个人大数据的定价方法设计
2021-07-02郭妍彤
郭妍彤
(四川大学计算机学院,成都610065)
0 引言
数据时代的快速发展给人们的生活带来了很多便利,可以帮助我们足不出户的采购、交易甚至是办理政务手续,政府及企业也越来越重视对数据的管理及开发利用;但是大数据巨大的应用价值导致数据泄露事件频出,并且人们带来了骚扰广告和诈骗电话等困扰。现在的个人数据所有权管理混乱,个人数据所有者不但无法很好的使用个人数据来获得利益,反而深受数据泄露之扰,导致个人用户也缺乏了提供数据的积极性,需要数据的需求者也很难通过合法合规的渠道来获得自己需要的数据。为此,麻省理工学院媒体实验室Sandy Pentland教授2010年提出个人数据商店(Personal Data Store)理念,鼓励人们贡献和分享数据[1],并基于此产生了一种新的数据管理理念——个人数据银行。个人数据银行是指将个人数据当作一种新型的“货币”存储在个人数据银行中,建立一种大数据资产管理运营系统,将个人用户授权后的信息进行采集、清理、共享和使用,同时给个人用户一定比例的利息作为回报。
在构建个人数据银行的过程中,如何合理地对个大数据进行定价也是一个需要解决的问题,一个良好的定价方式可以对个人数据银行的运行和数据的流通起到促进作用。
1 研究介绍
个人大数据最大的特点在于数据提供者的不同及数据质量的参差。个人大数据的数据提供者是许许多多不同的个人用户,他们在授权平台对其采集数据后,会源源不断地制造各种不同种类、不同质量的数据。这些数据并不都有相似的数据质量,也会因为授权等级而有许多不同的差异,比如相似的个人运动中的一条跑步数据,提供者A允许平台收集地理位置信息,那么这就是一条拥有完整跑步期间轨迹信息的跑步数据,而提供者B不允许收集地理位置信息,那么这就是一条只有时间、长度及速度的跑步记录。虽然都是相似的跑步信息,但是这样不同的数据包含了不同的价值和信息量,在个人数据银行中所能获得的收益也应该不尽相同。
将数据商品和以前的一般商品相比较而言,其衡量价值和价格的属性也与一般商品有很大的差别,定价已经不是以前“成本驱动”的定价时代了[2]。现如今数据市场越来越大,人们对数据的需求也越来越多,但是数据定价方式还没有形成统一的评价标准。在数据定价中,首先要将视线转移到“价值驱动”上,正确地衡量数据的质量和价值,同时以此对数据进行差异性定价,是最需要解决的问题。其次,在现有的数据定价方法中,大多数都是以包为数据定价的基本单位,这样无法区分每条数据的差距,对于每条元组来说都是一样的平均价,这对于个人数据银行这样的构建前提来说,并不适合。不同的数据根据其信息量不同、价值不同、重要程度不同等差异,应有不同的价格,如果每条元组的价格一致,那么无法给个人用户提供激励以促进大家提供更多高质量的数据。
2 个人数据银行定价设计
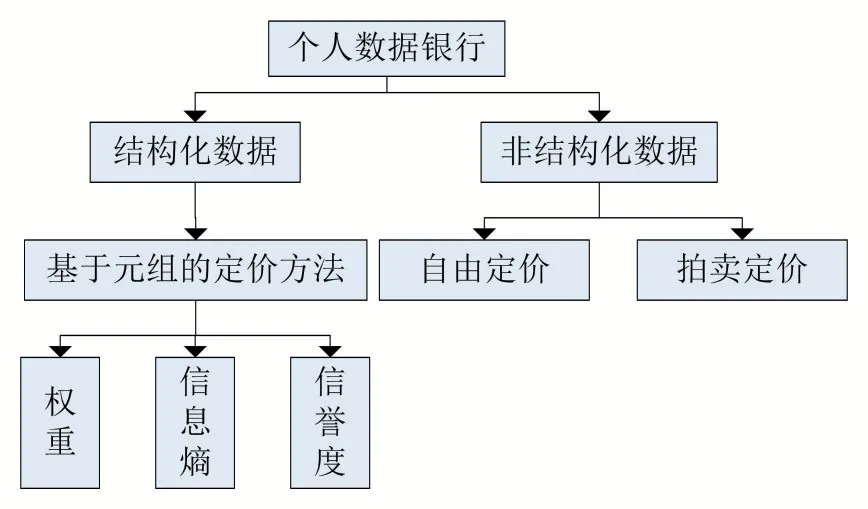
图1 个人数据银行定价总体设计
首先,我们先根据数据的结构不同,将数据分为结构化数据和非结构化数据。
在现在的数据流通中,格式化数据是使用最多的数据,小到一条外卖订单、大到一张医疗诊断单,其实都是一种结构化的数据。为此,我们将根据国家标准的《信息安全技术个人信息安全规范》中的分类标准对结构化数据进行划分,在数据经过脱敏后划分成个人基本资料、网络身份标识信息、个人健康生理信息、个人教育工作信息、个人财产信息、个人通信信息、联系人信息、个人上网记录、个人常用设备信息、个人位置信息、其他信息等十二类数据,并对每组信息设定好已有的数据结构模式及规模,进行整理及清洗。
而其他无法被轻易收集并处理成结构化数据的个人大数据,如个人的制作的视频集、个人拍摄的地貌图等个人用户愿意提供的有价值的数据,统一分为非结构化数据。
2.1 结构化数据的定价
针对不同种类的数据,应该有不同的定价方式。像是结构化数据,因为其不同的数据元组是由不同的数据提供者所提供,所以在数据的定价中,需要能够区分每一条数据,因为根据每一条数据的价值不同该数据的数据提供者所获得的收益也是不同的。对此,Shen[1]提出了以元组为基础的定价方式。在这种定价方式中,数据的最小衡量单位是元组,而其具体定价主要由三个部分影响,分别是:属性权重、数据熵和数据提供者的信誉值。
其中影响数据的因素为信息熵(q)、权重(w)及R指数(r),其对应的权重分别为α、β、γ,则满足以下约束:
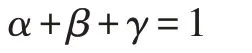
则每个元组的价格P i为:
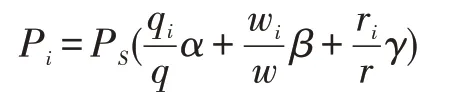
其中P S为整个数据集分成的价格。
这种方法中使用了信息熵来衡量数据中不同数据项的信息量,用权重来衡量数据中不同类型数据的价值含量,用信誉值来衡量数据提供者的信誉值。
但是在该方法中,并没有给出权重设计的详细方式,所以需要根据数据分类的情况,对数据的权重进行新的划分。我们可以将数据根据《信息安全技术个人信息安全规范》分类后,再根据每类数据中的详细分类对个人用户的重要性来对数据权重进行划分。
在该方法中,数据信誉度是根据所有数据的数据售出的次数而衡量的,但是在实际应用中,数据的售出次数与数据提供者的信誉度并没有很大关联,如果数据提供者刚好提供了售出次数多的数据类型,并不代表这位数据提供者的其他信息也是高质量的。因此,在本节设计中,将数据信誉度R值进行重新定义,如定义1,其中数据质量为数据信息熵和数据权重的加权和。
定义1如果某个用户的数据元组至少有r条数据质量大于r,那么这个用户的数据引用指数为R,称为“R指数”。
在此基础上,我们可以将数据质量M定义为如下公式:
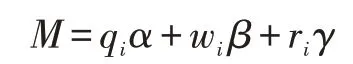
在个人数据银行中,数据需求者可以根据数据质量M、信息熵、权重和r指数来对数据质量进行筛选,可以给数据需求者更多样化的选择。
2.2 非结构化数据的定价
对于非结构化的数据,已经有规模的数据可以像结构化数据一样,为其定义几个反映其数据质量的指标,并根据数据指标对其进行数据价值的加权衡量。但是由于个人大数据的种类繁多,并不是所有的非结构化数据都可以很好地用这种方法进行,对此主要有两种定价方式:
(1)自由定价
自由定价即是根据数据所有者的意愿自己决定数据的具体价格。这种定价方式主要由数据所有者自己决定。这种定价方式简单、快捷,但是定价方式不透明。
(2)拍卖定价
拍卖定价是一种常用的数据定价手段,通常在数据提供者对自己提供的数据有自信的情况下会采用这种方式,因为通常情况下经过拍卖的商品一般是相对来说罕见、稀有的商品。在网上进行拍卖,虽然有节省场地、参与方便、时长更自由等优点,但是也会因为其网络形式而产生很多问题,例如:在网上竞拍者更容易产生联系从而容易出现共谋的情况、有些竞拍者会在拍卖结束前进行抢拍或拍卖结束后不认账等情况,这都会对卖方和其他竞拍者产生不利的影响。
所以在拍卖中还需要考虑到拍卖流程的安全性和私密性,需要在流程中由个人数据银行来保证交易的不可否认性、抗共谋性、底价隐藏性和密封递价性等特性,以保证参与数据各方的利益。
3 定价设计分析
在本文中对结构化属性提出了使用基于元组的定价方法,其中对属性进行划分可以根据不同数据属性的权重对不同数据种类进行定价,比如含有精准位置的运动信息肯定会比普通的运动信息要更有价值、使用场所更多;而信息熵可以从数据的信息量来衡量数据的价值,数据的信息熵越高则数据的信息量越高;信誉度则可以从数据的提供者的角度来衡量数据价值,如果数据提供者总是提供高质量的信息,那么将有机会获得更高的数据收益分成,将会促进数据提供者为个人数据银行提供更多更高质量的数据。
对于非结构化数据本文提出了使用自由定价和拍卖定价的方式,自由定价和拍卖定价都是一种积累数据定价信息的方式,我们可以根据这两种方法来收集非结构化数据的历史价格和影响价格的因素,在同类型数据收集到一定的规模后,可以根据收集到的信息将已有一定规模的非结构化数据独立出来,像结构化数据一样根据影响数据质量的因素进行定价。
4 结语
对于个人大数据中数据定价难的问题,提出将个人大数据分为结构化数据和非结构化数据两类,并对结构化数据使用基于元组的定价方式,对非结构化数据使用基于自由定价和拍卖定价的方式。
