基于多源信息的行人再识别研究综述
2021-07-28杜卓群胡晓光杨世欣李晓筱王梓强蔡能斌
杜卓群,胡晓光,杨世欣,李晓筱,王梓强,蔡能斌
1.中国人民公安大学 信息与网络安全学院,北京100038
2.中国人民公安大学 侦查学院,北京100038
3.上海市现场物证重点实验室,上海200083
近年来,视频监控成为了刑侦领域的一项关键技术,在案件的侦破过程中,视频侦查在安全防范、追踪犯罪嫌疑人行踪等方面起到了重大作用。
行人再识别(Person re-identification,Re-ID)是指利用计算机技术来对特定的行人进行身份匹配,确定不同的、没有重叠视野的摄像头下的行人是否同一的技术[1-2]。这一研究是计算机视觉和模式识别这两个领域的前沿课题,在如今建设“平安城市”的大背景下[3],公安机关在安保上投入良多,行人再识别这一新兴技术因此被广泛地应用于安防、刑侦和智能视频监控领域。
对于行人再识别系统来说,一般包含三个模块:行人检测、行人追踪和行人检索[4]。行人检索又称行人再识别,是研究的核心内容。近年来,该领域得到了学界广泛的关注,国内外提出了大量的行人再识别模型,而如今在限定的仿真条件下已能达到较好的识别率。
传统的行人再识别研究聚焦于视觉信息中的可见光图像,在实际的监控视频系统中,由于摄像机的成像质量、光照强度、监控视角以及行人姿态不同、遮挡等原因的出现,导致同一行人在不同摄像机下外观特征呈现较大的差异。为了解决这些研究难题,研究人员们将红外图像、深度图像、素描人像等图像引入了行人再识别视觉信息的研究。同时,文本信息和时空信息也提供了更加广泛的特征用以识别,时空信息的应用也为跨域无监督学习的行人再识别算法提升起到了很大的作用,引起了研究人员们的关注。这些多源信息应用于行人再识别研究中,从更多的角度对传统的算法进行了改良和优化,从而达到了更好的识别效果。
本文从行人再识别领域涉及到的多源信息的角度,对近年来多源信息用于行人再识别的研究进行梳理,从视觉特征、文本特征、时空特征三个方面的应用进行了阐述总结,对当前研究现状和未来发展趋势进行了探讨和归纳。
1 基于视觉信息的行人再识别
行人再识别研究是从对摄像机所采集到的视觉信息开始的。最初的研究多是基于可见光图像,实验室条件下,行人再识别模型在一些公开数据集上已经达到了较好的识别效果。为了让模型更加鲁棒,达到更好的识别效果,研究人员将红外图像、深度图像甚至素描图像也引入到了行人再识别的研究当中。
1.1 可见光图像
可见光图像(RGB image)在传统的行人再识别领域中应用十分广泛,它具有较高的分辨率和丰富的细节信息。行人再识别最早是应用传统的人工设计特征的方式,随着深度学习技术的发展,如今使用了卷积神经网络、生成对抗网络等方式,已经发展到了相对成熟的程度。
行人再识别最初来源于多摄像机追踪(multicamera tracking)的一个子问题来进行研究的,2005 年文献[5]首次提出了“行人再识别”这一概念,2007 年文献[6]创建了第一个公开行人再识别数据库VIPeR,从此行人再识别成为了计算机视觉一个独立的概念。
早期的行人再识别采用设计手工特征的方式,通过对全局特征[7-10]或局部特征[11-15]的提取来识别行人图片;度量学习的方式同样也是行人再识别的主流方法,利用相关特征通过标准距离度量来缩小或增大图像间的距离,从而达到聚类的目的。常见的度量学习损失函数包括对比损失[16]、三元组损失[17-19]、四元组损失[20]、中心损失[21]等;随着计算机视觉的发展,深度学习网络在行人再识别中得到了广泛的应用,深度神经网络(Deep Neural Networks,DNN)可以嵌入更加鲁棒的特征和学习更准确的相似性度量,与此同时卷积神经网络(Convolutional Neural Networks,CNN)更能结合全局特征,细粒度特征提取上更具泛化性,提取的特征比手工提取更加具有判别性,从而使得行人再识别的算法识别率得到了巨大的提高。
近年来很多表现优秀的算法在公开数据集Market-1501[22]、DukeMTMC-reID[23]上首位准确率Rank-1 已经达到了90%以上,但在行人图像的姿态改变、光照条件变化、目标遮挡等情况下,一些表现优越的算法或多或少出现了性能的下降。
为了解决这些问题,研究人员从特征提取的角度上对算法进行了改进,如改进目标检测算法[24]以改善目标遮挡问题所带来的影响;引入生成对抗网络(Generative Adversarial Network,GAN)[25]克服视角、光照等情况改变而带来的图像风格差异;增加注意力机制(attention mechanism)[26]对提取目标主体部分加权,提升算法运算效率。
除此之外,研究人员的目光不单单局限于可见光图像,随着红外相机和深度相机的广泛使用,红外信息和深度信息等其他视觉信息也加入了行人再识别的研究当中。
1.2 红外图像
红外图像(Infrared image)是通过环境中不同的物体发出的热辐射强度不同来探测目标。单独的红外图像缺乏细节信息,但在低照度环境或是目标被隐藏的环境中有较好的应用[27]。仅可见光图像进行的行人再识别研究会由于光照条件等情况的变化出现性能的下降,在夜间条件下,可见光图像行人再识别很难再达到不错的效果。而今很多摄像机将红外与可见光功能整合在了一起,其中红外相机在白天黑夜都可以获取行人红外信息,这为研究可见光-红外跨模态行人重识别提供了有利条件。
在可见光与红外行人再识别任务的处理中,最初研究者们主要将目光集中于,如何减少或者跨越红外模态和可见光模态之间的特征鸿沟。文献[28]的调查研究得出,如果要应用传统的行人再识别算法,跨模态的行人再识别任务的性能发生了极大的下降,他们为了研究RGB 图像和IR 图像的跨模态行人再识别,建立了一个大规模的行人再识别数据库SYSU-MM01,并且提出了一种基于DeepZero-Padding 的方式进行行人再识别工作。深度零填充流程如图1所示,作者在图像的通道上对RGB图像和IR图像进行了填充,首先将RGB图像转化为灰度图像,并将之放在第一通道中,而后零填充图像并放在第二通道,再对IR图像的第一通道零填充,其IG 图像本身放在第二通道中,最后使用SoftMax Loss将填充后的两种图进行行人标签有监督的训练,达到可见光-红外的跨模态行人再识别效果。

图1 可见-红外深度零填充示意图
文献[29]采用了可见光+红外这种双摄像头的采集方式,同时使用了可见-红外两种信息用于行人再识别工作。这样做可以减少噪声背景等干扰,作者尝试使用了卷积神经网络(CNN)来进行图像特征提取,并且为了实验,研究人员采集了一个跨模态数据库RegDB,后来被广泛用作可见光和红外光的跨模态识别训练。
文献[30]为了解决可见-红外两种模态间的差异,将两种不同模态的信息映射在相同的特征空间中,用同一种度量方式来度量其相似性,提出了双向双约束顶级损失(Bi-directional Dual-Constrained Top-Ranking,BDTR)这一方法。通过双向双约束网络提取RGB和IR图像的特征信息,使用双重排序损失(Bi-directional ranking loss)进行了有监督的训练,拉近了不同模态相同行人间的距离,应用双重约束顶级损失(dual-constrained topranking loss)的方式,引导了不同模态下同一行人特征的融合,增强了特征表示的可分辨性。BDIR 方法的具体网络构架图如图2所示。

图2 BDIR网络框架图
文献[31]提出了一种跨模式生成对抗网络cmGAN(cross-modality Generative Adversarial Network)的方式来解决RGB图像和IR图像两模态中用于行人再识别的区分信息的问题。该方法同样也使用了与BDTR 类似的思路,设计了一种基于判别器的生成式对抗训练,从不同的模式学习判别性特征表示,使得不同模态负样本对距离大于正样本对距离。作者将识别损失和跨模态三重态损失进行了整合,这可以最大程度地减少类间的歧义,同时提高实例之间的跨模态相似度。这篇文章将GAN的方法创造性地引入了可见红外跨模态行人再识别中,提供了一种新的思路。但该方法在跨模态数据集应用上并没有取得很好的效果,并不能很好地克服模态间的变化。为了提高两模态之间的相似性,文献[32]提出了一种新的对齐生成对抗性网络AlignGAN,将可见光图像通过CycleGAN生成对应的红外图像,通过特征对齐模块将生成的红外图像与真正的红外图像进行匹配,从而将跨模态问题转化为判别“红外”图像行人是否一致的单一模态问题。这种方式只是将可见光图像转换为了红外图像,在这种想法的基础上,文献[33]则是将可见光与红外两种图像相互转化。作者提出了一个减少两级差异学习D2RL(Dual-level Discrepancy Reduction Learning)方案,对图像级的子网进行了培训,将红外图像转化为可见光RGB图像,共同使用特征嵌入减少差异,这样使用统一表示的方式,特征级子网可以通过特征嵌入更好地减少外观差异。文献[34]对D2RL 方法进行了进一步的改进,提出了一种基于自注意力模态融合的网络。将CycleGAN 生成的跨模态图像与原图像对比学习训练两种模态特征,而后通过自注意力模块进行筛选,对保留下来的原始和转换后的特征经过Max 层融合,最后使用融合特征进行训练,数据跨模态的识别率得以提高。然而GAN的方法生成的图像质量都相对较差,有相当的噪声干扰,从而影响算法识别率。2021年,基于GAN的思路,文献[35]提出了一种新的RGBT(RGB-Thermal)表示学习框架,用于单RGB图像行人再识别。通过CycleanGan将RGB图像转化为红外图像,根据合成的RGBT 数据学习表示,采用注意网络改善两模式之间平衡信息,可在传统RGB 的行人再识别任务中释放照明和消除背景杂波。
与几种利用GAN 的方式缩小模态间隙所不同的,文献[36]创造性地引入了一个辅助的框架X modality,来缩小模态间的差异,将红外-可见光的双模态任务转化为X-Infrared-Visible 三模态学习任务,称之为XIV 学习框架,该结构框架如图3所示。作者认为,X模态图像比GAN 的方式更为轻量高效,使用特征学习器将三种模态图像输入,在共同的特征空间里共享信息,X 模态可从可见光和红外图像中学习优化,以联合的方式提取跨模态特征和分类输出。

图3 XIV学习框架
文献[37]提出了一种端到端的学习框架HPILN(Hard Pentaplet and Identity Loss Network),对现有的单模态行人再识别进行了适合于跨模态情况下的改造,使用新的损失函数Hard Pentapelt Loss同时处理单模态和跨模态的特征变化,并且还使用了身份损失函数提取身份损失信息,学习分离特征,以此提高模型性能。
以往的可见红外跨模态都在关注两种模态共享特征学习,而很少关注特异特征。D2RL通过GAN的方式将红外图像转化为可见光图像的形式,但这样的方式可能会出现不同的颜色特征,很难与可见光图像对应出正确目标。文献[38]针对这样的局限性,提出了一个端到端的跨模态共享特征转移(cross-modality Shared-Specific Feature Transfer,cm-SSFT)的算法,该算法可以同时利用各模态自身的特定(specific)信息及模态间的共享(shared)信息,根据不同模态样本对共享特征亲和力来建模,在模态间或跨模态转移共享特征,使得整个网络可以更有效地得到更多的信息,同时作者还提出了一种补充学习策略,学习自我区分和补充特征,大大提高了算法的优越性能和有效性。
大多数的可见-红外行人再识别主要关注如何消除模态间的差异,而对模态内差异的减少缺乏关注。为了同时缓解模态内和模态间共同的差异,文献[39]提出了一种层次交叉模态分解(Hierarchical Cross Modality Disentanglement,Hi-CMD)的方式,利用该模型自动分解可见光和红外图像中的鉴别因子(身体形状、服饰图案等)和排除因子(人体位姿、光照条件等),同时减少了模态内和模态间的差异。与其他关注于如何设计特征嵌入网络的方法相比,Hi-CMD 专注于图像级方法,采用图像生成技术与可见-红外跨模态识别任务结合,有效弥补了两模态之间的差异。
文献[40]提出了一种适合单模态和跨模态行人再识别的基准方法AGM(Attention Generalized Meanpooling with weighted triplet loss),其网络框架图如图4 所示。该方案在BagTricks[41]方法的基础上进行了改进,对非局部注意力机制进行融合,采用了广义均值(Generalized-Mean,GeM)池化的方式进行细粒度特征的提取,GeM池化公式如下:

图4 AGM网络框架图

式中,fk代表特征图,K代表最后一层中的特征图数量。Xk是特征映射k∈{1,2,…,K} 的W×H激活集。pk是在反向传播过程中学习的池化超参数。上述操作近似于pk→∞时的最大池化和pk=1 时的平均池化。在损失函数方面,除了使用SoftMax交叉点的基线身份损失之外,作者还提出了一个加权正则化的三元组(Weighted Regularization Triplet,WRT)损失,这种方式继承了正负样本对之间相对距离优化的优点,却避免了引入额外裕度参数的问题。该方法在解决四种不同类型的任务上都取得了不错的效果,在可见-红外跨模态问题上实现了较高的准确率。
为了解决可见光和红外两种模态间的差异,研究人员多是在对全局特征进行改进[28],而在RGB-IR 的任务中,共同特征是衣服图案和衣服类型,这些类型不受颜色和姿态变化影响。这样的局部特征更具有区分性,因此,文献[42]引入了近年来流行的注意力机制,提出了一种跨模态多粒度注意网络(Cross-modal Multi-Granularity Attention Network,CMGN),该网络使用了一个“蝴蝶型”的注意模块来学习局部特征,并将其与全局特征融合,增强了提取特征的可区分性,大大提高了可见红外跨模态行人再识别模型性能。
近年来可见光-红外行人再识别得到了国内外学者们的一致关注,近些年来发表的优秀论文层出不穷,但在可见光-红外研究常用的两个数据库SYSU-MM01和RegDB上,由于该数据库规模较小,可见-红外行人再识别算法识别率在最新的研究中仍然无法达到较高的识别率。不同类型图像间模态的差异仍是跨模态特征匹配的一大问题,但红外相机的出现对解决夜间环境下等光照较差情况的行人再识别提供了一个很好的思路。
1.3 深度图像
深度图像(Depth image)也称距离影像(range image),是指从相机到场景中各点的距离作为像素值的图像,可以反映物体表面的几何形态。深度图像可以经过坐标转化计算为点云数据,有规则及必要信息的点云数可以反算为深度图像数据。深度图像包含着场景内人物表面到视点的距离信息[43],该种图像提供了行人的身体形状和骨架的信息。同时,根据每个像素点蕴含的不同深度值,也可以将行人从复杂的背景中提取出来。由于其深度相机成像范围相对可见光RGB 相机而言较小,因而在室外大场景的情境中应用有限,但在室内小场景中,深度图像在人机交互场景的应用有广阔的前景。
2013年,为了解决可见光图像在特殊光照等其他极端条件下,行人再识别特征识别率下降的问题,文献[44]最早提出了将可见光图像、红外图像、深度图像三种特征放在一个联合分类器中,提取互补的信息,从而可以将特征融合成一个三模态再识别系统,如图5所示。虽然该系统在识别新人时会出现一些错误,但并不影响再识别的性能,并且这三种模态融合的方式提高了识别率,该研究也为其他视觉信息的融入提供了一种新的思路。

图5 三模态重识别系统管道
由于深度图像可以获取到身体形状和骨架信息,该种信息可以解决行人更换衣物这一问题所带来的挑战。文献[45]将软生物特征引入了行人再识别这一领域当中,使用深度相机提取了行人的3D 骨骼身体模型的点云,利用骨架信息构建描述符,以机器学习对其分类。研究人员为此收集了一个含有可见光图像、深度图像、人的分割图以及人体骨骼数据的数据库命名为BIWI RGBD-ID。
除了骨架特征外,运用人体形状和运动动力学,文献[46]聚焦于在没有RGB图像的前提下识别人,对人独一无二的步态特征提出了一种4D 循环注意力模型,将卷积和递归神经网络结合,用来识别小型且有区分性的区域。文献[47]更加关注于人体形态的描述,利用深度体素协方差描述符,并进一步提出局部旋转不变深度形状描述符,描述行人身体形状。同时,与文献[46]相反的是,本篇关注了在深度图像不可用时,用一种隐式特征传输方案,从RGB 图像中提取深度信息。基于从RGB图像中提取利用深度信息的思路,文献[48]提出了一个强化深度特征融合的模型,该模型在ResNet50 网络基础上加入了几何特征不变(Scale-Invariant Feature Transform,SIFT)特征,与深度特征进行特征融合互补,加强了网络的鲁棒性,达到了提取到更好的行人特征的效果。此外,该模型还可以处理行人检测的任务。
由于深度图像在室内小场景中有广阔的应用前景,文献[49]为了研究基于机器人平台上的人机交互,对机器人可以使用的高分辨率的RGB-D的传感器,收集外观和骨架信息,提出了一种特征漏斗模型(Feature Funnel Model,FFM),通过在作者自己收集的数据集RobotPKU RGBD-ID 上实验,得到了这种方式让度量模型更能适应环境变化,具有可移植性,提高了识别率。
之前的研究多是单独从两个不同通道利用RGB和深度信息,而忽略了两模态间的共享特征和交互关系。近年来,文献[50]提出了一种跨模态蒸馏网络(crossmodal distillation network),将两种图像嵌入到一个共享特征空间中,通过两步优化过程,提取RGB图像和深度图像行人躯干结构的共同特征,将深度图像中包含的人体姿态信息转成RGB 模态,利用这样的信息在RGB模态中进行检索。该方案在BIWI 和RobotPKU 两个数据集上的mAP 都取得了优于之前方案的10%左右。同年发布的文献[51]则是提出了一种既可以用于识别三维物体又可以识别行人的均匀和变分的深度学习(Uniform and Variational Deep Learning,UVDL)方法,用两个神经网络分别从RGB 图像和深度图像中提取外观特征和深度特征,设计一个统一且可变的多模态自动编码器,将两组特征投影到公共空间,最小化鉴别损失、重构误差。这种方法提供了一种一般化的可用于多模态对象的深度学习方法,可以推广到红外图像等其他视觉信息进行进一步的研究。
深度图像在应用于光照条件变化、衣着变化、背景噪音大这些问题下,与只利用可见光图像相比算法得到了一定的提升。但在行人距离相机太远时,深度图像还存在一定的局限性。同时,深度相机一般布置于室内场景,很少布置于室外,同样为深度图像与可见光图像结合的行人再识别算法提升造成了一定的困难。
1.4 素描图像
素描人像(Sketch portrait)的出现源于单单利用自然言语信息进行识别存在一定的局限性,而专业的技术人员可通过目击人描述绘制相应的素描人像。于是,2014 年起研究人员将素描人像应用于行人再识别领域中,对绘制的“草图”与相机拍摄出来的照片进行对比识别。
研究人员们刚开始试图将草图和相片建立联系获得识别,后来才将素描人像也应用在了行人再识别的研究中。文献[52]在原有草图图像检索的基础上,开创性地提出了在细粒度的框架上检索草图,他们引入了基于零件模型(Deformable Part-based Model,DPM)作为中级表示策略,以此来学习目标对象的姿势,在这个模型上进行图形匹配建立两模态之间的关系,从而达到识别的功效。为此研究人员还创建了一个SBIR 数据集,为之后的基于细粒度的草图研究打下了坚实的基础。文献[53]为了研究基于草图的细粒度图像检索(Fine-Grained Sketch-Based Image Retrieval,FG-SBIR)弥合照片和草图之间的领域鸿沟,引入了跨域图像合成工作,提出了一种基于跨域深层解码器的判别-生成的混合模型,可以增强学习的嵌入空间,保留两模态的不变信息,减少两模态之间的差异。文献[54]提出了一种新型的深层FG-SBIR模型,引入了视觉细节的空间位置敏感模块实现空间感知,将粗略和精细的语义信息结合,这样可以聚焦于草图和相片局部区域的细微差别,计算出其深层特征。最后引入了基于高阶可学习能量函数(Higher-Order Learnable Energy Function,HOLEF)损失并对其特征建模,使得建模结果更具有鲁棒性。文献[55]为了对徒手绘制的草图进行图形检索,建立了一个新的数据库,使用三元组注释深度学习网络,实现草图和图像之间细粒度的检索。文献[56]首次将素描人像用于行人再识别中,提出了素描行人再识别模型(SketchRe-ID)这一概念,作者对该种模型提供了一种对抗学习的方式如图6 所示,来共同学习身份特征和不变特征,并创建了一个SketchRe-ID数据集。
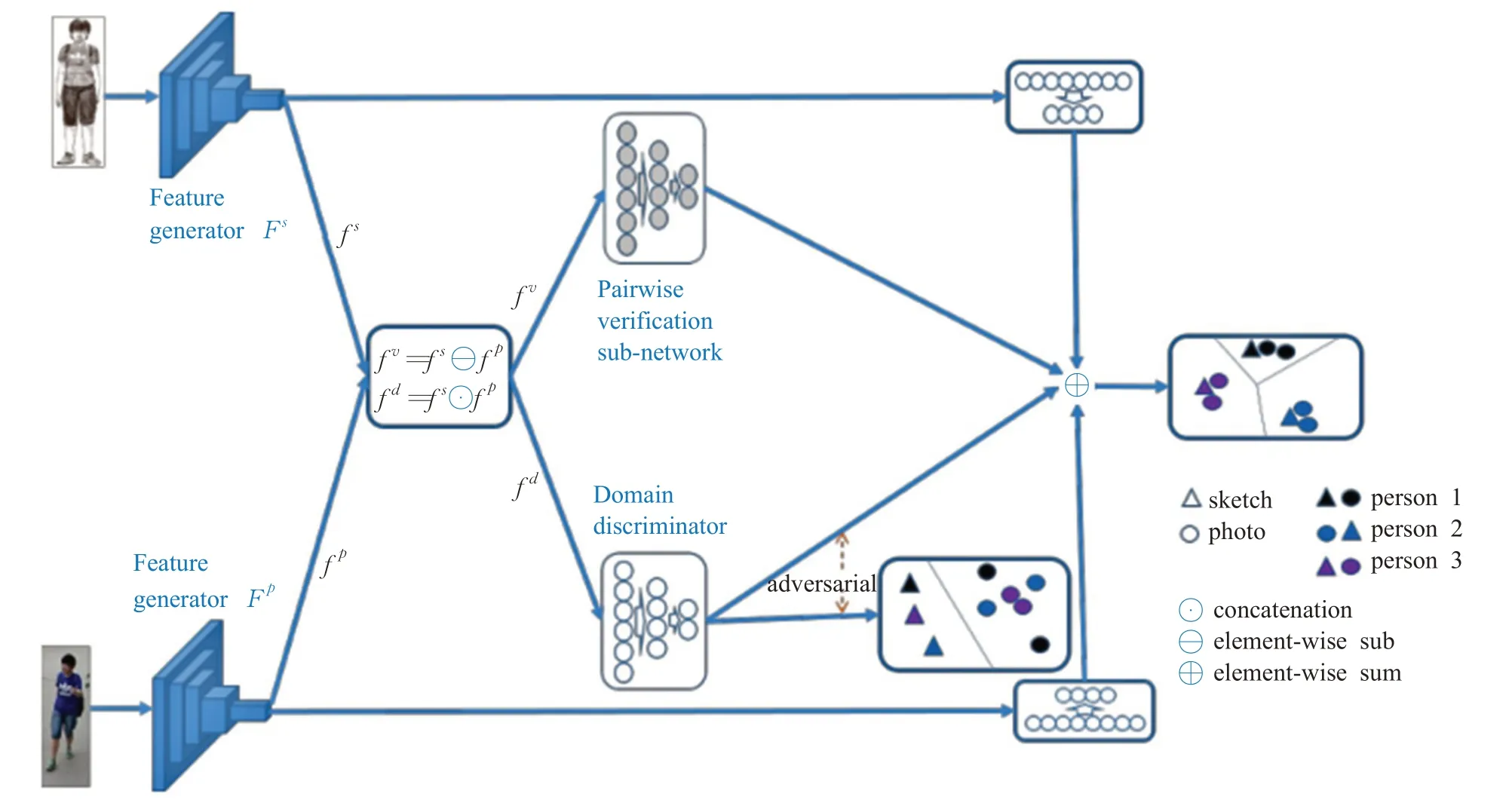
图6 跨域对抗性特征学习
将素描人像与摄像头下人的图像做行人再识别的这一数据库SketchRe-ID 体量较小,且数据库中的素描图像与相片具有一定的相似度。而这一研究是否可以应用于现实,实际应用绘制的各种类型风格素描人像是否可以达到一定的识别率,还有待进一步的研究。
2 基于文本信息的行人再识别
在公安实践应用中,有时候相机数据并不是随时都可以获得的。在无法获得目标对象的图像信息的前提下,可以通过目击证人获得一部分的语言描述作为标签,将文本信息与视觉信息进行比对,从而开展行人再识别的工作。
2017年以来,研究人员将模糊的自然语言信息与行人再识别领域相结合,做出了一系列的研究。文献[57]为了自然语言和行人再识别结合的研究,创建了一个包含详细自然语言注释和人员样本的大规模数据库CUHK-PEDES(CUHK Person Description Dataset),作者提出了一种具有门控神经注意的递归神经网络(GNA-RNN)来学习词汇和人像之间的关系,提取特征根据相关度给予不同的权重,根据相关度排序检索结果。文献[58]提出了一种对抗式跨模态检索的方式(Adversarial Cross-Modal Retrieval,ACMR),基于对抗学习的方式寻找对抗子空间,将两个模态提取特征提取到子空间后,输入到一个模态分类器,使用该分类器根据子空间特征判别出来自于图像形态还是文字形态,通过对抗学习让类内两个模态的特征投影更加紧凑。文献[59]采用了双路CNN 的结构来分别提取视觉特征和文本特征进行训练,这种端到端的学习系统可以直接从数据学习并充分利用监督。作者提出了实例损失(instance loss)的方式,可以更好地为排序损失提供权重初始化,学习更多的判别式嵌入。文献[60]引入了监督信息人体姿态,结合名词描述和视觉特征获得位姿的相关特征图,利用可视化验证了实验效果,提出了姿势指导的多粒度注意力网络(Pose-guided Multi-granularity Attention network,PMA),研究人员在CUKH-PEDES数据集上进行了大量的实验证明了他们技术的优越性。文献[61]提出了基于隐空间特征学习的跨模态检索方法,为了提高跨模态特征的匹配性能,提出了两个损失函数,分别是跨模态投影匹配(Cross-Modal Projection Matching,CMPM)损失和跨模态投影分类(Cross-Modal Projection Classification,CMPC)损失,可以优化跨模态的投影性能,学习更具有判别性特征的隐层特征。文献[62]对基于自然语言的行人再识别任务提出了多粒度的匹配方案,为了解决现有的细粒度跨模态检索问题,作者提出了一种多粒度图像-文本对齐(Multi-granularity Image-text Alignments,MIA)的训练模型,框架如图7所示,可以在多粒度(global-global,local-local,global-local)上实现的视觉和文本信息精准匹配。

图7 MIA总体框架
除了利用文段信息进行匹配外,一些研究人员将文段中的文本信息提出一个个词汇,将这些作为标签,作为行人属性信息。文献[63]将这样的行人属性信息与判别式卷积神经网络(Convolutional Neural Network,CNN)结合,提出了一个行人属性判别网络(Attribute-Person Recognition,APR)。作者对公开数据集Market1501和DukeMTMC的行人属性进行标注,用APR网络对行人属性信息和图像信息同时提取,大幅度提高了行人再识别的准确率。文献[64]在APR模型的基础上,对其进行了改进。在网络结构中增加了全连接层,在损失函数中基于属性样本数量进行了归一化处理,对样本数量不均衡的问题进行了调整,通过调节各损失层的权重处理了正负样本数量不均的问题。这篇文章在各数据集上的首位匹配率Rank-1 较APR 有所提升,数据集之间的交叉识别率也有部分的上升。
文本信息作为行人再识别一跨模态信息很早便得到了广泛的关注,从最初的全局模态信息对齐发展到了如今的局部模态信息对齐,也逐步引入了注意力机制、人体姿态加强等方式,在近年来的发展下识别率逐渐得到了提高。
3 基于时空信息的行人再识别
行人再识别现有的研究多基于样本有标注的有监督学习的方法,并且有监督学习下的算法性能已经达到了较高的准确率,而如果想要将训练好的算法应用于新的场景时,仍然需要对大量的样本进行标注构建相应的标签,在实际应用中有相当的局限性。无监督学习虽然可以在不同场景中都得到应用,但由于缺乏标签信息的训练,其算法的准确性较有监督学习而言较低,还不足以达到实际应用的要求。在摄像机提取行人图像分辨率较低的前提下,模糊图像很难利用视觉特征进一步提高模型的性能,因此国内外许多学者将目光聚焦在了行人重识别中摄像机采集到的另一些信息上。
除了得到广泛研究和关注的图片、视频信息这些视觉信息外,由于摄像机在实际应用中具有一定的空间分布,同时行人在不同的摄像机镜头下出现存在一定的时间差。这些摄像机蕴含的时空关系逐渐被学者们关注,通过在算法中引入时空信息,从而对无监督学习的行人重识别模型性能的提高提供了一个新的思路。
文献[65]在无监督学习应用的基础上,引入了时空特征,提出了一种无监督视觉时空信息融合(Transfer Learning of Spatio-temporal Pattern,TFusion)算法。TFusion算法模型如图8所示:首先将在有标签的、数据含量小的数据集训练出视觉分类器,再将分类器迁移到未标注的目标数据集,以这样的方式学习行人的时空特征;其次,作者提出了一种贝叶斯融合模型,将学时空特征与视觉特征相结合,使之前的分类器得到改善;最后,作者提出了一种基于排序学习相互促进的程序,用目标数据集中未标记的数据来逐步优化分类器,最终达到一个较好的识别效果,较其他的无监督学习的行人重识别算法得到了显著的提高。

图8 TFusion模型框架
文献[66]提出了一种新颖的双流时空行人重识别框架(two-stream spatial-temporal person ReID,st-ReID),利用一种基于后勤平滑(Logistic Smoothing,LS)联合相似度度量的方法,同时挖掘视觉语义信息和时空信息,构建成一个统一的度量函数。同时,作者开发了一种快速直方图(Histogram-Parzen,HP)的方式来模拟时空概率分布,rank1 水平较之前的技术方法有了一定的提高。
文献[67]提出了一种混合高斯时空模型约束的方法,行人走动时间差建模成一种遵循随机分布的变量,同一行人在具有一定空间分布的摄像机镜头下录像片段相似,图片捕捉前后时间差不是很大。高斯分布具有长尾特性,分布平滑,能很好处理行人步伐类似造成的波动。为了提高模型的泛化能力,文章通过改进视觉分类模型,对行人图片关键部位进行分割,同时使用损失函数对图片加以训练,以此得到深度视觉模型,再结合图片帧号和摄像机号,用大量的数据构建混合高斯模型来拟合真实行人行走时间分布,以此排除不可能出现的行人。文献[68]提出了一种生成对抗网络联合时空模型(GAN Uniting with Spatio-Temporal Pattern,STUGAN)的方法,利用图像分类器联合对抗网络和时空模型,使用生成对抗网络(SPGAN)技术生成目标场景的样本以提高模型稳定性,引入TFusion 算法的时空模型筛选出部分低概率匹配增强算法的准确性,最后利用贝叶斯融合的方式联合视觉特征和时空特征。与生成对抗网络的SPGAN 算法相比,该文章加入了时空模型的辅助后在一定程度上排除了仅依靠视觉特征判别出的相似的错位样本,从而减少了图像分类器的误差率。与使用了时空模型的TFusion 算法相比而言,该文使用的图像分类器利用了生成对抗网络的样本训练,从而削弱了领域偏差对图像分类器的影响。SPGAN作为较为先进的算法,其图像分类器构建的时空模型更接近于真实情况,与对抗网络联合后可以具有更好的性能。
现有的方式多是在不同摄像机间的过渡时间进行了建模,但在复杂的摄像机网络中不同人的过渡时间差分布也存在差异,对此学习一个稳健的时空模型存在一定的困难。文献[69]提出了一种无模型基于时域共现的评分加权方法称作时域提升(Temporal Lifting,Tlift),在每个摄像机中利用了一组附近的人,并找到了他们之间的相似之处,该方法的图解如图9所示。

图9 Tlift方法图解
该方式基于的假设是,在一个摄像机附近的人有可能在另一个摄像头下仍在附近,利用这种原理在行人重识别匹配中为附近的人增加权重。因为这种方案对每个摄像机应用共同约束避免了估算过渡时间,也无需事先学习时空模型,不需要提前训练,可以即时计算。在实验中,与TFusion相比Rank-1和mAP都得到了一定的提高。
时空信息的引入为无监督学习条件下的行人再识别跨域迁移提供了更广泛的可能,但由于行人衣着可能会发生变化,现有的视觉信息和时空信息结合的模型大多只能解决不太长时间的匹配问题。同时,现有的包含时空信息的数据库数量较少,这一能简单提取到的信息在过去时常会被忽视,时空信息与视觉信息结合的研究还有更大的发展潜能,未来需要更多包含时空信息的数据库的出现,才能训练出更好的模型来。
4 常用数据库
现如今的行人再识别研究方法多使用深度学习的方式,这种方法需要大量数据训练模型,采用越庞大的数据量进行训练,采集到的环境越贴近于实际情况,越能训练出鲁棒性好的行人再识别模型。近年来论文中基于视觉信息的可见光图像研究最广泛的常见数据集有CUHK03[7]、Market-1501[22]、DukeMTMC[23]、MSMIT17[70]。
CUHK03[7]采集于香港中文大学校园内,是第一个满足深度学习要求的行人再识别数据集。该数据集使用了5对摄像机包含1 467位行人的13 164张图片。
Market-1501[22]采集于清华大学校园内,使用了包含1个低分辨率摄像机的6台摄像机,涉及到1 501位行人的32 668 张图片。其中包含751 个行人19 732 张图片的训练集和750个行人12 936张图片的测试集,并且论文作者对该数据集行人进行了标注。
DukeMTMC[23]采集于杜克大学校园内,利用了8个相机采集36 411张图片,其中包含702个行人16 522张图片的训练集和702 个行人2 228 张图片的查询集,测试集中还包含408 个行人只出现在一个相机中作为干扰项,剩余图片作为候选集。该作者也为行人进行了标注。
MSMIT17[70]采集于北京大学校园内,利用了包含12台室外相机和3台室内相机共15台采集了4 101位行人126 441张图片,其中包含1 041位行人32 621张图片的训练集和3 060位行人11 659张图片的测试集。该数据集在一个月内选择了天气状况不同四天每天上午、中午、下午三个时段共3小时采集视频,原始视频时长180小时,情形比Market-1501更为复杂。
近年来论文常用的基于视觉信息的可见光图像数据集如表1所示,图表中列举了发表年份、行人的数量、相机的数量及数据集的容量相关信息。

表1 常见可见光图像行人再识别数据集比较
在传统上行人再识别在解决特殊情境下的算法识别率下降,研究人员们开始关注其他类型的视觉信息。从2017年开始,文献[28]为了研究跨可见光和红外图像这一跨模态的图像匹配问题(RGB-IR),采集了一个大规模的可见光-红外行人再识别数据库SYSU-MM01。该数据库包含六个摄像头,其中包含两个黑暗条件下户外的红外摄像头以及四个在正常光照条件下的可见光摄像头,这四个可见光摄像头又包含两个户外和两个室内场景。2017年,文献[29]的研究人员们为了减少可见光行人再识别中的噪音干扰,选用了可见光和红外光双摄像头的方式采集图像,以此采集了一个跨模态数据库RegDB,该数据库包括412 人,其中每人分别有十张可见光图像和红外图像,从此以后RegDB 的数据库被广泛应用到了后来的可见光和红外行人再识别跨模态研究中。
可见光-深度(RGB-D)的跨模态行人再识别最早是2014年文献[45]所采集的BIWI RGBD-ID数据集,含有可见光图像、深度图像、人的分割图以及人体骨骼数据,共50组,包含了50个训练集和56个测试集的数据来进行训练。2017 年文献[49]在研究机器人平台上的行人重识别,为了获取清晰的人脸,收集了与BIWI RGBD-ID同样数据类型的数据RobotPKURGBD-ID,且数据量更为庞大,包含180个90人的视频序列用来训练和测试。
2018年,文献[56]开始将素描人像用于行人再识别研究中,收集创建了SketchRe-ID的数据库,包含200个行人,其中每个行人包含一张素描图像和来自两个可见光相机的两张RGB图像。
用于其他视觉信息与可见光图像跨模态行人再识别的数据集如表2 所示,图中列举了应用类型、行人数量、相机数量及数据库图片数量相关信息。

表2 多源视觉信息行人再识别数据集比较
文献[57]开创性地收集了一个包含详细语言注释和人员样本的数据库CUHK-PEDES,也是近些年来唯一一个用于自然语言和行人再识别跨模态行人再识别研究的数据库,包含来自于现有行人重识别数据库中13 003人的40 206张图像,并且由两个独立的工作人员对每个人的形象分别用两个句子来描述,共计80 412个句子描述。
时空信息的实验开展于Market-1501[22]、DukeMTMC[23]两个数据库,Market-1501 存在6 个序列的视频,每个序列内有视频帧号表示图片的拍摄时间;DukeMTMC 是有8 个摄像头采集拍摄了85 min,视频帧速60 frame/s,并且包含着其摄像头网络拓扑图,摄像头拍摄区域无重叠,摄像头之间距离不同,行人在不同摄像头下出现存在一定的时间差可以用来建模迁移时间,用以行人再识别时空信息的研究。
随着深度学习技术的发展,为了实现更好的识别效果,行人再识别使用的模型也越来越复杂,为了使研究的算法具有更好的鲁棒性,需要逐渐扩大数据集的规模,需要更庞大的数据量来训练。实际应用环境中也存在着各种复杂的情况,需要不同摄像机的图像类型、不同的拍摄场景下更加多样的数据,数据集的发展还需要继续,只有更加庞大的数据集,才能开发出更好的算法来。
5 面临的问题和挑战
行人再识别发展至今已经得到了充分的研究与开发,随着计算机视觉领域的发展,GAN、注意力机制等加入了研究中,算法识别率较开始已经得到了大幅度的提升。
多源信息的应用为行人再识别提供了更广阔的思路,各有优劣,但也为这项技术尽快落地应用提供了重大作用。本文提到的多源信息的行人再识别方法的应用情况及优劣如表3所示。

表3 多源信息行人再识别方法比较
(1)多源信息间模态特征差异较大
在进行跨模态行人再识别任务中,可见光模态与其他视觉信息模态信息存在较大特征差异,与文本信息更是存在着天然的模态差异。现有的研究方式聚焦于提取共享特征、各类图像模态相互转化等方式,这些计算方式已经取得了一定的成效。现有的研究已经实现了可见光-红外和可见光-深度两模态间的相互转化,但素描图像甚至文本信息与视觉信息之间仍然无法实现模态之间互相转化。
(2)图像处理本身局限性
已有的行人再识别算法都容易受到光照情况、拍摄角度、成像质量、障碍遮挡等问题的影响,这些问题的出现使得算法性能受到了极大的影响,对目标人物跨摄像机的大范围持续追踪任务造成了不小的困难。多源数据的引入为解决这些问题提供了新思路,红外图像可以解决夜间条件下的识别问题,深度图像可以解决行人姿态变化、遮挡、换衣等问题,素描图像和文本信息在行人再识别落地时有重要的作用,时空信息则是为跨域迁移算法识别率的提升提供了重要作用。
(3)现有训练集数据体量较小
现有应用于多源信息行人再识别训练中的数据集的体量还是相对较小,而在实际应用过程中,行人再识别的任务则是要处理更庞大的数据量。训练集的体量小,在算法的效能上可能会与实际应用存在着误差,可能会影响实际使用的效果。而跨模态行人再识别数据库更是少,体量也相对较小,这对算法开发有着不小的影响。应该开发体量更大、更贴近现实应用的数据集,同时注意保留数据集的相机位置信息和照片时间信息用以做融入时空信息的研究。数据量的增大可以更好地训练深度学习网络模型,使模型在实际应用中更加具有鲁棒性,识别效率也更高。
(4)多模态行人再识别运算量过大
实际应用中,行人再识别使用聚焦于对汇总在服务器端的视频图像进行海量的检索。在面临着不同摄像头、不同清晰度、不同模态等问题下,尤其是跨模态的问题,要对模态进行转化等操作,更是要处理更多的数据。这些情况对算法提出了很高的要求,在处理时也需要消耗大量的带宽、算力和存储空间,而在需要实时处理事件时,面临着多个终端的数据,在计算效率上还是面临着较大的考验。在行人再识别的精准度已经有了长足发展之际,考虑算法性能的同时,也应当注意运算效率。近年来,文献[71]对Resnet50 进行模型剪枝压缩模型,性能也得到了保障。在运算量更大的多源信息行人再识别问题上,运算效率也应得到足够的考虑。
(5)更多的多源信息有待发掘应用
在行人经过摄像头下时,除了被摄像头采集到的图像信息、目击者提供的文本信息、摄像头本身包含的时空信息外,摄像头网络所处的基站,包括行人手机连接的路由器也会产生大量的数据,这些电子痕迹也提供了一定的时空信息。在计算机技术飞速发展的如今,信息社会存在着大量各式各样的数据类型,发掘更多类型的信息,应用到行人再识别乃至计算机视觉领域中来,可以为研究提供更多的思路。
(6)行人再识别技术有待实践的进一步检验
目前的行人再识别算法在实验室条件下已经可以取得较好的识别效果,但在实际应用中,复杂的环境下,大量的目标域并没有标注信息,从而现有的算法在迁移到实际应用中还存在着一定的难度。这样的前提下,有监督学习方法的使用受到一定限制,而无监督学习的识别率还有待提高。文本信息和时空信息的引入在一定程度上提高了行人再识别算法的识别率,对相当的不匹配数据进行了排除。为了尽快让该领域达到落地的标准,除了视觉信息外,多源信息的收集和利用将会起到重要的作用。
6 结束语
在“平安中国”的大背景下,许许多多的摄像机安装在城市内,形成了一个巨大的监控网络。这些监控网络大大地提高了公安人员的工作效率,为侦查工作、安防工作等做出了巨大的贡献。如今,计算机视觉领域不断发展,行人再识别更是成为了其中的一个热点问题。研究人员们聚焦于如何实现监控网络中对行人长时间和大范围的追踪,在近年里,ICCV、ECCV、CVPR 等顶级国际会议及期刊上都会有许多相关的论文。
多源信息行人再识别的研究在近些年的发展中,将视野从视觉信息上逐渐扩大,将文本信息、时空信息也引入到了行人再识别的研究中来。在研究中也证实到,多模态视觉信息、文本信息及时空信息的应用,使得算法在复杂场景下的识别率得到了一定的提高。这些多模态信息的出现,为多源信息行人再识别领域增添了很多的可能,也为研究提供了很多新的思路。
