电子银行客户群预测相关技术探析
2021-08-04周瑞涛王晓辉
李 翠,周瑞涛,王晓辉
(青岛黄海学院,山东 青岛 266555)
0 引言
客户群分类是对银行所开展的电子银行业务按照客户的使用和办理情况进行分类,为银行进行客户关系管理提供依据。客户群分类是客户关系管理(CRM)很重要的一环,可以说是必不可少的。
银行客户的分类通过数据挖掘技术来对进行,具体操作可以根据事先指定的规则找到满足规则的客户群;也可以对客户利用聚类方法进行自然分群;还可以根据交易行为对客户进行分类,以确定什么样的客户最有可能为银行创造高的利润[1]。如何利用现有的银行数据,对电子银行客户进行识别,找到高价值的客户并为之提供个性化的服务,是留住客户、维持与客户良好关系的有效方法。本文主要针对电子银行客户的分类预测方法进行了简述。
1 常用的分类预测算法
分类是一种被广泛应用的数据分析方式,它是描述数据结构类的重要模型,可以用它来预测离散的、无序的数据类别。数据分类是一个两阶段的过程,包括构造分类器的训练阶段和使用分类器预测给定数据的类别的分类阶段。数据挖掘中的分类算法有很多,常用的有决策树、基于规则的分类、贝叶斯等[2]。
1.1 决策树分类
20世纪70年代后期和80年代初期J. Ross Quinlan在E.B. Hunt,J. Marin和P. T. Stone的概率学习系统的基础上,提出了迭代的二分器方法即经典的ID3决策树算法[3]。后来,Quinlan又在ID3的基础上进行了改进,提出了C4.5决策树算法,并成为新的监督学习算法的性能比较基准。1984年,多位统计学家出版了著作《Classification and Regression Trees》,介绍了二叉决策树的概念,这标志着CART方法的产生[4]。这两种算法大约同时间出现引发了决策树归纳研究的浪潮。
决策树需要从标有类标号的训练集中训练得到。它是一种树形的结构,类似于流程图,其中内部结点是对某个属性值的判断,每个分枝是该判断的一个输出,而每个树叶结点存放一个类标号,树的最顶层是根结点[5]。
1.2 贝叶斯分类
贝叶斯分类是用来表示类隶属关系的概率大小。贝叶斯分类是基于贝叶斯定理的分类方法。朴素贝叶斯分类的思想:假设D是训练元组的集合。其中每一个元组用一个n维向量X={x1,x2,…xn}来表示,xi表示第i个属性值。X表示该元组在n个属性A1,A2,…An上的测量值;假定有m个类C1,C2,…Cm。给定元组X,分类法将预测在条件X下,该元组属于具有最高后验概率的类的大小。也就是说,朴素贝叶斯分类法预测X属于Ci,当且仅当
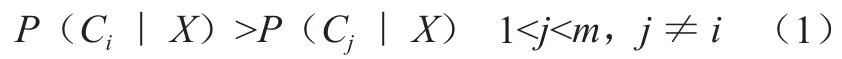
这样,找出使P(Ci|X)最大的类Ci,类Ci即被称作最大后验假设。根据贝叶斯定理
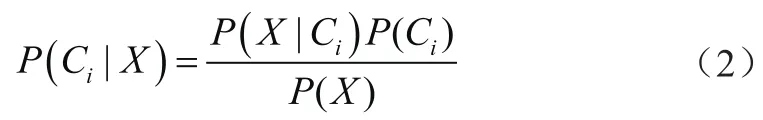
由于P(X)为固定的常数,所以只需要找到一个类Ci,使P(X|Ci)P(Ci)最大即可。
1.3 基于规则的分类
规则是一种表示少量信息和知识的有效方法。基于规则的分类,需要构造一系列的IF-THEN规则,可以用如下形式的表达式来表示:
IF 条件 THEN 结论
其中,IF后边的部分被称为规则前件或简称为前提,THEN后边的部分是规则的结论。在规则前件中,条件可以被分解为一个或者多个用逻辑连接词“与”连接起来的属性表达式,规则的结论部分是对一个类的预测。如果对于一个给定的元组,规则前件中的所有属性表达式都成立,就可以说规则前件成立,并且规则覆盖了该元组。
1.4 基于人工神经网络的分类
神经网络最先由心理学家和神经学家提出,目的是为了找寻开发和检测神经的计算模型。概括的来讲,神经网络是由一组相互连接的输入、输出单元构成,其中每个连接都有一个权重。在神经网络的学习阶段,通过调整连接的权重,使得它能够将输入元组从相应的类标号处输出。由于单元之间存在连接,神经网络学习又被形象的叫做连接者学习[6]。目前应用最广泛的神经网络模型之一BP神经网络,其组成如图1所示。
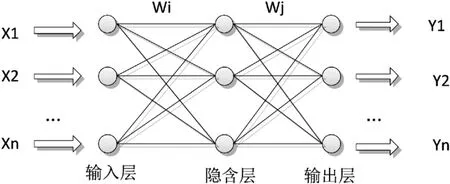
图1 BP神经网络
图1中,BP神经网络包含三层,每层由一些单元组成。每个训练元组的属性值测量对应于网络的输入,这些输入通过输入层,然后加权输送给称作隐含层的神经元,最终由输出层发布给定元组的网络预测。
神经网络的优点是其对噪声的抗干扰能力强,并且不需要知道属性和类之间联系的知识,但是神经网络的训练需要很长的时间,并且需要知道如网络拓扑或结构等的大量参数,而这些参数又主要是靠经验来获得。
2 粗糙集理论
粗糙集理论是由Z.Pawlak 教授在1982年提出的一种数学工具,它主要用于处理不确定性和含糊性的知识,其基本思想是在保证分类能力不降低的前提下,经过对知识的约简,推导出概念的分类规则。它的优点是不需要相关数据集合外的其他先验信息,适合发现那些潜在的和隐含的规则。属性简约作为数据挖掘的一个预处理步骤,也是粗糙集理论的核心应用之一[7]。粗糙集理论的处理思想和算法基础来源于其基本概念定义,下边介绍几个主要的定义。


3 C4.5算法
C4.5决策树算法利用贪心的思想,采用自顶向下递归的分治方法构造得来。大多数的决策树从训练集和其相关联的类标号开始构造,随着树深度的递增,训练集逐渐被划分为较小的子集。
构造决策树的核心是利用分裂准则选择合适的分裂属性来分裂获得子集。如果能找到一个好的分裂准则使所有分枝上的输出元组是纯的,这就是一个最优的分裂准则。
决策树C4.5算法主要步骤分两大部分,分别为属性选择度量和剪枝。
(1)属性选择度量。属性选择度量是一种启发式学习方法,表示选择一种分类准则,可以把指定类标记的训练元组划分为单独类的方法。将该分类准则应用于训练元组,可以把数据分区划分为较小的分区。最优的情况下,落在每一个小分区的所有元组都具有相同的类标号。
属性选择度量为训练元组的属性选择提供了评定标准,具有最高度量值的属性被选为训练元组的分裂属性。具体操作为用选择好的属性度量来标记新创建的树结点,分枝由度量的每个输出生长出来,进而划分元组。常用的属性选择度量有信息增益、信息增益率和基尼指数等,这也是区分ID3,C4.5和CART算法的关键所在。
(2)树剪枝。在创建决策树时,数据中往往存在离群点和噪声,因此造成许多分枝表示的是训练数据中的异常而不是正确的分枝,这种现象叫作过分拟合,剪枝就是处理这种现象的一种有效方法。通常,剪枝使用统计度量来减掉最不可靠的分枝。常用的剪枝方法有先剪枝和后剪枝。在先剪枝方法中,通过提前停止树的构建达到树剪枝的效果。当树构建停止时,结点就变成了树叶。
在采用先剪枝方法构造树的过程中,可以用信息增益、统计显著性、基尼系数等度量来评估划分的优劣。如果选择某个结点划分元组导致低于预定义的阈值,则停止对该结点输出的元组进一步的划分,树的构造因此停止。然而,找出合适的阈值是非常困难的。所以在实际的使用中,后剪枝的方法使用较多。后剪枝方法是在完全生长的树中减去子树。通过删除结点的分枝子树并用子树中最频繁的类来标记该分枝作为树叶来实现。
C4.5就是使用一种称为悲观剪枝的后剪枝方法,使用错误率决定对哪个子树进行剪枝。悲观剪枝不使用剪枝集,所谓剪枝集是指独立于建立未剪枝决策树和用于准确率评估的数据集,而是使用训练集来估算错误率。然而,基于训练集评估准确率过于乐观,因此具有较大的偏倚。所以,悲观剪枝通过加上一个惩罚来调节从训练集得到的错误率以抵消所出现的偏倚。
4 结束语
本文主要简述了客户管理系统中电子银行客户群预测的相关理论方法,包括常用的分类算法如决策树分类,贝叶斯分类,基于规则的分类等,重点介绍了粗糙集理论的相关知识和C4.5的基础知识。这些内容对客户管理系统中客户群的预测的工作起到基础构建的作用。
