基于匹配序列提取的相控阵雷达识别技术
2021-07-30杨卫国王志青
刘 傲,周 正,杨卫国,王志青
(1 海军航空大学,山东烟台 264001;2 91206部队,山东青岛 266109;3 91423部队,山东莱阳 265200)
0 引言
雷达辐射源识别是电子对抗的重要组成部分,准确有效的识别雷达对掌握现代电子战的主动权至关重要[1]。电子支援系统(ESM)截获的情报也为评估战场态势、部署武器装备等提供重要支撑[2-3]。科技迅速发展,各种新体制雷达不断涌现,实现多种工作状态并行[4],给电子侦察带来巨大挑战,能在复杂电磁环境中有效识别出相控阵雷达的搜索规律,在判断敌方雷达的工作状态和威胁程度方面有重要的军事价值。
一些文献对相控阵雷达搜索规律的识别进行了较为深入的研究。文献[5]提出了一种基于预测状态表示(PSR)模型的不需要先验信息的辨识方法。该方法尤其适用于具有未知规则性的雷达信号序列,还提出了一种降低系统动力学矩阵维数的新方法,在强噪声条件下具有良好的性能,完成了对雷达搜索规律的识别;文献[6]提出了一种基于波位建模的工作状态识别方法,先分析了三坐标对空情报雷达处理杂波时的特性,再进行模型建立和计算识别置信度,最后利用D-S证据理论融合了多个传感器获得的信息,实现对三坐标对空情报雷达搜索规律的识别;文献[7]分析了电子扫描雷达的工作特点和状态转换流程,通过提取两个截获信号状态转换序列的公共序列,识别电子扫描雷达的搜索规律。上述文献大多在信号能量、波束特点方面进行分析,很少在序列方面对相控阵雷达搜索规律进行描述。
相控阵雷达在执行搜索任务时,搜索状态的周期特性使得不同时段截获的信号序列呈现一定的相似性。利用这种相似性,文中通过分析相控阵雷达工作状态的序列特点,构建相控阵雷达的工作模型,利用Needleman-Wunsch算法[8],在不同跟踪序列占比和跟踪序列种类数条件下,对多条序列样本进行匹配序列的提取,完成对其搜索规律的识别。
1 相控阵雷达工作模型
1.1 相控阵雷达工作状态分析
相控阵雷达不同的工作状态决定了雷达信号脉冲参数中序列的不同。执行搜索任务时,相控阵雷达搜索任务执行模块会产生搜索任务序列。相控阵雷达对目标区域搜索的顺序固定,每次搜索时目标区域电子侦察设备截获的序列就会重复一遍[7],所以ESM截获的同一部雷达的搜索工作状态序列的类型,数目几乎不变,且具有一定的周期性。在不同时间段内截获的多条工作序列,若能提取出公共部分,便能找到雷达的搜索序列规律,文中将提取出的公共序列称为匹配序列。
相控阵雷达执行跟踪任务时,跟踪执行模块会产生跟踪任务序列,且跟踪任务的优先级要高于搜索任务[9-10]。由于目标与雷达的相对距离、位置,目标的速度、方位信息都是随机的,跟踪执行模块会根据实际情况产生相应的跟踪任务序列。跟踪任务序列的种类、数目都是随机的,并且会随机插入到搜索任务序列中。只考虑在搜索任务序列中插入跟踪任务序列的情况。通过雷达任务调动模块整合搜索和跟踪任务序列,搜索任务序列的任何位置都可能存在随机数目的跟踪任务序列,产生了搜索与跟踪联合的多状态工作任务[11]。工作状态的流程如图1所示。
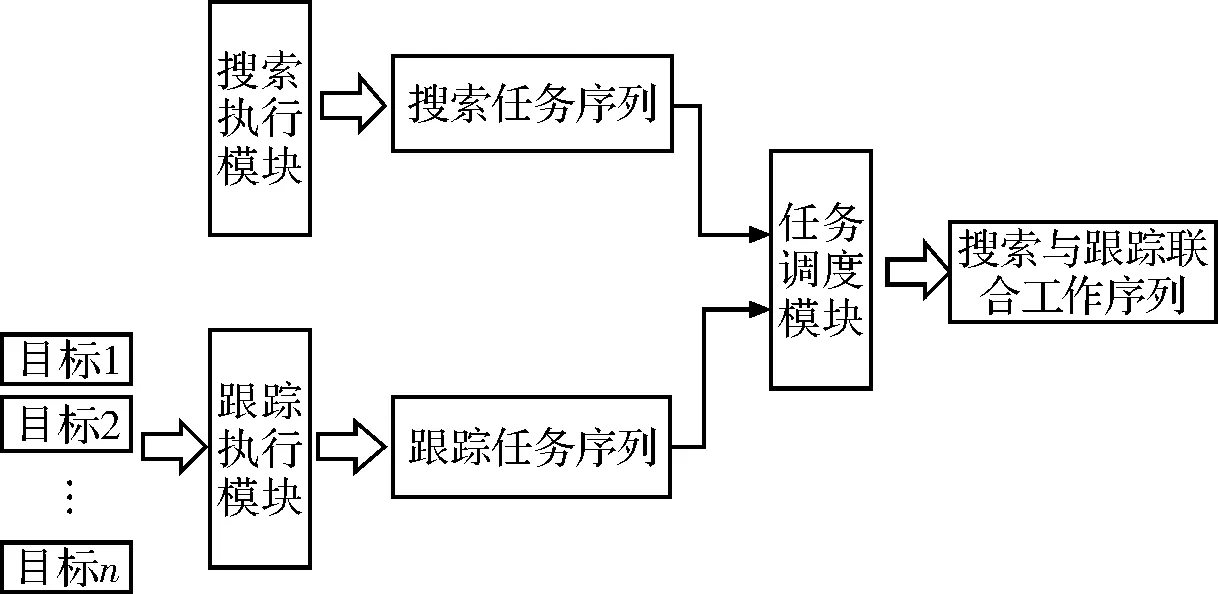
图1 相控阵雷达工作流程图
1.2 构建相控阵雷达工作序列模型
对相控阵雷达的不同任务类型的序列进行建模,搜索和跟踪任务类型分别表示为:
RS={RS1,RS2,RS3,…,RSp}
(1)
RT={RT1,RT2,RT3,…,RTq}
(2)
式中:RS为搜索任务类型,共p种;RT为跟踪任务类型,共q种。
设
R=RS∪RT
(3)
式中,R包含r个元素,且r=p+q。
设x,y为两条序列,其元素为符号。定义I(x,W)为在x的任意位置嵌入元素W。则I(x,y)表示在x中随机嵌入y中的元素。
假设在一个搜索周期内,相控阵雷达的搜索状态和跟踪状态序列分别表示为:
s={S1,S2,…,Si,…,SU}
(4)
g={T1,T2,…,Tj,…,TV}
(5)
式中:s为搜索状态序列;g为跟踪状态序列;元素Si为搜索状态时的一个搜索类型;元素Tj为跟踪状态时的一个跟踪类型,Si∈RS,Tj∈RT,1≤U≤p,1≤V≤q。跟踪状态时,雷达跟踪序列的选取是未知的,因此假设选取各个跟踪状态概率PT都相同,则有
PT=1/q
(6)
搜索和跟踪相结合的序列,可称为雷达工作序列。假设ESM已截获了不同时间段内的工作序列,文献[7]截获两条序列,将截获的工作序列设为n条,即l1,l2,l3,…,ln,n条含有相似的搜索规律序列s1,s2,s3,…,sn,有
(7)
s1∩s2∩s3∩…∩sn→send
(8)
式中:“∩”表示寻找n条序列间的匹配序列;“→”表示提取匹配序列的过程;send表示最终提取出的匹配序列。研究相控阵雷达的搜索规律,即在工作序列中提取出匹配序列。
2 相控阵雷达匹配序列的提取
先在两两序列的元素间建立对应关系,为保证相同元素可以对齐,允许在序列间插入空白位置,再提取出相同元素最多的序列,便得到匹配序列。先介绍通过Needleman-Wunsch算法提取两序列间匹配序列的方法。首先设M={E,F,G,H,/},其中M为所有任务组成的集合;“/”表示空位置,元素E,F,G,H为不同的任务类型;l1,l2为两条雷达工作序列,l1,l2顺序分别为:l1=E,G,H,E,G;l2=F,F,H,E,G,H,G。
2.1 拟定评分标准
评分矩阵Q(l+1)×(l+1)为l+1阶的Hermite矩阵,且
Q(l+1)×(l+1)=qij
(9)
式中,qij表示两条序列中第i个与第j个元素匹配的评分,匹配成功时得分为1,不同或与空位置匹配时得分为-1。若序列中第i个与第j个元素分别为A,B,则
q(A,B)=qij
(10)
可得评分矩阵Q如图2所示,“/”表示空位置。

图2 评分矩阵图
2.2 构建匹配得分矩阵
用匹配得分矩阵K来表示序列l1,l2所有匹配方案。K的行和列与两序列l1,l2分别对应。l1,l2的长度分别为n1,n2,则K为:
K(n1+1)×(n2+1)=(kij)
(11)
式中:kij为序列l1前i-1个元素组成的分序列和序列l2前j-1个元素组成的分序列的匹配评分。
构建K时,先初始化K的第一行和第一列,再从k22开始计算K中的各个元素kij,计算式为:
kij=max{k(i-1)j-1,ki(j-1)-1,k(i-1)(j-1)+q(L1(i-1),L2(j-1))}
(12)
式中:L1i为l1的第i个元素;L2j为l2的第j个元素。最终的k(n1+1)(n2+1)即为两序列最佳匹配的评分。
2.3 提取两序列间的匹配序列
先对匹配得分矩阵K进行取值回溯,得到最佳匹配方案。回溯流程为:从k(n1+1)(n2+1)开始,可分别向上、向左和左上移动一格,直至追溯到k11,最终形成的路径即为最佳匹配方案路径。当追溯到kij时,在k(i-1)j,ki(j-1),k(i-1)(j-1)中选择满足式(12)的值,继续下一步追溯,直至k11。
追溯完毕后,需在路径中提取匹配序列,方法为:在kij处,若路径向左移动,则表示在L2j前插入一个空白位置;若向上移动,则表示在L1i前插入一个空白位置;若向左上移动,则表示L1(i-1)和L2(j-1)配对成功。将追溯路径从右下角到左上角依次排列提取出匹配成功的序列,即为两序列间的匹配序列s12。匹配得分矩阵K及匹配序列的追溯路径如图3和图4所示。

图3 匹配得分矩阵及追溯路径图
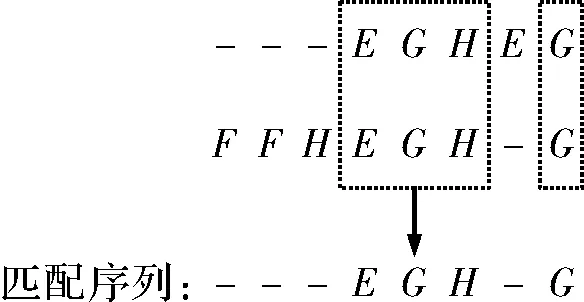
图4 提取匹配序列图
2.4 提取多序列间的匹配序列
对n条不同采样时间段的工作序列进行匹配序列的提取,可得到匹配序列s12,s13,s23,…,s(n-1)n。再整合n条匹配序列,从中提取最终匹配序列。先假定n条匹配序列在相同时间起点,再将不同序列中相同的元素保留,不同的元素剔除即可,最终形成匹配序列send。
2.5 性能评价标准
根据搜索和跟踪状态的序列特性,定义序列匹配率Pright和序列误匹配率Perror两个性能衡量指标,如式(13)和式(14)所示。匹配率表示由算法提取出的搜索序列与实际搜索序列的关联程度,序列误匹配率表示将跟踪任务误认为是搜索任务元素的个数在匹配序列send中的占比。
Pright=L/R
(13)
Perror=(N-L)/N
(14)
式中:L为算法提取的匹配序列send中与实际搜索序列元素在顺序和种类完全相同的元素个数;R为实际搜索序列中元素的个数;N为send中所有元素的个数。
3 仿真实验
3.1 实验1
假设相控阵雷达工作序列条数n=3,分别设为l1,l2,l3,每条序列元素总个数,即任务元素总数设为400,搜索任务种类p=8,跟踪任务种类q分别取4,7,8,11,12。对于跟踪任务元素在任务元素总数的占比,即跟踪序列占比分别为1/3,1/4和1/5时的匹配率和误匹配率进行仿真。每种比例的跟踪序列进行500次蒙特卡洛仿真实验,得到序列匹配率Pright和序列误匹配率Perror如图5~图7所示。
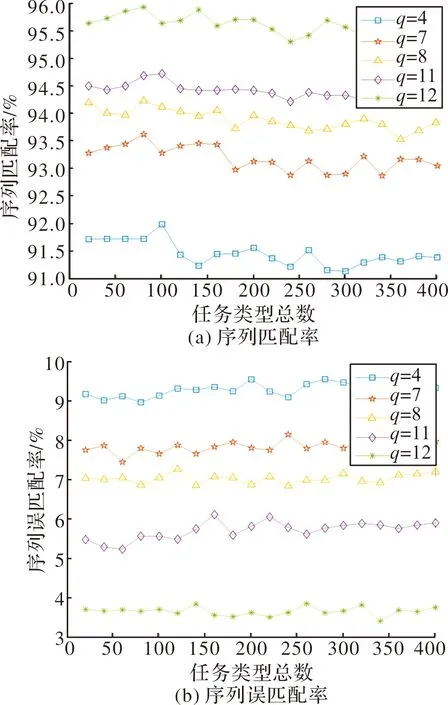
图5 跟踪序列占比1/3的识别效果
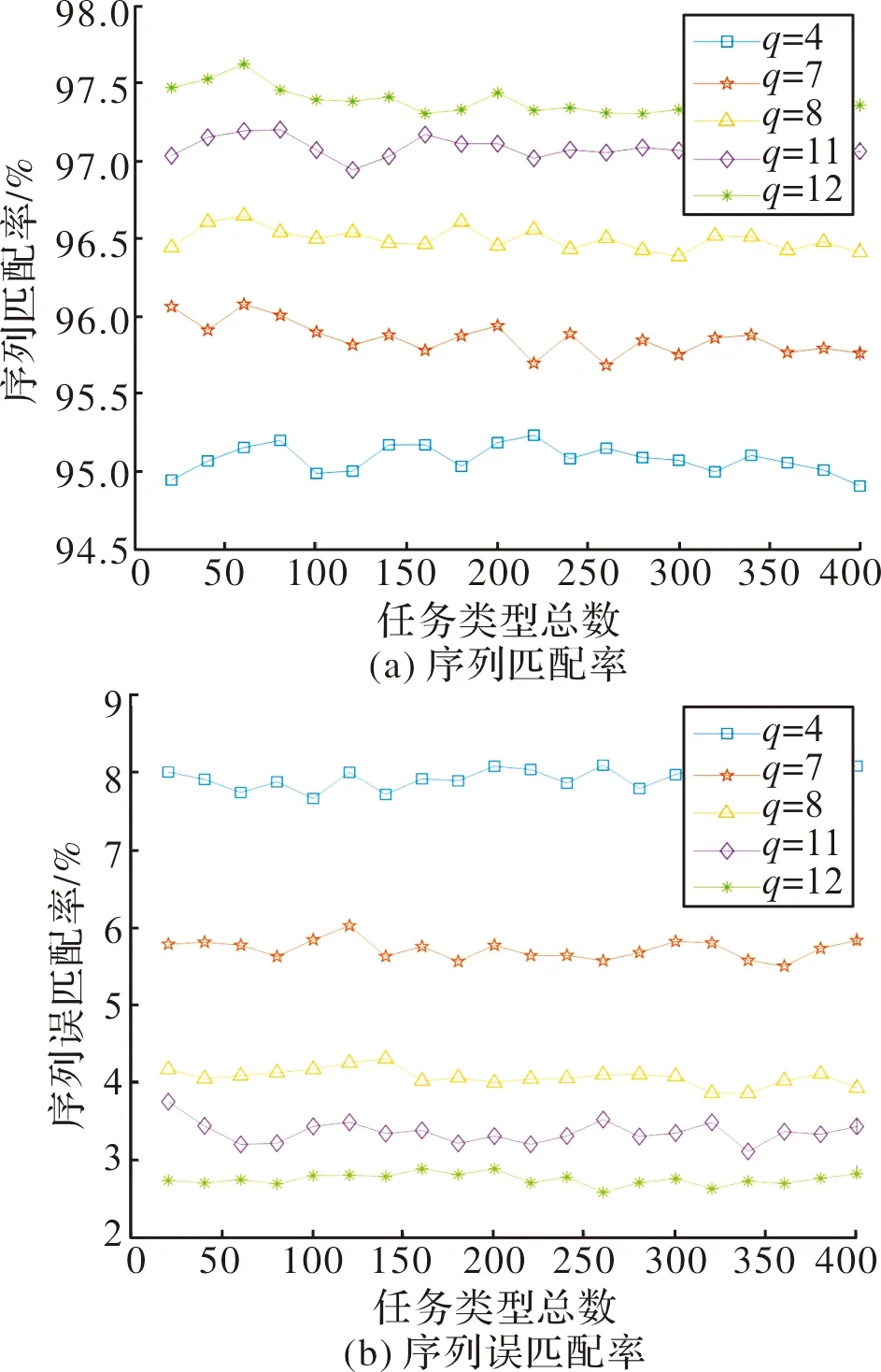
图6 跟踪序列占比1/4的识别效果
由图5~图7可知,跟踪序列占比为1/3时,匹配率保持在91%以上,误匹配率保持在9.5%以下;跟踪序列占比为1/4时,匹配率保持在94.9%以上,误匹配率保持在8.1%以下;跟踪序列占比为1/5时,匹配率保持在95.4%以上,误匹配率保持在4.8%以下,说明该方法仍能对雷达搜索规律进行有效识别。当跟踪序列的占比降低时,匹配率提高,误匹配率降低,且跟踪任务种类越多,识别效果越好,这是因为跟踪任务种类越多,相临的跟踪任务种类差别越大,便更有利于提取工作序列中相同的搜索任务。
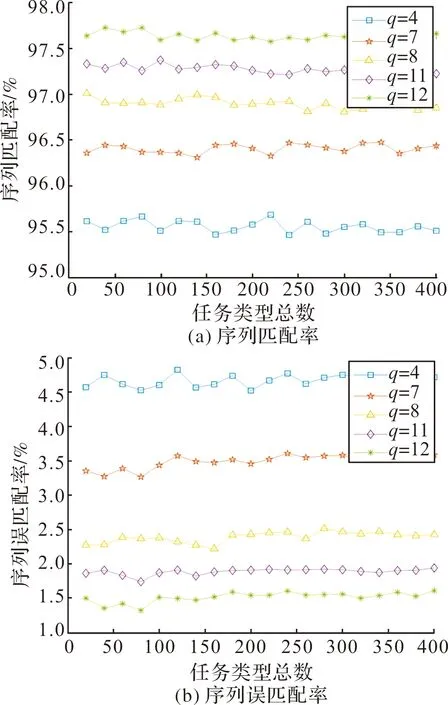
图7 跟踪序列占比1/5的识别效果
3.2 实验2
分别取n=4,5,任务元素总数设为400,搜索任务种类p=8,跟踪任务种类q=10。对于跟踪序列占比为1/4时,分别计算n=4,5时匹配率和误匹配率,并与n=3时及文献[7]相比较,每次仿真进行500次蒙特卡洛试验。对比结果如图8和表1所示。
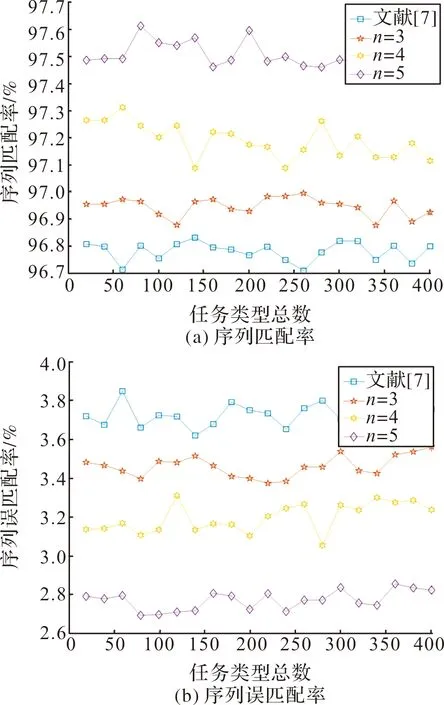
图8 匹配效果对比图
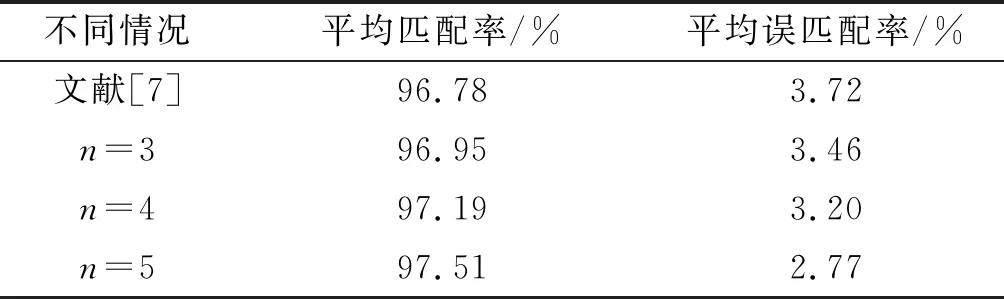
表1 平均匹配率及平均误匹配率
由图8和表1可知,工作序列越多,识别效果越好,在5条工作序列的情况下,平均匹配率达到97.51%,平均误匹配率为2.77%。这是因为在不同序列间提取匹配序列,等同于多次交叉验证试验,通过多次提取,使得相同序列元素的匹配率更高,提高了识别精度。
4 结论
通过分析相控阵雷达搜索及跟踪工作状态,建立工作模型,并使用序列分析技术对雷达匹配序列进行提取,完成对相控阵雷达搜索规律的识别。在不同跟踪情况下进行仿真,结果表明:跟踪序列占比为1/3时,匹配率仍保持在91%以上,误匹配率保持在9.5%以下,跟踪序列占比,跟踪任务种类与识别效果呈正相关,且仿真的工作序列越多,识别效果越好。
