基于Petri网的流程变体合并方法*
2021-06-25王吴松郑雪文
王吴松,方 欢,郑雪文
(安徽理工大学数学与大数据学院,安徽 淮南 232001)
1 引言
流程变体(Porcess Variants)可以被定义为系统流程族(模型)中相似但不同(Similar-but- different)的模型,通过对这些模型进行映射,从而发现这些模型间共同拥有的片段以及存在差异的片段。此时,将从模型中通过映射发现的片段称为模型的特征,即这些模型至少有一个共同的特征,也至少有一个特征可相互区分。从粗粒度的流程系统的角度分析,流程变体是流程族模型中从基模型衍生出的其他相似流程模型;从细粒度的流程系统的角度分析,流程变体是指各流程模型中那些具有某些共性同时又具备各自个性的模型片段。在组织合并、收购或重组的背景下,不同组织之间的业务流程往往存在着多种变体结构。对于组织管理者来说,业务流程的诸多变体在组织管理时会耗时耗力,同时也会增加运营成本。因此,将以前属于不同组织或分支机构的诸多流程变体进行合并,使之成为特定业务背景下的单一流程模型,以此来消除冗余。使得不同组织或分支机构能共同使用这一特定业务背景下的单一流程模型,从而降低运营成本是具有一定实践意义的。这种做法对于组织或分支机构来说是有益的,因为输入的流程变体的相关性降低,合并后的流程模型的规模会减小,模型规模的减小反过来又可以提高模型的可维护性和可理解性。
文献[1,2]要求通过流程变体发现的参考模型能使用一些配置手段(移动、删除、插入)导出其中任意一个流程变体,即可配置性;文献[3]要求合并模型应考虑所有原始模型的行为,即全面性;文献[4]要求合并过程模型中的每个节点都能很容易地追溯回其原始模型,即可追溯性。合并流程变体的目的是让组织管理者能够查看业务流程的多个变体之间的共性和差异,并对其进行管理。此外,组织管理者可以对合并模型进行更改操作,并将更改操作传递给流程变体,而不需要单独对每个变体进行更改操作。因而,本文中提出的变体合并算法需要满足上述3个要求。
现有的合并流程模型的方法大致可以分为2类:第1类是基于流程行为[1,2,5 - 11];第2类是基于标签相似性[6,10,12]。
第1类方法要求合并模型满足所有输入模型的行为,这也就意味着合并模型能够重放每个输入模型的行为。文献[1,2]介绍了由一个参考模型通过一些更改操作(删除、插入、移动)来配置出流程变体,通过启发式搜索方法挖掘流程变体进而推导出新的参考模型;文献[5]提出了一种计算合并模型的方法,而文献[6]在文献[5]的基础上加入了从合并模型中提取上下文信息的算法,并将此上下文信息提供给分析师,用于找到模型中需要集中优化的片段;文献[7]研究了在合并模型中可能会遇到的一些问题,同时也从另外的视角对流程模型的合并进行了深层次的研究;文献[8]提出了一种分解驱动方法,该方法允许从事件日志集合中发现层次合并流程模型,并且已发现的层次结构是由嵌套的抽象化流程片段组成,这也就意味着允许在不同的抽象级别上浏览可变性;文献[9]介绍了一种表达过程行为特征的形式化语言及其语义,并说明了它是如何支持流程合并的;文献[10]介绍了一种处理流程变体族的建模方法,该方法的关键是在分解步骤即将主流程分解为子流程,以及决定哪些子过程应该一起建模和哪些子过程单独建模;文献[11]通过对遗传过程发现方法的扩展,从事件日志集合中发现一个能描述一系列流程变体的可配置流程模型。
第2类方法则是只允许合并基于相同标签的流程模型。文献[6]介绍了4种合并类型:顺序合并、并行合并、条件合并和迭代合并,为了避免无效的合并,通过选择合并点进行合并以此产生一个合理的合并模型;随着可配置流程模型中可配置节点的增长,搜索空间的大小是按指数增加的。文献[9]介绍了一种扩展的事件过程驱动链,这种事件过程驱动链可以用来描述单一模型的相似过程集,同时也减少了管理的流程模型的数量,且可以区分集合中发生合并的每个特定元素的流程逻辑。文献[11]提出了3种策略:基于穷举搜索的方法、基于遗传的方法和贪心启发式的方法,并利用事件日志从可配置流程模型中配置流程变体,该方法很好地表示了一个特定分支中流程的特征。
现有的流程变体合并方法都是以事件过程驱动链为建模语言,合并方法以Petri网为建模语言的却很少涉及。而Petri网作为常用系统建模语言之一,由于其简单性、表达并发性的能力、清晰的语义和数学性质而受到广泛推崇,并随之诞生了大量的仿真分析工具,为分析Petri网性质提供了极大方便。同时,在已有的合并方法中[1 - 4],合并后的模型不能同时满足上述所提出的3个要求,即可追溯性、可配置性和全面性,并且合并后的模型结构在一定程度上过于冗杂,不利于组织管理者理解,即可理解性较差。
本文主要描述了一种基于Petri网的流程变体合并方法,该方法以流程模型的集合作为输入,并生成可配置的流程模型。可配置的流程模型是一个建模工具,它以集成的方式捕获了一系列流程模型。同时,生成的流程模型满足以下3个要求:可追溯性、可配置性和全面性。并且合并后的流程模型在规模上得到了一定程度的简化,便于组织管理者更好地理解模型。
2 相关概念
定义1(流程模型[13]) 满足下列条件的三元组PM=(P,T;F)是一个流程模型,其中:
(1)P为库所集,T为变迁集,将库所集与变迁集中的元素称为模型的节点;
(2)P∪T≠∅且P∩T=∅;
(3)F是PM的流关系且F∈(P×T)∪ (T×P);
(4)dom(F)∪cod(F)=P∪T。其中,dom(F)={x∈P∪T|∃y∈P∪T:(x,y)∈F};cod(F)={x∈P∪T|∃y∈P∪T:(y,x)∈F}。
此时,dom(F)也表示在定义域中2个相邻的节点x与y之间为因果关系;而cod(F)表示在值域中2个相邻节点间用x表示y。
定义2(流程变体[1,2]) 假设NG是一组流程模型,I表示一组流程更改操作(即删除、插入、移动),S0,…,Sn,S′∈NG是一系列的流程模型。设σ是流程更改操作中的任意一个更改操作,θ⊆I是一个对初始的流程模型进行更改的操作序列,将满足以下条件的流程模型称为流程变体:
(1)S0[σ>Sn表示σ作用于S0,且Sn是S0应用σ所得到的流程模型;
(2)S[θ>S′表示存在S0,S1,…,Sn∈NG,并且S=S0,S′=Sn,Si[σi>Si+1,i={1,2,…,n-1},对于这样的S′,称为S的流程变体。
定义3(前集与后集、传递前集与传递后集[14])假设G为一个流程图,G中的节点a是一个二元组(λG(a),τG(a)),其中λG(a)为节点a的标签,τG(a)为节点a的类型。在没有歧义的情况下,可以将下标G从(λG(a),τG(a))中删除。
NG∈G为流程图中的节点集合,EG为流程图的有向边集合。对于一个节点a∈NG,将前集定义为·a={m|(m,a)∈G};类似地,将后集定义为:a·={m|(a,m)∈G}。

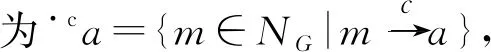
定义4(上下文相似性) 假设G1和G2是2个流程图,并且M:NG1→/NG2是一个单射。在这一映射规则下,将G1中的节点映射到G2中。2个映射节点a∈NG1和m∈NG2的上下文相似性定义如式(1)所示:
Sim(a,m)=
(1)
定义5(匹配分数) 设Si和Sj是2个流程变体,M是它们的映射函数,设0≤ω1≤1,0≤ω2≤1,0≤ω3≤1是分配给公共节点、插入或删除节点以及插入或删除边的权重值。c1代表公共节点的集合,c2代表插入或删除节点的集合,c3代表公共有向边的集合,c4代表插入或删除有向边的集合,对于cl(l=1,2,3,4)的定义如式(2)~式(5)所示:
c1=dom(M)∪cod(M)
(2)
c2=(NGi+NGj)c1,i≠j
且i=1,2,3;j=1,2,3
(3)
c3={(c,d)∈EGi|(M(c),M(d))∈EGj}∪
{(c′,d′)∈EGj|(M(c′),M(d′))∈EGi}
(4)
c4=(EGi+EGj)c3
(5)
f1表示流程变体中任意公共节点的距离,f2表示流程变体中插入或删除节点的分数,f4表示流程变体中插入或删除有向边的分数,fi(i=1,2,4)定义如式(6)~式(8)所示:
(6)
(7)
(8)
则流程变体Si与Sj间的匹配分数定义如式(9)所示:
(9)
3 流程变体间的匹配分数
流程变体之间至少有一个共同的特征、也至少有一个特征相互区分。模型之间的相似性度量,大多采取因果关系去衡量,即模型之间的行为轮廓。本文方法是基于流程变体之间的映射关系,对变体间的共同特征与差异进行衡量。为了更好地了解流程变体间的相似程度,本文通过匹配分数来对流程变体进行衡量,进而得出流程变体间的相似程度。
算法1流程变体间匹配分数
输入:流程变体Si,Sj。
输出:匹配分数fS。
步骤1i←1;
步骤2 FORitonDO
步骤3j←i+1;
步骤4publicregions←Map(Si,Sj);
步骤5c1←CountpublicNode(Si,Sj);/*计算变体间公共节点数量*/
步骤6VSi←CountNode(Si);
步骤7VSj←CountNode(Sj);
步骤8c2←ComputerInsertedOrDeletedNode(c1,VSi,VSj);/*计算变体间插入或删除节点的数量*/
步骤9c3←CountpublicEage(Si,Sj);/*计算变体间公共有向边的数量*/
步骤10ESi←CountEage(Si);
步骤11ESj←CountEage(Sj);
步骤12c4←ComputerInsertedOrDeletedEage(ESi,ESj,c3);/*计算变体间插入或删除有向边的数量*/
步骤13Simi,j←Correlationsimilarity(Si,Sj);/*计算变体间的相似性*/
步骤14f1←Computerdistance(c1,Simi,j);/*计算任意公共节点距离*/
步骤15f2←ComputerScoreOfInsertedOrDeleted-Node(c1,VSi,VSj);/*计算插入或删除节点的分数*/
步骤16f4←ComputerScoreOfInsertedOrDeleted-Eage(c4,ESi,ESj);/*计算插入或删除有向边的分数*/
步骤17fSi,jComputerMatchScore(ω1,2,3,f1,2,4);/*计算匹配分数*/
步骤18 ENDFOR
步骤19 RETURNfS
分析流程变体间匹配分数算法,步骤1~步骤3为算法的循环条件,通过这一循环得到流程变体间的不同组合。步骤4将变体Si映射到变体Sj上。步骤5~步骤16为计算流程变体间匹配分数的准备工作,其中步骤5为计算变体Si和变体Sj中共有部分的节点数量之和,步骤9与步骤5执行一样的操作,得出公共的有向边;步骤6~步骤8计算变体Si和变体Sj插入或删除节点的数量,步骤10~步骤12类似;步骤13计算节点间的上下文相似性,步骤14~步骤16分别计算公共节点的平均距离、变体Si和变体Sj插入或删除节点的分数、变体Si和变体Sj插入或删除有向边的分数。步骤17计算变体间的匹配分数。步骤18结束循环。步骤19返回匹配分数的值。
算法1中的步骤5利用了式(2),步骤8利用了式(3),步骤9利用了式(4),步骤12利用了式(5),步骤13利用了式(1),步骤14利用了式(6),步骤15利用了式(7),步骤16利用了式(8),步骤17利用了式(9)。
如前文所述,匹配分数是用来衡量流程变体间的相似程度。下面通过图书馆借还书籍的业务流程图来对匹配分数进行说明,同时,这一业务流程图将作为贯穿全文的案例来使用。图1 所示即为图书馆借还书籍的业务流程图。

Figure 1 Variants diagram of loaning and returning books process in library
现对图1中图书馆借还书籍流程变体图中的变迁做如下说明:A1(读者刷卡入馆)、A2(无目的性的借书)、A3(到借阅区浏览,挑选所需图书)、A4(自助机借书)、A5(服务台借书)、A6(刷借书证,核对相关信息)、A7(所在楼层服务台办理借书手续)、A8(借书成功,刷卡出馆)、A9(阅读完毕)、A10(还书前核实)、A11(信息正常)、A12(超期罚款)、A13(还书成功)、A14(指定书籍借阅)、A15(检索馆藏)、A16(书籍在架)、A17(书籍不在架)、A18(预约指定书籍)、A19(预约书籍到馆)、A20(登录网上图书馆网址)、A21(网上办理委托申请)、A22(委托申请办理中)、A23(取消委托申请)、A24(委托申请成功)、A25(核实地址)、A26(书籍运送)、A27(借书成功)、A28(将书寄回)。
匹配分数的数值越高,则说明2个流程变体间的相似程度越高,即流程变体间共有的共同特征越多。匹配分数0≤fS≤1。若通过算法计算出的匹配分数小于一定的阈值,则对流程变体不进行4.1节的算法2中流程变体的合并操作。此时,从图书馆借还书籍的业务流程图中选择2个流程变体S2和S3来运行算法1,得到这2个流程变体S2和S3的匹配分数fS=0.57。因为流程变体S2和S3的匹配分数为0.57,说明这2个流程变体间的相似程度较高,即所共有的共同特征较多,而从图1中也不难看出2个流程变体所共有的共同特征有2个部分(即图1中标号为3的框所圈出的部分)。基于算法1计算这2个流程变体的具体过程在第5节中给出。
4 流程变体的合并方法
流程变体的合并是在一对可配置的流程图上(如图1所示)进行的,但是有时也会出现合并2个不可配置的流程图的情况。为此,文献[15,16]中提出了一种使用扩展的Condec语言对不可配置的流程模型进行约束规范,进而将不可配置的流程模型转变成可配置的流程模型的方法,之后再进行流程变体的合并。
4.1 算法设计
算法2流程变体的合并算法
输入:流程变体S1、S2。
输出:合并模型MP。
步骤1map(S1,S2)→publicregions∪differentregions;/*将S1,S2映射,划分公共区域与差异区域*/
步骤2P=NULL;//节点的最大公共区域为空值
步骤3s=1;
步骤4 WHILEsDO
步骤5IF所有节点都包含在P中THEN
步骤6s=0;
步骤7ELSETHEN
步骤8Randomchoose(Vm≠Pl);/*随机挑选一个节点*/
步骤9Pl=Searchmaxpublicregion(Vm);/*寻找节点Vm的最大公共区域*/
步骤10P.add(Pl);/*将寻找到的最大公共区域添加到P*/
步骤11s=1;
步骤12ENDIF
步骤13 ENDWHILE
步骤14Addactivity(ST,ET);/*在变体S1和S2中插入开始活动ST与结束活动ET*/
步骤15Fi=maxpublicregions∪differentregions;//将最大公共区域与差异区域拆分为片段
步骤16i=1;
步骤17 WHILEiDO
步骤18matchscorei=computer(Fi);
步骤19IFmatchscorei=1THEN
步骤20Abstractpublicregions(Fi);
步骤21ELSETHEN
步骤22Notabstractpublicregion(Fi);
步骤23ENDIF
步骤24 ENDWHILE


步骤27 ENDFOR

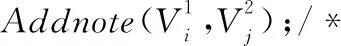
步骤30 ENDFOR
步骤31originalversionMP′←unionpublicregions;
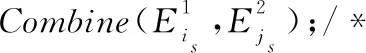


步骤35MP()←MergeRedunancyPlaces(MP″);
步骤36 RETURNMP
分析流程合并算法,步骤1在变体S1与变体S2建立映射关系,找到变体S1与变体S2相同与差异的一些片段,步骤2~步骤14将变体S1和S2之间的映射划分为一个仅由匹配节点和公共的有向边构成的最大公共区域,其中,s=0,1为判断是否找到最大公共区域的条件。步骤15分别对变体S1、S2添加一个开始活动(ST)与结束活动(ET)。步骤16~步骤25对最大公共区域进行抽象化处理,其中步骤19计算这些片段的匹配分数,步骤20~步骤24为判断片段可抽象化的条件。步骤25~步骤27对变体S1和S2中的每个有向边都添加一个注释。步骤28~步骤30与步骤25~步骤27进行的操作类似,只不过是对节点进行操作。步骤31对变体S1和S2中最大公共区域执行并集操作,得到原始版本的合并模型MP′。步骤32将变体S1和S2中替换边的注释结合起来。步骤33对节点也进行类似的操作。步骤34将原始版本的合并模型MP′与变体S1和S2的插入或删除的节点进行连接,得到合并模型MP″。其连接方式是根据源和汇在变体S1和S2中的位置。步骤35将合并模型MP″中冗余的库所合并为一个库所,以此得到最终的合并模型MP。
定理1(可配置性) 合并模型使用一些配置操作(移动、删除、插入)导出其中任意一个流程变体。
证明流程变体是由参考模型经过一系列的配置操作得到的。本文提出的合并算法旨在将流程变体合并为在一个特定业务背景下的单一参考模型。因此,这个单一的参考模型也可以通过配置操作得到任意一个流程变体。
□
定理2(可追溯性) 合并过程模型中的每个节点都能追溯回其原始模型。
证明合并算法中,对输入的每个流程变体的节点与有向边进行了注释(如在节点与有向边中添加了数字注释),确保了在合并后的模型中能更好地追溯来源。
□
定理3(兼容性) 合并模型考虑所有原始模型的行为。
证明因为合并模型是由流程变体经由合并算法得来的。利用反证法,假设合并模型没有考虑所有原始模型的行为,根据定理1,合并模型具有可配置性,即合并模型通过移动、删除、插入等配置操作可以得到任意流程变体。如若假设成立,则导出的流程变体与合并算法之前的流程变体是不一致的。因此,假设是不成立的,即合并模型考虑所有原始模型的行为。
□
4.2 基于Petri网的流程变体合并方法的性质分析
由于Petri网系统具有安全性、活性等性质,本文提出的流程变体合并方法建立在Petri网系统之上。下面对本文提出的基于Petri网的流程变体合并方法的相关性质进行分析。

综上,定理4的(1)得证。(2)和(1)的证明相似,在此不做赘述。
□
5 案例研究
流程变体不同组合间的匹配分数主要分为以下2种情况:组合间匹配分数相同和匹配分数不相同。而本文考虑的是后一种情况,当变体数量庞大时,变体数量为3个是一个临界值,如若变体数量为4个甚至更多,也是通过相同的方法来计算匹配分数,从而挑选出最适配的2个流程变体。因此在本文的研究中选择3个变体来计算不同变体组合的匹配分数。接下来通过对图书馆借还书籍的流程来进一步阐述所提出的方法。以标准借还书籍的流程模型为基础,通过一系列更改操作(如删除、插入、置换)来配置流程变体,以此得到3个流程变体,分别为S1(图1左)、S2(图1中)和S3(图1 右)。流程变体S1和S2是线下图书馆借阅书籍的业务流程图,而流程变体S3是线上图书馆借阅书籍的流程图。对于3个变体来说,其共有的部分为书籍阅读完毕至还书成功的这一过程;其不同之处就在于,线下图书馆是读者亲自去图书馆挑选所需书籍,而线上图书馆通过客户端挑选书籍,之后通过邮寄的方式来达到借书的目的。但是,对变体S1和S2来说,这2个流程变体的共同特征还包括刷卡入馆和借书这2个片段;那么,2个流程变体S1和S2中挑选借阅书籍的方式是不同的,流程变体S1是毫无目的性地挑选借阅书籍,流程变体S2是挑选特定的借阅书籍,这种特定的借阅书籍还可能不在架。对于流程变体的具体描述如图1所示。
之后本文以图书馆借还书籍业务流程Si(i=1,2,3)作为算法1和算法2的输入,验证本文所提出的流程变体间匹配分数算法和流程变体合并算法。
执行算法1中步骤4找到2个变体中的共有部分,用带标号虚线框标识出来,对于不同变体间的共有部分用了不同标号的虚线框标识,如图2所示;执行算法1中步骤5,统计3个流程变体两两之间公共节点的数量,即图1中虚线框住的部分就是3个流程变体的公共部分,记为c1;执行算法1步骤6~步骤8,计算2个流程变体的总节点数,再与公共节点数相比较得出变体中插入或删除节点的数量,记为c2。

Figure 2 Abstract fragments F1 and F2
算法1 中的步骤9计算2个变体中公共部分的有向边的数量,记为c3;步骤10~步骤12计算变体中插入或删除有向边的数量,记为c4。
算法1 中步骤13计算节点间的上下文相似性,此时在流程变体间分别选取一个特殊的节点,由定义5中的式(1)计算得出Sim(a,m)。
算法1中的步骤14计算公共节点的平均距离、步骤15计算变体Si和变体Sj插入或删除节点的分数、步骤16计算变体Si和变体Sj插入或删除有向边的分数,对应地分别记为f1,f2,f4。
对于流程变体S1和S2、S1和S3以及S2和S3来说,各流程变体之间相关的数值详见表1。
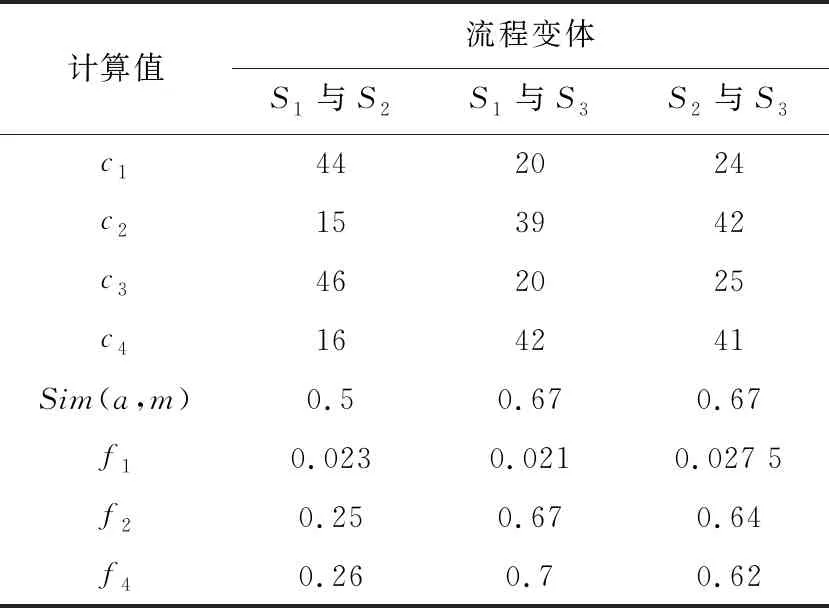
Table 1 Values associated with the matching score between each process variant
执行算法1中步骤17,计算变体间的匹配分数,此时将式(9)中的权重ωi设置为1,则流程变体Si(i=1,2,3)和之间的匹配分数可由式(9)计算得出,记为fSi,j。
表2中所示为2个流程变体之间的匹配分数。不难看出流程变体S1和S2的匹配分数相对于其他2对的匹配分数要稍微高一点,说明了S1和S2的相似程度略高于其他2对变体。因此,在接下来流程变体的合并算法中,选择匹配分数稍微高于其他2对的流程变体S1和S2。
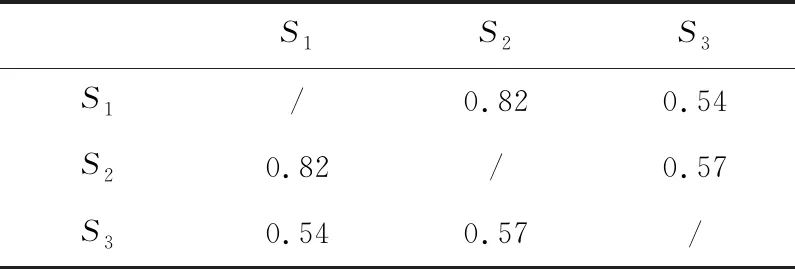
Table 2 Matching score fSi,j between process variants
执行算法2中步骤1,对变体S1和S2建立一个映射关系,从而找到流程变体S1和S2中相同与存在差异的一些片段。之后执行算法2中的步骤2~步骤14,将变体S1和S2之间的映射划分为一个仅由匹配节点和公共的有向边组成的最大公共区域。为了找到所有的最大公共区域,随机找一个没有包含在任何最大公共区域的匹配节点,并使用广度优先来搜索该节点的最大公共区域,之后使用相同的方法选择另外的匹配节点进行类似的操作,并以此创建另外一个最大公共区域。
算法2 中步骤15分别对变体S1、S2添加一个开始活动(ST)与结束活动(ET)。步骤16~步骤24用Fi标记找到的最大公共区域与差异区域,之后计算上述2类区域的匹配分数,将匹配分数计算结果为1的区域内部行为抽象化,得到了2个抽象化的片段,如图2所示。并将抽象化片段嵌入到流程变体S1和S2中,简化了变体S1与S2的结构。执行步骤25~步骤30,对有向边和节点添加注释。执行完算法2中前30个步骤后得到的流程图如图3所示。

Figure 3 Process variants after processing
执行算法2中步骤31~步骤34,得到一个合并模型MP″,如图4所示。合并后的模型应当满足这样的要求:流程图中的变迁最多有一个输入库所或输出库所,显然图4中的2处变迁不符合提出的要求,因此对合并模型MP″执行算法2中的步骤35,将冗余的库所合并为一个,得到如图5所示的流程合并模型MP。

Figure 4 Process variants merging model MP″

Figure 5 Process variants merging model MP
流程变体合并模型MP经简化之后,可以使用合并比(fc=|MP|/(|G1|+|G2|))来衡量流程变体的合并情况,即通过节点的增减情况来衡量流程变体的合并情况。从图2与图5中可以分别得出流程变体G1和G2的节点数|G1|+|G2|为59,流程变体合并图MP节点数|MP|为17,则合并比为0.29。合并比也从侧面反映了一个事实,即合并比越低,说明2个流程变体合并后所产生的合并图的效果越好。
6 结束语
本文以匹配分数作为流程变体相似性的判断基准,从备选流程变体中选出一对流程变体作为输入,输出是由这2个流程变体合并得到的流程模型。输出的流程模型具有全面性、可追溯性、可配置性,即保证合并后的模型包含了其输入的原流程变体,且可以通过对合并后的模型进行一些配置推导出原流程变体。此外,本文提出的流程变体合并方法在满足上述3个性质的基础上,还对变体间的最大公共区域进行了抽象化处理,使得流程变体的规模在一定程度上得到了缩减。因此,提升了合并模型的可理解性。但是,若作为输入的多个流程变体具有相同的匹配分数,需要对多个流程变体进行合并,最终得到合并模型。而合并的步骤是先将2个流程变体合并,再将得到的模型与第3个流程变体合并,直到所有的流程变体合并完毕。在未来的工作中希望能够一次性完成多个流程变体的合并,而不需要先将2个流程变体合并 ,再与剩下的流程变体合并,从而大大节省多个流程变体合并所需要的时间,同时,在多个流程变体的合并过程中也能降低出错率。
