稀缺资源语言神经网络机器翻译研究综述
2021-07-25李洪政黄河燕
李洪政 冯 冲 黄河燕
神经网络机器翻译(Neural machine translation,NMT)于2013 年正式出现[1].在短短几年的时间里,从最初的循环神经网络(Recurrent neuralnetwork,RNN)encoder-decoder 结构[2],到基于注意力机制的RNN search 模型[3]及其各种变体,再到目前最流行的Transformer 架构[4]以及随后多样的预训练模型,NMT 以其独特的优势迅速成为主流的翻译方法,翻译技术取得了巨大突破,翻译质量也不断得到改善和提高.
NMT 的成功与算力资源、算法模型和数据资源密不可分,尤其依赖于海量的双语数据资源.而获取高质量的双语资源往往需要很多高昂的代价,另一方面,世界上目前现存的很多语言在双语数据资源方面却十分匮乏甚至缺失.在机器翻译领域的研究中,这些语言一般称为“稀缺资源语言”,也称为“低资源语言”(Low-resource languages).本文接下来会交替使用这两种术语.
在数据因素的制约下,NMT 在低资源语言中的翻译效果仍然并不理想.而低资源语言机器翻译一直具有很多实际的需求和应用场景,因此引起了国内外学术界和业界的广泛关注,已经成为当前机器翻译领域的重要研究热点之一,也出现了很多值得关注的研究成果.
Google、Facebook、卡内基·梅隆大学(CMU)和爱丁堡大学等在低资源语言机器翻译上做了很多研究.国内机器翻译领域也非常重视这方面的研究.中科院自动化所、清华大学、苏州大学、东北大学、昆明理工大学、北京理工大学等多个科研团队在承担低资源语言机器翻译国家级科研项目、自主研发实用翻译系统等方面都积极推动深入的技术交流与合作,同时在全国机器翻译大会等多种学术活动都有广泛、密切的研讨,推动了这个方向的研究进展[5−8].
随着国内外研究的发展和深入,我们认为很有必要对目前稀缺资源语言机器翻译的研究进展进行比较全面的回顾.本文期望能够为机器翻译和相关领域的研究者提供有益的参考,帮助他们更好地深入了解低资源语言机器翻译的研究动态和选择未来的研究方向.
本综述的剩余部分组织如下:第1 节介绍了与低资源语言机器翻译相关的学术活动和公开的数据资源;第2 节详细梳理归纳了目前比较重要和常用的低资源翻译方法和技术,并总结了它们各自的特点;第3 节总结了这些方法之间的关系,第4 节分析了当前研究现状的主要特点;最后对未来的研究趋势和发展方向提出了展望和建议.
1 稀缺资源语言机器翻译学术活动及数据资源
1.1 相关学术活动
为了进一步推动稀缺资源语言机器翻译的发展,加快研究步伐,加强技术交流,实现技术与真实应用场景结合和技术落地,近两年以来国际上积极开展了各类有影响力的学术活动.
机器翻译领域最权威的国际比赛之一的机器翻译大会(Conference on Machine Translation,WMT)近几年来在新闻领域的翻译评测任务都会涉及英语−低资源语言的翻译,如古吉拉特语,哈萨克语等[9−12].
“针对紧急事件的低资源语言”(Low Resource Languages for Emergent Incidents,LORELEI)是美国国防高级研究计划局(DARPA)资助的项目,该计划的目标是显著提高计算语言学和人类语言技术的水平,以实现低资源语言的快速和低成本开发.为此,美国国家标准技术研究所(NIST)推出了相应的评测活动(LoReHLT)1https://www.nist.gov/itl/iad/mig/lorehlt-evaluations,评测任务包括机器翻译、实体发现和链接等.该评测活动从2016 开始每年一次,至2019 年已经连续举办了4 届.
WAT2https://lotus.kuee.kyoto-u.ac.jp/WAT/(Workshop on Asian Translation)是专门针对亚洲语言翻译的会议,到2019 年已经连续举办了6 届.该会议具有亚洲低资源语言和英语的翻译评测活动.
另外两个专门的学术活动是“低资源翻译技术研讨会”(Workshop on Technologies for MT of Low Resource Languages,LoResMT)3http://www.conference.amtaweb.org/,4https://sites.google.com/view/loresmt/和“低资源自然语言处理与深度学习研讨会”(Deep Learning for Low-resource NLP)5https://sites.google.com/view/deeplo18/home,6https://sites.google.com/view/deeplo19,这两个论坛已于2018 年和2019 年分别连续举办了2 届.
1.2 相关数据资源
机器翻译与数据资源密不可分.表1 整理了一些可以用于低资源语言翻译的数据资源:

表1 低资源语言翻译相关的数据资源Table 1 Data for low-resource MT
2 稀缺资源语言机器翻译方法
本部分将重点介绍低资源语言的机器翻译方法.由于zero-shot (即待翻译语言对之间未经过翻译模型训练)和zero-resource (即待翻译语言对之间没有平行语料数据)场景也属于低资源翻译的特殊形式,故也将其纳入本文的考察范围之内.目前已有研究方法大致可以分为五大类:第一类是利用第三方枢轴语言的翻译方法;第二类是从丰富资源语言到稀缺资源语言的迁移学习方法;第三类是利用单语数据,实现数据增强的方法;第四类是半监督和无监督方法;第五类是多语言和多任务的翻译方法.接下来将分别介绍每类方法,并在每类方法的最后总结各自的优势和不足等系列特点.
需要说明的是,本文希望考察“低资源”这一特殊场景的翻译方法研究,在整理文献时重点根据“低资源、零资源”等关键词语进行筛选,同时也会考虑文献中的数据集规模,如果某类方法出现在一些明显属于丰富资源语言或者较大实验数据集(比如规模多达几十万甚至百万)的文献中,那么我们倾向不将这些文献纳入本文的研究范围.另外,在有些研究中,某类方法可能会与其他类型的方法同时被使用.另有一些研究中使用的方法也不一定能够严格地归入文中介绍的其中一类.
2.1 基于枢轴语言的方法
基于枢轴语言(Pivot-based)的翻译方法试图为源语言和目标语言寻找一种(或几种)枢轴语言(如英语),实现源语言−枢轴语言−目标语言的翻译过程.一种代表性的方法是首先利用源语言−枢轴语翻译模型将源语言翻译为枢轴语言,然后利用枢轴语言−目标语翻译模型将枢轴语言翻译为目标语言[17].这种方法在统计机器翻译中具有广泛的应用,NMT 兴起并发展以后,也开始出现在NMT 和一些商业翻译系统中.例如Google 在GNMT 中很早就采用了枢轴语言翻译方法,实验结果明显优于没有增量训练(Incremental training,也即,使模型在不丢失已经学习到的已有数据信息的基础上,继续学习新加入的训练数据)的通用模型[18].
基于枢轴语言的翻译方法通常会存在错误累积问题.由于源语言−枢轴语言与枢轴语言−目标语言双语之间的关系不是非常紧密甚至毫无关系等原因,源语言−枢轴语言翻译模型中的错误会传递到枢轴语言−目标语言模型中.而且两种翻译模型通常单独训练,这进一步放大了错误传递.
为了解决这一问题,清华大学刘洋老师的团队做了深入而有影响的研究[19−21].Cheng 等[19]提出了一种联合训练的神经网络翻译模型,通过生成并共享枢轴语言的词向量,以及对小规模的源语言−目标语言双语语料进行最大似然估计的方法将源语言−枢轴语的翻译模型和枢轴语言−目标语的翻译模型联系起来进行联合训练.实验结果显示BLEU值比Baseline (独立训练两种翻译模型)提升了1~2 个百分点.
同样是为了解决错误传递问题,Zheng 等[20]针对零资源机器翻译,通过最大期望似然估计(Maximum expected likelihood estimation,MELE),直接训练源语言−目标语言的翻译模型.
如图1 所示,MELE 方法的目标是,在枢轴语言Z-目标语Y平行语料的基础上,针对源语言X-目标语言Y翻译模型,对枢轴语言Z-源语言X翻译模型获得最大期望.
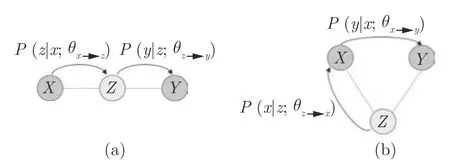
图1 基于枢轴语言的方法(a)和MELE 方法(b)Fig.1 Pivot-based method (a)and MELE method (b)
在Cheng 和Zheng 等的工作基础上,Chen等[21]针对零资源机器翻译进一步提出了“Teacher-Student”的框架.该工作的主要思想是,为了训练缺乏双语语料的源语言−目标语言的翻译模型(“学生”),可以利用预训练的枢轴语言−目标语言的翻译模型(“老师”)指导基于源语言−枢轴语言双语数据训练的学生模型,如图2 所示.

图2 基于枢轴语言的方法(a)和“老师−学生”方法(b)Fig.2 Pivot-based method (a)and“Teacher-student”method (b)
该框架提出了句子级和词语级两种“老师”模型,允许翻译模型直接进行参数估计,而无需将解码过程分解为两个步骤,因此既有效率提升,又可以避免错误传递.与Cheng 等的结果进行对比,最好的BLEU 分数在相同数据集上又提升了3 个多百分点.
Ren 等[22]假设源语言X-枢轴语言Z属于丰富数据的语言对,而枢轴语言Z-目标语言Y属于稀缺语言对.他们同样不针对(X,Y)进行直接建模,但与前面研究不同的是,他们将目标语言作为中间桥梁,对目标语言-枢轴语言翻译模型进行建模,把训练翻译模型P(Z|X)分解为训练P(Y|X)和P(Z|Y)两个翻译模型,然后利用期望最大化算法(Expectation-maximization,EM)对模型进行训练.
Lakew 等[23]针对多语种的zero-shot 翻译场景,提出了一种以英语为枢轴语言的迭代式翻译模型,在意大利语 − 罗马尼亚语数据上使BLEU 分数提升了8~10 个百分点.
除了文本信息,图像等多模态信息也可以作为枢轴语言信息用于低资源语言翻译.例如:Nakayama 和Nishida[24]把图片作为枢轴信息,认为对于改善零资源翻译效果同样有帮助.Chowdhury 等[25]利用Flickr30k 图片数据集中的图像信息和图像描述信息实现了印地语−英语的多模态低资源语言翻译,在图像信息的帮助下,BLEU 分数比单纯的文本翻译有了相应提升.
总结:基于枢轴语言的翻译方法以第三方语言为中介,以其简洁方便的特点能够适用于统计翻译和神经网络机器翻译等,具有比较久的研究历史,但该类方法由于不直接实现源语言和目标语言之间的翻译,在训练过程的几个阶段容易产生错误累积等问题,而且整个训练过程的解码时间相对较长.
2.2 迁移学习方法
迁移学习(Transfer learning)[26]是机器学习的一种重要方法,在自然语言处理领域同样有着广泛应用.Ruder 在其博士论文中有详细深入的论述[27].具体到低资源语言翻译,迁移学习的一般做法是首先在数据资源丰富的语言上训练模型,然后迁移到低资源语言上,进行微调,最终产生译文.
由于迁移学习涉及多种语言,因此丰富资源和稀缺资源语言之间的语言相关性是一个经常研究的问题.一般来说,语言相似性越高,越有利于迁移学习.在“父”语言和“子”语言之间共享BPE 得到的子词词汇表或者BPE 向量表示可以利用语言之间的相似性.
Zoph 等[28]率先将迁移学习用在机器翻译中.他们利用丰富资源的语言对训练了一个“父”模型,然后对稀缺语言的“子”模型进行权重初始化,最后在资源匮乏的语言对上训练最终的翻译模型.
Nguyen 和Chiang[29]进一步探索了父模型的语言对也属于低资源语言,但与子语言对之间有关系的场景,通过使用BPE 方法的共享词汇表和音译等改进了以前的方法.Dabre 等[30]也探索了语言相关性在迁移学习中对于翻译质量的影响效果.
Kocmi 和Bojar[31]则验证了语言对之间不存在关联性的情景中,利用Transformer 在父、子模型之间共享词汇,进行迁移学习翻译的效果.模型以英语为中间语言,分别在相关性较强的欧洲语言对之间和不相关的欧洲语言对之间进行了多组实验,结果都有不同程度的明显提升.但他们同时表明翻译效果可能还跟父语言对的规模有关.
Gu 等[32]针对双语数据都非常稀缺的语言对,提出了一种通用的翻译模型,把多种源语言共享的词语级和句子级表示映射到一种目标语言中,得到通用空间中的词向量表示.这样做的优势是,不同语言中语义相似的词语能够具有相似的表示并映射到同一个语义空间.随后他们又提出了一种与模型无关的元学习框架(图3)(Model-agnostic metalearning,MAML)[33],在多个语种上的实验效果要远远优于迁移学习模型.Li 等[34]也基于元学习方法利用多种领域的数据解决低资源翻译中的领域迁移问题.

图3 迁移学习,多语言迁移学习与元学习Fig.3 Transfer learning,multilingual transfer learning and meta learning
Kim 等[35]利用跨语言词向量,提出了一种不需要共享词汇表的迁移技术用于零资源翻译场景.随后又提出了一种基于枢轴语言的迁移学习方法[36],首先预训练源语言 − 枢轴语言和枢轴语言 − 目标语言的翻译模型,然后将二者迁移到源语言 − 目标语言翻译模型上进行微调.苏州大学张民老师团队最近针对zero-shot 场景提出了基于跨语言预训练模型的迁移学习方法,比Kim 等的效果进一步有所提升[37].
整体来看,目标语言端的迁移学习比源语言端的迁移学习更具挑战性.因为不同的目标语言需要特定的目标语言表示形式,而迁移学习则更喜欢目标语言不变的表示形式.迁移学习的成功取决于在这些因素之间取得适当的平衡.随着各种预训练模型的流行,迁移学习能够将尽可能多的知识迁移到翻译模型,在一定程度上也增加了翻译模型的可解释性.
总结:以预训练模型为主要方式的迁移学习方法已经广泛应用于自然语言处理的很多应用领域和场景,也极大地改善了翻译质量.但随着各种超大规模的预训练模型的发布,在一定程度上对于迁移学习涉及的语言之间的相似性和算力资源提出了更高的挑战,在训练过程中也会存在不易优化等困难.
2.3 半监督和无监督方法
低资源语言机器翻译通常缺乏大规模双语数据,而单语数据比较充足也更容易获取.半监督方法(Semi-supervised)主要利用单语数据和小规模双语数据实现翻译过程.其中回译技术(Back-translation,或称反向翻译)是一种主要手段,将在下一小节中详细论述.
Cheng 等[38]利用自动编码器(Autoencoder)分别重构单语的源语言X和目标语言Y.即,目标语言的自动编码器首先利用Y→X的翻译模型将目标语言编码为潜在的源语言,然后利用X→Y翻译模型解码重构新的目标语言Y´,同理,源语言亦如此.
Skorokhodov 等[39]则将预训练的语言模型与翻译模型结合起来,首先分别训练源语言和目标语言的语言模型,然后初始化翻译模型,在俄语−英语这一极低资源数据集上使BLEU 分数比baseline 提高了1.4 个百分点.
Gulcehre 等[40]利用“浅层融合”(类似于常规SMT 解码器中使用语言模型)和“深层融合”(将语言模型和解码器的隐藏状态拼接在一起)两种机制将单语目标语言的神经网络语言模型融合到翻译模型中,在土耳其−英语等低资源数据集上使BLEU分数提升了接近2 个百分点.
南京大学团队[41]最近提出了一种“镜像生成式”(Mirror-generative)的机器翻译模型,结合了回译、对偶学习等技术,可以更好地利用非平行语料改善翻译效果.
在无监督翻译(Unsupervised)方法中,则不依赖双语平行数据,只依赖单语数据训练翻译模型(如图4 所示).Facebook 的团队非常重视低资源翻译研究,做了很多开创性的工作[42−45].现有的无监督翻译方法通常包括两个阶段:首先预训练语言模型[46−47],然后在微调阶段利用回译等训练翻译模型.

图4 无监督翻译方法Fig.4 Unsupervised NMT
此后,无监督方法吸引了更多研究者的关注.在过去两年的NLP 顶级会议上就有多篇关于无监督翻译方法的论文.例如:Yang 等[48]对无监督翻译模型增加了权重共享约束,使得模型能够使用两个独立的编码器,然后使用生成对抗网络(GAN)改善了翻译效果.
Gu 等[49]针对零资源翻译场景,首先定量分析了零资源翻译的退化问题.然后通过预训练解码器的语言模型和对零资源语言对进行反向翻译,在数十种欧洲语言对上验证了方法的有效性.最近他们又利用25 种语言预训练去噪的模型,然后在不同规模的语言对数据集上调优,进行了句子级别和文档级别的翻译实验,在英语 − 越南语等低资源数据集上将BLEU 提升了10 多个百分点,取得了非常好的效果[50].
除了文献[43]等少数研究工作,大部分无监督翻译方法通常首先需要利用无监督跨语言向量模型(如Facebook 的LASER 和MUSE 工具等)[51-52]将两种语言的向量表示映射到共享向量空间,因此对于相似性较高的低资源语言之间的翻译比较有效,而在远距离语言对之间的翻译效果比较差.
总结:半监督和无监督翻译方法的一个优势在于可以更多地依赖于单语数据资源,而不必局限于双语数据,这在低资源翻译场景中具有很好的价值,在未来仍将是非常有希望的研究方向之一.但是这类方法的实际效果在不同语言之间的差别较大,在相似性更高的语言对上具有更好的效果.尽管有研究在日语 − 俄语等远距离语言对上的无监督翻译提升了翻译效果[53−54],但在大多数语言对上的效果仍然落后于传统的有监督方法.另外,有研究也指出,无监督方法的有效性依赖于大量辅助数据,以及其他条件是否满足[55].例如,当语言在形态上不同或训练领域不匹配时,无监督方法的有效性会受到损害.
2.4 数据增强方法
数据增强方法(Data augmentation)最初广泛应用于计算机视觉领域,是图像处理的标准处理技术,其目的是利用有限的训练样本数据增加健壮性并改进学习目标.后来开始应用于机器翻译等自然语言处理领域.在低资源语言机器翻译中,由于缺少足够的双语数据,数据增强方法主要利用已有的单语数据达到增加训练数据的目的,从而更好地训练翻译模型,改善翻译效果.单语数据主要来自目标语言一端,但也有研究利用源语言端的单语数据改善翻译效果.例如:中科院自动化研究所的宗成庆研究员团队早在2016 年就提出通过自学习算法和多任务模型框架利用源语言一侧的数据有效提升翻译质量,引起了广泛关注[56].
Gibadullin 等[57]对低资源翻译中如何利用单语数据做了比较全面的综述分析,他们把利用单语数据的方法分为“独立于翻译模型”和“依赖于翻译模型”两大类.本文将常见的数据增强方法同样分为以下两种类型.
1)回译方法
爱丁堡大学的团队首次将回译技术用于NMT,利用目标端的单语数据有效地提升了翻译性能[58].此后,这一方法被广泛应用在NMT 中,也被证明对于改善翻译质量特别是低资源翻译场景有很大帮助,回译已经成为NMT 的标准技术之一.
尽管回译对NMT 的性能提升有很大帮助,但其中仍有很多因素值得深入研究.很多工作针对回译从多个方面进行了探索.
Park 等[59]分析了仅使用反向翻译生成的多种合成数据对翻译模型的影响.Poncelas 等[60]也对多种训练数据类型(仅真实数据、仅合成数据、混合数据)以及回译数据的比例对于翻译效果的影响进行了实证分析.他们认为,与基于最大化推断生成的合成数据相比,基于采样和加入噪声的束搜索生成的合成数据能够提供更好的训练优势.后来他们又分析了SMT 和NMT 产生的合成数据对于NMT效果的影响,认为二者结合可以进一步提高翻译效果[61].
回译方法的一个主要局限是需要平衡真实数据和合成数据的规模.Edunov 等[62]对生成回译的多种方法进行了比较全面的实证研究和对比分析.他们表明,在合成数据中增加噪声数据不仅可以提高翻译质量,还可以使训练在合成句子与真实句子的比率较高的情况下更加可靠.Fadaee 和Monz[63]也进行了类似的工作.
回译方法虽然操作简单,方便有效,但产生的伪平行语料可能会面临数据质量较低的问题,在一定程度上会影响翻译性能.针对这个问题,有研究者做了相关工作.
Hoang 等[64]在回译的基础上进一步提出了迭代式回译,即不断重复回译的过程,直到获得更好的翻译效果.Imankulova 等[65−66]通过多次翻译筛选译文语句构建较高质量的伪双语数据,以改善翻译质量.
Wu 等[67]提出了一种名为“Extract-Edit”的双语数据抽取方法用于替代广泛使用的回译方法,以产生高质量的双语数据.
Currey 等[68]则利用反向翻译将第三方的单语枢轴语言分别生成源语言和目标语言,组成伪双语数据,然后实现源语言到目标语言的翻译.
2)词语替换方法
不同于回译方法,这种方法的主要做法是有针对性地替换训练数据中的词语,而无需训练回译需要的翻译模型.
Fadaee 等[69]在不改变训练语句句法和语义的前提下,将训练语料中的词语替换成一些低频词语.这样就增加了训练数据的规模.但该方法需要一些复杂的预处理步骤,而且实验表明只对低资源数据集有效.
Wang 等[70]对源语言和目标语言两侧均进行数据增强.利用从两侧词汇中统一采样的其他单词分别替换源语言句子和目标语言句子中的单词.在多个语言数据集上均有效提升了BLEU 分数.
Xia 等[71]结合枢轴语言方法提出了一种实现数据增强的通用框架(图5),不仅可以利用目标语言一端的数据,还可以将与稀缺资源语言有一定联系的丰富资源语言作为枢轴语言,获得丰富语言−稀缺语言的数据.
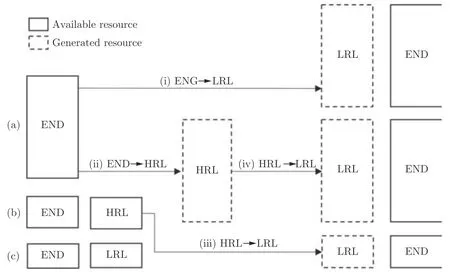
图5 数据增强框架.其中,(i)和(ii)是传统数据增强方法,(iii)和(iv)是新提出的方法Fig.5 Data augmentation method,where (i)and (ii)are traditional methods,while (iii)and (iv)are new ones
微软团队[72]提出了一种“软”语境数据增强方法.该方法可以将随机选定的词语替换为与该词语语境密切相关的“软”词语.软性词语可以通过语言模型获得,可以认为是基于语料数据的词表概率分布.
Zhou 等[73]则将句法信息引入数据增强方法,首先将目标语言调整为具有源语言句法结构和语序的目标语言,然后利用双语词典将调序后的目标语言中的词语替换为源语言词语,最后将其加入伪平行语料数据中,从而实现数据增强的目的.
除了以上两种类型的方法,Currey 等[74]通过复制目标端的数据也实现了提升翻译效果的目的.
数据增强方法在不同翻译任务上对于提升翻译效果存在差异性,也就是说,不是所有的数据增强方法在所有翻译任务上都能够提升效果.为了分析数据增强在不同方法和任务中通常能够获得什么益处,在深度学习理论的启发下,Li 等[75]从输入灵敏度(Input sensitivity)和预测余量(Prediction margin)两个维度进行了全面的实证检验.
总结:在缺乏大规模双语数据的场景中,数据增强方法能够快速地扩充训练数据,回译方法也以其自身的优势成为NMT 的标准处理技术和数据增强的重要途径.但这类方法通常需要考虑真实数据与新产生的合成数据之间的规模比例问题,有时候当伪数据超过一定规模后,反而会影响翻译性能,另外,通过数据增强产生的数据也可能会存在质量较差的情况,在一定程度上也会增加很多噪声.
2.5 多语言/多任务翻译方法
多语言(Multi-lingual)翻译的目标是通过单一翻译模型实现多种语言之间的互相翻译[76].文献[77]对多语言神经网络机器翻译做了详细的回顾.为了更好地改善低资源场景的翻译质量,近几年来这种翻译方法引起了很多关注,例如微软团队和CMU团队等都开展了有针对性的集中研究,包括知识蒸馏(Knowledge distillation)和语言集束方法[78−79],使用共享词向量表征所有语言,以及软解耦的编码方法等[80−81].
在多语言NMT 模型中,根据源语言和目标语言的数量,通常存在三种翻译策略:多对一翻译、一对多翻译以及多对多翻译.多对一模型学习将在源语端的任何语言翻译成目标端的一种特定的语言,这种情况下通常会选取语料丰富的语言比如英语;相似地,一对多模型学习将在源语端的一种语言翻译成目标端任意一种语言.多对一这种模式通常会看作多领域学习的问题,类似于源语端的输入分布是不一致的,但是都会翻译成一种目标语.而一对多模式可以被看作是多任务的问题,类似于每一对源语到目标语看作一个单独的任务.多对多这种模式就是这两个模式的集合.Google 的神经网络翻译系统在去年的最新进展中实现了以上三种策略在超过100 种语言之间的低资源和零资源翻译[82].
Firat 等[83]对零资源翻译场景提出了一种多语言翻译的调优算法,认为多对一的翻译策略更优于一对一的翻译方法.Zhou 等[84]对多个不同语族的多种欧洲语言进行了全面的定性和定量分析,得出了基于与低资源目标语言最相近的语族的几种语言训练多语言翻译模型,能够有效改善翻译质量的结论.Maimaiti 等[85]同样得到了类似的结论,与仅使用一对高资源语言对进行迁移学习相比,使用多个语言关系高度相关的高资源语言对并进行多个回合的微调可以提高翻译性能.类似工作还有文献[86]等.从这些研究可以看出,无论是多语言翻译,还是迁移学习方法,更强的语言相关性对于改善翻译效果都会有更多帮助.
除了欧洲语言,也有人研究了亚洲语言.Dabre等[87]将多语言翻译方法与迁移学习结合,实现了英语到亚洲多种语言的翻译.他们在多语言、多阶段微调过程中没有关注语言差异,而是表明数据大小很重要.但这种多语言、多阶段的迁移学习需要进一步的研究.Murthy 等[88]基于Zoph 等[28]的工作,使用英语作为辅助语言,以英语−印地语作为预训练的父模型,在预训练时还考虑了句法语序信息,最后在几种亚洲语言−印地语的子翻译模型上进行微调.
Imankulova 等[89]将领域适用性、多语言翻译和反向翻译等技术结合起来,首先利用领域外的数据训练多语言翻译模型,然后在领域内数据集上微调,在日语−俄语这一语言特点差异很大的极端低资源数据集上使翻译效果有了明显提升.
Neubig 和Hu[90]将多语言作为种子模型,提出了一种能够快速有效地适用于新语言的多语言翻译模型.类似地,Lu 等[91]在多语言翻译框架中引入国际辅助语言“因特语”(Interlingua)模块,在zeroshot 场景中将特定语言的编码器输出转化为独立于特定语言的解码器输入表示,实现了语言的直接翻译,而无需借助枢轴语言.
Sestorain 等[92]则利用强化学习方法共同训练融入语言模型的多语言翻译模型和重构目标,以保证译文的语法准确性和翻译质量.但这种方法在训练中非常耗时,而且在数次迭代后效果很难继续有所改善.
多语言翻译对于低资源翻译场景尽管具有很多优势,但同时面临着在独立模型下无法实现知识共享,且需要大规模存储和计算资源的问题.CMU 的团队为翻译模型设计了一种适用于多种语言的语境参数生成器,使翻译模型变得更加通用,并且适用于零资源和低资源翻译[81].中科院自动化研究所的宗成庆老师团队提出了一种结构紧凑且语言敏感的多语言机器翻译方法,能够很好地利用语言之间的共性,为低资源和零资源的翻译场景提供了新的解决思路[93].
多任务(Multi-task)翻译方法是NMT 的一种常见方法之一,其主要思想是利用多个相关的其他任务(如句法分析、语义分析等),来提升翻译任务的质量.
文献[94]利用词性标注和依存分析任务将句法信息引入翻译任务中,使得BLEU 分数有了1~2个百分点的提升;文献[95−96]改进模型架构设计,希望学习到多个任务之间共享的有效参数,同时改进训练安排,即调整不同任务之间的优先程度,保证将改善翻译质量作为主任务,其他相关任务作为辅助任务.
总结:多语言翻译方法对于低资源翻译任务是很有必要的,因为来自多种语言的翻译模型能够帮助资源匮乏语言获得额外的知识,同时不同语言也使得模型具有更好的泛化能力,与双语翻译相比具有更好的迁移学习能力[97].目前主流的多语言翻译模型主要有三种思路:1)使用不同的编码器和解码器表征不同语言;2)使用统一的编码器和解码器用于所有语言之间的翻译;3)在编码器和解码器中共享一部分参数表示语言之间的共性特征,另一部分表示语言的特有属性.但正如前面提到的,通常都会不可避免地面临模型结构复杂,计算复杂度增加以及知识共享存在障碍等问题.
以上回顾了低资源翻译的主要方法.另外,还有一些研究不一定能够严格地归入上述的某一类方法,如微软团队提出的对偶学习(Dual learning)[98]就与前面方法的学习范式有很多不同之处,自从提出以来产生了比较大的影响,以及最近提出的语言图蒸馏(Language graph distillation)方法[99]等.再如文献[100]等使用的方法同样证明了对于提升翻译质量的有效性.此处不再赘述.
3 翻译方法之间的关系
从前面的梳理可以看到,很多研究文献中结合了不止一种翻译方法和技术,表2 列出了一些这样的文献.

表2 使用多种翻译方法的一些文献Table 2 Literatures with more than one MT method
研究中使用的不同方法各有特点,也存在比较密切的联系,下面根据图6 依次进行简要分析.
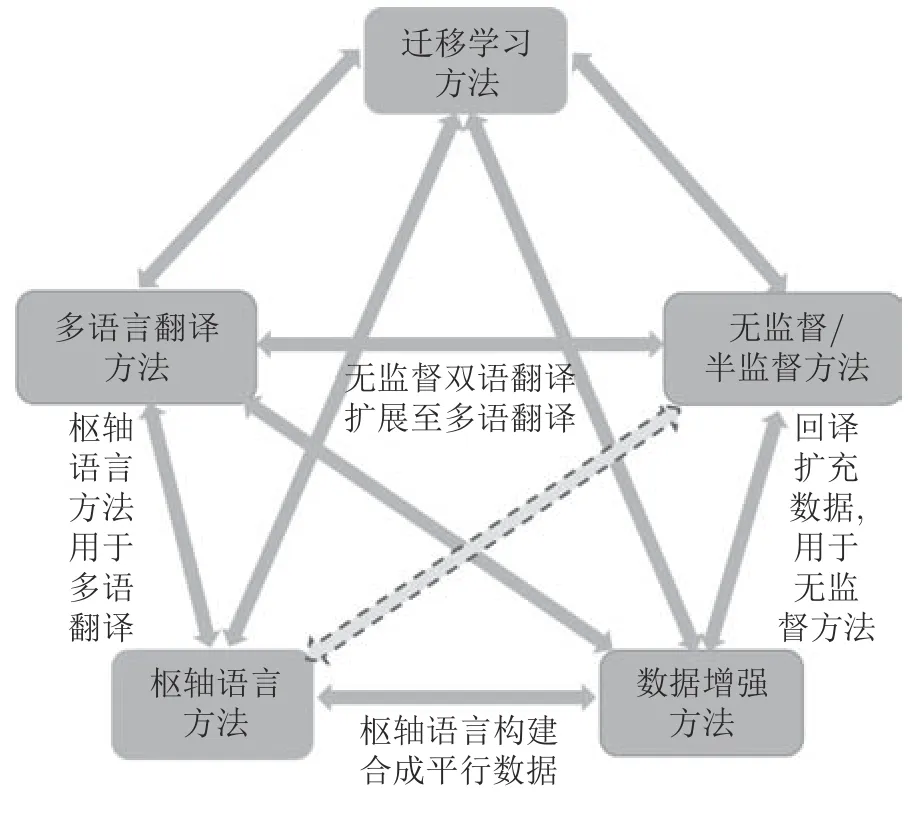
图6 几类翻译方法之间的关系Fig.6 Relations between the translation methods
迁移学习是目前非常流行而又高效的方法,特别是最近两年,在稀缺资源翻译研究中占有较高的比重,这种“预训练+微调”的模式可以应用到其他各类的翻译方法中.因此与其他各类方法都有关联.
枢轴语言翻译方法由来已久,在用于NMT 以前,经常用于统计翻译,甚至在更早的规则翻译方法中也有所体现.枢轴语言方法从一个语言对之间的翻译还可以扩展到多语种之间的翻译,比如多语种之间的零资源翻译场景.数据增强方法同样可以扩展到多语种翻译场景[101].
另外,枢轴语言还可以通过反向翻译构造枢轴语言与源语言/目标语言之间的合成双语数据,从而实现了数据增强的目的.
值得注意的是,在图6 中,枢轴语言翻译方法与无监督/半监督方法之间采用虚线箭头连接,这是因为多数场景(如zero-shot)的枢轴语言翻译可以看做是有监督翻译或半监督翻译,而不属于无监督方法.
无监督方法具有很大的挑战性.由于不使用双语数据,而摆脱了NMT 严重依赖大规模双语数据的局限,对数据资源的依赖较小,尤其适合于低资源和零资源翻译场景.尽管目前的翻译效果仍然相对不是非常理想,但在近期和未来一段时间应该会有很好的发展潜力.
将无监督翻译方法用于多语言翻译场景的研究目前暂时不多,因为多语言翻译通常属于有监督翻译方法.不过最近 Google 团队尝试了无监督方法的多语种翻译,在罗马尼亚语−英语数据集上使最好BLEU 分数提高了近两个百分点[102].相信未来会有更多这方面的尝试.
由于很多文献在不同领域、不同规模和不同语种的测试集上进行实验,我们认为难以比较以上不同类别方法之间的效果差异.但我们分析了过去三年(2017~2019 年)WMT 比赛的新闻领域翻译评测任务使用的方法,希望从实际比赛和工程实践中观察各类翻译方法的使用情况.
根据历年的评测总结报告,在2017 年的评测参赛队伍中,约有一半左右(12~15 个)使用了回译技术,而迁移学习和无监督方法等在当时还未出现或者尚不流行,几乎没有被用于参赛.在2018 年的比赛中,随着Transformer 的出现和流行,35 个左右的参赛队伍中的绝大多数(约30 个)都使用了Transformer 架构,而其中都使用了回译作为基本的技术手段,另外还有三四个队伍分别使用了无监督方法和多语言结合的方法.2019 年的比赛任务吸引了包括多家国内单位在内的更多参赛队伍(近50 个)参加,有效提交系统数量超过150 个,同时新增了无监督翻译任务,比赛中使用的方法也更加多元化.表3 总结了本文介绍的几类方法在参赛系统中出现的大概频次.

表3 几类方法在WMT2019 中的使用情况Table 3 The methods in WMT2019
除了以上方法,微软亚洲研究院、百度、小牛翻译等多家单位还使用了领域适用性(Domain adaptation)和知识蒸馏等多种有效的综合方法和技术.
图7 是WMT2019 提供的一些训练方法的统计和占比,从中也可以看出包括低资源翻译在内的神经网络机器翻译在国际比赛中的技术概况.

图7 WMT2019 中涉及的主要方法和技术Fig.7 Main methods in WMT2019
4 当前研究现状的特点
图8 简要总结了这几类翻译方法各自的优势与局限性.
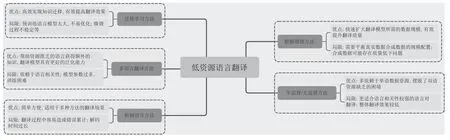
图8 各类翻译方法的优势与局限Fig.8 Advantages and limits of translation methods
通过梳理已有的研究方法,我们还总结了目前研究现状呈现的主要特点:
1)从目前工作的类型来看,已有研究主要分为两种类型:一种主要的类型是采用某种或者某些方法改善低资源翻译的质量;另一种则是对某种方法(如回译)进行不同程度的定性和定量研究和分析,希望对这些方法有更深入的了解等.这类工作不一定涉及方法改进,往往只是对于某个方法的实证性探究.
2)从机器翻译的类型来看,绝大多数研究集中于低资源文本翻译,这也是机器翻译最重要的应用场景之一;还有一些工作围绕语音翻译开展研究,包括语音转录(Speech transcription)[103],语音到文本的翻译等[104−106];甚至还有人研究低资源方言的机器翻译等[107−108].
3)从机器翻译涉及的领域来看,更多的研究通常更关注新闻、(Technology,Entertainment,Design)演讲等常见的通用领域的低资源语言翻译,一个主要原因在于这些领域的数据资源相对较多.文献[109]针对医疗领域中的医患交流口语翻译率先做了尝试.低资源翻译从常用领域逐渐扩展到更多的专门领域和场景很有必要,同时也更有挑战性.
4)从研究涉及的语种分布来看,低资源语种的分布很不均衡.绝大部分的工作主要集中于欧洲语言场景,英语毫无疑问是最为广泛的语言,无论是作为枢轴语言,还是与其他低资源语种之间的翻译;另有很少一部分研究以亚洲等其他地区的语种为研究对象,如日语−越南语等[110].
值得一提的是,就我们目前掌握的研究文献,汉语与其他低资源语言之间的NMT 研究数量仍然非常少,仅有少量研究采用统计翻译方法.以汉语−越南语神经网络翻译为例,昆明理工大学的团队近年来做了比较集中的研究[111−115].
5 研究趋势展望
稀缺资源语言机器翻译目前仍然具有很多挑战和困难有待解决,例如以下几个科学问题:
预训练模型与翻译模型的结合问题;不同语言,特别是远距离语言之间的有效表示学习问题;以及领域适用性等问题.
我们认为低资源语言机器翻译在未来可能会呈现如下研究趋势和发展方向:
1)加强预训练模型和迁移学习在低资源翻译中的研究.预训练模型和迁移学习在NLP 和机器翻译领域已被证明其有效性,并成为一种新的研究范式.一些研究工作已经开始关注将BERT (Bidirectional encoder representations from transformers)[116]等预训练模型融入低资源语言的翻译模型中[117−118],未来将有更多值得探索和研究的地方.例如:如何更好地将BERT/GPT (Generative pretrained transformer)[119]等流行的预训练模型融入到翻译模型中,并将迁移学习的功效尽可能最大化等.目前基于大规模单语数据的无监督预训练模型进行迁移学习和无监督翻译等研究正在增强.
2)加强语言之间的相关性等方面的语言学分析研究.整体来看,低资源翻译的研究多以改进算法模型提高翻译质量为主,而缺乏必要的语言学分析.目前虽然有一些研究从语言学角度出发,证明了语族接近的语言有助于改善低资源语言的翻译效果等,但值得进一步深入探索.如果能够发现不同语言之间更多的深层次的语言学特征,实现语言特征和知识的迁移和传递,相信会进一步促进稀缺资源语言翻译的发展,同时也可能使翻译过程更具有解释性.
3)加强更有效的语言表示学习研究.低资源语言对之间在词语、句法和语义等层面往往存在较大差异,甚至具有不同的书写系统以及属于不同的语族.在训练翻译模型时,如何处理并减小语言之间在编码表示中的差异,更好地平衡不同语言在向量空间中的表示始终是影响低资源翻译的核心问题.例如:构建语言无关的编码器和具有语言意识的解码器等都将是非常值得深入研究的话题.
4)加强汉语和低资源语言之间的机器翻译研究.我国目前正在大力推行“一带一路”倡议,构建人类命运共同体.语言互通是实现“一带一路”建设的重要保障,而机器翻译又是实现语言互通的加速器和催化剂.在未来应该进一步加强汉语与低资源语言,特别是“一带一路”沿线国家和地区语言之间的机器翻译研究,包括构建多样化的语言数据资源,利用不同方法全面提升翻译质量等.只有这样,才能更好地服务于国家的重大战略需求.
5)加强口语和方言等低资源语言的语音翻译研究.正如上文所述,目前大部分的低资源翻译主要关注文本翻译.语音翻译,包括自动语音识别,语音−文本转换以及语音−语音翻译等都具有很多应用场景,也存在很多机遇和挑战.未来关于低资源语言在语音上的翻译也将是一个很有趣和有价值的研究方向.
