基于SRP-PHAT 的实时声源定位算法设计与实现
2021-08-02刘生
刘 生
(南京熊猫电子装备有限公司,江苏南京 210046)
0 引言
近年来,随着人工智能及交互技术的发展,越来越多智能设备可以实现人机对话。为了提高自动语音识别率,业内通常使用波束形成技术进行定向收音,获得了较好的收音效果[1]。针对一些如智能音箱、机器人等智能对话设备,为了实现全向的高效收音,通常会在对话开始时利用声源定位技术获得声音的方向,并将其作为参数传给后续的波束形成部分进行处理。
常用的声源定位算法主要有基于最大可控响应功率的波束形成方法、基于高分辨率谱估计的方法与基于时延估计的定位方法[2-4]。基于相位变换加权的可控波束响应功率(Steered Response Power-Phase Transform,SRP-PHAT)声源定位算法由于具有较强的鲁棒性,可实现真实环境中的声源定位,因此也得到了广泛应用[5-6]。由于算法运算量较大,在嵌入式系统中,为提高算法的实时性,一般使用FPGA 或专用CMOS 芯片进行算法实现[7-8]。在智能语义交互产品中,目前的主流技术是使用Linux 或Android 系统进行网络通信,连接语音对话服务器,实现语义识别、语义处理及语音合成。这部分功能需要使用通用ARM 处理器进行实现,如果使用FPGA 或专用CMOS 芯片实现语音定位及前端语音处理部分功能,势必会提高产品复杂度,成本也会随之升高。本文基于ARM 平台处理器,使用Python 及C++语言对算法进行设计与实现。将原来利用专用芯片实现的前端语音功能在嵌入式ARM 平台上重新进行设计与实现,对产品集成度进行了提升。
1 SPR-PHAT 算法原理
对空间中特定位置或方向信号进行定向增强的技术是阵列信号处理中的一项关键技术。这些技术大多基于波束形成理论,主要通过麦克风阵列捕捉声音并进行相关信号处理。传统意义上的波束形成可通过滤波求和处理,在对麦克风信号求和以产生定向信号聚焦之前,会在时域对麦克风信号进行滤波。滤波器通常会在波束形成过程中进行动态调整,以增强所需的信号源,同时衰减其他信号源。一种最简单的对信号进行滤波处理的方法就是对源信号进行时间偏移,该偏移值为各个阵列间的信号传播延迟,这种方法被称为延迟求和(Delay-and-Sum)波束形成[9-10]。通过延迟麦克风信号,将各通道的源信号在时间上对准,之后对所有通道的源信号进行求和。应用更复杂滤波求和技术的滤波器以及其他信号增强处理算法通常都是基于这种时间对准方法。
波束形成技术在麦克风阵列中得到了广泛应用[11-13]。对于这种应用,滤波求和技术不仅需要抑制背景噪声以及不需要的信号,同时还必须保证想要的信号通过滤波器后不能失真。当将波束形成技术应用于声源定位时,这些滤波器只需在完成波束形成运算后,对特定方向的信号进行功率增强即可。本文使用的PHAT 算法正是利用了该特性,使用可控波束响应功率算法对所有可能的相位变换进行求和运算。SRP-PHAT 可直接对多路麦克风信号进行变换处理,利用多个麦克风提高位置估计的准确性。
SRP 可以使用块处理方案加以实现,该方案使用短时数字傅里叶变换作为麦克风信号频谱的估计[14-15]。将阵列信号在时域上分割成多个块,并计算每个块的转向响应。信号块的数字傅里叶用Xm,b[k]表示,其中m 是麦克风索引,b 是块索引,Gm,b[k]是麦克风m 离散时间滤波器的傅里叶变换,会在每个块b 中单独进行计算。块b 的转向响应可定义如下:
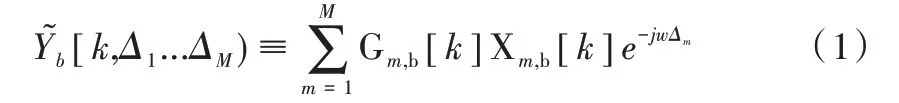
[k,Δ1...ΔM)是索引为k 的离散频率函数和连续的转向延迟(Δ1...ΔM表示阵列所有连续的转向延迟)。理论上需要对信号中所有频率段的数据进行处理,但在实际使用过程中,一般会选择一个或多个频率段的数据进行处理。同时,尽管M 个转向延迟是连续的,但在实际使用过程中,会在预定义的一组空间位置或方向进行采样,并通过对K 个离散频率进行求和,从而获得转向响应功率:
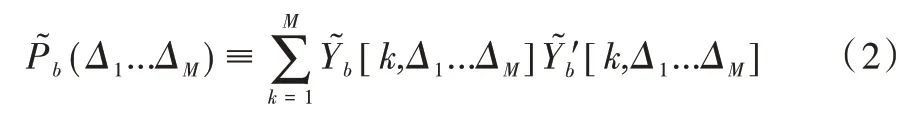
离散滤波器如下:
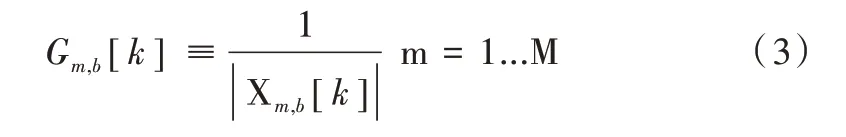
将式(3)代入式(1),相位变换加权的可控响应表示为:
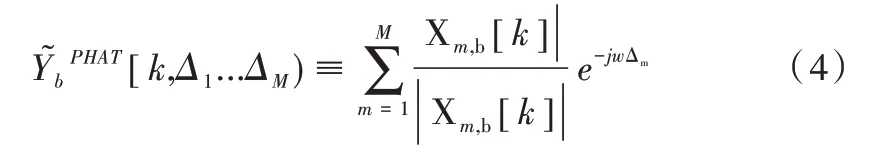
将式(4)代入式(2),可获得相位变换加权的可控响应功率SRP-PHAT 为:
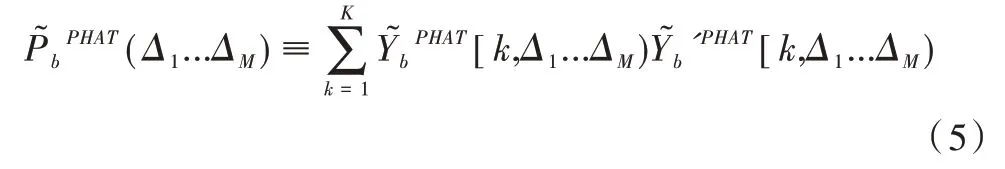
2 算法实现
为方便计算,首先对多个通道的麦克风数据进行DFT变换,根据麦克风的物理参数计算在某特定方向上的可控时延;然后基于音频数据的DFT 以及可控时延,结合公式(5),可求得该方向所有频率的SRP-PHAT;最后重复上述运算,直到获得所有方向的SRP-PHAT 值,并选取最大值对应的方向作为音源方向。具体流程如图1 所示。
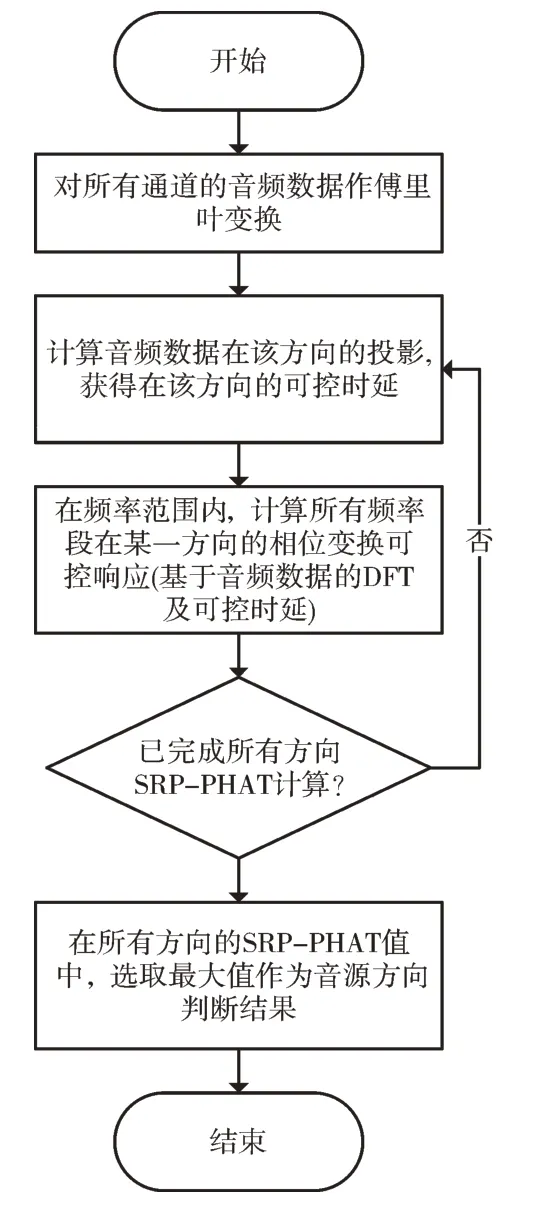
Fig.1 Flow of SRP-PHAT algorithm implementation图1 SRP-PHAT 算法实现流程
上述程序可利用Python 的NumPy 库方便地实现如矩阵内积、点积以及共轭转置等诸多矩阵运算,并可使用NumPy 库中的fft 函数实现傅里叶变换[16]。但如果要在嵌入式平台上运行,考虑到部署方便的问题,实验一般使用C++实现。由于在算法中需要使用傅里叶变换、线性代数等运算,必须使用相应的数学库。本文使用了Xtensor、Xtl、OpenBLAS 等数学运算库[17-19]。Xtensor 是一个C++库,用于多维数组表达式的数值计算,可提供支持延迟广播的可扩展表达式系统,Xtensor 提供的API 遵循C++标准。
基于Xtensor 库有很多扩展包,其中Xtensor-fftw 主要实现了xt::fftw 函数以进行fft 运算。fftw 是一个用来计算一维或多维离散傅里叶变换(DFT)的C 语言函数库,其支持输入任意大小的实数及复数运算。Xtensor-blas 是对Xtensor 库的扩展,基于FLENS 项目的CXXBLAS 和cxxla⁃pack 将BLAS 与LAPPACK 库进行绑定,具有计算逆矩阵、求特征值、解线性方程组及求解行列式等功能。其提供的函数接口基本可直接与NumPy 库兼容,因而方便程序移植。上述几个库还依赖Xtl(提供了基本的科学计算函数库)和OpenBLAS(Basic Linear Algebra Subprograms 基础线性代数子程序库),这些库之间的关系如图2 所示。
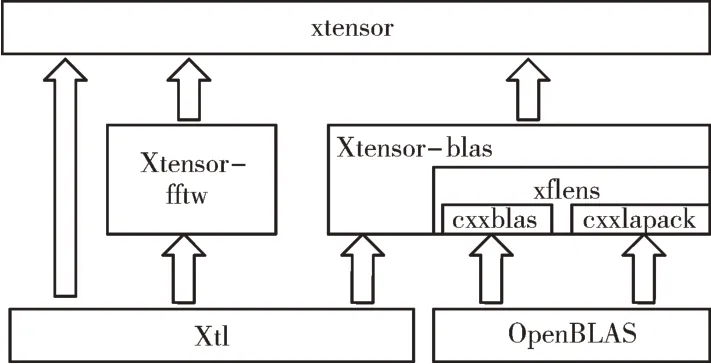
Fig.2 Algorithm library structure图2 算法库结构
3 实验分析
3.1 实验环境
在性能对比实验中,主要对算法的准确性及实时性进行分析。通过选取编程语言、运行环境、频率范围、采样时间等几种不同变量进行多组组合实验,以获得这些参数对算法准确性及性能的影响。实验采用的录音设备为Re⁃Speaker Core v2.0[20],该麦克风阵列排列以及实验时收音方向如图3 所示。

Fig.3 Microphone array arrangement and sound reception diagram图3 麦克风阵列排列及收音示意图
3.2 准确性实验
准确性实验主要对算法定位的准确性进行测试。定义中心到MIC 的方向为0°,中心到MIC4 的方向为180°,录制在180°方向、距离约50cm 位置处人声阅读文章的音频。经6 麦克风录制后的音频数据格式为6 通道,采样深度为16bit,采样频率为16K。具体音频如图4 所示,音频时间长度为1min。
Fig.4 6-channel audio of microphone array图4 麦克风阵列6 声道收音音频
在实际应用中,频段范围的选择比较重要,由于人声的频率范围集中在300~3 000Hz,选取该频率范围可在尽量保证准确性的前提下,减小算法运算量。为考察频率范围对算法准确性的影响,本实验选取0~8 000Hz 与300~3 000Hz 范围进行对比实验。具体方法为将1min 时间以50ms 进行切片,分别进行处理,共获得1 200 个样本。对处理结果进行统计,获得不同频段范围的准确率如图5 所示。
从实验结果可以看出,在0~8 000Hz 及300~3 000Hz频段范围进行处理时,定位偏差在±5°范围内的概率分别为92%及81%。0~8 000Hz 频段的误差范围可控制在±14°以内,而300~3 000Hz 频段的误差范围为±18°以内。可以看出,在采用了较小频率范围后,整体精度还是降低了10%~20%。
为了得到不同时间片对处理准确性的影响,分别以25ms、50ms 及500ms 对数据进行切片,然后对切片数据分别进行处理,并对处理结果的偏差值进行统计。结果如图6 所示。
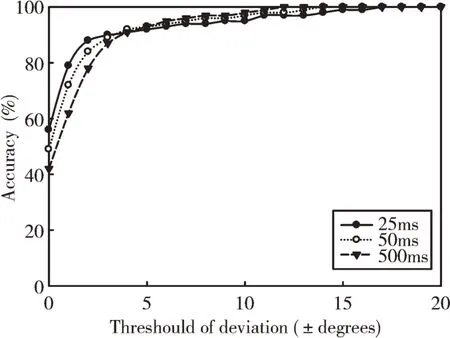
Fig.6 Accuracy of different time slices图6 不同时间片的准确率
从实验结果来看,25ms 的数据切片在0°方向的准确率最高,但在±4°以后的准确率小于其他两种切片方式,整体准确率基本在控制±17°以内。从整体来看,不同时间切片对声源定位的准确性并无明显影响。
3.3 实时性实验
很多嵌入式设备对算法的实时性都有一定要求,因此本节对该算法的实时性能进行测试与分析。选取1 000ms的6 麦克风数据进行处理,相位变换加权角度的精度分别为1°、2°与4°。选取X86 平台以及嵌入式ARM 平台,X86处理器为i7-4790,嵌入式ARM 处理器为RK3399,运行的操作系统均为Linux Ubuntu 发行版。0~8 000Hz 及300~3 000Hz 频段在各平台运行耗时如图7 所示。
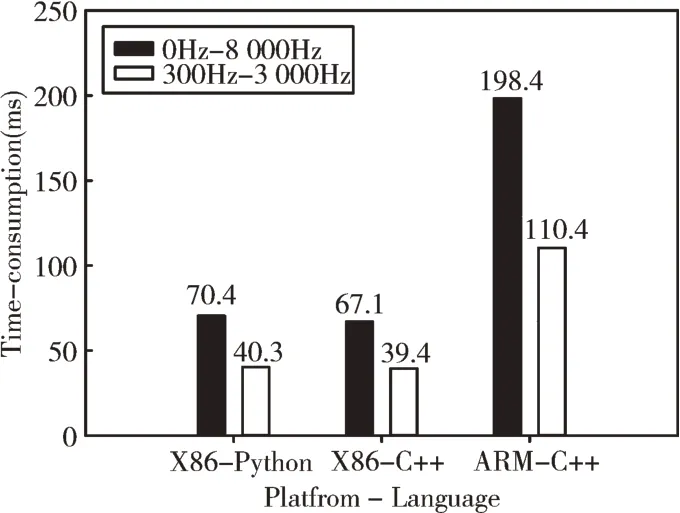
Fig.7 Time consuming of each platform图7 各平台运行耗时
从实验结果来看,相对于0~8 000Hz 频段范围,采用300~3 000Hz 频段范围能够减少约40%的处理时间。
业内认为一般情况下,C++语言运行效率高于Python。为了对比使用Python 和C++的算法性能区别,对应用两种语言在X86 平台的处理速度进行测试。可看到通过两种不同语言实现的程序运行时的性能差距较小,这是因为在使用Python 语言实现算法时,已利用cPython 库加速矩阵预算过程,因此在使用C++语言后,性能并未得到较大提升。
最后,使用C++语言实现该算法,并在嵌入式ARM 处理器RK3399 芯片上进行性能测试。ARM 平台由于处理能力有限,运行耗时约为X86 平台的2.8 倍。
在一些产品交互应用,特别是语音机器人中,主要是在唤醒操作时对声源进行定位,提供声源方向,为后续波束形成提供音源方向参数。根据实验结果,在嵌入式平台通过本算法对1 000ms 的6 麦克风数据进行处理需要110ms 的时间,在人机对话交互过程中,该时间在可接受范围内。如果希望进一步提高算法响应速度,可根据需求减小相位变换角度分辨率。继续在ARM 处理器上进行实验,分别选取角度分辨率为1°、2°与4°,运行多次取均值,实验结果如图8 所示。
根据实验结果,可看出通过降低角度分辨率,可以线性地降低算法复杂度,减少运行时间,但需要在实现过程中通过综合考虑进行效率及精度取舍。
对于音源持续时间与处理耗时的关系也进行对比实验,选取音频时间为1 000ms、500ms 和50ms,在ARM 平台上运行多次取均值,结果如图9 所示。
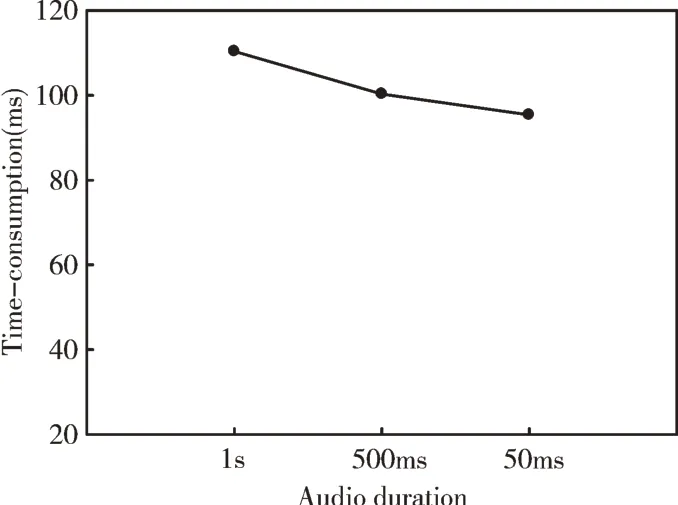
Fig.9 Time consuming of different audio duration图9 不同音频时长运行耗时
可以看到,对于不同时长的音频进行处理,其耗时并未随音频时长的减少而大幅下降,减少的时间大部分来自对源数据进行预处理及傅里叶变换导致的时间变化。因为傅里叶变换后将时域数据转为频域信息,对频域数据进行相位变换加权后的数据矩阵大小与时长无关,比较耗时的部分是在角度搜索中进行互功率最大值运算。
4 结语
本文简要分析了SRP-PHAT 算法原理,并提出使用Py⁃thon 及C++语言实现该声源定位算法。针对在工程实践中的角度分辨率及音源时长等相关参数对算法准确性与实时性的影响进行实验与分析,为算法部署时的参数选取提供了依据。实验结果表明,该算法在嵌入式平台处理耗时在200ms 以内,能基本满足嵌入式平台的应用要求,也可根据需求选取不同的音频频率段,调整搜索精度以进一步提高算法的实时性能。根据实验结果,该方案可应用于智能语音交互产品中,使用单个ARM 芯片即可实现声源定位,并通过与服务器的通信实现语音识别、语义分析等关键功能。下一步在产品具体实施过程中,需要结合噪声抑制以及回声消除等其他音频处理技术,进一步提高声源定位的准确性。
