基于机器学习的江苏省冬小麦气象产量客观区划及歉年预测
2021-08-02郝玲张佩史逸民刘瑞翔王伟健朱云凤
郝玲 张佩 史逸民 刘瑞翔 王伟健 朱云凤


摘要:利用江苏省统计局提供的全省75个县(市、区)1981—2018年的冬小麦产量,基于灰色系统滑动模型得到各县(市、区)冬小麦气象产量。采用K-means算法对全省各县(市、区)冬小麦气象产量进行聚类分析,将全省客观划分为南、北2个冬小麦种植区,区域连续且相互独立。通过C4.5决策树算法,基于130项前期春季气候因子对2个种植区的冬小麦气象产量“是否歉年”分别建立决策树预测模型。在北种植区冬小麦是否歉年的预测中,决策树模型的自学习准确率为82.0%,测试准确率为90.9%;在南种植区冬小麦是否歉年的预测中,决策树模型的自学习准确率为92.5%,测试准确率为91.67%。结果表明,K-means算法和C4.5算法对江苏省冬小麦气象产量区划和预测具有良好效果,可为江苏省冬小麦产量预测提供有意义的参考。
关键词:冬小麦;气象产量;种植区划;K-means算法;C4.5算法;决策树预测模型
中图分类号:S162.5+3 文献标志码: A
文章编号:1002-1302(2021)12-0162-06
收稿日期:2020-10-20
基金项目:江苏省第五期“333高层次人才培养工程”项目(编号:BRA2019348)。
作者简介:郝 玲(1983—),女,天津人,硕士,工程师,主要从事应用气象及天气预报技术研究。E-mail:702381568@qq.com。
通信作者:刘瑞翔,硕士,工程师,主要从事气象灾害评估与监测研究。E-mail:261650438@qq.com。
在我国冬小麦是重要的粮食作物,在全國粮食安全中具有重要位置[1]。江苏省位于温带季风气候与亚热带季风气候的南北过渡带上,不同区域的气象条件往往具有较大的差异,对农作物的生长发育往往有着不同的影响[2]。因此,对农作物种植区进行合理的区划具有重要意义。沈宗瀚在1936年便依照我国的气候、土壤条件及小麦生长状况等特点,将全国划分为长江流域、淮河流域、陇海铁路东段、陕西中部、豫鲁北部及燕晋区6个冬小麦种植区[3];根据小麦的冬春习性、籽粒色泽及质地软硬,金善宝于1943年将小麦种植区划分为红皮春麦、硬质冬春混合以及软质红皮冬麦3个区域[4];1961年,金善宝在《中国小麦栽培学》中,依据我国的气候特点,特别是年平均气温、冬季气温、降水量及其分布以及小麦类型、耕作栽培制度、适宜播期和成熟期等因素,将我国的小麦种植区划分为3个主区及10个亚区[5];金善宝在《中国小麦学》中依据地理地域、品种冬春性、籽粒特性以及栽培环境等因素的综合影响对小麦种植区进行区划,将我国小麦种植区分为3个主区10个亚区和29个副区[4];赵广才结合多年小麦栽培技术成果和生产实践经验,在前人研究基础之上对我国小麦进行区划研究,将我国小麦种植区划分为4个主区及10个亚区[3,6]。众多学者基于小麦种植区的气候特点、小麦本身的特性及基于主观的经验对小麦的种植区进行划分。
冬小麦的产量受气候条件、生产技术水平等多种因素影响,其生长条件和环境可以看成是非常复杂的非线性系统,因此其产量是受到不同生长阶段的多种气象要素和生长发育环境等多个影响因子相互作用的共同结果,冬小麦单产的提高主要依靠品种和栽培措施的改进以及对气象条件变化的趋利避害等方面[7]。然而,20世纪80年代以来,全球气温普遍升高,极端天气频发,对冬小麦产量造成了严重的负面影响[8-9]。高苹等基于海温和大气环流特征对江苏省小麦适播期进行了预测研究[10];吴洪颜等建立了基于太平洋海温的冬小麦湿渍害预测模型并发现2个高相关区,即Nino区和西太平洋北部海区[11];随着遥感技术的发展,越来越多的学者利用卫星遥感资料预测冬小麦产量,李卫国等基于遥感信息获取小麦生理过程与气候环境状况建立了简化的小麦估产模型可对不同年份、不同区域的小麦产量形成情况进行监测与预报[12-13]。
大尺度的大气环流系统强度和位置的调整、不同区域海温异常变化往往能够导致大区域甚至全球范围的气候异常,从而间接影响农作物气象产量的丰歉[14]。于彩霞等利用逐月的大尺度气候因子对小麦白粉病进行了效果良好的产期预测研究[15]。尚志云等利用74项大气环流指数基于贝叶斯分类模型对河北省冬小麦白粉病建立了预测模型[16]。姜燕等利用不同膨化时段的74项环流指数距平值对全国小麦条锈病发病面积建立预报模型[17]。也有学者通过模拟全国小麦、玉米等农作物在干旱等恶劣气候环境中的产量评估异常气候对农作物产量的影响[18]。
随着5G互联网浪潮的掀起,大数据、云计算、人工智能等新兴领域蓬勃发展。而数据挖掘技术是人工智能的重要分支领域。国内外越来越多的学者将数据挖掘技术应用于农业方面[19-21]。然而,目前学界对江苏省冬小麦气象产量的客观区划及预测的相关研究相对较少,本研究旨在利用数据挖掘中经典的K-means聚类算法对江苏省冬小麦气象产量建立客观合理的区划模型,再利用前期春季的气候指数集通过C4.5决策树算法对不同冬小麦种植区建立产量歉年的预测模型,为农产品气象产量的区划与预测提供新的思路。
1 材料与方法
本研究利用数据挖掘中经典的K-means聚类算法对江苏省75个县(市、区)的冬小麦气象产量进行聚类分析,通过各县(市、区)冬小麦气象产量数据上的相似程度客观判断各地区所属类别,进而对江苏省冬小麦气象产量进行客观的区划。针对不同区域,利用130项前期春季气候因子,基于数据挖掘中C4.5决策树算法,对各区域冬小麦产量歉年进行预测。
1.1 资料来源
本研究使用的资料来源如下:(1)江苏省统计局提供的全省75个地区1981—2018年冬小麦产量;(2)江苏省气象局提供的全省各站1981—2018年日最高气温、日最低气温、日平均气温、日降水量以及日照时数等气象资料;(3)气候指数来自国家气候中心(NCC)整编的百项气候系统指数集。
冬小麦气象产量的处理:由于科学技术进步和自然条件的变化,农作物的产量可分离为趋势产量、气象产量和随机误差,随机误差可忽略不计。
y=yt+yw+ε。(1)
式中:y为作物产量;yw为气象产量;yt为趋势产量;ε为随机误差。计算趋势产量的方法有多种,本研究采用灰色系统GM(1,1)滑动模型[22]获取。
对于冬小麦的气象产量序列{yw},总样本数为n。通过计算气象产量序列标准差σ,定义当气象产量小于-0.5σ为冬小麦产量歉年。
1.2 方法介绍
1.2.1 K-means聚类算法
K-means算法是数据挖掘中最经典的聚类算法,也是数据挖掘中十大算法之一[23]。聚类即根据相似性为原则对事物进行分类,使得“类内相似,类间相异”。K-means算法采用距离作为相似性指标,从而发现给定数据集中的K个类,且每个类的中心是根据类中所有数值的均值得到的,每个类的中心用聚类中心来描述。K-means不需要任何先验知识,是无监督算法,在人工智能、数据挖掘、机器学习和模式识别领域中均有广泛应用。
K-means算法在本研究中的描述及实现过程如下:
在给定的气象产量数据集yw={x1,x2,…,xn}初始化K个簇C={C1,C2,…,Ck},其最小化损失函数为
E=∑ki=1∑x∈Ci‖x-μi‖2。(2)
其中Ci的中心点:
μi=1|Ci|∑x∈Cix。(3)
在样本中随机选取k个样本充当各个簇的中心点{η1,η2,…,ηk},计算所有样本点与各个簇中心之间的距离,把样本划入最近的簇中。
1.2.2 C4.5算法
决策树技术是一种对海量数据集进行分类的非常有效的方法。通过构造决策树模型,从有目标变量和预测变量的数据集中提取决策规则、模式和知识[24]。机器学习中,决策树是一个预测模型;它代表的是对象属性与对象值之间的一种映射关系。 树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,从根节点到叶节点所经历的路径对应一个判定测试序列。
C4.5算法是一种常用的决策树算法,这种算法通过特殊处理方式可以恰当地选择每个节点上的属性变量[25]。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。这一算法的理论基础是信息论中熵的概念,目标是找到保持分类最小差异性所需最低限度的信息[26]。令S为包括s个数据样本的训练集,S(Ci)为S中属于Ci类的样本个数(i=1,2,…,m)。此时训练集S的信息(熵)定义为
info(S)=∑mi=1S(Ci)slog2S(Ci)s。(4)
接着,需要通过属性A将信息S分为{S1,S2,…,SV}(属性A所包含不同值的数目为v)。
info(A|S)=∑Vj=1SjSinfo(S)。(5)
增益计算如下:
gainratio(A|S)=gain(A|S)info(A|S)。(6)
其中
gain(A|S)=info(S)-info(A|S)。(7)
与其他分类算法相比,决策树算法(以C4.5算法为例)具有以下优点:决策树是一种自解释的模型,并且可以抽象出决策规则方便执行;该模型可以同时处理离散和连续型变量;对数据中的缺失值不敏感。
2 基于K-means算法的江苏省冬小麦气象产量的区域划分
江蘇省位于我国东部沿海,受季风影响,冬夏较长,春秋偏短,地跨南北气候带,全省年平均气温均自南向北递减。江苏省南部和北部的季节起止时间也有明显差异,一般苏南地区和淮北地区相差1周左右。降水量的分布也存在南多北少,内陆少于沿海的特征,江苏省不同区域具备的气候特点不尽相同。为了更加客观地反映冬小麦产量的气象区划,本研究利用江苏省75个地区的冬小麦气象产量数据本身的相似程度,基于K-means聚类算法建立全省冬小麦气象产量的区划模型。
利用1981—2018年各地冬小麦产量,通过上文所述的灰色系统滑动模型获得各县(市、区)每年气象产量,将全省气象产量数据集输入K-means算法,利用轮廓系数来确定聚类数,选择轮廓系数较大的k值[23]。
为了简洁地划分江苏省冬小麦种植区,通过从2~5比较K值的轮廓系数,轮廓系数越接近1聚类效果越好,当k=2时轮廓系数达到0.5,聚类的效果达到最佳(图1)。 因此笔者所在课题组将聚类数K定为2。
通过K-means算法聚类后,制作出江苏省冬小麦气象产量区划(图2)。可以看出,2个冬小麦种植区南北分布,北种植区面积较南冬小麦种植区更大,北种植区包含全省75个县(市、区)中的47个县(市、区),占63%。南冬小麦种植区包含全省75个县(市、区)中的28个,占37%。
通过统计江苏省冬小麦北南种植区的气象产量(图3),可以发现北种植区与南种植区冬小麦气象产量的整体趋势是近似的,不同的是南种植区的气象产量随时间变化的幅度较北种植区更大,说明北种植区气象条件对于冬小麦产量而言更加稳定可靠。另外,在个别时间段存在反位相的情况,如1986—1988年。
综上所述,江苏省冬小麦气象产量区划区域具有连续性,不同种植区的产量具有相似的变化趋势的同时具备一定的差异性,这样的特点为本研究建立不同种植区冬小麦气象产量的预测模型建立了良好的研究基础。
3 基于C4.5决策树算法的江苏省不同种植区冬小麦气象产量是否歉年的预测模型
3.1 试验数据的预处理
本研究使用C4.5决策树算法,将试验数据分割为关系互斥的训练集和测试集2个部分。训练集约占总样本数的80%,测试集约占20%。训练集用于建立决策树模型,测试集用于检测模型的泛化能力。笔者所在课题组将气象产量不足-0.5倍标准差的年份定义为冬小麦的气象产量歉年,即当北种植区气象产量不足-2.50 kg/hm2,南种植区气象产量不足-4.15 kg/hm2时分别为北种植区和南种植区的冬小麦气象产量歉年。笔者所在课题组将江苏省冬小麦气象产量的预测抽象成北种植区和南种植区冬小麦气象产量“是否歉年”的二元分类问题。通过统计,在1981—2018年的38年中,北种植区有8个年份为冬小麦气象产量歉年,南种植区有12个冬小麦气象产量歉年,较北种植区更多(表1)。
为了尽可能不影响数据的原有分布状况,本研究利用等距离抽样的方式分离模型的训练集和测试集数据样本(图4),以5年为1个步长抽取1个样本作为模型的测试集,剩余的数据样本作为模型的训练集。因此,训练集中共有31个年份,其中北种植区有6个年份为歉年,南种植区有11个年份为歉年;测试集中共有7个年份,其中北种植区有2个年份为歉年,南种植区有1个年份为歉年。
为了维持目标属性“是否歉年”与否样本量间的平衡以及模型学习和测试准确率更加客观,本研究对训练集和测试集中的歉年样本分别进行有放回的抽样,目的是在不丢失数据特征的情况下使得歉年样本和非歉年样本在数量层面达到平衡(表2)。根据气候系统指数集中的各项指数春季数值(3—5月),得到春季的130项气候信号指数平均数据集。通过上述处理得到建模所需的训练集与测试集,为建立江苏省冬小麦气象产量歉年预测模型做好数据层面的准备工作。
3.2 预测模型的构建与检验
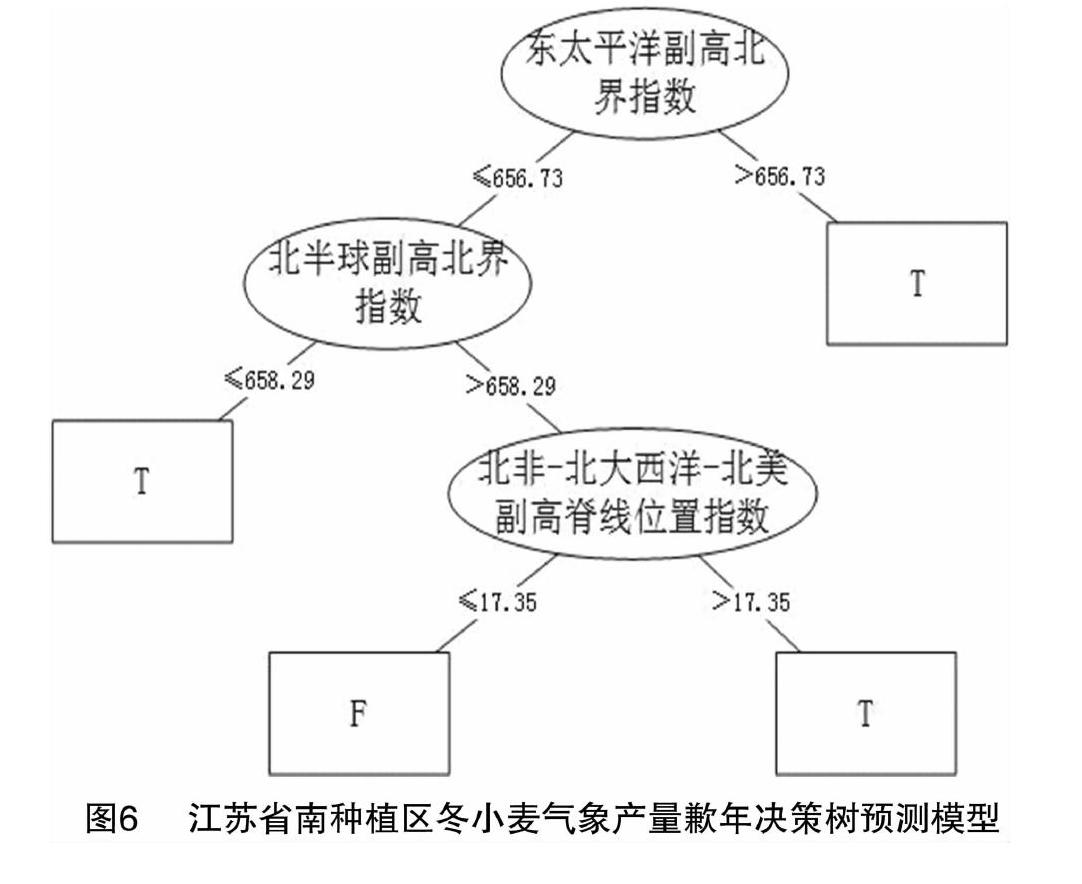
以江苏省北、南2个种植区的冬小麦气象产量是否发生歉年为目标变量,模型的输入变量为130项当年春季气候信号指数。将预处理好的训练集数据输入C4.5算法得到北、南种植区冬小麦气象产量是否歉年决策树预测模型(图5、图6)。为了保证模型不过拟合,笔者所在课题组通过设定叶节点样本数量来控制决策树的深度,本研究设定样本数量约为总样本数的15%左右。该模型中判别江苏省冬小麦北种植区气象产量是否歉年的关键因子为春季北半球极涡中心经向位置指数,而预测南种植区气象产量是否歉年的重要判别依据为东太平洋副高北界指数。
北种植区冬小麦气象产量歉年预测模型的学习准确率为82.0%,通过测试集对模型进行检验,准确率达到90.9%;南种植区冬小麦气象产量歉年预测模型的学习准确率为92.5%,通过测试集对模型进行检验,测试准确率达到91.7%(表3)。从决策树可以看出,北种植区的小麦气象产量歉年更容易受到极涡及太平洋中东部海温异常的影响, 而南种植区的小麦气象产量歉年更容易受到副热带高压系统位置变化的影响。决策树模型对江苏省不同种植区冬小麦气象产量是否歉年的预测提供了一种新的预测手段和参考依据。
决策树简单直观且易于理解,通过决策树每个分支,即从根节点到叶节点(T/F)可以抽象出一条If…then…的规则,决策树中具有上述特征的规则形成决策规则集[27](表4、表5)。
4 结论与讨论
冬小麦是江苏省重要的粮食作物,其产量丰歉关系到社会稳定、国家安全等重要領域。本研究利用机器学习技术中经典的K-means聚类算法对江苏省冬小麦种植区进行合理、客观的划分,进而对不同种植区冬小麦气象产量是否歉年建立基于C4.5算法的决策树预测模型,预测效果较好,并得
到以下结论:
(1)通过K-means算法对江苏省各地冬小麦气象产量数据的相似程度进行判别,基于“类内相似,类间相异”的原则将江苏省冬小麦种植区划分为北、南种植区,2个种植区各自完整、连续且相互独立,实现了客观、合理的区划目的。
(2)江苏省南、北2个种植区小麦气象产量的变化趋势类似,但北种植区气象产量随时间变化较南种植区更加稳定。可见北种植区和南种植区冬小麦气象产量既有联系也有差异。
(3)通过对南北种植区冬小麦气象产量是否歉年分别建立C4.5决策树预测模型,北种植区决策树模型的学习准确率为82.0%,测试准确率为90.9%;南种植区决策树模型的学习准确率为92.5%,测试准确率为91.7%。
(4)从北种植区和南种植区冬小麦气象产量是否歉年的决策树模型中可以看出,影响北种植区的气候因子主要是春季极涡系统位置的变化以及赤道中东太平洋区域的海温异常;影响南种植区的气候因子主要是全球副热带高压系统的位置变化。
随着大数据时代的不断推进,计算硬件与计算智能的不断加强深化,数据挖掘技术在农业生产中也得到越来越广泛的应用。本研究利用机器学习技术分别对江苏省冬小麦种植区进行客观区划以及对不同种植区的气象产量歉年建立有效的预测模型,为江苏省冬小麦产量的预测提供了有意义的参考。然而,由于机器学习方法相比于传统的数学统计方法对数据样本数量的要求更大,计算设备计算速度的要求更高,需要对比更多更复杂的训练策略并择优选取,可以相信,随着数据样本的不断积累,训练策略和参数的不断优化,在预测的准确率上还有较大的提升空间。
参考文献:
[1]高 苹,居为民,陈 宁,等. 人工神经网络方法在赤霉病预报中的应用研究[J]. 中国农业气象,2001,22(2):22-25.
[2]吴洪颜,高 苹,徐为根,等. 江苏省冬小麦湿渍害的风险区划[J]. 生态学报,2012,32(6):1871-1879.
[3]赵广才. 中国小麦种植区划研究(一)[J]. 麦类作物学报,2010,30(5):886-895.
[4]金善宝. 中国小麦学[M]. 北京:中国农业出版社,1996.
[5]金善宝. 中国小麦栽培学[M]. 北京:农业出版社,1961.
[6]赵广才. 中国小麦种植区划研究(二)[J]. 麦类作物学报,2010,30(6):1140-1147.
[7]徐 敏,徐经纬,高 苹,等. 不同统计模型在冬小麦产量预报中的预报能力评估——以江苏麦区为例[J]. 中国生态农业学报,2020,28(3):438-447.
[8]丁一汇,戴晓苏. 中国近百年来的温度变化[J]. 气象,1994(12):19-26.
[9]任国玉,郭 军,徐铭志,等. 近50年中国地面气候变化基本特征[J]. 气象学报,2005(6):942-956.
[10]高 苹,张 佩,谢小萍,等. 基于海温和环流特征量的江苏省小麦适播期预测[J]. 气象,2012,38(12):1572-1578.
[11]吴洪颜,高 苹,刘 梅. 基于太平洋海温的冬小麦春季湿渍害预测模型[J]. 地理研究,2013,32(8):1421-1429.
[12]李卫国,王纪华,赵春江,等. 基于遥感信息和产量形成过程的小麦估产模型[C]//中国气象学会. 2007年中国气象年会论文集. 北京,2007:582,586.
[13]李卫国,赵春江,王纪华,等. 遥感和生长模型相结合的小麦长势监测研究现状与展望[J]. 国土资源遥感,2007(2):6-9.
[14]徐 敏,徐经纬,高 苹,等. 基于海温和大气环流特征量的农业气候年景预测[J]. 江苏农业科学,2016,44(9):435-439.
[15]于彩霞,霍治国,黄大鹏,等. 基于大尺度因子的小麥白粉病长期预测模型[J]. 生态学杂志,2015,34(3):703-711.
[16]尚志云,姚树然,王锡平,等. 基于大气环流特征量的河北省冬小麦白粉病预报模型[J]. 中国农业气象,2014,35(6):669-674.
[17]姜 燕,霍治国,李世奎,等. 全国小麦条锈病长期预报模型比较研究[J]. 自然灾害学报,2006,15(6):109-113.
[18]曹 阳. 1961—2010年潜在干旱对中国玉米、小麦产量影响的模拟[D]. 北京:中国农业科学院,2014.
[19]时 雷. 基于物联网的小麦生长环境数据采集与数据挖掘技术研究[D]. 郑州:河南农业大学,2013.
[20]杨凌雯. 基于数据挖掘的智慧农业生产系统的研究[D]. 杭州:浙江理工大学,2016.
[21]张晴晴. 决策树及支持向量机回归算法在麦蚜发生程度预测中的应用[D]. 泰安:山东农业大学,2016.
[22]汤志成,高 苹. 江苏省单季晚稻产量预报的分段加权动态模式[J]. 气象,1989,15(11):30-34.
[23]Wong M A,Hartigan J A. Algorithm as 136:a K-means clustering algorithm[J]. Journal of the Royal Statistical Society,1979,28(1):100-108.
[24]史达伟,耿焕同,吉 辰,等. 基于C4.5决策树算法的道路结冰预报模型构建及应用[J]. 气象科学,2015,35(2):204-209.
[25]Friedl M A,Brodley C E. Decision tree classification of land cover from remotely sensed data[J]. Remote Sensing of Environment,1997,61(3):399-409.
[26]Han J,Kamber M,Pei J. Data mining:concepts and techniques[M]. Amsterdam:Elsevier,2006.
[27]史达伟,李 超,周 灏,等. 基于春季气候信号的“台风是否经过江苏”预测研究[J]. 气象科学,2020,40(1):130-135.
