鲁棒性协同过滤研究
2021-07-02易乔敏
易乔敏
(四川大学计算机学院,成都610065)
0 引言
大数据时代,推荐系统作为一种重要的信息过滤技术,在帮助用户快速发现自己感兴趣的内容上发挥了重要作用,因而被广泛部署到各种在线应用中。推荐系统旨在从用户的历史交互/反馈中捕捉用户的兴趣或偏好,并提供个性化推荐。例如,网易云音乐根据用户的听歌记录提供歌单推荐;微博根据用户的兴趣推荐相关的博主;淘宝根据用户的浏览足迹在用户主页展示其可能感兴趣的商品等。
在各种推荐系统中,协同过滤已经成为主流的推荐方法之一,其思想是相似的用户有相似的偏好,相似的商品具有相似的特征。典型的协同过滤方法主要包括3种类型:基于用户的协同过滤、基于商品的协同过滤和基于模型的协同过滤。为了提高协同过滤的性能,许多工作开始考虑辅助信息[8,21,32],如社交网络、商品标签,等等。尽管如此,大多数现有协同过滤方法仍依赖于一个潜在假设,即用户历史反馈可以真实有效地反映用户的兴趣或偏好。然而事实上,用户历史反馈往往是有噪音的,当大数据时代尤其如此。例如,用户在淘宝上的一次商品点击可能是一个随机行为导致的自然噪音,其不能代表用户的真实兴趣;豆瓣上某个用户对某部电影的评分可能因用户评分时的愉悦心情而高于其对电影本身的满意度,因此产生噪音评分。又如,某些电商利用画像注入攻击产生许多恶意噪音,以此操纵推荐系统来达成某些商业企图。恶意或非恶意噪音的存在使协同过滤方法难以准确地捕捉用户的真实偏好,当用户的历史交互发生改变时,缺乏鲁棒性的协同过滤方法难以产生稳定的推荐结果,甚至推荐性能显著降低。因此,如何从有噪音的用户反馈数据中有效捕捉用户的真实偏好,对提高推荐的鲁棒性至关重要。事实上,准确且鲁棒的个性化推荐一方面有利于提升用户对推荐结果的满意度和信任度,另一方面也有助于提升应用的用户粘性,带来经济利益。
1 鲁棒性协同过滤
根据Robust Statistics[1]对算法鲁棒性的定义,本文从三个层次来分析协同过滤算法的鲁棒性:
第一,鲁棒性协同过滤应该具有较高的推荐准确性。为了提高推荐性能,除了考虑用户的历史反馈数据,许多协同过滤推荐算法利用辅助信息或混合模型[2-4]来捕获用户偏好。诸如社交网络、用户/物品属性、知识图谱等辅助信息有助于学习更好的用户和商品表达以提升推荐性能;混合模型组合不同推荐模型的推荐结果,以集成的方式提升推荐准确性。
第二,鲁棒性协同过滤应该具有一定的处理用户反馈中自然噪音的能力。事实上,用户的交互行为或评分行为常常是不完美的,鲁棒性推荐要求推荐模型在面对有自然噪音的用户反馈时,能够在一定程度上保持推荐结果的准确性和稳定性。因此,鲁棒性协同过滤需要从噪音反馈中挖掘用户的真实偏好。
第三,鲁棒性协同过滤应该具有一定程度的抵抗恶意噪音的能力。受某些经济利益的驱动,一些恶意用户有目的地向推荐系统注入大量虚假用户画像,从而提升或降低某些物品被推荐的可能性[5]。然而,恶意用户的推荐目的往往不符合大多数其他用户的期望,故显著降低个性化推荐性能。防止恶意噪音对推荐系统产生灾难性的影响是鲁棒性推荐的一大挑战。
一些研究已经关注到推荐的鲁棒性问题[5-7,9-13]。早期工作[5-7,11-13]主要集中于研究推荐算法抵抗恶意噪音的能力。为了提高推荐系统对恶意攻击的鲁棒性,一些方法[5,12]通过分析真实用户与可能的恶意用户之间打分行为的差异识别恶意用户,从而提前过滤恶意用户或降低恶意用户的数据对模型学习的影响。文献[7]总结了八种不同的注入攻击策略和恶意噪音环境中鲁棒性协同过滤的三个方面的技术,包括攻击策略、探测策略和鲁棒性推荐算法。其中,鲁棒性推荐算法专注于对恶意噪音的探测和过滤,例如文献[12]通过交替进行聚类去噪和训练SVD两个过程,提高SVD的鲁棒性。此后,针对恶意噪音的鲁棒性推荐算法致力于控制恶意攻击的影响,因为直接过滤可能的噪音会同时消除一些真实的用户画像。近年来,基于神经网络的协同过滤方法被广泛研究,在自然噪音环境中,针对推荐系统的两大任务,即评分预测和Top-K推荐,一些研究者已经提出了不同的鲁棒性神经推荐模型。
2 鲁棒性协同过滤用于Top-K推荐
2.1 现有研究
在自然噪音环境下,鲁棒性Top-K推荐旨在从噪音交互中准确捕捉用户的真实兴趣或偏好,以产生准确且稳定的个性化Top-K推荐列表。现有鲁棒性Top-K协同过滤方法,其大致可分为两种类型。一种现有工作通过在训练过程中向训练数据或模型参数中注入额外噪音来提高推荐模型的鲁棒性[9,14-16],另一种现有工作则利用变分自编码器(VAE)等生成模型获得鲁棒的用户和商品嵌入以提高推荐模型的鲁棒性[17-19]。
基于噪音注入的方法包括两种类型。一种方法将降噪自编码器引入Top-K协同过滤。例如,根据降噪准则,CDAE[15]在模型学习时以一定概率对用户交互向量进行drop-out破坏,之后从破坏的用户交互向量中学习用户隐表示以重构原始交互向量;通过最小化重构误差,CDAE能够从破坏的用户交互向量中学习鲁棒的隐表示,从而具有一定的容噪能力。另一种方法引入对抗训练和对抗噪音提高模型的鲁棒性[10,18,20]。例如,文献[14]提出对抗个性化排名方法APR,该方法利用对抗训练在模型学习过程中为模型参数引入一定水平的对抗噪音,从而学习鲁棒的用户和商品表示,提高贝叶斯个性化排名方法的鲁棒性。由于基于神经网络的协同过滤算法优秀的推荐表现,文献[9]提出一个通用的对抗学习框架,致力于同时提高基于神经网络的推荐模型的Top-K推荐性能和鲁棒性。
然而,这两种基于噪音注入的方法仍有两个不足。第一,模型的鲁棒性依赖于一个先验确定的噪音注入水平,固定的噪音水平忽略了不同用户个性化的噪音分布;第二,基于对抗噪音的方法需要设置恰当的对抗噪音水平,从而平衡模型的推荐性能和鲁棒性,防止过强的对抗噪音降低模型的推荐表现。
近年来,由于变分自编码器强大的表示学习能力,一些工作提出基于变分自编码器的鲁棒性Top-K推荐模型[19,21]。例如,文献[19]提出一个推荐变分自编码器模型,简称RecVAE,该模型为变分自编码器的推断网络设计了一个新的网络结构,并结合降噪准则从用户的隐式反馈数据中捕捉用户偏好,大大提升了Top-K推荐的性能。这些研究也证明,变分自编码器能够很好地处理稀疏的用户交互向量。
对于基于变分自编码器的Top-K推荐方法的鲁棒性,本文从两个角度进行阐述。第一,变分自编码器基于用户历史交互为每个用户学习一个隐表示的高斯分布,该分布建模了用户交互数据的不确定性,其中高斯分布的方差刻画了用户个性化的噪音水平;第二,变分自编码器的优化使用了重参数技巧,重参过程相当于为潜空间引入随机噪音,从而为推荐模型引入了随机性,有利于提高模型的泛化性能。然而,一些研究也指出,变分自编码器倾向于学习一个单模态的潜特征空间,其缺乏足够的表达能力以捕捉隐表示的真实后验分布。在推荐系统的应用场景中,用户-商品的交互数据常常蕴含多模态的特征,即不同用户或不同商品具有不同的偏好分布或特征分布。因此,许多基于变分自编码器的推荐模型常常难以捕捉多模态的偏好分布。
2.2 未来研究方向
本节总结了自然噪音环境下,鲁棒性Top-K推荐仍面临的两大挑战:第一,不同用户的交互数据具有不同的噪音水平;第二,不同用户的偏好分布是多模态的。因此,鲁棒性推荐需要自适应地建模用户的个性化噪音水平,同时具有足够的表达能力以捕捉用户的多模态偏好。
现有工作利用变分自编码器的网络结构为解决第一个挑战提出了一种解决方法,但是原始变分自编码器难以处理多模态的偏好分布。为了捕捉多模态的数据分布,文献[23]提出WAE,其具有VAE的优良特性,但利用Wasserstein距离保持了潜特征空间的多模态,从而鼓励模型近似真实的数据分布;文献[24]引入生成对抗网络(GAN)[20]并提出一种名为对抗变分贝叶斯(AVB)的训练技巧,使推断网络能够更灵活地近似真实的后验分布;文献[25]将AVB的思想引入协同过滤推荐。与此同时,作为另一种强大的生成模型,生成对抗网络具有强大的捕捉数据分布的能力,因此现有工作也开始探索GAN在推荐领域的应用,主要包括两个方面:第一,利用GAN学习用户隐表示,以捕捉用户的潜特征偏好;第二,利用GAN直接生成用户交互向量。然而,不像图片常常具有稠密的向量表示,推荐系统中稀疏的用户交互数据为GAN学习用户偏好分布带来新的挑战。由于变分自编码器正好具有很好的处理稀疏数据的能力,本文认为未来的工作可以结合GAN和VAE这两种强大的生成模型为Top-K协同过滤任务设计一种新的网络结构,以同时捕捉个性化的噪音分布和多模态的偏好分布,从而提升Top-K推荐的准确率和鲁棒性。
3 鲁棒性协同过滤用于评分预测
3.1 现有研究
在自然噪音环境下,鲁棒性评分预测旨在从噪音反馈中准确捕捉用户的真实偏好,以准确且稳定地重构“用户-商品”评分矩阵。利用评分预测进行推荐最早被学术界广泛研究。自从2006年Netflix大奖赛以来,推荐系统开始从学术界被引入工业界,并广泛应用于各种电子商务应用中。Netflix大奖赛主要解决电影评分预测问题,其中矩阵分解(MF)方法大获成功,成为主流的协同过滤算法之一。MF迭代训练一个低维用户矩阵和一个低维商品矩阵,使这两个矩阵的乘积近似原始评分矩阵,从而补全原始评分矩阵并据此进行推荐。显而易见,以MF为代表的评分预测方法的性能依赖于用户评分的真实有效性。然而,一些研究已经发现用户评分是有偏差的。文献[25-26]指出,当用户被要求再次评分其曾经评分过的商品时,只有大约60%的用户保持相同的分数。事实上,由于记忆损失、用户偏好难以量化以及许多其他因素,大量的可观测评分是有噪音的,这些噪音评分会影响协同过滤模型在评分预测任务上的准确性和鲁棒性。
早期主要有两种方法处理评分中的自然噪音:第一,移除噪音评分或噪音用户画像[28-29];第二,通过获取再评分数据探测和纠正噪音评分[2,22]。然而,估计误差导致直接移除可能的噪音会同时错误地删除非噪音评分,增加评分矩阵的稀疏性,而记忆偏差、用户意愿等因素导致难以保证再评分数据的真实有效。
近年来,一些方法致力于仅利用历史评分训练鲁棒的评分预测模型,其主要包括对噪音评分的纠正和降低噪音评分的影响两种思想[26-27,32]。文献[27]利用噪音探测和噪音纠正两个过程来处理自然噪音,其主要缺点是需要先验地定义一些分类标准和并划分分类区间,最终的预测模型的性能依赖于噪音探测和噪音纠正的质量,而噪音探测和纠正的质量可能受到不完美的预测模型的影响,并且噪音探测过程中使用预设的阈值划分分类区间,没有考虑到用户评分层次的个性化。最近,一些方法通过降低噪音评分在模型损失中的权重来提高模型训练的稳定性和评分预测准确性[26,32]。文献[32]发现现有的自适应学习率方法可以提高模型在稀疏数据上的收敛表现,然而用户评分不仅稀疏且有噪音,对噪音数据设置小的学习率有利于降低噪音数据对模型学习的干扰。文献[26,32]以不同方式实现了自适应学习率的评分预测算法,旨在提高评分预测模型对自然噪音的鲁棒性。
3.2 未来研究方向
个性化噪音分布和多模态偏好分布同样为鲁棒性评分预测带来巨大挑战。由于神经网络强大的信息抽取能力,利用神经网络自适应地评估用户评分中的自然噪音是一个很有前景的研究方向。另外,相对于隐式反馈来说,显式的用户评分数据往往具有更高的稀疏性,成为鲁棒性评分预测的另一大挑战。直观地,神经网络的训练依赖于训练数据的规模,稀疏的评分数据通常导致神经网络模型训练不足而难以捕捉用户的真实偏好分布。因此,本文认为设计一种合适的网络结构,其能够在识别噪音的同时实现有效的数据增强,有利于提高模型在稀疏且有噪音的场景下的评分预测鲁棒性。
4 实验
本节,我们在两个真实的数据集上比较了现有鲁棒性推荐算法的性能。
4.1 数据集
我们在MovieLens 1M和Digital Music数据集上进行实验。这两个数据集的统计信息如表1所示。

表1 数据集统计信息
在MovieLens 1M数据集中,每个用户至少有20个评分。Digital Music数据集是来自亚马逊的一个公开数据集,其原始数据集具有较高的稀疏度,我们仅保留至少有5次评分的用户和商品。对于Top-K推荐任务,我们将显式的评分转化为隐式的0-1交互数据。
4.2 对比方法
对于Top-K推荐任务,我们在CDAE[15]、APR[14]、ACAE[9]、RecVAE[19]和NeuMF[3]上进行了实验;对于评分预测任务,我们在AdaError[32]、Norma[26]和MF上进行了实验。其中,NeuMF是一种神经协同过滤的通用框架,该方法采用多层感知机建模用户和商品的潜特征之间的非线性交互;MF是一个矩阵分解模型,该方法学习用户和商品的低维嵌入向量,并使用向量的內积为预测评分。
4.3 评价指标
4.3.1 Top-K推荐评价指标
对于Top-K推荐任务,我们采用留一法进行评估,即对于每个数据集,我们为每一个用户抽取一条交互数据用于测试,该方法被广泛应用于Top-K推荐评估[9,14-15,33]。需要注意的是,对于每个数据集,我们以类似构造测试集的方式构造验证集,用于调整超参数。由于在测试时对每个用户进行所有商品的排序非常耗时,因此我们采用文献[15]和[33]的做法,即检查测试集中用户已经交互过的商品是否排在事先随机选择的99个该用户未交互过的商品之前。我们采用命中率(HR)和归一化折扣累积增益(NDCG)来衡量Top-K推荐性能。命中率的计算公式定义为:

其中rel i表示排名为i的物品是否被命中,若命中则rel i=1,否则r el i=0。HR和NDCG都是越高越好。
4.3.2 评分预测评价指标
对于评分预测任务,对于每个数据集,我们按8:2随机划分训练集和测试集,之后在训练集中随机留出20%的评分构成验证集。我们采用RMSE(Root Mean Square Error)和MAE(Mean Absolute Error)作为评价指标。定义如下:

其中,T test表示测试集。
4.4 实验结果
表2展示了在两个数据集上各个方法的Top-K推荐表现。除了NeuMF以外,其他方法都以不同方式考虑了噪音交互。通过实验指标我们发现,考虑了噪音交互的鲁棒性方法并不一定具有最优的Top-K推荐性能。例如,在Digital Music数据集上,鲁棒性推荐方法APR、ACAE和RecVAE的表现好于未考虑噪音交互的NeuMF,但是在MovieLens 1M数据集上,NeuMF优于所有的鲁棒性方法。另外,鲁棒性推荐方法在不同的数据集上表现有所差异。例如,RecVAE和APR分别是MovieLens 1M和Digital Music数据集上最好的鲁棒性推荐方法。这些实验结果证明了个性化噪音水平和多模态偏好可能是影响推荐模型鲁棒性的重要因素。

表2 所有模型在MovieLens 1M和Digital Music数据集上的Top-K推荐表现
表3展示了在两个数据集上各个方法的评分预测准确性。其中,MF没有考虑噪音评分。通过观察实验指标我们发现,考虑了噪音交互的鲁棒性评分预测方法并不总是具有最优的表现。例如,在MovieLens 1M数据集上,Norma具有最好的表现,而同样考虑了噪音评分的AdaError的表现甚至差于MF;在Digital Music数据集上,MF的评分预测表现最好,Norma的性能差于AdaError。我们认为,这样的结果可能与数据集的不同稀疏性有关。
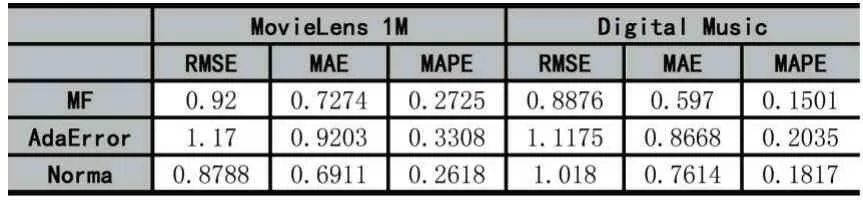
表3 所有模型在MovieLens 1M和Digital Music数据集上的评分预测准确度
5 结语
本文总结了噪音环境下鲁棒性协同过滤的研究现状,重点回顾了自然噪音环境下基于神经网络的鲁棒性Top-K推荐和评分预测方法,并在两个真实的数据集上进行了实验。最后,针对Top-K推荐和评分预测两大任务,本文分别提出一些鲁棒性推荐的未来研究方向。实验结果显示了本文提出的研究方向对于提升推荐模型鲁棒性的可行性。
