一种基于标签传播的社团检测算法
2021-08-06谭玉玲
谭玉玲
(罗定职业技术学院 信息工程系,广东 罗定 527200)
复杂网络可看作是一个包含大量节点的无向图或者有向图,边上的权值是节点与节点之间的相似度,相似度高的节点可最终被划分进入同一个社团.通过对社团的检测,可以了解到整个复杂网络的发展趋势以及整个群体的关键特征,并且有利于了解到网络的拓扑结构并提取出隐藏在复杂网络中的有利信息[1].正是因为社团检测在日常生活中应用地越来越广泛,如何精确划分复杂网络成为社团就成了人们关注的重点.
对于传统的社团检测算法大致可分为图划分方法、基于层次聚类的算法、基于进化的算法等[2].标签传播算法是一种经典的被广泛使用的社团检测算法,有着简单、快速等优点.文献[3]提出了最经典的GN算法,文献[4]提出了一种新的标签传播的社团检测RAK算法,分类效果好且复杂度较低.文献[5]对RAK算法进行改进,引入目标函数,将算法的社团检测变为一个模块度最大化的问题.文献[6]中改进了节点标签的更新方式,但是容易陷入局部最优.文献[7]提出了一种基于社团核的标签传播算法,改善了算法性能,但需要提前给出社团核数目,导致检测结果可能变得随机.
已有的标签传播算法具有很强的随机性且其鲁棒性较差等问题.本文针对基于标签传播算法中存在的社团检测结果不稳定的情况,提出了一个基于循环查找核节点的标签传播算法,实验结果证明本文所提算法可以有效检测出社团结构.
1 社团检测相关技术
1.1 标签传播算法
标签传播算法是一种基于图的算法,主要思想是把复杂网络图中每个节点都被赋值上一个标签值,若相邻节点与一个节点的相似度大,则把相邻节点的标签值替换为该节点的标签值,具有相同标签的节点则被认为可以规划到同一个社团中[8].
在实际生活中,如果A生病了,有可能会传染给同学B,此时同学B有一个朋友C,C与A并不相识,但是B有可能传染给C,结果导致C也生病,此时A、B、C理论上可被划到一个社团中,因为是同一个原因生病.标签传播算法不仅仅适用于小型网络,同样适用于大型复杂网络.
节点的标签被更新为节点相邻数目最多的标签,标签更新的公式如下所示[9]:
li=arg maxa∑t∈Γiσ(lt,a),
(1)
式(1)中,li表示节点i的标签,t表示节点i的邻居节点,a表示更新后的标签,Γ(i)是表示节点i的邻居节点集合,lt表示节点t的标签,当lt与a相同时,σ(lt,a)=1,否则为0.
传播中标签更新过程如图1所示.图中标签为1的节点的更新过程,由于标签为1的节点有4个邻居节点,标签分别为2,3,3,5,其中有两个邻居节点的标签为3,则标签为1的节点将会更新为3.
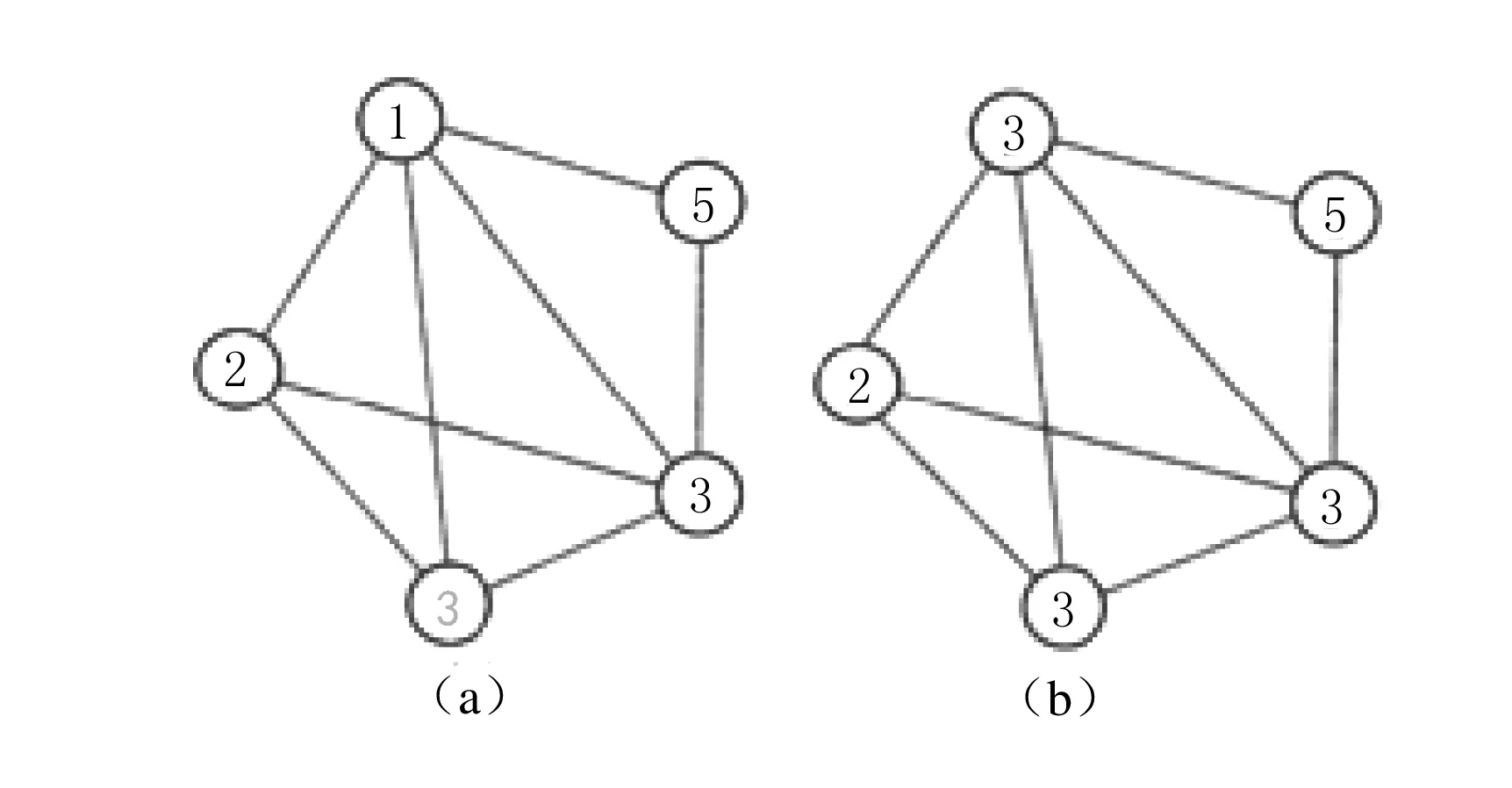
(a)图为更新标签之前的状态
标签传播算法的基本步骤如下所示.
步骤1:对复杂网络中所有节点的标签进行初始化;
步骤2:将算法的迭代次数初始化为n=1;
步骤3:将复杂网络中的所有节点随机排列形成T序列;
步骤4:对于T序列中任意一个节点i,Ti(n)=f(Ti1(n),……,Tim(n),Ti(m+1)(n-1),……,Tik(n-1));
步骤5:当网络中所有节点的标签不再更新时算法结束,否则迭代次数加1,即n=n+1,且返回步骤3.
1.2 社团检测结果的评价
对于社团检测来说,最后的结果是要得到一个社团内部关系紧密、社团与社团之间关系稀疏的划分结果,因此,就要有一些算法评价标准来判断划分结果的好坏,以算出的值显示划分社团的精确程度.目前,最常用的两个算法评价标准是Newman提出的模块度Q函数,传统的模块度存在分辨率问题[10].模块度函数经常被当作社团检测的评价标准,模块度Q越大,表示复杂网络划分越精确,所以优化模块度函数Q值一直是学者所追求的目标.对于本文中引用的无向复杂网络,模块度函数可以如式(2)表示:
(2)
其中:u表示网络中随机选择的一个社团,t代表复杂网络中社团的总体数目,l(u)代表社团u内边的条数,m表示所有社团即整个网络的所有边的条数.
2 基于循环核心节点标签传播的社团检测算法
2.1 算法的改进思想
标签传播算法大致可分为标签初始化阶段、标签传播阶段和标签划分阶段3个部分.本文主要是通过对第2部分标签的传播阶段进行改进,实现算法对社团结构检测的准确性等方面的提高,主要采取以下策略:①利用循环核心节点查找传播标签;②在邻居节点标签存在相同数量的情况下,只对核心节点进行赋值标签,其他节点从其靠近的核心节点获取标签.
(1)循环查找核节点思想描述
在不同的复杂网络中,都会存在一个与其他节点关系紧密且包含主要信息的一个节点,该节点被称为核心节点[12].核心节点是网络中最有影响力的节点,从该节点发出或者接受的信息也极其重要,在一个复杂网络中,核心节点可能会存在很多个,每个社团会有一个核心节点,核心节点的发展可能会影响这个网络的发展趋势,所以只有抓住核心节点的趋势,才能够掌握整个网络的走向.通过循环查找核心节点,利用核心节点强大的关联力,向核心节点周围进行标签传播,如此可以大大降低算法的复杂度,提高算法的效率.
本文首先查找每个节点在邻居中节点度最大的点作为核心节点,将核心节点作为潜在社团的中心,并将标签传播给它的邻居,逐步形成社团.由于每个核心节点对邻居节点的影响程度不同,所以还需要计算核心节点与邻居节点的相似程度.
(2)降低标签传播随机性思想描述
当对节点进行标签初始化后,则会从一个节点开始进行标签传播,当节点与节点之间边上的权值越大时,该节点的标签就会传播到权值大的边所连接的相邻节点上,该节点的标签值就会覆盖邻居节点的标签值,即邻居节点的标签更新.在理想状态下,每一次迭代过程中,与一个节点连接的所有的边中有且仅有一条边上的权值最大,即只存在一个邻居节点会成为该节点的传播候选节点.然而,有时候会出现与该节点连接的多条边上的权值均相等的情况,此时就会出现多个节点成为该节点的传播候选节点.目前存在的很多算法在遇到这种情况时会在传播候选节点中随机选择一个节点进行标签传播,这就是标签传播算法的随机性.这种随机性大大增加了算法的复杂程度,也影响了算法最后划分社团的准确性.在标签的传播过程和选择过程中,当几个节点的标签值相同时,标签划分也是随机的,这一方面也大大增加了算法的复杂程度.
所以本文算法从传播和选择的随机性进行改进,降低这两个部分的随机性.在标签传播初始化阶段,循环查找到核心节点后,只对核心节点赋值标签,周围其余的节点只从其靠近的核心节点获取标签,加入社团.
2.2 改进算法总体描述
(1)改进算法总体框架描述

图2 算法总体框架
(2) 网络预划分算法描述
输入:网络节点数n,网络拓扑信息;
输出:预划分的结果f1.
步骤1:初始化网络中所有节点标签:1, 2,……,n,其中n表示网络中节点数;
步骤2:根据网络拓扑信息计算节点及其邻居的节点度;
步骤3:选择网络中相互连接的节点度最大的节点作为核节点,初始化核节点集合;
步骤4:计算核节点与其邻居的相似度Fs,当Fs高于某阈值,将该邻居节点标签改为该核节点标签,否则邻居节点标签保持不变;
步骤5:若此时迭代未结束,则整理未改变标签的节点作为新的网络,转向步骤2,否则转向步骤6;
步骤6:输出预划分结果f1.
(3) 基于标签传播算法的预划分优化
输入:网络预划分结果f1,网络节点数n,网络拓扑信息;
输出:预划分的结果f2;
步骤1:整理网络预划分结果中的节点标签;
步骤2:根据网络拓扑信息逐个搜索节点的邻居节点的标签;
步骤3:选择节点邻居中数目最多的标签,将该标签更新为此节点的标签;
步骤4:根据是否所有节点标签达到稳定不再变化,或者根据迭代次数判断更新是否结束,若结束,输出划分结果f2,否则返回步骤3.
(4)算法随机性的改进
初始化时,对核心节点赋值,称为点值,复杂网络中其他节点不赋值.
步骤1:计算所有节点的点值;
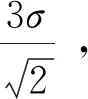
步骤3:找出部分的点值极值点的节点后,对该节点进行赋值标签值;
步骤4:迭代次数初始化n=1;
步骤5:更新节点数量初始化s=0,在极值节点的邻居节点中选择一个节点j,将节点j的标签更新为邻居节点中极值最大的那个节点的标签值.如果节点j的标签值更新,则s=s+1;
步骤6:如果s>0,则n=n+1,并跳转至步骤5.
3 算法验证与分析
3.1 对比算法与测试网络
为了验证本文算法在人工网络和真实网络下的实验结果,选取了7种典型算法进行对比.对比算法如下: LPA算法[11]、LPAm算法[12]、MIGA算法[13]、GN算法[14]、Meme-net算法[15]、MOEA/D算法[16]以及GA算法[17].LPA是标准的标签传播算法;MIGA算法是一种基于模块度的改进遗传算法,通过优化模块度函数获得较优的社团检测结果;GN算法通过计算边界数将边移除从而分解网络,得到网络社团结构;Meme-Net算法是一种协同的遗传算法,并采用爬山法作为局部搜索方法;MOEA/D算法基于多目标进化算法的社团检测;GA算法是一种检测网络中社团结构的遗传算法,该方法引入社团得分的概念,并通过最大化社团得分获得最佳的网络划分.算法参数设置与文献中推荐的保持一致.
本文测试网络如下:Karate网络空手道俱乐部的复杂网络;Football网络美国大学足球队的复杂网络;还有Dolphin网络新西兰海豚的复杂网络.本文采用了模块度函数Q值算法评价标准,最后使用Q值与其他算法的Q值结果进行对比.
3.2 实验结果与分析
各种算法在空手道Karate复杂网络上的Q值结果比较检测如图3所示.

图3 空手道Karate的Q值结果比较图
由图3可知,本文算法在空手道Karate复杂网络上的Q值是0.4198,与其中3种算法结果相同,略高于剩下两种算法,所以本文的算法在空手道Karate复杂网络上的结果是可行的.
各种算法在美国大学足球队Football复杂网络上的Q值结果比较如图4所示.
由图4可知,本文算法在美国大学足球队Football复杂网络上的Q值是0.6034,高于其中四种算法,所以本文的算法在美国大学足球队Football复杂网络上的结果是可行的.
各种算法在新西兰海豚Dolphin复杂网络上的Q值结果比较如图5所示.

图4 美国大学足球队Football的Q值结果比较图

图5 新西兰海豚Dolphin的Q值结果比较图
由图5可知,本文算法在新西兰海豚Dolphin复杂网络上的Q值是0.5276,略高于其他5种算法,所以本文的算法在新西兰海豚Dolphin复杂网络上的结果是可行的.
各种算法在以上3个复杂网络模型的Q值结果最优值总结如表1所列.
4 结论
本文提出了一种改进的标签传播社团检测算法,使用循环查找核心节点的方法,增加社团检测结果的多样性.在标签传播过程中,减少随机性的影响,结果表明了算法的有效性.今后的研究将进一步考虑算法的时间复杂度,设计更优秀的社团检测算法.

表1 最优值总结
