基于LightGBM 的文本关键词提取方法
2021-08-02马莉媛朱良奇黄季涛李梦君荆苗苗
马莉媛,黄 勃,朱良奇,黄季涛,李梦君,荆苗苗
(上海工程技术大学电子电气工程学院,上海 201620)
0 引言
移动互联网快速发展与大数据、云计算等技术的出现催生了众多新媒体发展,公众获取信息的渠道逐渐增加,信息获取愈加便利。但有些媒体为了吸引用户眼球,追求更高的点击率,对文章标题过度润色,部分文章甚至出现文不对题的现象。用户在信息检索时多用文本标题进行检索,由于信息过载、垃圾信息过多导致无法快速找到精准信息等问题。面对繁杂的信息,可利用关键词提取技术快速且精准地提炼文本信息。
关键词提取指从文本中提取与目标内容最相关的词汇,被提取的关键词必须具备3 个条件:可读性、相关性及涵盖性。1958 年Luhn[1]提出了题内关键字索引的概念,使检索刊物时对索引的编辑工作实现自动化,加快了检索刊物的出版速度,保证了文献报道及时性;1999 年,Witten等[2]提出一种KEA 全新算法,该算法主要是利用候选目标关键词第一次处在文档内的位置与TF-IDF 值进行匹配从而获得特征值,然后使用贝叶斯模型训练获得关键词;2000 年,Turney[3]采用C4.5 决策树分类器进行关键词提取;Mihalcea 等[4]基于PageRank 算法与单词之间的语义关系,提出基于图模型的Texrank 算法,该算法精度较高,考虑了词的位置信息,但是计算复杂度较高;徐文海等[5]提出了一种基于向量空间模型与TF-IDF 方法的中文关键词抽取算法。该算法在对文本进行自动分词后,用TF-IDF 方法对文献空间中的每个词进行权重计算,然后根据计算结果抽取出科技文献关键词,这种方法较易理解,且容易实现,但是过度依赖语料库,精度不高,没有考虑语义信息;刘啸剑等[6]提出一种基于图与主题模型的关键词抽取算法,首先利用LDA 主题模型计算出词与词之间的相似性,作为词与词之间的权重并构建一个带权无向词图,最后再从这些短语节点中选择TopK 个词作为文章关键词,该方法考虑到文本隐含语义,但是提取的关键词较广泛、时间复杂度较高且需要大量训练。为了改进TF-IDF 算法、Textrank 算法及LDA 算法缺陷,近年来众多融合算法被提出。例如,牛永洁等[7]提出融合因素的TF-IDF 关键词提取算法,朱衍丞等[8]提出基于SVM 的融合多特征TextRank 的关键词提取算法,曾庆田等[9]提出融合主题词嵌入与网络结构分析的主题关键词提取方法。虽然这些融合算法在一定程度上提高了原始算法准确率,但是在处理海量数据时该类方法准确率有所下降。
针对以上问题,本文提出基于LightGBM 的文章关键词提取。首先通过TF-IDF 模型,为文本选出20 个候选关键词;然后通过特征工程[10],对文本候选关键词进行特征提取,共提取5 个特征;再将20 个候选关键词经由特征工程提取出5个特征,将这5个特征作为LightGBM算 法[11]参数,判断这20 个候选关键词是否为关键词;最终选择预测概率较高的词作为文本关键词。
1 特征工程
假设现有一篇文本T,文本句子长度为n,则有T={S1,S2,…,Sn},对于∀Si∈T,有Si={w1,w2,…,wm}。对文本数据进行预处理,本文采用Jieba 分词对文本进行分词及去除停用词处理,去除与文章语义无关的部分词汇,例如标点符号、形容词、副词、助词及人称代词等,得到一个长度为l的词组列表,用该词组表示文本,得到T={w1,w2,…,wl}。
此时得到长度为l的词组T可能存在冗余和噪声,IDF本身是一种抑制噪声的加权,而TF-IDF 是对文档或句子中的词语进行频率计算的常用方法,某个词TF-IDF 取值取决于两个因素:词频及该词稀有程度,因此TF-IDF 描绘了一个词语在所属文档或句子的稀有程度。虽然TF-IDF 算法精度不高,但该步骤仅去除一部分噪声,即过滤掉通用词,保留重要的词语,且TF-IDF 易于实现,故本文采用TF-IDF对经过预处理之后的数据进行粗略筛选,选出20 个候选关键词K={w1,w2,…,w20}。
经由TF-IDF 得到的候选关键词此时还是文本数据,对文本数据进行特征提取,转换为可用于机器学习的数字特征,即将文本数据特征值化。对这20 个候选关键词进行特征提取,主要提取以下5 个特征:字典特征、文本特征、词频特征、相似度特征及词性特征。
1.1 字典特征提取
字典特征提取指将文本数据映射在向量空间。首先对候选关键词进行One-Hot 编码得到其向量表示。由于One-Hot 编码得到的词向量矩阵过于稀疏,对One-Hot 编码进行Word Embedding 得到低维稠密向量。本文用Word2Vec[14]的Skip-Gram模型训练词向量(见图1)。Skip-Gram 模型主要定义了=概率分布,其思路是以中心词为中点,定义一个长度为2m 的滑窗,计算上下文词汇出现的概率。通过重复操作,选择词汇向量,使概率分布值最大化。
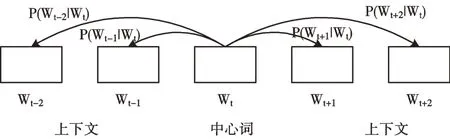
Fig.1 Skip-Gram model图1 Skip-Gram 模型
首先,将中心词汇One-Hot 编码作为输入,与所有中心词汇表示组成的矩阵相乘,得到中心词汇向量表示vc,再将其与输出词汇向量表示uo相乘,即uoT vc,得到基于中心词汇vc的上下文词汇向量表示。
然后,利用softmax 将数值转换成概率分布,即计算两个单词向量点积,将其转换为softmax(uoT vc)。uTw vc的意义是遍历w=1,2,…,l,计算出每个单词与vc相似度。
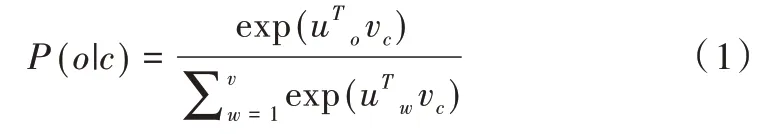
此时得到上下文词汇概率分布是存在误差的。定义一个损失函数J'(θ)对该模型进行训练。
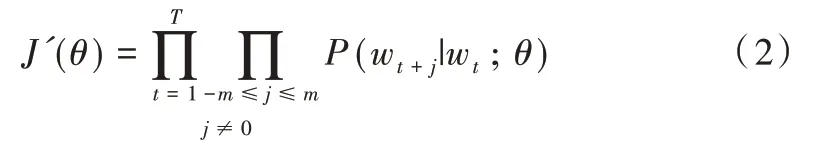
其中,J'(θ)表示在一段长文本中,遍历文本中所有位置;θ是模型参数,也是词汇向量表示;wt为中心词;wt+j为上下文单词。求J'(θ)负的对数似然,得到J(θ)。
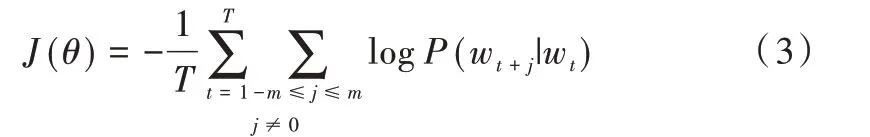
训练模型主要目的是调整参数θ,以此让负的对数似然最小化,从而使预测概率最大化。
1.2 文本特征提取
由字典特征提取得到候选关键词向量表示,但此时向量表示是静态词向量,即不考虑其词法和语序问题,因此利用N-gram 模型[12],用于提取上下文文本特征。N-gram模型是概率判别模型,其本质是基于n 阶马尔可夫假设,即一个词的出现仅与它之前的若干个词有关。

在计算复杂度方面,模型参数量级是N 的指数函数O(Nn);在模型效果方面,当n 从2 到3 时,效果上升显著,但之后提升不显著,因此综合计算复杂度与模型效果两个因素,本文取n=3。
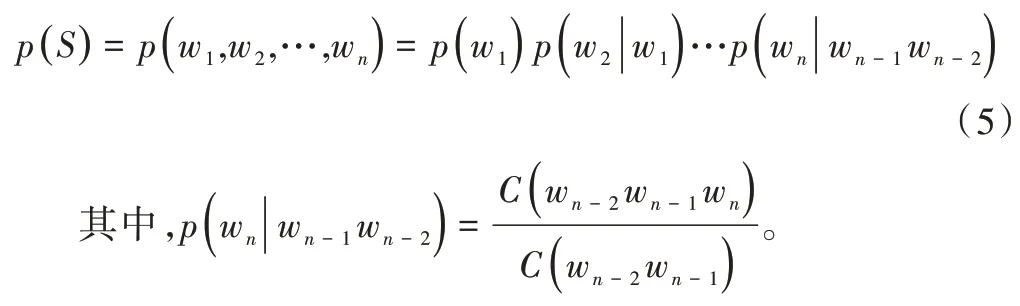
1.3 词频特征提取
由Word2Vec 得到的词向量表示并没有考虑词频,但在计算词的重要程度时,词频是非常重要的权重之一,因此需提取词频特征,本文用每个词TF-IDF 值作为词频特征。
1.4 相似度特征提取
关键词的设立是为了让用户在短时间内掌握文本信息,如若选取关键词意思相近,则不能很好地概括文本内容,说明关键词有冗余,因此计算词间相似度,去除冗余词组,可提升关键词提取效果。本文通过计算词向量间余弦相似度提取候选关键词相似度特征。
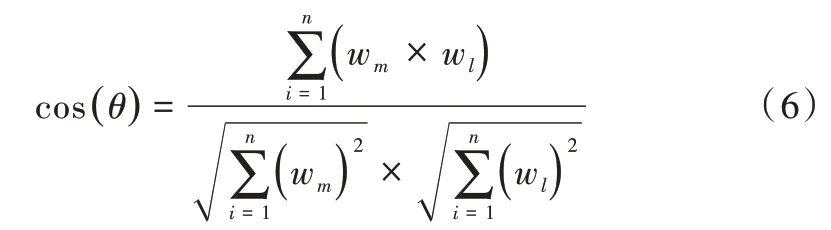
1.5 词性特征提取
关键词精髓在于通过短短几个词语了解文本内容,这要求提取的关键词十分精简。在汉语言中,实词往往更能表征文本内容,因此对候选关键词进行词性判别可过滤一些噪音[13]。
首先,对词性进行加权。由于名词、动词、形容词、感叹词、介词、连词等不同词性的词语对文本内容呈现贡献不同,因此对词性进行加权,给不同词性赋予一定权重。词性加权公式为,其中n为词性总类数,xi表示第i个特征粒子,j表示某种词性。
其次,特征词为某种词性概率的计算公式为:

其中,tj表示特征t词性特征。
则词性权重计算公式如式(8)所示,其中PF×TDF表示特征t的词性加权总值。

2 基于LightGBM 的文本关键词提取
对候选关键词进行特征工程,得到候选关键词字典特征、文本特征、词频特征、相似度特征及词性特征,然后采用决策树算法将关键词提取转化为二分类问题。梯度提升决策树(Gradient Boosting Decision Tree,GBDT)[14-15]是一种流行的机器学习算法,在此基础上产生了很多经过工程优化的算法,如XGBoost[16-17]、pGBRT 等。本文 使用Light⁃GBM 算法,其中基于梯度的单边采样(Gradient-based One-Side Sampling,GOSS)可有效解决数据量较大的问题,同时在计算过程中使用互斥特征捆绑(Exclusive Feature Bun⁃dling,EFB)方法有效简化数据。
2.1 关键词提取
以文本特征、词频特征、相似度特征及词性特征作为划分属性,建立一个样本集T,则T={(w1,y1),(w2,y2)…(w20,y20)},其中wi为词向量,yi∈{0,1}为标签,当yi=0 时,该词wi不是关键词,反之表示候选关键词wi为关键词。LightGBM 算法作为分类器进行关键词提取步骤如下。
步骤1:对样本T进行归一化处理。
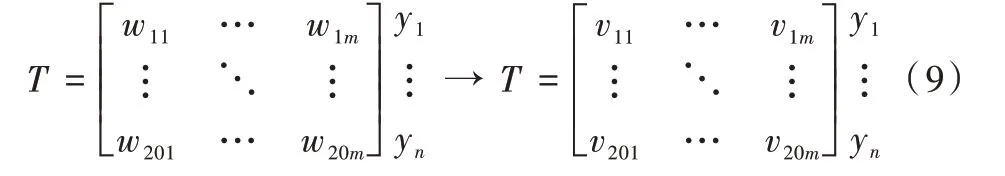
步骤2:计算初始梯度值λ(初始值设置为0)。
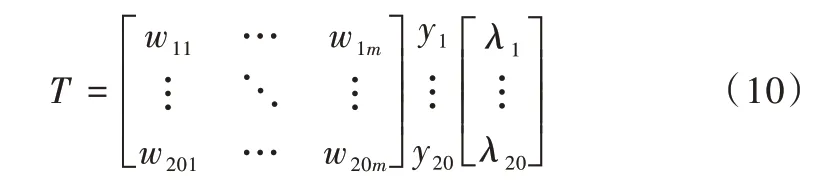
步骤3:建立树。LightGBM 算法特色是直方图优化,将特征工程中得到的特征值划分为离散值进行装箱处理,形成bins。直方图构建过程如图2 所示,将特征值为浮点型数据的特征装箱处理,即特征值离散化,然后进行装箱处理形成bindata。
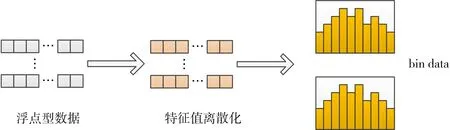
Fig.2 Histogram construction图2 直方图构建
2.2 直方图优化算法
利用直方图寻找最佳分裂点


(1)建立直方图。假设通过上述算法建立的直方图为:
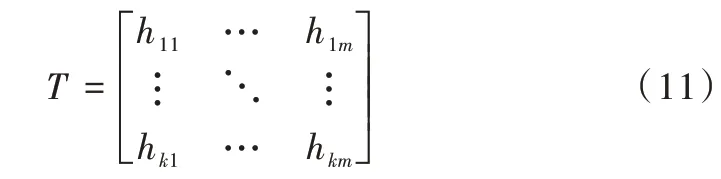
其中,对每个特征创建一个直方图hij=(cij,lij),该直方图存储了两类信息,分别是样本梯度之和cij=H[f.bins[i]].g与样本数量lij=H[f.bins[i]].n。遍历所有样本,累积上述两类统计值到样本所属的bin 中。
(2)寻找最佳分裂特征。分别以当前bin 作为分割点,累加其左边的bin 至当前bin 梯度和SL及样本数量nL,并与父节点上的总梯度SP与总样本数量nP相减,得到右边所有bin 的梯度和SR及样本数量nR,计算出增益后在遍历过程中取最大增益,以此时特征和bin 特征值作为最佳分裂特征G与分裂阈值I。
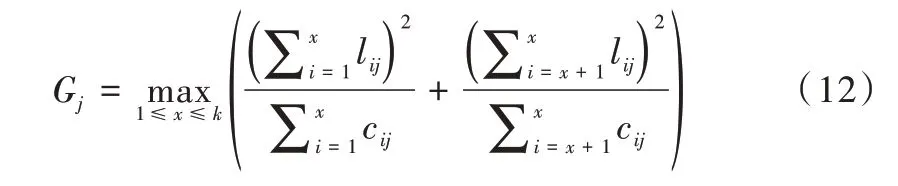
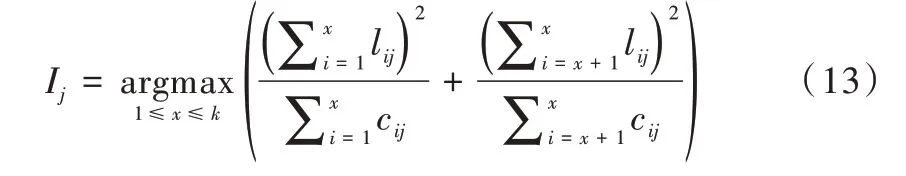
(3)建立根节点。
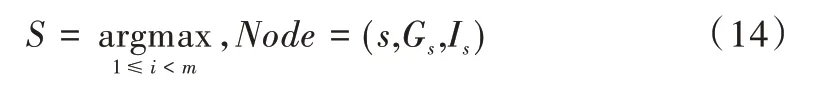
(4)根据最佳分裂特征,分裂阈值将样本进行切分。
(5)重复(1)~(4)选取最佳分裂叶子、分裂特征、分裂阈值,切分样本,直到达到叶子数目限制或所有叶子不能分割。
(6)更新当前每个样本输出值。
步骤4:更新梯度值。
步骤5:重复步骤3、步骤4,直到所有的树均完成建立。
步骤6:调节参数,进行分类实验。
3 实验
本文实验利用搜狐校园算法比赛提供的数据,包含大约10 万篇搜狐网站上的各类文章资讯。实验使用准确率P、召回率R 及F1 评价关键词抽取效果。实验分别抽取了2~5 个关键词作为自动抽取关键词与数据集中人工标注的关键词进行对比。与本文LightGBM 方法进行对比的算法包括TF-IDF、TextRank、LDA。
从表2 和图3 可以看出,随着提取关键词个数的增加,准确率均有所降低,即TopN 越小,准确率越高。纵向对比LightGBM 与其他算法,发现LightGBM 算法提取关键词的效果明显优于其他算法。因此综合考虑总体试验评价结果,本文LightGBM 算法整体效果最佳。

Table 2 Results comparison of the keyword extraction methods表2 各类关键词抽取方法结果对比
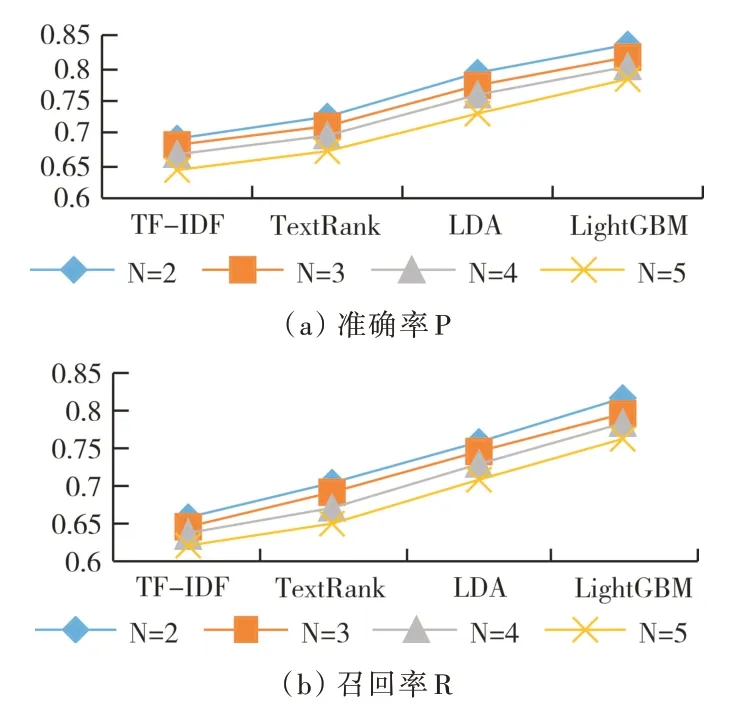
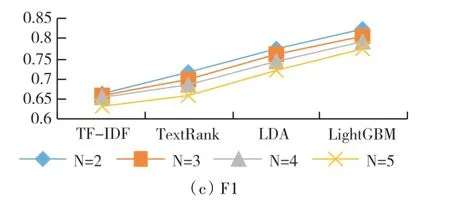
Fig.3 Accuracy,recall and F1 values of each method when N is 2~5图3 N 取2~5 时各方法准确率、召回率及F1 值
4 结语
关键词提取是自然语言处理的基础与核心。自然语言处理中的信息检索、摘要生成、文档分类、基于检索的问答系统等均与关键词提取联系紧密。本文提出融合特征工程与LightGBM 算法实现关键词提取,利用TF-IDF 中IDF 抑制噪声的特点选择候选关键词,并通过特征工程提取候选关键词的5 个特征作为LightGBM 特征集,将关键词提取问题转化为二分类问题。实验结果表明,该方式可进一步提高关键词提取效率。下一步研究将利用神经网络实现文本关键词提取,并与传统关键词提取方法从效率及准确率两个维度进行对比,寻找性能更佳的方法。
