融合胶囊网络的文本-图像生成对抗模型
2021-07-28黄晓琪
黄晓琪,王 莉,李 钢
1.太原理工大学 大数据学院,山西 晋中030600
2.太原理工大学 软件学院,山西 晋中030600
随着人工智能的飞速发展,深度学习技术已在计算机视觉、语音识别、自然语言处理等多个研究领域取得了诸多成绩。其中在生成图像方面取得的进展有:Rematas等[1]使用足球比赛视频数据训练网络,从而提取3D 网格信息,进行动态3D 重建。Oord 等[2]利用自回归模型产生了清晰的合成图。Dosovitskiy等[3]训练了一个反卷积网络,根据一组指示形状、位置和照明的图形代码生成三维椅子效果图。何新宇等[4]提出了一种基于深度卷积神经网络的肺炎图像识别模型用于肺炎图像的识别。近年来,生成对抗网络在生成高质量图像方面显示出了巨大优势,它是由GoodFellow 等[5]提出的,该模型在工业界和学术界都有广泛的应用,除了图像外,它还可以应用于视频和语音领域[6-7]。
随着深度学习的不断发展,越来越多的生成对抗网络模型被提出,在生成图像方面取得了越来越好的效果:Reed等[8]提出了GAN-INT-CLS模型,首次利用GAN有效地生成以文本描述为条件的64×64图像。然而,在许多情况下,它们合成的图像缺少逼真的细节和生动的物体部分,例如鸟的喙、眼睛和翅膀;此外,它们无法合成更高分辨率的图像(例如128×128或256×256)。Reed等[9]为了更好地根据文本描述控制图像中物体的具体位置,提出了GAWWN(Generative Adversarial What-Where Network)模型,把额外的位置信息与文本一起作为约束条件加入到生成器和判别器的训练中。Wang等[10]利用提出的样式结构生成对抗网络(Style and Structure Generative Adversarial Networks,S2-GAN)模型以结构生成和样式生成两部分相结合的方法实现室内场景图像的生成。Zhang 等[11]在网络层次结构中引入了层次嵌套对抗性目标,提出了高清晰生成对抗网络(High-Definition Generative Adversarial Network,HDGAN)模型,规范了中间层的表示,并帮助生成器捕获复杂的图像统计信息。Denton 等[12]在拉普拉斯金字塔框架内建立了多个GAN 模型,以前一层级的输出为条件生成残差图像,然后作为下一层级的输入,最后生成图像。
上述这些文本-图像对抗模型的判别器都使用卷积网络[13]提取图像特征,由于在卷积神经网络中,上一层神经元传递到下一层神经元中的是个标量,标量不能表示出高层特征与低层特征之间的空间关系。另外,它的池化层会丢失大量有价值的信息,因此,卷积神经存在特别大的局限性。2017年年底,Hinton等[14]发表的论文Dynamic routing between capsules提出更深刻的算法及胶囊网络架构,胶囊网络采用到神经胶囊,上一层神经胶囊输出到下一层神经胶囊中的是个向量,向量可以表示出组件的朝向和空间上的相对关系,极大地弥补了卷积网络存在的不足。
改进后的模型使用胶囊网络实现图片的分类,当标题向量和图片向量拼接后,依次进入初级胶囊层和第二胶囊层进行处理,由于胶囊层间传递的是向量,它很好地考虑了对象间的空间关系。经实验验证,加入胶囊网络后有效提高了生成图片的真实性和多样性。
1 模型架构
1.1 GAN-CLS结构及原理
图1 说明了GAN-CLS 的结构。生成器定义为G:RZ×RT→RD,判别器定义为D:RD×RT→{0,1},T是描述嵌入的维度,Z是输入生成器中噪声的维度。

图1 文本条件GAN-CLS架构
在生成器中,首先从噪声分布z∈Rz~Ν(0,1)中进行采样,使用文本编码器φ对文本标题T进行编码,然后再使用连接层将嵌入的描述φ(t)压缩为小尺寸,然后使用leaky-ReLU 激活函数对其进行处理,最后连接到噪声矢量z。接下来,推理过程就像在一个正常的反卷积网络中一样:通过生成器G将其前馈;一个合成图像x是通过x←G(z,φ(t))生成的。图像生成对应于生成器G中基于查询文本和噪声样本的前馈推理。
在判别器D 中,首先使用空间批处理归一化和leaky-ReLU 激活函数执行多个层的步长为2 的卷积处理,然后使用全连接层降低描述嵌入φ(t)的维数,其次对其进行校正。当判别器的空间维度为4×4时,在空间上复制描述嵌入,并执行深度连接,然后执行1×1 的卷积和校正,再执行4×4的卷积,以从D计算最终分数,最后对所有卷积层执行批处理规范化。
其中,判别器的损失函数如下所示:

生成器的损失函数如下所示:

上述的两个公式中,x表示真实的图片,t表示真实的标题向量,x表示生成的图片,t表示错误的标题向量。在原始模型中,先训练1 次判别器再训练1 次生成器,如此迭代交替进行训练,当生成器和判别器达到最优后,输入标题到生成器来生成预期的图片。
1.2 使用胶囊网络的判别器
改进后的判别器如图2 所示,主要由以下3 部分组成:卷积层、初级胶囊层和第二胶囊层。卷积层主要负责提取输入图像的低级特征,包含有256 个步长为1 的9×9 的卷积核。初级胶囊层负责将卷积层提取到的特征组合起来,该层由32 个胶囊组成,每个胶囊又含有8个步长为2的9×9×256卷积核。第二胶囊层用来实现特征的分类,得到的向量模长表示图片所属的类,该层共有2个胶囊,该胶囊层由全连接层构成。
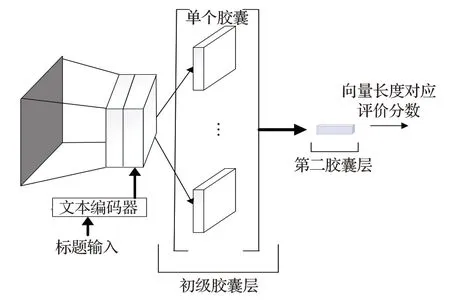
图2 使用胶囊网络的判别器
此判别器的工作流程:首先将图片输入判别器,经卷积网络提取图像特征后得到图片特征向量;其次将英文标题输入到文本编码器得到标题特征向量;最后将图片特征向量和标题特征向量进行拼接得到新的特征向量。将新的特征向量输入到初级胶囊层,该层将这些低级特征向量组合起来,将组合后的特征向量输入到第二胶囊层,该层负责将组合后的特征向量进行分类,得到的特征向量的模值越大表示图片和标题匹配度越高。
胶囊网络能够比卷积神经网络更好地学习特征和它们之间的关系,因为初级胶囊层查看输入图像的所有特征,而路由过程确定有助于第二胶囊层胶囊的全局特征集。其中第二胶囊层的网络结构和原理如图3所示。
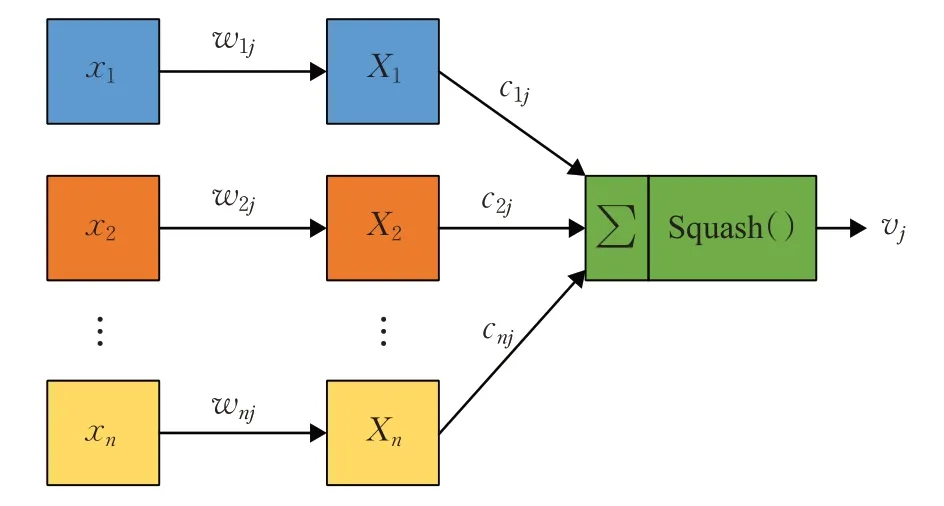
图3 第二胶囊网络的内部原理
判别器的损失如下所示:

其中,m+=0.8,m-=0.2,当K类实体存在时,Tk=1,否则,Tk=0,λ=0.5 用作下权重因子,以防止训练早期活动向量的收缩,vk表示胶囊层k的输出。
生成器的损失函数如下所示:

其中,P(z)代表先验分布,P(α)表示标题向量的真实分布,x表示生成的图片,t表示真实的标题向量。
对判别器进行改进后,由于胶囊网络能够很好地表达底层对象之间的空间关系,因此判别器相对原始模型来说,其判别能力更强。先训练1次判别器,再训练1次生成器,如此迭代训练,直到二者达到最优,二者能力相对原来模型都更优,因此生成器生成图片的质量更高。
1.3 第二胶囊层网络
神经胶囊网络不仅可以用于文本分类,也可以用于多标签迁移和图片分类的任务,在本文中,重点将它用于图片分类的任务,图3所示为第二胶囊网络的结构和工作原理。
第二胶囊层由很多类似人脑神经的神经元组成,它输出的向量的维度比较高,另外,该激活向量的模值越大,表示标题向量和图像向量越匹配,生成的图像越符合标题描述。另外在很多实际应用中,该向量的模长还可以代表某对象存在的可能性,如该模长比较长,则代表该对象存在的概率很高。图3 表示了第二胶囊网络的内部工作原理,主要分为四个流程,如下所示:
(1)仿射变换。首先将xn作为第二胶囊网络的输入向量,然后把这些输入向量和对应的权重矩阵wnj进行相乘后就可以得到向量Xn,权重矩阵可以表示出底层特征和高层特征之间的关系,比如空间关系和其他的一些重要关系,这就是仿射变换的实现过程。
(2)标量加权。经过仿射变换后得到向量Xn,接着用耦合系数cnj与该向量进行相乘,其中耦合系数决定着某个低层胶囊的输出向量作为哪个高层胶囊的输入,同时耦合系数是使用动态路由的方法来实现更新。
(3)累加求和。经过标量加权后,可以得到一些向量,对这些向量进行求和。
(4)把进行累加求和后得到的结果输入函数Squash()进行处理后得到非线性处理的结果。非线性处理的过程可以使用如下公式表示:

其中,sj是Xn经过标量加权操作后得到的相关向量再经过累加求和得到的结果,sj经过Squash()函数得到vj。Squash()函数不会改变该向量的方向,但会将该向量的长度控制在小于1的范围内,Squash()函数处理后的结果即为第二胶囊层的输出。
2 实验及结果分析
2.1 数据集及评估方法
在实验数据集的选择和参数的设置上,本文引用了鸟类图像的CUB 数据集和花图像的Oxford-102 数据集。CUB拥有11 788张鸟类图片,属于200个不同类别中的一个。牛津102数据集包含了来自102个不同类别的8 189幅花卉图片。在实验中将这些划分为不相交的训练集和测试集。CUB 有150 个训练类和50 个测试类,而Oxford-102 有82 个训练和20 个测试类。在进行小批量选择训练时,随机选取图像视图和其中一个标题。它的实现是建立在dcgan-tensorflow之上的。值得注意的是在模型中参与训练、测试以及最后输入模型的标题都是英文标题。
本文采用了3种图像评估方法:
(1)FID(Frechet Inception Distance)Score[15]是近年来提出的图像评价标准,它不仅考虑合成图像的分布,而且还要考虑如何比较它和真实数据的分布。它直接测量合成数据分布p(⋅)和真实数据分布pr(⋅)之间的距离。实际上,在实际应用中,图像由inception 模型用视觉特征进行编码。假设特征嵌入遵循多维高斯分布,合成数据的高斯均值和方差(m,C)从合成数据分布p(⋅)中获得,真实数据的高斯均值和方差(mr,Cr)从真实数据分布pr(⋅)处获得。合成数据的高斯分布和真实数据的高斯分布差异由以下公式计算:
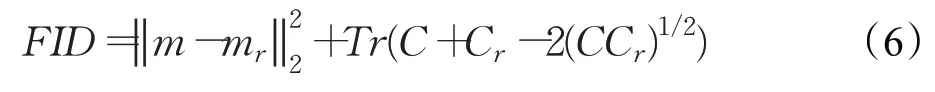
FID的值越低,表示真实数据和合成数据的距离越小。
(2)使用数值评估方法Inception score[16]进行定量评估。数值评估方法如下所示:

其中,x表示一个生成样本,y是初始模型预测的标签,p(y)是边缘分布,p(y|x)是条件分布。这个指标背后的意义是好的模型应该生成多样而且有意义的图片。因此,KL 散度在边际分布p(y)和条件分布p(y|x)之间应该足够大。
2.2 结果对比
为了证明将卷积网络替换为胶囊网络后可以提高模型的性能,本节将实验中原始模型以及改进后的模型得到的结果和最近使用的比较流行的文本到图像生成的网络模型进行各种类型结果对比,使用IS评估指标和FID 评估指标来评价图像的质量。以本章的实验中设置的参数为依据,共计全部使用了40 000张生成的图像来评估模型的性能。
本文中的GAN-CLS模型为实验使用的原始生成对抗模型,它的模型如图1 所示,在此模型中加入流行插值后的GAN-CLS-INT[8]是近期比较经典的文本生成图像模型,进一步加入位置信息和条件约束后称为GAWWN[9],本文融入胶囊网络后的模型为GAN-CLS-SA。
从表1可以看出,本章模型GAN-CLS-SA和其他的一些经典模型相比较,结果都有了提高。本文改进的模型与GAWWN模型的结果相比,Oxford-102数据集上IS的结果提高了0.17,CUB 数据集上IS 的结果提高了0.23,这表明改进后的模型生成的图片特征更丰富,更有意义。Oxford-102 数据集上FID 的结果降低了3.59,CUB数据集上FID的结果降低了4.73,这表明本文改进模型生成的图片更逼近真实图片的数据分布。由表1观察可知,模型GAN-CLS-SA 和GAN-CLS 在Oxford-102数据集上的结果对比后可知FID和IS的数值分别降低和提高了14.49%和22.60%,而在CUB 数据集上FID和IS的结果分别降低和提高了9.64%和26.28%。

表1 定量结果
最后详细地比较了GAN-CLS、GAWWN 和GANCLS-SA三种模型生成图像的视觉质量。从定性的角度比较了上述三种模型在CUB数据集中鸟类测试图像和Oxford-102 数据集中花朵测试图像的文本描述标题下生成的相同图像。最终结果比较分别如图4和图5所示。

图4 相同花标题对应结果对比

图5 相同鸟标题对应结果对比
通过观察图4 能够发现,GAN-CLS 生成的花的形状没有其他两种模型饱满,颜色不够准确。虽然GAWWN生成的图像中花的形状相对前者饱满,但颜色方面也不够准确或可信,相比之下,GAN-CLS-SA 生成的样本在颜色方面相对GAWWN比较准确或较可信。
图5为三种GAN模型在CUB和Oxford-102两种数据集上的结果,从图中可以看出,GAN-CLS-SA 模型生成的图片中鸟的基本形状和颜色方面更加符合标题描述,边缘和细节更加逼真,与其他模型相比取得了较优的结果。
3 结束语
本文在GAN-CLS 模型的上,首先将判别器中的卷积网络替换为胶囊网络,用胶囊网络实现对图片的分类。在Oxford-102花卉数据集和CUB鸟类数据集上的实验结果表明,本文中提出的模型效果优于基于原始生成对抗网络的模型的效果,证明了对卷积网络替换为胶囊网络,提高了生成图像的质量。除了完成文本生成图像的任务外,生成对抗网络模型还可以完成图像到图像的生成。未来,将进一步通过注意力机制来优化网络结构。
