上下文感知的高铁信息服务推荐方法研究
2021-06-23张振海张湘婷
张振海,张湘婷
兰州交通大学 自动化与电气工程学院,兰州730070
随着移动互联网和5G技术的发展,通过移动终端或手机为旅客提供便捷的信息服务是“智慧铁路”研究的重点领域之一[1-2]。为了响应“互联网+”的国家号召,高铁站在12306的售票系统基础上增加了一系列与旅客出行相关的拓展服务如酒店预订、美食团购、旅游简介等,其目的是提升旅客服务质量的同时使铁路运营效益达到最大化。在高铁站,旅客获取的移动信息服务主要采用以业务为中心的静态服务组合方法,以业务流程模型构建为基础实现服务间的交互与协作。该方式虽然描述了服务之间的控制和数据依赖关系,但未充分对用户访问的大数据进行挖掘,以用户为中心服务功能未能充分体现,过多冗余的应用服务必然会降低用户的使用效率,导致用户体验性较差。因此,需要以用户为中心研究,通过对用户上下文信息的分析与挖掘,发现用户的操作行为之间蕴含的关联关系,研究更加智能的服务推荐方法,提高高铁信息服务质量。
目前,众多国内外学者在服务推荐方面展开研究,从多个角度提出了数据挖掘的模型与方法,传统推荐算法如协同过滤、基于内容的推荐、混合推荐等。如文献[3]根据用户对学习资源的个性化需求,提出基于内容过滤的推荐方法。文献[4]对用户进行聚类,建立推荐服务库,从而实现服务推荐。文献[5]利用关联规则考虑用户需求设计智能旅游景点推荐系统。上述方法是“用户-项目”之间关联关系占据推荐重要位置,但随着移动应用的兴起,用户周边环境也开始影响用户服务选择,针对此问题,一些学者将“移动用户-移动应用-上下文”关联关系引入推荐系统中。文献[6]利用用户所在位置,挖掘出此位置频繁使用的服务功能推荐给用户,该方法只考虑一种上下文的推荐,会导致数据稀疏,从而推荐精度不高。文献[7]设计一种融合上下文信息与社交网络信息的个性化推荐系统,通过随机决策建立原始用户-商品评分矩阵对上下文信息处理,最后采用矩阵因式分解进行预测,但此方法未考虑上下文与用户行为之间的关系。相似的,文献[8]提出一种基于上下文感知的个性化度量嵌入推荐算法,考虑上下文情景信息,进一步研究了上下文与用户操作行为之间存在规律信息。文献[9]提出一种基于用户聚类和移动上下文的矩阵分解推荐算法,采用kmeans对用户聚类找到相似用户簇。关于高铁信息服务方面,文献[2]分析推荐系统在铁路延伸服务中的应用前景,证明向用户即时推荐所需服务或产品,在发挥铁路资源优势的同时提升用户满意度。文献[10]提出基于云模型相似性度量的协同过滤推荐算法应用在旅客服务推荐中,使用云模型表示项目评分和用户评分,衡量用户-用户、项目-项目之间的相似度,从而对未知用户进行评分,但只对MovieLens数据集进行实验没有实际结合铁路客运情况。对于高效的高铁移动信息服务,旅客当前的应用场景对服务功能的选择影响较大,因此如何对上下文信息预处理和挖掘上下文信息与服务间的规则考虑为高铁站旅客量身定做一个专属的服务集合是十分重要的[11-12]。
为此,本文分析当前高铁站旅客出行需求,结合高铁运输特点构造上下文模型,采用改进FP-Growth算法,赋予不同类型上下文项单独最小支持度,以上下文项与服务间的关联规则作为匹配依据,对获取当前上下文信息进行相似度计算,最终精准定位旅客需求,为多样化、个性化的客运服务奠定基础。
1 高铁信息服务推荐模型框架
上下文是表述实体状态特征的所有信息,例如地点、天气、时间等[13-14]。上下文的感知是将上下文的变化融入到模型中向用户推送信息或服务,协助完成具体的任务。基于上下文感知的服务推荐方法是利用上下文信息作为服务推荐主要依据,建立上下文与服务功能之间的关系,获得符合当前应用场景下的服务集合并且动态加载到用户界面中,如图1所示。

图1 上下文感知的服务推荐方法
在基于上下文感知的高铁信息服务推荐模型中,由用户基本信息、第三方提供的信息和移动设备感知信息所构成的上下文信息库以及高铁站内、站外的延伸服务构成的服务信息库是作为推荐主要依据,根据显式信息与隐式信息对用户信息服务进行建模[15]。用户使用系统时,服务系统自动获取当前上下文,通过对应推荐算法进行服务匹配,构造个性化服务推荐集合,最终发布到移动客户端,具体框架如图2所示。本文采用改进FP-Growth推荐算法挖掘上下文与服务之间的关联规则,对有价值的用户历史记录信息进行统计与分析,通过用户行为预测实现信息服务的精准推荐。

图2 基于上下文的高铁推荐模型框架
2 FP-Growth算法及相关概念
(1)相关概念
关联分析是发现隐含于大数据中具有实际意义的规律信息,这些规律可描述为关联规则或是频繁项集[16]。假设I={I1,I2,…,I m}为项的集合,同时在事务数据库D中每一条事务T均为I的非空子集,即T⊆I,而且每一条事务T独有与之对应的标识符TID(Transaction ID)。
定义1(项集)项的集合,包含k个项的项集称为k项集。
定义2(支持度)在数据挖掘的关联分析中,支持度是所有事务T中同时出现A项(或项集)的概率,计算公式如下:
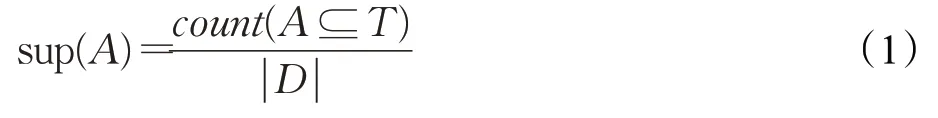
支持度也可表示为A项(或项集)在数据库D中出现的频数,称为支持度计数。设置最小支持度min_sup,若sup(A)≥min_sup,称项集A是频繁项集[16]。
定义3(关联规则)是蕴含关联的规则,形如X→Y,其中X为前件(antecedent),为Y后件(consequent)。
(2)算法描述
①遍历事务数据库D,计算每项支持度并过滤不符合的项,获得频繁1项集L,按照支持度大小降序排列得到有序频繁1项集P,然后对事务数据库D重新调整。
②创建根节点root和频繁项目头表,再一次遍历事务数据库D,将依据P的排序对每条事务进行处理,扫描每条事务开始建立分支生成FP-tree。
③根据FP-tree树找到单项的条件模式基,递归挖掘条件FP-tree,最终依据频繁项集从中得出关联规则。
3 高铁信息服务推荐方法
3.1 数据预处理
为满足当前实际应用场景,以UML关系图为基础建立高铁移动应用上下文模型结构,如图3所示。该模型说明各元素之间的关系,分为时间、空间、用户和应用四类,其中ISO 8601和UTC为当前日期和时间。

图3 高铁移动服务应用的上下文模型
为更规范表达的例子事务,本文定义数据操作符,如表1所示,根据此操作符列出事务示例,如表2所示。其中,T.c,T.d和T.l分别表示当前时间、发车时间和剩余时间,该信息可从用户访问移动应用获取;L.d分别表示用户所在地A与目标位置B的距离,该数据可从手机GPS定位中获取;L.w代表当前天气情况,可通过手机自带软件获取;U.a、U.g、U.p、U.i分别表示用户的年龄、性别、职业以及兴趣爱好,可从用户基本信息中获取;业务状态B.s可由应用软件与用户进行交互获取[17]。
3.2 构建高铁移动信息服务FP-tree
传统FP-Growth算法只针对一维数据项设置单一支持度,进行规则提取实现推荐。对实际应用而言,每个上下文项都是属性和数值组成的键值对,如果设置单一最小支持度会造成关键上下文项丢失,例如U.g只有male和female两种选择,而T.c分为六个时间段,因此两类上下文项中的值出现概率不同,前者远大于后者。因此,根据每类上下文项出现概率分别设置最小支持度(服务功能项最小支持度设为0,排在最后),即多最小支持度Min_sup={MinSup1,MinSup2,…,MinSup n}。若项A的支持度Sup(A)≥Min_sup A,则A为二维频繁项集。基本思想是:在事务数据库D中,设置多最小支持度Min_sup确定有序二维频繁1项集L,根据L对每条事务重新调整建立分支,构建FP-tree。

表1 数据操作符

表2 事务示例
具体算法描述如下所示:
输入:事务数据库D;
最小支持度Min_sup
Min_sup={MinSup1,MinSup2,…,MinSup n};
输出:FP-tree;
遍历事务数据库D,计算每一个项的支持度计数并与Min_sup比较,获得二维频繁1项集L,依照最小支持度的值降序排序得到有序二维频繁1项列表L′。
创建一个FP-tree的根节点,记为Null;
for事务中每条事务Tdo按照L′的顺序调整次序;
将每条经过排序得到二维频繁项集合[p|P],其中p为首个元素,P为剩余元素集合;
调用函数insert_tree([p|P],T),创建FP-tree;
end for
inser t_tree([p|P],root)
ifiis kind ofNandN.item-name=p.
item-name//i是已有分支的一项
N.count++;
else
创建新节点N;
N.count=1;
p.parent=r oot;
将此节点加入到项表头相同item-name节点上;
end if
insert(i,node);
3.3 上下文信息及相似度计算
上下文信息获得途径有手机内置传感器、用户注册信息或者系统软件本身等。上下文信息分为:离散型上下文信息(职业、天气等);连续型上下文信息(年龄、剩余时间等)[18]。假设系统内有F种类型的上下文信息,记,即历史记录中用户u x在使用服务S y时全部上下文信息,其中为第k种类型的上下文。记Ccurrent=是目标用户U c在使用当前系统时的所有上下文信息,其中为第k种类型的上下文,计算相似度公式如下:
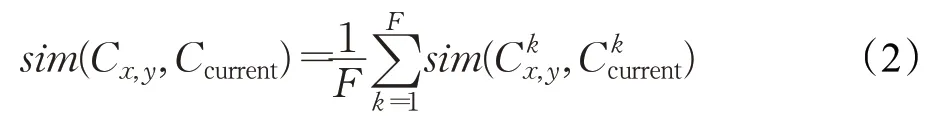
如果第k种类型的上下文信息是属于离散型,则分为相关性和非相关性。当上下文信息具有相关性,计算公式如下:
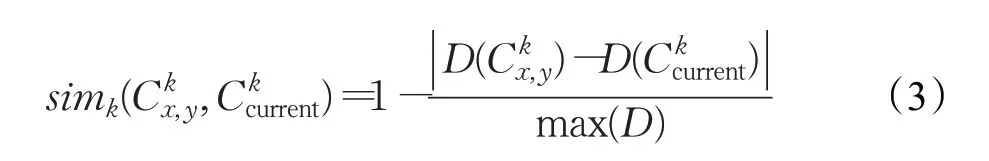
数据预处理中天气可分成晴天、阴天、雾天、雨天和雪天五种,设置等级为1~5,如simk(晴天,阴天)=1-simk(晴天,雪天)simk(晴天,阴天)>simk(晴天,雪天),晴天与阴天相似度更高。
当离散型上下文信息值具有无相关性,计算式如下:

在数据预处理中对旅客职业按照国家职业分类大全分成8类,这些职业之间并没有相关性,例如技术性职业与商业性职业相似度就为0。
如果第k种类型上下文信息是连续型数据,则先将连续型转变成离散型,然后用离散型上下文信息的相似度算法,将连续型数据转化为离散型的计算公式如下:
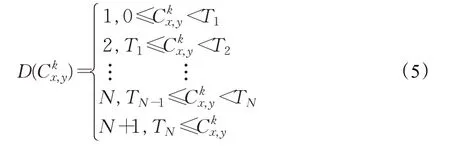
式中,Tn(1≤n<N)是分界点,当转化成离散化之后求相似度的计算方法如式(3)所示。
3.4 基于关联规则的服务匹配
在FP-tree中每条路径均包含类似于C→S的关联关系,C是除根节点之外的自上向下构成序列集合,S是每一条路径中包含的服务功能集合。在当前应用场景时,可根据上下文C′构造适合该场景的服务集合,将上下文C′与FP-tree每个分支中的C做相似度计算,即sim(C,C′),综合排序取Top-k,得到服务推荐集合。
具体算法描述如下所示:
输入:FP-tree;用户当前上下文信息Current;最小相似度MinCount;推荐服务个数K。
输出:服务集合S。


4 实验结果与分析
4.1 数据集
因为目前高铁旅客信息服务推荐领域积累不足,为了采集旅客相关信息,在兰州站征集了50个志愿者的智能手机,职业有教师、学生、工人等,在高铁站使用的“铁路12306”“智行”“美团”等相关类型APP上采集约15万条数据。随机选取10 000条用户历史数据,以9∶1的方式分成训练集和测试集,训练集是采用本文算法挖掘出上下文信息和服务功能之间的关联规则,测试集是根据训练集进行服务匹配。
本文使用的硬件为Intel®酷睿I5-42210U,2.70 GHz处理器,8 GB内存,操作系统是Windows 7旗舰版64位;软件为eclipse3.4-jee-ganymede开发运行平台,JDK7.0版本。
4.2 指标选择
评价一个服务推荐算法往往从命中率(Recall)、准确率(Precision)和综合评价(Comprehensive evaluation)3个方面进行考虑,命中率主要用于衡量算法得出推荐服务集合Ure与实际可推荐服务集合Ureal的交集与实际可推荐服务数量的比值,计算公式如下:

准确率主要衡量算法所得出的服务集合Ure与实际上可推荐的服务集合Ureal的交集与算法得出服务数量的比值,计算公式如下:
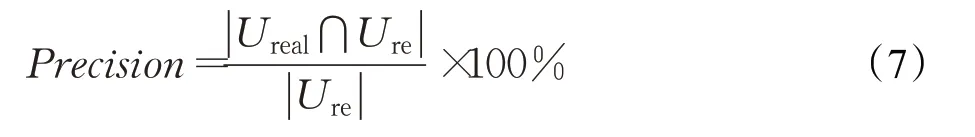
综合评价指标,可以很好地考量推荐算法的整体性能,计算公式如下:

4.3 结果分析
在事务数据集中,根据上下文项的出现频率和重要程度设置本算法的多最小支持度Min_Su p={U.g=0.3,T.c=0.2,T.d=0.15,L.w=0.13,U.a=0.15,U.p=0.1,U.i=0.1,T.l=0.1,B.s=0.4},图4显示出实验参数对推荐系统产生的影响。Top-k的取值可直接影响实验的有效性,k值过小即算法推荐数量过少,会导致命中率过低,由图可知,k增加时命中率也随之增加。k≤5时命中率要低于准确率,是因为用户期望的服务个数大于算法推荐个数。从图中也可看出随着k增加准确率会降低,虽然k增加命中服务的概率也会增大,但是这种增加是具有概率性的。特别是在命中率很高的情况下,k的增加反而会使准确率降低,因此整体呈下降趋势。当k≥11时,命中率和准确率不再改变,原因是用户所需服务已达到饱和同时Top-k的所取个数为整个候选服务集合。从图中可看出Top-k的较理想取值k=8。
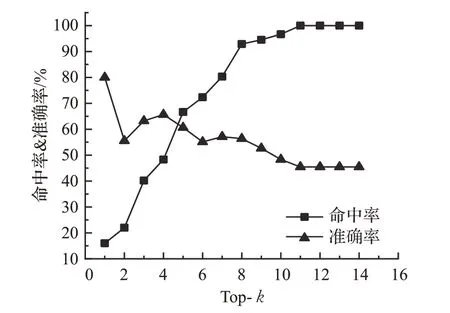
图4 Top-k对实验影响
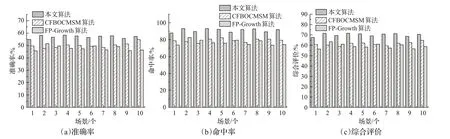
图5 实验对比结果
图5 是在图4得出的Top-k(k=8)的基础上进行实验所得结果。实验将本文算法、传统FP-Growth算法和文献[10]提出基于云模型相似性度量的协同过滤推荐算法(即CFBOCMSM),进行命中率、准确率和综合评价三方面比较。传统FP-Growth算法的最小支持度设为0.2。为了更好地分析对比这三种方法,本文将设置10个不同高铁应用场景下的用户所需服务。由图可知,本文算法产生结果均高于其他两种算法,这是由于设置多最小支持度对FP-tree进行扩展,将频率较高的项设置较大的最小支持度,避免关键项丢失的同时控制规则数量,使得平均准确率从47.94%提高到57.05%,平均命中率从76.74%提高到91.02%。
在事务数据集上,随机选择3 000、6 000、9 000条事务对其挖掘,求得准确率与命中率结果,如图6所示。

图6 事务数对结果的影响
由图可知,历史事务数与服务应用的命中率和准确率成正比,因为历史事务数量直接影响关联规则数,事务数据越多对挖掘越有帮助。
5 结论
服务推荐是当前服务计算领域中的热点,随着高铁站旅客对出行效率和出行质量要求的不断提高,追求高质量服务组合的难度也随之增加。分析传统FP-Growth算法在实际高铁应用场景所存在的局限性和挖掘不足的问题,提出基于上下文感知的服务推荐方法,根据不同类型上下文项设置多最小支持度,得到上下文和服务之间的关联关系,采取上下文项相似度的计算方法进行服务匹配,最后获得推荐的服务集合。此方式可以缩短用户与高铁信息服务之间的距离,进一步落实“以人为本”的服务理念,提升现阶段的高铁信息服务水平。实验证明改进后的算法显著提高了服务匹配的准确率和命中率,该方法可以有效利用上下文信息并获得满足用户需求的推荐结果。随着历史数据量的不断增大,FPGrowth改进算法产生的FP-tree过于庞大,因此需在海量数据环境中实现并行化,提高运行效率是下一步的研究重点。
