合。由于古籍的最大价值在于汉文转写的藏语方言语音部分,因此除了一般在线词典检索的文字结果输出外,系统还应支持输出目标词汇的古籍扫描切片和对应的方言读音输出。
《西番译语》的不同版本散落在世界各地,本文涉猎的只是国内馆藏的一部分。从工具系统的体系性和完备性角度考虑,多方言在线词典应该具备较好的开放性,即开放地吸纳留存各地的不同方言即不同历史版本内容资源,从而使这个平台不僅能够提供信息服务,更能通过UGC(用户生成内容)和互联网集聚的模式不断扩大内容维度,增加资源体量,最终为从事领域研究的群体提供专业的服务。
(四) 功能细节
1. 查找单词
单词查询是《西番译语》在线词典的核心功能,用户可以输入规范化的汉文、英文或藏文词条,并选择不同方言版本的《西番译语》典籍进行查询。系统将显示基于该典籍的方言藏文及汉文音译书写,同时提供该词条对应的典籍扫描图片及方言发音音频。
2. 新增词条
《西番译语》尚有散落传本未能归集,利用互联网的开放性进行数据扩展对《西番译语》的学术研究具有重大作用。新增词条即是满足这一需求的功能部署,用户可以在这里录入典籍新传本(不同于系统已有的传本)具体词条的汉文、藏文和汉文音注,同时上传词条对应的扫描图片及藏语方言发音音频,以期能够逐步建成《西番译语》各传本的完整数据库。
3. 历史记录
功能是各类在线词典的基本配置,用于回溯特定用户的查询轨迹并快速定位目标词条及其对应的数据内容,是词典系统提高查询效率,增加用户体验的一个常用方法。
实事求是地说,本文所列《西番译语》的上述功能,只是在线词典最基本的组成部分,要达到真正完备成熟尚有许多方面可以提升。比如在查询部分提供不同版本典籍对照展现,又比如在新增单词部分提供数据上传批量处理功能等,诸如此类的工作,需要随着用户行为、用户体验和需求反馈不断进行改进和完善。
(五) 数据加工
在线词典的数据形态包括了文字、图片和声音。文字内容部分可以借助图书出版流程中基础数据录入环节,确立一定的格式规范然后进行批量的数据库导入。扫描图片的切片及不同方言音频采集是本项目数据加工的重点,也是难点所在,尤其是音频采集部分。《西番译语》涉及740个词汇的9种发音,将产生将近8000个独立的音频素材,加之方言分布的地域差异,无疑对采集工作提出了不小的挑战。语音素材整理的重点是对每一个词的不同方言语音采集样本进行审定。审定的难点主要在于古今方言语音变化带来的挑战,当下的语音样本有可能质疑古籍汉字转写藏语方言的可靠性,如何保障采集语音样本的准确性或许还会成为一个专项研究的问题。
(六) 库表结构
为了更具针对性,本部分主要讨论在线词典数据库词典内容的库表设计,普适的用户及历史记录数据库库表设计不再进行赘述。我们注意到词典数据及其关系的两个特性: 其一是每本古籍的词条数量是固定的,即740个;其二是每本古籍中的汉文词条在不同方言版本中是一致的。基于汉文词条的一致性与唯一性前提,我们将汉文及对应标准藏文作为多方言查询的关键词进行数据组织。在数量固定和词条一致性前提下,数据库设计中通过设定ID关联不同版本的古籍词条便成为可能。
考虑到数据库查询的效率及未来《西番译语》其他版本词条数据扩展的便捷性,我们设计了两个库表结构: 第一个表结构用于建立汉文词条、标准藏文及ID的关联;第二个表结构面向9个版本的词条数据,9个版本的词条数据将分别存储在9个同一结构的不同表格中。其中的ID和第一个汉藏词条表结构ID字段一致对应。数据查询的逻辑是: 根据用户提交的汉文词条或者标准藏文词条,从第一个表结构中定位ID,再依据这个ID和目标方言信息,从第二个表结构中提取关联的古籍数据。
(七) 技术架构
实现一个常规的互联网词典查询功能,可以选择的技术路线是非常丰富的。比如,从平台部署、开发难度和运行维护成本等角度考虑,APACHE作为WEB服务器,MYSQL作为数据库,PHP作为前端开发,就可以是一个非盈利性在线信息服务常用的平台方案。然而经过认真分析功能需求复杂度、技术实现成本和实现效果,可以选择DJANGO+MYSQL+PYTHON作为《西番译语》在线词典系统的技术框架。除了成本方面的因素,主要基于以下几点考虑: 其一, MYSQL是开源数据库系统,其运行速度快、体积小、使用成本低、可移植性强以及非凡的可扩展性等诸多特性是开发在线词典小型系统的绝佳选择;其二,相对其他编程语言,PYTHON在数据处理领域具有压倒性的优势和便利性,尤其是在互联网信息挖掘与提取,诸如内容爬取和分析等方面,对《西番译语》词典数据库基于互联网内容资源的扩展将起到事半功倍的作用;其三,DJANGO 是面向PYTHON开源免费的高端WEB框架,这个框架解决WEB开发中的大部分繁琐环节,倡导快速开发、简洁实用设计的理念。
六、 结论
综上,藏文古籍自身具备的藏量、技术、学术研究环境、国家政策支持等良好客观条件,为其实现不同程度及规模的数字出版工作提供了强有力的保障。然而,规模较小、应用范围相对狭窄的古籍,无论从政府性立项的优先性排序,抑或商业性的选择,都很难进入数字化范畴。而其中不少古籍,以其内容的稀缺性或版本的珍贵性,均具有重大的开发价值,如若埋没,至为遗憾。
本文以明清古籍藏汉审音辞书《西番译语》为例,探讨了小众型藏文古籍在线出版应用的可能性,以期能够在更广泛层面发挥其学术应用价值,更好地服务于学术研究及古籍保护工作。
附 注
[1]創建人金·史密斯先生生前将该中心全部纸质文献12000函捐赠给了西南民族大学民族文献中心,后西南民族大学成立“金·史密斯藏学文献馆”,并与TBRC联合建立中国民族文献数据库及网络共享平台。
[2]根据笔者2019年对联图科技公司做的调研材料。
[3]《清实录》一三,卷三百二十四,“乾隆十三年九月上”,转引自聂鸿音、孙伯君(2010)20。
[4]钱大昕(清). 补元史艺文志, 转引自任小波(2009)128。
[5]《西番译语》(国图藏本)第七册,栗苏译语,天文门。
[6]《西番译语》(国图藏本)第八册,打箭炉译语,人事门。
参考文献
1. 马创新,曲维光,陈小荷.中文古籍数字化的开发层次和发展趋势.图书馆,2014(2).
2. 苗炜编.最漫长的博士.新知,2014(6).
3. 聂鸿音,孙伯君.《西番译语》校录及汇编.北京: 社会科学文献出版社,2010.
4. 任小波.明清《西番译语》传本寻踪.中国藏学,2009(3): 130,132.
5. 施向东.清朝本《西番译语》藏汉对音译例研究.民族语文,2019(4).
6. 王海磐.藏文文献数据中心启动藏文古籍文献数据化手机整理.光明日报,20170822.
7. 张贺.与时间赛跑,古籍数字化如何加速.人民日报,20160623.
8. 赵越.《西藏图书期刊数据库及资源管理与检索平台》获奖,西藏商报,20170610.
(民族出版社 北京 100013)
(责任编辑 刘 博)
