An RGB-D Camera Based Visual Positioning System for Assistive Navigation by a Robotic Navigation Aid
2021-07-26HeZhangLingqiuJinandCangYe
He Zhang, Lingqiu Jin, and Cang Ye,
Abstract—There are about 253 million people with visual impairment worldwide. Many of them use a white cane and/or a guide dog as the mobility tool for daily travel. Despite decades of efforts, electronic navigation aid that can replace white cane is still research in progress. In this paper, we propose an RGB-D camera based visual positioning system (VPS) for real-time localization of a robotic navigation aid (RNA) in an architectural floor plan for assistive navigation. The core of the system is the combination of a new 6-DOF depth-enhanced visual-inertial odometry (DVIO) method and a particle filter localization (PFL)method. DVIO estimates RNA’s pose by using the data from an RGB-D camera and an inertial measurement unit (IMU). It extracts the floor plane from the camera’s depth data and tightly couples the floor plane, the visual features (with and without depth data), and the IMU’s inertial data in a graph optimization framework to estimate the device’s 6-DOF pose. Due to the use of the floor plane and depth data from the RGB-D camera, DVIO has a better pose estimation accuracy than the conventional VIO method. To reduce the accumulated pose error of DVIO for navigation in a large indoor space, we developed the PFL method to locate RNA in the floor plan. PFL leverages geometric information of the architectural CAD drawing of an indoor space to further reduce the error of the DVIO-estimated pose. Based on VPS, an assistive navigation system is developed for the RNA prototype to assist a visually impaired person in navigating a large indoor space. Experimental results demonstrate that: 1)DVIO method achieves better pose estimation accuracy than the state-of-the-art VIO method and performs real-time pose estimation (18 Hz pose update rate) on a UP Board computer; 2)PFL reduces the DVIO-accrued pose error by 82.5% on average and allows for accurate wayfinding (endpoint position error ≤45 cm) in large indoor spaces.
I. INTRODUCTION
ACCORDING to Lancet Global Health [1], there are about 253 million people with visual impairment, of which 36 million are blind. Since age-related diseases (glaucoma,macular degeneration, diabetes, etc.) are the leading cause of vision loss and the world population is rapidly aging, more and more people become blind or visually impaired (BVI).Therefore, there is a crucial need for developing navigation aids to help the BVI with their daily mobility and independent lives. The problem of independent mobility of a BVI individual includes wayfinding and obstacle avoidance.Wayfinding is a global problem of planning and following a path towards the destination while obstacle avoidance is a local problem of taking steps without colliding, tripping, or falling.
To provide wayfinding and obstacle avoidance functions to a BVI traveler at the same time, the location of the traveler and the 3D map of the surroundings must be accurately acquired. The technique to address the problem is called simultaneous localization and mapping (SLAM). In the literature, several robotic navigation aids (RNAs) [2]–[8] that use SLAM [9] for assistive navigation of the blind have been introduced. The performance of these RNAs relies on the pose estimation accuracy since the pose information is used to build a 3D map of the environment, locate the blind traveler in the environment, and guide the traveler to the destination.Stereo camera [2], [3] and RGB-D camera [4], [7] based visual SLAM methods have been developed to estimate the pose of RNA and detect surrounding obstacles from the generated 3D point cloud map. To improve the pose estimation accuracy, geometric features [5], [6], and inertial data [7], [8] have been utilized in existing SLAM methods.However, the pose error can still accrue over time and may become large enough (in case of a long trajectory) to break down RNA’s navigation function. To tackle this problem,visual maps [10], [11], Bluetooth low energy beacons [12],radio-frequency identifications [13], and near field communication tags [14] have been employed to correct accumulative pose estimation error. However, building a visual map ahead of time can be time-consuming as it requires extraction and storage of visual features point-by-point in a certain spatial interval to cover the entire navigational space, while the approach of using beacons or the alike requires re-engineering the environment and is thus not practical for assistive navigation.
To address these disadvantages, we propose, in this paper, a vision position system (VPS) that uses an RGB-D (i.e., colordepth) camera and an inertial measurement unit (IMU) to estimate the pose of an RNA for wayfinding applications. The system uses the floor plan (i.e., architectural CAD drawing) of an indoor space to reduce the accumulative pose estimation errors by a 2-step scheme. First, a new visual-inertial odometry (VIO) method is used to estimate 6-DOF RNA poses along the path. Second, a 3D point cloud map (local map) is built (by using the estimated poses) and projected onto the floor plane to create a 2D map, which is then aligned with the floor plan by a particle filter localization (PFL) method(i.e., the 2D geometric features such as walls, doors, corners,and junctions of the two maps are aligned) to reduce RNA position and heading errors on the floor plan for wayfinding.
The RNA prototype uses a sensor suite consisting of an RGB-D camera and an IMU for localization, making the device an RGB-D-camera-based visual-inertial system (RGBD VINS). A VINS employs a SLAM technique, known as VIO, to estimate the system’s motion variables by jointly using its visual-inertial data. In [15], three state-of-the-art VIO methods, namely, OKVIS [16], VINS-Mono [17], and VIORB[18], are compared in the context of RNA pose estimation.The results show that VINS-Mono outperforms the other two.However, to enable real-time computation of VINS-Mono on the UP Board computer used by the RNA, some modifications, such as using a constant inverse depth for each visual feature in the iterative optimization process, and reducing the size of the sliding window, must be made to the algorithm/implementation. These modifications, however,trade the method’s pose estimation accuracy for computational efficiency. To address the problem, we propose a socalled depth-enhanced visual-inertial odometry (DVIO) to estimate the RNA’s pose for assistive navigation. DVIO is developed based on the framework of VINS-Mono and it improves VINS-Mono’s pose estimation accuracy by 1) using the geometric feature (the floor plane extracted from the camera’s depth data) to create additional constraints between the graph nodes to reduce the accumulative pose error; 2)using the depth data from the RGB-D camera for visual feature initialization and update to avoid iterative computation of the visual features’ inverse depth in each step of the optimization process. Unlike VINS-Mono, DVIO does not need to estimate the metric scale, which is known from the depth data. As a result, it is free of pose estimation error induced by inaccurate scale estimation. Based on the DVIOestimated egomotion, a PFL method is employed to determine the RNA’s pose (3-DOF pose including position and heading)on the floor plan of the navigational space for wayfinding.The main contributions of this paper include:
1) We propose a new VIO method, called DVIO, to estimate the 6-DOF pose of RNA. The method achieves better accuracy in pose estimation by using the depth data from an RGB-D camera.
2) We introduce a VPS to estimate the RNA’s 3-DOF pose on the floor plan for wayfinding. VPS employs PFL to estimate the pose based on the DVIO-estimated egomotion.PFL helps to improve pose estimation accuracy.
3) We develop an assistive navigation system based on VPS and validate its efficacy by experiments with the RNA prototype in the real world.
II. RELATED WORk
A. Related Work in VIO
Existing VIO methods can be classified into two categories,namely loosely-coupled [19]–[21] and tightly-coupled [22],[16]–[18]. In this section, we provide an overview of the tightly-coupled methods as the proposed DVIO falls into the same category. MSCKF [22] is an extended Kalman filter(EKF) based visual-inertial SLAM method. It utilizes IMU measurements to predict the filter state and employs visual feature measurements to update the state vector. Unlike a traditional EKF, it simultaneously updates multiple camera poses (in the state vector) by using a novel measurement model for the visual features. This model estimates a visual feature’s 3D location by using its multi-view geometric constraint, computes the feature’s reprojection residuals on multiple images, and use them as innovation to update the state vector. The method adopts adelayedstate update strategy, i.e., a tracked visual feature is used to update the state vector only when it is no longer detected, to get the most from the multi-view constraint. In so doing, it uses much fewer visual features for state estimation as those features that are currently tracked are not used.
On the contrary, the smoothing-based VIO methods[16]–[18] use all visual measurements of the related keyframes to estimate the current motion state and may achieve a more accurate result. OKVIS [16] is a smoothingbased VIO method that performs a nonlinear optimization by using a cost function consisting of the sensor measurements at several keyframes. Specifically, the cost function is formulated as the weighted sum of the residuals of the visual features’ reprojections and the inertial measurements. This formulation incorporates all visual features’ measurements and leads to better pose estimation accuracy than that of MSCKF [16]. OKVIS performs well on a stereo VINS.However, its performance may significantly degrade in the case of a monocular VINS. This is because it lacks a reliable approach to accurately estimating the initial values of the state variables (e.g., gyroscope bias, metric scale). Due to the nonconvexity of the cost function, a poor estimate of the initial state will likely cause the optimization process to be stuck at a local minimum and result in an incorrect pose estimation. To mitigate this issue, VIORB [18] implements a sophisticated sensor fusion procedure to bootstrap a monocular VINS with a more accurate estimate for the initial state, consisting of the pose, velocity, 3D feature locations, gravity vector, metric scale, gyroscope bias, and accelerometer bias. However,VIORB requires 15 seconds of visual-inertial data to obtain an accurate result. It is not suitable for our case that requires a scale estimation right at the beginning. ORB-SLAM3 [23]improves the initialization approach by using an inertial-only maximum-a-posterior (MAP) estimation step [24] to compute the values for the scale, velocities, gravity, and IMU biases.This step takes into account the IMU’s measurement uncertainty and the gravity magnitude in producing an estimate that is accurate enough for a joint visual-inertial bundle adjustment (BA). The output of the inertial-only MAP is used to initialize the values of the VINS’ state parameters to speed up the convergence of the visual-inertial BA. The approach allows the VINS to initialize itself in less than 4 seconds.
Qin and Shen [25] discover that the metric scale error is linearly dependent upon the accelerometer bias and simultaneously estimating the scale and the accelerometer bias requires a long duration of sensor data collection. To overcome the problem, they propose the VINS-Mono [17]method, where the initialization process is simplified by ignoring the accelerometer bias. The method uses a two-step approach to initializing the VINS’ motion state. First, it builds a scale-dependent 3D structure by a visual-only structurefrom-motion method. Second, it aligns the IMU integration with the visual-only structure to recover the scale, gravity,velocity, and gyroscope bias. This initialization approach converges much faster (in ~100 ms) with negligible accuracy loss [25]. However, VINS-Mono [17] still falls short of realtime computing performance on a computer with limited computing power [26]. Using a smaller sliding window may speed up the computation. But it may result in unwanted loss of accuracy.
Research efforts for the above state-of-the-art VIO methods have been mainly focused on monocular VINS [17], [18],[22], or stereo VINS [16], [27]. RGB-D-camera-based VIO is a less-explored area. In [28], an EKF based VIO method is introduced for pose estimation of an RGB-D VINS. The method uses the egomotion estimated by IMU preintegration to generate state prediction and treats the pose estimated by using the visual-depth data as the observation to compute the state update. Linget al.present a smoothing-based VIO method [29] for RGB-D VINS. The method determines the metric scale from the depth data and obtains the VINS’ initial motion state by simply aligning the visual-based pose with the IMU-preintegration-based pose. While it uses the standard VIO framework to estimate the VINS’ motion state, the visual features’ inverse depths are initialized by using the camera’s depth data and are kept as constant values in the optimization process. Shanet al.[30] proposed VINS-RGBD, a smoothingbased VIO method that exploits the depth information in the framework of VINS-Mono [17]. In the initialization process, it uses corner points [31] and employs a 3D-2D-PnP [32]method to build the visual structure. After the initialization, it estimates the VINS’ motion state and the inverse depths of the tracked visual features through a nonlinear optimization process. If a feature’s depth is provided by the RGB-D camera, the inverse depth value is treated as a constant.Otherwise, the depth value is estimated by triangulation, and the inverse depth value is iteratively updated in the later optimization process. The triangulated depths for far-range visual features are not accurate, and the depth estimation error can reduce the pose estimation accuracy during optimization.Instead, we avoid depth estimation for the far-range visual features, and we utilize the epipolar constraint to model their measurement residuals in the optimization step for pose estimation. Also, we exploit the geometric feature (the floor plane extracted from depth data) to reduce the accumulated pose estimation error. The proposed DVIO method improves the above smoothing-based VIO methods by incorporating visual features without depth and geometric feature into the graph for more accurate pose estimation. It achieves real-time computation (~18 Hz) with decent accuracy on a UP Board computer.
B. Related Work in Localization
As an incremental state estimation method, VIO accrues pose errors over time. When using VIO for navigation in a large space, a loop closure can be used to eliminate the accumulated pose error. However, if a loop closure cannot be detected or it is not detected in a timely fashion, the accrued pose error may become big enough to make the navigation system malfunction. To address the problem, the floor plans of the operating environments have been used to reduce accumulative pose errors in the robotics community. Boniardiet al.[33], [34] introduce a pose-graph method to track the 3-DOF pose of a robot in a floor plan (CAD drawing) by using a 2D LiDAR. A scan-to-map matching is first performed to align the LiDAR scans with the floor plan and determine the robot’s pose with respect to the floor plan. Then, this relative pose measurement is used to create additional edges (between the related nodes), which serve as prior constraints in the graph structure to incorporate the floor plan into the graph.The use of the floor plan in the graph SLAM process helps to reduce the accrued pose error. The method has a 50-ms runtime on an Intel Core i7 CPU (8-core, 4.0 GHz). It is difficult to achieve real-time computation on an Up Board computer (with a 4-core 1.92 GHz Intel ATOM CPU). In [35],Watanabeet al.present a method to localize a robot in indoor space by using an architectural floor plan and depth data of an RGB-D camera. The method first extracts a number of planes from the depth image at the robot’s current pose and projects the 3D points belonging to the planes onto the floor to produce a 2D source point cloud. It then uses a ray-tracing algorithm to generate a simulated 2D target point cloud from the floor plan. Finally, the robot pose (with respect to the floor plan) is determined by aligning the source point cloud with the target point cloud using the GICP algorithm [36]. However,the method can malfunction when the GICP algorithm is stuck to a local minimum or the scene is not geometrically featurerich.
(6)在保持油井正常生产的情况下,继续摸索稠油井出砂、排砂规律,制定和优化工作制度,为今后的工作方向打下基础。
The multimodel PFL [37] based method is more robust for pose tracking. Winterhalteret al.employ a 6-DOF PFL approach [38] to track the camera pose for a Google Tango tablet in an indoor environment by using the data from the device’s RGB-D camera and IMU. The method utilizes the VIO-estimated motion to predict the pose for each particle. It computes an importance weight for each particle, which is proportional to the observation likelihood of the measurement given the particle’s state. The likelihood value is estimated by comparing the actual depth data with the expected depth data(from the floor plan) given the predicted pose. A particle survives with a probability proportional to its importance weight in the re-sampling step. To reliably track the device’s 6-DOF pose, 5000 particles are used. This results in a high computational cost. To achieve real-time computation, the PFL algorithm must run on a backend server. In this work, we simplify the method and employ a 3-DOF PFL method to estimate the RNA’s position and orientation on a 2D floor plan for real-time assistive navigation. Our method uses only 100 particles for pose tracking, resulting in real-time computation (~50-ms runtime) on an Up Board computer. The proposed method creates a local submap by registering several frames of depth data (instead of using just one frame of depth data [38]) and aligns this map with the floor plan to determine the device pose with respect to the floor plan. The multi-frame local submap is less likely to be geometrically featureless,making our method more robust to depth data noise.
III. RNA PROTOTYPE AND NOTATIONS
As depicted in Fig. 1, the RNA prototype uses an Intel Realsense D435 (RGB-D) Camera and an IMU (VN100 of VectorNav Technologies, LLC) for motion estimation. The D435 consists of a color camera that produces a color image of the scene and an IR stereo camera that generates the corresponding depth data. Their resolutions are set to 424×240 to produce a 20 fps data stream to the UP Board computer[39]. The D435 is mounted on the cane with a 25° tilt-up angle to keep the cane’s body out of the camera’s field of view. The VN100 is set to output the inertial data at 100 Hz.The prototype uses a mechanism called active rolling tip(ART) [40] to steer the cane to the desired direction of travel to guide the user. The ART consists of a rolling tip, a gear motor (with a built-in encoder), a motor drive, and a clutch. A custom control board is used to engage and disengage the clutch. When the clutch is engaged, RNA enters the robotcane mode and the motor drives the rolling tip and steers the cane into the desired direction. The slippage at the rolling tip is detected by comparing the encoder and gyro data. If the slippage is above a threshold, RNA switches itself into the white-cane mode temporarily until the slippage drops below the threshold. The details on this human-intent detection scheme for automatic mode switching are referred to [5].When the ART is disengaged, the rolling tip is disconnected from the gear motor, turning RNA into the white-cane mode,and the user can swing the RNA just like using a white cane.In this case, a coin vibrator (on the grip) vibrates to indicate the desired direction. The user can switch between the two modes by pressing a push button on the grip. The clutch controller and the motor drive are controlled by the Up Board via its general IO port and RS-232 port, respectively.


Fig. 1. Top: RNA prototype. The body, camera, and world coordinate systems are denoted by {B} (or XbYbZb), {C} (or XcYcZc), {W} (or XwYwZw),respectively. The initial {B} is taken as the world coordinate system {W} after performing a rotation to make the Z-axis level and align the Y-axis with the gravity vector ← g-. In this paper, the superscripts b and c describe a variable in{B} and {C}, respectively. Bottom: Solidworks drawing of the ART.

IV. DEPTH-ENHANCED VISUAL-INERTIAL ODOMETRY
The motion state of RNA is estimated by the proposed DVIO method which consists of three parts: feature tracker,floor detector, and state estimator. The feature tracker extracts visual features from a color image and tracks them to the next image. It also selects keyframes based on the average parallax difference. If the average parallax of the tracked features between the current frame and the latest keyframe is larger than a threshold (10 pixels), this frame is treated as a keyframe. The tracked features in the keyframes are passed to the optimization process to estimate the VINS’ motion state.The features extracted from the non-keyframes are only used for tracking. The floor detector extracts the floor plane from the D435’s depth data. The state estimator estimates the state of the IMU by using the visual features, the floor plane, the depth data, and the IMU measurements. The details of each part are described below.
A. Feature Tracker
The feature tracker detects Harris corner features [41] at each image frame. To obtain a higher processing speed without compromising pose estimation accuracy, the image is evenly divided into 8 × 8 patches, within which at most 4 features are extracted and tracked. These features (at most 256) are tracked across image frames by the KLT tracker [42].A RANSAC process based on the fundamental matrix is devised to remove outliers that do not satisfy epipolar constraint. Inliers are passed to the state estimator for pose estimation.
B. Floor Detector


Fig. 2. Graph structure for DVIO.
C. State Estimator



Fig. 3. Characterization of the D435 camera: the linear motion table moves the camera from 400 mm to 2400 mm with a step-size of 100 mm. At each position, 300 frames of depth data were captured and used to compute the mean and RMS of the measurement errors. The method in [41] was employed to estimate the ground truth depth, which is then refined by using the known camera movement (100 mm) to obtain the ground truth depth. Given a camera pose, the wall plane is projected to the camera frame as the ground truth plane.



V. VISUAL POSITIONING SYSTEM FOR ASSISTIVE NAVIGATION
The DVIO-estimated pose is used to 1) generate a 3D point cloud map for obstacle avoidance, and 2) obtain a refined 2D pose by PFL on a floor plan map for wayfinding. DVIO and PFL form a visual positioning system, based on which an assistive navigation system is created as shown in Fig. 4. The system was developed based on the robot operating system(ROS) framework. Each ROS node is an independent functional module and it communicates with the others through a messaging mechanism. The Data Acquisition node acquires and publishes the camera’s and the IMU’s data,which are subscribed by the DVIO node for pose estimation.The Terrain Mapping node registers the depth data captured with different camera poses to form a 3D point cloud map,which is then reprojected onto the floor plane to create a 2D local grid map for obstacle avoidance and localization of RNA in the 2D floor plan. Based on the RNA’s location in the floor plan, the path planning module [45] determines the desired heading to direct RNA towards the next point of interest(POI). This information is passed to the Obstacle Avoidance module [46] to compute the desired direction of travel (DDT)that will move RNA towards the POI without colliding with the surrounding obstacle(s). Based on the DDT, the ART Controller steers RNA into the DDT, and the speech interface sends audio navigation messages to the blind traveler via the Bluetooth headset. Both the tactile and audio information will guide the blind traveler to move along the planned path. The details of the major modules such as PFL, path planning,obstacle avoidance, and ART control are described below.
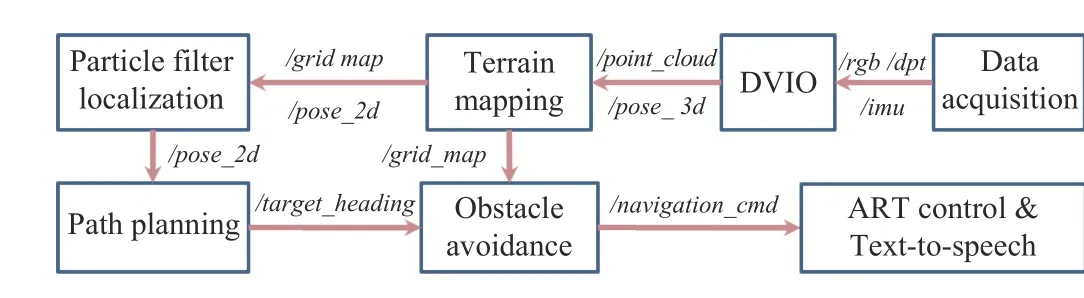
Fig. 4. Software pipeline for the assistive navigation software.
A. Particle Filter Based Localization


B. Path Planning
We use our earlier POI graph method [45] for path planning. The graph’s nodes are the POIs (hallway junctions,elevators, etc.) and each edge between two nodes has a weight equal to the distance between them. The A* algorithm is used to find the shortest path from the starting point to the destination. At each POI along the path, a navigational message is generated based on the next POI. This message is conveyed to the user by the speech interface. In addition, at each junction POI where a turn is required, the needed heading angle change is computed as the difference between the current heading angle and the angle required to move towards the next POI.
C. Obstacle Avoidance
In this work, we employ the traversability field histogram(TFH) [46] method to determine an obstacle-free direction for RNA. First, a local terrain map surrounding RNA is converted into a traversability map (TM). Then, a polar traversability index (PTI) is computed for each 5° sector of the TM. The smaller the PTI, the more traversable the direction. The PTIs are structured in the form of a histogram. Consecutive sectors with a low PTI form a histogram valley, indicating a walkable direction to RNA. The valley closest to the RNA’s target direction is selected and the DDT for RNA is thus determined.The steering angle for RNA is calculated based on the DDT and the current RNA heading. The steering angle is then used to control the ART. In addition, a navigational message is generated based on the next POI. This message is conveyed to the user via the speech interface.
D. ART Control

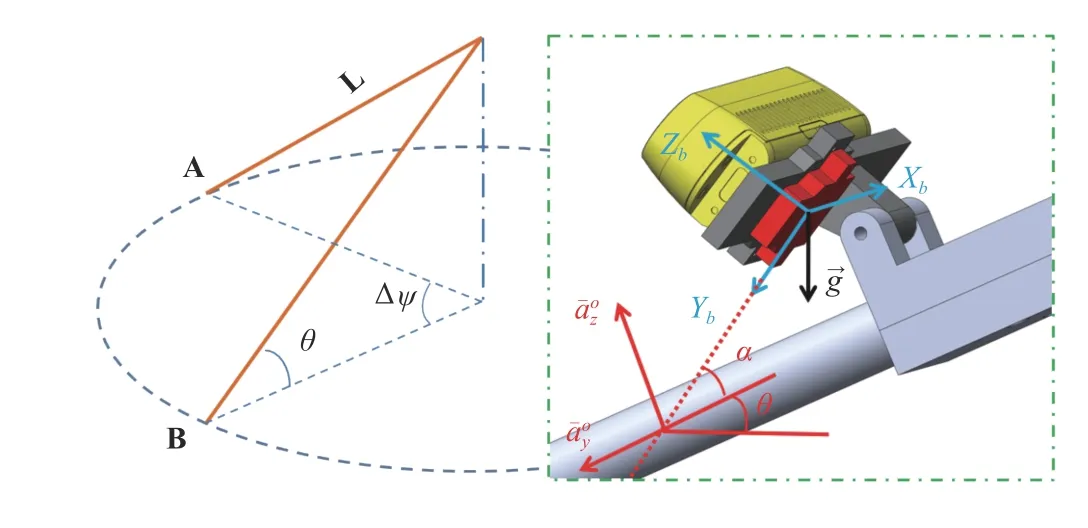
Fig. 5. Left: RNA swings from A to B; Right: Computation of θ from the accelerometer data.
body and it is known a priori.
VI. EXPERIMENTS
A. DVIO Accuracy: D435 + VN100
The performance of DVIO was compared with that of VINS-Mono [17] and VINS-RGBD [30] by experiments.Eight datasets were collected by holding RNA and walking at a speed of ~0.7 m/s. During each data collection session, the user swung RNA just like using a white cane. The ground truth positions of the start point and endpoint are [0, 0, 0] and[0, 0, 20 m], respectively. We use the endpoint position error norm (EPEN) as the metric for pose estimation accuracy.DVIO’s pose estimation accuracy and computational cost can be tuned by adjusting the size of the sliding window. For the sake of real-time computation, we used a small window consisting of 4 pose-nodes for DVIO. For the fairness of comparison, VINS-Mono and VINS-RGBD also used a 4-node sliding window and their loop closure functions were disabled. To demonstrate that the use of the floor plane and the visual features with unknown depth improves pose estimation accuracy, we ran DVIO with three different conditions, denoted DVIO-DFV, DVIO-DF, and DVIO-D,representing the full DVIO implementation, DVIO that does not use visual features without depth, and DVIO that does not use visual features without depth and the floor plane,respectively. Their pose estimation accuracies are compared with that of VINS-Mono and VINS-RGBD in Table I. It can be seen that: 1) using the floor plane reduced the EPEN of DVIO-D by 21.5%; 2) using visual features without depth reduced the EPEN of DVIO-DF by 12.3%. Therefore, the full DVIO has the best accuracy. On average, it reduced the EPEN by 40.2% and 26.4% when compared with VINS-Mono and VINS-RGBD, respectively.
B. DVIO Accuracy: Structure Core
We collected eight more datasets from the most updated RGB-D camera with an integrated IMU-Occipital Structure Core (SC)-that can provide synchronized image, depth (0.7–7 meters), and inertial data and compared DVIO’s pose estimation performance with that of VINS-Mono and VINSRGBD by using these datasets. We characterized the SC by using the method in [43] and found that the depth measurement is of high accuracy (error < 2 cm) if the depth is no greater than 4.0 m (Fig. 6(b)).
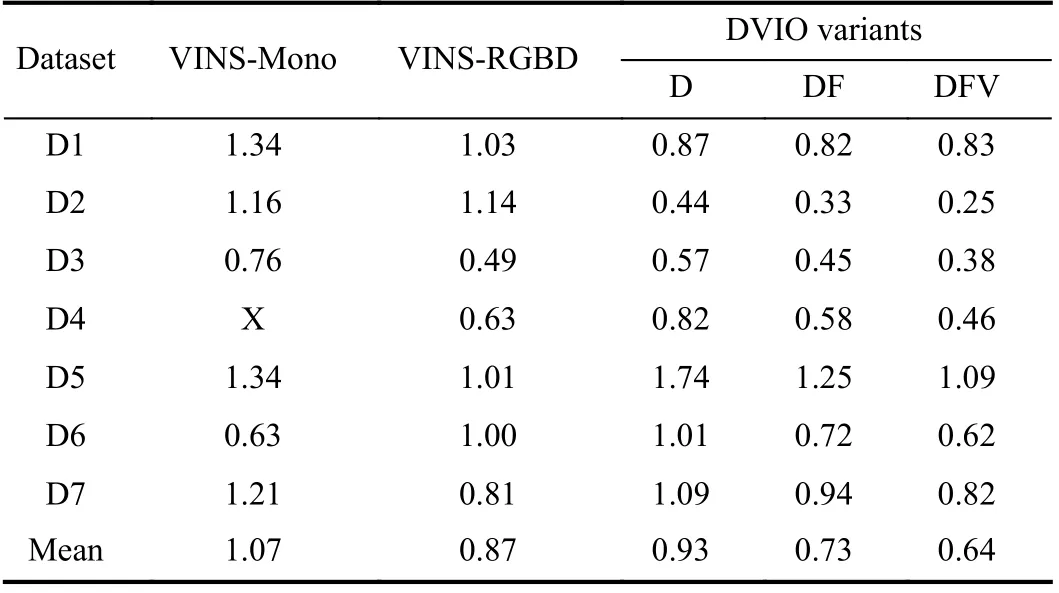
TABLE I COMPARISON OF EPENS (METERS) OF VINS-MONO,VINS-RGBD, AND DVIO

Fig. 6. (a) SC sensor on a white cane for data collection. The coordinate systems of the body (IMU), color camera, and the LED-target are denoted by XbYbZb, XcYcZc, and XTYTZT, respectively. The LED-target will be tracked by the MoCap system to produce the ground truth poses. (b) Measurement error vs distance of the SC sensor.
We installed the SC on a white cane in a way similar to D435 (see Fig. 6(a)) and collected eight datasets by swinging the cane and walking (~0.7 m/s) in our laboratory. Based on the ground truth poses provided by the OptiTrack motion capture (MoCap) system, we calculated the absolute pose error for each point on the trajectories generated by DVIO,VINS-Mono, and VINS-RGBD. Table II summarizes the results. It can be observed that DVIO has the smallest RMSE in seven of the eight experiments. Its RMSE is only slightly larger than that of VINS-RGBD in one experiment. This demonstrates that DVIO has a much more accurate pose estimation than the other methods. On average, it reduced the RMSE by 57.1% and 23.7% when compared with VINSMono and VINS-RGBD, respectively. The trajectories generated by the three methods for four of the experiments are compared in Fig. 7, which show that the trajectories generated by DVIO are more accurate than that of VINS-Mono/VINSRGBD.
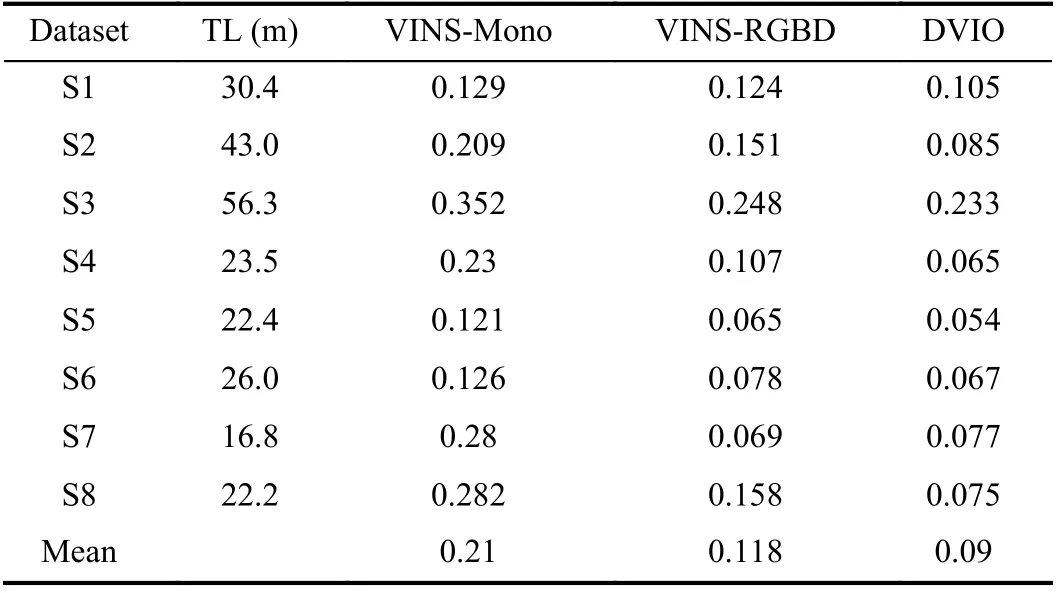
TABLE II RESULTS ON THE LAb DATASETS: RMSE OF THE ESTIMATED TRAjECTORY OF EACH VIO METHOD. TL - TRAjECTORY LENGTH
C. Runtimes of DVIO and Other Modules
Table III shows the runtimes of the major modules of the assistive navigation software system depicted in Fig. 4. The average runtimes of DVIO, terrain mapping, PFL, and obstacle avoidance are 55.6 ms, 19.9 ms, 17.5 ms, and 0.5 ms,respectively. Since each module runs as an independent thread on a different core of the CPU, the software system achieves real-time computation on the UP Board computer(~18 fps).

TABLE III RUNTIME F OR MODULES OF RNA
D. PFL Performance Evaluation
To evaluate RNA’s localization performance, we carried out experiments by holding RNA and walking along several different paths on the second floor of the Engineering East Hall of Virginia Commonwealth University. We created the floor plan map (as shown in Fig. 8(a)) from the architectural floor plan drawing after performing necessary editing to the doors (to show the geometric shapes of the closed doors along the paths). The distinctive geometric shapes of the areas around the doors, junctions, and corners will be used by PFL for RNA localization in the floor plan. For each experiment,the target and actual endpoints of RNA were recorded and their difference is calculated as the EPEN for performance evaluation. Table IV summarizes the EPENs of the experiments. The trajectories estimated by PFL (i.e., DVIO +PF) and that by DVIO only are compared in Fig. 9 to demonstrate the improved localization accuracy. It can be seen that PFL has a smaller EPEN for each experiment. Its mean EPEN over all experiments is 0.58%, i.e., 82.5% smaller than that of DVIO, meaning that the particle filter reduces the DVIO-accrued pose error by 82.5% on average. It is noted that the use of EPEN in the percentage of path-length allows us to compute the mean value over experiments with different paths for overall performance comparison. In principle, PFL eliminates DVIO-accrued pose error whenever RNA “sees” a geometrically featured region. When RNA moves in a corridor (between two featured regions), PFL can eliminate the lateral but not the longitudinal position error. As a result,PFL’s pose error is the PF alignment error plus the uncorrected DVIO pose error since the last alignment(occurred at the last geometrically featured region). This means that the path-length does not affect the EPEN of the PFL method. One can see from Table IV that the EPEN of data sequence DS6/DS7 is much smaller than that of DS4 even if its path-length is much longer. This is because the endpoint of DS6 locates at junction 1 and the last concave wall of DS7 that RNA “saw” is very close to the endpoint while the elevator (endpoint for DS4) is much farther from junction 3 (the last-seen feature).
From the trajectory plots (Fig. 9), it can be seen that the trajectories estimated by DVIO (blue lines) intersect with the walls or doors as the result of the accrued pose error. But the PFL method eliminated the pose errors from time to time and resulted in much more accurate trajectories (red lines).
E. Wayfinding Experiments
We tested the practicality of the visual positioning system by performing two navigation tasks in the Engineering East Hall. Task I is from RM 2264 to RM 2252 (path-length: ~35 meters) and task II is from RM 2264 to the elevator (pathlength: ~80 meters). Two sighted persons (blind-folded)performed these tasks. Each person conducted two experiments for each task and he/she stopped at the point when RNA indicated that the destination had been reached.The EPENs (in meters) for the experiments are tabulated in Table V. As the path-length does not affect a PFL-estimated trajectory, we use the absolute EPEN as the performance metric. The average EPEN for tasks I and II are 0.20 m and 0.45 m, respectively. Due to the small error, RNA successfully guided the users to get to the destinations in all experiments. In Table V, we also show the mean EPENs over persons and that over experiments for each task. Their values are close to the overall averaged value (0.20 m or 0.45 m),indicating a consistent localization performance.
In these wayfinding experiments, we placed numerous obstacles along the paths to test the assistive navigation system’s obstacle avoidance function. The results show that the obstacle avoidance module functioned well and the ART successfully steered RNA into an obstacle-free direction toward the destination. As this is beyond the focus of this paper, we omit the details for simplicity. Successful obstacle avoidance reflects accurate pose estimation of PFL from a different aspect.
VII. CONCLUSION AND FUTURE WORk
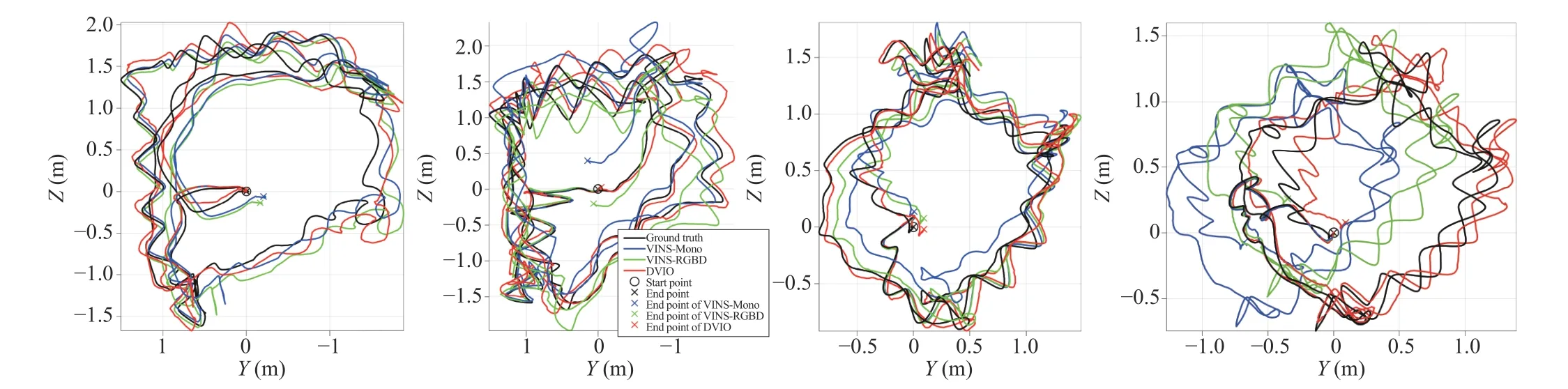
Fig. 7. From left to right: trajectory comparison for datasets S1, S2, S5, and S8. The trajectories of the ground truth, VINS-Mono, VINS-RGBD, and DVIO are plotted in black, blue, green, and red, respectively. o indicates the start point and the end point of a trajectory.

Fig. 8. Experimental settings for localization/wayfinding experiments.
This paper presents a new VIO method, called DVIO, for 6-DOF pose estimation of an RGB-D-camera-based VINS. The method achieves better accuracy by using the geometric feature (the floor plane extracted from the camera’s depth data) to add constraints between the graph nodes to reduce the accumulative pose error. Specifically, it tightly couples the floor plane, the visual features, and the IMU’s inertial data in a graph optimization framework for pose estimation. Based on the characterization of the camera’s depth measurements,visual features are classified into ones with a near-range depth and ones with a far-range depth. For near-range visual features, the depth values are initialized and updated by directly using the camera’s depth measurements because these measurements are accurate. For far-range visual features, thedepths are regarded as unknown values because the camera’s depth measurements are less accurate and therefore, the epipolar plane model is used to create constraints between the related nodes in the graph. The use of the floor plane and the inclusion of both visual features with and without a depth value improved the pose estimation accuracy. To support wayfinding application in a large indoor space, a PFL method is devised to limit the accumulative pose error of DVIO by using the information of the operating environment’s floor plan. The PFL method builds a 2D local grid map by using the DVIO-estimated egomotion and aligns this map with the floor plan map to minimize the pose error. PFL and DVIO form a VPS for accurate device localization on the 2D floor plan map.
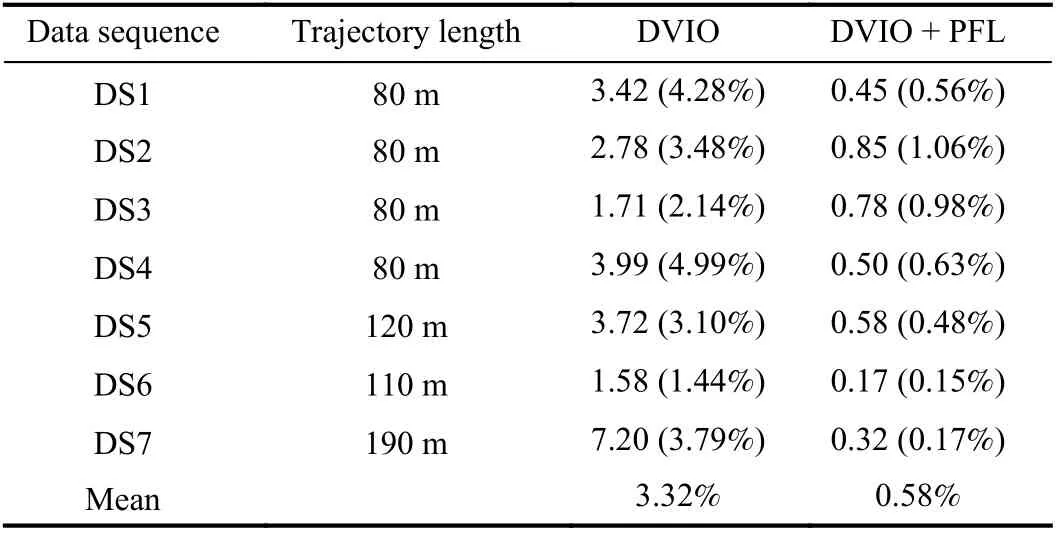
TABLE IV COMPARISON OF EPENS: METERS (% OF PATH-LENGTH)
We validated the VPS’ localization function in the context of assistive navigation RNA in a large indoor space. To extend VPS into a full navigation system, we developed other essential software modules, including data acquisition, path planning, obstacle avoidance, and ART control. The ART mechanism can steer RNA into the desired direction of travel to guide the visually impaired user to avoid obstacles and move towards the destination. Experimental results validate that: 1) DVIO has better pose estimation accuracy than stateof-the-art VIO and it achieves real-time computation on a UP Board computer; 2) PFL can substantially reduce DVIO’s accumulative pose error for localization in a floor plan; and 3)VPS can be effectively used for assistive navigation in a large indoor space for both wayfinding and obstacle avoidance.
In terms of future work, we will recruit visually impaired human subjects to conduct experiments in various indoor environments to validate the assistive navigation function of the RNA prototype.[1]R. R A Bourne, S. R. Flaxman, T. Braithwaite, M.V. Cicinelli,et al.,“Magnitude, temporal trends, and projections of the global prevalence of blindness and distance and near vision impairment: A systematic review and meta-analysis,”Lancet Glob Healthm, vol. 5, no. 9,pp. 888–897, 2017.

Fig. 9. Trajectories estimated by DVIO and PFL (DVIO + PF) on the floor plan of the Engineering East Hall. The start and endpoint for DS6/DS7 are the same.

TABLE V EPENS OF WAYFINDING EXPERIMENTS
猜你喜欢
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Distributed Subgradient Algorithm for Multi-Agent Optimization With Dynamic Stepsize
- Kernel Generalization of Multi-Rate Probabilistic Principal Component Analysis for Fault Detection in Nonlinear Process
- Learning Convex Optimization Models
- Robust Controller Synthesis and Analysis in Inverter-Dominant Droop-Controlled Islanded Microgrids
- Cooperative Multi-Agent Control for Autonomous Ship Towing Under Environmental Disturbances
- Passivity-Based Robust Control Against Quantified False Data Injection Attacks in Cyber-Physical Systems