多源末制导弹载融合图像目标检测研究进展
2021-07-30钱立志杨传栋
薛 松,钱立志,张 航,杨传栋
(1 陆军炮兵防空兵学院兵器工程系,合肥 230031;2 陆军炮兵防空兵学院高过载弹药制导控制与信息感知实验室,合肥 230031;3 陆军炮兵防空兵学院研究生队,合肥 230031)
0 引言
图像末制导是现代精确制导技术的重要组成部分,不仅能够提高武器系统的命中精度,提升作战效能,而且可以提高战场感知和毁伤效果评估的智能化水平。
目前图像末制导技术经历了单模制导和多模复合制导两个阶段[1]。单模制导普遍采用的制导方式有电视制导、红外成像制导和雷达成像制导等[2]。电视制导为可见光图像,分辨率高,但易受天气条件影响;红外成像由于靠温度差探测,因而适合在夜间工作,并且能够识别一定条件下的伪装目标,但红外图像对比度低,视觉效果较差;雷达成像制导主要有微波、毫米波和激光雷达制导[3],毫米波的大气衰减小,穿透性好,受天气影响较小,具有全天候工作能力[4],但是毫米波波束窄,不适于大范围搜索。因此利用可见光、红外、毫米波等单模制导的各自特点,将其两两或三者结合,充分发挥各自优势,取长补短,形成多源图像末制导,获取多源末制导弹载图像,提高对目标的打击能力,具有较大的研究价值与应用前景。
目前大量的研究主要集中在编码压缩[5]、增强、校正[6]、消旋[7]及拼接[8]等方面[9],或是仅研究多源图像融合方法或单一类型图像的目标检测技术,如文献[10]提出了一种高性能弹载图像融合导引系统并进行了相关研究;文献[11]提出了弹载可见光与红外图像融合算法;文献[12]提出了一种YOLO3改进的弹载图像目标检测算法;文献[13]提出了一种基于CNN的弹载图像目标检测方法;文献[14]提出了针对运动目标的红外图像末制导跟踪算法;文献[15]提出了针对电视制导图像的局部特征检测与匹配算法。而针对多源末制导融合图像的目标检测类问题研究较少。
文中依托项目课题,根据多源末制导弹载融合图像目标检测中需要的关键技术,对图像融合技术和目标检测技术进行综述,重点介绍相关网络框架和优缺点并对未来可能的发展方向进行展望。
1 末制导弹载图像
末制导弹载图像与一般成像平台获取的图像有很大不同,弹丸在飞行过程中姿态变化较大。当弹丸命中精度距目标中心圆概率误差达到一定范围内时,图像导引头开始工作并将目标区域内图像通过弹载图像发生机和发射天线发送回地面站。当弹体高度距离地面一定距离时,弹体进入末制导阶段,导引头对场景目标自动检测识别辅助地面操作手进行目标捕获,从而引导控制弹丸最终命中目标,如图1所示为末制导成像工作过程。在成像过程中,导引头易受外部条件的干扰,获得的图像背景变化快,存在尺度变化以及各种噪声干扰,易发生各种偶然性降质等因素,会极大影响成像结果,如图2(a)、图2(c)所示,且在雨雪烟尘等低能见度条件下往往会影响其成像效果。这些干扰因素在影响成像效果的同时也为后续场景目标检测带来困难。此外战场目标类型多样,如图2(b)所示,针对重点目标和目标重点部位检测也是急需解决的困难。因此需要设计适合多源末制导弹载图像的图像融合算法以及针对融合图像的目标检测算法。

图1 末制导成像工作过程

图2 末制导弹载图像
目前大多数图像融合和目标检测算法针对的目标场景多为自然图像或民用领域,涉及到末制导弹载图像及军用领域研究较少。为此文中首先概述经典的多源图像融合法方法和目标检测算法,并进行对比分析,然后对已有研究的弹载图像算法进行综述。
2 多源图像融合方法
多源图像融合是指采用不同类型图像传感器获得同一场景图像,通过图像处理等方法获得信息较为完整,易于后处理的图像。多源图像融合始于20世纪80年代的基于金字塔变换方法[16],此后多国学者的大量研究提出的多源图像融合方法大致可分为3类:基于变换域的图像融合方法、基于空域的图像融合方法和基于深度学习的图像融合方法。
2.1 基于变换域的图像融合方法
由于小波变换能获得较好的融合效果,因此研究者对其进行了大量研究,提出了基于多小波变换[17]、复小波变换[18]等一系列基于小波变换的图像融合方法。此外,研究者们还利用独立主成分分析[19]、高阶奇异值分解[20]、鲁棒性主成分分析[21]、稀疏表示[22]等方法提升融合后的图像效果,新思想新方法的提出促进了图像融合的发展。
2.2 基于空域的图像融合方法
基于空域的图像融合方法直接在空域上对图像进行融合处理。文献[23]借助分块理论提出的方法获得了较好的融合效果。此后研究者们利用其他方法也较好解决了图像融合问题,如文献[24]和文献[25]提出多聚焦的图像融合方法;文献[26]提出的基于旋转引导的图像融合方法。
2.3 基于深度学习的图像融合方法
卷积神经网络(convolutional neutral networks,CNN)的快速发展和良好应用使得研究者们考虑利用CNN解决多源图像融合的方法。如文献[27]利用深度卷积神经网络解决了多聚焦图像融合问题。文献[28-29]借助深度学习理论解决了红外与可见光图像融合问题;文献[30]研究了高光谱图像融合问题。以上方法均不是端到端的模型。文献[31]研究了一种端到端的基于卷积网络的无监督模型,取得了较好的融合效果。
3 目标检测方法
目标检测即找出图像中所有感兴趣的物体并框选物体的类别和位置。传统的目标检测算法对选取的区域进行特征提取并回归,这些方法计算时间长、运行效率低,逐渐被基于深度学习的目标检测算法取代。目前主流的基于深度学习目标检测算法根据是否需要生成候选框可分为两类:双阶段目标检测算法和单阶段目标检测算法。
3.1 双阶段目标检测算法
双阶段目标检测算法由候选区域获取和目标识别定位两个步骤组成。该类算法的代表有:R-CNN,SPP-Net,Fast R-CNN,Faster R-CNN等。这些算法检测精度普遍较高,但网络结构复杂,计算任务量大,检测效率低下,难以满足检测实时性需求。
3.1.1 R-CNN
R-CNN(regions with convolutional neural network features)模型由Girshick等[32]于2014年提出,该模型虽然首先将卷积神经网络应用于目标检测,但并非纯粹神经网络方法,而是用卷积神经网络代替手工提取特征,模型结构如图3所示。R-CNN主要分为3个阶段:首先利用选择性搜索算法在图像中提取2 000个左右的候选区域,并将每个候选区域缩放成统一的227×227像素,其次利用AlexNet对候选区域提取特征向量并入到SVM进行分类,最后对目标候选区域进行优化和输出。
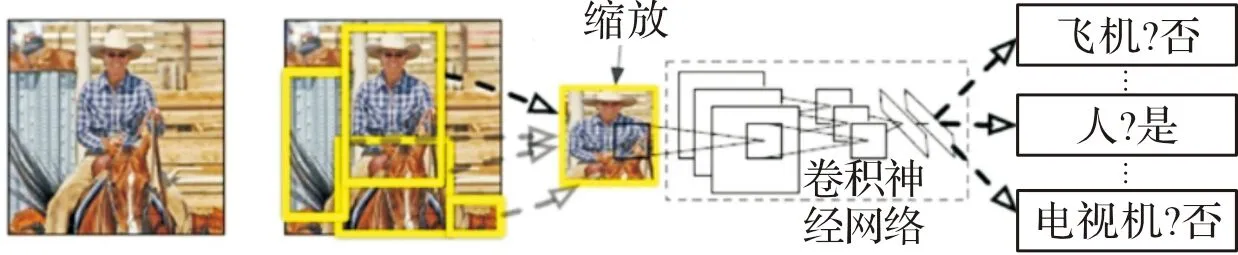
图3 R-CNN网络结构图
R-CNN的提出使得目标检测取得巨大突破,并开启了基于深度学习目标检测的热潮,但仍然存在不少弊端,R-CNN流程的第一步中对原始图片通过选择搜索提取的候选框多达2 000个左右,而这2 000个候选框每个框都需要进行CNN提取特征及SVM分类,计算量很大,导致R-CNN检测速度很慢。
3.1.2 SPP-Net
针对R-CNN网络全连接层输入的固定尺度问题,2014年He等[33]提出了SPP-Net(spatial pyramid pooling convolutional networks)网络,该网络不局限于图像的尺寸,而是对任意输入以固定尺寸进行输出。网络将空间金字塔池化层放在最后一个卷积后,并对特征进行池化,并以固定长度供给全连接层。网络结构如图4所示。
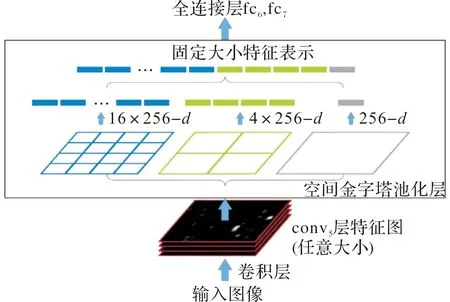
图4 空间金字塔池化层结构图
虽然SPP-Net网络通过简化操作使检测速度得到了很大提升,但该网络的训练仍然分为多个阶段,并存在生成候选区域,步骤繁琐。
3.1.3 Fast R-CNN
Fast R-CNN[34](fast region-based convolutional neural network)将SPP层简化为RoI(region of interest)Pooling层,该层是一个只有一层的金字塔池化层,并仅需要下采样到一个7×7的特征图,可实现特征的重复利用。此外,Fast R-CNN在分类任务上采用softmax和Smooth L1替代SVM,统一了算法框架,使整个训练过程是端到端的。Fast R-CNN目标检测的过程如图5所示。
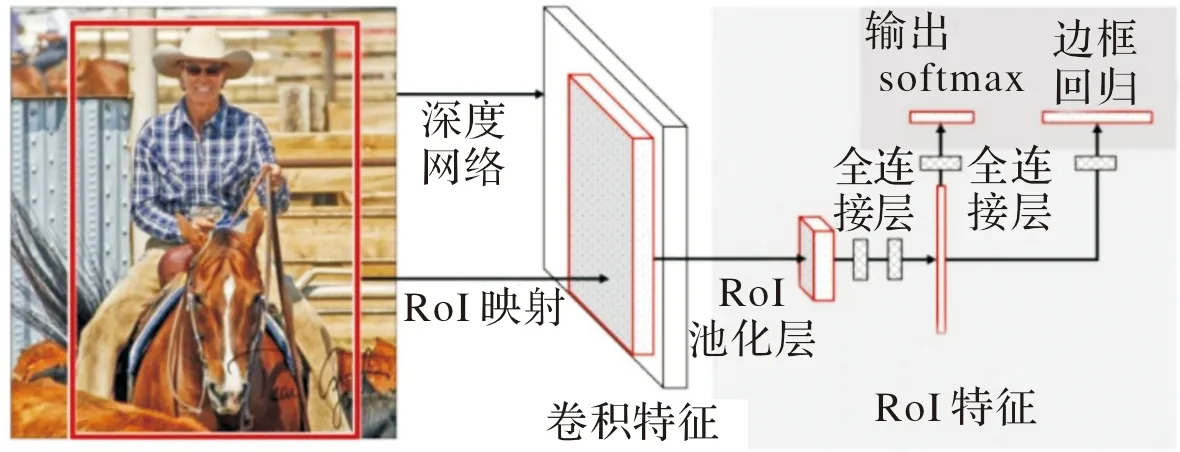
图5 Fast R-CNN网络结构图
Fast R-CNN在检测精度和检测速度上都有所提升,这一算法的成功提出使得研究者们考虑选择搜索+CNN框架,在保证准确率的同时提升处理速度,也为后来的Faster R-CNN铺垫。
3.1.4 Faster R-CNN
针对R-CNN,SPP-Net,Fast R-CNN网络均需使用选择搜索算法选取候选区域而造成算法运行速度较慢问题,Ren等[35]2016年提出了Faster R-CNN网络(faster region-based convolutional neural network),创新性的使用了区域生成网络(region proposal networks,RPN)代替了选择搜索算法,实现了卷积神经网络端到端的处理过程,同时引入锚框作为初始候选区域应对目标形状的变化问题。整个模型可以分为区域生成网络和Fast R-CNN检测网络两大模块,如图6所示,其中区域生成网络的工作原理如图6(a)所示。
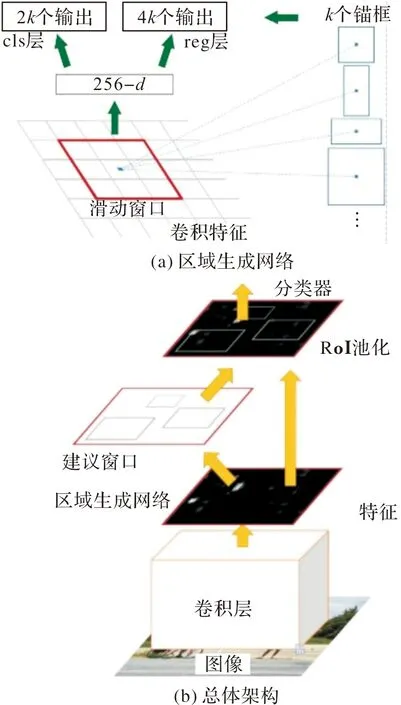
图6 Faster R-CNN网络结构图
RPN的使用使得Faster R-CNN网络提高了算法的精度和速度,但网络依然使用了RoI Pooling层,计算繁琐。由于使用了不同尺度的锚点,在映射到原图时可能会造成目标尺寸改变,对小目标检测效果不好。
表1对上述R-CNN,Fast R-CNN,Faster R-CNN三种框架进行了总结,表2给出了双阶段目标检测算法的速度对比,其中mAP(mean average precision)为平均精度均值。

表1 双阶段目标检测框架总结
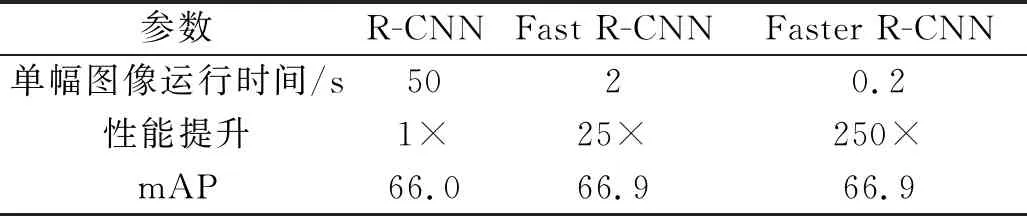
表2 双阶段目标检测框架速度对比
综上所述,随着R-CNN,SPP-Net,Fast R-CNN,Faster R-CNN等算法的不断发展,基于深度学习目标检测算法的检测精度和运算速度都有所提升。因此基于R-CNN的框架仍然是当前主流目标检测算法的重要组成部分。
3.2 单阶段目标检测算法
与双阶段目标检测算法不同,单阶段目标检测算法利用了回归的思想,直接将整张图作为网络的输入,在图像的多个位置上进行均匀抽样并利用卷积神经网络提取特征后直接参与分类与回归,确定目标所属的类别。由于采样导致的样本不均衡造成该类算法的精度下降,典型算法有:YOLO系列、SSD等。
3.2.1 YOLO
2016年Redmon等[36]深入分析了双阶段算法存在的候选区域网络造成目标检测算法实时性差的原因,提出一种新的目标检测算法YOLO(you only look once)。YOLO算法省略候选区域网络,利用整张图作为网络的输入直接进行预测,具体实现过程为:
1)将一幅图像分成S×S个网格(grid cell),每个网格对应特征图中的一个点,负责检测中心点落在该网格内的目标。
2)每个网格要预测B个边界框,每个边界框除了要回归自身的位置之外,还要附带预测置信度值。因此每个边界框包含(x,y,w,h)和置信度共5个值。此外每个网格还要预测目标的类别信息,记为C,表示包含此类目标的概率。
3)将每个网格预测的类信息和边界框预测的置信度信息相乘,就得到每个边界框的预测结果。
4)设置阈值,对保留后的预测结果进行非极大值抑制优化处理,最终输出检测结果。

图7 YOLO网络结构图
YOLO算法未使用锚框先验知识,算法过程简单,大大提升了网络的检测速度。然而算法对相互靠得很近的物体、小目标检测以及特殊尺寸物体检测效果不好。
3.2.2 YOLO v2
Redmon和Farhadi[37]针对YOLO检测精度较低的问题提出了YOLO v2(YOLO 9000)的改进模型。有两大改进:一是采用了多种策略在保持YOLO原有速度的优势之下,提升准确率和召回率;二是提出了一种目标分类与检测的联合训练方法,使得YOLO v2可以同时在COCO和ImageNet数据集中进行训练,实现多达9 000种物体的实时检测。具体如下:
YOLO v2算法在每个卷积层后增加批归一化、多尺度训练等操作来提高模型的检测精度,去掉了dropout层,mAP提升2%。
算法借鉴了Faster R-CNN中RPN的锚框策略,提升了网络的召回率,但mAP有一定程度下降,mAP由69.5下降到69.2,召回率由81%提升至88%。
算法采用了K-means聚类,使得模型复杂度和召回率之间达到折中。并且使用聚类的中心代替锚点,最后使用欧式距离进行边界框优先权的衡量高。在K为5的条件下,Avg IOU从60.9提升到了61.0。在K为9的的条件下,Avg IOU提升至67.2。
此外引入了转移层,使得特征图的数目提高了4倍,有利用小目标物的检测。
3.2.3 YOLO v3
YOLO v3[38]通过多种先进方法的融合,将YOLO系列的短板(速度很快,不擅长检测小物体等)进行优化。达到了良好的检测速度。YOLO v3在YOLO v2的基础上,提出了3类改进:一是多标签预测分类,在YOLOv3的训练过程中,使用二元交叉熵损失来进行类别预测。二是改变网络结构,使用全新设计的Darknet 53残差网络,兼顾了网络的性能和效率,并且去除了池化和全连接层,前向传播中通过改变卷积核的步长实现尺寸的改变。三是跨尺度预测,算法结合特征金字塔网络进行上采样多尺度融合预测,提升了小目标的检测效果,获得了较高检测精度,但由于其模型的复杂度使得检测速度并没有明显的提升。
3.2.4 SSD
SSD[39](single shot multibox detector)网络是一种端到端的卷积神经网络模型,具体过程如下:
1)输入一幅图片(300×300),将其输入到预训练好的分类网络(改进的传统的VGG16网络)中来获得不同大小的特征映射;
2)抽取Conv4_3,Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2层的特征图,在这些特征图层上面的每一个点构造6个不同尺度大小的先验框,然后分别进行检测和分类,生成多个初步符合条件的先验框;
3)将不同特征图获得的先验框结合起来,经过NMS方法获得符合条件的先验框集合,即检测结果。
SSD的结构如图8所示。
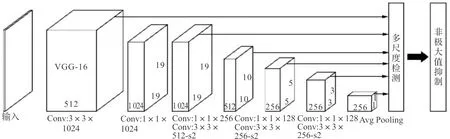
图8 SSD网络结构图
SSD运行速度超过YOLO,在一定条件下检测精度甚至超过Faster R-CNN,但需要人工设置先验框的初始尺度和长宽比的值,且调试过程非常依赖经验。算法使用低级特征去检测小目标,由于低级特征卷积层数少,特征提取不够充分,对小目标识别较差。
3.2.5 YOLO v4
2020年,Bochkovskiy等[40]提出了YOLO v4。该网络参考YOLO v3,在数据增强、模型结构和训练方法等方面进行了大量改进,实现了检测精度和检测速度的最优平衡。为了实现YOLO v4在输入网络分辨率、卷积层数、参数和层输出数量间达到最佳平衡,使用了SPP附加模块的CSPDarknet53作为骨干网络,结合PANet路径聚集和YOLO v3作为YOLO v4的网络架构。此外,对backbone和detector使用的BoF(bag of freebies)和BoS(bag of specials)进行了大量改进,提升了网络的检测性能。另外,为了使网络能够在单个GPU上训练,引入了自我对抗训练数据增强方法,修改了空间注意模块、路径聚合网络和交叉小批量归一化。
3.2.6 YOLO v5
2020年6月9日,Ultralytics公司开源了新的目标检测网络框架并命名为YOLO v5。网络框架基于PyTorch,对之前网络框架性能有了大幅提升。检测速度更快,对每个图像的推理时间最快为7 ms,即140帧/s,而YOLO v4在转换为相同的Ultralytics PyTroch后只有50帧;mAP约为0.895,与YOLO v4相当;体积小,但权重文件为27 MB,YOLO v4为244 MB,YOLO v5比YOLO v4小了近90%,可轻松部署到嵌入式设备中。
3.3 目标检测算法对比
3.3.1 图像数据集
目标检测算法数据集通常用于算法测试或是各种目标检测竞赛等。测试用数据集通常包括PASCAL VOC,ImageNet,MS COCO,如表3所示。

表3 目标检测常用数据集
PASCAL VOC数据集源于2005年开始的PASCAL VOC挑战赛,该数据集为目标检测中公认的基准数据集,图像共有20个类,由训练集、验证集和测试集3部分组成。
ImageNet是一种WordNet结构的图像数据集。该数据集包含14 197 122张图片和21 841个类别,每张图片都进行了严格的标记并每年对错误的数据进行修改与维护。
MS COCO(microsoft common objects in context),是微软赞助的一个新的目标检测、分割、场景理解等任务于一体的大型数据集。该数据集从复杂的日常场景中截取,图像中的目标通过精确的分割进行位置的标定。图像包括91类目标,超过250万个目标标注,目标尺寸变化更大,对检测算法性能更具挑战性。
3.3.2 对比测试分析
目标检测算法常用的指标为mAP,该指标与两个参数有关,一是精确率(p),表示检测出的物体的准确程度,二是召回率(r),表示数据集中检出物体所占的比例,计算如下:
(1)
其中:TP表示模型作出正样本判定且判定是正确的;FP表示模型作出正样本判定且判定是错误的;FN表示模型作出错误的负样本判定。通过p和r构成的曲线称为PR曲线,曲线以下的面积表示平均精度(average precision,AP),用来衡量某一个类检测的好坏。在多类多目标检测中,计算出每个类别的AP后,再除以类别总数,即所有类别AP的平均值,计算过程如公式(2)所示。
(2)
算法的对比结果如表4所示。
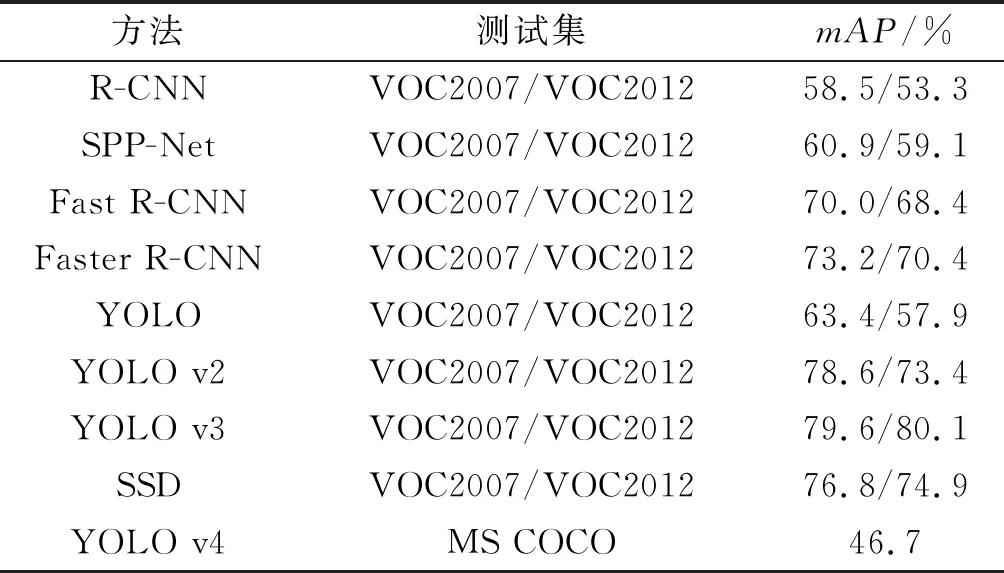
表4 算法对比测试
从表4可以看出,在主流的目标检测算法中,双阶段目标检测算法检测精度整体较高,而在单阶段检测算法中,通过对网络框架的不断改进,算法的检测精度也有了较大提升,如YOLO v3在PASCAL VOC 2007和2012上达到了79.6%和80.1%。
4 弹载图像融合和目标检测方法
前文综述了图像融合算法和经典的目标检测方法及测试数据集,并给出了对比分析。由于弹载图像的特殊性,通用的图像融合算法和目标检测方法并不能很好的适用。当前针对弹载图像的融合算法和目标检测方法研究较少,下文针对已有研究展开综述。
4.1 弹载图像融合方法
文献[11]提出了一种基于信息融合的战场态势显示技术,实现弹载传感信息的融合结算及效果显示。在信息融合部分分为数据融合和图像融合两个方面。采用加权平均法完成仿真数据的融合:
(3)
式中,w1,w2,…,wn为各自对应的权值;采用二维小波分解法进行图像融合,分解方法为:
(4)
则图像重构算法为:
(5)

融合后的效果如图9所示。

图9 弹载红外与可见光融合
4.2 弹载图像目标检测方法
文献[12]提出了一种YOLO3改进的弹载图像目标检测算法,该算法针对弹载图像尺度变化快、定位精度高、实时性要求强的特点,对YOLO v3方法进行改进,对多尺度预测分支特征图上的先验框尺寸进行K-means维度聚类,增强了尺度适应性;对位置损失函数进行改进,提高了位置定位能力;使用快速NMS算法加速预测过程,提高了网络实时性。具体步骤如下:
1)设置先验框。输入目标训练数据真值框宽高,并设置K=9得到9个初始聚类中心,按照中心重合的方式,计算每个真值框和每个聚类中心(先验框)的IOUji,计算真值框与聚类中心的距离dji=1-IOUji,重新计算聚类中心W′i=∑wim/Ni,H′i=∑him/Ni,重复以上计算并输出,其中m∈{1,2,…,Ni}。
2)改进损失函数。使用GIOU距离作为边界框的损失评价标准:
(6)
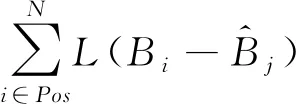
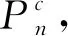
经过改进后的算法能够较好的应对不同尺寸目标,对多种类型武器装备能够正确识别,如图10所示。

图10 文献[12]测试结果
5 总结与展望
图像融合和目标检测作为计算机视觉领域中重要且具有挑战性的问题,受到了广泛关注,随着研究的不断深入,图像融合和目标检测领域己经发生了巨大的变化,针对弹载图像这一特殊类图像在算法处理和实际应用上都有了一定发展,但由于实际成像环境的复杂性,针对弹载图像的处理方法还不够完善,仍然存在一些急需解决的问题。
1)融合图像的准确性与实时性问题。一方面,弹载图像在实际成像过程中环境变化快、影响成像因素复杂,获取的弹载图像质量未知性较强,增加了图像融合的难度;另一方面,现有方法在提高图像融合视觉效果的同时也增加了融合特征的复杂度,导致计算较为复杂。因此在弹载图像融合算法过程中,考虑人眼视觉效果的同时也要兼顾算法的实时处理能力。
2)融合图像的准确性与适用性问题。通过融合算法对多传感器采集的图像进行融合,在提升人眼视觉效果的同时提升了目标辨析能力,但可能会导致算法过于复杂,而降低视觉效果会带来算法的简化,但也可能存在目标辨识度降低的问题,因此对于弹载图像融合问题,应当从实际应用角度出发,兼顾融合结果的视觉效果和应用需求。
3)特殊场景和特殊目标检测需求。由于弹载成像的复杂性使得成像结果具有尺度变化快的特点,并伴有各种噪声的干扰。这类特殊的场景和因素为专门设计适用于弹载目标检测算法提出新的挑战。
此外弹载图像目标检测的目标针对性也是后续研究热点,具体体现在以下两个方面:一是小目标作为一类特殊的研究对象,由于其分辨率低、像素少,可利用的信息量也较少,小目标检测一直是一类具有挑战性的问题;二是对重点目标、重点部位的检测问题,为后续毁伤效果评估提供支撑。
