利用收益预测与策略梯度两阶段众包评论集成
2021-08-07马廷淮
荣 欢,马廷淮
1.南京信息工程大学 人工智能学院,南京 210044
2.南京信息工程大学 计算机与软件学院,南京 210044
随着互联网的飞速发展,越来越多的用户选择在网络上发布关于某一特定对象的评论文本,由此产生了大量的用户评论。这些评论包含了用户对特定对象所持有的观点看法,以及情感态度,集成评论文本中的关键信息有利于决策制定并锁定关键用户群体,具有重要的应用价值[1]。评论集成源于众包数据中对数据标注结果的清理。一般而言,标注者会在众包平台上对同一对象进行类别标注,不同标注者所提供的类别标签存在差异,由此需要对标注结果进行真值推测,即标签集成[2]。特别的,如图1 所示,本文将集成对象从离散的数值标签转为连续的文本内容,即通过收集关于同一对象的众包评论文本,以既定压缩率K抽取众包评论文本关键语句形成集成文本以代替原始评论,由此推测出与当前评论对象最为匹配的内容描述。此外,区别于数值型数据,评论中蕴含了发布者所持有的情感态度,故本文在评论集成过程中重点关注情感强度较为突出的语句,从而更明显反映出用户在评论时的情感状态。
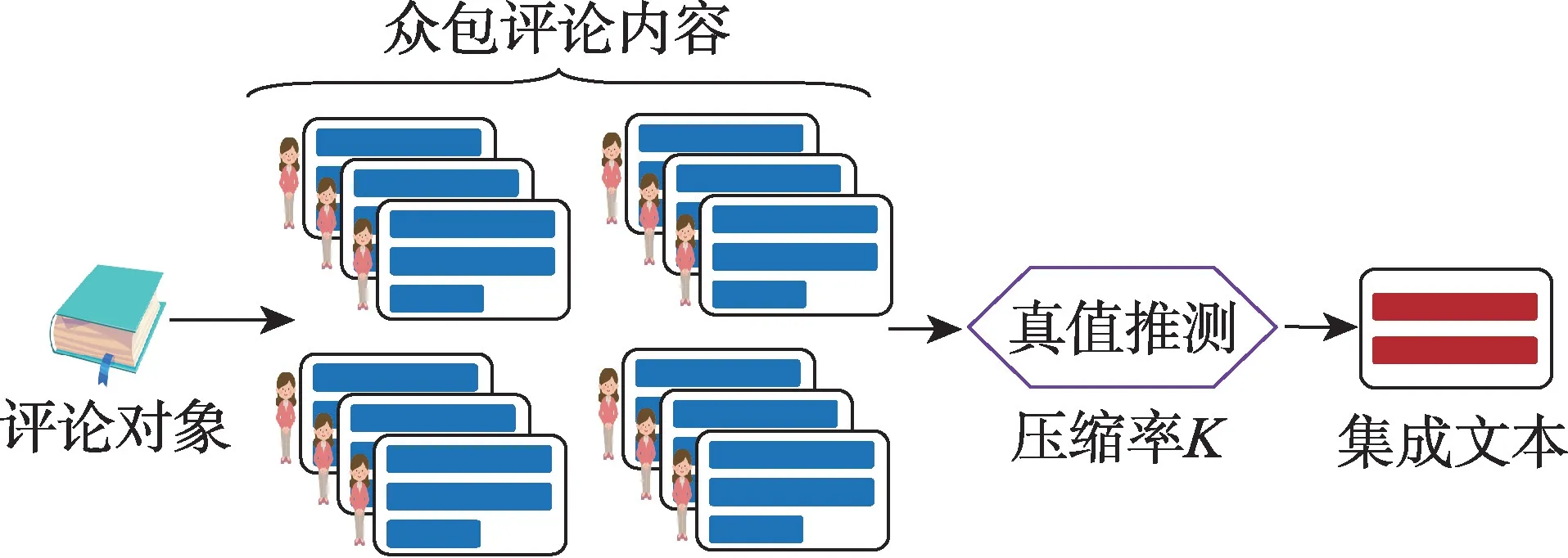
Fig.1 General process of crowdsourced comment integration图1 众包评论文本集成的一般过程
然而,评论集成所面临最大困难是缺少真值指导。对于常规的标签集成任务而言,最终集成结果仍由所标注对象的标签真值进行评价,故在进行标签真值推测时可利用真值样本,通过基于概率统计的相关方法进行数据分析与修正;相反,对于评论集成而言,获取众包评论集成真值需投入较高的人力与时间成本,且当文本量较大时,通过分析文本内容确定评论集成质量的思路不可行。故为了克服上述困难,本文提出一种利用长期收益预测与策略梯度上升的两阶段众包评论文本集成方法(two-phase crowdsourced comment integration method,TP_CCI)。该方法构建代理,旨在不依赖任何人工提供的真值数据,仅依靠代理从原始评论中抽取关键语句形成集成文本,由此推测出与当前评论对象最为匹配的内容描述。
具体而言,所提出方法TP_CCI 以特定深度神经网络组件表示代理结构(记为Q),在第一阶段从语句相关性(relevance,Rel)与语句冗余度(redundancy,Red)刻画集成文本内容质量并以此作为收益,针对集成文本内容质量,预测在当前状态s下,选择特定语句a后,直至文本集成过程结束时所能够取得的长期收益,由所预测长期收益指导代理学习出针对文本内容质量的最优选择策略π*=arg maxaQ(s,a)。此处,s为当前时刻下原始评论文本与集成文本状态,a为代理从原始评论中抽取的特定语句,Q(s,a)(即Q-值)表示代理在特定状态s下选择语句a直至文本集成过程结束时,集成文本在内容质量上所能够取得的长期收益期望;其次,在第二阶段中,所提出方法TP_CCI 以集成文本情感强度作为收益,利用策略梯度(上升)对第一阶段最优选择策略π*进一步调整,使得所产生集成文本从客观角度最突显语句情感强度,不论语句情感的正负倾向。
1 相关工作
与众包标签集成相比,现有众包评论文本集成所做工作较少[3],且文本摘要与众包评论文本集成问题最为相似,二者目标均是将较长文档内容按既定压缩率K整合为较简短的内容总结,其中应包含源文档中的重要语句,且减少语句间的冗余性。
现有文本摘要工作大致可分为抽取型与生成型两种。典型的抽取型文本摘要工作有:文献[4]利用语句与标题相似性、词语TF-IDF(term frequencyinverse document frequency)权重以及语句位置嵌入作为特征进行语句表示,通过训练深度学习分类器,判定当前语句是否应被选入文本摘要中;文献[5]将源文档中的语句作为节点,将文档转为结构化图,根据图中节点(语句)中心度选取若干关键语句形成摘要文本。生成型文本摘要旨在利用源文档中已有词语,组织新的关键短语与语句形成文本摘要,典型工作包括:文献[6]通过词向量训练将语句表示为n维句子向量,以此为输入,利用编码器与解码器结合上下文注意力机制,生成新的语句内容形成摘要;类似的,文献[7]在利用编码器与解码器生成文本摘要过程中引入摘要与源文档在单个词语、两个词语以及最长公共子序列上的重合度,通过最大化三者重合度提高文本摘要质量。
文本摘要与众包评论文本集成的差异性主要集中在两方面:(1)文本摘要问题较为重视语句一致性与连贯性,即摘要中关于特定对象的属性描述应在上下文中保持一致,且语句衔接应尽可能与人为书写摘要接近[8];相反,对于众包评论文本集成而言,其根本目的是使用户快速知晓众多购买者对当前物品所持有的主要观点,如图1 所示,当既定压缩率K较大时,集成文本中或包含意见相反的观点,此类不一致性信息在集成文本中仍为重要信息[9]。(2)现有文本摘要工作主要采用有监督方法,即通过人为提供的“金标准”摘要训练模型以处理新文本生成摘要[10],然而对于众包评论文本集成问题而言,获取众包评论集成后的“真值数据”成本巨大,利用有监督方法进行模型训练较困难。
故为克服众包评论文本集成在获取“真值数据”上的困难,本文摒弃传统有监督方法,由所构建代理的经验收益指导模型训练[11-12],通过经验收益进行模型训练的常用关键技术包括:Q-值学习(Q-learning[13])与策略梯度(policy gradient[14])。具体而言,记状态(state,s)为当前所处环境的抽象表示,给定状态s,有若干动作(action,a)可供代理(记为Agent)选择,当代理在状态s下选择了动作a后,可由当前状态s流转至下一状态s′,从而获得收益(reward,r),重复上述过程即可获得代理的一次行为经验,记为τ={s1,a1,r1,s2,a2,r2,…,sT-1,aT-1,rT-1,sT},则通过行为经验指导代理进行动作选择的总体目标如式(1)所示,即最大化其长期收益期望,其中一次行为经验τ由概率分布P产生。

由此,Q-值学习旨在根据时刻i处状态s与所选动作a,利用DQN(deep Q-network)神经网络,预测从时刻i至时刻T(一次行为经验τ结束),代理所能够取得的长期收益期望,由所预测长期收益期望选择最优动作a,从而间接形成最优选择策略;此处,DQN 神经网络无固定结构且是该情形下所使用深度神经网络统称[15];相反,策略梯度旨在直接学习出一个最优选择策略,使得代理所取得的长期收益期望最大化。
综上所述,本文摒弃传统有监督学习方法,不依赖于任何人工提供的真值数据,以深度神经网络构建代理,借助Q-值学习与策略梯度上升,在两阶段分别以文本内容质量(即语句相关性与冗余性)以及文本情感强度作为收益,由代理所取得的经验收益分两阶段指导众包评论文本集成过程。
2 两阶段众包评论集成
2.1 文本表示与众包评论集成过程
如图2 所示,当给定评论对象后,可从众包平台收集不同用户所发布的评论文本,本文将M个用户所发布评论内容合并为一个源文档(记为source_doc)。首先,对每个源文档进行文本预处理,具体包括分词、去除停用词、词性标注(仅保留副词、形容词、动词与名词);之后,采用Skip-2-Gram[16]预训练词向量,由此每个词语可表示为dim维词向量,且如式(2)所示,源文档中每个句子可由其所包含词语的词向量均值表示为句子向量。

Fig.2 Representation of comment and demonstration of comment integration in extractive way图2 评论文本表示方法与抽取型集成过程示意

此外,如图2 所示,各时刻下状态(state)可由源文档及其集成文档(记为Int_doc)共同表示,记为statei=
2.2 针对集成文档内容质量的长期收益预测
如上所述,当代理以图2 所示过程进行语句选择时,挑选具有最大长期收益期望的语句a以确保选择最优性。采用Q-值学习预测从当前时刻i处,选择任意语句动作a后,直至集成过程结束(时刻T)所产生的长期收益期望;此处,收益针对集成文档内容质量(即语句相关性与冗余性)进行衡量。具体而言,如图2 所示,记给定状态si=
具体而言,如图3 所示,代理(Agent)首先分析状态st的前N个历史状态与动作选择,通过多次卷积操作,将N个历史状态动作对(s,a)卷积为向量mt-1:t-N。此处,每个状态可表示为s=[source_vec,Int_vec],其中source_vec为源文档句子向量均值,Int_vec为集成文档句子向量均值,显然,source_vec值不会改变,但Int_vec值会随着集成过程推进而不断改变,图3 中语句动作a为从源文档选取的句子向量(sentence_vector)。另一方面,在图3 底部,从当前状态st=[source_vec,Int_vect]出发,经过一系列激活函数变化,最终获得向量mt:T,该向量是对后续状态流转表示上的预测,其中Sig 表示Sigmoid,μ表示所预测均值,δ表示所预测标准差,Z=[μ+δ·Normal(0,I)],Normal表示正态分布,ε~clip(Normal(0,I),-c,c)为所引入噪声以防止过拟合,其取值将大于c或小于-c部分全部截断,均设为c与-c。最终,给定当前状态st=[source_vec;Int_vect],代理根据图3 所示过程,预测后续长期收益期望Q(st),具体如式(3)~式(5)所示。

式(3)将两部分状态解析结果合并,经过ReLU激活变化后,引入参数WRel,它用于观察当前状态,并刻画后续状态变化时集成文档与源文档的相关性(Rel);同理,式(4)将两部分状态解析结果合并,经过ReLU 激活变化后,引入参数WRed,它用于观察当前状态,并刻画后续状态变化时集成文档所具备的冗余性(Red);式(5)以相关性与冗余性之差预测当前状态st=[source_vec;Int_vect]所能够产生的长期收益期望,即向量Q(st)∈RA,此处A表示对齐后所有可选动作(语句)数量,且Q(st)中每个分量表示状态动作对(st,ai)的长期收益期望,即Q(st,ai)∈R(Q-值),由此一次性将所有可供选择语句长期收益期望全部预测出来。
2.3 阶段1:利用Q-值的语句选择策略学习
基于图3 所示代理结构与式(3)~式(5)所示基于函数Q(st,ai)(Q-值,针对文档内容质量)的长期收益预测过程,图4 给出第一阶段针对集成文档内容质量的最优语句选择策略学习过程。
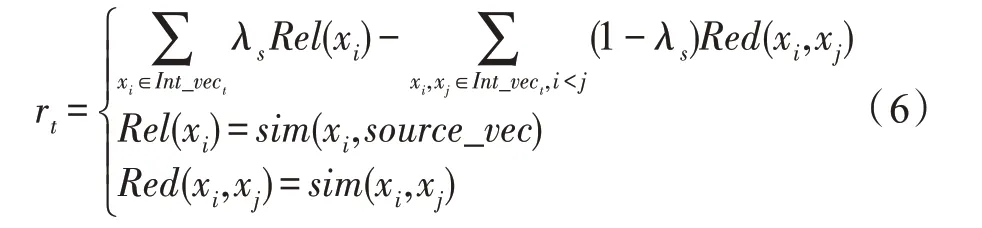

Fig.3 Expected long-term reward of each action(sentence)predicted by agent under state st图3 代理预测状态st 下各语句动作的长期收益期望

Fig.4 Selection policy based on content quality of integrated comment by Q-value图4 由Q-值针对集成文档内容质量的语句选择策略
具体而言,图4 引入两个代理(即两套如图3 所示的神经网络组件),分别记为Agent_Online(θ1)与Agent_Target(θ2),两个代理结构完全一致,但使用两套独立参数(如θ1与θ2)。在职责划分上,Agent_Online(θ1)为最终所需学习的选择策略(即代理),它根据当前源文档与集成文档状态,进行一系列语句动作选择,产生多个形如(st,at,st+1,rt)的记录,并放入缓存乱序存储;每条记录表示代理从当前状态st通过采取动作at流转至下一状态st+1,由此产生当前时刻收益rt,当前收益rt由式(6)计算,即在当前时刻t处,集成文档Int_vect自身相关性由其所包含语句向量与源文档向量表示source_vec相似性之和决定;集成文档Int_vect自身冗余性由其内部所包含语句向量相似性之和决定,最终当前时刻收益rt为集成文档自身相关性与冗余性之差。此外,式(6)中的相似性函数sim可为任意向量相似度计算方法,本文采用余弦相似度。
其次,如前所述,在训练Agent_Online(θ1)时本文不引入任何人为提供的真值数据,故Agent_Target(θ2)的唯一职责是抓取缓存记录,并重新预测长期收益,以此作为经验训练Agent_Online (θ1),因而Agent_Target(θ2)不可被训练。两个代理协作过程如式(7)~式(11)所示。

首先,在式(7)中,代理Agent_Target(θ2)从缓存中获取由Agent_Online(θ1)产生的记录(st,at,st+1,rt),取得其中的下一状态st+1,并预测从st+1起每个语句动作(action,a)所能产生的长期收益,通过选择最优语句动作a′,获得在下一状态st+1,选择下一语句动作a′ 后,集成文档所能够取得的最大长期收益;该值通过式(3)~式(5)从集成文档语句相关性与冗余性两方面计算获得,故可视为在状态st+1下,针对集成文档内容质量长期收益的最优值;γ表示折扣率。由此,式(7)表示状态st所产生当前收益rt,与从状态st+1起后续最大长期收益之和,即从状态st出发所能取得最优长期收益的重新预测,记为;该值是式(8)中所计算收益上限。换言之,式(8)中,表示当代理Agent_Online 从当前状态st出发时,针对集成文档内容质量所预测的长期收益期望(由式(3)~式(5)计算)。
因此,式(7)与式(8)观察样本记录(st,at,st+1,rt),并由代理Agent_Target(θ2) 为Agent_Online (θ1)创建关于集成文档内容质量上的“伪真值”,最终获得长期收益误差“error”。接下来,式(9)与式(10)对误差做0-1 截断,并获得标准化后的损失函数J(θ1),通过最小化该损失函数,即可不依赖于任何人工真值数据,针对集成文档内容质量训练代理Agent_Online(θ1)。最后,式(11)表示在训练若干步后,将代理Agent_Online(θ1)的参数拷贝至Agent_Target(θ2)中,从而更新Agent_Target中的参数θ2。
2.4 阶段2:基于策略梯度的语句选择策略学习
第一阶段学习完成后,代理Agent_Online(θ)便具备了针对集成文档内容质量的相关参数取值。第二阶段利用策略梯度针对集成文档情感强度进一步对Agent_Online(θ)进行训练,使其所产生集成文档具备较强的情感强度,以突显评论者的情绪态度,具体流程如图5 所示。图5 首先对代理Agent_Online(θ)进行结构调整,即当图3 所示组件结构计算出集成文档相关性与冗余性后,额外添加神经网络层计算softmax(φ([Rel;Red]))∈RA,此处A为对齐后的语句总数,φ为激活函数。该层负责拟合给定状态state=

Fig.5 Phase 2:selection policy training process on sentence sentiment intensity by policy gradient图5 阶段2:基于策略梯度进行针对语句情感强度的选择策略训练
接下来,由所拟合分布p(a|s)按概率选取语句,并记其下标为Index。为了刻画语句选择时的不确定性,此处按概率(而非最大值)选取语句,以确保每个语句都有机会被选中。之后,如图5 所示,将所选中语句下标转为0-1 编码。特别的,在第二阶段中,代理Agent_Online(θ)每进行一次语句选择就观察一次源文档,确认源文档可供选择语句中情感强度最大的语句下标(已选择语句不再考虑),由此通过观察源文档获得情感强度的“真值”标签。最终,如图5 所示,阶段2 将语句选择转化为分类问题,迫使代理Agent_Online (θ)所拟合的概率分布p(a|s)能够选中情感强度最高的语句。此处,每个语句情感强度由该句所包含词语的情感强度绝对值(|wsent|)之和计算得到。本文借助情感词典SenticNet 5.0(https://sentic.net/downloads/)直接获取词语情感强度值(wsent∈[-1,1])。第二阶段利用策略梯度针对集成文本情感强度方面的训练过程如下所述。

首先,代理Agent_Online(θ)进行多轮语句选择,获得N次行为经验,其中a为所选择语句。显然,每完成一轮τi,则产生一个集成文档,且τi的总体收益R(τi) 由式(12)获得。式(12)以词语情感强度绝对值(|wsent|)之和表示各时刻下所产生收益rt,在此基础上计算针对集成文档情感强度的累计收益R(τi)。此外,式(12)通过N次经验的收益均值对R(τi)做标准化,使得针对情感强度的收益取值存在正负差异。

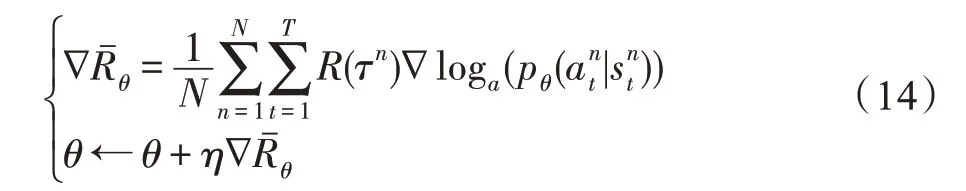
接下来,如式(13)所示,代理Agent_Online(θ)的优化目标为最大化N次经验的总体收益均值(即情感强度)。特别的,在式(13)中利用每次τn的总体收益R(τn)为对应的语句选择概率pθ(a|s)进行加权,意在表明若第n次经验所带来的总体收益R(τn)(即情感强度)越大,则希望语句a被选中的概率越大,由此获得最优语句选择策略。pθ(a|s)以交叉熵方式,由图5中每轮观察所得的“真值标签”与代理Agent_Online(θ)选择所得的下标编码计算获得。最后,式(14)对式(13)所示的目标函数做“策略梯度上升”,由此确保当总体收益R(τn)较大时,提升相应参数梯度,并提高具体参数值,其中η表示学习率。
算法1 给出了两阶段训练代理Agent_Online(θ)的完整过程。首先,第1~3 行做文本表示与必要的数据组装(如statei=
算法1两阶段训练Agent_Online(θ)

最后,值得注意的是,如图5 所示,第二阶段为Agent_Online (θ)添加新的神经网络层,此时参数θ包含阶段1 针对集成文档内容质量训练的参数取值,以及新添加网络层参数。故在第二阶段训练时,仅初始化新网络层参数,已有参数在第一阶段取值基础上做微调。此外,当代理Agent_Online (θ)完成两阶段训练后,其参数θ便含有应对集成文档内容质量与情感强度的具体取值,此时可由训练后的Agent_Online(θ)按图2 所示过程,以源文档与集成文档状态为输入(statei=
3 实验结果与分析
本章对所提出方法TP_CCI 进行一系列测试并分析实验结果。首先,对于数据集而言,本文从亚马逊(https://www.amazon.cn/)平台中爬取200 本书的众包评论,其中每本书包含M=10 个用户所发布评论,由此构成每本书的众包评论源文档(共计200 个,记为Dataset_200)。此外,为了从文档内容质量与情感强度两方面评估集成文档质量,本文为每个源文档书写了人工集成文档(记为Manual_Integration),人工集成文档由从事自然语言处理的研究人员书写且经过两轮质量检查。对于TP_CCI 而言,人工集成文档不参与上文论述的两阶段训练,仅用于实验结果评估。
更进一步,对于数据集Dataset_200 而言,本文将其随机分为两组,分别记为group1 与group2,每组各包含100 个源文档与100 个人工集成文档(Manual_Integration)。对于group1 而言,100 个源文档字节数分布于[2 931,11 022]之间,平均大小为6 645 字节,100 个Manual_Integration 的压缩率K分布 于[20.54%,22.60%]之间,平均压缩率为21.30%;对于group2 而言,100 个源文档字节数分布于[2 783,10 359]之间,平均大小为6 505 字节,100 个Manual_Integration 的压缩率K分布于[40.04%,43.98%]之间,平均压缩率为41.15%,此处压缩率K指集成文档字节与源文档字节比率。
在实验设置方面,选用dim=128 维词向量,图3中历史状态N=5,所引入的ε~clip(Normal(0,I),-c,c),取正态分布中Normal(0,I=0.1),c=0.2;学习率η=0.06;group1 中取折扣率γ=0.95 ;group2 中取折扣率γ=0.9。值得注意的是,此处选用正态分布的原因为其所拟合的参数分布与真实场景最为接近,且上述参数取值均通过网格搜索以确定最优值。此外,阶段2 中使用词典SenticNet 5.0 提供词语的情感强度绝对值(|wsent|∈[0,1]),故与文献[17]保持一致,仅关注动词、形容词、副词、名词以及习语,以去除虚词(等停用词)影响。最后,如算法1 所示,TP_CCI 在阶段1与阶段2 中各取100 轮迭代训练,且每20 步将Agent_Online 所使用参数θ1拷贝至Agent_Target 参数θ2。此外,本文 将TP_CCI 与ASRL[18]、Reaper[19]、MMS_Text[20]、SOSML[21]、SummaRuNNer[22]、DQN_RNN[23]进行对比,其中ASRL、Reaper 与TP_CCI 一致,均不借助人工提供的真值数据(即Manual_Integration),仅依靠收益经验进行训练,但ASRL 与Reaper 不采用神经网络组件,均由差分学习[24]实现;MMS_Text 与SOSML 为无监督方法,二者均将源文档转为图结构,以节点表示语句,通过对节点打分抽取前TopN个语句形成集成文档;SummaRuNNer 与DQN_RNN 为有监督方法,即以Manual_Integration为真值指导训练过程。上述所有方法均以语句为单位,通过抽取语句形成集成文档(直至满足压缩率阈值K后停止),且记上述方法所产生集成文档为Auto_Integration。本文实验环境为GPU,NVIDIA GeForce GTX 1080Ti 11 GB,由Python 2.7 与Tensorflow-1.10实现。
在评价指标方面,本文首先采用ROUGE-1(R-1)、ROUGE-2(R-2)以及ROUGE-L(R-L)[25]评估Auto_Integration 与Manual_Integration 在1 个词语、2 个词语以及最长公共子序列上的重合度,并计算三者均值(averaged summary rouge,ASR),以此评价集成文档内容质量(即内容指标);其次,本文分别使用式(15)与式(16)评估文档的情感强度(即情感强度指标)。式(15)计算文档的整体平均情感强度,式(16)计算各文档情感强度最大值的平均,此处D表示文档数量,S表示文档语句数量,W表示词语数量。此外,式(15)与式(16)均采用词语情感强度绝对值(|wsent|),旨从客观角度评估文档情感强度,不论情感正负倾向。

最后,在实验过程方面,本文在group1 与group2上,分别取各方法5-折交叉验证评价指标均值(如内容质量与情感强度两方面)为最终结果,且在group1与group2 上进行文本集成(产生Auto_Integration)时,上述所罗列方法分别取平均压缩率K=21.30%与平均压缩率K=41.15%。
3.1 众包评论文本集成效果与效率比较
表1 给出了在group1 上众包评论文本集成效果与效率指标(斜体、加粗、下划线字体表示最优结果,斜体、加粗字体表示次优结果,其他表一样)。此处,内容指标R-1、R-2、R-L 以及ASR 借助人工集成文档(Manual_Integration)进行计算,使用压缩率K=21.30%,且“baseline”表示在Manual_Integration上的情感强度取值。通过观察表1 可以发现,在内容指标上(如R-1、R-2、R-L 以及ASR),本文 方法TP_CCI 总体优于其他两个收益指导方法ASRL 与Reaper;与无监督方法相比,仅在R-L 上TP_CCI 低于SOSML;与有监督方法相比,TP_CCI 所取得内容指标与SummaRuNNer 以及DQN_RNN 几乎接近;在情感强度指标方面(如avg_senti 与avg_senti_max),本文方法TP_CCI产生的集成文档(Auto_Integration)优于人工产生的集成文档(Manual_Integration),即相比于人工产生的集成文档,方法TP_CCI 产生的集成文档具备更高的情感强度,能够更直观反映用户的情感态度。另一方面,与其他方法产生的集成文档相比,TP_CCI 取得最优情感强度。最后,在效率方面,当Agent_Online 训练完毕后,其产生集成文档所耗费时长(单位:s)仍在可接受范围之内。

Table 1 Comparison of performance and efficiency of crowdsourced comment integration on group1(compression rate K=21.30%)表1 在group1 上众包评论文本集成效果与效率比较(压缩率K=21.30%)
表2 给出了在group2 上众包评论文本集成效果与效率指标。此处,内容指标R-1、R-2、R-L 以及ASR借助人工集成文档(Manual_Integration)进行计算,使用压缩率K=41.15%,且“baseline”表示在Manual_Integration 上的情感指标取值。与表1 类似,即便方法TP_CCI 在进行众包评论文本集成时,未借助任何人工真值(如Manual_Integration),仅由收益经验指导学习,但在表2 中,方法TP_CCI 所取得内容指标几乎接近于有监督方法SummaRuNNer,甚至优于有监督方法DQN_RNN;此外,在表2 中,方法TP_CCI 所取得情感强度指标仍优于人工产生的集成文档,且优于其他对比方法。与此同时,从表2 可以发现,即便group2 中文档压缩率有所提高,TP_CCI 的测试效率仍控制在可接受范围之内。表1 与表2 均使用平均压缩率分别在group1 与group2 上进行众包评论文本集成,故还需对压缩率K进行讨论,明确其对文本集成的指标影响。
3.2 对两阶段训练过程的讨论
本节对所提出方法TP_CCI 在两阶段训练结果上进行比较,即分别仅由阶段1、阶段2 以及两阶段同时训练代理,之后根据代理所习得语句选择策略,以图2 所示方式通过既定压缩率K选择语句产生集成评论文档,由此借助上述三类训练方案所产生集成文档在内容质量与情感强度指标上的差异,比较方法TP_CCI两阶段训练效果。
具体而言,表3 给出了方法TP_CCI 在group1 上的两阶段训练效果,可以发现当同时利用Q-值学习在阶段1 中进行长期收益预测(以文档内容质量为收益)以及利用策略梯度在阶段2 中进行梯度上升(以文档情感强度为收益)所取得的文档集成效果最优。此外,当仅通过阶段2(针对文档情感强度)训练代理时,所产生集成文档在内容质量与情感强度指标上表现欠佳;相反,当仅通过阶段1(针对文档内容质量)训练代理时,所产生集成文档指标与两阶段训练效果较为接近。该现象可归因为文档情感总是通过内容体现,针对文档内容质量进行语句选择策略学习亦可间接提高文档对情感态度的表达,该现象也说明了本文对阶段1 与阶段2 在训练顺序上的合理性。表4 给出了方法TP_CCI在group2 上的两阶段训练效果,与表3 类似,同时进行两阶段训练所取得的集成文档质量最优,仅由阶段1 训练所产生的集成文档质量次之。最后,表3 与表4 中三类训练方法产生集成文档耗费时长均较为接近,该现象可归因为三类训练方法均以图2 所示方式,以相同结构代理产生集成文档。

Table 2 Comparison of performance and efficiency of crowdsourced comment integration on group2(compression rate K=41.15%)表2 在group2 上众包评论文本集成效果与效率比较(压缩率K=41.15%)

Table 3 Comparison of performance of two-phase training on group1(compression rate K=21.30%)表3 在group1 上两阶段训练效果比较(压缩率K=21.30%)
3.3 对压缩率K 的讨论
表5 给出了在group1 上,当分别取压缩率K为10%、20%、30%以及40%时,进行众包评论文本集成所取得的效果与效率指标。此处,内容指标R-1、R-2、R-L 以及ASR 借助人工集成文档进行计算,且人工集成文档所使用压缩率K≈20%。表5 中复用表1 结果,记压缩率K≈20%。值得注意的是,由于group1上压缩率K分布于[20.54%,22.60%]之间,改变压缩率会造成Auto_Integration字节数低于或高于Manual_Integration,故表5 的情感强度指标不再与人工集成文档相比较(即省略表1 中的“baseline”)。通过表5可以发现,在内容指标方面(如R-1、R-2、R-L 与ASR),本文方法TP_CCI 总体上优于同类型收益指导方法,以及两个无监督方法,与有监督方法内容指标仍较为接近;此外,在情感强度指标上,不论压缩率K如何变化,方法TP_CCI 所产生集成文档均具备最优情感强度,亦反映出通过图5 所示由情感强度收益,拟合语句选择概率分布的思路有效可行。在表5中当压缩率K从10%增加至40%时,平均情感强度(avg_senti)在K≈20%处取得最高值后逐步下降,即当压缩率K≈20%时取得最好结果,压缩率K增大后文本集成性能受到影响;相反情感强度最大值的平均(avg_senti_max)随压缩率增大而提高。最后对于测试效率而言,由表5 可以发现,不论压缩率K如何变化,方法TP_CCI 所耗费时长仍控制在可接受范围之内。

Table 4 Comparison of performance of two-phase training on group2(compression rate K=41.15%)表4 在group2 上两阶段训练效果比较(压缩率K=41.15%)

Table 5 Using different compression rates K to conduct crowdsourced comment integration on group1表5 在group1 上以不同压缩率K 进行众包评论文本集成
最后,表6 给出了在group2 上,当分别取压缩率K为10%、20%、30%以及40%时,进行众包评论文本集成所取得的效果与效率指标。此处,内容指标R-1、R-2、R-L 以及ASR 借助人工集成文档进行计算,且人工集成文档所使用压缩率K≈40% 。表6 中复用表2 结果,记压缩率K≈40%。与表5 类似,表6 中方法TP_CCI 的内容指标总体上优于同类型收益指导方法,但如表6 所示,当压缩率K取20%、30%与40%时,方法TP_CCI 所取得内容指标优于有监督方法DQN_RNN,可以发现即便TP_CCI 不依赖于人工真值(即人工集成文档),依旧能通过收益经验取得较乐观的内容指标。另一方面,表6 中TP_CCI 的情感强度仍在各压缩率下取得最优值,且测试效率仍控制在可接受范围之内。

Table 6 Using different compression rates K to conduct crowdsourced comment integration on group2表6 在group2 上以不同压缩率K 进行众包评论文本集成
综上所述,本文提出利用收益预测与策略梯度的两阶段众包评论集成方法(TP_CCI),区别于常规有监督方法,该方法通过评论文本集成的收益经验,不依赖于任何人工提供的真值数据,仅通过源评论文档便可自行完成评论文本集成。此处收益经验由集成文档内容质量与情感强度共同构成,且通过实验可以发现,本文方法TP_CCI 的内容指标总体优于同类型收益指导方法以及无监督方法,与有监督方法所取得内容指标几乎接近;此外,不论压缩率K如何变化,方法TP_CCI 所取得的情感强度指标均优于其他现有方法,且产生集成文档所耗费时长仍控制于可接受范围之内。
4 结束语
众包数据中含有大量的隐藏信息,对这些信息进行处理十分重要。目前,大量工作集中于众包数据的标签集成,即清理标注数据以推测出标签真值,将集成对象从离散标签转为连续文本所做工作仍较少。评论文本集成即根据大众所书写的评论内容推测出关于某一特定对象较为匹配的内容描述。为了克服有监督学习在集成文本真值依赖上的束缚,以收益经验指导代理,通过两阶段学习针对源众包评论文档内容质量与情感强度的最优语句选择策略,可取得较为可观的文本集成效果。实验表明所提出利用收益预测与策略梯度的两阶段众包评论集成,能以较少的数据成本,在内容指标与情感强度两方面总体上取得最优,且效率上仍在可接受范围之内。下一步将探讨多代理环境下的众包评论文本集成方法。
