多尺度高分辨率保持和视角不变的手姿态估计
2021-07-28杨文姬黄丽芳
熊 杰,彭 军,杨文姬,黄丽芳
1.江西农业大学 计算机与信息工程学院,南昌330045
2.江西农业大学 软件学院,南昌330045
3.浙江大学CAD&CG国家重点实验室,杭州310058
4.江铃控股有限公司,南昌330052
基于视觉的手姿态估计在人机交互、AR(增强现实)、VR(虚拟现实)和机器人操作等方面有着重要的作用。然而在手姿态的估计过程中会因为手的固有特性而存在自遮挡、自相似和高自由度等难题。为解决这些问题,有些研究者从深度图像[1-6]或多视角相机系统[7]中估计3D 手姿态,但由于其便捷性不足以及普适性不高等种种原因,不能被广泛推广到实际应用场景中。因此直接从单张彩色图像中估计手姿态显得尤为重要[8-12]。
从单张彩色图像估计3D 手姿态的流程主要有三种,第一种是直接从图像中估计出3D姿态[11],第二种是先估计2D 热图(亦可当作估计2D 手姿态),然后利用CNN 学习2D 热图到3D 姿态的映射[8,13-14],最后一种是联合估计2D姿态和3D姿态[9-10],其中第二种流程如图1所示,本文也采取该流程进行2D和3D手姿态估计。在该流程中,很多研究者专注于3D姿态估计的创新[8,13]而缺少了对2D姿态估计的重视,然而3D姿态估计的结果依赖于2D姿态,因此提高2D姿态估计的精度对于估计3D姿态是有帮助的。
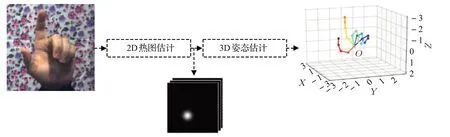
图1 手姿态估计流程图
目前2D 手姿态估计主要是通过估计2D 关键点热图的方式来实现。现有2D关键点热图估计大多数采用卷积姿势机(Convolutional Pose Machine,CPM)[8,13]或沙漏网络(Hourglass Network,HNet)[10,14]进行。如文献[10,14]使用了HNet,该网络由一个串联的对称的高到低和低到高分辨率子网络的结构组成,即先将经过前期卷积处理的特征图通过高到低分辨率子网络进行下采样得到尺度较小的特征图,然后使用最近邻上采样逐步恢复到原始分辨率,并在恢复过程中以跳跃连接的方式与下采样中的相应尺度特征图的低层次特征进行融合,以达到多尺度特征融合的目的。然而HNet 不能在整个训练过程中始终保持高分辨率表示,从而导致得到的高分辨率表示不够稳定,不利于手关节的精准定位。文献[8,13]采用CPM 进行2D 关键点热图估计,其先通过VGG 网络将输入下采样到一定大小的特征图,然后对该特征图进行多阶段的热图估计,具体地将上一阶段的输出作为下一阶段的输入以逐步提高估计精度,并在每个阶段中进行中间监督来解决梯度消失问题。该方法在一定程度上能够维持高分辨率表示,但在多阶段学习过程中分辨率唯一,没有多尺度特征表示和多尺度融合,因此不能很好地描述手姿态不同方面的信息。
针对现有的HNet不能始终保持高分辨率表示以及CPM 没有进行多尺度特征融合等问题,本文引用一种新的网络架构——高分辨率网络(High-Resolution Network,HRNet)[15]用于提升手关节2D热图估计的准确性,进而有利于后续的3D 姿态估计。该网络采用并行结构连接高低分辨率子网络,并在不同分辨率子网络间进行反复融合以增强各自分辨率表示的特征。为了融合更多的分辨率子网络,形成了多个阶段,每个阶段是在前阶段基础上融入新的低分辨率子网络并进行并行连接而构成。
该网络以并行的方式连接多个分辨率子网络,因此能始终保持高分辨率表示且得到的高分辨率表示也更稳定。此外,在所有分辨率表示下进行反复的融合来增强各分辨率表示特征,使最终输出的高分辨率表示是丰富的,因此能使热图预测得更精准。
为了获得3D 姿态,在得到2D 热图后,使用全局旋转视角不变的方法[8]将2D 热图映射到3D 姿态。最后,在三个公开数据集(RHD、STB、Dexter+Object)上定量或定性地验证了本文方法在2D 手姿态估计和3D 手姿态估计上的有效性。
1 相关工作
手姿态估计的方法可以分为三类,包括判别方法[16-18]、生成方法[19-22]和混合方法[23-27]。判别方法通过数据驱动方式学习图像到手姿态的映射,其典型代表是最近热门的深度学习。后两类方法都需要一个预定义的手模型,用来寻找被检测图像最有可能的姿态,其过程是复杂且耗时的。本章主要对基于深度学习的彩色图像手姿态估计研究进行简述。
在彩色图像的手姿态估计中,很多方法[7-8,10-11,13-14,18,28]使用CPM或HNet进行2D关键点热图估计或手姿态特征提取,并将得到的特征表示用于后续工作(如3D姿态估计)。Zimmermann 等人[8]是第一个提出利用CNN 的方法完成3D 手姿态估计的任务,设计了一个规范坐标系,让网络学习该坐标系下关键点位置的隐式铰接先验来估计相对的3D 手姿态。Cai 等人[13]只在网络训练期间利用额外的深度图像对3D手姿态回归起到弱监督作用。Yuan等人[11]将深度图像当作特权信息,利用配对的深度-彩色图像分别训练基于深度图像的网络和基于彩色图像的网络,并在这两个网络的中间层中共享信息。Simon 等人[7]采用多视图自举的方法提升2D 热图估计网络的精度,并将多视图2D 姿态三角化成3D 手姿态。Iqbal等人[10]提出一种包含2D热图和深度值热图的2.5D热图表示,然后从该表示中重构3D 姿态。与估计稀疏的3D手姿态不同[7,8,10-11,13],Baek等人[28]采用密集的参数化3D 手模型估计3D 手网格。Ge 等人[14]提出了一种基于图卷积神经网络(Graph CNN)的方法估计3D 手形。Zhang 等人[18]通过多任务设置和几何约束来估计3D 手形、2D手姿态和3D手姿态。
总之,目前基于彩色图像的手关节2D 热图估计[7-8,10,13-14,18,28]或手姿态特征提取[11]工作大多数采用CPM或HNet进行。由于上述两种网络在获取特征表示方面存在不足之处,本文引用HRNet 来估计2D 关键点热图,该网络能形成稳定且丰富的高分辨率表示以进行空间精准的热图估计。
2 本文方法
本文方法包含两个部分,分别为基于多尺度高分辨率保持的2D 手姿态估计和基于视角不变的3D 手姿态估计。
2.1 基于多尺度高分辨率保持的2D手姿态估计
将一张彩色图像I∈PH×W×(3P表示图像矩阵,H、W为图像的高、宽)作为2D热图估计网络的输入,网络会为每个关键点产生一张热图,即K个关节产生K张热图。从每张热图中选择置信度(热值)最大的位置作为关键点的位置,K个关节位置jk:jk=(uk,vk),其中u、v表示像素坐标,K在本文中为21。
2D 热图估计网络由三个部分组成,首先是一个包含两次下采样的卷积层,将分辨率为256×256的输入提取到64×64大小的特征图。紧接着就是HRNet,其输出的特征图具有与输入特征图相同的分辨率。最后通过回归网络(拥有21个卷积核的卷积层)来估计2D热图。
2.1.1 HRNet总体结构
该网络遵循ResNet[29-30]中各阶段的深度分布和各分辨率表示之间通道数成一定倍数关系的设计规则,包含四个阶段且相邻的大小不同的特征图之间通道数之比为2。对于融合过程,受到文献[31]中融合多个分支网络的中间表示方法的启发,对多个分支进行反复融合以增强各分辨率表示特征。
具体的,HRNet由四个并行连接的多个分辨率子网络和四个阶段组成。除第一行子网络外,其他并行子网络的第一个输入由上一行特征图下采样而来,边长是其一半,通道数是其两倍。除第一阶段外,其余各阶段由高到低分辨率子网络构成并通过融合单元(融合单元说明见2.1.2 节)交换多个分辨率子网络之间的信息。网络结构如图2 所示,数据流表示特征图没有经过任何处理,水平方向和垂直方向分别表示网络的深度和特征图分辨率大小,融合方式为值相加。第一阶段包含了4 个残差单元,每个残差单元是宽度为64 的瓶颈网络(bottleneck)。第二、三、四阶段分别含有1、3、3 个融合块,每个融合块由对应多个分辨率的卷积单元和一个融合单元组成,而每个卷积单元又有四个残差单元,每个残差单元包含两个3×3 卷积核和不进行任何操作的跳转连接部分。
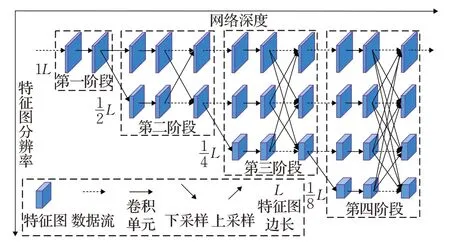
图2 HRNet结构简图
本次实验的网络中,各并行子网络的卷积通道数分别为32、64、128、256,对应特征图边长分别为64、32、16、8。
2.1.2 多尺度特征融合
为进行反复的多尺度融合,在网络的同一阶段不同子网络间引入融合单元,以便于每个子网络能接收来自其他并行子网络的信息。融合单元能将多个分辨率子网络输出的特征图多次融合成对应多个分辨率子网络的输入。如图3所示,将第3阶段融合单元F分为f1、f2、f3三个部分进行从高到低分辨率特征图融合,下采样使用卷积核为3×3,步长为2的卷积层,上采样采用最近邻插值方法。对于f3,虚线方块体表示第一次下采样的特征图,然后对此再进行下采样得到目标特征图。
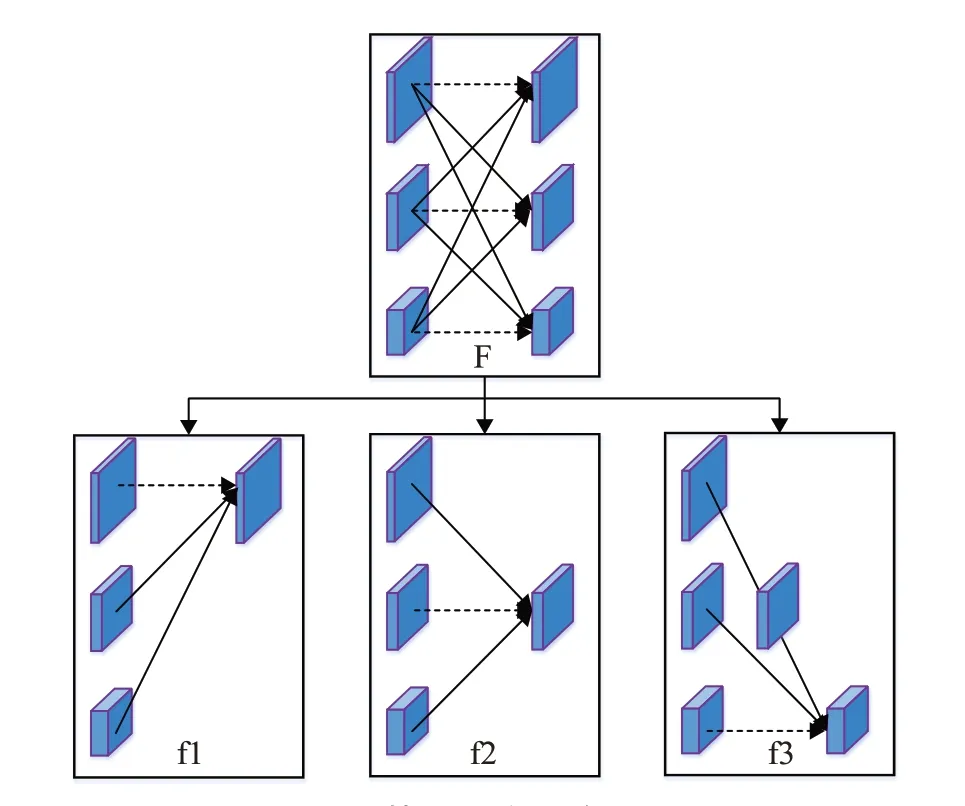
图3 第三阶段融合单元
在融合单元中,输入有n个不同分辨率的特征图:{X1,X2,…,Xn},输出也有n个不同分辨率的特征图:{Y1,Y2,…,Yn},并且输出的各特征图的分辨率大小和宽度(宽度为特征图个数)与输入一样,从图3中可以看出这一点。
输出Ym=,函数s(Xi,m)包含下采样或上采样操作以使处理后的特征图分辨率大小保持一致。例如,当特征图边长为1L,而目标特征图边长为时,用一个大小为3×3,步长为2 的卷积核进行下采样。如果目标特征图边长为,则用两个连续的大小为3×3,步长为2 的卷积核进行两次下采样,以此类推。对于上采样,用最近邻插值方法放大特征图。为保证上采样后的特征图宽度与目标一致,在上采样前要先经过1×1大小的卷积核处理。如果i=k,则不需要经过任何操作,如图3中的虚线箭头。
为直观地表示某一阶段处理过程,此处以第三阶段N3 为例,如图4 展示了该阶段有三个融合块B1、B2、B3,且每个融合块包含了三个并行卷积单元和一个融合单元。
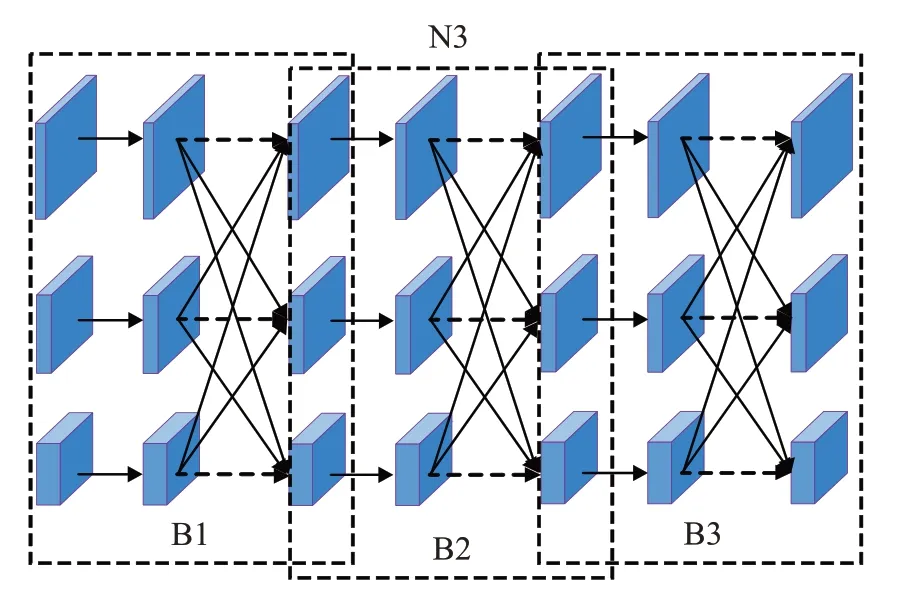
图4 第三阶段网络结构图
2.1.3 损失函数
在HRNet后添加一个通道数为K的卷积层来回归热图。损失函数LH定义为预测热图Hpred与真值热图Hgt的均方误差,其中真值热图使用标准差为2 的高斯函数得到,其中心在每个关节点的位置上。真值热图:
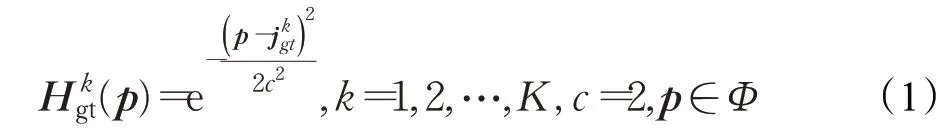
Φ为热图上的像素点位置。损失函数LH公式如下:

2.2 基于视角不变的3D手姿态估计
2.2.1 3D手姿态坐标的表示
定义相机坐标系内3D 手姿态坐标为ck:ck=(xk,yk,zk)。为解决绝对坐标中手姿态的偏移和尺度模糊问题,采用平移不变(见公式(3))和尺度不变(见公式(4))的方法将绝对坐标标准化,过程如下:

表示相对坐标,cr为手掌关节坐标,此时手掌关节为坐标原点。然后将标准化:

其中,表示标准坐标,s为中指掌指关节(如图5中的m)与中指近端指间关节(如图5中的p)之间的欧式距离。
为使网络学习到全局旋转视角不变的手姿态,将转换成规范坐标系[8]内坐标即规范坐标,公式如下:

R()是一个3×3 的变换矩阵,其通过两个步骤计算得到。首先,将中指掌指关节依次绕着z、x轴旋转使该关节落在y轴上(即让图5 中线段加粗部分om与y轴对齐)以计算出Rz,Rx:
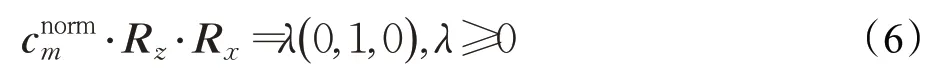
然后将经过式(6)变换后的小指掌指关节(如图5中的i)绕着y轴旋转使该关节的z值为0计算出Ry:
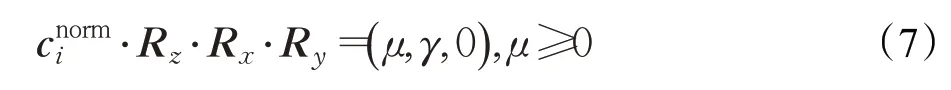
经过上面两个变换步骤后,最终的标准坐标到规范坐标的变换矩阵表示如下:

由于左、右手之间存在对称关系,因此当目标是右手时,可以沿着z轴翻转右手,左手情况下坐标不变。图5 给出了标准坐标和规范坐标的几张示例图,可以看出标准坐标的手姿态方向变化较大,而规范坐标的手姿态方向基本一致。
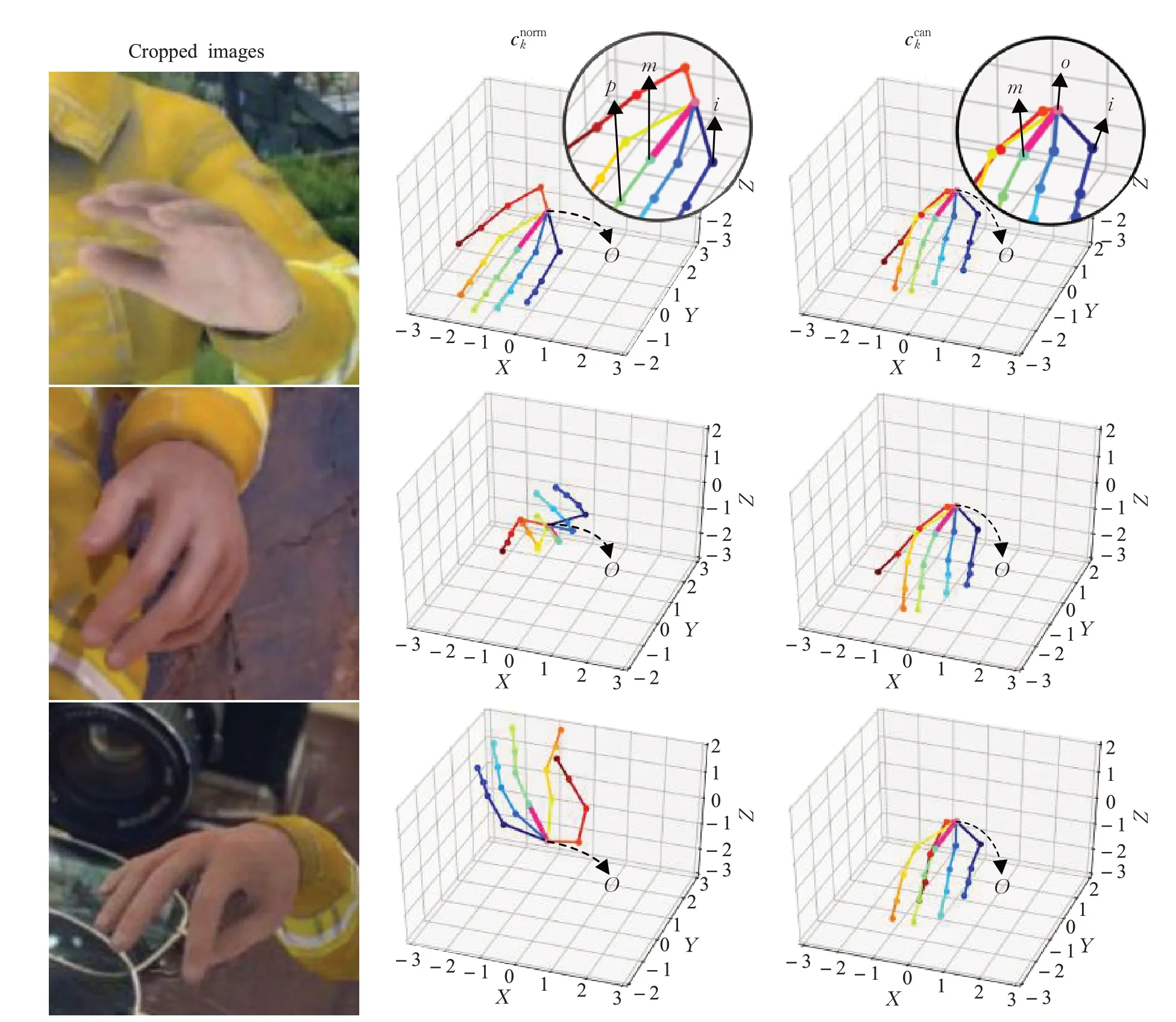
图5 不同坐标表示的手姿态
2.2.2 2D热图到3D姿态估计网络
为方便描述,后文将和中的下标k去掉。在第2.1节得到2D热图的基础上,使用文献[8]中的姿态先验网络来估计标准坐标。该网络有两个并行的处理流,一个用于估计样本的规范坐标ccan,另一个估计旋转矩阵R。R为R(cnorm)-1,可看作样本从规范坐标转换回标准坐标的视点。两个处理流结构一致,只是参数不相同,都先使用六个卷积层得到特征表示,然后与图像显示左手或右手的独热编码(One-Hot Encoding)连接起来,再通过三个全连接层分别估计规范坐标ccan和对应视点R。然后标准坐标cnorm可由式(5)推断得出。网络结构如图6 所示,这里实线箭头表示一个卷积层,长方形条表示一个全连接层。
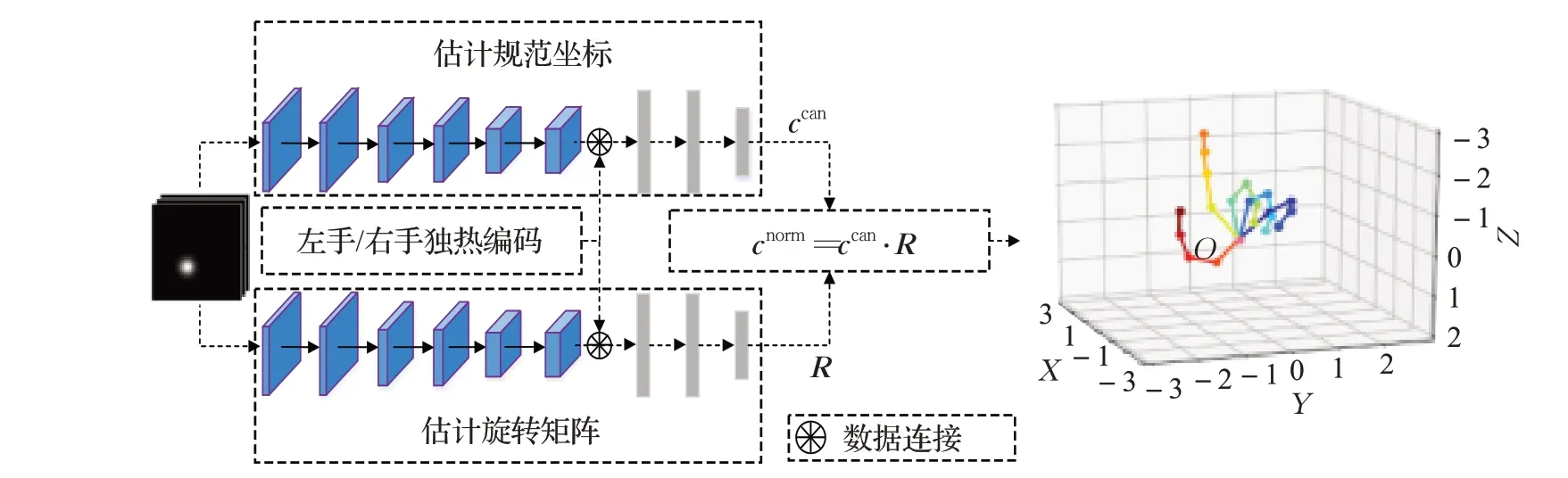
图6 3D手姿态估计网络
2.2.3 损失函数
该网络包含两个损失,首先是规范坐标ccan的均方误差:

然后是对应样本的旋转矩阵R的均方误差:

总损失为Lc和LR之和。
3 实验及结果分析
3.1 数据集及预处理
为验证本文方法的有效性,在RHD、STB和Dexter+Objec(tD+O)数据集上进行了实验。
RHD数据集[8]是人工渲染合成的数据集,训练集有41 258张图像,测试集有2 728张图像,图像的分辨率为320×320,每张图像都拥有2D 和3D 标签以及对应的手部掩模,本文实验只用到前两种标签。
STB数据集[32]是真实世界中采集的数据集,按六个不同的背景和难易两类手姿态被分为12 份,每份有1 500张图像,其中10份当作训练集,另外2份当作测试集。每张图像的分辨率为640×480,同样实验中用到了2D和3D关节标签。
D+O数据集[33]是手与物体交互的数据集,其根据手与物体不同的交互动作划分为6 份,总共有3 145 张图像,每张图像的分辨率为640×480。该数据集对手部只提供五根手指的指尖坐标。
RHD和STB数据集的区别:
(1)RHD 数据集21 个关节包括手腕和五个手指各手指的掌指关节、近端指间关节、远端指间关节、顶端指间关节,而STB数据集其中一个关节点不是手腕而是手掌心。
(2)关节排序不一致。
由于网络的输入是以手为中心的裁剪图像,而且数据集之间存在差异,因此需要对原图和标签进行预先处理,以使网络能顺利学习到手的特征。具体处理如下:
(1)以STB手部关节位置为参考,将RHD的手腕坐标与中指掌指关节坐标求均值得到掌心坐标。
(2)调整RHD数据集中手部关节顺序,使其与STB数据集关节顺序一致。
(3)以中指掌指关节坐标为手的中心位置,找到能包含所有关节点的最小正方形框,并缩放到256×256大小。为使裁剪的图像能将手完全包含进去,将这个最小正方形框边长放大了0.25 倍。当然在评估的时候手会被还原到原始大小,以保证数据对比的公平性。
特别的,由于D+O 数据集对手部只提供五根手指的指尖坐标,不能通过手的关节坐标得到以手为中心的裁剪图片,且无法获得相对坐标,因此本文不对其进行定量分析,只做定性实验,从视觉上体现出本文方法对复杂场景下的手姿态估计仍具有一定效果。为了从该数据集中提取手的部分,使用文献[8]的分割网络来裁剪出手部图像并缩放到256×256大小,然后用此图像作为本文网络的测试集进行实验。
3.2 实验细节
实验由2D 姿态估计网络和3D 姿态估计网络两部分组成。对于2D姿势估计网络,其训练分为两次,第一次只使用RHD 数据集初始化该网络参数,第二次则在第一次基础上用STB和RHD数据集混合训练网络。两次训练轮数都为20,学习率前10 轮为10-3,后10 轮为10-4。3D姿态估计网络的训练过程与2D姿态估计网络的类似,但两次训练轮数都为25,前15 轮的学习率为10-5,后10轮为10-6。两部分网络一次性训练的样本数据量都为16。实验在Pytorch 深度学习框架上实现,GPU型号为NVIDIA RTX 2080 Ti。
3.2.1 HRNet各阶段融合块数量的确定
网络包含了多个阶段,各阶段融合块数量的合理配比决定了网络的性能(第一阶段不需要多尺度融合,因此没有融合块)。在保证网络的精准度和处理速度的前提下,在RHD数据集上做了11组实验,如表1。该表中FPS表示测试时每秒评估样本的速度,AUC和EPE两个评估指标说明见3.3.1 节。从表1 中第1、2、3、4 等四组实验结果对比可知当第二阶段融合块数量大于1 时AUC 值有所下降,这可能是由于层次(深度)过深的较高分辨率表示对生成后续阶段的低分辨率表示不够友好导致的,因此第二阶段融合块数量设置为1即可。由表1 中第1、6、10 和5、7、11 等6 组实验结果可知当第三或第四阶段融合块数量为2,增加第四或第三阶段融合块数量时精度都会持续提升,但从EPE mean值可以预见再继续增加融合块数量对网络性能提升并不大,反而增加了网络运算量降低了估计速度。此外还可以预见这两个阶段融合块数量间存在一个平衡以使网络性能最佳,再结合第3、8、9 等3 组实验综合考虑第三和第四阶段融合块数量应皆设置为3,此时网络综合性能最优。综上所述,网络第二、三、四阶段融合块数量应分别设为1、3、3。
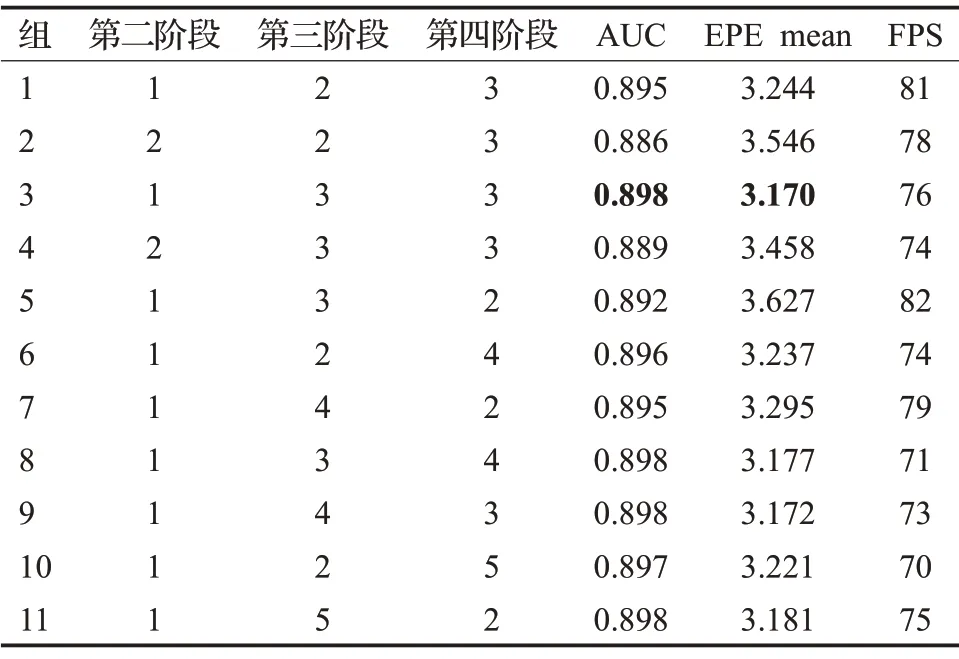
表1 HRNet各阶段融合块不同数量的评估结果
3.2.2 混合数据集训练
由于STB数据集中真实数据样本数量有限、视觉多样性不够丰富以及标注不完整等方面的问题,加入RHD数据可以充实STB数据集从而提高网络的泛化能力。本文首先用RHD数据初始化网络,然后将RHD和STB两个数据集按照1∶1的比例训练初始化后的网络,并用训练后的网络进行2D 姿态的估计,实验结果见表2。由结果可知,混合训练时在RHD(AUC 为0.890)和STB(AUC 为0.869)数据集上的测试结果都较好,表明该方法能同时学习到两个数据集的特征分布。文献[8]在RHD数据集的结果较差的原因可能和数据集训练的方式有关,其是先用RHD数据初始化网络,之后再输入STB 数据微调网络,这使得网络在先前RHD 数据上学到的特征被后续在STB数据集的训练冲淡,因此网络在RHD数据上的准确性下降,在RHD数据集上的AUC仅为0.724。
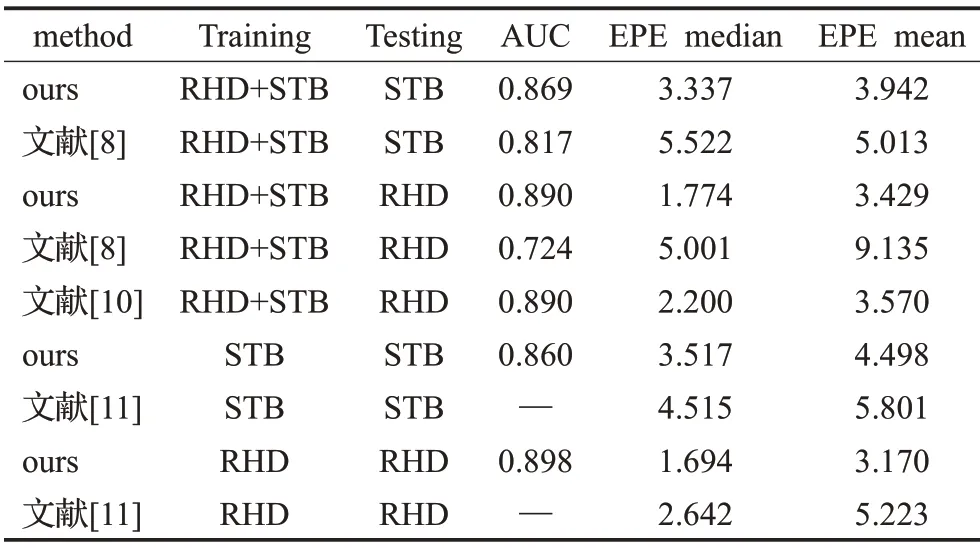
表2 不同方法的2D手姿态评估结果
需要注意的是,在3D姿态估计网络中,由于这两个数据集的2D 和3D 的转换关系(相机内置参数)本身存在差异,因此混合训练时合成数据占比要降低,否则会导致该部分网络对真实数据预测变差。该部分网络训练过程中设置样本数STB:RHD为6∶1。
3.3 2D手姿态估计
为验证HRNet 在2D 手姿态估计中的有效性,分别从定量和定性两个方面进行了实验。
3.3.1 定量对比
本文与其他文献[8,10-11]一样,采用像素上的平均端点误差(EPE)和在不同错误阈值下正确关键点百分比下的曲线下面积(AUC)作为评估指标进行数据对比,
其中EPE 值越小表示评估误差越小,AUC 值越大表示评估精度越高。实验结果见表2,该表中除本文方法得到的数据外,其他数据来自相应文献[8,10-11],其中文献[10]只提供了在RHD 数据集上的测试结果。从表2中看出,在平均端点误差中位数(EPE median)和均值(EPE mean)上,本文方法均优于献[8,10-11]。在AUC值上,相比于文献[8],在STB 数据集上高出约5 个百分点,在RHD数据集上高出约15个百分点。相比文献[11],在STB数据集上的EPE mean值下降了22.5%,从5.801下降到4.498,在RHD 数据集上的EPE mean 下降了39.3%,从5.223 下降到3.170。与文献[10]相比,各评估指标数值比较接近,可能是因为该文献采用了联合估计的方法,使得2D 与3D 估计能够相互促进。但即使如此,本文方法仍具有一定优势。
3.3.2 定性结果
为了更直观地展示2D 关节估计的准确性,将估计结果进行了可视化,如图7所示。该图中前两行是STB数据集,后两行是RHD 数据集,最后一行为D+O 数据集,其中一、三行为真实标签,二、四、五行为预测结果。由结果可知,在RHD、STB两个数据集上的预测均达到了不错效果。由于训练集中并没有类似手与物体交互的图像,因此对D+O 数据集中被物体遮挡的手关节预测存在一定误差。

图7 2D手姿态可视化
3.4 3D手姿态估计
3.4.1 定量对比
本文在STB数据集上和五种先进方法[8-9,27,32,34]得到的3D手姿态效果进行对比,结果见图8。图8展示了不同方法在不同错误阈值情况下的PCK曲线,左图为STB数据集上的对比结果,右图为RHD 数据集上的对比结果,除本文方法得到的数据外,其他实验数据均来源于文献[14]。由图可知,在STB 数据集上,在大多数错误阈值上本文方法都优于参与比较的方法。在RHD数据集上,AUC值要比文献[8]高出0.109。
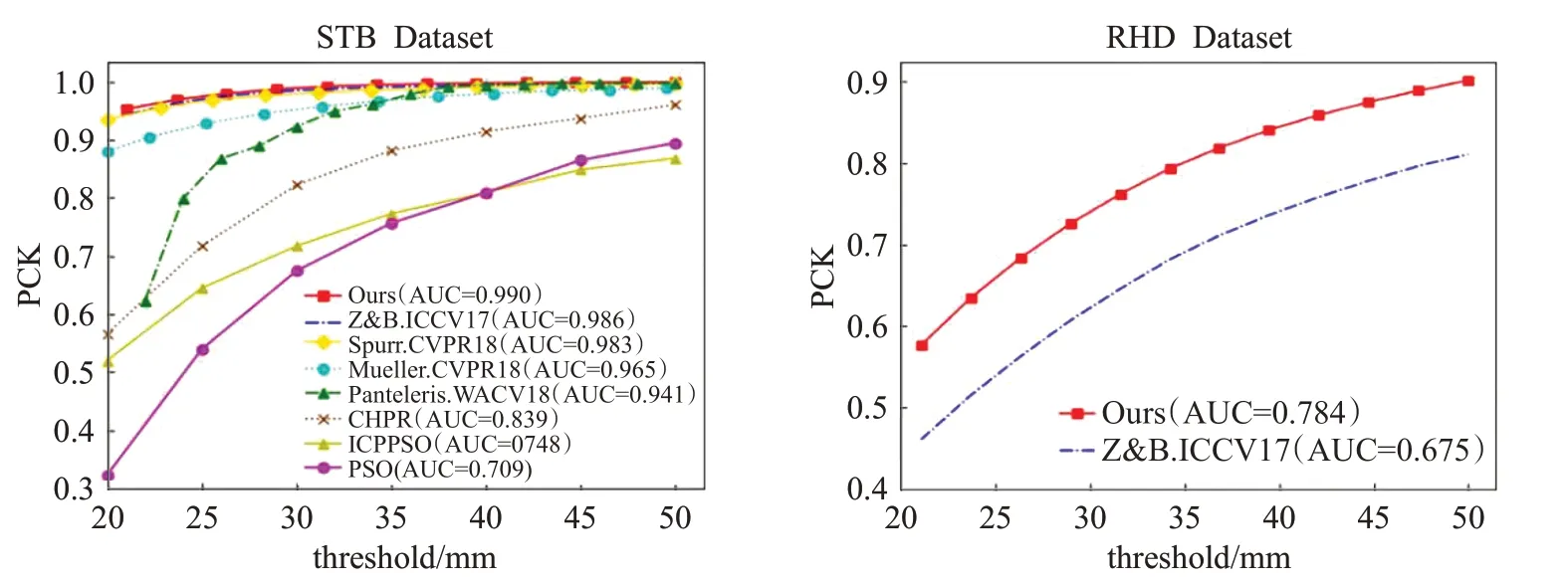
图8 不同方法的3D手姿态估计结果对比
3.4.2 定性结果
同样的,本文将STB、RHD 和D+O 数据集上的3D手姿态估计的结果以可视化的形式进行了展示,结果如图9 所示,该图中一、二、三行分别为STB、RHD 和D+O数据集。与图5中标准坐标显示的不同,为了使估计出的姿态效果更明显,图9将手姿态的x、y、z坐标顺序转换成z、x、y,并调整了视角到合适的位置,但正面视角与y-z平面垂直。
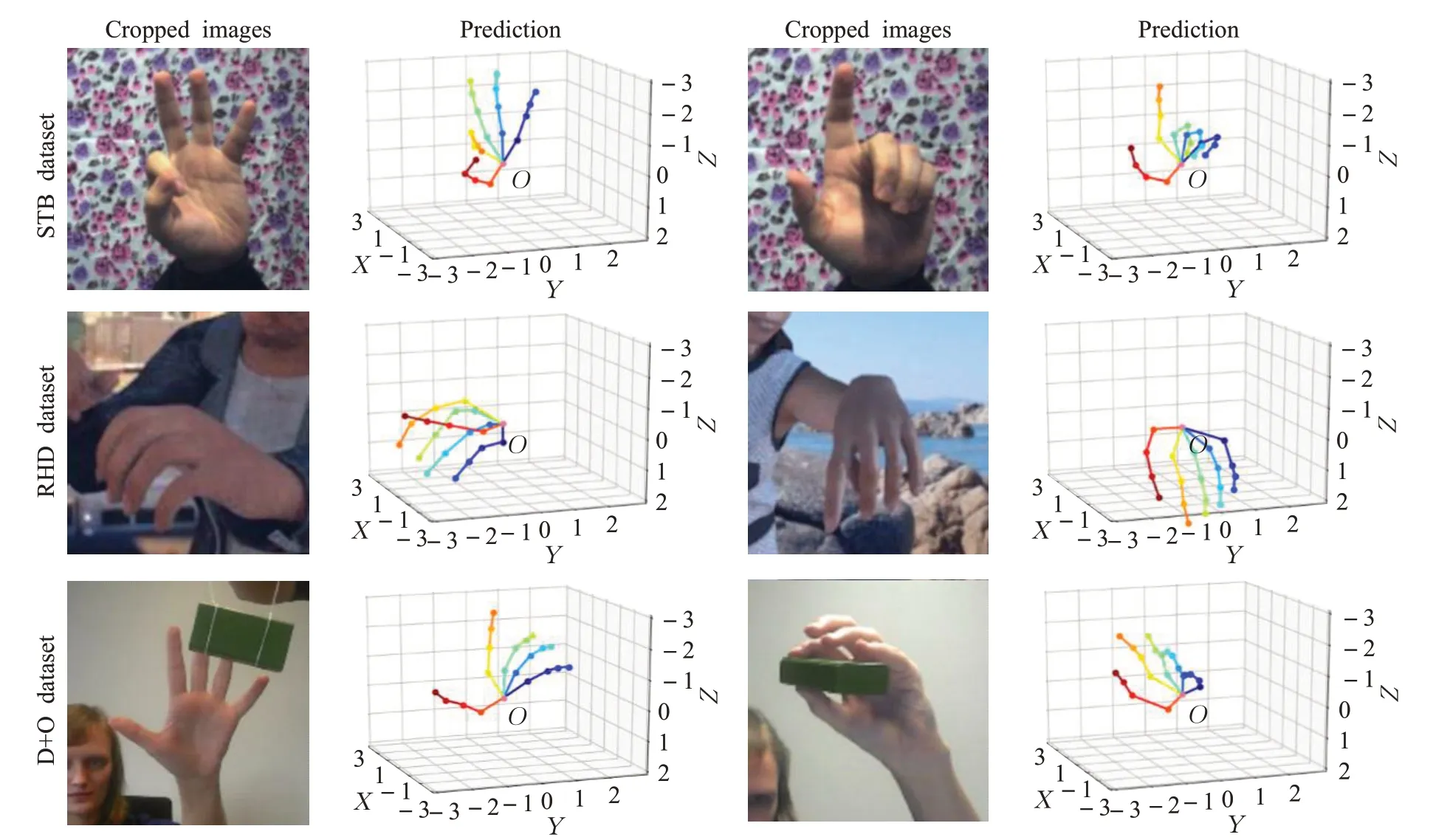
图9 3D手姿态可视化
3.5 消融研究
本文在RHD数据集上研究了融合单元和视角不变方法给网络性能带来的影响。
3.5.1 融合单元
对2D 姿态估计网络中有、无融合单元模块进行实验,结果如表3所示。该表中+表示保留所有融合单元,-表示只保留第四阶段最后一个融合单元,带箭头部分表示相对提升或降低的数值百分比。从该表中可以看出,引入融合单元后网络性能有所改善,最直观的表现是AUC 值提升了2.3%。然而,引入融合单元会增加网络的运算成本,增长比例为5.1%,但在相对其他评估指标改善的前提下,其增加的运算量在可接受的范围内。

表3 有、无融合单元的结果对比
3.5.2 视角不变方法
对视角不变方法与直接估计方法进行3D姿态估计实验对比,结果如表4 所示。直接估计方法(Direct)表示直接估计标准坐标cnorm而不需要用到规范坐标ccan,其网络结构与本文估计规范坐标ccan的结构一样。从表4中可以看出,直接估计方法的精度要低于视角不变方法,表明估计规范坐标和旋转矩阵R要比直接估计标准坐标更有效。可以理解为把一个相对困难的问题(直接估计标准坐标)划分成两个较容易的问题(分别估计规范坐标和旋转矩阵),从而降低了网络学习难度。

表4 视角不变和直接估计的结果对比
3.6 网络实时性
本文在RHD测试集上分别对2D和3D姿态估计网络的运算实时性相关数据进行了统计,各项数据见表5。从该表中可知,在整个估计过程中2D 姿态估计占用了绝大多数的计算量,达到了86亿次浮点运算(文献[8]为258 亿次),这与HRNet 本身的并行结构以及多个融合块的设计有关,而3D 姿态估计网络由两个简单的并行处理流组成,其计算量仅为1亿次。本文方法平均处理一张图像的时间约为0.014 s,处理速度达到了每秒71张,实时性较高。
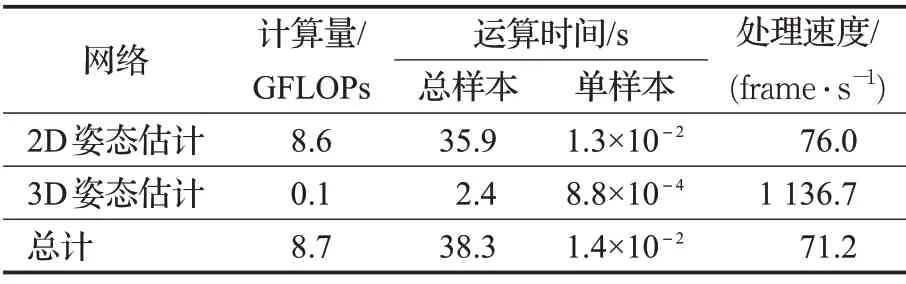
表5 网络实时性相关数据统计
4 总结
针对现有手姿态2D关键点热图估计或手姿态特征提取方法存在的问题,本文引用了一种多尺度高分辨率保持的网络来估计热图,有效地提升了2D 手姿态估计的准确性。之后,使用全局旋转视角不变的方法将2D热图映射到3D 姿态。在上述方法上,使用三个公开数据集数(STB、RHD、Dexter+Object)分别对2D 和3D 姿态估计进行了实验,结果显示了本文方法的有效性。考虑到未来手姿态估计可能会向密集的3D 手形发展,如何将HRNet应用到其中成为接下来的研究方向。
