Spark环境下SQL优化的方法
2021-08-04杨彦彬干祯辉
杨彦彬,干祯辉
(1.中通服软件科技有限公司,上海 200000;2.杭州东方通信软件技术有限公司,浙江 杭州 310013)
0 引言
随着大数据时代到来,关系型数据结构逐渐被NOSQL所替代。但是,由于传统SQL语法方便易学且普及率高,因此直接废弃难度很大,最终以Hive SQL及Spark SQL为代表的大数据组件也转向支持传统SQL。这些组件提供了SQL解析为分布式运算引擎的功能,但在如何提升执行效率方面则没有更多论述。本文以此为切入点,一方面讨论了SQL迁移后出现的问题原因,另一方面给出了简单实用的解决技巧,以利于在未来生产实践中推广。
1 大数据处理框架Spark概述
Spark是一个日常数据处理框架,它在接受job的时候,内部会对其进行细致划分,分为逻辑执行计划和物理执行。逻辑执行计划是将一个RDD切分成不同的Stage,并产生一系列依赖关系,也就是Task之间窄依赖和宽依赖,其中宽依赖部分形成了Shuffle[1]。大部分Shuffle处后续会切分成多个Stage提交节点后执行Action操作,称之为物理执行。
Spark的Task执行可以分为两种计算形式:流水线性计算和非流水线性计算,前者直接计算完成,有效减少内存空间,典型的是filter()或者map()等操作。而后者则需要借助内存空间完成,典型的是Groupbykey()或者Reducebykey()等操作。因此流水线性计算速度要快于非流水线性计算。图1是Spark整体转换流程[2]。

图1 Spark整体转换流程
2 业务数据迁移带来的问题
Hive SQL及Spark SQL这些组件出现,实现了将收集后的海量数据按照原有业务模型进行计算的可能,但是这个过程中也带来了很多问题,最典型的无疑是数据倾斜。所谓数据倾斜,即海量数据的主键执行一对多关联后由于分配节点计算量不均匀,导致一个节点还在执行计算时候,其他节点已经完成,都在等待该节点结束运行[3]。图2左侧就是数据倾斜的原因图示,明显节点1计算量远大于节点2和3。数据倾斜在实际工作当中的外在表现是某一个Task进度长时间徘徊在99%左右。而在最终结果集WEB UI中明显看到某节点执行时间与其他差异。图2右侧WEB UI中,红框的节点计算时间远大于其他节点。
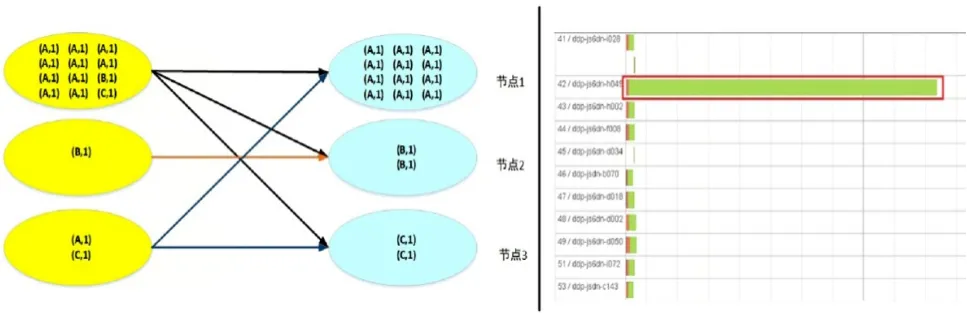
图2 数据倾斜产生原因和表现
3 Spark环境下SQL优化方法
3.1 传统Spark SQL优化方法不足
常规优化SQL手段就是简化其复杂程度,将聚合、分组函数多次拆分,形成若干个简单SQL,以此降低Task之间的join操作,同时单个SQL尽量利用流水线模式加快计算速度。但是该方法对数据倾斜几乎产生不了实质作用,因为简化的SQL的无法解决数据分布不均的问题。
3.2 Spark SQL扩展主键优化
数据倾斜产生的核心原因在于相同的业务主键聚集于一个计算节点,这是分布式计算模型特点所决定的。因此如果能将主键打散,并以打散的主键进行数据关联,通常是首选解决方案。实践当中我们一般将主键按照一定规则编码,形成新主键,并进行关联。图3描述了主键规则编码前后的变化。左侧以10000作为主键,各节点分布不均。右侧则是通过主键编码:分别形成10000-1、10000-2、10000-3,此时任务被均匀分布到各个节点。但是需要指出,该方法也会增加任务分区和Task数量,加大了资源调度难度。因此使用时要进行斟酌[4]。

图3 按规则编码主键前后的变化
另外,某些时候即使采用主键编码也很难解决Spark在最后阶段Reduce过程中的倾斜,因而在此基础上需要配合广播join持续优化。
3.3 Spark SQL广播join优化
广播join的实质在于将较小的表通过Driver端分发到各计算节点,将原来计算方 式,即各个分区计算完成后再与小表进行join操作变化为小表直接在分区join,从而避 免了海量数据主键在最后阶段Reduce过程时一对多出现场景[5]。图4描述了广播join的原理。

图4 广播join的实现原理
典型的广播join用在Hive表,一般能够提前确认表大小,避免广播后出现错误。在非Hive表上则需要通过强制广播join实现,Spark通过broadcast()方法来完成。但是由于Spark无法提前确认分发表大小,在使用该方法的时候,当Driver端内存不足会出现OOM现象。同时过大的表亦不适合广播join方法。因此使用前尽量确认分发表大小。
4 优化前后性能比对
使用前述方法优化之后性能一般有明显提升。图5是优化前后比对图。以1.8亿数据量测试,50 G内存提交。优化前计算用时1 229 585 ms约等于20.5 min,优化后用时877 460 ms约等于14.6 min,相比优化前提速约30%。图5红圈是同一个计算节点,未优化之前明显的数据倾斜,优化之后Task分布更为均匀,数据倾斜也相应消失。

图5 优化前后的对比
5 结束语
随着各类技术的不断研究,相信在不久的将来会出现更多基于大数据的SQL优化方法和手段,为进一步提升大数据计算应用提供了坚实的保证。
