气象地面实时历史统计数据云存储技术研究
2021-08-02陈晔峰吴书成鲁奕岑
魏 爽,杨 明,陈晔峰,吴书成,吴 彬,鲁奕岑
(1.浙江省气象信息网络中心,浙江 杭州 310002;2.湖州市气象局,浙江 湖州 313000)
0 引言
随着全球气候变暖,自然灾害增多,强降水、冰雹、雷电、干旱等极端天气气候事件频发。加强气候观测,提高防灾减灾能力成为普遍关注的问题[1-2]。气象自动站为局部区域的气象预报服务和灾害监测提供了大量观测资料,使有效捕捉中小尺度天气系统成为可能[3]。随着数据量的增加,数据环境复杂度增强,传统的关系型数据库存储方式已不能满足大数据的业务需求[4-5]。如何合理有效地存储大量数据记录[6],实现高并发情况下的高速存储,同时在毫秒级时间内提供查询统计服务,是当前气象业务部门亟需解决的难题。
为满足气象预警、决策服务、气候评估等业务需求,各级气象部门陆续建立了气象资料存储系统[7]。文献[8]提出国家级气象资料存储检索系统(简称NMARS)的设计思路和技术路线,在向国家级气象业务、科研提供资料检索服务的同时,也为社会用户提供所需资料;高祝宇等[9]开发了一套针对气象业务的数据服务系统,以Web 服务方式提供数据接口,实现对气象数据服务的统一管理;王海宾等[10]为服务2009 年上海世博会等大型活动,设计并实现了基于Oracle 的长三角自动站数据库系统,实时处理长三角地区的自动站资料并入库,极大扩展了资料的共享度;刘尉等[11]基于Oracle 关系型数据库,对任意时段气候数据统计流程进行优化,优化后的统计流程在任意时间任意时段均可保持很高的效率。
随着云存储技术的飞速发展,分布式云存储成为解决海量数据存储的最有效手段[11-12]。陈京华等[13]利用分布式技术构建了基于“分布式关系型数据库+事业型数据库+列式数据库+表格系统+分布式文件系统”的混合型大数据服务中心模式,进行数据存储、管理和服务,极大提升了数据影响力;雷鸣等[14]、陈效杰等[15]采用Hadoop/Hive 集群优势,存储和处理气象数据集,实际应用效果很好。已有研究表明,采用云关系型数据库存储结构,能够有效提高气象数据存储效率,满足大规模气象数据在业务应用中对存储查询和处理速度的要求[16-18]。本文针对地面气象数据特点和气象业务服务需求,充分利用分布式应用服务和云存储技术,提出一种基于分布式云存储技术的任意时段数据统计方法,为相关单位开展类似业务提供借鉴。
1 关键技术
1.1 统计算法规范
统计方法的规范和统一是保证气候统计数据准确性、连续性和均一性的最基本条件之一[19-20]。《全国地面气候资料统计方法》和《地面气象观测规范》等规定了气象国家级自动站(简称国家站)的统计方法和不完整记录的处理方法。为获得高质量的区域站统计资料,满足本地实际业务需求,本文参考上述规范有关规定,根据省内区域站历年站点个数、观测数据完整性等情况,设计了区域站小时、日、旬、月、年数据统计方法,能保证各要素统计数据完整率在80%以上。
1.2 统一数据存储规范
规范的数据存储既能与国家局大数据云平台数据存储同步,提高检索功能和服务效率,又易于地面多要素相关分析。本文遵循标准、规范先行原则,参照国家局CI⁃MISS 数据库设计规范[21],以支撑气象数据预报服务、科研应用需求为目标,在气象云存储数据平台基础上设计了实时历史一体化数据云存储方法,规范定义存储表结构、索引、约束等项目。
1.3 分布式存储
气象国家站建站时间较长(杭州站1951 年建站),区域站站点个数多(2020 年约3 400 站),实时与历史一体化数据量非常庞大。为满足快速获取数据需求,针对结构化的地面统计数据,采用主键、属性和值3 个部分存储,如表1所示。

Table 1 Statistical data storage structure表1 统计数据存储结构
应用云关系型数据库分库分表技术,每个分库负责数据读写操作,分散整体访问压力,有效提高数据存储和服务效率。以支撑气象数据查询统计及预报、科研应用需求为目标,建立自动站小时、日、旬、月、年数据统计应用表,形成基于云平台的地面实时历史一体化长序列统计数据库,满足业务系统和用户对数据的各类应用需求,如图1 和表2 所示。
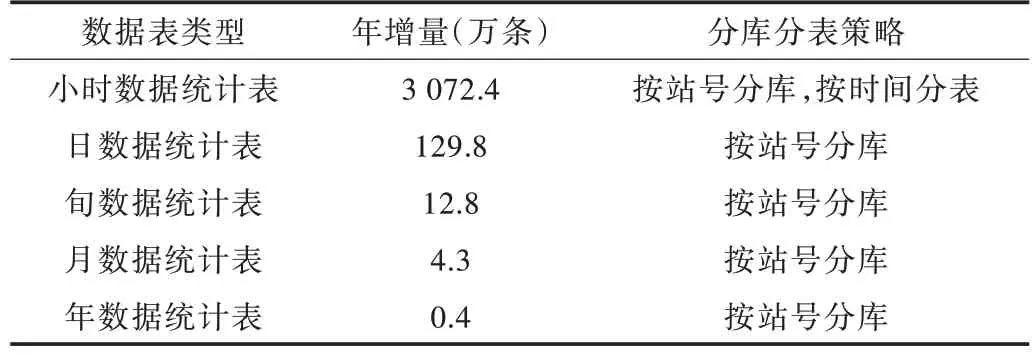
Table 2 Storage strategy of statistical database表2 数据库存储策略
1.4 任意时段数据统计方法
一般情况下,对于质量控制后的数据,统计值要事先存储在数据库表中,在进行任意时段数据实时统计时,取已保存的统计结果及少量数据进行合并统计运算,即可得到最终的统计结果。以此原则开展任意时段数据的实时统计,可降低实时数据的读取和统计时间,大大提高数据查询效率。
本文选取日、月为时间单位,对任意时段在时间轴上进行分解,设计任意时段数据统计流程。定义任意时段起始日期为t1,结束日期为t2,判断开始日期月增加1 与结束日期减少1 之前逻辑关系。将任意时段分解为两种情形:①日数据;②日数据、月数据。由图2 确定各分解情形对应的起止日期和读取的数据库表,进而直接通过语句查询统计数据结果。
其中,y1*m1表示年和月,*代表月份的变化可能引起年的变化,Month表示月表,Day表示日表。针对任意时段统计查询,应用年数据可以减少统计量,但无形中增加了判识流程时间复杂度。经实例分析后,确定以日、月为统计单位较为合适。

Fig.1 Statistical database based on cloud platform stores real-time long series ground historical data图1 基于云平台的地面实时历史长序列统计数据库

Fig.2 Data decomposition and identification process of arbitrary data statistical method图2 任意数据统计方法资料分解判识流程
2 技术应用情况
2.1 检验数据、环境及方法
从时间跨度和并发数两个角度来评估查询时效,分别调用原关系型数据库(SQL Server)和云关系型数据库,采用平均耗费时间统计方法对两种数据环境查询效率进行对比和评估。
检验程序运行于内网服务器,服务器基本硬件配置为:2.5GHz CPU,64G 内存,操作系统Windows 64 位。
2.2 不同时间跨度分析
为检验不同时间跨度任意时段数据的查询效率,设定3 种业务中常用的查询个例进行对比分析。查询要素选择气温、雨量、风向风速、气压、湿度、能见度等常用要素,统计量包括最大值、最小值、累计量、日数、排名等,每次查询同一条件均重复10 次,取10 次平均耗时作为这一条件的最终耗时进行计算。
2.2.1 历年统计值查询
初始日期设定为1 月1 日,以10 天为增长单位确定循环的结束日期,查询每个时间段内区域站历年(2004-2020年)统计值,结果如图3 所示(彩图扫OSID 码可见,下同)。原关系型数据库查询平均耗时随时间跨度递增,由0.78s 增加至3.05s,而云关系型数据库任意时段的时间跨度查询耗时均保持在0.6~0.8s 之间,可见云关系型数据库性能较好,文中提出的任意时段数据统计方法效果明显。

Fig.3 Map comparison of query time for statistical values over the years图3 历年统计值查询耗时对比
2.2.2 任意时段30 年统计值查询
初始日期和增长单位同上,查询每个时间段内国家站30 年(1981-2010 年)统计值。数据量由国家站站数×天数×30 年=75×10×30=22 500 增加至75×360×30=810 000,是初始时段的36 倍。通过图4 可以得到类似结论,查询原关系型数据库平均耗时突变次数较多,呈缓慢递增趋势;而云关系型数据库查询返回结果的时间介于0.01~0.03s 之间,稳定性较好。

Fig.4 Map comparison of query time of 30-year statistical value in any period图4 任意时段30 年统计值查询耗时对比
2.2.3 任意时段统计值查询
初始日期设定为2008 年1 月1 日,以30 天为增长单位确定循环的结束日期,查询每个时段内区域站统计量。2008 年区域站站点数×天数=1 045×30=31 350,2020 年区域站站点数×天数=3 400×30×150=15 300 000,后者约增长488 倍。从图5 可以看出,原关系型数据库平均耗时起初突变次数较多,随后平缓增长至0.72s;而云关系型数据库平均耗时保持在0.1~0.3s 之间,并未随着数据量的骤增发生明显变化。通过对比两个数据库的耗时可以发现,云关系型数据库对提升数据统计效率作用非常明显。

Fig.5 Map comparison of query time statistics in any period图5 任意时段统计值查询耗时对比
2.3 不同并发数分析
以极端天气多用户查询进行实验,在10、50、100、500、1 000 不同用户数情况下,为了尽量使两者测试环境一致,分别在原关系型和云关系型数据库中设定相同的统计任务,记录并发访问数据库响应时间。图6 为并发访问数据库性能对比情况。
并发数为10 时,原关系型和云关系型数据库平均耗时分别为101ms 和33ms;并发数增长至1 000 时,两者分别为6 429ms 和592ms。由此看出,应用云分布式存储技术,在高并发情况下,数据量越大,云关系型数据库性能提高越明显,本例提升了1 个数量级,较好满足了高并发统计数据需求。

Fig.6 Map comparison of query time in different concurrency图6 不同并发数查询耗时对比
3 结语
本文利用云关系型数据服务建立了地面实时历史一体化长序列统计应用数据库,并实现了任意时段数据统计方法。分布式数据服务的应用不仅缓解了单台数据库服务器的运行压力,还满足了用户实时高并发访问需求,实现了硬件资源利用最大化。以日、月为统计单位,提出的任意时段数据统计方法能够进一步提高统计效率,且统计耗时不会随着数据量的增大出现明显变化。该研究成果通过气象云大数据平台数据服务系统提供数据服务,为浙江气象防灾减灾决策服务平台等多个业务系统提供云数据支撑,应用效果良好,对相关平台开发具有一定的指导作用。随着气象业务的快速发展,对于数据查询服务的时效性要求会越来越高,数据的高效存储和个性化服务仍需不断完善,以满足更高的业务需求。
