融合FP-Growth和RBM的图书推荐算法研究
2021-07-21杨宇环张开生
杨宇环,张开生
(1.陕西科技大学 图书馆信息部, 陕西 西安 710021;2.陕西科技大学 电气与控制工程学院,陕西 西安 710021)
0 引言
互联网、大数据技术、移动技术等高科技的迅猛发展推动着社会的进步,但数据的爆炸式增长也带来了“信息过载”问题[1].面对大规模的信息,用户无法在短期内准确提取到有价值的数据,因此推荐系统应运而生.推荐系统旨在从海量数据中快速捕获有效数据反馈给用户,最典型的应用场景是电商平台,而随着图书馆智能化水平的提高,图书的个性化推荐逐渐成为研究热点.
目前,基于内容的推荐以及协同过滤推荐作为推荐系统领域最为流行的方法,也逐渐被应用在图书推荐系统中[2].梁思怡等[3]综合考虑读者评分、时间上下文以及兴趣变迁等因素,提出优化时间上下文的协同过滤算法ICBO UserCF(Interest Caputure-Based Optimization UserCF),提高了图书推荐准确度;陈海军[4]提出将改进的Apriori算法用于个性化推荐图书管理系统,向读者推送与历史借阅图书相关联的书籍,能够满足快速推荐的需求;李默等[5]利用标签系统对图书内容进行语义分析,使用关联规则过滤相似读者,结合了基于内容和协同过滤推荐的优势;胡代平等[6]关注到读者阅读兴趣具有时间变化性,提出结合二分网络结构和传统图书推荐算法的混合推荐方法;宋楚平[7]提出一种协同过滤改进方法,以图书分类为项目生成用户评价矩阵,解决高校图书推荐过程中面临的“数据稀疏”和“冷启动”问题;李欣弘[8]基于Apriori算法提出了一种改进的关联规则方法和基于上下文的文本情感分析算法,提高图书推荐的准确性.
目前,大部分基于内容和协同过滤的图书推荐系统仅考虑了读者的属性特征,而忽视了不同读者阅读的个性化特征.本文通过结合FP-Growth和RBM的协同过滤算法,有效利用两者的优势,从而提升图书的个性化推荐性能.
1 相关工作
1.1 FP-Growth关联规则算法分析
关联规则是一种被广泛应用在不同领域的模式识别方法,其能够反映事物之间的相互关联性和依赖性,本质上是发现大量数据中项与项之间存在的紧密的相关关系.Apriori和FP-Growth是常见的关联规则算法,Apriori通过多次扫描原始数据构造候选集,进而从候选集挖掘出频繁项集.其缺点是多次读取原始数据会造成磁盘I/O次数增多,进而导致算法效率低下[9],同时存在不能挖掘定量规则的缺陷[10].FP-Growth将频繁模式树FP-Tree引入频繁项挖掘,树状图中每个节点都对应频繁项集中的一个项[11].FP-Growth算法通过FP-Tree数据结构压缩原始数据,从而对原始数据只需进行两遍扫描,相比Apriori效率更高.
FP-Growth算法的流程为:
(1)建立一个二维表,从第一个事务标签(Transaction ID,TID)开始,对其所对应的项进行计数,并将这些计数信息存储在哈希表中;然后在统计后续TID的项时,若能够在哈希表中找到该TID的项,则直接将哈希表中相应的计数加1,若在当前哈希表中没有查到该项,则将该项直接添加到哈希表的最后,同时记录该项的计数个数[12];最后删除哈希表中低于最小支持度阈值的项,再将哈希表的行根据计数由大到小的顺序进行排序.以7颗FP-Tree为例,说明FP-Growth挖掘过程,如表1所示.

表1 示例
(2)遍历FP-Tree数据结构,并统计原始集合中各个项出现的次数,得到的项头表如表2所示.设定FP-Growth算法的最小支持度为2,删除原始集合中计数结果小于最小支持度的项,即I8,I10,I6项.同时按照支持度从大到小对每颗树中的原始集合重新排序,得到的数据集合如表1的第3列所示.

表2 项头
(3)扫描原始集合统计频繁项集,如扫描到T3时,将
1.2 受限波尔兹曼机
波尔兹曼机(BoltzmannMachine,BM)是一种根植于统计力学的随机神经网络,能够学习输入数据中复杂的规则,但是训练时间较长[13].1986年,Smolensky等提出了受限玻尔兹曼机,它是一种可通过输入数据集学习其概率分布的随机生成神经网络.
近年来,随着深度学习在医疗诊断、图像识别等领域大放异彩,国内外学者逐渐将深度学习引入到推荐系统中,其中受限玻尔兹曼机(RestrictedBoltzmannMachines,RBM)成为研究热点.2007年,RBM模型首次被应用在推荐系统中,用于解决协同过滤存在的数据稀疏性问题.在应用过程中,一方面由于传统RBM模型的可见单元只能取0和1数值,存在与推荐数据集中的评分数据不匹配的问题;另一方面用户评分矩阵存在较多的空缺数据,如何用神经元表示缺失的评分数据也是待解决的问题.针对以上问题,Salakhutdiov提出RBM协同过滤算法[14],将可见层的神经元数量扩展到K个,同时将缺失的评分数据用特殊神经元表示,从而解决了数据输入和数据稀疏问题.
受限波尔兹曼机是一种具有两层结构、对称连接且无自反馈的随机神经网络模型[15].受限玻尔兹曼机由可见层和隐藏层组成,两层之间使用对称权重的全连接,且处于同一层中的神经元之间互不相连.RBM结构如图1所示.
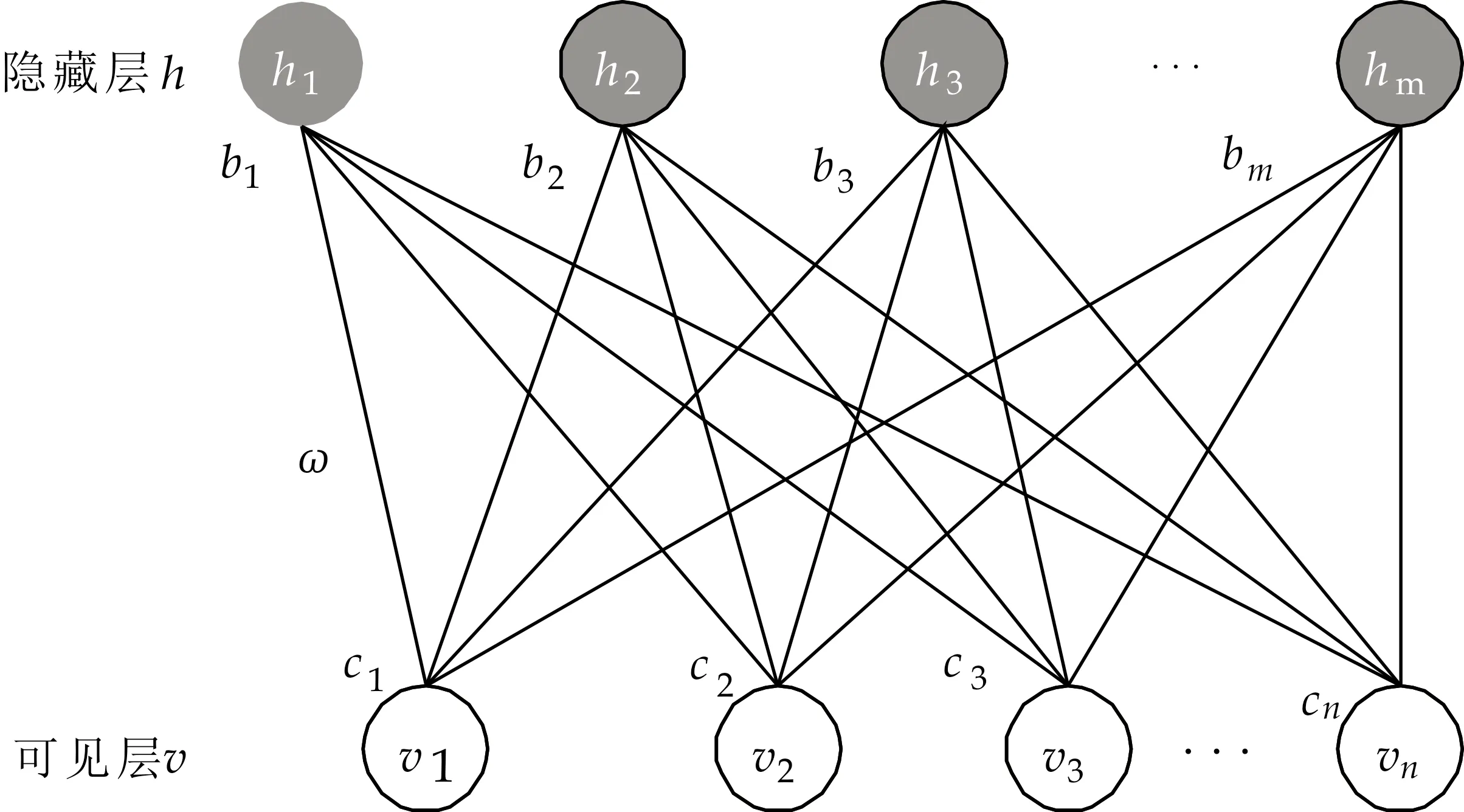
图1 受限玻尔兹曼机网络结构图
图1中隐藏层h表示为h=(h1,h2,h3,…,hm)T,可见层v表示为v=(v1,v2,v3,…,vn)T,其中m和n分别为隐藏层和可见层神经元的个数.常见的RBM模型的可见层和隐藏层具有两种状态,即1表示激活状态,0表示未激活状态.采用下标j和i分别标识隐藏层和可见层,其中j=1,2,…,m,i=1,2,…,n,则hj和vi分别表示隐藏层和可见层相应神经元的状态.连接两层的权值矩阵为W=(wij)n×m,b=(b1,b2,…,bn)T为可见层的偏置,c=(c1,c2,c3,…,cm)T为隐藏层的偏置.
RBM是一种基于能量的模型,模型的训练的目的是使能量函数最小[16].RBM能量函数定位为:
(1)
式(1)中:θ={wij,bi,cj}是RBM的未知参数集合.对能量函数进行正则化和指数化处理,则可见层和隐藏层的联合概率密度函数为:
(2)
RBM模型具有层内无连接、层间全连接的结构,因此两层相互独立.当可见层的单元状态确定时,隐藏层单元被激活的概率为:
(3)
当隐藏层单元状态确定时,可见层单元被激活的概率为:
(4)
Δw=ε(Edata(vihj)-Emodel(vihj))
(5)
Δc=ε(Edata(hj)-Emodel(hj))
(6)
Δb=ε(Edata(vi)-Emodel(vi))
(7)
式(5)~(7)中:ε表示学习率,Edata(·)和Emodel(·)分别表示训练数据集和重构模型所定义的分布之上的数学期望.
2 基于FP-Growth和RBM的图书推荐模型
基于FP-Growth和RBM的图书推荐模型框架分为三层,包括输入层、算法模型层、输出层.将读者的历史借阅记录作为输入层;算法模型层由关联规则FP-Growth和RBM协同过滤模型进行耦合组成图书个性化推荐模型.输出层用于输出图书推荐的结果.图书推荐模型如图2所示.
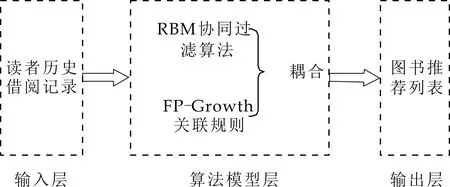
图2 图书推荐模型框架
FP-Growth关联规则不需要用户的评分作为输入,通过读者的借阅书籍之间的相关性,生成强关联规则,将相关性高的规则推荐给读者,具有高效性[18].协同过滤模型一般需要用户的评分数据作为输入,而一般仅有少部分读者会对图书进行评分,获得的反馈数据较少,导致数据稀疏,因而难以实现图书的精准推荐.RBM模型可见层的输入为读者对图书的兴趣评分矩阵.读者的借阅记录包括图书属性、借阅时间、还书时间等信息,以借阅时间为主确定读者对图书的兴趣度,从而解决缺少评分数据而导致的数据稀疏问题[19].读者对图书的兴趣度I表示如下:
(8)
式(8)中:s和l分别为读者所有借阅记录中最短和最长的借阅时长,t为某本图书被借阅时长.当t≤s时,t的取值为s;当t≥l时,t的取值为l.由于图书的评分值取值范围为1~5,因此按照式(9)对兴趣度I进行转换.
(9)
首先,计算出读者对图书的兴趣度I,进而将其值转换成1~5的兴趣度W,从而得到读者和借阅图书的二维兴趣度矩阵.最终以兴趣度矩阵作为RBM模型的输入,得到RBM模型输出的评分结果.
融合FP-Growth和RBM的图书推荐模型将FP-Growth关联规则和RBM协同过滤模型产生的结果以耦合公式进行耦合,得到最终的图书评分,从而实现图书推荐.耦合公式如式(10)所示.
R=α×FP+(1-α)×RBM
(10)
式(10)中:R表示最终的图书评分,RBM表示RBM协同过滤模型的输出结果,FP表示FP-Growth的置信度.α为权重,可根据推荐结果调整α.
3 实验结果与分析
实验平台为Windows7操作系统,CPU为Intel(R)Core(TM)i5-5200U,4GB内存,利用MATLAB10.0软件进行仿真实验.实验选取某高校图书馆2014~2016年的图书借阅数据进行实验.图书借阅数据包含165万条借阅记录,涉及图书接近16万本,读者接近3万人.
本文通过FP-Growth产生强关联规则,然后训练RBM协同过滤模型得到评分结果,最后利用耦合公式得到最终的图书评分.将图书推荐评分按照从大到小进行排序,取排序列表的前10个作为图书推荐结果.针对图书预测评分,采用平均绝对误差MAE进行评估.TopN的推荐结果一般采用准确率precision、召回率recall和F值进行评价,其分别定义为:
(11)
(12)
(13)
(14)
式(12)~(13)中:Hu表示用户u的真实借阅集合,Ku表示推荐书籍.
由于本文算法是将两种算法以一定的比例权重进行结合,因此实验将对比不同的权重α对最终模型的影响,从而确定最优的α以融合FP-Growth和RBM模型.将权重α分别设置为0.01、0.05、0.1、0.15、0.20,验证其对本文模型准确率、召回率、F值的影响如图3所示.
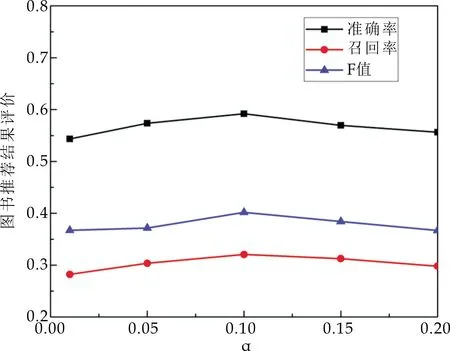
图3 权重α对图书推荐结果的影响
由图3可知,随着权重α从小到大,准确率、召回率和F值均呈现由增递减的过程.在α=0.1时,各个评价指标达到峰值,模型最优.针对本文模型预测的图书评分,权重α对MAE平均绝对误差的影响如图4所示.
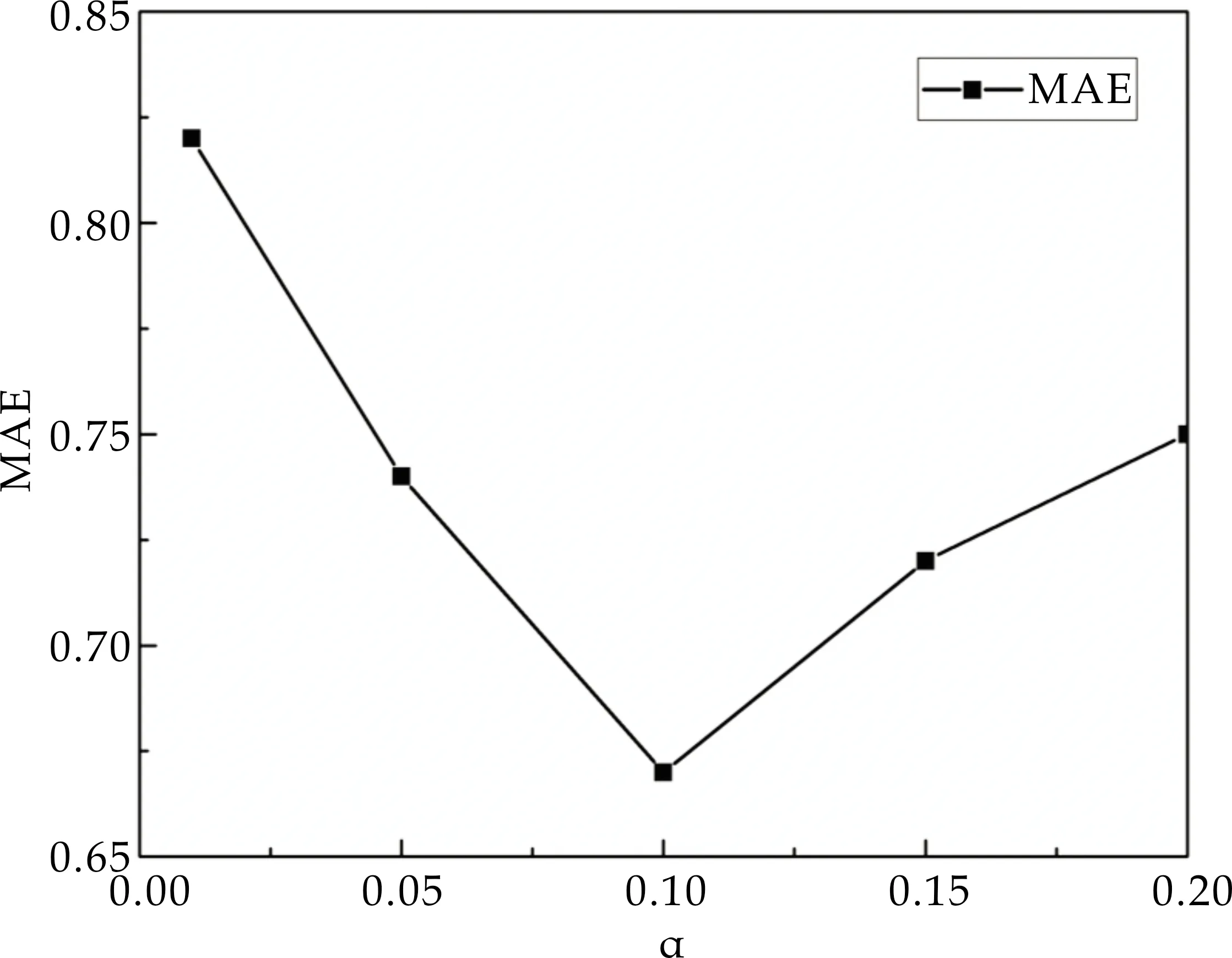
图4 权重α对MAE的影响
由图4可知,权重α同样在0.1处取得最好的效果,对应的平均绝对误差MAE值为0.67.由此综合图3和图4的实验结果,α=0.1时模型取得最优结果.因此,在确定权重α取0.1的情况下,将本文算法同FP-Growth关联规则和RBM受限玻尔兹曼机模型进行TOPN图书推荐结果对比,对比结果如表3所示.

表3 3种推荐算法的评价结果
由表3可知,本文算法在各项指标上均取得最高值,表示图书推荐结果与实际真实读者借阅的图书列表最为接近,其次是RBM模型,最后是FP-Growth关联规则.相比于单一的FP-Growth和RBM模型,本文的融合模型在准确率、召回率、F值上均有明显的提高.本文算法相比RBM协同过滤模型准确率提高了7.58%,召回率提高了2.54%,F值提高3.46%,说明本文算法能够更加准确的将图书推荐给读者.
4 结论
为了促进图书馆的智能化发展,本文致力于为读者提供高质量的图书推荐服务,将FP-Growth关联规则和RBM协同过滤进行组合,相比单一模型,更能挖掘借阅信息的深层特征.实验结果表明本文模型的图书推荐结果最好,相比FP-Growth和RBM,其准确率分别提高15.63%和7.58%,召回率分别提高4.12%和2.54%,F值分别提高8.08%和3.46%.因此,本文提出的模型能够更加精准的将图书推荐给读者,有效地提高了图书个性化推荐的准确度,能够为图书馆的智能服务提供技术支持.
