全国高职专业点数据爬虫的设计与实现
2021-07-31邓子云
邓子云
(长沙商贸旅游职业技术学院 湘商学院,湖南 长沙 410116)
为能用大数据技术分析全国高等职业教育(以下简称“高职”)专业点布局的规律与存在的问题,需要先获得全国高职专业点的设置数据。在全国职业院校专业设置管理与公共信息服务平台(http://zyyxzy.moe.edu.cn)中,已经收集了全国高职专业点设置的数据和专业名录,该平台中的数据面向互联网公开。因此,可以设计出一种爬虫来爬取这些数据。
一、爬虫的架构设计
爬虫的架构设计包括功能架构和技术架构两个部分[1]。目前关于爬虫的设计已有成熟稳定的框架系统,因此没有必要再从技术底层开始全面开发爬虫[2]。可供选择的爬虫框架系统有基于Java语言的Crawler4j[3]、基于Python语言的Scrapy[4]。考虑到后续作大数据处理仍然采用Python语言,且Python语言开发简便、快捷,因此选用Scrapy作为爬虫开发的框架[5]。
(一)功能架构
从功能需求出发,结合Scrapy框架,应当实现如图1所示的功能:1.需要爬取专业设置点的数据;2.需要爬取专业名录数据;3.需要对爬行过程中的异常作出处理;4.为应对反爬虫系统需要作爬虫伪装;5.将爬取的数据存储到数据库中;6.设计并实现高职专业数据库系统。

图1 爬虫的功能架构
(二)技术架构
爬虫在爬取网站(http://zyyxzy.moe.edu.cn)的页面数据后,用XPath表达式[6]从网页中提取到专业点和专业名录数据,填充到数据项SpecialitiesItem和数据项SpecialitiyDictItem中,这两个数据项分别表示专业点和专业名录。再通过项目管道SpecialityDataPipeline将数据项中的数据存储到数据库的表中。
从技术架构来看,Scrapy核心引擎、调度器、下载器、爬虫的爬行功能在技术上不需要再行开发[7],利用Scrapy框架中已有的功能模块即可。结合爬虫的功能架构和技术架构,还应在技术上实现以下技术模块(见图2):

图2 爬虫的技术框架
1.高职专业数据库
设计Specialities表、SpecialitiyDict表等的ER(Entity Relation)关系,并用SQL(Structed Query Language)语句完成表创建、记录插入、记录修改、记录删除等操作。数据库采用了SQL Server 2017。
2.项目管道
项目管道(SpecialityData Pipline)用于封装对数据库的操作,在其中要设计并实现设置数据库的连接参数、用连接池获得数据连接、释放数据库连接、执行SQL语句等功能[8]。
3.数据项
数据项(SpecialitiesItem和SpecialityDictItem)用于封装由爬取到的数据构成的数据结构,常用一个数据项来对应数据库中的一个表。
4.网站爬虫
通过设定爬虫(CrawlPages Spider)的爬取方向,可分别爬取专业设置点和专业名录数据。
5.异常处理中间件
中间件(ExceptMiddeware)对Scrapy框架捕获到的各种异常进行处理[9]。
6.伪装中间件
中间件(AgentMiddeware)将爬虫伪装成各种浏览器爬取数据。
7.Scrapy配置
对Scrapy框架进行配置,主要配置项包括数据库连接参数、异常处理中间件的类等[10]。
二、数据库设计与实现
从前述分析来看,关键的两个数据表是专业点设置表、专业名录表,再看这些表中哪些数据可以作分类或用数值代替字符串,以降低存储并提升数据的范式。为此,设计ER图如图3所示。
(一)ER图
从图3可以看出,数据库中设计了6个表,表与表之间存在依赖关系。专业点表中记录了编号、专业点设置的省份代码,以及设置专业点的学校的代码、专业代码、专业学习年限、专业点备案年份等字段。专业点表通过专业代码与专业名录表关联,通过设置专业点的省份代码与省份表关联,通过设置专业点的学校的代码与学校表关联。
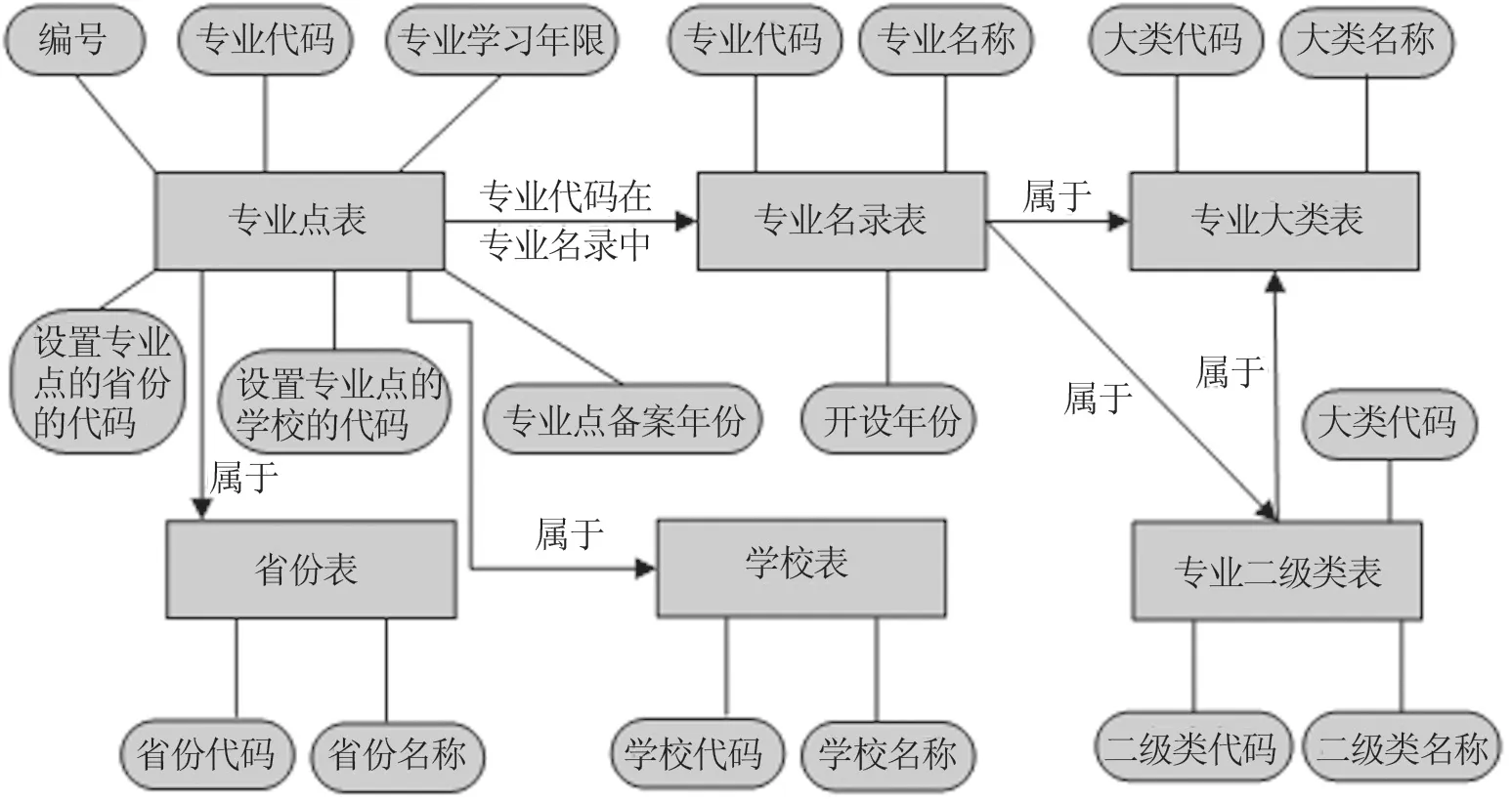
图3 ER图
专业名录表中的专业代码可以拆分成大类、二级类和二级类中的专业编号,该表中还有专业名称和开设年份字段。因此通过专业代码可以关联专业大类表、专业二级类表,一个专业二级类又属于某一个专业大类。
(二)表及其字段
根据图3所示的设计思路,可设计出SQL Server 2017中的表,如表1所示。
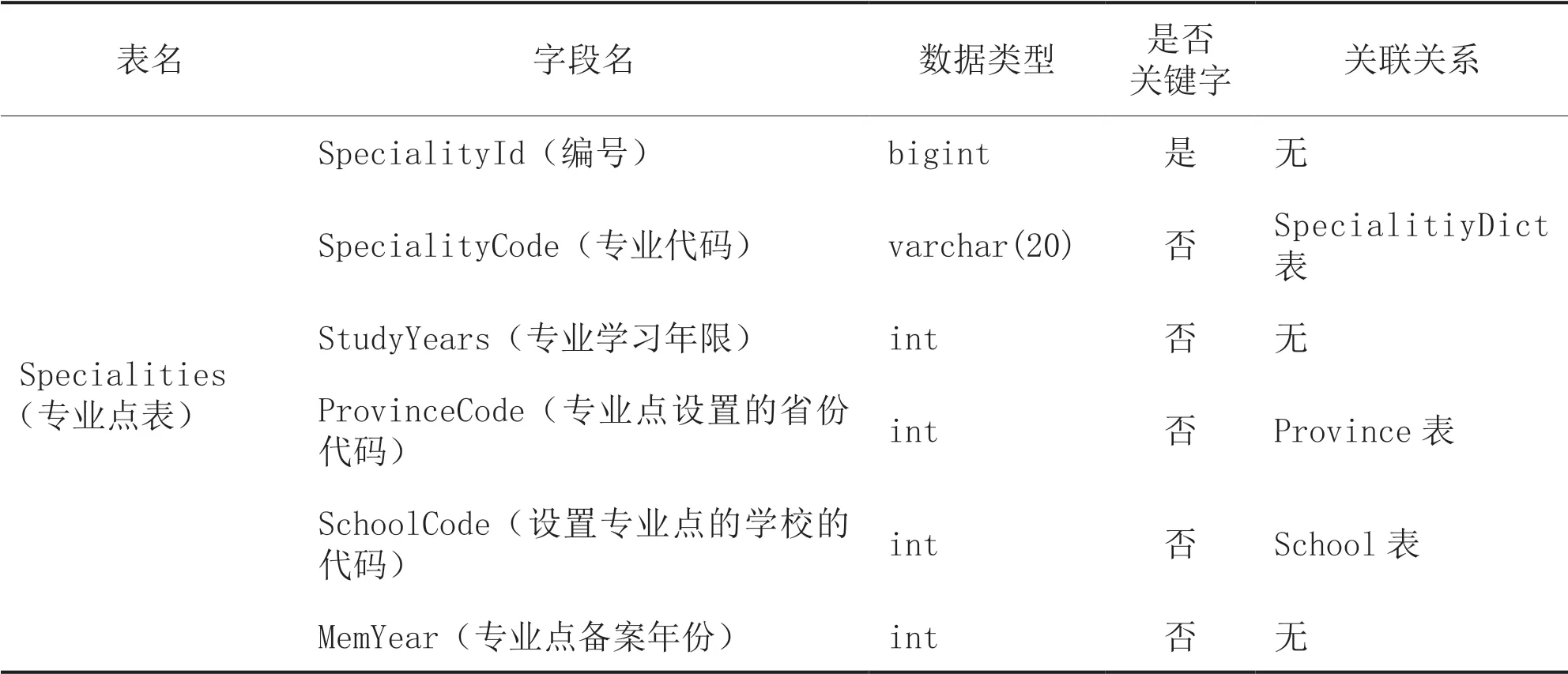
表1 SQL Server 2017中表的实现
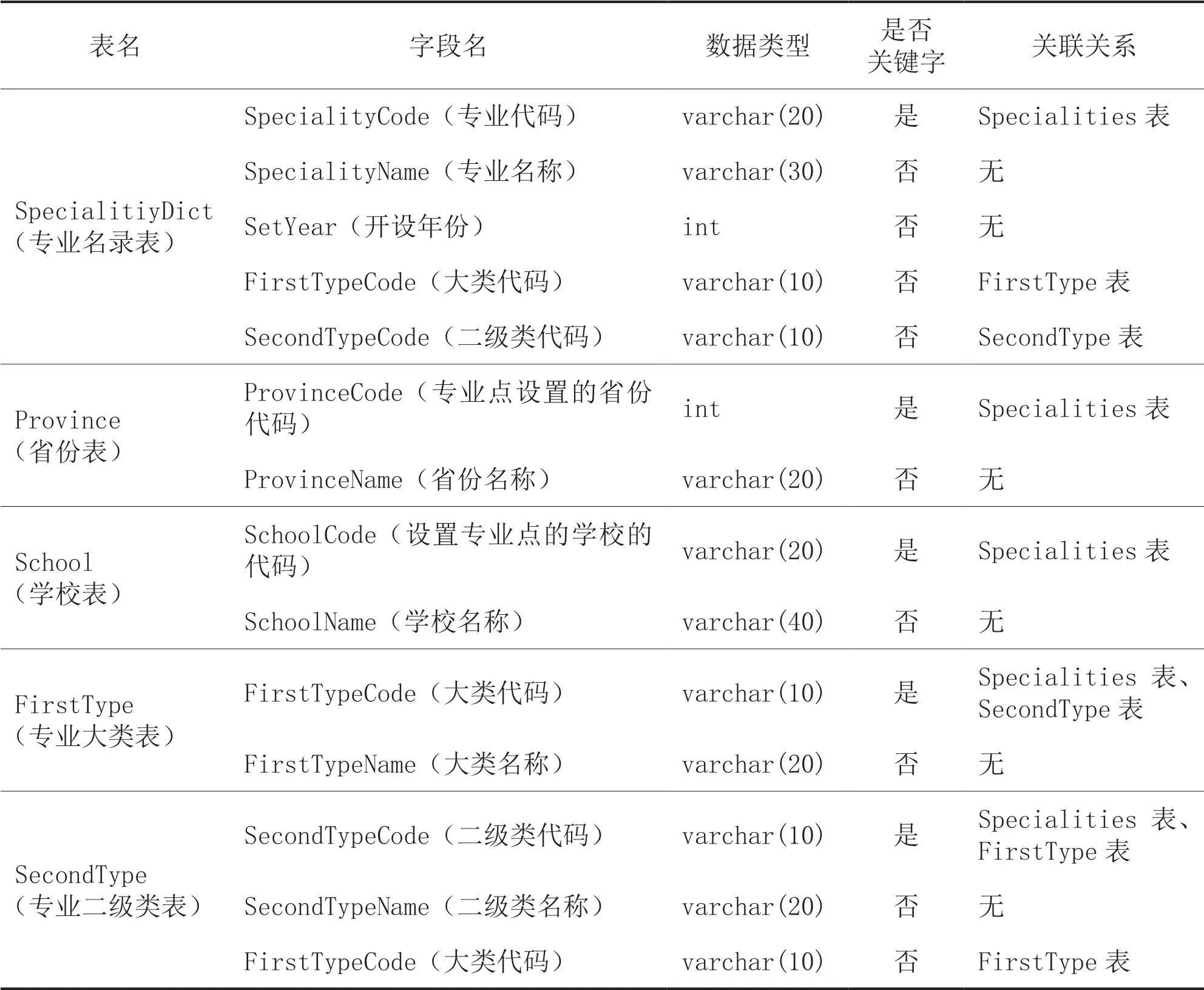
续表
三、爬虫的设计与实现
根据前述技术架构的设计,爬虫还需要设计与实现项目管道、数据项、网站爬虫、异常处理中间件、伪装中间件,并对这些技术模块作出配置。
(一)项目管道
在项目管理中可使用twisted.enterprise的adbapi模块[11]来作数据库的建立连接、关闭连接操作,以及执行SQL语句(包括插入、增加、删除、修改)操作。
应在启动爬虫时建立数据库连接池,代码如下:

应在关闭爬虫时关闭数据库连接池,代码如下:

应在项目管道收到数据项后,即可调用执行插入数据库数据的代码:


(二)数据项
数据项封装了从网页中爬取的数据,并可用于通过项目管道操作数据库中的数据[13]。为简化起见,只需要设计实现2个数据项即可,即数据项SpecialitiesItem和数据项SpecialitiyDictItem。这两个数据项的代码如下:


(三)网站爬虫
为了爬取网站中的数据,需要专门设计一个爬虫类。这个爬虫类中的代码相对其他技术模块的代码较为复杂。
要爬取专业点的设置数据,可分析其网址(http://zyyxzy.moe.edu.cn/mspMajorRegisterActi on.fo?method=index&startcount=100),如图4所示。

图4 要爬取数据的页面
在网址中通过startcount参数表示当前页的专业点数据的起始号,每页显示100条专业点数据。但还有年份参数是通过表单提交的。因此不仅要在网址中带入每页数据的起始号,还需要生成一个表单,在表单中设置专业备案的年份。
爬取2016—2020年专业点数据的代码如下:



在返回数据项后,Scrapy框架会自动通过项目管道向数据库中作数据操作。
要爬取专业名录的数据,相对爬取专业点的设置更为简单。
在专业名录网址(http://zyyxzy.moe.edu.cn/msp MajorGzAction.fo?method=list&startcount=100)中通过startcount参数表示当前页的专业点数据的起始号,每页显示100条专业点数据。专业名录的网页无需用表单来提交数据,也不需要传入年份参数。考虑相对较为简单,不再赘述和重复列出爬取专业名录数据的源代码。
(四)异常处理中间件
爬取处理中间件的作用是及时捕获异常并报错,但并不中止爬虫的运行。要处理的异常如下:

(五)伪装中间件
比较简单的实现伪装中间件的做法是用一个集合列出所有准备伪装的浏览器的名称:


然后再随机的选择其中的一个浏览器名称,放入到请示页面时的头部中:

四、爬取效果
使用爬虫爬取到了全国职业院校专业设置管理与公共信息服务平台中2016—2020年的专业点设置数据和专业名录数据,其中专业点设置数据如图5所示,总共爬取到275,873条专业点设置数据和770条专业名录数据。

图5 全国专业点的数量和增长率
以爬取的数据为基础,可以进一步开展全国专业点布局的大数据分析。下面给出两个分析示例。
(一)全国专业点布局
可根据爬取到的各省设置专业点的数量情况得出布局的一些明显规律。其中,2020年全国形成了“三核一X”的形态,即三个专业点核心圈为四川、广东、四省(江苏、安徽、山东、河南),一个“X”形状的隔离带把三个核心圈隔离开来。
(二)专业点集中度
经大数据分析发现专业点数高度集中。排名前50名的专业的专业点数占所有专业的专业点总数的比例在2020年为50.97%,其中排名前10名的专业如表2所示。在2020年总共有779个专业,前50名的专业的专业点数就超过了一半,6.42%的专业的专业点数占了所有专业点总数的50.97%。

表2 2020年点数排名前10名的专业
2020年,在779个专业中,全国有216个专业的专业点数低于或等于5个,这216个专业中有41个专业已没有专业点,41个专业的专业点数仅1个,33个专业的专业点数仅2个。
五、结语
从全国高职专业点设置数据爬虫的设计与实现来看,使用Scrapy框架研发的爬虫系统代码简洁,不需要再行开发下载网页、下载调度等方面的功能,可以让研发人员有更多的精力专注于业务相关的代码的研发。该爬虫在功能架构上有6个功能模块的需求,在技术架构上实现了7个技术模块,在数据库中用6个表来存储数据,设计与实现了项目管道、数据项、网站爬虫、异常处理中间件、伪装中间件等技术模块。该爬虫总共爬取了275,873条专业点设置数据和770条专业名录数据,用来作全国专业点布局的大数据分析。
