基于机器学习的网络入侵检测方法研究
2021-07-30魏嘉昕
魏嘉昕
(华东交通大学,江西 南昌 330000)
0 引 言
随着信息和网络技术的发展和普及,网络信息安全变得越来越重要。与传统的网络防御技术相比,智能入侵检测系统能够主动拦截和警告网络入侵,具有很大的实用价值。如何提高智能网络入侵检测的有效性已经成为网络安全的一个焦点[1]。目前,使用智能入侵检测系统被视为网络安全和抵御外部威胁的有效解决方案。然而,现有的入侵检测系统在新的攻击下往往检测率较低,在处理审计数据时开销较大,因此机器学习方法在入侵检测中得到了广泛应用。机器学习技术之一的SVM是一种基于统计学习理论的新算法,在解决模式识别和语音识别的分类问题上比传统的学习方法有更高的性能[2]。然而,随着大数据时代的到来,SVM遇到了训练和测试时间长、错误率高以及真阳性率低的问题,这限制了其在网络入侵检测中的使用。
在基于SVM算法对入侵检测问题的研究中,Belkin M等人提出拉普拉斯结合SVM,将流形正则化项运用到传统的SVM中,最后利用表象定理将其转化为求解二次规划问题,但实际生活应用中线性分类器远远不够[3]。Yang G等人设计了一种基于最小二乘法的入侵检测方法,以提高SVM在复杂非线性系统中的检测能力,然而算法的训练和测试时间相对较长[4]。Chen Z等人提出了粗粒度并行遗传算法来同时优化SVM特征子集和参数,提出了一种新的适应度函数,该函数包括分类精度、特征数以及支持向量数,但训练SVM需要很长时间[5]。在该方法中,启发式遗传算法被用于优化SVM核参数,通过启发式策略动态调整遗传算子,以模型的分类精度为目标函数,实现基于高斯核SVM分类模型的参数优化。然而,这种方法没有考虑特征加权对SVM检测精度的影响。
遗传算法通过种群搜索策略和个体间的信息交换表现出优异的全局优化能力,被选为在大空间中搜索的最强大工具之一,有可能在搜索空间中找到最佳解[6]。本文将在SVM的基础上结合遗传算法提出一种改进的网络入侵检测方法,使其具有更好的判别能力,对入侵检测系统具有更高的真检测率和更低的误报率。
1 支持向量机SVM
SVM最早由瓦普尼克于1995年提出,是一种基于统计学习理论的新机器学习方法[7]。其思想是通过一个映射函数将输入映射到一个更高维的特征空间,并在这个空间中构造一个最优的分离超平面。其中,映射函数不是以显式的形式给出,而是通过指定一个核函数作为这个空间中每对点之间的内积来隐含地给出。
假设一个有N数据的训练集二元分类问题,其中xi表示输入,yi表示相应的输出值,则有:

对于非线性情况,首先将原始数据xi非线性映射到高维特征空间H,并将映射函数表示为f(x),即在这个特征空间中解决一个线性分类问题,使其数据样本之间的距离尽可能达到最大[8]。
由于直接求解超平面和偏置项比较困难,便引入非负松弛因子ξi和惩罚系数C,将其转化成一个优化问题,通过最小化正则风险函数来估计,具体为:

预先选择惩罚参数C>0,以控制分类余量和错误分类误差成本。为了对该优化问题求解,引入拉格朗日乘子αi,对上式(2)转化为对偶问题得到:

式中,K(xi,yi)为核函数,需要同时满足的条件为,其中0≤αi≤C,i=1,2,…,N。
2 遗传算法GA
遗传算法是一种基于自然选择理论的生物进化模型或抽象算法,是进化的模拟,通过种群搜索策略和个体间的信息交换表现出优异的全局优化能力。与传统的多点搜索算法不同,遗传算法容易避免局部最优,主要由选择、交叉、变异以及抽样4个基本部分组成。其算法流程如图1所示。

图1 遗传算法流程图
遗传算法中的选择是为了寻找更好的个体,保持种群的多样性。根据目标函数值选择个体进行繁殖的机制,交叉合并两者之间的个体遗传信息。其中遗传物质可能会因繁殖或基因的变形而随机改变,但变异所表现的效果是积极的,可以避免局部最大值。最后根据前一代及其后代计算新一代的程序[9]。与传统的连续优化方法相比,二者的区别如下。一是遗传算法以编码的方式工作,而不是参数本身,具有良好的可操作性;二是传统方法都是从一个点开始搜索的,而是遗传算法总是在一组点上运行,具有较好的鲁棒性,提高了达到全局最优的机会,降低了陷入局部静止点的风险;三是遗传算法不需要使用任何关于目标函数值的辅助信息,可以应用于任何类型的连续或离散优化问题,但需要指定一个有意义的解码函数;四是遗传算法使用概率转移算子,而传统的连续优化方法使用确定性转移算子。更具体地说,从实际的一代计算新一代的方式有一些随机成分,用概率性传递规则代替确定性规则,具有全局寻优特点。
3 基于GA-SVM的改进入侵检测方法
3.1 基本体系结构
该算法主要由两步组成,第一步采用遗传算法包装器特征选择方法为每类攻击选择最优特征进行训练,第二步采用多SVM分类器,每个分类器检测一类攻击。每个攻击分配一个不同的分类器,并使用所提出的文件系统技术选择每个攻击数据的特定特征进行训练。分类器是线性排列的,每个分类器都是根据攻击的严重程度放置的。对于每个分类器,其输出要么属于攻击组,要么属于非攻击组,但新类别最后一个分类器的输出除外。如果数据被归为攻击类别,那么分类器将对报告用户进行进一步处理,否则它会将输入数据转发给下一个分类器来确定类别,这个过程一直持续到输入数据类别被确定。基于GA-SVM网络入侵系统的体系结构如图2所示。

图2 基于GA-SVM的网络入侵系统的体系结构
在该体系结构中,主要由基于遗传算法和SVM的特征选择、基于遗传算法和SVM的特征加权和参数优化、训练以及分类4部分组成,具体介绍如下。
一是基于遗传算法和SVM的特征选择。输入网络流量数据,创建特征染色体,根据本文提出的适应度函数对染色体进行评价,选择适应度函数值最大的染色体作为最优染色体,解码最佳特征子集。二是基于遗传算法和SVM的特征加权和参数优化。根据最佳特征子集创建特征和SVM参数染色体的权重。通过评估具有最高分类精度的染色体并选择它作为最佳染色体,解码最佳SVM参数和特征权重。三是训练。将原始数据随机分成大小相同的k份子集,并保留这k份子集,将其中k-1个子部分被用作训练支持向量机的训练数据。四是分类。保留的k个子部分被分类为测试数据和预测结果。其所有测试集都是独立的,可以提高该训练结果的可靠性。
3.2 数据来源
本文中的实验数据来自KDD Cup99数据集,该数据集是网络入侵检测研究中最常用的数据集[10]。由于该数据集的数据量较大,会导致训练过程耗费时间较长,因此从该数据集中随机选择一定数量的数据进行研究分析。与此同时,该数据集包含5种数据类型,分别为正常记录(Normal)、拒绝服务攻击(DOS)、监视和其他探测活动(Probe)、来自非远程机器的非法访问(R2L)以及普通用户对特权的非法访问(U2R),其中有4种为攻击类型数据。
该实验基于遗传算法和SVM算法对网络入侵检测系统进行优化。其中涉及到许多参数的设置,这些参数对实验效果起着非常重要的影响,如交叉和变异概率会随着迭代次数而变化。合适的适应度函数有助于遗传算法更有效地探索搜索空间等。本文算法的参数设置如表1所示。

表1 基于遗传算法和SVM参数设置
4 实验结果和分析
本文提出了基于遗传算法的SVM两步优化方法,为了验证该方法在网络入侵检测的有效性,分别在通过训练集上实现了BP算法、SVM算法以及SVM-GA算法。计算比较假阳率(False Positive Rate,FPR)、真阳率(True Positive Rate,TPR)以及正确检测率(Correct Detection Rate,TDR)3个指标[11]。其中,FP是实际类别为阳性的错误样本个数,TP是实际类别为阳性的正确样本个数,TN是实际类别为阴性的正确样本个数,FN是实际类别为阴性的错误样本个数。
FPR是指分类器在实际类别为阳性的所有样本中错误预测的样本比例,计算公式为:

TPR是指分类器在实际类别为阳性的所有样本中正确预测的样本比例,计算公式为:

TDR是指分类器在所有预测类别为正的样本中正确分类的样本比例,计算公式为:

BP算法、SVM算法以及SVM-GA算法最终的假阳率、真阳率和误报率比较结果如表2所示。
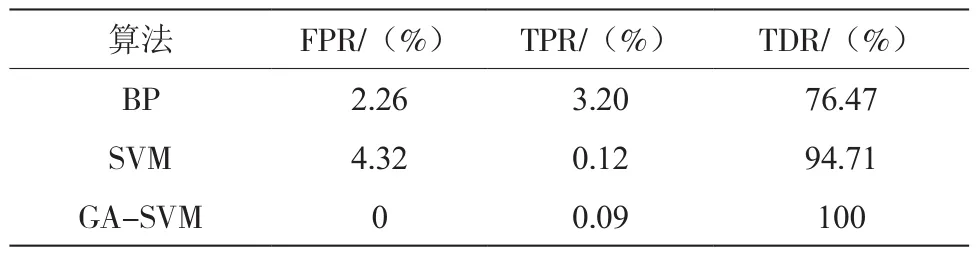
表2 算法性能比较
分析拒绝服务攻击(DOS)、监视和其他探测活动(Probe)、来自非远程机器的非法访问(R2L)以及普通用户对特权的非法访问(U2R)4种攻击类型,其结果如图3所示。

图3 不同类型攻击检测结果比较
5 结 论
本文提出了一种基于遗传算法和SVM的网络入侵检测算法。首先,通过优化遗传算法的交叉概率和变异概率,有效利用遗传算法的种群搜索策略和个体间的信息交换能力。该算法加快了收敛速度,提高了SVM的训练速度。其次,提出了一种新的适应度函数,可以降低SVM误差率,提高真阳性率。最后,同时优化核参数、惩罚参数以及特征权重,提高SVM滤波的精度。实验结果表明,本文提出的基于遗传算法和SVM的改进入侵检测技术在同等条件下与基于神经网络算法的网络入侵检测系统和基于SVM算法相比,提高了入侵检测率和真阳性率,降低了假阳率。
