二维形状特征描述及分类识别研究进展综述
2021-07-28邹媛媛陈泊璇
刘 磊,邹媛媛,陈泊璇
1.沈阳建筑大学 机械工程学院,沈阳110168
2.高档石材数控加工装备与技术国家地方联合工程实验室,沈阳110168
物体的形状特征由于其不会随着光照、颜色和纹理等的变化而发生改变,被认为是一个稳定的特征,因此,形状特征被广泛应用于物体识别、目标跟踪等领域。其中,鲁棒的二维形状表示可以提高形状识别的精度和准确率,因此,形状表示在形状识别、形状检索等相关应用中起着重要作用。通常,二维形状的表示可分为三类:基于轮廓的表示方法、基于区域的表示方法以及基于骨架的表示方法。近年来,研究学者针对二维形状的高效表示,在传统特征表示的基础上,不断提出了新的形状特征表示方法,例如通过融合不同类别的特征来表示二维形状,以提高形状描述的准确性。
高性能高精度的分类识别方法也会影响二维形状分类识别的准确度。现有研究中常用机器学习分类器进行二维形状分类识别,主要有支持向量机[1](Support Vector Machine,SVM)和随机森林[2](Random Forest,RF)等传统的分类器以及集成分类器,其中,集成分类器相较于单分类器,识别性能得到了一定的提升。基于机器学习的二维形状识别分类过程如图1 所示。随着深度学习的发展,运用卷积神经网络[3-4](Convolutional Neural Network,CNN)进行二维形状分类识别也受到了研究学者的关注,成为了一个新的方向。

图1 基于机器学习的二维形状识别分类流程图
本文首先对二维形状特征表示和识别中的关键问题研究现状进行了总结,接着,综述了近年来二维形状表示方法和识别分类方法,对各方法进行了综合分析,其中,形状特征表示方法分别包括基于轮廓的、基于区域的、基于骨架的以及基于多特征融合的二维形状特征表示方法,识别分类方法主要包括传统的机器学习分类器、集成分类器、深度学习方法等,然后,汇总了二维形状识别中常用的标准数据库,最后,展望了二维形状特征表示和分类识别方法的研究发展趋势,并对本文工作做了总结。
1 形状特征表示方法研究进展
鲁棒的二维形状表示应该对平移、旋转、尺度变换等变化不敏感,并对边界噪声有一定的鲁棒性。本章主要综述近年来二维形状特征表示方法的研究进展。
1.1 基于轮廓的形状表示
基于轮廓的二维形状表示方法基于形状边界,通过提取轮廓边界特征来表示二维形状。根据是否将轮廓进行分段,该方法又可分为使用总体轮廓的轮廓全局表示方法以及使用轮廓段的轮廓局部表示方法。
轮廓全局表示方法主要有Wang 等人[5]提出的名为高度函数(Height Function,HF)的形状描述符。首先将轮廓以固定的采样点进行表示,对于每个采样点,高度函数定义为其他采样点到此采样点切线的距离。然后通过平滑高度函数得到紧凑和鲁棒的形状描述符。Shu等人[6]提出的名为轮廓点分布直方图(Contour Point Distribution Histogram,CPDH)的形状描述符。这是一种通过极坐标下物体轮廓点的分布位置来表示形状特征的方法。CPDH是尺度不变和平移不变的,对于旋转不变问题,需要添加额外的条件加以保证。Shi等人[7]提出的基于轮廓重构和特征点弦长函数的图像检索算法,以轮廓为基础,这种方法通过分析轮廓的能量保持率并对轮廓进行降维重构,减少了噪声对轮廓的影响。通过筛选有效的轮廓特征点,得到轮廓点和相应特征点的弦长关系作为轮廓特征的表示,这种方法满足不变性要求。
轮廓局部表示方法主要有Laich 等人[8]提出的用有序的轮廓片段序列来表示轮廓形状的方法,然后使用最小二乘模型,将每个片段与一个三次多项式曲线相关联,再将得到的曲线进行归一化,得到最终的形状描述符,这种方法是缩放、旋转、平移不变的。Yang 等人[9]提出的一种名为三角形质心距离(Triangular Centroid Distances,TCDs)的形状描述符。首先通过离散曲线演化[10](Discrete Contour Evolution,DCE)算法将轮廓分割成轮廓片段,然后计算轮廓质心点,轮廓片段上的两个采样点和轮廓质心点形成一个三角形,计算此三角形的质心,得到三角形质心和轮廓质心之间的距离,作为最终的形状描述符。
近年来,有研究学者基于单词包[11-12](Bag of Words,BoW)模型,融合全局轮廓信息和局部轮廓信息,研究了一种形状特征包[13](Bag of Shape Features,BoSF)形状分类识别框架。该框架主要可分为以下几个部分:第一步提取输入形状的轮廓,并应用离散轮廓演化算法将轮廓分解为不同长度的轮廓段;第二步对每一个轮廓段进行特征描述;第三步进行形状编码,常用的编码方式为局部线性约束编码[14](Locality-constrained Linear Coding,LLC);第四步特征池化,并得到直方图作为最终的形状表示;第五步运用SVM 进行训练和实验。该框架最终得到的形状表示既包含局部信息,又包含全局信息。BoSF框架的算法流程图如图2所示,其中,特征池化方法可以采用空间金字塔匹配[15](Spatial Pyramid Matching,SPM),也可以采用最大池化及平均池化等。

图2 BoSF框架算法流程图
许多基于该框架提出的方法在常用的形状分析数据库上均取得了不错的识别率和分类准确率。Wang等人[16]提出了名为轮廓碎片包(Bag of Contour Fragments,BCF)的形状表示。这种方法使用形状上下文[17]描述每个轮廓片段,并使用LLC算法将其编码成形状代码,最终通过SPM算法汇集形状代码,得到紧凑的形状表示。Pedrosa 等人[18]提出了名为显著点袋(Bag of Salience Points,BoSP)的形状描述子,这种描述子为寻找两组显著点的对应关系提供了快速解决方案,有助于加速形状匹配任务。Shen等人基于该框架,在特征池化过程中采用最大池化和平均池化加权,并通过学习确定权重,这种改进提高了识别准确率。Zeng 等人[19]针对二维形状识别中的非刚性变换和局部变形问题,提出采用曲率对每个轮廓段进行表示,得到曲率词袋Curvature Bag of Words(CBoW)模型。实验结果表明该算法识别率高,鲁棒性好,适用于非刚性变换和局部变形的目标形状识别领域。表1对上文所提到的一些描述符做了汇总。

表1 几种基于轮廓的表示方法
基于轮廓的二维形状表示方法提取的特征包含丰富的边界信息,其中,轮廓全局表示方法抗噪性较好,但无法捕捉局部特征,导致区分不同形状的能力较差,轮廓局部表示方法能够更好地捕捉局部形状,但是对边界噪声较敏感,且不易实现,融合局部轮廓信息和全局轮廓信息的特征能够更准确地表示形状,识别效果更好。
1.2 基于区域的形状表示
基于区域的二维形状表示方法通过利用形状的内部区域来表示二维形状,有学者选择通过提取整个形状区域的特征进行表示,也有选择对区域进行分割,提取分割后的子区域特征进行形状表示。
柯善武等人[20]提出了一种融合图像显著区域二维形状特征的图像检索算法。这种方法很好地解决了当目标存在变形以及大小存在巨大差异时难以提取图像形状特征的问题。Wahyono 等人[21]提出了一种基于质心的树结构(CENTREES)。该方法是一种典型的基于区域的形状分类识别方法,其将形状质心作为根节点,根据点和相对于质心的主轴之间的角度将形状分成几个子区域,对每个子区域,用几种几何参数作为描述符。最终,所有参数的向量作为形状描述符,该方法是平移旋转缩放不变的。该算法的流程图如图3 所示。Wang等人[22]提出了一种将形状分解与形状分类相结合的框架,构造一个被称为“分解图”的数据结构,最后通过在分解图上搜索最优路径得到分解和分类的结果,实验证明该方法有很好的分类性能。Priyanka等人[23]提出了名为三角二阶形状导数的形状描述符,将几何概念和图像导数算子融合来实现特征描述和提取,取得了很好的检索率。表2对上文提到的方法做了汇总。

表2 几种基于区域的表示方法
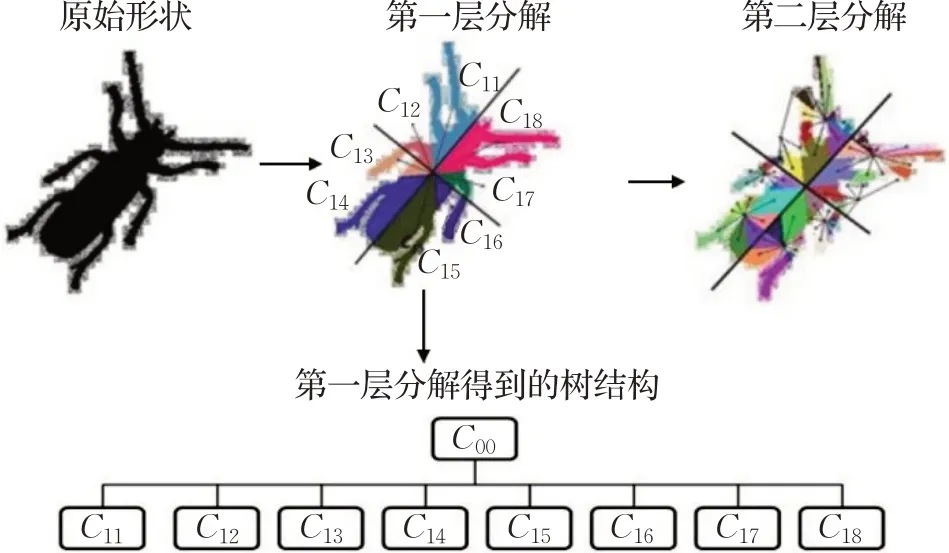
图3 基于质心的区域形状分解流程图
基于区域的二维形状表示利用了形状内部信息,多数学者采用对区域进行分割的方法,通过分割得到的子区域对形状进行描述,这种方法区分不同形状的能力更强。然而,区域分割方法不易实现,且当数据集较大且形状种类多时,存在细节信息丢失的情况。
1.3 基于骨架的形状表示
基于骨架的二维形状表示方法通过提取形状骨架来表示二维形状。在提取骨架时,用到了最大内切圆模型,最大内切圆指的是圆心在形状内部且至少内切形状轮廓上两个点的圆形。形状骨架点由这些内切圆的圆心集合而成。
陈展展等人[24]提出了一种骨架树匹配算法。这种算法不考虑骨架树的拓扑结构,只匹配骨架树的叶子节点,实验证明这种方法提高了匹配精度。Bai 等人[25]提出了一种称为路径相似骨架图的匹配算法。其主要思想是通过比较骨架端点之间的测地路径(骨架末端节点之间的最短骨架路径)来匹配骨架图,该方法不考虑拓扑图的结构,即使形状存在一些变形,该方法也能得到正确的结果。Aslan等人[26]提出了一种运用不连续骨架进行形状匹配的算法,这种表示没有传统连续骨架常见的不稳定性问题,实验结果证明该种表示方法鲁棒性较好。Shen等人[27]提出了一种聚类结构,它基于一个名为公共结构骨架图(Common Structure Skeleton Graph,CSSG)的骨架表示,这种骨架表示表达了集群的各个骨架的节点之间可能存在的对应关系,实验结果证明该方法是有效的。Xie等人[28]提出了一种形状匹配和建模方法,该方法基于代表性的骨架特征,在匹配过程中使用骨架分支与沿着形状曲线的连续片段进行自然对应,避免了不同片段之间的错误对应。实验结果显示了其具有很好的性能。
骨架是形状数据的一种简单的一维表示,不仅能表示形状的拓扑信息并且包含一些丰富的细节信息。然而,当形状受到较大噪声影响时,骨架可能会存在冗余的骨架枝,导致结构混乱,影响对真实形状的判断。
1.4 基于特征融合的形状表示
在二维形状特征表示中,为了提高形状描述的准确性,有研究学者在传统特征表示的基础上,通过融合多种特征来表示二维形状,并取得了很好的识别效果。
卢勇强等人[29]采用轮廓与骨架相结合的方法来描述二维形状特征,该方法引入生物信息序列分析方法到二维形状分析中,提出了一种轮廓骨架协同编码方案。实验结果表明,与原有方法相比,该方法提高了识别效率和准确性。Yang 等人[30]提出了一种用于形状匹配和检索的不变多尺度描述符,该方法对DCE 算法加以改进,改善了原算法的过度演化问题,并采用这种改进之后的称为自适应离散轮廓演化(ADCE)的算法提取轮廓显著特征点,并将归一化面积、弧长和中心距离三种描述符进行融合,作为最终的二维形状表示,实验结果表明该表示方法具有较好的鲁棒性。Lin等人[31]针对非线性失真导致形状轮廓分类性能差的问题,提出了一种基于轮廓的多特征融合算法,实验结果显示该方法优于原有的其他方法,解决了几何变换和非线性失真导致的分类性能差的问题。Shen 等人[32]提出了一种称为骨架相关形状上下文(Skeleton-associated Shape Context,SSC)的形状描述符,该描述符获取与骨架信息相关的轮廓片段,在此基础上,运用BoSF 框架进行特征提取,形成了一种对整体形状有意义的特征向量。实验结果表明,该方法在几个标准形状数据集上取得了很好的识别性能。Lin 等人[33]提出了一种运用区域特征进行形状分类的方法,该方法将名为区域骨架描述符(Region Skeleton Descriptor,RSD)、区域面积描述符(Region Area Descriptor,RAD)和简化形状签名(Simplified Shape Signature,SSS)三种描述符进行融合,作为最终的形状表示,在核极限学习机[34-35](Kernel Extreme Learning Machine,K-ELM)上进行实验。实验结果表明该方法的效率和准确率都很高。表3 对上文提到的特征融合方法做了简单汇总。

表3 几种特征融合的表示方法
上文提到的基于轮廓、区域、骨架以及特征融合的二维形状表示方法各有优缺点,表4对其做了一个汇总。

表4 各类表示方法对比分析
2 形状分类方法
二维形状分类识别中,通常选用机器学习分类器进行形状分类,在提取出形状特征后,通过选取训练样本,训练分类器,最终可以得到有效的模型完成形状分类识别。本章主要讨论了在二维形状分类中常用的传统机器学习分类器、集成分类器以及深度学习方法。
2.1 传统机器学习分类器
传统的分类技术又可分为有监督学习和无监督学习两类,在二维形状分类中,常用的分类器多为有监督分类器,包括朴素贝叶斯分类器、随机森林、支持向量机等等。
朴素贝叶斯分类器是一种概率分类方法,其原理是利用贝叶斯公式,根据某种特征的先验概率计算出它的后验概率,选择具有最大后验概率的类别作为特征所属的类别。朴素贝叶斯分类器的优点在于数据集易于训练,并且完成计算所花费的时间较少。
Sun 等人[36]利用类段集对轮廓形状进行分类,实验采用了贝叶斯分类器,得到了很高的分类精度。
随机森林(RF)是一种有监督学习的分类器,它包含多个决策树。决策树是一种树形结构,它通过将数据划分成具有相似性的子集来完成树的构建,这种划分过程会一直持续到不能继续划分下去为止。树中包含两种节点,其中,有两个及以上分支的节点称为决策节点,没有分支的节点是叶子节点。随机森林是许多决策树的一个集成,并且输出的类别由个别树输出类别的众数决定。随机森林的效率很高,即使是大型的数据集,依旧可以高效运转,且在数据不一致的情况,它也能提供准确性。
Lepetit 等人[37]将随机森林分类器用于三维物体检测和姿态估计。Bosch等人[38]比较了随机森林分类器与支持向量机(SVM)用于图像分类的性能,结果表明,当使用感兴趣区域(Region Of Interest,ROI)时,随机森林分类器较支持向量机有约5%的性能提升,且当在分类器训练期间生成额外的数据时,随机森林分类器的性能也会得到提升,文章方法的随机森林分类器与支持向量机相比,最终得到一个约10%的性能提升。Huang等人[39]提出了一种管状结构分类的方法,该方法提取了三个形状描述符:三角形面积、距离阈值以及最小惯性轴,将其组合作为最终的形状表示,并使用随机森林分类器进行训练和实验,取得了很好的分类结果。Keskin 等人[40]运用随机森林分类器进行手势形状分类,同样得到了很好的分类效果。
支持向量机(SVM)是一种有监督学习的分类器,是当前最常用的分类算法。SVM的决策边界是对学习样本求解的最大边距超平面。SVM的目标是以最小的错误率对物体进行分类。SVM的优势在于给出的结果比其他方法更准确,但是它的训练过程需要一定的时间且需要额外内存来存储训练图像[41]。
文献[16]使用线性支持向量机分类器进行形状分类,同时提出使用径向基函数核和交集核等能够提高性能,但较为耗时。文献[13]同样使用了线性支持向量机进行形状分类。文献[32]使用线性支持向量机进行形状分类,并指出该方法使用非线性核分类器反而会导致性能下降。Daliri 等人[42]提出了一种形状识别的核方法,该方法使用支持向量机进行形状分类,在常用的形状分析数据集上均取得了较好的结果。
2.2 集成分类器
对于有监督机器学习任务,集成学习是一种有效的方法,其思路是通过多机器学习算法的集成来提升预测的结果。理论上,集成学习在训练集上比单一模型的拟合能力更强,且某些集成学习方法也能更好地处理过拟合的问题。对于分类性能好的分类器,集成学习往往能够给予更高的权重。
常用的集成方法包括bagging[43]、boosting[44]等,除此之外,投票法、简单加权以及随机森林方法也常用于分类器的集成。
采用相同的分类算法,在不同的训练集子集上进行训练,且采样时将样本放回,这种方法称为bagging,也称为自举汇聚法。使用该方法进行集成得到的分类器与单一分类器相比,降低了在训练集上训练的偏差和方差。该方法流行的原因不仅在于其可以并行进行,还因为此方法易于拓展。
提升法是指将多个弱学习器结合成为一个强学习器的集成方法,代表方法包括AdaBoost 和梯度提升两种。两种方法类似,差别仅在于AdaBoost 方法不再是调整单个预测器的参数使得成本函数最小化,而是不断在集成中加入预测器,使模型越来越好。该方法的缺点是无法并行,所以在拓展方面的表现不如bagging方法。
投票法是指将多个分类器的结果进行聚合,然后将得票最多的结果作为最终的结果的一种方法,这种大多数投票分类器也被称为硬投票分类器,其工作原理如图4所示。

图4 多数投票法集成分类器
简单加权是指使用不同的分类器在同一训练集上进行训练,得到的结果通过权重进行组合的一种集成方法。通常,组合权重α可通过学习过程获得。加权组合得到的集成分类器性能往往高于单一的分类器。
Mohandes 等人[45]提出了一个基于准则的多分类器组合技术框架及其应用领域,将分类器的组合类型大致分为四类:组合级别、阈值类型、组合的适应性和基于集成的方法。Wang等人[46]提出了一种融合特征以及分类器的方法来进行形状识别,该方法通过训练7种不同的单分类器,并通过平均规则进行融合得到分类结果,在标准形状分析数据库上显示出很好的性能。Rida等人[47]提出的掌纹识别,Zhao 等人[48]提出的手写字体识别,均采用了集成学习的技术,显示出分类器集成相较于单分类器,性能得到了提升。
2.3 深度学习方法
卷积神经网络(CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,它是多层感知器(MLP)的一个变种形式。其基本结构由三层组成:输入层、隐藏层、输出层。其隐藏层又包含卷积层、池化层、全连接层等结构。CNN 对于大数据集的处理效果很好,当数据集样本偏小时,性能受到很大影响。采用CNN 进行形状分类识别流程如图5所示。

图5 卷积神经网络进行形状识别分类流程图
Atabay 等人[49]提出了一种适用于二值图像的CNN结构,该方法在小尺度的二值图像上性能较高且时间复杂度较低。在另一篇文章中,Atabay 等人[50]将CNN 用于叶片图像分类,引入指数线性单元(ELU)代替校正线性单元(ReLU)得到新的CNN 结构。实验结果表明在两个叶片数据集上,新的CNN网络结构性能优异。Tixier等人[51]利用传统的2D CNN网络进行图形分类,该方法将图形进行处理之后输入进网络来进行后续操作,该方法在时间复杂度方面优于图核方法,并且适用于更大图形的更大规格的数据集。表5 对上文提到的几种分类器做了简单汇总。

表5 几种不同分类器的识别率比较
3 二维形状标准数据库
为了便于开展二维形状分析研究,目前,研究学者建立了多个二维形状标准数据库,本文将常用的二维形状标准数据库进行了汇总。
MPEG-7数据库[52]是形状分析研究领域中最常用的数据库,其包含70个类别,在每个类别中,有20个形状,因此数据集中的形状总数为1 400个。
Animal数据库[53]包含20个类别,每个类别中有100个形状,总共由2 000 个形状组成。由于动物是非刚性物体,该数据集中的形状具有很高的类内可变性,因此,这个数据库的分类识别任务相当具有挑战性。
Swedish leaf 数据库[54]由15 个类别组成,每个类别有75个样本,共有1 125个形状。由于有较大的类内差异,这个数据库的识别也相当具有挑战性。
ETH-80数据库[55]包含八类对象。每个类别中有10个物体是从不同的视角拍摄的,每个物体有41 幅彩色图像,如图6所示,共有80个样本。
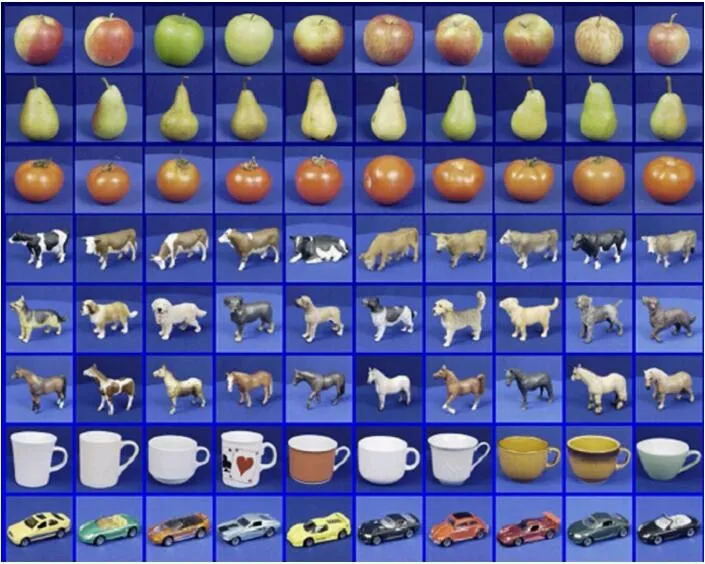
图6 ETH-80数据库
Tools数据库[56]包含8类对象,其中包括6类不同的剪刀和2 类订书机,一共40 个形状,如图7 所示。在每一类中,这五种形状相互之间有较大的关节变形差异。

图7 工具数据库
针对二维形状识别分类问题,分类识别准确率[16]往往是执行分类任务的算法的评估标准。基于机器学习的方法中,半训练和留一法是两种常用的评估方案。半训练是指将一半样本用于算法的训练,另一半样本用于实验测试。留一法是指将90%的样本用于算法训练,剩下的10%样本用于实验测试。
表6 汇总了上文提到的表示方法和识别分类方法在标准数据库上的识别率。并将现有在上述五个数据库上表现较突出的方法的识别率汇总在表7之中。

表6 各方法识别率汇总

表7 不同数据库上表现较突出的方法的识别率
4 研究发展趋势
随着二维形状特征描述及分类识别技术研究的不断深入,学者们提出了众多的形状描述符以及识别分类方法。由于实际中的形状往往存在噪声、变形、遮挡等情况,使得这些方法的准确实现受到挑战。因此,对该领域的研究还有很多值得深入的地方。
在表示方法方面,单一的人工特征描述符方法接近稳定,基于此,新提出的特征描述符往往尝试将传统特征进行融合,将融合后的特征作为最终的形状描述符,以提高形状表示的准确性。在分类识别方法方面,传统的动态规划方法以及相似性度量方法存在算法复杂度高以及精确度不够的问题,使得机器学习方法逐渐被学者们应用到二维形状识别分类的研究当中。不满足于单一分类器得到的结果,已有学者运用集成学习方法将多种分类器进行集成,以提高分类识别的精确度。同时,深度学习方法也在该领域得到了应用,并展示出良好的性能。
5 结束语
本文综述了用于二维形状特征描述及分类识别领域的新的技术。主要从形状特征提取、形状分类识别、形状数据库三个方面展开讨论。形状特征提取方法主要基于轮廓、区域、骨架三种特征,特征融合方法的提出,一定程度上弥补了单一特征进行形状分类识别所表现出的不足。分类识别方法主要基于机器学习,现有方法大多使用单一分类器完成分类识别任务,集成学习方法也在形状分类识别领域得到应用,并取得了令人满意的结果。文中列举的形状分析数据库是进行二维形状分类识别实验常用的数据库,不同方法在不同数据集上的表现略有差别。
