基于无监督学习的无人机目标跟踪*
2021-06-25方梦华
方梦华,姜 添
(1.中国矿业大学计算机科学与技术学院,江苏 徐州 221116;2.矿山数字化教育部工程研究中心,江苏 徐州 221116)
1 引言
在计算机视觉领域,目标跟踪是一项热门的研究技术[1],在众多领域中都发挥着十分重要的作用。视觉目标跟踪的主要任务是从给定视频序列的第1帧图像中确定后续要跟踪的目标,采用特定的跟踪算法,对后续视频序列中跟踪目标的位置信息进行准确的预测。目标跟踪技术在日常生活中已经得到了普及和应用,例如视频监控等。随着计算机视觉与人工智能等技术的不断发展,复杂场景下利用无人机进行目标跟踪逐渐成为研究热点[2]。要实现无人机对目标的持续跟踪,航拍焦点就必须始终对准要跟踪的目标,因此,选择一个合适的目标跟踪技术在视觉处理系统中是非常关键的。进行目标跟踪任务时,经常会遇到跟踪的目标尺度发生变化、背景场景对目标的跟踪造成干扰、跟踪的目标发生一定的形变等诸多挑战。利用无人机进行目标跟踪时,跟踪的目标与无人机均在运动变换中,目标跟踪过程中容易出现目标被其他事物严重遮挡或者目标在画面中占比过小等问题,跟踪难度会加大,从而影响目标跟踪效果。为了解决上述问题,本文针对无人机场景下的目标跟踪进行研究。
随着计算机应用技术的发展,越来越多的学者开始利用深度学习方法进行目标跟踪[3]。Tao等人[4]提出了孪生实例搜索的目标跟踪SINT(Siamese Instance Search for Tracking)模型,首次将目标跟踪任务转换为利用孪生网络来进行匹配的问题。文献[5]提出了全卷积孪生网络SiamFc(Siamese Fully Convolutional)模型。为了实现在更大的候选图像中对跟踪目标的精准定位,该模型采用全卷积神经网络作为其主干网络,取得了不错的跟踪效果。此后有不少学者基于孪生网络设计模型对目标进行跟踪。虽然跟踪速度有一定优势,但对于跟踪的精确度,效果不是十分乐观。随后还涌现了一些跟踪性能优越的模型。针对无人机目标跟踪过程中出现的目标被遮挡、目标尺度发生变化的问题,文献[6]提出了一种基于残差网络的无人机自适应目标跟踪模型。文献[7]基于孪生网络,提出了一种自适应无人机目标跟踪网络模型,跟踪性能较好。为了解决目标遮挡以及相似背景目标对于Camshift算法的影响,Qin等人[8]对Camshift算法进行改进,结合卡尔曼滤波和多特征融合,设计了一种新的目标跟踪模型,很好地解决了之前的跟踪算法在遇到目标遮挡等干扰时,鲁棒性较差的问题。上述模型在普通的目标跟踪场景下,有较好的跟踪效果,但是针对无人机的复杂场景,跟踪效果并不十分理想。此外,很多目标跟踪模型比较依赖训练数据。当前出现的一些性能优越的深度目标跟踪模型,通常是有监督的学习,提取特征时采用的是预先训练好的卷积神经网络。现实情况是,当前的一些无人机航拍数据集并不完善,数据集中的部分数据缺乏统一标注。基于上述情况,参考基于无监督学习的视觉目标跟踪模型[9],本文将其在无人机场景下进行应用,设计了一种主干网络为轻量级网络的无监督网络模型,在训练网络模型之前不需要预先对视频数据进行标注,采用前向目标跟踪和多帧反向验证,完成无人机目标跟踪任务。
2 相关网络结构
2.1 目标跟踪网络模型SiamFc
SiamFc[5]是一种基于孪生网络结构、以全卷积神经网络作为主干网络的目标跟踪模型,如图1所示。该模型对孪生网络结构进行离线训练,实现了在一个较大的搜索区域搜索样本图像。孪生网络有2个分支卷积网络,在网络的训练阶段对其进行相似性学习。为了实现模型的实时跟踪,在目标跟踪阶段,对这种相似性关系进行在线调试,完成跟踪任务。
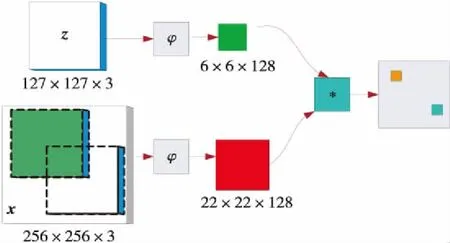
Figure 1 SiamFc network structure
采用全卷积神经网络作为跟踪模型的主干网络,样本图像的大小与样本搜索的图像区域大小可以不统一,基于这一优势,网络可以接收较大的搜索输入图像,从而更好地进行目标跟踪。SiamFc的相似度函数的计算如式(1)所示:
f(z,x)=φ(x)*φ(x)+b
(1)
其中,z为图像首帧的目标框,也就是输入的范本。x为输入的搜索图像。φ(z)和φ(x)表示对z和x进行特征提取。*是卷积运算,通过卷积运算提取z和x中最为相近的部分。b表示各个位置在得分图中的取值。在目标跟踪阶段,以上一帧目标位置为中心,计算等待搜索图像的响应得分图。当前目标的位置由步长乘以得分最大的位置得到。
SiamFc网络模型通过判别方法训练正、负样本,该模型的逻辑损失表示如式(2)所示:
I(y,v)=log(1+exp(-yv))
(2)
其中,v表示样本搜索图像中单个位置的得分值,y是取值为{-1,1}的标签,判定正负样本的方法如式(3)所示:
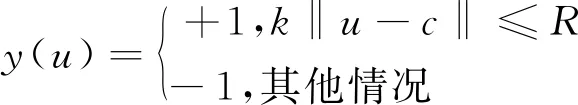
(3)
其中,u代表在得分图中的某一个位置,当得分图中u在以c为中心、R为半径的区域内时,将其视为正样本,不在该区域内则视为负样本。k是得分图经过网络后缩小的倍数。
正样本的概率值可表示为式(4)所示:
(4)
负样本的概率值可表示为式(5)所示:
(5)
网络训练阶段,对候选位置计算平均损失函数,如式(6)所示:
(6)
其中,D表示最后的得分图|D|表示得分图的大小,v(u)代表样本搜索图像在位置u处的得分值。
SiamFc训练网络的卷积参数θ采用随机梯度下降方法得到,如式(7)所示:
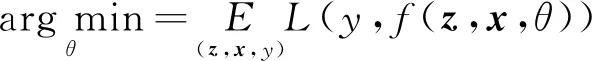
(7)
其中,(z,x)表示从带有标注的数据集中选取的训练样本,x表示搜索区域,z表示目标区域中心。在对网络进行训练的过程中,为了保持跟踪的目标宽高比不变,将超出图像的部分采用像素平均值填充。整个训练过程不考虑目标类别,但是需要保证输入网络模型的图像尺寸是统一的。
2.2 无监督网络模型UDT
无监督目标跟踪UDT(Unsupervised Deep Tracking)[10]是一种无监督的目标跟踪模型。该网络模型的无监督流程如图2所示。模型中的卷积神经网络采用无监督学习方式,对一定数量未标注的视频数据进行训练。UDT是以判别相关滤波器网络DCF Net(Discrimitive Correlation Filters Network)为主干网络结构的跟踪模型。DCF Net结合了孪生网络和判别相关滤波,融合了二者进行目标跟踪任务的优势,构建了一种轻量级的端到端的目标跟踪网络模型。UDT网络模型在训练阶段包括2个过程,即前向跟踪和反向验证。前向跟踪是指由第i帧对第i+1帧的目标位置区域进行预测。反向验证是指由第i+1帧对第i帧的目标区域的结果进行反向预测。利用这2个过程计算损失函数,从而优化跟踪性能。
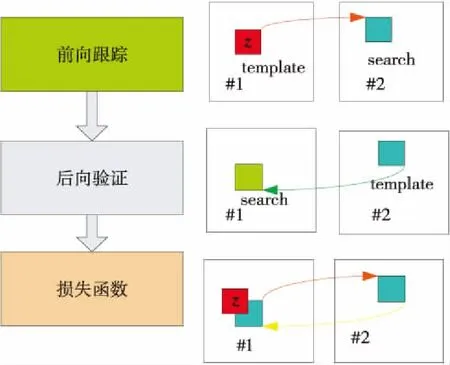
Figure 2 Process of unsupervised object tracking
3 无监督无人机目标跟踪模型
基于网络模型SiamFc和UDT无监督的目标跟踪思想,本文对前向跟踪、后向验证的跟踪方法进行改进,设计了一种新的基于无监督学习的无人机目标跟踪网络模型。原有的UDT无监督网络的主干网络是DCF Net,虽然DCF Net是一种端到端的目标跟踪网络模型,但是其实时性不如SiamFc网络。因此,本文所设计的目标跟踪网络结构,对UDT网络中的基于相关滤波的孪生网络结构进行改进,将原来的DCF Net网络替换成SiamFc网络。考虑到利用无人机进行目标跟踪,无人机自身的计算系统较小,对于大量神经网络参数的计算有一定的限制,在利用较深层数的深度网络对跟踪目标特征进行提取时,可能会出现模型跟踪性能受限、跟踪速度下降等问题。因此,本文在设计的网络模型结构中,选择SiamFc较浅的神经网络模型AlexNet替换DCF Net网络。模型主干孪生网络参数如表1所示。
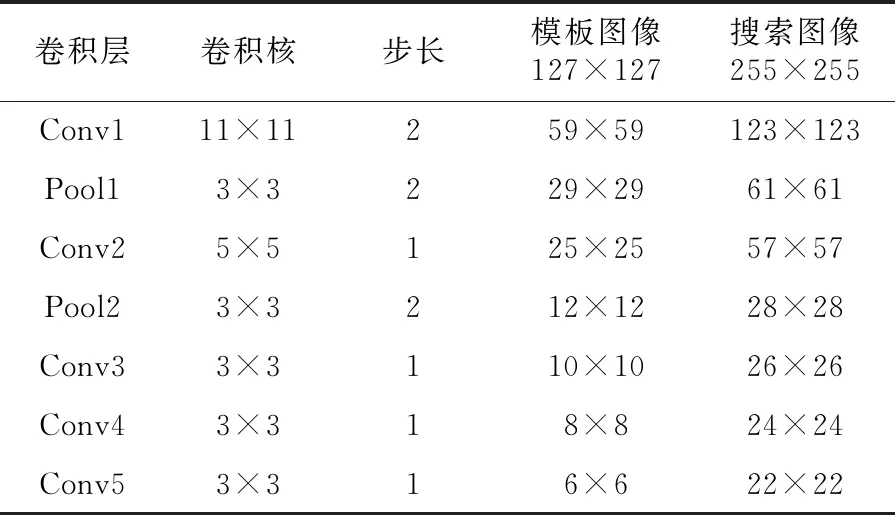
Table 1 Siamese network parameters
当前的无人机目标跟踪相关视频数据集还不够完善,这给无人机目标跟踪的研究带来了一定的困难。同时,利用无人机进行目标跟踪时,无人机所处的外部环境可能比一般环境更为复杂。基于此,本文设计了一种以SiamFc为主干网络、采用多帧验证的无监督无人机目标跟踪模型。该模型不仅在主干网络上进行了改进,使用了全卷积的孪生网络结构SiamFc,同时对前向跟踪、后向验证的无监督跟踪方法进行了改进,在无监督的网络训练阶段,通过前向跟踪、多帧验证的方式,利用无人机在复杂场景进行目标跟踪。本文设计的无监督无人机目标跟踪模型结构如图3所示。
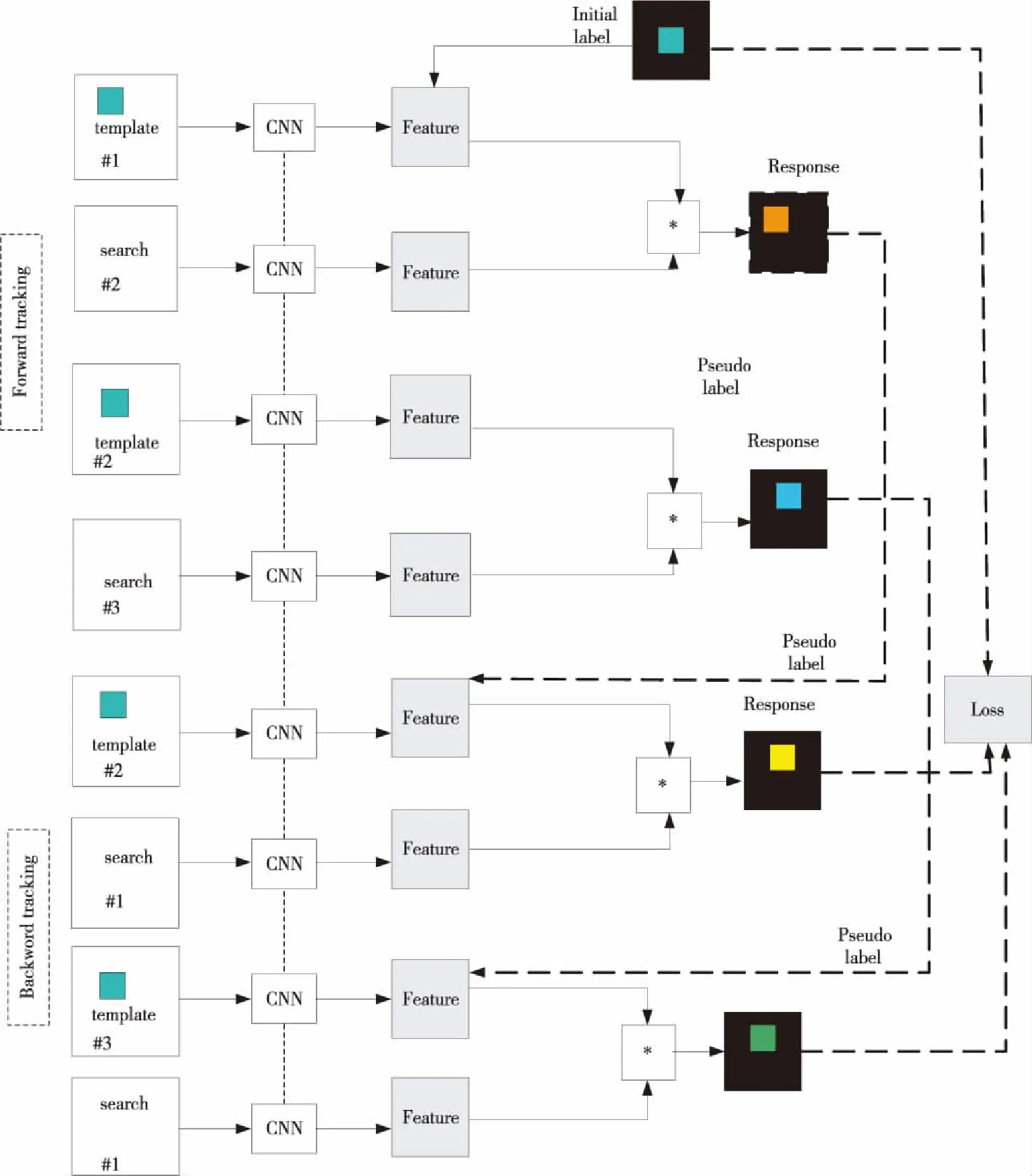
Figure 3 Unsupervised UAV target tracking model
基于SiamFc网络的目标跟踪机制以及无监督学习的前向跟踪、后向验证的目标跟踪方法,本文提出以SiamFc为主干网络、以多帧验证的方式进行无人机目标跟踪的网络模型。多帧验证的方式与后向验证不同,后向验证是以第2帧的目标跟踪结果对首帧进行预测,然后计算损失函数。多帧验证是指在前向跟踪过程中,不仅要验证第2帧图像的目标位置,还要多验证1帧图像的目标位置,才得到第3帧图像中的目标响应图。然后利用第3帧的目标跟踪结果,对首帧目标进行再次预测。采用这种方式的原因在于,无人机在航拍视频过程中,自身也在高速运动,这样会造成目标跟踪时,前向跟踪阶段目标位置的跟踪结果有所偏离。另外,无人机在高空拍摄视频,跟踪的目标较小,受到的背景干扰较多。无人机相关的视频数据集中可能包含了较多的背景信息,在一定程度上会对目标跟踪的性能产生影响。更严重的情况是,跟踪的目标可能被障碍物遮挡,出现目标堵塞的情况,也会对整个目标跟踪任务产生影响。因此,本文设计的网络模型在后向验证时,采取多帧验证的方式,提高利用无人机进行目标跟踪的性能。

(8)
其中,YT表示第1帧图像。
4 实验结果与分析
本文设计的无监督无人机目标跟踪模型在目标特征提取阶段采用AlexNet网络,通过Image- Net VID数据集训练无监督的网络结构。设计的模型采用孪生网络结构,目标区域分支与搜索区域分支共享参数。本文通过100个周期训练网络结构,设置学习率的初始值为0.01。

Figure 4 Comparison of tracking results between the proposed model and the classic models
为了验证设计的目标跟踪模型的跟踪性能,选取了目标跟踪模型SiamFc[5]和高效卷积算子ECO(Efficient Convolution Operators)[11]进行对比实验。同时,为了证明所设计的模型优于原UDT模型的跟踪性能,将其与原UDT模型进行对比实验。为了方便对比多帧验证方式和后向验证方式,首先将UDT模型的主干网络修改为SiamFc(简称为UDT-S),与本文设计的跟踪模型进行对比实验。综上,一共选取了4种模型作为基准模型,与本文设计的目标跟踪模型进行对比实验。采用VisDrone2019数据集中的视频序列作为实验的数据集,通过对比部分视频序列的目标跟踪结果评估不同的目标跟踪模型。
(1)定性分析。
采用无人机的一些航拍视频数据,将本文提出的模型与其他2种跟踪模型进行对比实验。目标在当前帧的跟踪结果通过图4中不同颜色的矩形框表示。图4中,每1行图像代表1个视频序列。黑色矩形框表示的是本文模型的跟踪结果。ECO和SiamFc的分别用白色框和灰色框表示。
对比图4中目标跟踪结果可知,在第1个无人机视频序列中,由于跟踪的目标自身较小,并且其在不断的运动中尺度发生了变化,ECO模型在跟踪过程中出现了目标丢失情况,而本文设计的无监督无人机跟踪模型和SiamFc模型只是产生了一定程度的跟踪漂移。在第2个视频序列中,因为目标所处环境相对空旷,没有过多的背景等环境影响,无监督无人机目标跟踪模型与另外2种对比模型均较好地跟踪了目标。对于第3个视频序列,由于跟踪的目标在不断移动,ECO模型对目标的跟踪出现了错误,SiamFc模型对于目标的跟踪也发生了一定的跟踪漂移,但是本文设计的模型却较好地跟踪了目标。对于第4个视频序列,无人机飞行高度较高、跟踪的目标相对较小,同时目标处于快速运动中,发生了一定程度的目标形变,影响了跟踪任务的进行,因此几种模型的跟踪表现均不是很好,但是对比可以发现,本文模型仍比其他2种模型跟踪的效果要好一些。总的来说,面对实际应用中无人机目标跟踪出现的各种问题,本文提出的模型在整体性能上优于其他2种典型的跟踪模型。
图5显示了本文设计的算法和原UDT模型、UDT-S模型对4个视频序列的目标跟踪效果对比。其中,黑色框表示本文设计的模型的跟踪效果,白色框表示原UDT模型的效果,UDT-S模型跟踪效果由灰色框表示。

Figure 5 Comparison of the tracking results of the proposed model and the before improvement
对比图5中的目标跟踪结果可以发现,对于第1个无人机视频序列,目标所处背景较为复杂,UDT模型和UDT-S均出现了一定的跟踪漂移情况,相比之下,本文设计的模型则较好地跟踪到了目标。与第1个视频序列相比,第2个视频序列中的目标较为明显,从跟踪结果可以看出,3种模型均较好地跟踪了目标。在第3个视频序列中,本文设计的目标跟踪模型和UDT-S都较好地跟踪了目标,UDT模型出现了一定程度的跟踪漂移。在最后一个视频序列中,UDT和UDT-S的跟踪表现均不是很好,本文设计的模型虽然出现了一定程度的跟踪漂移,但也实现了对目标的跟踪,整体效果比其他2种模型要好。综合4个视频序列的跟踪结果可以得出,改进后的模型比改进之前的UDT模型以及后向验证模型跟踪性能更加优越。
(2)定量分析。
目标跟踪模型通常利用中心位置误差和区域重叠面积比率[12]2个指标进行评价。
中心位置误差计算方法如式(9)所示。假设目标的中心位置为(x0,y0),跟踪到的目标位置为(x,y),中心位置误差是通过计算人工标注的目标框与跟踪模型跟踪到的目标框中心位置之间的欧氏距离得到的。
(9)
error值越小,表明跟踪性能越好,越能精确地跟踪到目标。本文对不同模型跟踪的中心位置误差进行了计算,得到它们分别针对4个视频序列的平均中心位置误差,如表2所示。
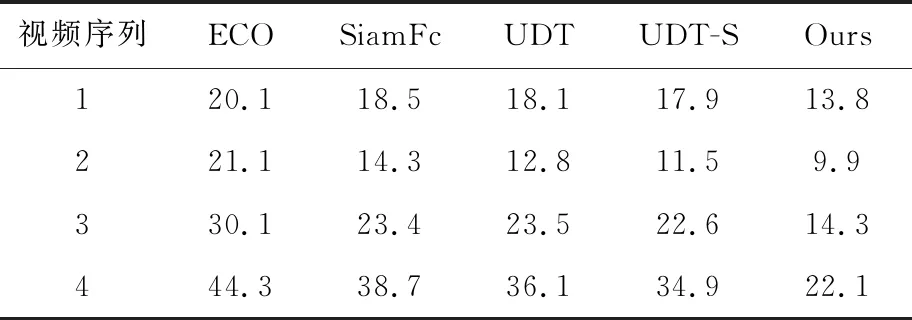
Table 2 Average center location error
区域重叠面积比计算方法如式(10)所示:
(10)
其中,Rg表示人工标注区域,Rr表示跟踪模型预测的边界区域,∩是交集,∪是并集。不同模型计算的面积重叠比如表3所示。
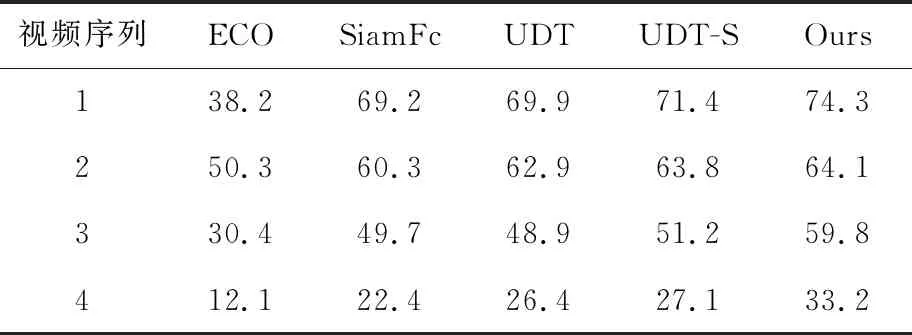
Table 3 Average overlap
由表2和表3可以看出,在视频序列1中,对于平均中心位置误差而言,ECO模型跟踪结果的平均误差最大,本文设计的模型平均误差最小,其他3种模型平均误差之间的差别相对较小。关于另一个平均区域重叠面积比率指标,ECO模型的区域重叠面积比率较低,其他4种模型的区域重叠面积比率远高于它,这是因为ECO在后面的视频跟踪图中出现了跟踪目标丢失的情况。对比SiamFc、UDT、UDT-S和本文设计的模型的区域重叠面积比率,本文设计的模型区域重叠面积比率最大。在视频序列2中,对比5种模型的平均中心位置误差值,本文设计的模型误差值最小。对比5种模型的平均区域重叠面积比率,SiamFc、UDT、UDT-S和本文设计的模型均达到了60%以上,但是本文模型仍然以微小的优势胜出。对于视频序列3,5种模型的平均中心位置误差均高于它们对视频序列2的误差值,这是因为视频序列2的目标移动幅度小,所以跟踪效果比视频序列3中的目标要好一些。对比5种模型的平均中心位置误差值,本文设计的模型占有很大的优势。在平均区域重叠面积比率方面,也是本文设计的模型好于其他4种跟踪模型。在视频序列4中,目标快速运动,发生了形变,整个视频图像中的跟踪目标过小,直接影响了所有跟踪模型的性能,所以5种模型的平均区域重叠面积比率均较小,但是相比而言,本文模型在2个评价指标上均优于其他4种模型。对于4个视频序列,本文设计的无人机目标跟踪模型平均区域重叠面积比率大,平均中心位置误差相对均较小,相对于改进前的UDT模型在2个评价指标上的表现均较好。对比UDT-S模型,本文设计的多帧验证无人机跟踪模型在2个评价指标上的表现均比较优越,可见对于复杂场景下的目标跟踪而言,使用多帧验证的无监督目标跟踪模型较后向验证效果更好。总的来说,本文设计的无监督的无人机目标跟踪模型比ECO、SiamFc、UDT、UDT-S这4种跟踪模型跟踪性能更加优越。
5 结束语
针对无人机相关航拍数据集中数据不完善、部分数据缺乏标注等问题,本文提出了一种无监督无人机目标跟踪网络模型,采用前向跟踪、多帧验证的方式来对无监督的网络模型进行训练。另外,考虑到无人机系统计算能力有限这一情况,采用了轻量级网络结构进行特征提取,从而更好地完成无人机的目标跟踪任务。为了验证本文设计的模型对于目标跟踪的性能,选取无人机航拍视频序列进行实验,将其与其他典型模型的目标跟踪效果进行对比,同时对比改进前的模型跟踪效果。定性分析和定量分析的结果表明,本文设计的无监督无人机目标跟踪模型跟踪性能优于其他跟踪模型和改进之前的模型,能够较好地实现无人机场景下的目标跟踪。当然,这个模型也存在一定的不足之处。如果视频数据集中的正负样本不平衡,模型的跟踪性能会受到一定的影响。此外,因为考虑到无人机系统自身计算性能限制,本文设计的模型采用的是较浅层的神经网络结构,对于目标深层特征的提取也是有限制的,未来在网络结构上也需要进一步改进。
