空间站有效载荷预测性维护支持系统设计
2021-07-09施建明王功王伟李绪志
施建明王 功王 伟李绪志
(中国科学院空间应用工程与技术中心,北京 100094)
1 引言
空间站空间应用系统有效载荷设备包括信息管理、供配电、热控、氮气供应等共用支持设备、空间科学实验和技术试验机柜、舱内外独立载荷等。在空间站运营期,这些设施、设备长期运行,需要定期在轨维护、维修及系统升级。空间站有效载荷维修保障资源有限,修复性维修和定期维修精准性低、资源代价大,难以满足空间站运行安全性、可靠性要求。预测性维护对设备进行状态监测、持续对监测数据进行分析计算、评判设备的健康状态、预测健康趋势,为有效载荷制定更合理的维护维修计划和备品备件上行方案。
NASA针对国际空间站任务开展了集成系统健康管理(Integrated System Health Management,ISHM)技术研究,并开发了状态监测工具软件,用于航天飞机、ISS控制力矩陀螺、ISS主动热控系统的状态监测任务。软件的核心算法是K最近邻(Knearest Neighbor,KNN)和聚类(Clustering),这些算法和工具在航天器健康监测上有较成功的应用。借鉴NASA的经验,余晟等提出一种基于推演式聚类学习算法的卫星健康状态监视系统,并通过热控分系统的测试数据对该系统的有效性进行验证,能较好地完成状态识别与评估。
有效载荷方面,NASA在科学实验柜接口定义文档中对有效载荷的健康和状态数据的定义、数据传输、处理、显示等进行了规定。中国空间站有效载荷设计了一定的在轨故障诊断功能,并将故障事件和传感器参数等数据下行至地面。同时,也开展了预测及健康管理(Prognostic and Health Management,PHM)相关方法、算法研究与地面健康管理软件开发工作,通过制冷机在轨数据、热控子系统地面测试数据等进行了技术验证。
有效载荷产品种类较多,故障模式与机理复杂,需要采用不同算法处理大量的监测数据、训练故障诊断和预测模型。为提升算法、模型及业务程序的开发和集成效率,各有效载荷产品应统一开发范式,解决标准不统一、接口不匹配、数据不一致等问题。且预测性维护技术相关方法、理论研究成果急需工程化的软件和平台来承载,并通过实测数据来实现技术验证和迭代。为此,本文构建面向有效载荷的系统层预测性维护支持平台,对核心的自动辅助建模软件开展架构设计和基础开发工作,为后续持续扩展和优化打下基础。
2 预测性维护支持系统方案设计
有效载荷产品自身集成了一定的在轨故障自检测和诊断功能,对影响安全性和重要功能的异常状态进行实时检测,采用阈值判断的方式来实现,适用于故障需要立即响应的场景。预测性维护支持系统能充分利用地面的存储和计算资源,对有效载荷长期运行积累的大量数据开展分析,能完成在轨不便开展的趋势分析、多维监测数据联合分析以及复杂机器学习模型的训练、使用、评价与再训练等任务。经过实际数据充分验证的算法和模型,还能用于在轨故障检测功能和性能的升级。
空间站有效载荷在轨出现故障时,很多情况下无法通过自诊断功能独立确认要更换的目标部件,即在轨可更换单元(Orbital Replaceable Unit,ORU),而人工分析和排查往往费时费力。通过综合分析有效载荷监测数据,调用诊断模型,结合推理逻辑,能实现故障的快速准确定位,这是预测性维护支持系统的智能诊断功能。有效载荷包含有退化特征的产品,例如泵组、过滤器、电池、制冷机等,建立性能退化模型,持续跟踪退化趋势,预测剩余寿命,为备件保障和维修准备提供预测性指示。此外,还需定期对设备、分系统、系统开展基于监测数据的健康评估,让地面人员能全面掌握有效载荷健康动态。图1为空间站有效载荷预测性维护支持系统的方案设计图,由数据库、自动辅助建模软件、计算平台、Web UI程序4个部分组成。
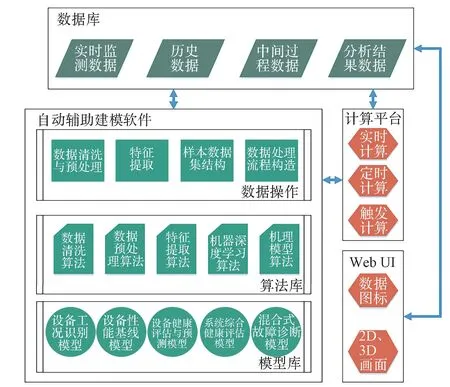
图1 预测性维护支持系统方案Fig.1 Scheme of the predictive maintenance support system
2.1 数据库
空间站有效载荷数据量大、来源多,为充分挖掘数据中对预测性维护有指导意义的信息,应统一规划数据源。根据数据来源不同,分为研制阶段产生的数据与运行阶段产生的数据。以运行阶段的数据为主要数据来源,根据需要提取研制阶段的数据辅助分析。数据类型分为结构化数据和非结构化数据,针对不同数据类型选择合适的数据库。有效载荷监测数据以时序数据为主,在工业大数据、工业互联网领域,InfluxDB、OpenTSDB等是常用的开源时序数据库软件,可用于存储与管理有效载荷状态监测数据。表1列出了预测性维护支持系统的数据源及相应的数据库产品选型。
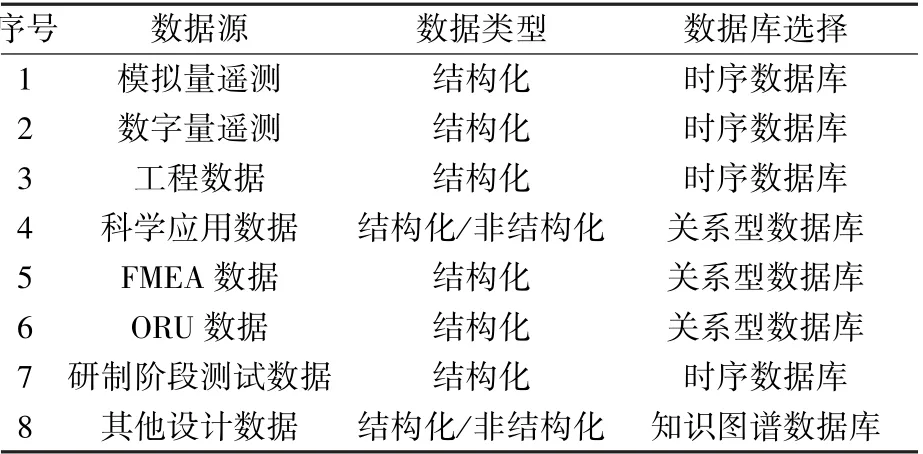
表1 预测性维护支持系统数据源Table 1 Data sources of PMSS
有效载荷运行状态监测数据以遥测、工程数据(下行的状态监测数据)为主,包含了在轨诊断(例如机内测试)给出的故障或异常状态的指示量,在排除错误诊断的前提下,这些指示量可为数据标记提供重要的参考。数据通过天地通讯链路下行至地面,地面控制中心进行通讯管控,地面数据中心进行数据管理,预测性维护支持系统作为地面系统的一部分,提供非紧急故障的诊断、健康状态长期跟踪和预测等服务,允许一定的时间延迟。因此,数据库可贴近业务端进行部署,以近实时的方式从数据中心获取所需的数据。
2.2 自动辅助建模软件
设计开发自动辅助建模软件是为提供统一的有效载荷故障诊断和预测建模平台,在此平台上,建模专家和领域专家协作开展建模工作,把概率统计、信号处理、机器学习等数据建模技术同有效载荷产品知识和故障机理紧密结合起来,并进行快速迭代、集成与扩展。建模流程如图2所示,具体步骤如下:
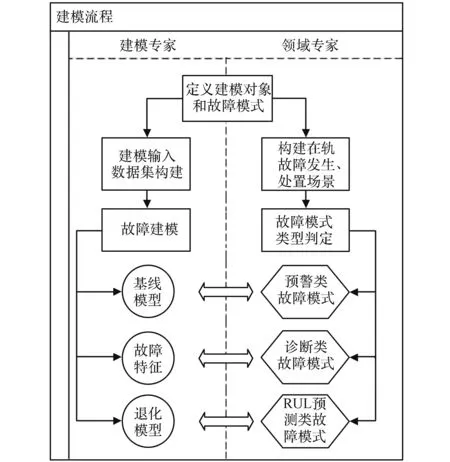
图2 PHM建模流程Fig.2 PHM modeling process
1)定义建模对象和故障模式。根据有效载荷产品组成和FMEA报告等,建模专家和领域专家共同梳理出模型清单;
2)构建故障模式发生和处置场景,为建模提供应用依据;
3)对故障模式类型进行判定,包括预警类、诊断类及RUL预测类;
4)基于模型清单,对每个模型建立所需的输入数据进行梳理,构建输入数据集;
5)建立故障模型,包括用于故障预警的基线模型、用于故障诊断的特征识别模型、用于RUL预测的退化模型。
空间站有效载荷产品类型多样、故障模式复杂、研制单位众多,不同故障诊断、预测算法和模型应能以标准接口进行集成,并以统一范式实现。自动辅助建模软件是预测性维护支持系统的核心部分,承载有效载荷数据智能分析、故障诊断与预测建模、模型优化及管理的功能,第3节将对辅助建模软件的设计进行详细论述。
2.3 计算平台
自动辅助建模软件生成的模型,由计算平台调用完成数据计算处理,并将结果输出,包括异常预警信号、故障诊断结果、指标预报或RUL预测值等信息。当数据量不大时,可在单台计算机或服务器上完成计算任务。随着数据量的增大,需要并行计算甚至分布式大数据计算平台,以提高计算速度,满足业务需求。
根据异常预警、故障诊断、预报预测等业务特点的要求,分别采用实时计算、触发计算、定时计算等策略来实现对数据的计算处理。
2.4 Web UI程序
界面程序将与状态监测和诊断相关的信息通过数据可视化的形式展示出来,包括基于2D、3D的设备画面展示、基于仪表盘或图表的数据展示等。UI界面显示出的诊断、预测、预报等信息,可支持地面人员开展维护维修决策活动。
基于Web技术开发后端程序包括:①构建SpringBoot后端框架;②编写数据库访问配置文件;③开发数据查询与写入程序。开发前端程序包括:①2D、3D显示图纸设计和代码开发;②对图元进行数据绑定配置,实现与后端测点的关联。数据库中的各类数据经由后端程序查询后,设置到前端图元、图标上,实现数据的实时呈现。
3 自动辅助建模软件设计
设计开放式、层次化、可扩展的软件架构,不同有效载荷产品研制方可在统一的架构上增量式开发算法和模型,汇聚成空间站有效载荷预测性维护的算法库和模型库。
3.1 层次化架构与软件包设计
自动辅助建模软件的层次化架构设计如图3所示,由接口层、特征层、算法层、模型层、应用层5个层级构成。
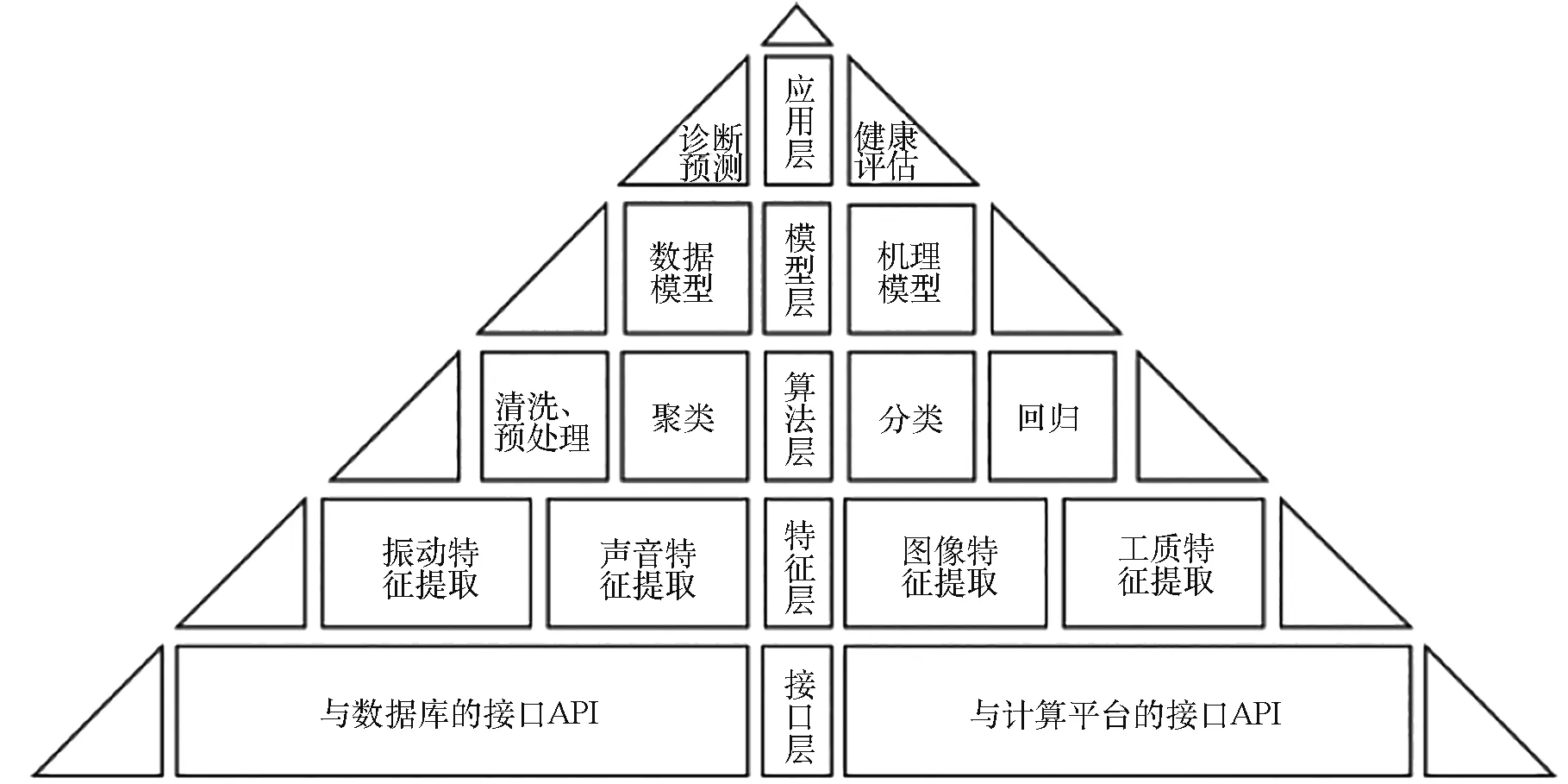
图3 自动辅助建模软件架构Fig.3 Architecture of the AAMS
基于图3所示的层次化架构,构建与架构一一匹配的软件包,由代表各层软件子包组成,程序文件分门别类地放置在设计好的路径下,方便函数的调用和类的实例化。程序集成、扩展和升级在软件包的统一管理下有序开展。由于涉及大量复杂的工程计算和智能建模,自动辅助建模软件可采用Matlab、Python等进行开发,利用已有的框架或工具来构建定制化的算法库和模型库,提高开发效率。图4所示的软件包是基于Matlab环境设计的,一级软件子包分为“+api”、“+features”、“+algorithms”、“+models”、“+app”,其中“+”不可或缺,其作用是将子包纳入可执行路径下。
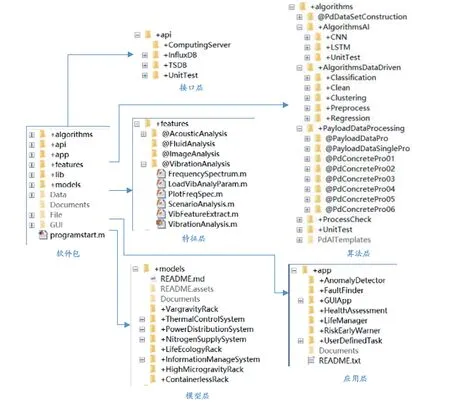
图4 自动辅助建模软件包组成Fig.4 The AAMS package
3.2 各层程序设计
3.2.1 接口层
接口层承载建模软件与外部的接口程序,包括与数据库的接口程序及与计算平台的接口程序。通过与数据库的接口,软件可对数据库进行读写操作,获取所需的数据,并将处理后的输出结果写入数据库。通过与计算平台的接口和外部计算程序进行交互,使用外部计算资源,或由外部计算程序调用内部的模型和算法。
在“+api”文件夹下建立相应数据库接口程序的二级子包,例如“+InfluxDB”、“+TSDB”等,包括数据库配置文件、配置文件解析程序、数据查询程序、数据写入程序等。
为便于开发人员调用建模软件包中的程序,在接口层提供相应的API(Application Programming Interface)。通过接口层,自动辅助建模软件方便集成到预测性维护支持系统中,或移植到已有的运维平台上去使用。
3.2.2 特征层
有些情况下,故障特征与原始监测数据无直接的关联,例如设备振动信号、声音信号、图像数据、工质理化特性等。需要采用特征提取程序将原始数据转化成相应的特征数据。
在建模软件中设计特征层,将可能用到的特征提取程序归于“+features”路径下。一般包括特征配置文件、配置文件解析程序、特征提取函数、特征提取脚本等。
通过特征提取出的中间数据可写入到数据库中,或保存在“+features”下的FeatureData路径下,便于统一管理。
3.2.3 算法层
在工业系统预测性维护场景中,数据驱动是当前的主流,在“+algorithms”算法包中,除了数据清洗、预处理、聚类、分类、回归等算法程序外,还有数据集构造、流程检查等辅助性程序。在运营阶段初期,大部分有效载荷处于正常状态,通过聚类算法或回归算法可学习健康基线,得到各种运行模式下的正常类簇或参数关联模型。通过类簇识别、偏移量计算能发现异常征兆。随着有效载荷出现退化或故障,提取特定窗口的多维监测数据用于构造数据集。通过回归算法能训练相应的预测模型,用于预测未来健康退化趋势和RUL;通过分类算法能训练故障特征识别模型,用于故障诊断。
为提高算法开发和使用算法分析数据的效率,需设计一种标准化同时又具有弹性的数据处理机制,包括标准化算法类设计、弹性数据处理模板和可追溯的算法比对机制。
1)标准化算法类设计。首先,设计7个算法父类,分别是数据清洗算法Cleaner、数据预处理算法Preprocessor、聚类算法Clusteringer、分类算法Classifier、回归算法Regressor、深度学习回归算法(Long Short Term Memory,LSTM)、深度学习分类算法(Convolutional Neural Network,CNN)。每个父类下继承了多个具体的算法子类,例如聚类下有Kmeans聚类、层次聚类、自组织映射等。其次,每个算法子类采用标准的框架设计,类的属性为算法参数,类方法主函数是数据处理流程,包括数据输入、算法参数设置文件导入、交叉验证数据集构造(必要时)、核心处理模块、结果整理和输出。
2)弹性数据处理模板。建模时可采用单一算法处理数据,也可采用多算法串接的方式处理数据,并有不同算法、不同算法参数设置比对的需求。为不重复编写算法代码,且能灵活配置算法和设置算法参数,采用数据和算法分离的策略模式及多算法串接的模板模式。串接多算法形成数据处理流程后,调用流程检查程序,确保所构造的流程符合数据分析处理的逻辑。
3)可追溯的算法对比机制。设计一种可追溯的比对机制,使得建模人员能快速完成模型批训练、批测试,并回看不同算法参数设置下的模型评分,自动导出最优的算法参数和模型。在标准算法类设计时考虑算法调参和比对问题,算法每次调用都会自动去读取相应的参数设置文件,通过记录每次参数设置及对应的评分来进行追踪。
3.2.4 模型层
辅助建模软件的模型层包括数据模型和机理模型。基于聚类、分类、回归等算法对数据进行处理所输出的模型即数据模型:聚类模型是聚类分析得到的类簇信息,包括类簇的中心、半径及其标记;分类模型是通过分类算法处理得到的模型,如决策树(Decision Tree,DT)分类模型、支持向量机(Support Vector Machine,SVM)分类模型、浅层神经网络(Neural Network,NN)分类模型、卷积神经网络CNN分类模型等;回归模型是通过回归算法得到的模型,如线性回归(Linear Regression,LNR)模型、非线性回归(Nonlinear Regression,NLR)模型、关联向量回归(Relevance Vector Regression,RVR)模型、序列到序列LSTM回归模型等。在“+models”下建立ModelLearned路径,将训练好的模型保存在该路径下,也可导出为标准数据格式的文件用于其他分析软件或平台。
与有效载荷产品层级一一对应,构建故障诊断和预测的机理模型。以有效载荷热控系统为例进行说明,“+models”下建立“+ThermalControlSystem”二级软件子包,所有热控系统相关的模型层程序文件均放置在该路径下。
首先,“+ThermalControlSystem”下建立@Component文件夹,在此文件夹中定义一个抽象的父类Component,在Component父类中定义热控系统及其部件的通用属性,例如名称(Name)、设计参数(Design Param)、输入数据(Input Data)、故障诊断和预测模型、诊断结果等属性,其中,诊断结果属性包含运行模式(Opt Mode)、健康基线(Base Line)、异常检测结果(Is Anormal)、故障模式(Fault Mode)、健康状态(Health Status)健康指标(Health Indices)等。
然后,构建热控系统模型子类包:@Thermal-ControlSystem、@Pumppackage、@Accumulator、@Pipeline、@Controller、@Filter、@Sensor等,涵盖热控的系统级模型和部件级模型。在子类方法中,编写诊断模型或预测模型的建模逻辑函数,该函数调用算法进行建模,或者从已训练好的模型库中导入模型,并对数据模型和产品的实际故障进行关联。例如,在@ThermalControlSystem子类文件夹下构建ThermalControlSystem子类,在该子类方法中定义用于构建热控系统健康状态识别所用聚类模型的函数,该函数的主要功能是调用聚类算法(需要时增加数据清洗、预处理算法)处理输入数据,得到聚类模型,并对设定的健康状态和类簇进行关联绑定。这样,实例化ThermalControlSystem子类后,就可以通过调用相应的方法来完成针对具体业务的建模任务。
3.2.5 应用层
应用层是软件的顶层,包括主程序及下属的异常检测、故障诊断、健康评估、健康指标合成、预测性分析等子程序。子程序各司其职,每个程序实现自己的单一职能。根据需求和场景的不同,预测性维护业务可对监测数据开展实时分析诊断,输出异常检测和故障诊断结果;可在发现指标异常偏离基线后,对指标进行预测,并对可能的风险进行预警;可定期开展健康状态评估;还可在健康状态发生变化时开展RUL预测等。建立以业务流为主线的主程序,并调用下属各子程序,应用层以类似于搭积木的方式灵活快速地搭建好特定的业务流程。
此外,还可开发图形用户界面应用(GUI App),便于建模人员、领域专家开展离线数据分析和建模,并对后台业务进行可视化的操控和实时分析结果查看。
4 开发与测试实例
4.1 采用策略模式分离数据和算法
在对产品状态监测数据进行处理时,经常会遇到需要对数据施加不同算法的情形。聚类(Clustering)分析常用来识别设备的工作状态,聚类算法有很多种,如Kmeans、Hierarchical Clustering(HC)、SOM(Self Organizing Map)等。在用聚类算法进行建模时,需要对比不同的算法,每种算法下面又有不同的算法参数需要设置。通过策略模式能将算法封装起来,用户可方便地选择或替换算法,而算法也独立于数据。图5为采用策略模式开发聚类算法的统一建模语言(Unified Modeling Language,UML)图。
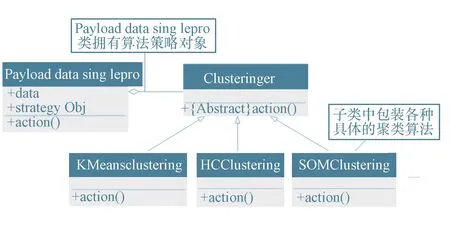
图5 策略模式分离算法和数据Fig.5 Separation between algorithm and data based on strategy pattern
各类之间通过如下的机制进行协作,以实现数据和算法的分离:
1)在PayloadDataSinglePro类对象中存放数据,而在Clusteringer子类对象中存放算法,PayloadDataSinglePro类的属性strategyObj指向具体的Clusteringer子类对象,可以对该属性的重新赋值来自由地更换算法;
2)PayloadDataSinglePro类对象把对具体的数据处理请求转交给Clusteringer子类对象;
3)当转交计算请求时,PayloadDataSinglePro类对象把自己作为一个参数传递给Clusteringer子类对象方法中action函数,从而使得子类对象拥有了计算所需要的数据。
4.2 结合策略模式和模板模式实现数据处理模板
当需要采用2个或2个以上算法串接来处理设备监测数据时,就需要构造一种既符合数据处理流程逻辑,又可灵活配置算法的数据处理模板。不论数据如何变化,也不论数据处理流程如何改变,封装好的算法类始终保持不变,只是每次处理所选的算法和算法组织顺序有所不同。
采用多算法来处理数据有一套固定的流程,全流程处理遵循数据清洗、数据预处理、机器学习3个骨干步骤,这3个骨干步骤是不能颠倒顺序的。另外根据数据处理目标的不同,数据处理流程有以下6种模板:①仅选择数据清洗步骤中的多个算法;②仅选择数据预处理步骤中的多个算法;③选择跨数据清洗、数据预处理2个步骤中的多个算法;④选择跨数据清洗、机器学习2个步骤中的多个算法;⑤选择数据预处理、机器学习2个步骤中的多个算法;⑥选择跨3个骨干步骤中的算法。这里假定机器学习算法一次处理只采用1种算法。
首先设计一个数据处理基类PayloadDataPro,将固定的处理步骤封装在PayloadDataPro的templateMethod方法中,然后设计6个数据处理子类PdConcretePro1~PdConcretePro6,与上述6种数据处理模板一一对应。为子类能够自由选择算法,在PayloadDataPro的属性中定义strategyObj,使得基类拥有策略对象,以聚类算法Clusteringer为例,该设计的UML如图6所示。PayloadDataPro类中的templateMethod要声明成封装的方法(Sealed),在基类中约定固定的数据处理流程,保证子类不会违反顺序,3个骨干步骤的方法要声明成抽象(Abstract)和访问受保护(Access=protected),以此固定接口且强制要求子类必须实现相应骨干步骤。PdConcretePro子类实现3个骨干步骤具体数据处理流程,方法声明为protected,以保证这些方法只能被内部的方法templateMethod调用。
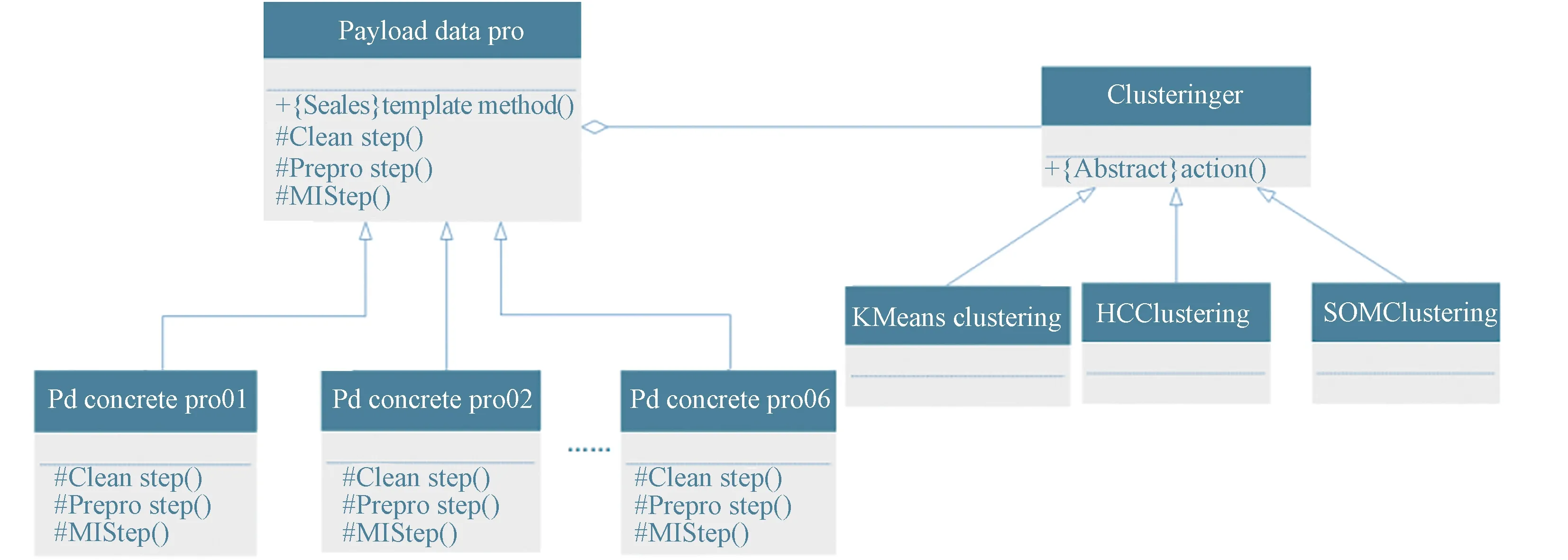
图6 结合策略模式与模板模式构建有效载荷数据处理流Fig.6 Payload data processing flow constructed by strategy pattern and template pattern
4.3 数据分析与建模测试
采用公开的燃料电池耐久性试验数据来测试自动辅助建模软件的可用性,电池堆的总输出电压Utot反映设备的性能或健康状态,随着时间积累,Utot呈现下降的趋势,燃料电池性能逐渐退化。主要开展以下2方面的测试:①对比KMeans算法和HCClustering算法,测试算法更换和调参模式;②先采用MidFilter中值滤波算法进行数据清洗,后采用Kmeans或HC聚类算法进行聚类,检验数据处理流程的设计。
采用4.1、4.2节中的开发策略,开发出算法类、数据处理类等程序,然后编写相应的测试脚本,对电池数据进行建模分析。以MidFilter+HC为例进行说明,如表2所示。

表2 数据分析与建模测试脚本Table 2 Testing script for data analysis and modeling
在执行聚类分析时,程序自动读取参数设置文件,实现不同参数下的模型训练,当需要更改算法时,只需要对测试脚本做简单的更改即可,例如将聚类算法改成Kmeans算法,将表2程序的第4行改为mlStrategy=MachineLearning.KMClustering()即可。
评分采取Calinski-Harabasz(CH)准则,CH指标通过计算类中各点与类中心的距离平方和来度量类内的紧密度,通过计算各类中心点与数据集中心点距离平方和来度量数据集的分离度,CH指标由分离度与紧密度的比值得到。CH越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果。
表3展示了聚类分析不同算法或算法组合和不同参数设置下的评分,其中采用中值滤波加Kmeans且分类数为4时得到的聚类模型最佳。
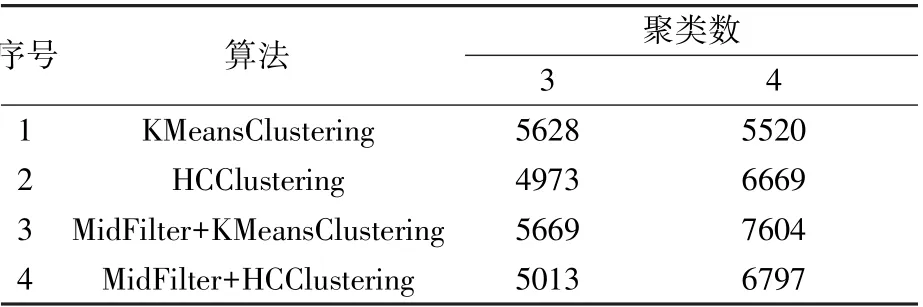
表3 聚类分析评分结果Table 3 Scores of data clustering with different algorithms
5 结论
本文提出了一种可行的预测性维护支持系统框架,设计了自动辅助建模软件架构,并进行了基础开发,解决了相关算法、模型和业务程序开发缺少统一标准的问题。已开发出算法库,建模人员无需重复编写算法代码即可快速完成常见数据驱动故障诊断和预测建模工作,能提高大量数据处理和建模时的效率。此外,通过外部接口定义和接口程序,自动辅助建模软件易于部署,与系统其他模块的集成也十分便利。
