基于元度量学习的低资源语音识别
2021-06-24侯俊龙潘文林
侯俊龙, 潘文林
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
语音是人类学习和生活的重要交流工具,也是各民族文化传承与发展的重要载体.随着近年来大数据及设备超强运算能力的出现,各种各样的人机交互式智能产品(如智能家居、智能音箱等)逐渐走进每个家庭,给人们的生活带来了极大便利.但对于一款实用的智能化产品来说,便捷高效的人机交互方式必不可少.语音作为语言的声学表现形式,被认为是当前人类最简单、最直接的交流方式,利用语音进行人机交互极有可能成为未来智能化产品的主要交互方式.
语音识别(speech recognition)的目标是让机器理解人类语音信号并作出相应回应,它是实现语音交互的关键技术,自20世纪50年代提出以来便日益成为人工智能领域的研究热点[1].经典的研究工作有: Graves等[2]在2013年提出使用循环神经网络进行语音识别,其模型在TIMIT音素识别中取得了较好的识别效果;次年他们又提出了端到端语音识别系统,模型的泛化性能得到了更进一步的提升[3];2016年百度提出了端到端的深度学习方法,能够很好的识别出汉语或英语[4];同年微软提出结合使用LSTM和卷积神经网络来进行语音识别,其精度达到了人类识别效果[5].但从可见文献看来,现有研究工作大多局限于汉语或英语等国际主流语言,究其原因是这些语言资源丰富,在语音识别研究中很容易获取到大量语料用于模型训练.然而,在当前参差不齐的语言环境下,很多民族语言正处于濒临消亡的危险境地.根据民族语言网(ethnologue:language of the world)统计,截至2020年10月全球现存7 117种语言,其中约40%语言使用者较少,被称为低资源语言[6].在语音识别研究中,低资源语言常因使用人口基数少、覆盖范围小使得语料采集的难度加大、成本升高,很难获取到足够语料用于模型训练.在这种数据量过少或不足情况下,选用传统深度学习方法进行语音识别很容易出现模型过拟合[7].因此,如何进行低资源语音识别逐渐成为了人工智能领域一项亟待解决的问题.
低资源语音识别研究起步相对较晚,其中比较有代表性的研究工作有:王俊超等[8]在2018年提出采用迁移学习方法进行低资源维吾尔语语音识别,取得了很好的识别效果;同年12月,孙杰等[9]提出跨语种的CMN声学模型来对低资源柯尔克孜语进行语音识别,其模型具有比同级CNN网络更好的泛化性能;去年,Xu等人研发出了一个能够用于低资源环境的语音识别系统,他们先用具有丰富数据资源的语言对模型进行预训练,完成后再在目标语言上微调模型,其实验结果表明该方法能够让模型在目标任务上取得较为理想的识别效果[10].采用迁移学习方法对低资源语言语音进行识别虽然能够让模型泛化性能得到一定提升,但该方法的使用通常需要提前准备两个甚至更多的大规模语料库用于模型训练,这将带来大量的人力、物力及财力耗费.随后,人们还提出采用数据增强技术来解决低资源环境下声学模型难以训练的问题,该技术旨在通过某种算法来扩增样本数量及其多样性以使模型能够得到充分训练.该方法虽然能够在一定程度上缓解模型的过拟合问题,但却并未让小样本学习问题得到完全解决[11].最近,学术界不少研究学者受到人类学习能力的启发提出了一种基于元学习的小样本学习方法,该方法能够让模型学会如何从少量数据中快速获取新知识,现已在图像处理[12]、文本分类[13]、植物病害识别[14]等诸多领域得到了成功应用.低资源语音识别由于缺乏足够的语音语料通常很难让模型得到充分训练,进而导致语音识别精度较低.为了有效解决低资源语音的难识别问题,很多语音学研究员也开始尝试将元学习方法用于小样本语音识别研究,较为经典的研究工作有:王璐等[15]探究表明了元学习方法有助于解决小规模语料的语音识别问题;王翠等[16]提出采用MAML算法对佤语孤立词语音进行识别,其模型在小样本孤立词语音识别任务中取得了较高的识别精度;2019年10月,国外学者Koluguri等[17]将元学习方法用于儿童-成人语音分类,其模型在儿童-成人语音数据集上取得了比传统深度学习方法更好的分类效果;此外,华为诺亚方舟实验室研究员Tian等次年8月提出采用Reptile算法对低资源环境下的口语语音进行识别,其实验结果表明Reptile算法在低资源语音识别任务中具有比传统梯度下降算法更强的泛化能力[18].元学习是通过模拟人类学习方式来处理不同学习任务的一种方法,从日常的学习和生活中发现人类自出生时起便拥有非常强的比较学习能力,人们能够借助这种能力来分辨不同物体.受此启发,本文将在低资源环境下选取佤语和普米语作为研究对象,开展基于元度量学习的低资源语音识别研究.
1 相关理论
1.1 小样本学习
小样本学习本是人类所特有的一种学习能力,它是指人类能够从少量的样本中快速学习新的概念.譬如,人类在只观察过较少的猫狗图片后,当新的猫狗图像出现时,人们就能够利用从少量数据中学到的经验来对新样本进行识别.但对于机器而言,要学习处理一个特定的分类或识别任务通常需要成千上万条数据进行反复训练,如果拥有的数据量过少或不足,其学习能力还会受到严重限制.最近,受到人类小样本学习能力的启发,人们对机器小样本学习的兴趣也愈发浓厚,他们渴望机器能够以人类学习方式利用有限数据资源进行学习,即机器小样本学习[19].截至目前,深度学习领域对小样本学习问题的划分大致有如下3类:1)零样本学习(zero-shot learning)[20-21];2)单样本学习(one-shot learning)[22-23];3)少样本学习(few-shot learning)[24].
在小样本学习中,人们普遍面临的问题是如何克服模型因数据量过少或不足所带来的严重过拟合问题.早期,为了避免模型过度拟合、提升模型表达能力,人们提出采用手动数据增强技术来扩增样本数量及其多样性[25].这种方式虽然能够缓解模型过拟合,但也不可避免的加大了数据处理成本,并且很难普适所有数据.随后谷歌研究学者受AutoML启发提出了自动数据增强方法,其模型在不同数据集上均表现出了超强的泛化能力[26].使用数据增强虽然能扩增一定量数据,但随着数据量的不断增加,模型对设备运算能力的要求也越来越高.此外,在零样本或单样本学习任务中,仅仅使用数据增强技术很难完全解决小样本学习问题.而后,为了更好的解决小样本学习问题,不少研究学者开始了元学习方法的研究,它被认为是当前解决小样本学习问题最为有效的一种方法.
1.2 元学习
元学习(meta learning),亦称学会学习(learning to learn),是近期人工智能领域的一个新兴研究方向[27].它与传统的深度学习方法不同,常规深度学习是利用大量的标注数据来对模型进行训练,旨在让训练好的模型能够在特定任务上具有较强的泛化能力.而元学习则旨在让模型从大量任务中学习如何解决问题,也就是希望模型能够从一系列不相交任务中获取某种共性知识来指导新任务学习.因此,在元学习中通常需要提前准备大量类似且不相交任务用于模型训练,每个任务均包含训练集(支持集)和测试集(查询集).此外,还需将生成的所有任务划分为元训练数据(Dτi)和元测试数据(Dτj),其中Dτi∩Dτj=Φ.
1.3 元度量学习
元度量学习旨让模型从大量任务中学习如何比较样本的相似性,它是借助最近邻算法的思想来处理不同的学习任务.其实现过程是先将支持集与查询集样本投影至一个度量空间,随后选用某个度量函数计算出支持集与查询集样本的相似性,最后通过最近邻算法来预测未知样本的类别标签,其定义如(式1)所示.
(1)
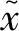
在小样本物体分类或识别任务中,元度量学习方法旨在通过最近邻思想从大量任务中训练出一个具有较强泛化性能的通用神经网络模型,使其在不同的学习任务中能够提取出具有较强表征能力的样本特征,随后通过选取某个度量函数来对样本特征进行比较以完成相应的分类或识别任务.元度量学习中选用不同的度量函数能够得到不同网络模型,其中比较常见的相似性度量函数有余弦距离[28]、欧式距离[29]或马氏距离[30].这类距离函数虽然能够合理地反映出物体的相似程度,但由于其度量方式过于单一,通常很难普适所有问题.为此,不少研究学者还提出使用可学习的神经网络来度量样本的相似性[31-32].
2 元度量学习网络
元度量学习算法旨在让模型能够从大量类似但不相交任务中学习如何比较样本的相似性,当新的学习任务出现时,模型只需通过对样本特征进行比较即可完成相应的分类或识别任务.元度量学习网络通常由嵌入模块和度量模块2部分组成,前者主要用于提取输入数据的深层特征,根据数据类型的不同可选用卷积神经网络或循环神经网络;而度量模块则主要用于测算不同任务中支持集样本与查询集样本的相似性.其框架结构如图1所示.
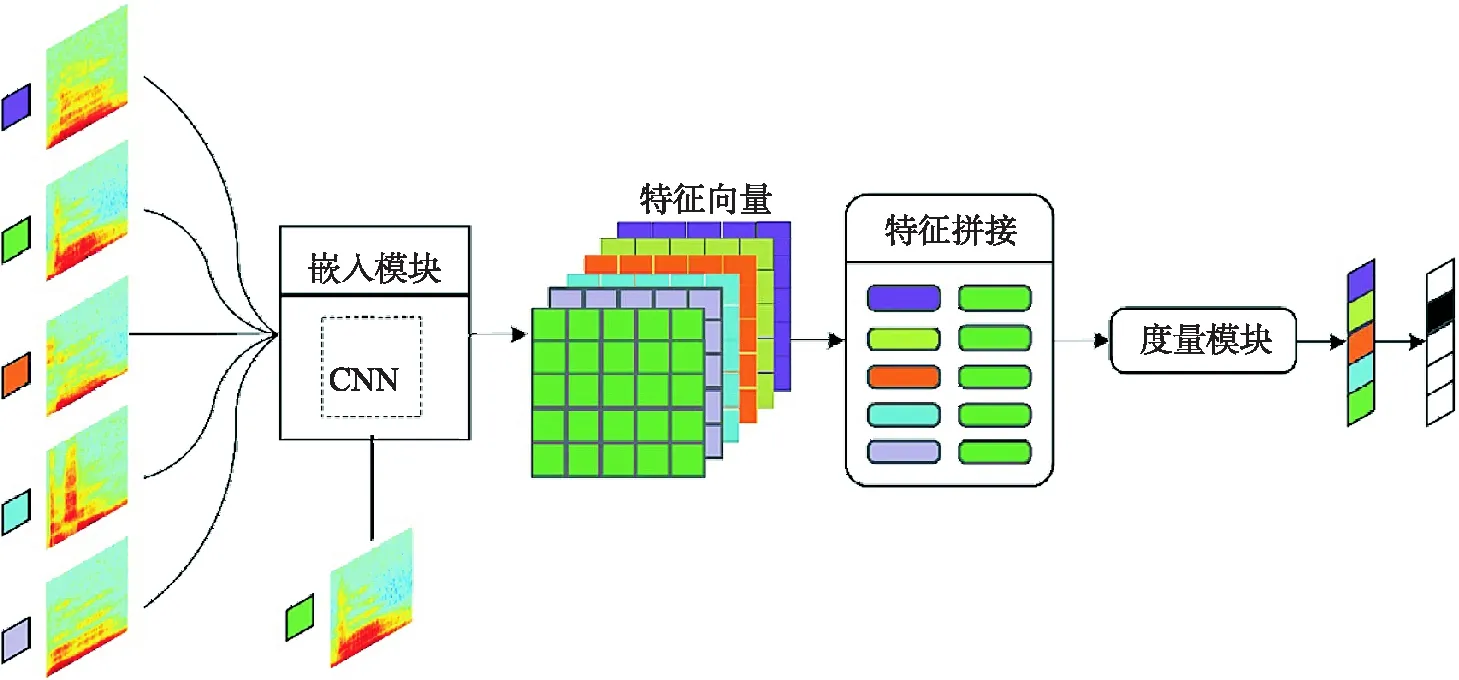
图1 元度量学习网络框架结构
当前极具代表性的元度量学习网络主要包括原型网络(prototypical network,P-Net)、关系网络(relation network, R-Net)及其变体.P-Net与R-Net的组成结构如图2所示,图中S表示支持集,Q为查询集,μ为支持集中各类样本的特征均值,即类原型.
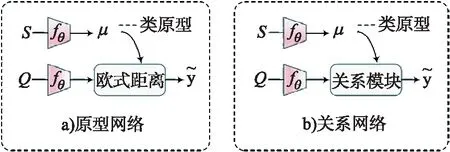
图2 P-Net 与R-Net 框架组成
图2中关系网络是在原型网络基础上进行改进所得,其框架结构非常相似.P-Net与R-Net的嵌入模块选用同一深度神经网络fθ来对输入数据进行特征提取,二者均选择将提取出的支持集样本特征按类求取平均值并将其表示为类原型μ.二者的不同之处在于原型网络是选用单一且固定的欧式距离函数作为分类器,而关系网则改用一个可学习的浅层神经网络(关系模块)来度量样本的相似性.
2.1 元度量学习网络优化过程
在小样本学习任务中,不同的元度量学习算法其实现过程大致相同,本文将以关系网络为例详细介绍元度量学习网络的优化过程,其实现过程描述如下:
1) 先从大量任务中随机采样一批任务输入到嵌入模块提取出支持集样本与查询集样本的特征fθ(xi)和fθ(xj).
2) 随后对支持集样本特征按类求取平均值得到各类原型μi,计算过程如式(2)所示.
(2)
3) 接着将各类原型分别与查询集样本进行特征拼接形成组合特征如式(3)所示.
Z=μi⊕fθ(xj).
(3)
4) 最后再将拼接而成的组合特征输入到关系模块Rφ,该模块通过一个可学习神经网络来计算支持集与查询集样本的相似度ri,j,计算过程如式(4)所示.
ri,j=Rφ(Z)=Rφ(μi+fθ(xj)).
(4)
5) 在关系网络训练过程中,通过不断最小化均方误差损失(Mean Square Error,MSE)函数来对模型进行优化,其优化目标如式(5)所示.
(5)
其中,I为指示函数,当yi=yj时,其值为1;否则为0.
3 实验
3.1 实验数据集
实验所用语料均是在录音棚环境下采录所得,每种语料包含 1 500 类孤立词.其中,佤语语料由4个发音人(2男2女)分别录制每词5遍所得,共计 30 000 条孤立词语音;而普米语语料则是由3个发音人(2男1女)分别录制每词8遍所得,共采录得到 36 000 条语音语料,所有语料经标注整理后均采用傅里叶变换将其转换为声谱图.
由于元学习是从大量任务中学习可迁移知识,因此在模型训练前需先对声谱图进行必要处理以生成具有大量任务的小规模语料库.元学习数据集一般由元训练数据及元测试数据组成,本文实验分别将每种语料的70%用于元训练,其余样本用作元测试.元学习的数据集分布如图3所示,其中τj为随机采样所得任务,每个任务均由支持集和查询集组成.
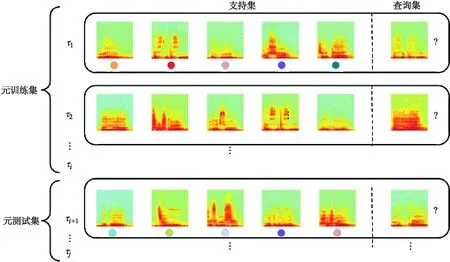
图3 元学习数据集分布示意图
3.2 实验环境及超参数
为了比较不同元度量学习网络在低资源语音识别中的性能,本文所有实验均在同一开发环境(Python)中使用相同的深度学习框架(Pytorch)来完成,系统选用Windows 10.0,实验还使用GPU对模型进行加速.P-Net与R-Net中相同的超参数设置如下:所有模型均使用初始学习率为0.001的Adam优化器;训练轮数epochs=200,每轮包含25个小样本学习任务;在五类单样本语音识别任务中,组成每个任务的样本类别数n=5,支持集与查询集的类内样本数分别为k=1和q=10;在5类5样本语音识别任务中,上述参数则分别设置为n=5,k=5,q=10.
3.3 模型结构
P-Net与R-Net的嵌入模块使用同一个浅层卷积神经网络来提取语音信号特征,二者的度量模块则选用不同的度量函数来测算样本的相似性,P-Net使用欧式距离函数来计算样本的相似性,而R-Net则选用一个可学习卷积神经网络作为分类器.R-Net中各模块组成结构及参数如表1所示,其中stride表示步长,padding表示零填充方式,使用ReLU激活函数,特征采样选用最大池化(MaxPool)函数.

表1 关系网络各模块组成结构及参数
3.3 实验结果分析
实验选用准确率来评估声学模型的泛化能力,假设存在一个样本总数为N的数据集,在模型训练过程中每次选取Q个样本进行标签预测,若预测正确的样本数为T(T≤Q),则该模型在这次训练任务中的准确率就表示为
(6)
其中P值越大,说明模型的泛化能力越强.
3.3.1 佤语孤立词语音识别性能
本文先在佤语数据集上分别探究了原型网络与关系网络的泛化能力,二者在不同的佤语孤立词语音识别任务中的识别精度如表2所示.
通过纵向比较表2中数据能够发现,关系网络具有比原型网络更强的泛化能力,其在五类单样本(5-way 1-shot)识别任务中的精度达到了98.51%,而在5类5样本(5-way 5-shot)识别任务中的精度更是高达99.56%.据此我们能够分析得出:元度量学习网络中使用可学习深度神经网络来度量样本相似性能够有效提升模型的泛化性能,具有比使用单一且固定的线性距离函数更好的识别效果.

表2 不同元度量学习网络在佤语数据集上的性能比较 %
此外,通过横向观察表中数据还能够发现,当佤语孤立词语音识别任务中样本类别数恒定时,元度量学习网络的泛化性能会随着类内样本数目的增加而不断提升;而当类内样本数目恒定不变时,其泛化能力则会随着样本类别数的增加而逐渐下降.与5类单样本和5类5样本佤语孤立词语音识别任务相比,关系网络在10-way 1-shot和10-way 5-shot任务中的识别精度分别下降了0.89%和0.35%.
3.3.2 普米语孤立词语音识别性能
此外,本文还在普米语数据集上验证了不同元度量学习网络的泛化性能,其在不同的普米语孤立词语音识别任务中的识别精度如表3所示.
通过纵向比较表中数据同样能够发现,在学习任务相同的情况下,关系网络的泛化性能显著优于原型网络.并且通过横向观察表3中数据仍然能够得出,当普米语孤立词语音识别任务中的样本类比数恒定不变时,元度量学习网络的泛化性能与类内样本数呈正比;而当类内样本数目固定不变时,其泛化性能会随着样本类别数的增加而出现下降趋势.

表3 不同元度量学习网络在普米语数据集上的性能比较 %
4 结语
本文探究了不同元度量学习网络在低资源语音识别中的性能,所用模型在佤语和普米语孤立词语音识别任务中均取得了很好的识别效果.此外,本文还通过实验验证了元度量学习网络中选用可学习神经网络来度量样本相似性比使用单一且固定的线性距离函数效果更佳,并且本文还分析了样本量变化对模型泛化性能的影响.在后续的研究工作中,我们将继续针对低资源语音的难识别问题探索性能更优的元度量学习方法.
