基于深度监督的跨模态图文检索方法研究
2021-06-24徐慧铭
焦 隆, 徐慧铭, 程 海
(黑龙江大学 电子工程学院, 哈尔滨 150080)
0 引 言
随着互联网文本、视频和图片等不同类型媒体数据的快速增长,跨模态检索在现实应用中变得越来越重要。跨模态检索旨在实现不同数据模式之间的灵活检索,它将一种类型的数据作为查询,来检索另一种类型的相关数据[1]。跨模态搜索结果有助于用户获取有关目标事件或主题的全面信息。跨模态学习方法可分为二值表示学习和实值表示学习两类[2]。文献[3]利用二值表示方法提高计算效率,并将异构数据映射到一个共同的汉明空间中,跨模态检索速度更快。由于表示学习被编码为二进制码,检索精度通常会因信息丢失而略有下降。实值表示学习方法包括无监督方法、成对方法和有监督方法。文献[4]使用无监督方法,利用多媒体文档中共存的信息来学习不同类型的共同表示。文献[5]使用成对的方法,利用更多相似的图像文本对来学习公共表示,比较来自不同模态的样本。文献[6]使用有监督方法,利用标签信息来区别不同类别的信息。尽管这些方法已经使用了分类信息,但分类信息仅用于学习每种模态中或多模态之间的区别特征,并没有充分利用语义信息。文献[7]使用典型相关分析CCA方法,通过最大化两组异构数据之间的成对相关性来学习公共空间。然而,多媒体数据之间的关联过于复杂,无法通过应用线性投影来完全建模。文献[8]提出了一种基于深度卷积神经网络和神经语言模型的多模态深度神经网络,分别学习图像模态和文本模态的映射函数。利用样本的标签分类信息来学习图像和文本的模态内语义特征,随着多媒体数据的不断增长,采用一般深度学习的特征表示,由于维数过大而面临储存空间与检索效率的挑战,导致无法适应大规模多媒体数据检索任务。
本文提出了基于深度监督跨模态检索方法,保持不同语义类别样本之间的区别,同时消除跨模态差异。将样本在标签空间和公共表示空间中的判别损失最小化,以监督模型学习鉴别特征。此外,最小化了模态不变性损失,并使用权重共享策略来学习公共表示空间中的模态变化特征,在这种学习策略下,充分利用了分类信息和语义信息。利用新增的数据集对改进的模型进行调参优化,提高了图文检索的准确率,实验证明所改进的算法在平均精度值上优于现有图文检索算法。
1 图文检索数据特点
1.1 跨模态检索函数表示
双模数据的跨模态检索即图像和文本的跨模态检索。把图像-文本对的实例集合映射为函数表达式:
(1)


由于图像特征向量和文本特征向量通常具有不同的统计特性,并且位于不同的表示空间中,所以它们不能在跨模态检索中互相直接比较。利用交叉模态学习可以得到这两种不同模态的函数,图像模态的函数表示为:
(2)
文本模态的函数表示为:
(3)
式中:d为表示公共空间的维数;γα和γβ为两个函数的可训练参数,可以使不同数据模态的样本直接进行比较。
在公共空间中,同一种类别样本的相似度大于不同种类别样本的相似度。因此,可以利用返回数据集中不同数据类型的相关样本来查询数据类型。将ω中实例的图像、文本和标签用矩阵表示,分别为U=[u1,u2,…,un]、V=[v1,v2,…,vn]和Y=[y1,y2,…,yn]。
1.2 VGGNet和Word2V-ec模型
卷积神经网络(Convolutional neural network,CNN)是一种前馈神经网络[9],本文跨模态图文检索网络模型采用经典的卷积神经网络VGGNet网络结构来提取图像和文本的特征[10]。小卷积核是VGGNet的重要特点,使用多个较小的卷积核代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合能力。在训练高级别的网络时,可以先训练低级别的网络,用前者获得的权重初始化高级别的网络,可以加速网络的收敛。
文本模态的公共表示学习采用了Word2V-ec模型,包含Skip-grams(SG)和Continuous bag of words(CBOW)两种算法。通过训练模型,保留模型中的一部分权重参数,来获得词向量。Skip-gram根据中心词预测周围的词,模型如图1所示。可以看出,SG模型预测的是p(wt-2|wt),p(wt-1|wt), …,p(wt+2|wt),由于图中词wt前后只取了各2个词,所以窗口的总大小是2。假设词ωt前后各取k个词,即窗口的大小是k,那么SG模型预测的将是p(wt+p|wt)(-k≤p≤k,k≠0)。
CBOW根据周围的词预测中心的词语,模型如图2所示,CBOW与神经网络语言模型不同的是去掉了最耗时的非线性隐藏层。模型预测的是p(wt|wt-2,wt-1,wt+1,wt+2),由于图中目标词wt前后只取了2个词,所以窗口的总大小是2。假设目标词wt前后各取k个词,即窗口大小是k,那么模型预测将是p(wt,wt-(k-1),…,wt+1,…,wt+(k-1),wt+k)。
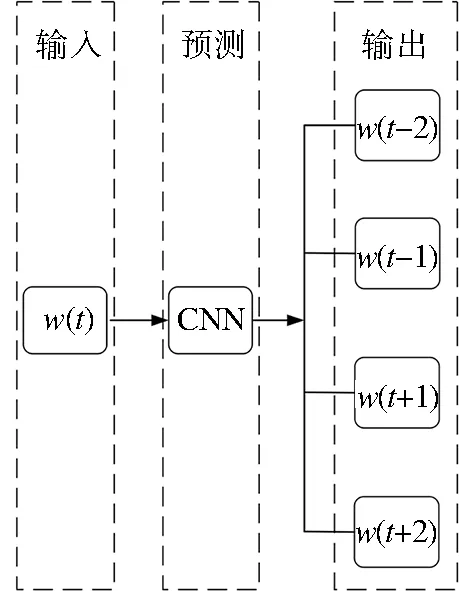
图1 SG模型
2 设计与实现
2.1 跨模态图文检索的网络结构
跨模态图文检索方法的总体框架如图3所示,其中包括两个子网络:一个子网络用于图像模态,另一个子网络用于文本模态,它们都是以端到端的方式进行训练。图像子网络通过深度卷积神经网络VGGNet生成4 096维特征向量作为图像的原始高层语义表示,进行公共表示学习,得到每个图像的公共表示。采用Word2V-ec模型将文本矩阵输入到与文本CNN[11]配置相同的卷积层,生成文本的原始高层语义表示,可以进行公共学习表示。为了确保这两个子网络学习图像和文本是共同的表示空间,强制两个子网络共享最后一层的权重。最后,假设空间中的公共表示是在理想分类的基础上,将参数矩阵为p的线性分类器连接到这两个子网络中,利用标签信息学习判别特征。因此,可以很好地学习交叉模态相关信息,提取判别特征。

图3 方法总体框架
2.2 损失函数的设计
基于深度监督跨模态检索的目标是学习数据的语义结构,即学习一个公共空间,其中来自同一语义类别的样本应该是相似的,即使这些数据可能来自不同的形式。来自不同语义类别的样本应该是不同的,为了了解多媒体数据的鉴别特征,提出在标签空间和公共标识空间中最小化鉴别损失,通过最小化每一个图像-文本对表示之间的距离,以减少交叉模式的差异。为了保持特征投影后不同类别样本的区分性,假设公共表示是理想的分类,并使用线性分类器来预测投影在公共表示空间中的样本语义标签,在图像模态网络和文本模态网络的顶部连接线性层。分类器利用训练数据在公共空间中表示,为每个样本生成一个c维向量的预测标签。引入不同的损失函数来优化模型,标签空间中的判别损失函数为:
(4)
公共空间中的判别损失函数为:
(5)
模态不变性损失函数为:
(6)
结合方程得出总损失函数为:
μ=μ1+Aμ2+Bμ3
(7)
式中:超参数A和B控制最后两个分量对模型的影响;n是输入实例的数目,函数采用随机梯度下降算法进行优化[12]。
3 实验测试与分析
3.1 数据集训练
采用交叉模态数据集作为训练数据集,Pascal sentence数据集包含1 000幅图像,共20个图像类别,每个图像都对应有描述图像内容的英文文本[13],如图4所示。在此基础上增加了5个不同类别的数据集,每个类别包含50幅图像和对应的英文文本,新增后的数据集共有1 250幅图像,25个图像类别。将新增后的数据集按照4∶ 1的比例将数据集分为训练集和测试集,其中1 000幅图像用于跨模态图文检索网络模型的训练学习,250幅图像用于测试检索准确率试验。

图4 Pascal sentence数据集示意图
在训练模型时,用大小不同的随机数对网络的权值和阈值进行初始化。选用5种新增的图文数据集进行训练调参和优化模型,训练过程中各参数的变化对训练准确率的影响曲线如图5和图6所示。可以看出Batchsize对准确率的影响,迭代次数相同、在Batchsize=100时,准确率达到最大稳定值。在调整学习率参数时,Learning_rate为0.1、0.01和0.00 1时都出现了因学习率过大导致无法正常收敛的问题。由图6可知,在Learning_rate=0.000 1时,准确率更高,收敛性最好。在参数选择时,Batchsize为100,学习率为0.000 1时,在训练过程中会达到最优权重。经过多次的调参训练,模型的主要参数设置如表1所示,参数的设置是由多次训练保存最优模型时确定的。

表1 主要参数设置

图5 不同训练批次的训练准确率
将整个Pascal sentence数据集放到模型中训练,自动提取学习特征,训练的准确率如图7所示,损失率如图8所示。可以看出,随着迭代次数的增加,准确率增加,最后达到稳定状态。损失率恰恰相反。随着训练的次数不断增加,准确率最高为98.2%,实验证明本文的跨模态图文检索模型检测效果很好。
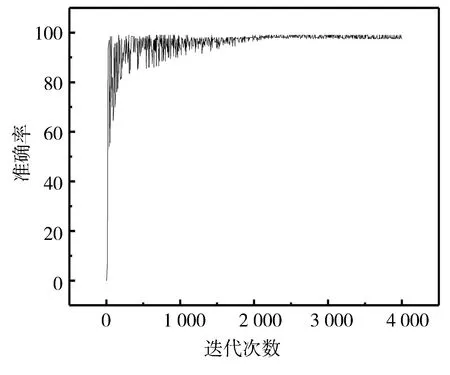
图7 Pascal sentence数据集的训练准确率
3.2 损失函数实验
通过实验测试所研究的损失函数对算法性能的影响,损失函数主要由三部分组成,分别是公共空间中的模态不变性损失μ1、公共空间中的判别损失μ2和最小化标签空间中的判别损失μ3。为了综合评估本算法相关的性能,执行了两个模式检索任务:图像检索文本和文本检索图像。平均精度值MAP综合考虑了排序信息和精度,是跨模态检索研究中广泛使用的性能评价标准[14]。本文采用平均精度值MAP作为评价指标,对所改进的损失函数进行消融实验,分别测试了没有模态不变性损失函数μ1的模型1、没有公共空间中判别损失函数μ2的模型2和没有标签空间中判别损失函数μ3的模型3,并与完整模型在Pascal sentence数据集上平均精度值(MAP)对比,最高分数以黑色字体显示,如表2所示。可以看出,完整的目标函数在数据集上表现的最好。通过数据分析发现,在目标函数中同时考虑识别损失和模态不变性损失是一种有价值的多模态学习策略。
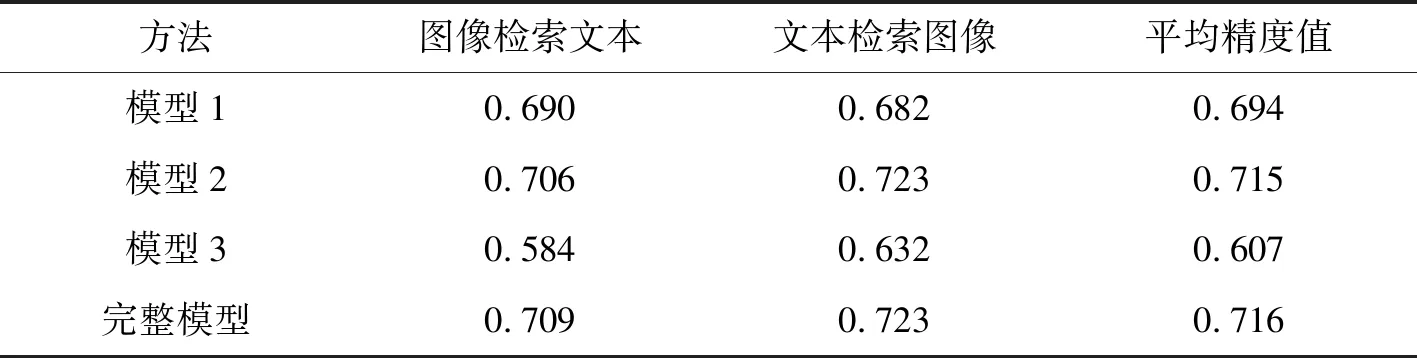
表2 不同模型的MAP值
3.3 对比实验及测试结果
在新增后的Pascal sentence数据集上,使用平均精度值(MAP)对3种现有的图文检索算法进行性能评估。本算法与传统的图文检索算法CCA[7]、基于深度学习的图文检索算法DCCA[15]和ACMR[1]等不同类型的图文检索算法进行对比,结果如表3所示。可以看出,基于深度学习的DCCA和ACMR算法在数据集中测试的平均精度值远高于传统算法CCA。实验表明,改进的算法比DCCA和ACMR的平均精度值分别提升了5.6%和6.2%,改进后算法的性能优于传统算法和现有基于深度学习的算法。

表3 不同方法的MAP值
测试方法是在Pascal sentence数据集中的测试集上随机进行的。由图像检索文本,检测结果是返回与图像内容匹配度最高的3个英文文本,如表4所示。由文本检索图像,检测结果是返回与文本内容匹配度最高的3个图像,如表5所示。可以看出,本文改进算法的识别分类是有效的,能够准确地返回图文内容相互匹配的结果。

表4 图像检索文本结果

表5 文本检索图像结果
4 结 论
针对基于深度监督的跨模态检索网络结构设计与优化作了深入研究。对于跨模态检索,所学习的公共表示既可以是有区别性的,也可以是模态不变的。通过在公共表示空间和标签空间最小化判别损失和模态不变性损失来实现这个目标。利用卷积神经网络对新增的数据集进行训练学习,对算法进行多次调整参数,得到最优网络模型。通过数据集进行验证测试,实现了图文检索内容的相互匹配,对比现有其他图文检索的模型,本方法的平均精度值更高,性能更好。所改进的模型不仅可以应用于图像和文本两种模态的跨模态检索,可以涉及到更多的模态,如音频和视频等,也可以应用到智慧医疗和脑科学等领域。
