基于YOLO-GT网络的零售商品目标检测方法
2021-07-14周可鑫左云波谷玉海朱腾腾卞景艺
周可鑫,左云波,谷玉海,朱腾腾,卞景艺
(北京信息科技大学 现代测控技术教育部重点实验室,北京 100192)
随着经济水平和互联网技术的不断发展,人们的消费观念也随之在发生变化。从传统的线下消费到线上的网店消费,再到现在逐渐起步的线下新零售方式,人们不仅重视线上消费的便利,还重视线下消费的体验[1]。因此,对于传统线下消费场所来说,从商品的供应到商品流通的各个环节都急需升级改造,来满足顾客们的消费体验。其中,商品结算环节是线下消费过程中最重要的一环,传统的结算方式还是以人工为主,由收银员一步一步完成商品的清点和结算工作,效率非常低,尤其在节假日,顾客会花费大量时间用于排队结算,这大大影响了顾客的消费体验。因此,提出一种能满足自动清点,实时结算,方便部署且具有很高的应用价值以及学术价值[2]的零售商品检测方法尤为重要。基于图像识别检测的无人结算是无人结算中的一种重要技术方法。
图像的目标检测是计算机视觉领域的一个重要分支,其目的是检测出图片上的所有目标的类别信息以及位置信息[3]。2012年ImageNet大赛之后,深度神经网络得到了飞速发展,其中最具代表的就是卷积神经网络的快速发展,已经广泛应用到了目标检测领域中。目前,基于深度学习的目标检测方法主要有两大类,一类是基于提取候选框的两阶段检测算法,代表有:R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]等。此类算法在工作时首先会生成一系列的候选框,之后根据候选框完成相应的分类识别工作。这些算法的优点是检测精度高,缺点是检测速度较慢,普遍不满足实时检测的需求。另外一类是基于回归问题的单阶段检测算法,代表有:YOLOv1[7]、YOLOv2[8]、YOLOv3[9]算法以及SSD系列算法[10]。此类算法检测速度非常快,但是精度低。目前,检测性能最优的算法是由Alex等在2020CVPR会议上提出的YOLOv4算法,与YOLOv3相比,YOLOv4算法将COCO数据集的检测精度提高了10%,速度提升了12%[11]。近几年,学者们还致力于研究在移动端如手机和嵌入式平台运行的目标检测网络,这一类网络普遍体积较轻,且性能良好,部署方便。这类网络结构代表有:MobileNetV1[12]、MobileNetV2[13]、Mobile-NetV3[14]、ShuffleNetV1[15]、ShuffleNetV2[16]等。由于这类网络可以部署灵活,使用方便,因此这类算法是目前目标检测领域研究的重点。
在前人的研究基础上,本文提出一种改进的YOLO-GT目标检测算法,部署在Jetson nano核心板上用于零售商品RPC数据集目标检测。YOLOv3-Tiny是YOLOv3的简化版,其结构轻便,可部署在嵌入式平台工作,运行速度与YOLOv3相比要快得多,但缺点是精度低,尤其是对于小目标物体检测来说效果更差。借鉴特征金字塔(FPN)[17]的思想,将YOLOv3-Tiny网络的浅层信息与深层信息充分融合,将2个预测尺度变为3个预测尺度,增强对小目标检测的能力。此外,还借鉴了华为公司在2020年CVPR会议提出的线性扩展卷积层(Ghostmodule)[18]的思想对网络中的卷积层进行优化,提高网络的计算速度,减少网络在工作时所耗费的资源,在已经增加网络层数的情况下,保证检测时间不受太大影响。同时,对于激活函数进行更新,利用Mish[19]激活函数替代原先的Leaky Relu和ReLu激活函数,进一步优化提升网络的非线性拟合能力。最后,重新根据数据集优化先验框的数目和尺寸,提升网络在预测时的检测精度和速度。将改进的YOLOv3-Tiny网络命名为YOLO-GT。经过实验,对于同一商品数据集YOLO-GT与YOLOv3-Tiny相比,mAP提升了1.84%。检测单张图片速度提升464 ms。与原YOLOv3-Tiny网络相比性能得到提升,并且满足无人结算的使用要求。
1 YOLOv3-Tiny算法
1.1 YOLOv3-Tiny网络结构
基于深度学习的目标检测网络主要由3个部分组成,首先是用于特征提取的主干网络(Back-Bones)部分,其次是用于特征融合的分析网络部分(Neck),最后是用于结果预测的部分(Heads)。在YOLOv3-Tiny中,用于特征提取的网络由7个3×3的卷积层以及6个步长为2的池化层组成[20]。特征融合部分依然采用YOLOv3的思想,借鉴FPN思想,将网络浅层信息与深层信息融合。实现了2个尺度(13×13,26×26)的预测,保证了对小目标物体检测的能力。同时,每个尺度依然分配3个先验框(anchor box),可实现多目标检测,不仅加快模型收敛的速度,还保证了预测精度。预测部分与YOLOv3也相同,由YOLO层完成。YOLO层之前的卷积层的卷积核个数由类别数确定,计算公式为:

YOLOv3-Tiny的结构如图1所示。

图1 YOLOv3-Tiny网络结构图
1.2 YOLOv3-Tiny损失函数
YOLOv3-Tiny的损失函数依然延续整个YOLO系列算法的思想,由3个部分组成。分别是定位损失,分类损失以及置信度损失[21]。网络训练时,YOLO的每个单元格会预测多个边界框,最终只选择与目标框(ground truth)目标具有最高IOU的那个框作为预测框(bounding box)。YOLOv3-Tiny使用预测值和目标框之间的误差平方求和来计算损失。每个目标框的目标仅仅与一个先验框相关联。如果一个目标框的目标没有分配先验框,则不会导致分类损失和定位损失,只会拥有置信度损失。YOLOv3-Tiny的损失函数计算公式为:
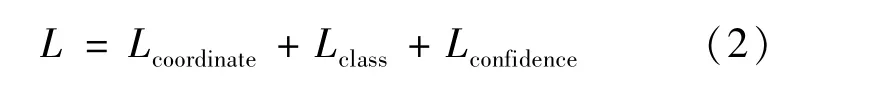
1.2.1 定位损失
YOLOv3-Tiny相比于前几个版本的YOLO算法,在定位损失计算上有所不同。YOLOv3-Tiny的预测框(bounding box)生成与先验框(anchor box)有关。网络在生成预测框时,不再直接预测预测框的具体尺寸,而是首先预测出预测框与先验框相比的宽高偏移值(tw,th)以及相对单元格的中心坐标的偏移值(tx,ty),再经过计算得到具体的预测边界框尺寸,如图2所示。
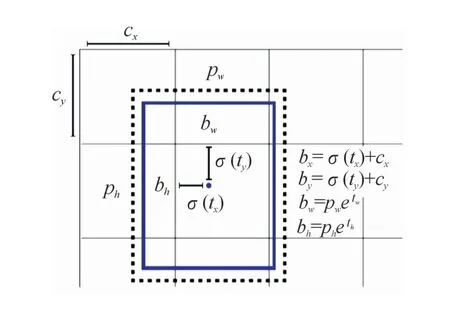
图2 先验框与预测框关系示意图
图中的虚线框为先验框,实线框为预测框。其中pw和ph为先验框的宽高尺寸,bw和bh为预测框的具体宽高尺寸,由偏移值和先验框的尺寸计算得到。cx和cy为单元格左上角点相对于整张图片的坐标值。σ()为引用的Sigmoid函数,目的是将偏移值tx、ty压缩到(0,1)之间,保证模型可以正常收敛。bx和by为计算得到的边界框具体的中心点坐标。由于网络预测出的是边界框的各项偏移值,因此计算定位损失主要是以偏移值为主,式(3)为计算定位损失的公式:
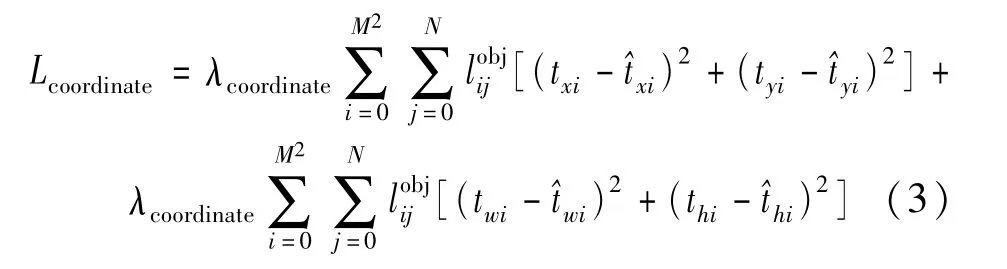
式中:txi、tyi、twi、thi为预测框的中心点坐标偏移值以及宽高偏移值;为目标框的中心点偏移值以及宽高偏移值;M为单元格数目;N为每个单元格预测预测框的数目;代表目标性,当检测目标的中点落入第i个单元格中的第j个预测框时取1,否则取0;λcoordinate为2部分损失各自所占权重大小。
1.2.2 分类损失
YOLOv3-Tiny网络在训练时,利用二元交叉熵损失作为分类损失。摒弃了softmax分类器,将分类问题转化成了回归问题,可实现多目标分类,分类损失计算公式为:

式中:M为单元格数目;代表目标性,当第i个单元格包含有目标中心时,取1,反之取0;(pi(c)-(c))2为计算所得的条件类别概率的平方误差;pi(c)为预测到的目标属于类别c的概率;为真实的条件类别概率。
1.2.3 置信度损失
若预测框中包含有检测目标,置信度损失为:

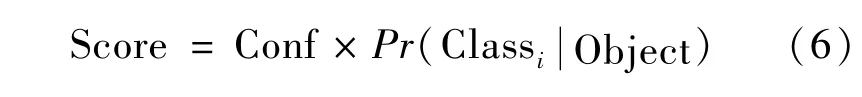
式中:Conf表示预测框的置信度;表示单元格内有目标,且目标属于类别i的条件概率。置信度分数表示预测框与目标的匹配程度。当预测框中不包含检测目标时,同样需要计算置信度损失,计算公式为:

在实际网络训练过程中,大部分的预测框是不包含任何目标的,如果不加处理直接计算,会导致类不平衡的问题,即在训练中频繁地在检测背景而不是目标,为了解决这一问题,需要引入损失因子λnoobj,借助损失因子将这部分的损失所占比重降低。因此,总的置信度损失为式(5)和式(7)之和:

2 YOLO-GT网络
综合考虑原YOLOv3-Tiny在识别时的各种问题,从改变网络结构以及优化训练方案2个方向出发,对YOLOv3-Tiny进行优化,提出YOLO-GT网络。
2.1 优化网络结构
2.1.1 线性扩展的卷积层
在各种CNN模型中,图像经过卷积层的处理会生成大量的特征图,这些生成的特征图并不都是独一无二的,大部分的特征图与特征图之间存在很大的相似性,我们将其称之为特征图的冗余[18]。特征图的冗余对于网络训练是非常重要的。图3为ResNet-50网络某一个卷积层输出的特征图可视化。

图3 ResNet-50特征图可视化
图3中圈出了3组相似的特征图。线性扩展卷积层思想着眼于卷积层生成的特征图冗余,提出在生成特征图时,一部分特征图代表着图像的本质特征,而另一部分特征则是与本质特征相似的冗余特征,在生成冗余特征时,无需按部就班借助大量卷积核生成,可用一系列简单的线性操作代替卷积核生成特征图冗余,这样做不仅可以加快网络的计算速度,还可以减轻网络的“重量”。因此可对普通卷积层进行修改,分2步生成完整的特征图,如图4所示。

图4 卷积层特征图
从图4(a)(b)中可看出,在普通卷积层的操作中,可直接生成特征图。而线性扩展卷积层是将卷积层分为了2个部分,首先是利用普通的少量卷积对输入图像进行操作,生成图像的本质特征。之后利用一系列的线性操作,通过本质特征生成更多的特征,这部分新生成的特征就是冗余特征,最后将2个部分特征堆叠,完成整个卷积操作。利用线性操作生成特征图这一步骤中,借鉴了深度可分离卷积的思想(depthwise separable convolution)[22],对每一个本质特征图都会进行线性操作,生成冗余特征图。整个过程可以表示为:

式中:f′表示少量的卷积核;Y′表示生成的本质特征图集合;y′i表示本质特征图集合中的第i个特征图;δi,j表示用于生成第j个冗余特征图的第j个线性计算公式;yi,j表示生成的冗余特征图集合。一共可以得到m·s个特征图。这里的线性操作选择3×3卷积操作。因为卷积是一个高效的计算方式,不仅涵盖了很多广泛使用的线性计算,而且硬件对于卷积也提供了很好的支持。使用线性扩展卷积层思想的卷积层,能有效降低卷积计算的成本,加快网络的计算时间。借助线性扩展卷积层的思想,对YOLOv3-Tiny主干网络中的卷积层进行优化,使得主干网络变得轻量化的同时,提升网络提取图片特征信息的速度。
2.1.2 特征融合优化
在特征融合优化方面,依然借助FPN的思想,充分利用网络的浅层信息和深层信息,采用上采样的方式融合网络浅层特征和深层特征,得到不同尺度的特征预测图。具体操作是,将网络的第15层输出特征与第48层输出特征融合,将网络的第17层输出特征与第37层特征融合,使得原2个预测尺度的网络变为3个预测尺度网络,增强了网络对于小目标商品的检测能力。网络层数虽然较之前更深了,但是上述卷积层的优化正好弥补了这一部分改变可能带来的负面作用,使得网络变得更加轻便,更加紧凑。优化网络结构得到的YOLO-GT网络结构如图5所示。

图5 YOLO-GT网络结构图
2.2 优化训练方案
2.2.1 Mish激活函数的使用
YOLOv3-Tiny的激活函数选择的是ReLu和Leaky ReLu。尽管这2个激活函数已经被广泛应用到深度学习领域,甚至成为激活函数的标准选择,但是在实际使用的过程中,还是有一些无法忽略的缺点。如图6所示,Relu在x>0的区域是正比例曲线,避免了梯度饱和以及梯度爆炸的情况发生,但是在x<0的区域,Relu将所有的值都置为0。在网络实际运行过程中,x小于0时对应的梯度也小于0,导致后续神经元的梯度都为0,造成“神经元坏死”现象,影响网络的训练测试效果。此外,ReLu不是0均值输出,会造成偏置现象,对数据的分布变动影响较大。

图6 ReLU激活函数曲线
如图7所示的Leaky ReLu弥补了ReLu的不足,用一个非常小斜率的正比例函数处理x<0情况的值,避免了“神经元坏死”的现象发生,使得ReLu在负区域以激活替代之前的置0,保留部分x<0的信息,使得网络在训练阶段更加稳定。

图7 LeakyReLU函数曲线
选择Mish激活函数替换原有的Relu以及Leaky Relu。Mish激活函数的公式为:

式(11)为目标函数,由相应样本的隶属度以及该样本到各个聚类中心的距离相乘得到。Mish是一个非单调光滑激活函数,同时继承了ReLu和Leaky ReLu的下有界上无界的优点,产生很强正则化效果的同时,又能避免发生梯度饱和和梯度消失的情况。另外,对于负区域,Mish用一条光滑曲线替换了Leaky ReLu的正比例曲线,提高了表达能力以及梯度流,同时非单调特性使得小的负输入成为小的负输出。此外,学者们通过大量实验也证明了光滑的激活函数会使得网络获得更好的信息,从而可以提高准确性和泛化能力。Mish在深度网络中的表现要优于ReLu和Leaky ReLu。因此,本文选择Mish作为YOLO-GT的激活函数,其曲线如图8所示。

图8 Mish激活函数曲线
2.2.2 优化锚框数目及尺寸
YOLOv3-Tiny根据COCO数据集,利用Kmeans算法得到9个先验框的具体尺寸。这里采用模糊C均值(FCM)聚类算法,以实验使用的RPC零售商品数据集为准来重新获取先验框的尺寸。FCM不同于K-means,它是以模糊概念为核心思想,基于目标函数,利用每个样本点属于某一类别的隶属度及距离各聚类中心的距离来确定这个样本点具体属于哪一类。FCM聚类算法的目标函数以及约束条件为:

式中:c代表想要得到的聚类个数;n代表数据集中样本点个数;表示样本j属于类别i的隶属度,m为隶属度因子。式(12)为约束条件,即所有样本点的隶属度之和为1。当目标函数在约束条件下取得极小值点或者在一定范围内微小变化时,我们就认为此时的聚类中心为迭代出来的最优聚类中心,因此需要分别对目标函数中的umij以及c求导,令其导数为0,这样就可以分别求出二者的迭代表达式,结果为:
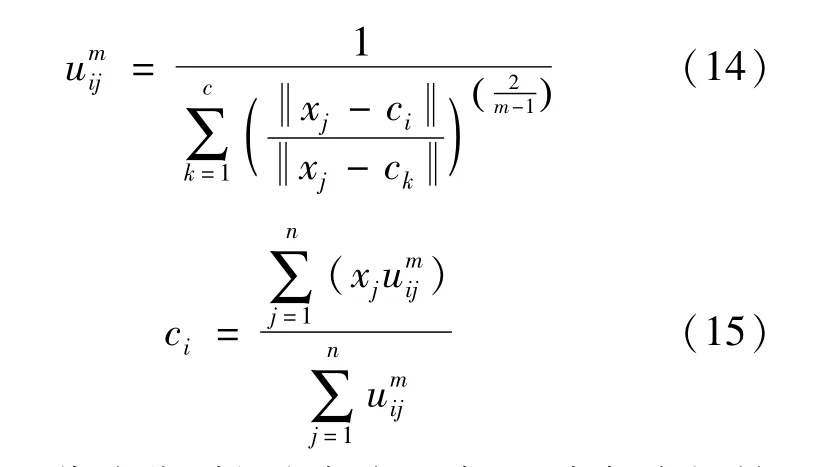
步骤1根据RPC数据集的标注信息初始化9个anchor box。
步骤2将聚类中心信息代入到式(14),迭代出隶属度数值。
步骤3 将得到的和c代入到式(12)得到新的目标函数值,与上一次的目标函数值比较,若变化范围在一定阈值内,确定此时的聚类中心为最优聚类中心即所需最优的anchor box,否则,进行步骤4。
步骤4利用式(15)迭代出新的聚类中心,返回步骤2。
经过FCM聚类算法重新得到anchor box的具体尺寸为:[49,45],[40,70],[79,50],[62,72],[51,127],[82,87],[127,72],[105,115],[147,150]。
3 实验
3.1 RPC零售商品数据集
实验采用旷视公司提供的RPC零售商品开源数据集,共200类商品目标。其中训练集共有图片53 736张,测试集共有图片24 000张,图片像素大小为1 830×1 830。图片均采集自真实结算场景,满足实验要求。使用前,将RPC零售商品数据集的格式统一转换成为供darknet框架使用的VOC格式,每一张样本图片都有一个对应的拥有该样本图片标注信息的xml文件,再经过进一步转换,将xml格式标注文件转化为txt格式标注文件,完成数据集的准备工作。
3.2 网络训练
YOLO-GT网络初始化设置信息为:将Batch和subdivisions设置为64和16,其中,Batch是指网络经过训练Batch张图片后更新一次权重,subdivisions是指,网络每组训练subdivisions张图片。初始学习率设置为0.001,其决定网络模型的参数更新的幅度大小。迭代次数设置为50 000,每经过45 000和48 000次迭代后更改学习率,每次更改的学习率较上次相比缩小10倍。具体的网络训练环境如表1所示。

表1 网络训练环境
利用RPC开源数据集,同时对YOLO-GT网络与YOLOv3-Tiny网络进行训练,得到的训练损失收敛图如图9所示,2种网络单次运行的计算次数如表2所示,工作时占用的空件大小如表3所示。

表2 计算次数

表3 占用空间大小

图9 YOLOv3-Tiny与YOLO-GT网络训练损失收敛图
从图9(a)(b)中可以看出,YOLO-GT网络训练过程比YOLOv3-Tiny网络稳定,且收敛速度更快。最终YOLO-GT网络的损失值收敛到0.6左右,YOLOv3-Tiny网络损失值收敛到0.8左右,满足训练停止条件,证明设置训练次数为50 000是合理的。
从表2中可以看出,改进后的网络单次运行时的计算量比原网络减少2.342 BFLops,这得益于对卷积层的优化,较少的计算量保证了网络提取图片特征的速度得到了提升,同时,从表3可以看出,YOLO-GT工作时占用的空间大小约为YOLOv3-Tiny的1/4,大大减少了对于资源的占用,更易于部署运行在嵌入式平台或其他移动端。
3.3 网络测试及结果对比分析
将训练好的网络模型移植到Jetson Nano核心板上,利用RPC数据集中的测试集部分对各网络模型进行测试,选择平均检测准确率(mAP)和召回率(Recall)以及网络检测时间(ms)作为评价指标。其中平均检测准确率是准确率(AP)的平均值,准确率指的是预测正确的结果占总样本的百分比。平均检测准确率及准确率的计算公式为[23]:
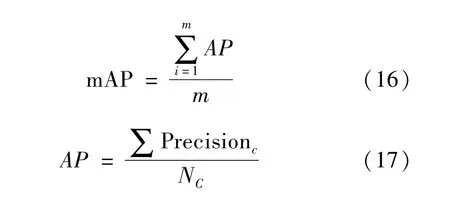
式中:m为类别总数;Precisionc为类别c的精确率之和;Nc为包含类别c的图片之和。Precisionc是指在被所有预测为类别c的样本中实际为样本c的概率,计算公式为:

召回率(Recall)是指实际为正的样本被预测为正样本的概率。在这里是指所有被正确检测出的类别c个数占类别c样本总个数的比例,计算公式为:

式中:N(True)c代表正确检测出类别c的样本数目;N(True)c代表类别c样本集中没有被检测出的数目。
网络在训练的过程中,每经过4次epoch对测试集进行一次检测,并记录检测结果mAP。其中1次epoch是指网络对数据集进行一次完整的训练。2个网络检测测试集的mAP变化如图10所示。
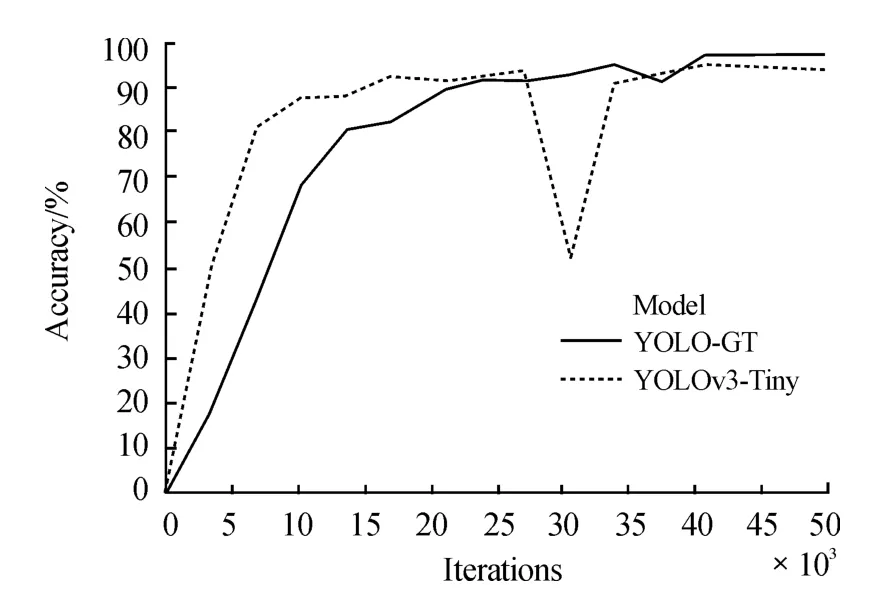
图10 mAP变化曲线
图10中的实线表示的是YOLO-GT网络的平均检测精度变化趋势,虚线表示的是YOLOv3-Tiny网络的平均检测精度变化趋势。从图中可以看到,在前20 000次左右的训练迭代中,YOLOv3-Tiny对于测试集的检测精度要比改进后的网络高。但是之后YOLOv3-Tiny网络的检测精度突然变差,从93%突然降到了52%。而YOLO-GT的检测精度一直在平稳上升,在经过25 000次左右迭代后平均检测精度超过了YOLOv3-Tiny网络。最终YOLOv3-Tiny的平均检测精度稳定在95%左右,YOLO-GT的平均检测精度稳定在97%左右。最终选择二者最佳检测精度作为最终结果记录下来。
实验时,还选择引入YOLO的其他版本Tiny网络进行训练测试,得到各自最优的检测精度以及召回率,结果如表4所示。

表4 不同网络对于RPC数据集的检测结果%
从表中4中的数据可以看出,YOLO-GT的平均检测精度与YOLOv3-Tiny相比,增长了1.84个百分点,与YOLOv2-Tiny相比,增长了8.62个百分点,与Tiny-YOLO相比,增长了36.35个百分点。召回率方面,YOLO-GT与YOLOv3-Tiny相比增长了2.08个百分点,与YOLOv2-Tiny相比,增长了7.55个百分点,与Tiny-YOLO相比,增长了37.4个百分点。从综合比较结果来看,YOLO-GT具有较高的检测性能,提升了原YOLOv3-Tiny网络的检测精度,并且通过与其他版本的Tiny网络比较优势更为明显,准确率和召回率均已经超过了95%,满足RPC目标检测的基本要求。其次,对各网络对于每张图片的平均检测时间进行了记录,结果如表5所示。

表5 不同网络对于RPC数据集的检测速度
从表5中可以看出,YOLO-GT的检测速度为342.67 ms,与YOLOv3-Tiny相比提升469.56 ms,约57.81%。得益于对卷积层的优化,网络在检测时速度得到了很大提升,更容易满足实时检测的使用需求。
综合以上所得的性能指标信息,可以看出改进后的YOLO-GT提升检测速度的同时,准确率也有小幅度提升。同时,YOLO-GT自身轻便,很容易部署在嵌入式平台或其他移动端平台,方便使用。从各类数值分析可以得出结论,优化改进得到的新目标检测网络YOLO-GT网络在计算速度,检测速度,平均准确率,召回率等方面都有所提升,单张检测时间342.67 ms证明可实现实时RPC目标检测,具有良好的性能。接下来将通过实际检测场景对比进一步说明YOLO-GT网络的高性能。
3.4 实景检测
利用真实场景拍到的图片数据对网络进行测试。如图11所示,共列举出来了4种检测对比图,其中左侧为YOLOv3-Tiny的检测图,右侧为YOLO-GT的检测图。前2组为少量商品的检测结果图,从图中可以看到,YOLOv3-Tiny对小目标商品的检测效果较差,出现了漏检的现象。此外,商品之间间距较小时,YOLOv3-Tiny的检测准确率也偏低,漏检现象更为明显。作为对比,YOLO-GT对于小目标商品检测效果较好,同时在商品间距变小时,依然表现出了较高的检测准确率。后2组为大数量商品场景的检测结果图,从图中可以看出YOLOv3-Tiny漏检现象更为明显,而且还出现了错检现象。YOLO-GT网络在大数量商品场景下表现更为优越,即使商品数量多,彼此间隔小,依然可以全部正确检测出来。通过综合分析可以得出结论,改进得到YOLO-GT网络的检测性能优于YOLOv3-Tiny,尤其是对于小目标商品检测以及大数量商品检测,同时,YOLO-GT的漏检率和错检率都远远低于YOLOv3-Tiny。YOLO-GT表现出较高的检测性能,检测速度和检测准确率均满足使用要求。

图11 YOLOv3-Tiny与YOLO-GT检测图
4 结论
以YOLOv3-Tiny网络为基础进行优化,提出一种用于零售商品RPC自动结算场景的新的目标检测网络YOLO-GT。YOLO-GT主要对原网络的卷积层以及特征融合方式进行了线性扩展与FPN融合优化,利用Mish函数优化激活函数以及FCM优化先验框的尺寸和数目,保证网络变得轻便的同时准确率也可以得到小幅度提高。最终,利用旷视RPC零售商品数据集在嵌入式平台Jetson Nano进行实验,实验结果表明YOLO-GT对于零售商品数据集的mAP与YOLOv3-Tiny相比提高1.84%,速度提高57.81%。同时,利用实景数据进行检测,与YOLOv3-Tiny相比降低了漏检率和错检率。对于零售商品而言,YOLO-GT的检测效果更佳,满足无人结算的使用要求,具有很强的应用价值。
