低信噪比下联合训练生成对抗网络的语音分离*
2021-06-25全海燕
王 涛,全海燕
(昆明理工大学信息工程与自动化学院,云南 昆明 650500)
1 引言
不同于用语音增强去抑制噪声信号来提升目标语音能量,语音分离技术是希望将目标说话人语音从多说话人的混合语音中分离出来。早在20世纪80年代,相关研究人员就对该领域有了深入研究,但这些方法在低信噪比SNR(Signal-to-Noise Ratio)的条件下,分离性能都不太理想。后来随着计算机性能的提升和人工神经网络技术的成熟,研究者们对语音信号的特征研究更加深入,由于低信噪比SNR下目标说话人语音较弱,其特征不明显,因此增加了对语音分离的难度。
神经网络是近年来受各领域欢迎的热门方向。1989年,Tamura团队[1]提出将神经网络运用到混合语音分离中,来得到目标语音在时域上的非线性映射。随后,Xie等人[2]通过提取语音信号的频域特征,再将其送入神经网络来学习目标语音的映射关系。但是,由于计算机性能的限制,早期的神经网络层数较少,结构简单,并且训练数据较少,无法得到更为准确的映射关系。而近几年,在深度学习浪潮的推动下,深度神经网络DNN(Deep Neural Networks)被广泛应用于语音分离中。2006年,Hinton等人[3]提出深度信念网络DBN(Deep Belief Networks),使得神经网络真正意义上有了“深度”。Roman等人[4]率先将DNN用于语音分离,通过特征学习来预测每个时频单元的理想二值掩膜,从本质上提升了分离语音的清晰度。Xu团队[5]通过一个DNN来实现混合语音与目标语音的对数幅度谱映射,并根据相位信息来恢复时域波形。次年,Huang等人[6]提出了基于循环神经网络RNN(Recurrent Neural Networks)的语音分离方法,其分离性能有所提升,但对长时建模的能力有限。Wang等人[7,8]根据不同性别说话人之间的差异度,提出了一种无监督的DNN进行语音分离,其获得的分离效果显著。Goodfellow等人[9]提出的生成对抗网络GAN(Generative Adversarial Networks)为深度学习带来了新的突破,其在图像领域取得了极大成果,但在语音分离上应用较少。Pascual等人[10]提出的语音增强生成对抗网络SEGAN(Speech Enhanced Generative Adversarial Networks)直接处理时域语音信号,通过对抗学习使用判别模型来促进生成模型分离,提升了高频信息的恢复,从而获得更清晰的分离语音。文献[11]进一步将GAN运用到人声与背景音乐的分离中,以混合信号的频谱特征作为系统输入,能更好地对高频成分进行分离,从而有效分离出人声信号。以上方法的优势是在高SNR下能不同程度地提升对目标说话人语音特征提取的能力,但SNR较低时,分离性能受限。
虽然GAN相比于其他神经网络能更好地提升对高频成分信息的恢复,但其训练过程中仍只关注目标说话人的语音特征信息,因此在SNR较高时性能突出,而在低SNR下,由于目标说话人的相关语音特征不明显,所以分离性能有限。研究表明[12],干扰说话人的语音信息(尤其在低SNR下)对分离性能具有重要价值。为了进一步提升分离语音质量,本文提出了一种基于联合训练生成对抗网络的混合语音分离方法,其以时域波形作为网络输入,充分利用GAN的对抗机制,构建联合训练结构使判别模型用于获取干扰说话人的高维时域特征信息,进而促进生成模型更好地分离出目标说话人语音。在GAN中加入干扰说话人语音,弥补了低SNR下目标说话人特征信息较弱的不足,从而有效提升GAN的语音分离性能。此外,本文通过构建同性(男男、女女)和异性(男女)组合方式的混合语音来验证所提方法在不同条件下的有效性和泛化性。
2 基于联合训练生成对抗网络的语音分离
2.1 生成对抗网络
GAN是2014年Goodfellow等人提出的一种新的深度学习模型,其各种变形已经在图像处理和自然语言处理等领域取得了显著效果,并逐渐向其它领域渗入。图1为GAN模型结构图,其主要由生成模型G和判别模型D构成,x是服从Pdata(x)分布的真实数据样本,z是服从Pz(z)分布的随机变量,G的任务是将噪声数据z的分布映射到真实数据x的分布上;而D则是对生成数据G(z)和真实数据x进行判别。

Figure 1 Structure of GAN
GAN与其它深度学习模型最大的不同在于其对抗学习机制,其过程就是D不断对输入数据进行判别,并通过输出的概率值对真假样本进行分类,即D(G(z))=0或D(x)=1;而G则根据D的判别结果相应地调整生成数据,使得D无法做出正确的判断。这个过程可用式(1)所示的交叉熵损失函数来表示:
Ez~Pz(z)[ln(1-D(G(z)))]
(1)
2.2 联合训练语音分离生成对抗网络
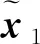

Figure 2 Architecture of cooperative training speech separation based on GAN
损失函数是保证参数更新的关键,由于语音数据的一维特性,因此采用最小二乘GAN[13]LSGAN(Least Squares GAN)的损失函数来作为本文SSGAN的损失函数,这样能更好地衡量分离语音与纯净语音之间的差距。图2在D的输入信号中引入xc作为额外条件,能为判别过程提供辅助信息。则G和D的损失函数分别如式(2)和式(3)所示:
(2)

(3)
为了使分离语音与纯净语音之间的距离最小化,并且加快网络收敛,Isola等人[14]在G的损失函数上加入L1范数,并由参数λ控制,且λ的取值决定着L1范数对G损失函数作用的大小。λ取值太大会忽略D对G的反馈作用,取值太小则无法促进G进行有效分离,将λ设置为100时能有效平衡两者的作用。此外,本文在实际训练中选取xm替换xc,则将式(2)和式(3)修改为:
(4)
λ(‖G(xm)-x1‖1+‖xm-G(xm)-x2‖1)
(5)
2.3 生成模型和判别模型的网络结构
本文采用全卷积神经网络FCN(Fully Convolutional Networks)[15]来构建一个端到端生成模型网络结构,其主要由卷积和反卷积2部分构成,能不断提取目标语音的高维特征,并通过反卷积形式来还原目标语音,如图3所示。
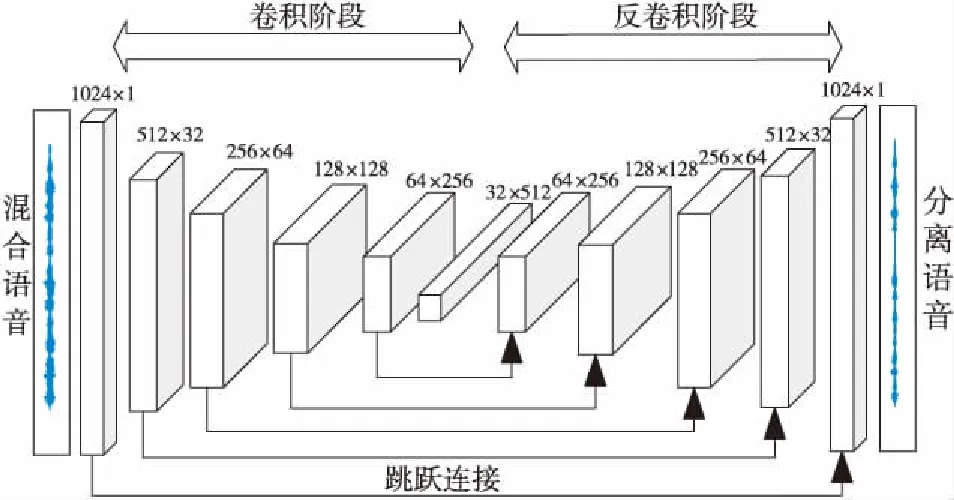
Figure 3 Network structure of generative model
生成模型的卷积阶段采用大小为31的卷积核,步长为2,其每层卷积核个数分别为1,32,64,128,256,512。卷积过程对混合语音进行降维压缩,最后得到的特征向量包含了高维时域特征。而反卷积阶段同卷积阶段对称,并对提取的特征向量进行逐层恢复。此外,每层网络的输出激活函数均采用带泄漏修正线性单元LeakyReLU[16]。由于在卷积过程中不断对一维信号进行卷积操作,因此会丢失部分有用的细节特征,而引入跳跃连接,能为下一层反卷积提供细节补偿。
图4为判别模型的网络结构,主要用于训练干扰说话人的语音特征信息,其网络有2个信号输入端,最后输出为判别概率。判别模型的卷积阶段与生成模型的卷积阶段类似,不同点在于判别模型采用FCN构建一个二分类卷积网络[17],最后一层采用步长为1的1×1的卷积核进行下采样,从而将高维特征映射到一维数据上进行分类。
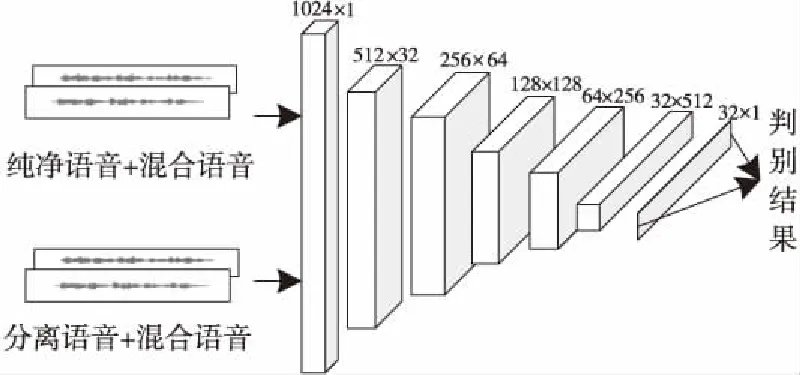
Figure 4 Network structure of discriminative model
3 实验
3.1 实验数据和评价指标
实验采用Aishell中文语音数据库[18]来进行验证。该数据库总共包含400位说话人,每人大概讲350句话,每人的说话内容互不重复。实际生活中的说话人语音混合包含男男混合(M-M)、女女混合(F-F)和男女混合(M-F) 3种情况,为此,从数据库中随机选取6位不同男性和6位不同女性的语音来构建数据集,并且每位说话人包含300句语音。构建M-M训练集时,随机选取3位男性作为目标说话人,剩余3人作为干扰说话人,每人选取250句语音,则目标说话人语音和干扰说话人语音分别为750句,然后按照0 dB,-3 dB,-6 dB,-9 dB信噪比等级进行语音混合,分别得到4组不同信噪比下各750句混合训练语音;测试集和训练集构建方式相同,将每人余下50句语音作为测试语音,分别得到不同信噪比下各150句混合测试语音。F-F数据集、M-F数据集与M-M数据集构建方式一致。
衡量语音分离性能的客观评价指标主要包括语音质量感知评估PESQ(Perceptual Evaluation of Speech Quality)[19],这是一种近似主观测听的客观指标,得分一般在1~4.5;短时客观可懂度STOI(Short-Time Objective Intelligibility)侧重于评估语音的可懂度,取值在0~1;而信噪干扰比SIR(Source to Interference Ratio)、信噪伪影比SAR(Source to Artifact Ratio)和信噪失真比SDR(Source to Distortion Ratio)这类客观指标是主要描述分离信号中仍然存在的干扰信号、噪声和失真等。
3.2 实验设置
训练集和测试集语音均在16 kHz下采样,由于语音信号具有短时平稳的特性,所以在训练前对3组不同等级信噪比的数据集进行分帧处理,其帧长设置为1 024个点,帧移512个点,最后得到每种信噪比下81 000帧训练语音和16 200帧测试语音。训练时采用RMSprop优化算法[20],其训练批次设置为50,批次大小为128,学习速率为0.000 1。整个训练流程如图5所示,其由2部分构成,第1部分是判别模型D对真样本数据对(纯净的干扰语音和混合语音)和假样本数据对(分离的干扰语音和混合语音)训练,输出分别为1和0;第2部分是生成模型G对混合语音的分离训练,这时判别模型D参数固定,输出为1。

Figure 5 Training flowing chart of SSGAN
3.3 实验结果和分析
本文选取文献[12]中基于卷积编解码器CED (Convolutional Encoder Decoder)和基于FCN的2种语音分离方法进行对比,CED和FCN的网络结构类似,不同之处在于CED通过改变损失函数将干扰说话人语音带入网络训练,而FCN只对目标说话人进行训练,为了保证本文所提方法与以上2种方法对比的有效性,在神经网络的层数和参数设置上基本保持一致;同时还对比了SSGAN在Inde-Stru和Coop-Stru 2种训练结构下的语音分离性能。
由于数据集采用分帧的形式进行训练,所以本文采用线性重叠相加合成法将测试结果还原为原始语音长度,并按5种语音性能评估方法进行打分。表1~表5分别给出了3组混合语音在不同方法下的PESQ、STOI、SAR、SDR和SIR值。其中,表1~表5均采用CED和FCN来直接表示进行对比的2种语音分离方法。从5个表中可以观察到,随着SNR减小,所有方法的分离性能都有所降低,说明了低SNR下进行语音分离是困难的。整体上对比(FCN、Inde-Stru)和(CED、Coop-Stru) 2组数据,可以看到只关注目标说话人的FCN和Inde-Stru在评价得分上明显低于同时关注目标说话人和干扰说话人的CED和Coop-Stru,并且SSGAN的2种训练结构都分别优于FCN和CED。这说明使用GAN框架的语音分离方法通过判别模型对生成模型进行微调,获得的语音特征更加准确和丰富,且在加入干扰说话人语音后,能为训练过程提供更多的分离信息。表2各组数据变化不明显,可能原因是可懂度与说话内容有很大联系,而本文所构建的训练集包含多个说话人的语音数据,在训练过程中考虑的是不同说话人的发音特征,而与说话内容没有关系,因此在STOI值无较大变化。此外,表1和表2表明,F-F的分离效果要低于M-M的,而表3~表5中F-F的得分却要好于M-M的,这是由于PESQ和STOI都是基于频域计算的,男性语音频率低于女性语音频率,表明神经网络对于高频成分的分离性能普遍较差,而Coop-Stru在一定程度上提升了对高频信息恢复的能力;但SAR、SDR和SIR是基于时域信号进行评价的,所以神经网络对女性语音幅值、相位等时域信息的恢复效果更好。M-F由于是异性语音混合,语音间的区别最大,所以分离性能最好。总体来看,无论是同性还是异性语音混合,采用Coop-Stru的SSGAN在语音分离上性能提升显著,提升了在低SNR下的分离语音质量。

Table 1 PESQ score of three groups of data under different methods

Table 2 STOI score of three groups of data under different methods

Table 3 SAR score of three groups of data under different methods
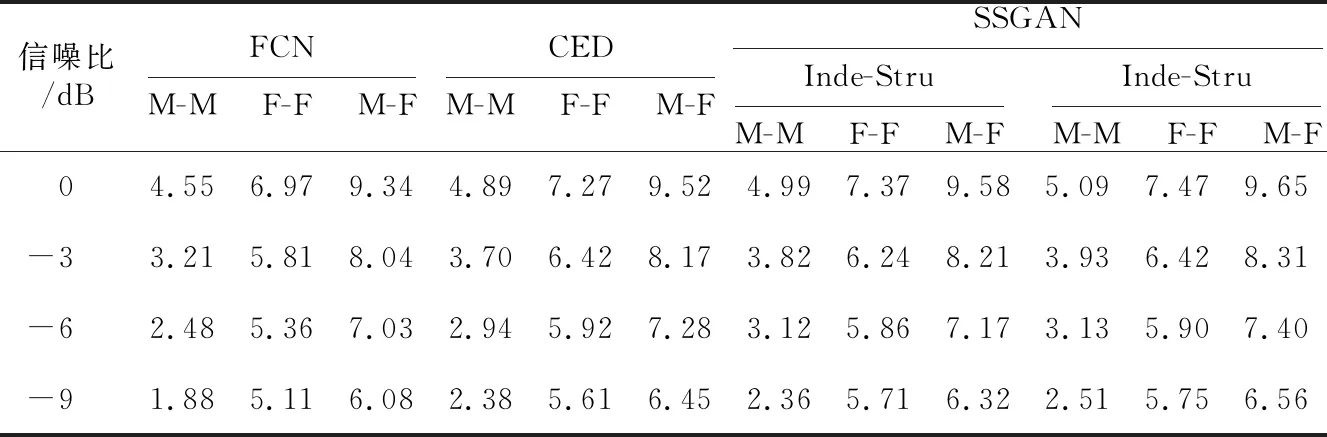
Table 4 SDR score of three groups of data under different methods
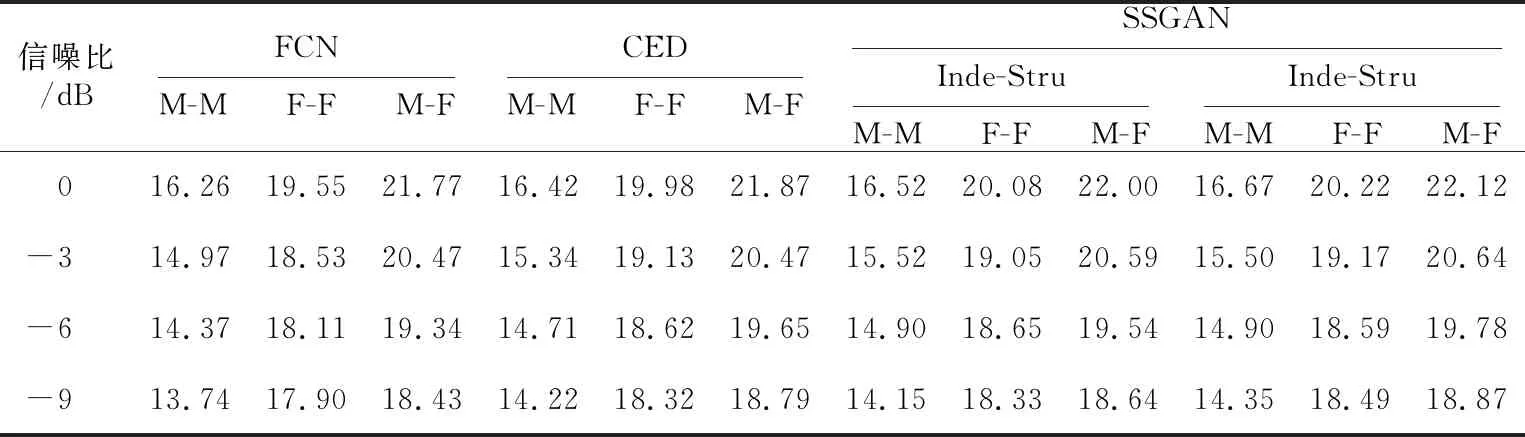
Table 5 SIR score of three groups of data under different methods

Figure 6 Separate speech spectrograms of different methods
为了验证各方法对高、低频信息的恢复能力,图6展示了M-F数据集中一句-6 dB信噪比的测试语音在不同分离方法下的语谱图。图6a和图6b分别为混合语音(Mixed)和目标说话人纯净语音(Clean)的语谱图,图6c~图6f为各方法的分离语音语谱图。
图6中,Inde_SSGAN和Coop_SSGAN分别表示采用Inde_Stru和Coop_Stru 2种结构的SSGAN。从图6中可以看到,4种分离方法对于低频部分的分离效果都要好于高频部分的,这也进一步解释了表1中M-M的PESQ得分为何高于F-F的PESQ得分。此外,可以观察到基于FCN和CED的分离方法得到的语谱图对于高频信息的恢复效果要明显差于Inde_SSGAN和Coop_SSGAN 2种分离方法的,更多高频语音细节被丢失,原因在于GAN中的判别模型在训练过程中不断向生成模型提供更丰富的细节信息,从而提升了高频语音成分的恢复效果。而SSGAN的2种结构虽然对高频语音部分信息的恢复有较好的提升,但从图框所包含的信息来看,Inde_SSGAN对部分高频细节成分恢复仍然弱于Coop_SSGAN,说明了在训练过程中加入干扰说话人的语音信息能促进GAN进行更有效的分离。
4 结束语
提高低SNR下的语音分离性能是语音分离技术的研究重点。本文提出了一种基于联合训练GAN的语音分离方法,充分利用对抗机制,使GAN在训练过程中同时考虑了目标说话人和干扰说话人的语音特征,增加了分离信息来源,提升了低SNR下的分离语音质量。在3组不同混合形式的数据集上的实验结果表明,多数神经网络对于高频信息的恢复能力较弱,而本文所提方法能有效提升对高频信息的恢复能力。未来的工作是研究更优的方法来获得低SNR下的高质量分离语音。
