结合深度神经网络与内容转录的语音识别研究
2021-08-02郑磊
郑 磊
(山东青年政治学院信息工程学院,山东济南 250103)
0 引言
随着数字时代的到来,信息爆炸式增长,传统的以文本形式保存信息的方式已经不能满足现代人对知识的需求[1]。声音作为一种直接记录和掩饰信息的媒介,在实时传递信息的同时,将情感传递给信息,对信息的记录更有价值[2]。随着多媒体文件的大量应用,基于多媒体数据的信息检索技术已成为信息学研究的热点[3-5]。如何像检索文本一样快速、准确地从各种多媒体文档中查找最重要的信息成为当前关注的热点。
本文介绍了语音识别原理和相关算法。在此基础上将深度神经网络算法(Deep Neural Network,DNN)应用于大词汇量连续识别系统,建立基于深度神经网络的声学模型关键词检测系统。在对比实验中,将所提出的深度神经网络模型应用于构建声学模型,与传统GMM-HMM 进行对比,深入分析了算法对识别系统性能的影响。
1 相关研究
关键词检测技术起源于20 世纪70 年代,最早研究是基于“给定词”概念。语音识别作为关键字检索的一项关键技术受到广泛关注。2006 年,Mustafamk 等[6]提出深度学习概念。微软研究人员将受限的Boltzmann machime(REM)和深度信念网络(DBN)引入到语音识别声学模型训练中,在大词汇量语音识别系统中取得成功[7]。
我国语音识别研究起步较晚。在国家的大力支持下,中国科学院自动化研究所、中国科学院声学研究所等科研机构在语音识别方面进行了广泛研究并取得显著进展。目前,微软、1BM、谷歌等国外公司相继开发了中文语音识别系统[8-9],中国的公司如百度讯飞、搜狗也推出了相应的中文连续语音识别项目。语音识别技术与关键字检测系统在未来有着非常广阔的发展前景。但是,语音识别技术仍然面临着各种挑战,如无法有效避免语音识别错误等[10]。本文希望通过对基于DNN 的语音识别算法进行研究,为提高语音关键字检索系统语音识别性能提供新的思路。
2 研究方法
2.1 语言识别流程和原则
一个完整的语音识别系统包括语音预处理、语音特征提取、语音模型库构建、语音模式匹配等功能。对于录制的语音信号,首先进行语音预处理操作。预处理包括采样、量化、滤波、预加重、窗口加帧和端点检测等步骤,然后进行语音信号特征提取,目的是提取能够表征语音信号性质的特征参数,去除不相关的噪声信号,获得用于声学模型或语音识别的输入参数。语音识别和语音预处理流程如图1 所示。
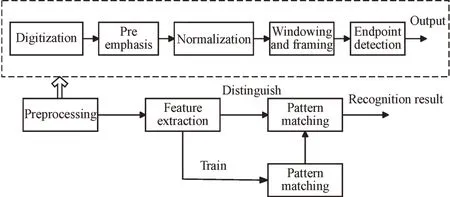
Fig.1 Speech recognition structure and speech preprocessing flow图1 语音识别结构和语音预处理流程
2.2 语音识别算法模型基础
语音识别的核心是声学模式,目前主要采用隐马尔可夫模型对语音信号的时间变化建模。HMM 每一种状态下的观测概率估计方法可分为离散型、半连续型和连续型。目前,语音识别系统主要是连续或半连续的。通过HMM描述声学层模型时,隐藏状态对应于声学层相对稳定的语音状态,可以描述语音信号的动态变化。
图2 中HMM 模型有6 种状态,其中4 种是启动状态,第1 种状态表示开始状态。每个隐藏状态会根据概率分布向外发射一个状态,然后转到右边的状态。最右边的结束状态表示HMM 已经结束。在某个时间节点模型有一系列状态。在t+1 时,模型的每个状态都会转到一个新的状态,表示一个新的状态序列。这一过程最重要的特征是T 时刻状态只与t-1 时刻的状态相关,这被称为马尔科夫。HMM 基本组成包括:①状态集S={s1,s2,...,sN},其中N 表示音素的个数;②状态转移矩阵A;③表示每种状态初始概率的输出分布B={bj(x)} 。
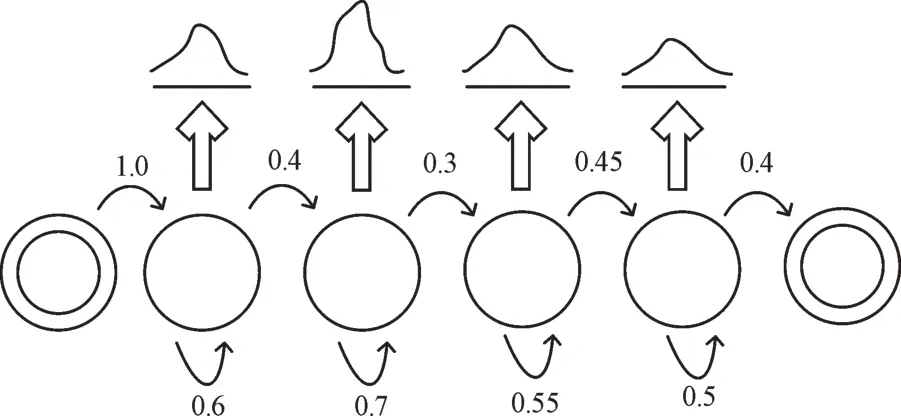
Fig.2 HMM model structure图2 HMM 模型结构
2.3 DNN 与传统声学模型结合
关键字检测系统通常基于大词汇量连续语音识别器。在语音关键字检索系统中,采用GMM 与HMM 相结合的GMM-HMM 模型作为LVCSR 的声学模型,但该模型对语音信号识别率较低。随着深度学习技术在语音识别领域的发展,利用DNN 代替GMM 形成DNN-HMM 声学模型引起广泛关注。DNN 模型是一种具有多层隐含层的前馈神经网络模型。DNN 模型共有L+1 层,其中0 层为输入层,1 到L-1 层为隐藏层,L 层是输出层,相邻层由前馈权值矩阵连接。
大多数情况下DNN 模型激活函数为Sigmoid 函数:

σ(z)的输出范围是(0.1),这有助于获得稀疏表达式,但它使得激活值不对称。对于多分类任务,每个输出神经元代表一类i∈{1,2,…,C},其中C=NL是类的数量。给定训练准则可使用众所周知的误差反向传播算法提取模型参数C=N,并利用链式规则进行推导。模型参数采用一阶导数信息,按下式进行优化:

式中:和分别为第t 次迭代更新后第1 层的权值矩阵和偏差向量。
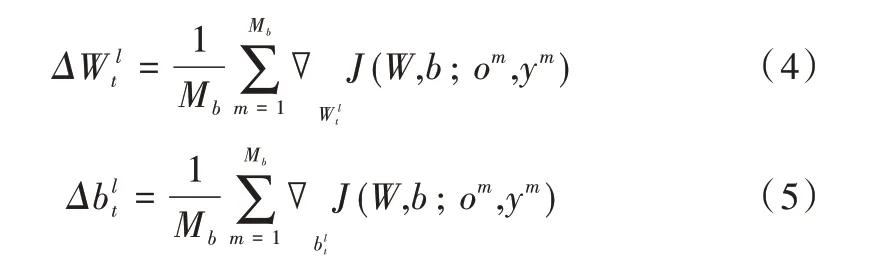
式(4)和式(5)分别为第t 次迭代后得到的平均权重矩阵梯度和平均偏差向量梯度,其中ε为学习速率,∇XJ为J 相对于x 的梯度。
对于每个任务,DNN 的模型参数需要由训练样本S={(om,ym)|0 ≤m≤M} 进行训练。式中M 为训练样本个数,om为第M 个观察向量,ym为对应的输出向量。这个过程称为训练过程或参数估计过程,需要给出一个训练标准和一个学习算法,在语音识别任务中,通过声学模型训练完成这一过程。对于相邻层间完全连通的DNN,权值初始化为一个较小的随机值,以避免在一个拥有相同梯度的层中由于隐藏层太多而难以优化所有隐藏单元。DNN 可能需要扩展到测试数据集之外。语音符号是时间序列信号,DNN 不能直接对其建模。利用HMM 对语音信号的动态变化进行建模,利用DNN 估计观测概率。DNN-HMM 模型结构如图3 所示。
DNN-HMM 训练步骤如下:①将训练集与常规训练的DNN-HMM 模型进行对齐,得到对齐信息;②建立上下文敏感状态到语音ID 的映射;③根据训练DNN 所需的输入和输出标签生成信息;④获取DNN 中需要的HMM 模型结构;⑤基于输入和输出标签估计语音的先验概率,利用反向传播算法调整网络参数得到DNN-HMM 模型。
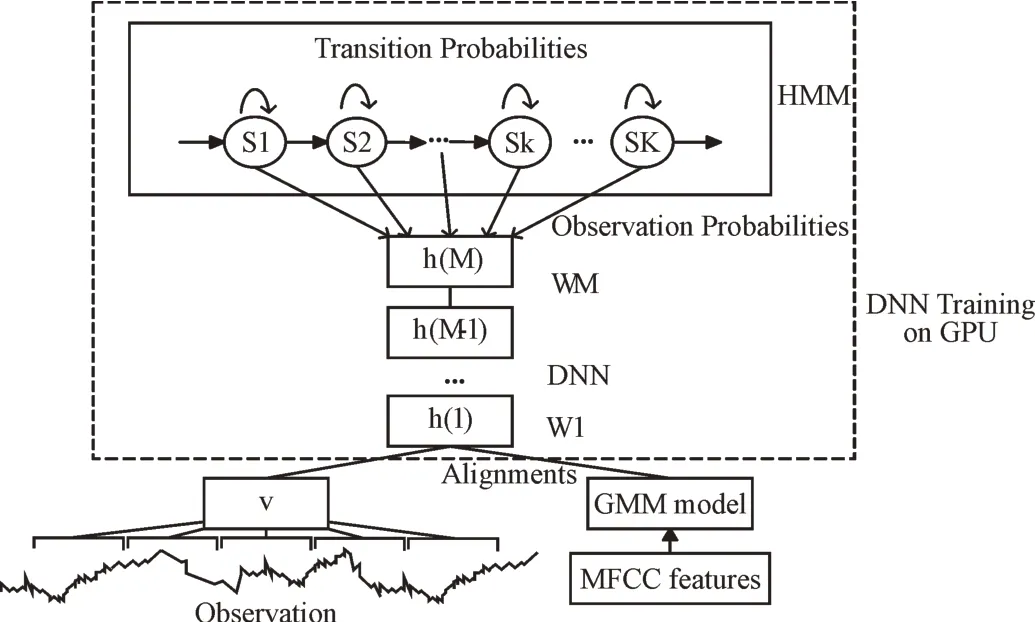
Fig.3 DNN-HMM model structure图3 DNN-HMM 模型结构
3 实验结果
3.1 实验数据
本实验选择开源中文普通话语音数据库aishell,对同一扬声器的测试集执行数据库中的语音材料。在安静环境下使用电脑录音软件Cool Edit Pro 录制语音信息,挑选8名演讲者依次阅读20 个教育词汇,每个单词读10 次。采样频率设置为8kHz,每个采样点被量化16 位并存储在单声道中,共获得1 600 个语音样本作为训练和识别语料库。以前3 道和后3 道作为训练集,共有960 个样本,使用中间4个样本作为同一扬声器测试集,共640 个样本。
在语音信号特征提取中,从训练集和同一说话人测试集的每个预处理语音样本中提取24 维Mel-frequency Ceps⁃trum(MFC)系数特征,并采用均值方差对其进行正则化,该功能窗口大小为25ms,重叠时间为10ms。比较传统的神经网络模型和DNN 模型的语音识别性能,以语音识别正确率作为评价标准,数值均为统计平均值。
3.2 基于语音识别的语音关键字检索系统构建
语音关键字检索系统包括系统索引和关键字检索。其中,索引由索引语音识别、后处理语音识别、索引构建组成。关键字检索由关键字检查和置信度评估两部分组成,如图4 所示。语音识别错误和外来词严重影响系统的查全率,模糊匹配方法能有效提高召回率,但增加了查询时间。在关键字查询过程中,可以在超类数据库中执行初始快速查找以缩小搜索范围,然后在音节序列数据库中执行精确的查询以加快搜索速度。
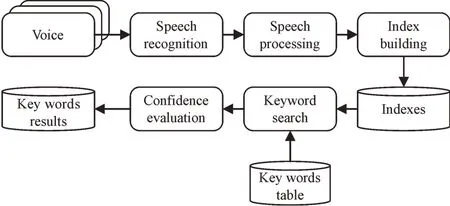
Fig.4 Composition of voice keyword retrieval system图4 语音关键字检索系统组成
语音关键字检索系统依赖于识别结果,因此语音识别的性能对系统的检索性能有着至关重要的影响。语音识别系统性能通常是通过识别错误率和实时率来评价的。在语音关键字检索系统中,语音数据的识别过程可以离线进行而不必考虑实时指标。识别结果表明,错误类型包括插入错误、删除错误和替换错误。将识别最佳结果与参考文本进行比较,可以得到识别错误率。
3.3 语音识别结果比较
语音信号特征参数的帧数设置为23,选取非线性tanh函数作为激活函数。输出为30 个神经元,使输出神经元的数目与待分类神经元数目相同。以估计概率分布与实际概率提取之间的高斯熵作为目标函数,当语音识别精度提高到0.2%以下时停止迭代。不同语音识别算法的识别准确率结果如表1 所示。

Table 1 Recognition accuracy of different speech recognition algorithms表1 不同语音识别算法的识别精度 (%)
如表1 所示,基于LSTM-HMM 和DNN-HMM 模型的语音识别准确率明显高于传统的GMM-HMM 模型,同时LSTM-HMM 模型的语音识别准确率达到96.5%,表明该模型具有更好的性能。LSTM 训练参数大小为436 570,DNN训练参数大小为698 100,GMM 训练参数大小为1 226 700。在训练集语音样本有限的情况下,训练模型的过拟合会导致训练模型过拟合问题。因此,基于DNN 的语音识别可以减小训练参数大小,有效避免训练模型的过拟合。
语音信号具有很强的随机性,同一语音单元扩展的语音特征参数及帧数可能不同,规则帧数对不同算法识别性能的影响如图5 所示。随着规则帧数的增加,输入与原始特征参数的距离越来越近,两种网络模型的识别精度不断提高。模型是通过随机梯度下降法计算均方误差,然后通过调整网络参数减小均方误差来实现。因此,网络模型的收敛性直接反映了整体性能是否优越。

Fig.5 Influence of regular frame number on recognition performance of different algorithms图5 规则帧数对不同算法识别性能的影响
4 结语
为解决传统关键字检测系统中GMM-HMM 声学模型的低识别率问题,本文将基于DNN 的语音识别算法应用于关键字检测。使用DNN-HMM 声学模型代替原系统中的GMM-HMM 模型,并在此基础上对关键字检测进行研究。通过对比实验选择一个开源普通话语音数据库——aishell,它是在同一个扬声器的测试装置上播放的。在安静环境下,使用电脑录音软件Cool Edit Pro 录制语音信息。实验表明,基于LSTM-HMM 模型和DNN-HMM 模型的语音识别准确率分别为96.5% 和91.6%,显著高于GMMHMM 的78.5%,说明本文提出的LSTM-HMM 模型性能更好。在训练集语音样本有限的情况下,会产生训练参数尺度过大、训练模型过拟合问题。基于DNN 的语音识别算法可以减小训练参数尺度,从而有效避免训练模型过拟合问题。
基于LSTM-HMM 的语音识别技术具有较高的准确率,更适合于语音关键字检索。但在复杂语音环境下,关键字检测的鲁棒性仍有很大的提升空间。因此,后续研究可以探索提取更鲁棒的声学特征方向,在有噪声干扰的情况下准确检索所需的语音信息。
