基于共同语境的近义词/同义词短语查找模型
2021-07-28石晨,张宇,胡博
石 晨,张 宇,胡 博
1.东南大学,南京211189
2.浙江警察学院,杭州310053
近义词短语和同义词短语无监督查找文本挖掘和搜索引擎到语义分析,以及机器翻译等多种应用都很有用。同义词具有不同程度的相似性,从完全的语境替代或绝对同义词到近义词或词语辩析体现了相似性的由高至低[1-2]。文献[3]总结了在意义上接近而不能完全替换,但在其外延、内涵、含义、重点或表达的深意有所变化的词语(近义词)的定义。以上这些定义可以扩展到多词短语,例如“极难”可以扩展为“非常具有挑战性”;同义词是一个比一般的释义任务更窄的子集,因为后者可以包含多种形式的语义关系。
近义词短语的提取在诸如自然语言处理(Natural Language Processing,NLP)、信息检索、文本摘要、机器翻译和其他人工智能应用等领域具有极其重要的意义。尽管查找单个词或常见的封闭词组的近义词可能只需要查找同义词库,但查找近义的多词短语一般需要一个基于对大型语料库的分析生成过程。例如,采用本文方法查找“it is fair to say”的近义词如下:“it’s safe to say”“we all understand”“it’s pretty clear”“we believe”“it’s well known”“it’s commonly accepted”等。尽管这些短语的含义非常接近,但对于构成它们各自许多相应的单词来说,却并不是这样;此外,对于专有名词,采用本文方法还可找到正字法(拼字正确的)变体(最好的同义词)以及描述性近义词。例如,对于“Al Qaeda”,会查找出“Al Qaida”“Al-Qaeda network”“jihadist group”“terrorist organization”“Bin Laden’s followers”;显然,近义词短语有助于文本挖掘,例如在文本语料库或文本流中发现感兴趣的实体,以及在大型和各种各样的自然语料库中发现以不同方式表达的关系。
近年来,近义词的重要性引起了人们的关注。文献[4]提出在许多任务中处理Twitter 摘要。近义词在信息检索中显得至关重要,特别是回忆很重要的事情时,这时搜索查询的近义词可能具有极高的价值。例如,如果一个人想要“廉价住房”,则搜索“负担得起的住房”可能是有用的。如果查找“心脏病发作”,也可以通过扩展查询,搜索“心脏骤停”或“心力衰竭”。尽管搜索引擎可以自动提供扩展搜索,但就人们所能观察和理解而言,只有通过高度相关的单个词替换才能实现;此外,为了模拟短语叙词表,由于预编译的数据库[5]无论大小如何,都不能实现完全覆盖,因此实时(可扩展)系统是必不可少的。
文献[6]基于向量空间模型(Vector Space Model,VSM)相似度算法和《知网》相似度算法,针对TF-IDF算法计算权重时融入特征项位置因素、弥补词频统计过于片面的问题,提出了VSM 与《知网》语义理解相结合的相似度计算模型,即把相同和相似的词语作为空间坐标的同一维度,计算相似度时融入词语语义相似度。这样既弥补了VSM 在语义层面的不足,又弥补了《知网》词语相似度算法忽略词语重要程度的缺陷;为解决一词多义等词汇歧义问题,文献[7]提出了一种基于低维向量组合的语义向量模型。模型引入了知识库与语料库的多语义特征的融合,主要的语义融合对象包括连续的分布式词向量和来自于WordNet 结构中的语义特征信息。首先利用神经网络语言模型,预先从文本语料中学习得到连续的低维词向量,然后从知识库WordNet中抽取多种语义信息和关系信息,再将多语义信息融入到词向量进行知识扩展和强化,生成语义向量,从而实现基于向量空间的语义相似性度量方法。实验结果表明,该方法优于基于单一信息源(知识库WordNet 或文本语料)的语义相似性度量方法;文献[8-9]提出了扩展统计语言模型和神经语言模型,模型根据之前见过的单词,基于2~10-gram 预测下一个单词;文献[10]基于神经网络并采用排名损失训练目标,加入额外的上下文来训练单词嵌入,通过学习每个单词的多重嵌入来考虑同音异义性和一词多义性。
也有在短语级研究语义相似性问题的NLP 文献报道。文献[11-12]提出的组合分布式语义方法试图通过将向量合成函数应用到与其构成词相关的向量上来形式化复合词的含义,但没有讨论短语同义词,更重要的是把短语(复合词)视为由个别构成词构成,而不视为不同的实体,从而忽略了一个基本事实,即整体的语义可能与其构成成分的语义有很大的不同;另一些讨论短语的方法没有将它们分解成构成词,而是采用并行资源构造释义对,包括释义范畴的多种语义关系;文献[13]采用手工编码的语言模式仅对齐特定的文本片段上下文来生成释义,而且需要特定语言资源如语音标记部分和解析器;这种方法只能找到具有相同内容词的替代结构,例如“X 制造Y”意指“X 是Y 的工厂”。而近义词有一组不同的词,如“使收支相抵”和“支付账单”,都无法通过他们的方法检测到;文献[14]提出了一种启发式方法,有助于基于上下文的机器翻译系统。方法采用不同上下文数量及其长度来估计近义词。
本文针对大型语料库中近义词/同义词短语的查找问题,提出了一种基于共同语境的近义词/同义词短语查找新模型。它通过n-gram分布式方法捕获语义相似性,不需要解析就能隐式地保存局部句法结构,使底层方法语言独立;具体实现分为两个阶段:第一阶段是上下文收集和过滤,即用围绕查询短语的本地上下文作为条件模型的特征来捕获语义和语法信息。第二阶段是候选词短语收集和筛选,即对数据中的每个“左”“右”和“配对”的全部实例进行迭代,以收集一组近义词/同义词候选短语;还给出了构成模型的要素和用于评价模型性能的评分函数;共同语境的实例越多,所述上下文就越具体,共享上下文就越长,潜在的近义词/同义词关系就越强,而且本文模型仅依赖于一个大型的单一语料库,不需要预先存在的语言或词汇资源就可以应用于任何语言;实验结果表明,本文提出的建模方法在总的统计评分查找性能和整体可扩展性方面都优于常用的其他查找方法模型。
1 基于共同语境的近义词/同义词短语查找系统模型
为叙述方便,将本文提出的近义词/同义词短语查找系统模型简称为近-同义词系统模型(Near-Synonym System Model,NSSM)。它采用一种不同于其他方法的新方法,不需要并行资源,也不采用预先确定的手工编码模式集;NSSM通过n-gram分布式方法捕获语义相似性,不需要解析就能隐式地保存局部句法结构,使底层方法语言独立;NSSM 还是一个Web 服务器,它的功能类似于一个活的近义词短语生成器;NSSM基于后缀数组[15]和并行计算来实现大型语料库的实时性能。后缀数组采用一种增广形式的二叉树来搜寻语料库中字符串模式的所有出现。在处理诸如“W是A的子字符串吗?”之类的查询时,时间复杂度为O(P+lgN),其中P=|W|,N=|A|。
给定一个长度为N的大文本A=a0a1a2…aN-1,令Ai=aiai+1…aN-1表示A的后缀,即始于位置i。后缀数组则是按字典顺序排序的数组Pos,即Pos[k]是集合{A0,A1,…,AN-1}中第k个按字典顺序的最小后缀的开始,即:

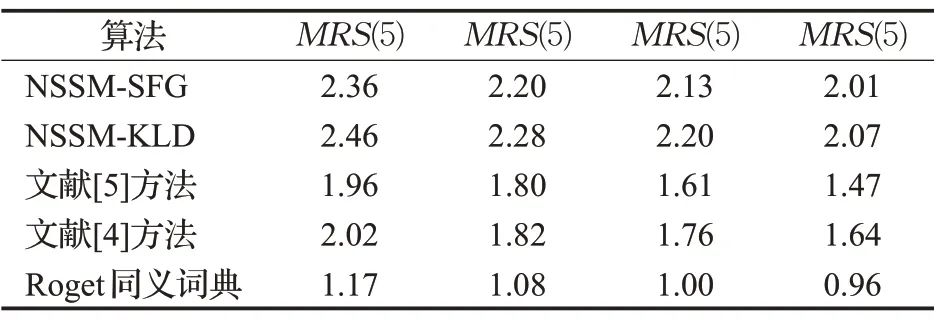
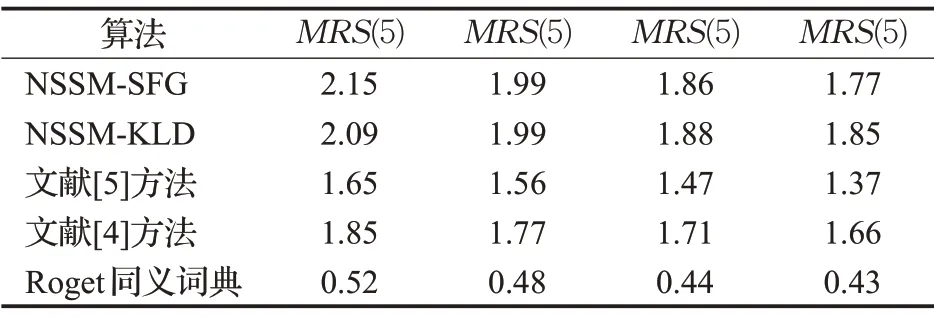
是词典编纂的顺序。由于它是排序的,所以它可以通过搜索Pos中W的左和右边界来定位A中字符串模式W的所有出现,这需要2 个二进制搜索,即2×O(P+lgN)时间。在本文中,A是一个单词标记序列,且P< 采用术语“查询短语”来表示要查找的近义词或同义词的输入短语,NSSM 的整个运行体系结构如图1 所示,图中以“has undergone a majorsea changein the last five”为例。 图1 给定一个输入短语的NSSM运行体系结构 总的来说,NSSM运行包括以下两个阶段。 第一阶段,上下文收集和过滤。NSSM用围绕查询短语的本地上下文(共同语境)作为条件模型的特征来捕获语义和语法信息。本地上下文包括: (1)称之为“左”的左上下文,是一个查询短语的最左端的3~4-gram标记。 (2)称之为“右”的右上下文,与(1)定义类似(较长的n-gram可进一步改善结果)。 (3)称之为“配对”的配对左右上下文,即将同一查询短语的左和右上下文结合在一起。 迭代查询短语在数据中的每一次出现,并在每个实例中收集相应的本地上下文,分别形成3 组不同的左、右上下文和配对左右上下文。为了计算上下文查询短语的相关性(参见模型要素一节),在迭代期间使用多线程后缀数组将查询短语的每个上下文的频率以及查询短语的频率存储在数据中。 第二阶段,候选词短语收集和筛选。对数据中的每个“左”“右”和“配对”的全部实例进行迭代,以收集一组近义词/同义词候选短语,但遵从下列最小和最大候选长度: 式中,QL为查询短语长度,d0和d1是常量参数。为了计算候选上下文强度和归一化因子(见模型要素一节),仍采用多线程后缀数组存储每个上下文的每个候选短语的频率以及它们独立出现的频率,以加快进程。 下面对算法的计算复杂度进行简单分析。 考虑一个后缀数组,给定一个查询短语q,如果N是数据中的单词标记数,f(q)是q的频率,X是q的上下文(左、右和配对)集合,Y是q的挖掘到的近义词/同义词候选集合,fmax(x) 是X中最高频率的上下文,XLmax是最大允许的单边上下文长度(在本文中为4),则当仅采用共享特征增益评分函数(见后面小节)时,对于查询短语q,NSSM的运行时间复杂度的严格上限为: 采用并行后缀数组时,上述表达式中唯一的区别是:N、f(q)和fmax(x)定义为本地数据对应的一个后缀数组,而不是整个数据。 本节提出一个新的条件模型来构造一个概率组合函数,实际上就是根据共享(公共)特征集上的函数来度量两个实体之间的相似性,具体如下。 1.2.1 上下文查询短语相关性 上下文查询短语相关性(Contextual Query Phrase Relevance,CQR)是衡量查询短语对其上下文的重要性的一种度量,是与其一起出现的其他短语相比较: 式中,p(⋅)和q(⋅)分别为分布中的概率点和频率点。 1.2.2 候选上下文强度 候选上下文强度(Candidate Contextual Strength,CCS)是衡量查询短语上下文与近义词/同义词候选短语之间的关联程度的一种度量,是与其周围的其他本地上下文相比较: 1.2.3 归一化 为了解决候选短语之间基级频率的变化问题,引入一个归一化因子: 式中,d是一个常数。 1.2.4 上下文信息 根据上下文的内容(例如类型和/或字数),有些上下文仍然比其他上下文包含更多的语义信息,本文模型设法考虑到这一点。因此,上下文信息(Contextual Information,CInf)为: 式中,w(x)是上下文x中的内容字数,l(x)是x的长度,a、b和c为系数。 为了得到共享特征增益(Shared Feature Gain,SFG)评分函数,结合上述概念,首先计算左上下文(L(q))的分数: 模型还考虑了替换的上下文匹配,这些匹配本质上是“配对”匹配,但在查询的不同实例中采用左匹配和右匹配: 式中,DL(q)是L(q)的一个子集,表示左移。同样,可以计算出右上下文和配对左右上下文的分数,并将这三个分数结合得到最终分数为: 式中,Ccf>1 是用于提高配对左右上下文的得分,使之与SC匹配。 KL 散度(Kullback-Leibler Divergence,KLD)[16]是度量两个概率分布之间的差异,本文用它来度量当给定一个候选对象的上下文分布用于近似给定查询短语的相同上下文分布时所丢失的信息,即: 式中,L(q)表示查询短语和候选词的组合左集合。和前面一样,概率比p(⋅)和r(⋅)可以解释为频率比。应用平滑方法,并计算合并的右上下文和合并的配对左右上下文的分数,然后将三者结合得到最后的分数为: 采用式(15)重新评分和重新排名通过共享特征增益所得到的前1 000个得分候选上下文。 在全部参数大于零的条件下,S(y,q)是两个非负凸函数的乘积,且仍然是凸的。这使得优化目标是两个凸函数的差。本文采用二值搜索的多起始坐标上升,而不增加线性步长。参数在30 个查询短语集上进行训练,与性能评价中采用的短语(见实验部分)分开。 实验选择英文Gigaword(http://www.chineseldc.org)为本文实验提供一个综合新闻专线文本数据档案。把语料库分割成32 个相等的部分,每个分割部分构造一个后缀数组。选择的服务器硬件可以并行支持多达32(16×2)个线程,因此每个后缀数组都在自己单独的线程上运行。使用37.5%的数据(12 个后缀数组)用于实验。完整的Gigaword 可能会得到更好的效果,但会运行得更慢。 实验中挑选了54 个随机选择的查询短语,其中包括15个单词、23个单词短语和16个较长的短语。对于每个查询短语,采用前面本文提出的2 个评分函数(共享特征增益评分函数及Kullback-Leibler散度评分函数)和参与比较的其他模型算法的每一个生成20个近义词的候选词。要求注释者(6名人工评级员)对每个查询短语-同义词候选组合提供评级,评级从0~3,其中3 表示绝对同义词,2表示近义词,1表示某些语义相关性如上义关系、下义关系或反义关系,0表示没有关系。 本文对标准度量指标平均精度(Mean Average Precision,MAP)和归一化折现累积增益(Normalized Discounted Cumulative Gain,NDCG)进行扩展。不直接采用MAP,因为它对等级不敏感,并且只对二进制(0或1,相关或不相关)评级标准有效;在NDCG的情形下,即使它考虑了排序,也不会因为结果差而受到惩罚,此外,NDGG也不因丢失结果而受到惩罚;因此,本文的标准度量指标采用平均等级敏感得分(Mean Rank-sensitive Score,MRS),这样使得较低等级(离最高排名更远)的注释分数降低: 式中,Sr是注释分数,n是第n个等级的截止点(临界点),r是候选等级,A是评级者集合。MRS通过用零填充丢失值的评级序列来考虑丢失结果。 2.3.1 与Roget同义词词典的比较 为了表明一般词典查找同义词短语的不足,将本文模型方法法与Roget同义词词典基准进行比较。与所有其他主要包含单个词的词典一样,将查询短语中单个词的同义词集中的元素组合起来,为54 个查询短语的每一个构造候选词。例如,在“strike a balance”中,随机选择“hammer”和“harmony”分别作为“strike”和“balance”的同义词,构成“hammer a harmony”作为候选词;假设单个词同义词条目的同义词精度为100%,而其余部分雇用3名人工评级员。表1、表2和表3分别比较了单个单词、两个单词和大于两个单词和查询短语的共享特征增益(SFG)、KL 散度(KLD)和Roget 同义词词典的MRS得分(见表1、表2和表3的第1行、第2行和第5行)。可以清楚地看到,基于本文模型方法的SFG 和KLD 的MRS性能在单个单词查询短语长度上与Roget 同义词词典查询非常接近,但在两个单词和大于两个单词的多个单词查询短语长度上比Roget 同义词词典查询的MRS性能有明显提高,即使在截止点n达到20 时,相比于Roget 同义词词典查询的MRS,本文模型方法的SFG和KLD的MRS也分别提高了1.05和1.34,而且随着多个单词查询短语长度的增加,MRS并未降低,而是提高得越多。这进一步表明了本文模型方法对于词典结构有相当大的优势,特别是在两个单词级别上性能最佳;就SFG 和KLD 的MRS性能而言,SFG 对于单个单词级别上查询的性能更强,而KLD 对于两个单词和大于两个单词级别上查询的性能更强。 表1 单个单词的查询短语的评分函数比较 表2 两个单词的查询短语的评分函数比较 表3 大于两个单词的查询短语的评分函数比较 还可以看到,由于MRS对截止点不敏感,所以基于本文模型方法得到的两个评分函数SFG和KLD在更严格的截止点(即更低的n值)得到更大的分数,这意味着本文模型方法能够从相对较弱的匹配中区分更强的语义匹配,并将高度同义的候选词排名更高。 2.3.2 与释义数据库的比较 将本文模型方法与文献[5]提出的机器翻译技术PPDB 进行比较。PPDB 的英文部分包含了超过2 220万个释义。从7 300万个短语和800万个词汇释义对中提取了54 个查询短语的前20 个近义词,利用数据库中提供的注释Gigaword分布相似性分数来对候选词进行排名,此外,由6名人工评判提供评级。表1、表2和表3的第3 行为采用文献[5]提出的机器翻译技术PPDB 得到的MRS(n),与表1、表2和表3的第1行和第2行进行比较,可以清楚地看到,基于本文模型方法的SFG 和KLD 的MRS(n)在每个截止点(n)和短语长度(单个单词的查询短语、两个单词的查询短语和大于两个单词的查询短语)上都有更好的性能。鉴于NSSM是在单语料库上运行,不需要任何NLP特定资源,与PPDB相比,它是一个实时检索系统,而PPDB 并不是这样,这一点对于实时查询来说相当重要。 2.3.3 与开放源可扩展释义获取工具包的比较 与一种基于Hadoop的开放源可扩展释义获取工具包[4]进行了比较。具体而言,文献[4]的释义获取工具包将一个短语的上下文定义为短语的直接左右侧的ngram 连接,并将一个n-gram 上下文的最小长度和最大长度分别设置为2 和3,但他们采用逐点交互信息加权短语向量来计算余弦相似性,以作为两个短语之间相关性的度量,即: 式中,C(p)表示短语p的上下文向量。 用NSSM 在本文的数据集(占预处理后的英语Gigaword 第五版的37.5%)上实现了式(18)的评分函数,如表1、表2 和表3 的第4 行所示,仍然可以看到,基于本文模型算法得到的两个评分函数SFG 和KLD 的MRS(n)无论在每个截止点(n),还是在短语长度(单个单词的查询短语、两个单词的查询短语和大于两个单词的查询短语)上都优于基于Hadoop 的开放源可扩展释义获取工具包。 最后,图2 所示为基于18.7%、37.5%和71.8%的Gigaword语料库采用SFG评分函数,对于单个词的短语、两个词的短语和大于两个词的短语得到的MRS(n)。可见,采用NSSM 的检索质量随着语料库的增大而提高,说明本文的NSSM是有效的。 图2 对于不同词短语采用SFG评分函数得到的MRS(n) 本文提出了一种新的用于从大型单语无注释语料库中查找近义词/同义词短语的无监督建模方法,而且本文模型仅依赖于一个大型的单一语料库,不需要预先存在的语言或词汇资源就可以应用于任何语言,模型方法是基于频率统计、信息论和可扩展算法的结合;实验结果表明,在词汇和短语两个级别的查找上都明显优于自动近义词/同义词短语的查找方法,并且在多词近义词/同义词生成方面优于基于同义词词典的方法,在总的统计评分查找性能和整体可扩展性方面都优于常用的其他查找方法模型;对于未来的研究,主要考虑:(1)在多种语言上测试本文提出的NSSM,因为它不包含特定于英语的假设或知识;(2)将NSSM 完全并行化为一种高效的基于云的近义词/同义词短语服务器;(3)实现基于任务的评价,如Web搜索。1.1 NSSM运行体系结构



1.2 模型要素
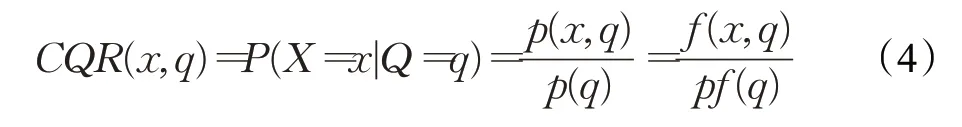
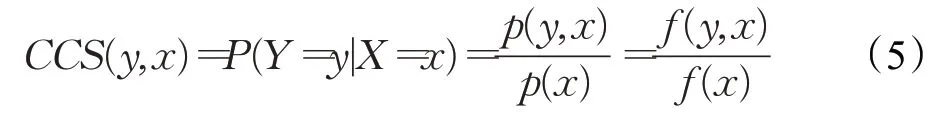

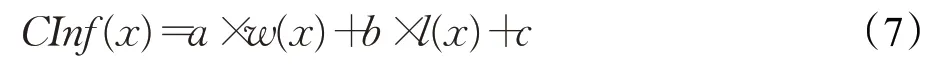
1.3 共享特征增益评分函数
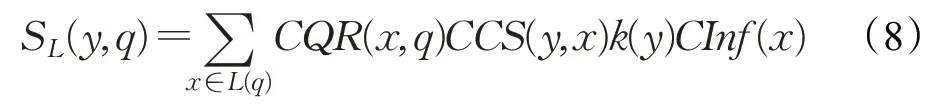
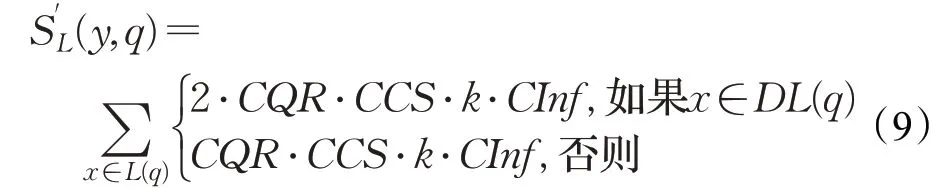
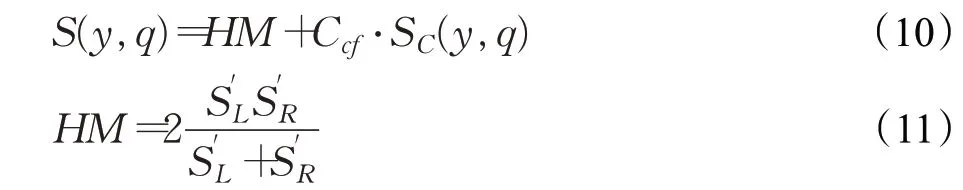
1.4 Kullback-Leibler散度评分函数
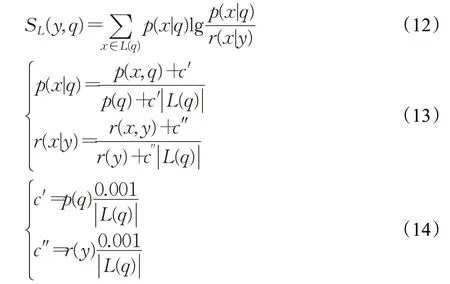
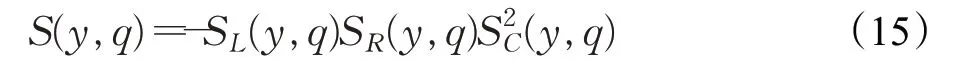
1.5 参数训练
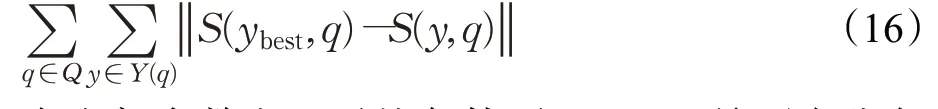
2 实验结果及分析
2.1 Gigaword语料库
2.2 等级敏感评价
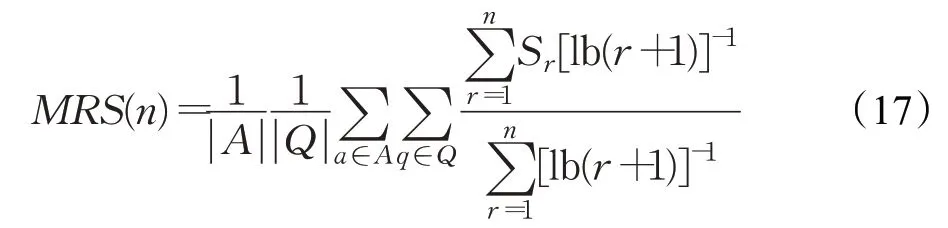
2.3 查找性能比较

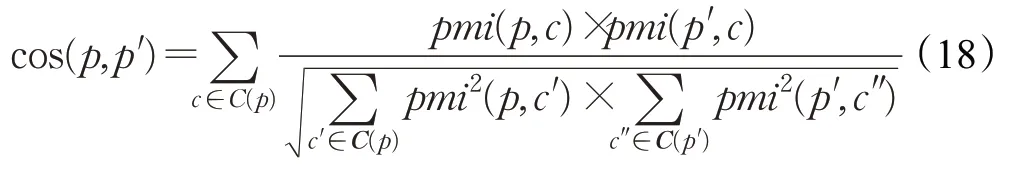

3 结束语
