多变量时间序列聚类综述
2021-08-02杨秋颖翁小清
杨秋颖,翁小清
(河北经贸大学 信息技术学院,河北 石家庄 050061)
0 引 言
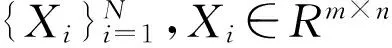
MTS在心理学、经济学、商业、金融等社会人文科学以及工程、质量控制、监测和安全等领域是一种非常普遍的数据类型。MTS的主要特征为:第一,MTS含有时间和变量两个维度,且属性变量间可能存在相关和冗余[1];第二,不同的MTS样本的长度或取样频率可能不一定相同[2]。MTS的高维性和高冗余性使得传统的聚类方法有时无法直接用于此类数据类型。
聚类是一个把数据对象划分成子集的过程,每一个子集是一个簇,使得簇中对象彼此相似,但与其他簇中的对象不相似[3]。MTS聚类面临以下两个挑战[4]:
(1)高维度。MTS在时间维度的基础上增加了变量维度,使得特征的数量越来越高,确定对MTS聚类有重大贡献的显著特征,以及减少表现为虚假特征的滋扰的影响是MTS聚类的一项重大挑战。
(2)隐含特征。MTS可能存在一些隐藏的特征,这些特征可能不明显,因此在直接的数据分析中被忽略。这些隐含特征是给定数据集中的外生因素或内生因素。传统的机器学习技术在捕捉这些存在但隐藏的特征方面效果较差。因此,在为集群解决方案建模时,需要更先进和严格的方法来考虑这些可能的特性。
本文从基于实例、基于特征和基于模型的角度,对近年来MTS聚类方法的研究进行归类,并简要介绍其在实际中的应用。
1 基于实例的方法(Instance-based)
基于实例的时间序列聚类是指,对未经过任何处理的时间序列直接应用聚类算法实现聚类[5]。大多是把对传统数据的聚类算法应用到了时间序列数据上。
Spiegel等[6]提出了一种基于SVD的自底向上算法来识别内部均匀的时间序列段。为了识别重复模式,将获得的时间序列子段采用层次聚类方法进行分组,提出的自底向上分割算法在自动确定模型秩和合并阈值等特征上扩展了传感器融合算法。评估表明,所提出的自下而上(BU)方法优于直接的临界点(CP)分割。Spiegel等[7-8]提出了一种基于递归图的距离(RecuRRence plot-based,RRR),该距离可以度量两个多变量时间序列之间的相似性,与使用DTW进行聚类识别出的原型序列相比,能够覆盖更多的重复出现的模式。
Li[9]使用DTW构建多元时间序列数据相似性矩阵和分量属性序列相似性矩阵,利用近邻传播(Affinity Propagation, AP)聚类算法对这些相似性矩阵进行聚类分析进而获得各种维度视角下的多元时间序列数据关系矩阵,使用Cosim函数对合并的关系矩阵进行相似性度量获得一个相似性矩阵,再次使用PA算法对相似性矩阵进行聚类分析,获得最终的数据类标签。数值实验结果表明,与传统聚类方法相比,所提出方法不仅能够有效地反映总体数据特征之间的关系,而且通过重要分量属性序列之间的关联关系分析能够提高原始时间序列数据的聚类效果。但该方法使用了多次AP聚类过程,其时间性能取决于AP聚类的收敛性,通常需要较高的计算时间代价。Attila等[10]以实际应用背景为基础,引入一种新的交叉相关(Cross-correlation)的相似性度量方法和基于图的聚类技术。首先定义两个样本间的相似性以及属性间的相似性,在样本间相似性的基础上,提出基于图的聚类方法和降维方法,实验表明该方法在噪声容忍中表现更好。Li[11]受传统K-means算法的启发,在聚类中心的选取上使用CPCA代替传统的均值法,在距离度量上使用数据在子空间上的重构误差代替欧氏距离,在拥有K-means算法的线性时间复杂度的基础上,考虑了原始数据值的分布以及变量间关系。
Singhal等[12-13]将主成分分析中的主成分空间间的角度度量、数据集间的马氏距离,以及数据中的附加特性的欧式距离进行加权平均组合,作为传统K-means算法中的距离度量,提出一种新的多变量时间序列数据聚类方法。此外考虑K-means算法中聚类个数K是个超参数,提出一种新的确定最佳簇数的方法。
核K-均值聚类方法需要输入聚类个数,不能处理异常值或噪声,Chandrakala等[14]提出了一种在核特征空间基于密度的聚类方法,可以聚类变长度的MTS样本,不需要输入聚类个数,且性能优于光谱聚类以及核K-means聚类。Edmond 等[15]为了将不同的时间序列按照底层数据结构进行分组,提出了一种基于独立分量分析的时间序列数据聚类算法。
基于实例的方法使用MTS样本的全部信息,避免了特征的丢失;但MTS具有高维性和高冗余性,过多的信息可能导致内存压力大、距离度量的计算量大且不稳定以及过多的信息使特征表达不准确等问题。基于实例的MTS聚类方法特性的比较如表1所示。
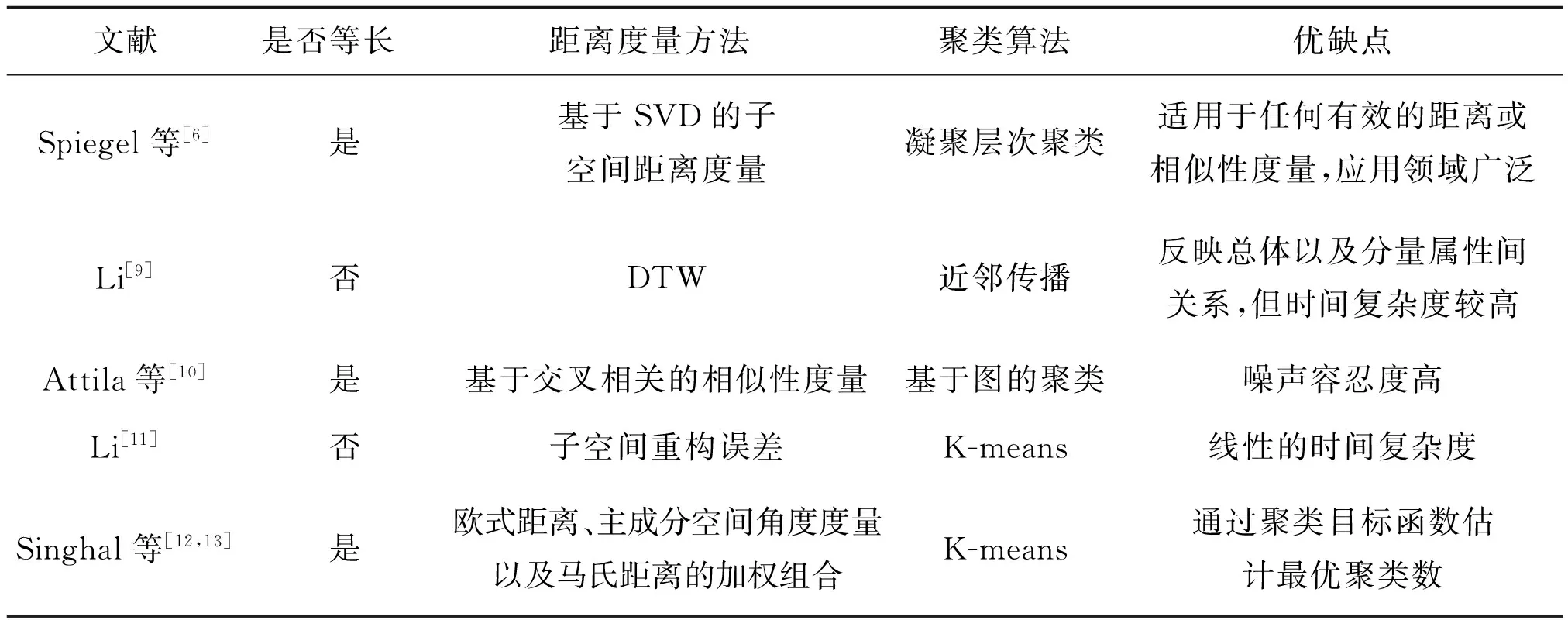
表1 基于实例的MTS聚类方法特性的比较
2 基于特征的方法(Feature-based)
基于特征的时间序列聚类是指将时间序列数据经过变换或映射提取特征,实现维数约简,最后再结合其它聚类算法实现聚类。在基于特征的时间序列聚类中,按照时间序列特征的分类,可以将基于特征的时间序列聚类分成三类,即基于形状、结构和模型的时间序列聚类。基于形状的方法根据原始时间序列的波动形状提取特征,其性能可能会受到噪声、振幅缩放、偏移平移、纵向缩放、线性漂移和不连续[1]等问题的影响;基于结构特征的聚类主要是从数据的结构特征出发,揭示时间序列潜在的规律。基于模型特征的聚类是指按照不同的要求或目的,找到相对应的模型,然后根据模型特征将样本分到不同的组中。
小波技术具有保持时间和频率信息的能力,在非平稳信号处理中表现良好,是一种适用于时间序列数据处理和监测以及统计过程控制的潜在工具[16]。DUrso等[17]首先在若干个尺度上将MTS样本每个变量分解为小波序列,然后在每个尺度上计算小波的方差、MTS任何两个变量之间小波系数的相关度,最后在每个尺度上将小波的方差以及小波系数之间的相关度连接成一个向量,用这个向量代表MTS样本进行硬和模糊聚类(Crisp and fuzzy clustering)。Barragan等[16]使用基于连续小波变换(CWT)的多尺度PCA相似性因子计算MTS样本之间的距离,对MTS样本进行模糊聚类,并将该方法用于Tennessee Eastman Process(TEP)数据集。
此外,考虑MTS具有基于变量和基于时间的维度,Li[18]使用中心序列表示MTS,用分段聚合近似和符号化进一步表示由中心序列导出的扩展序列;Wang等[19]将时间序列的每个变量看成单变量时间序列提取其统计特征组成新的向量;Li[20]计算任意两个变量之间的协方差用于表示MTS;Fontes等[21]将改进的PCA相似度因子和基于均值的欧氏距离(AED)结合在模糊聚类方法中,使用主成分方向和均值的加权和来比较不同的MTS,并将其用于燃气涡轮机的故障分析。Li等[1]提出了一种基于动态时间扭曲(DTW)和形状距离(SDB)两种距离测量方法的特征加权聚类方法。该聚类算法分为四个阶段。首先,使用快速搜索和寻找密度峰值(DPC)的聚类方法选择聚类中心。然后,考虑多元时间序列的整体匹配,对所有变量进行DTW生成模糊隶属度矩阵。然后利用SBD测量各维间的距离并构造多个模糊隶属度矩阵,重新考虑各独立维的贡献。最后,利用传统的模糊聚类算法模糊C-means对模糊隶属度矩阵进行聚类并生成聚类结果。
考虑之前算法均是将多变量数据矩阵变成向量进行处理,He等[22]提出一种保持数据矩阵结构的基于空间加权距离的模糊聚类(SWMDFC)算法。算法使用变元的PCA算法,对同一变量的所有样本构造特征向量组成单变量时间序列使用PCA实现变量降维。对降维后的变量还原为多变量时间序列,使用空间加权距离计算矩阵相似性,最终使用模糊聚类划分样本类别。郑诚[23]将MTS每个时刻的值放入矩形网格中用二维离散余弦变换DCT来对矩形网格提取特征得到特征矩阵,又将每个时刻间的矩阵变换看作向量,从而用高维空间的线段序列来表示多变量时间序列,提出了 LS 相似度来计算线段序列之间的相似程度,最后采用层次聚类来发现其中的模式并找出其中的离群点。Zhou等[24,25]将MTS数据集转化为一个多关系网络,提出了一种基于多重非负矩阵因子分解(MNMF)的多关系社区检测算法,用于MTS聚类;多关系网络描述了MTS样本之间的局部以及全局关系,MNMF充分考虑MTS样本内部变量之间的复杂关系。Liang等[26]专注于处理高维多元时间序列,将传感器网络在一个时间步长的输出数据表示为一个图像,并用图像的BSF特征(Bipolar Sigmoid Feature)来表征图像内容即传感器网络的状态,从而将时间序列转化为高维特征空间中的轨迹,引入链相似性来度量时间序列的相似性并采用层次聚类方法来探索MTS的模式。
copulas是内含随机变量之间依赖结构的分布,Marti等[27]提出的MTS聚类方法,使用Earth Mover's Distance度量MTS样本内部依赖之间的相似程度,使用Dependence Coefficient度量MTS样本相互依赖关系的相似程度对MTS样本进行聚类,比较这三种距离的优缺点。处理MTS中的不可见类的描述和识别方法是具有挑战性的问题,Hosseini等[28]提出一个无监督学习的框架,实现对MTS数据集中不可见类的可解释分析。它基于一种新的多核字典结构(MKD),使用带标签的MTS维的核表示来学习语义属性。基于这些属性,无监督MKD-SC框架根据特征空间中未见类的维数与已见类别维数的关系(部分/全部)重新构造特征空间中未见类,从而为新数据提供可解释的描述。在得到稀疏编码的基础上,提出了一种增量聚类方法来逐步将新的MTS分类为不同的聚类。
基于特征的方法,可以在清楚的表达特征的同时实现维数约简;但上述大多数方法没有清晰考虑MTS的时间和变量属性,本质上MTS样本是二维数据。图1是基于特征的MTS聚类方法的梳理。

图1 基于特征的MTS聚类方法的梳理
3 基于模型的方法(Model-based)
基于模型的时间序列聚类是指,先对时间序列建立模型,然后利用模型的参数、系数、误差等模型信息对时间序列数据进行聚类,得到聚类结果;或者将原始时间序列进行离散化,然后建立模型,提取模型参数,再进行聚类。时间序列数据挖掘可使用的模型有很多,如人工神经网络、隐马尔科夫、高斯混合等经典模型。
Vaquez等[29]对MTS的变量进行聚类,首先使用递归神经网络(Recurrent Neural Networks)和迁移学习(transfer learning)计算每个MTS样本变量之间的相似度,得到每个MTS样本的邻接矩阵,将这些邻接矩阵聚合为一个总的邻接矩阵,然后对变量进行分组。Vazquez等[30]对先前的工作[29]进行了改进,先使用样条曲线对MTS进行光滑处理,然后再对MTS建立递归神经网络模型。Dino等[31]为了处理来自不同领域的变长多变量时间序列,提出一种新的方法DeTSEC。DeTSEC分为两个阶段,首先学习基于门控循环单元网络(Gated Recurrent Unit, GRU)的加入注意力机制的自动编码器,旨在初步完成数据的嵌入表示;随后在聚类改进阶段向对应的类延伸嵌入流行。
基于监督学习的深度学习算法可以学习数据的隐藏特征从而为聚类问题建立更准确的模型。但现实中的时间序列大部分是无标签的,因此基于监督学习的深度学习算法无法直接用于时间序列聚类。为此,Tavakol等[32]首先提取多变量时间序列的特征用于传统的K-means聚类以获得数据的标签,从而将问题从无监督学习转化为有监督学习;其次,建立基于自动编码器的深度学习模型,学习时间序列数据的已知特征和隐藏特征及其创建的标签,预测未知的时间序列数据的标签。
Sidart Deb[33]提出了基于向量自回归(vector auto-regressive, VAR)模型估计的参数向量来识别多变量时间序列样本对或样本组的相似性的检验程序。该程序同时适用聚类个数已知和未知的情况,因此可以广泛用于现实中的各种问题。Zhou等[34]提出的可以处理不等长、离散值的基于模型的MTS聚类算法包括以下三步:首先将时间序列离散化;然后发现时态模式,用置信值表示不同变量之间的关系,最后,使用模式的置信值对MTS样本聚类。
用MTS子序列聚类,可以从时态数据中发现重复模式。Hallac等[35]提出了一种基于Toeplitz逆协方差的MTS子序列的聚类方法(TICC),同时对数据进行分段和聚类,根据子序列的相关结构对其进行聚类,并通过多层马尔可夫随机场(Markov random field,MRF)对每个子序列进行重构,为了发现这些簇,TICC通过动态规划和ADMM来更新簇的MRFs.针对既有名词性变量又有数值型变量的MTS,Ghassempour等[36]提出了一种基于HMMs的聚类方法,首先将每个时间序列映射为一个HMM,然后,定义一个合适的度量,计算HMMs之间的距离;最后,基于距离矩阵对HMMs进行聚类。
Li等[37]提出一种基于模型的自适应状态连续稀疏逆协方差(ASCSICC)聚类算法。引入状态连续性,使传统的高斯混合模型(GMM)适用于时间序列聚类。为了防止过拟合,采用乘子交替方向法优化GMM逆协方差的参数。此外,该方法同时对时间序列进行分段和聚类。在技术上,首先根据相邻时间序列数据的距离相似度估计自适应状态连续性。然后,以自适应状态连续性的动态规划算法为e步,以求解稀疏逆协方差的ADMM为m步。将E-step和M-step组合成期望最大化(EM)算法进行聚类处理。Mikalsen等[38]针对缺失数据的多元时间序列,提出时间序列聚类核方法(TCK),利用改进的信息先验分布对角协方差GMM模型处理MTS缺失值,利用集成学习方法结合多个GMM的聚类结果形成最终的核,以确保对参数的鲁棒性。TCK可以作为许多不同的学习算法的输入,特别是在核方法中。实验结果表明,TCK对超参数设置具有较强的鲁棒性,对无缺失数据的预测任务具有较强的鲁棒性,对有缺失数据的预测任务具有较好的鲁棒性。
基于模型的方法中,建模过程需要消耗一定时间且使用模型参数进行聚类,模型的不确定性对聚类效果有一定影响。图2是基于模型的MTS聚类方法的梳理。

图2 基于模型的MTS聚类方法的梳理
4 多变量时间序列聚类的应用
多变量时间序列聚类广泛应用于金融商业等社会人文科学以及医疗、工程、监测、人体模式识别和地球物理分析等领域。
Dai C等[39]针对未标记EEG时间序列聚类问题,提出了一种新的EEG聚类算法将脑电聚类映射到改进的Frechet相似性加权脑电图的最大权值团搜索。考虑脑电图中顶点和边的权重,并根据顶点和边的相似权值对脑电图进行聚类。
Zhang等[40]首先利用离散小波变换获取每对变量之间的小波方差和相关系数,实现多元时间序列的初始聚类,将相关性相似但形状相反的时间序列分配到同一聚类中;然后通过符号聚合近似(SAX)方法,基于形状对多元时间序列进行聚类;最后将这既考虑相关性又考虑形状的两阶段多元时间序列聚类算法用于北京IC卡客流量数据分析。
为了有效地对金融MTS数据进行聚类,Zhou等[41]首先利用局部线性嵌入算法将原始时间序列数据进行降维处理,然后对提取的特征向量采用改进的kmeans算法进行聚类。
聚类分析能作为独立的工具来获得数据分布的情况,还可以作为其他算法的预处理步骤,简化计算量,提高分析效率。Kamal等[42]将模糊聚类与遗传算法相结合,模糊聚类算法根据历史数据对每个聚类的隶属度对其进行模糊化,然后利用这些隶属度对结果进行去模糊化。此外,遗传算法负责选择适当的模型,将其应用于交通事故伤亡人数和著名大学招生数据集的预测。Abonyi等[43]提出了一种用于同时识别局部概率主成分分析(PPCA)模型的聚类算法并将其用于视频监控。其中,PPCA模型用于度量分段的同质性,模糊集用于表示分段的时间,聚类相容性准则的模糊决策算法来确定所需分段数,而所需主成分数则由模糊协方差矩阵特征值的横截面图来确定。该算法在时间上倾向于连续聚类,并能检测出多元时间序列隐藏结构的变化。Chen等[44]提出一种新的自动聚类算法来生成不同长度的语篇区间,并将其用于加权指数(TAIEX)的预测。
此外,Malik等[45]使用不同的MTS聚类方法对比分析人体平衡控制的四种模式,试图寻找其关联关系。Salvo等[46]提出了一种基于动态时间序列分割和自组织映射技术的地球物理多元时间序列聚类方法。
5 总 结
本文从基于实例、基于特征和基于模型三个方面,对MTS聚类方法进行了综述,并简要介绍其在现实中的应用。MTS聚类研究目前已经有了很大的进展,但仍存在很多问题需要解决。例如,MTS的聚类研究主要集中在相似性度量、维数约简以及聚类原型的研究,其中度量的稳定性,如何从两个维度进行维数约减进一步提高聚类效果值得进一步研究;此外,深度学习方法的出现极大的提高了MTS的聚类效果,但许多深度学习方法无法直接处理无标签数据,将深度学习应用于MTS聚类也值得今后进一步研究。
