抽取式机器阅读理解研究综述
2021-06-23李艳玲
包 玥,李艳玲,林 民
内蒙古师范大学 计算机科学技术学院,呼和浩特010022
机器阅读理解(Machine Reading Comprehension,MRC)是自然语言处理(Natural Language Processing,NLP)领域的热门研究方向,利用机器对数据集中的文本内容进行理解和分析,回答提出的问题,能够最大程度地评估机器理解语言的能力。目前,MRC任务一般分为填空式、选择式、抽取式、生成式和多跳推理式5类[1]。在过去的数十年中,涌现出许多在限定领域的MRC应用,例如智慧城市、智能客服、智能司法系统以及智能教育系统。
抽取式机器阅读理解是MRC任务中重要的一类,其主要利用给定的文本内容和相关问题,通过对文本内容的分析和理解,给出正确的答案。该任务需要预测出答案的起止位置从而选出答案片段,通常也被称为跨距预测或者片段预测[2]。抽取式MRC任务中的问题一般由人工提出,答案可能存在长度上的差距,同时存在问题无答案的可能,更加贴合现实生活中的应用场景。
近年来,随着MRC受到越来越多的关注,针对MRC的总结性文章也随之增加。Liu等人[2]于2019年发表了一篇关于神经机器阅读理解方法的综述,其重点在于归纳基于深度学习的MRC方法,对于早期基于规则的方法与机器学习方法没有介绍,且对于数据集的介绍比较简单,没有深入挖掘;同年,Zhang等人[3]发表了一篇有关MRC的综述,其中较为客观全面地介绍了MRC数据集以及一些经典模型,但是对于MRC的未来发展方向没有提出任何建议;Gupta等人[4]于2020年发表了一篇关于会话机器理解(Conversational Machine Comprehension,CMC)的综述,其重点归纳了CMC的相关数据集与模型;Dzendzik等人[5]于2021年发表了一篇关于MRC英文数据集的综述,该文详细介绍了数据集的数据收集以及创建过程,并对各个数据集从多维度进行了分析对比,但对于MRC方法没有进行介绍。目前还没有一篇综述文献针对抽取式MRC进行系统全面的介绍,本文聚焦于抽取式MRC的常用数据集以及相关模型方法,对常用数据集进行了系统介绍与分析,对相关模型方法进行了分类总结,希望本文对抽取式MRC在国内的研究起到一定的推动作用。
1 机器阅读理解
1.1 机器阅读理解的发展历程
对于MRC的研究有着悠久的历史,近半个世纪以来,其发展经历了三个阶段。
第一阶段:自20世纪70年代起,人们开始利用基于规则的方法构建早期MRC系统,最具代表性的有Lehnert等人提出的QUALM系统[6]和Hirschman等人提出的DEEP READ系统[7]。基于规则的方法采用模式匹配的方式提取特征,且匹配时使用固定大小的窗口。受限于当时的数据集规模、文本编码能力和计算机水平,MRC进步缓慢。
第二阶段:2013至2015年间,随着机器学习的发展,学者们开始使用机器学习相关方法解决MRC任务。Richardson等人提出了MCTest数据集[8],该数据集通过众包方法构建,其优点是可以保证问题的多样性,且问题和答案更接近人类真实问答。该数据集的出现直接推动了基于机器学习的MRC模型的发展,这些模型大多是基于最大间隔(Max-Margin)[9],通过加入丰富的语义特征集(句法依存、共指消解、语义框架、词嵌入等),实现对“文本-问题-答案”三元组的拟合。对于特征的提取主要依赖于依存解析器、语义角色标注等技术,这些NLP技术是由单一领域数据训练所得,应用于MCTest数据集会引起噪声。而且该数据集规模太小,不足以训练良好的机器学习模型。
第三阶段:2015年以来,随着深度学习的再次兴起,MRC也获得了巨大的发展,大规模MRC数据集应运而生,如CNN/Daily Mail[10]、SQuAD1.1[11]等。研究者们开始利用神经网络搭建MRC模型,相比于传统的基于规则的分类器,基于深度学习的MRC模型能够更好地识别词汇匹配和释义,提取更深层次的语义特征。但是基于深度学习的MRC模型仍然存在一些缺陷,如:传统的词向量无法解决一词多义问题,注意力模块的网络结构复杂,难以处理较长的文本等[12],因此预训练语言模型应运而生。预训练语言模型通过在大量文本上进行半监督训练以捕获句子间深层次的语义关系,从而提升模型性能,其中最具代表性的BERT(Bidirectional Encoder Representation from Transformers)模型[13],一经问世就刷新了NLP领域11项记录。预训练语言模型在一些数据集上的表现甚至超越了人类,其能力被越来越多的学者认可,对于该领域的研究呈现出加速增长的态势。
1.2 机器阅读理解任务及其难点
现有MRC任务一般可以概括为5类:填空式MRC、选择式MRC、抽取式MRC、生成式MRC和多跳推理MRC。
填空式MRC任务需要推测出段落中缺失的词语,该任务存在答案内容简短、与现实生活距离较远等特点,其数据集出现较早,且依赖于人工标注,存在一定的局限性。选择式MRC任务主要从多个候选答案中为问题选择正确答案,该任务存在答案局限、单一等特点。抽取式MRC的答案可能是一个字词、一段话或者无答案,其更加符合人类日常需求。
抽取式MRC任务是近年来学者们研究频率最高的MRC任务,其面临的困难也较其他任务更大。
(1)搜索空间广:需要从给定的大量文本中寻找答案。
(2)迷惑性大:给定段落中可能存在一些“似是而非”的答案,如何从具有迷惑性答案的段落中找出正确答案是该研究的难点。
(3)存在无答案问题:一般情况下,所提出的问题均存在对应的答案,但在一些有难度的数据集中,存在问题无对应答案的情况。如何正确理解段落内容,并对问题的可答性作出正确判断也是该研究的重点。
2 抽取式机器阅读理解
抽取式MRC任务因其更加实用而被学者广泛研究,其更能检验模型的理解能力。表1给出了中文抽取式数据集CMRC2018[14]的一个示例。
给定段落中,具有许多迷惑性答案,如:广茂铁路加两条支线全长421.326公里,广三铁路全长49公里,三茂铁路全长357公里。这种情况要求机器理解更深层次的文本语义,从而找到正确答案,而不只是进行简单的文本匹配。
2.1 形式化定义
通常情况下,假设抽取式MRC给定三元组数据(C,Q,A),其中,C即Context,表示数据集中的文本;Q即Question,表示数据集中的问题;A即Answer,表示该问题在文本中的答案。通过数据的表示学习,模型能够拟合输入与输出的关系f,其表示通常如式(1)所示[9]:

表1 CMRC2018示例

式(1)中的A通常表示为(astart,aend),起始位置astart和结束位置aend之间的部分即为所要预测的最终答案。
2.2 数据集
抽取式MRC数据集具有问题复杂、答案自由、涉及领域多样等特点。随着研究者们对抽取式MRC研究与探索的不断深入,越来越多的抽取式MRC数据集应运而生。目前,抽取式MRC数据集主要包括SQuAD1.1[11]、NewsQA[15]、TriviaQA[16]、SearchQA[17]、SQuAD2.0[18]、CMRC2018[14]等。
2.2.1 SQuAD1.1
2016年,Rajpurkar等人提出第一个真正意义上的大规模抽取式MRC数据集SQuAD1.1(Stanford Question Answering Dataset 1.1)[11]。该数据集的形式为“问题-文本-答案”三元组,其答案是文章中的某个片段,解决了现有数据集的两大不足:第一,现有数据集规模太小;第二,足够大的数据集往往是机器生成的,其内容与人类语言习惯不符,无法直接测试机器的阅读理解能力。SQuAD1.1的发布直接推动了当时抽取式MRC的发展,具有里程碑式的意义。
2.2.2 NewsQA
Trischler等人认为MRC系统特别适合大量、快速变化的信息源,如新闻,所以他们构造出一个全新且具有挑战性的、需要进行推理才能得到答案的大型抽取式MRC数据集:NewsQA[15]。该数据集通过众包方法构建,众包方法保证了提出问题的多样性。工作者从上万篇CNN新闻文章中提取出十万多个自然语言问题,相比于SQuAD1.1,该数据集包含无答案问题,难度相对较高。
2.2.3 TriviaQA
TriviaQA数据集[16]包含超过65万个“问题-答案-证据”三元组、95 000个问答对和独立收集的证据文档(平均每个问题有6个),证据文档收集于Wikipedia和Web,为答案预测提供高质量的远程监督。与众包方法相比,这种远程监督的构造方法不需要大量的人力资源,造价成本低。相比于当时其他大型数据集,TriviaQA问题构成较为复杂,其丢弃了假设条件,更接近于人类问答,需要更多的跨句推理预测答案,具有一定的挑战性。随着深度神经网络的发展,越来越多的研究人员开始关注TriviaQA这类复杂数据集。
2.2.4 SearchQA
SearchQA与TriviaQA构造方法类似,Dunn等人也采用了远程监督方法构造SearchQA数据集[17]。该数据集由超过14万个“问题-答案”二元组组成,每对二元组平均有49.6个片段。与之前的大多数数据集不同,SearchQA通过世界上最大的搜索引擎获取嘈杂、真实的上下文,构造“问题-答案”二元组,其更加贴近人类生活,实用性更强。
2.2.5 SQuAD2.0
SQuAD1.1数据集只关注可回答问题,且现有模型对于无答案问题的识别研究关注较少。为了弥补这些不足,Rajpurkar等人[18]又提出了SQuAD2.0数据集,在SQuAD1.1的基础上加入了53 775个“无答案问题”,该数据集更具挑战性,在SQuAD1.1上性能最好的模型在SQuAD2.0上的F1值由85.8%变为66.3%。难度的增加使模型在该数据集上的准确率明显下降,该数据集也成为学者们的研究热点。
2.2.6 CMRC2018
现有阅读理解数据集大多是英文的,中文数据集屈指可数。目前,基于中文的数据集包括填空式数据集PeopleDaily/CFT[19]、生成式数据集DuReader[20],以及抽取式数据集CMRC2018[14]等。
为弥补抽取式MRC数据集在中文领域的空白,Cui等人提出CMRC2018数据集[14]。该数据集由近万个真实问题组成,并新增了挑战集(Challenge Set),以模拟更加复杂的真实环境。由于挑战集中的问题需要机器具备一定的知识推理能力,目前还没有特定的模型能够获得较好的效果。该数据集仅包含有答案问题且规模较小。
各数据集基本信息如表2所示。对于抽取式MRC的研究是从SQuAD1.1数据集的发布开始兴起,目前数据集的构造方式大致可以概括为众包方法和远程监督方法两种。众包方法可以保证问题和答案的质量,但是需要耗费大量人力物力;远程监督方法无需人工标注,节约成本,但是数据集质量无法得到保障。抽取式任务的评估指标主流的有EM(Exact Match)值和F1值两种。目前中文领域以及针对专业领域的数据集较少,有待研究者们的开发。从表2中可以看出,NewsQA、TriviaQA、SearchQA的人类表现与当前最优(State Of The Art,SOTA)值都比较低,说明这些数据集难度较大,其通过减少单词匹配类型、增加综合类型答案提高数据集挑战性,从而带动模型的发展。CMRC2018挑战集通过加入推理答案和设置迷惑性答案加大了数据集难度,模型在其上的表现较差,但是人类表现却取得了不错的成绩。这表明,目前的MRC模型不能处理需要在几个线索之间进行综合推理的难题,机器依然无法做到像人类去阅读、无法真正做到理解文本语义,对于MRC模型的研究仍然“任重而道远”。
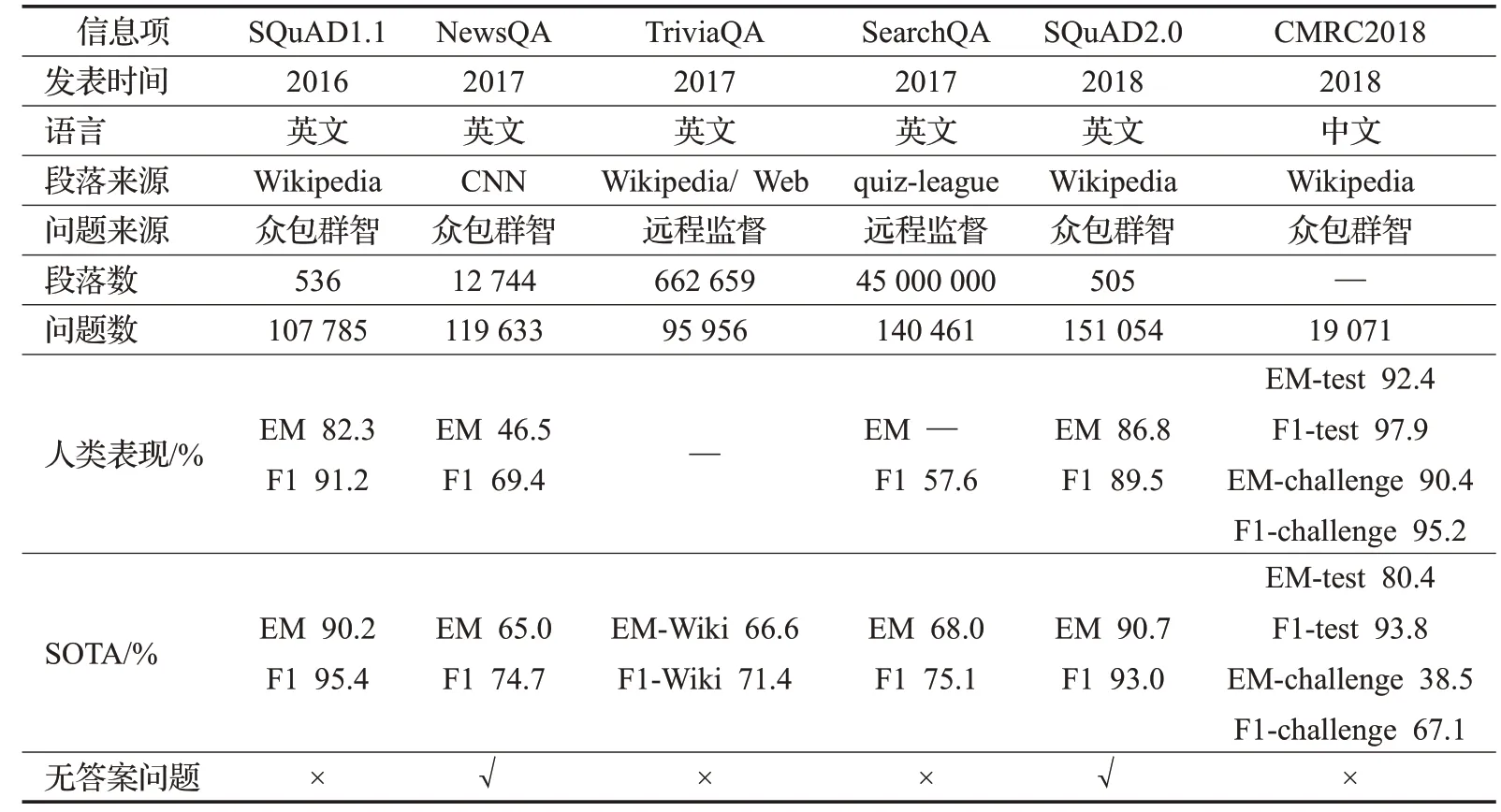
表2 数据集基本信息
2.3 评价标准
对于抽取式MRC任务,需要模型对预测所得答案和真实答案进行对比。通常使用EM值和F1值对模型性能进行评价[11]。EM指的是模型的输出答案与真实答案完全一致的百分比。F1值指的是模型的输出答案与真实答案的覆盖率,通过准确率和召回率计算。评价指标计算公式如下:
(1)EM值

其中,Nreal代表模型所预测答案与真实答案完全匹配的个数,Nall代表真实答案的总个数。
(2)F1值

其中,Noverlap表示预测正确的单词/字符数目,即预测答案与真实答案之间的词汇重叠度;Nallanswer表示所预测答案的所有单词/字符数目;Ntruthanswer表示真实答案的所有单词/字符数目。
3 抽取式机器阅读理解模型
传统的基于机器学习的MRC模型采用模式匹配的方法进行特征提取,性能提升受限。随着深度学习的发展,基于神经网络的MRC模型得以迅速发展。循环神经网络(Recurrent Neural Network,RNN)[21]、卷积神经网络(Convolutional Neural Networks,CNN)[22]、长短时记忆网络(Long Short-Term Memory,LSTM)[23]、门控循环单元(Gated Recurrent Unit,GRU)[24]和注意力机制(Attention Mechanism)[25]的出现大大推动了MRC的发展,它们能够提取深层次的文章语义、语序特征信息以及长距离上下文语义信息,对于提取文本中所包含的特征信息具有一定的优势。
目前,大多数抽取式MRC模型的网络架构由嵌入层、编码层、信息交互层和答案预测层组成[26]。嵌入层将文本和问题映射成包含相关文本信息的向量表示,便于计算机理解;编码层通常利用神经网络对文本和问题编码,得到上下文语义信息;信息交互层将文本和问题的编码信息进行融合匹配,最终得到混合两者语义的交互向量,信息交互层是整个模型中最重要的一层;答案预测层根据语义交互向量抽取出答案边界,得到最终预测答案[26]。抽取式MRC模型的网络架构如图1所示[2]。
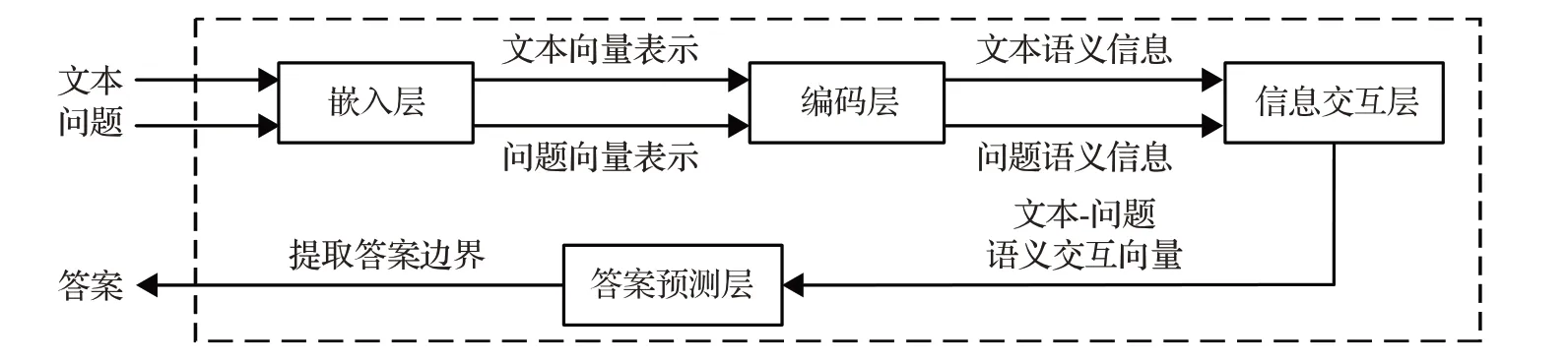
图1 抽取式MRC模型的网络架构图
目前研究人员对于模型的研究主要针对上述4层进行改进,根据方法可以将抽取式MRC模型分为:基于注意力机制的MRC模型、基于迁移学习的MRC模型、加入推理机制的MRC模型以及结合外部知识的MRC模型4类。
3.1 基于注意力机制的抽取式机器阅读理解
注意力机制最早应用于计算机视觉(Computer Vision,CV)领域,Mnih等人[25]首次将注意力机制应用于RNN模型进行图像分类,该方法在图像分类任务中取得了显著成效。随后,Bahdanau等人[27]将注意力机制应用于神经机器翻译(Neural Machine Translation,NMT)任务,使翻译和对齐同时进行,显著提升了翻译的准确率,这是第一个将注意力机制应用于NLP领域中的工作。2017年,Vaswani等人提出了自注意力机制[28],用于学习文本表示。自此,各种基于注意力机制的衍生变体相继出现,注意力机制被广泛应用于各种NLP任务当中。
注意力机制在MRC模型中应用的基本思想是读取文本时重点关注文本与问题的相关部分,降低无关内容的权重。近年来基于注意力机制的抽取式MRC模型发展较快,随之其面临的挑战也越来越大。
Seo等人[29]针对现有应用注意力机制的MRC模型存在的两个问题:第一,只是应用于文本中的部分内容,第二,只是单向的应用,无法充分融合利用上下文与问题之间的关联信息,提出了双向注意力流(Bi-Directional Attention Flow,BiDAF)网络。该网络在句子的不同粒度上对上下文和查询进行编码,以获得不同粒度的信息表示。模型结构如图2所示[29]。
字嵌入层和词嵌入层负责将每个字、词映射到高维向量空间,{x1,x2,…,x T}和{q1,q2,…,q J}分别表示输入上下文段落和查询中的字词;上下文嵌入层使用LSTM建模词间交互信息;注意力流层将查询与上下文信息连接、融合,获得从上下文到查询(Context-To-Query,C2Q)以及从查询到上下文(Query-To-Context,Q2C)的注意力权重,权重的计算都是由共享相似矩阵S∈RT×J导出的,相似矩阵计算公式如式(6)所示[29]:

其中,S tj表示第t个上下文词和第j个查询词之间的相似度;α为对两个输入向量之间的相似性进行编码的可训练标量函数;H:t表示上下文H的第t列向量;U:j表示查询U的第j列向量。
设a t∈RJ表示第t个上下文词对查询词的注意力权重,对于所有t,权重和为1。注意力权重由a t=softmax(S t:)∈RJ计算,查询向量表示为U͂:t=ΣJ a tj U:J,U͂为一个包含整个上下文注意力查询向量的二维矩阵。通过b=softmax(maxcol(S))∈RT获得上下文词上的注意力权重,其中最大函数(maxcol)跨列执行,上下文注意力向量为h͂=Σt b t H:t∈R2d,表示与查询相关的上下文中最重要词的加权和。h͂跨列平铺T次,得到H͂∈R2d×T。
最后,将上下文嵌入和注意力向量组合在一起以产生G,其中每个列向量可以被认为是每个上下文词的查询感知表示。定义公式如下[29]:

其中G:t为第t列向量,β为融合输入向量的可训练向量函数,d G是β函数的输出维度。
建模层的输入为G,它对上下文词的查询感知表示进行编码。建模层的输出捕获了以查询为条件的上下文词之间的交互。建模层使用双层BiLSTM,每个方向的输出大小为d,得到矩阵M∈R2d×T,该矩阵被传递到输出层,用来预测答案。
开始索引和结束索引在文本中每个词上的概率分布计算公式如下所示[29]:
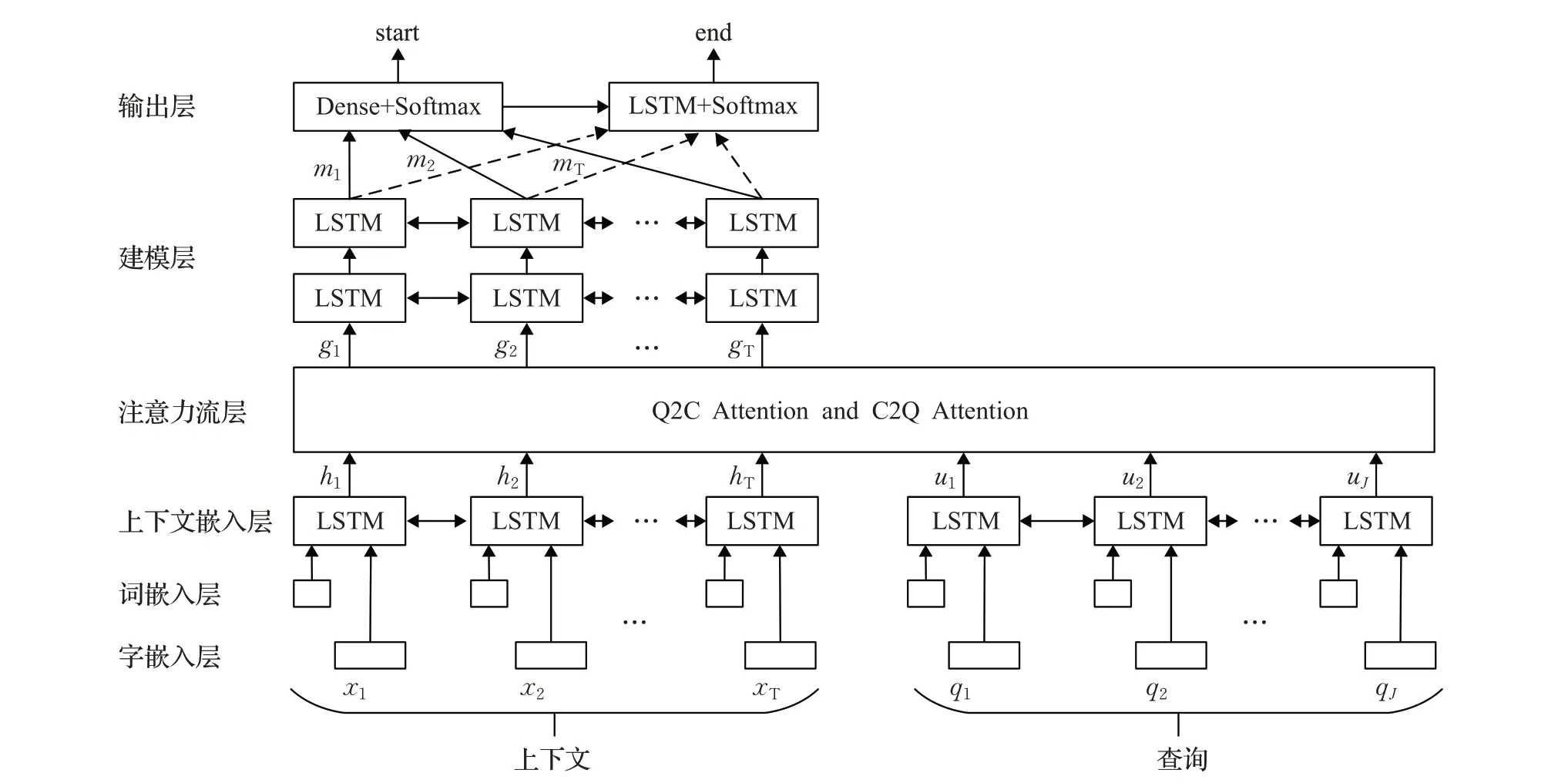
图2 BiDAF模型结构图
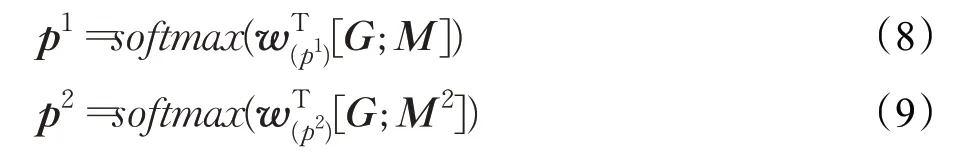
其中w(p1)∈R10d为可训练的权重向量。
损失函数计算公式如下[29]:
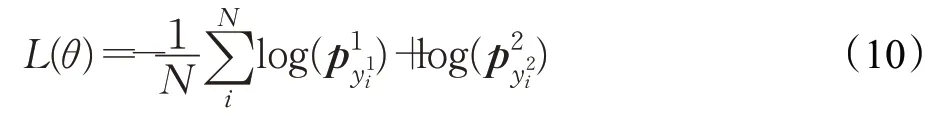
其中,θ为模型中所有可训练权重的集合,N为数据集中的样本数目,yi1和yi2分别为第i个样本的开始索引和结束索引,p k表示向量p的第k个值。
BiDAF模型在SQuAD1.1数据集上达到了73.3%的EM值和81.1%的F1值,优于之前所有方法。
BiDAF模型是MRC发展史上十分重要的模型,后续许多学者在此基础上研究MRC问题。万静等人认为BiDAF对多段落信息间相关性考虑不充分,提出了PRBiDAF(Passage Rank-BiDAF)模型[30]。PR-BiDAF对文本与问题的关联匹配度进行排序以选取最有可能存在答案的段落,该模型在MRC问题中取得了较好的效果。
Wang等人[31]首次将自注意力机制应用于MRC模型,提出了门控自匹配网络R-Net。利用基于门控注意力的递归网络生成问题感知的段落表示,能够精确定位文本的重要部分,但是这种表示方式常常会忽略窗口外的有用信息,对上下文的表示非常有限。为解决该问题,R-Net直接将问题感知的段落表示与其本身进行自匹配,动态地从整篇文章中收集段落中的单词证据,并将其与当前段落单词的相关证据及其匹配的问题信息编码到段落表示ht P[31]:
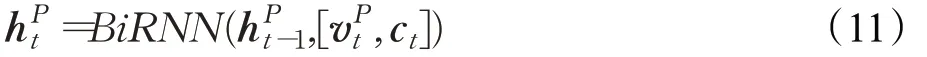
其中,是整个段落(v P)的集中注意力向量[31]:
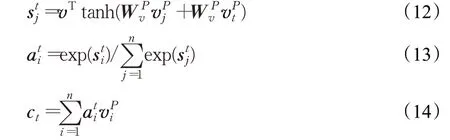
在MRC模型中加入自注意力机制这一做法获得了极大成功,后续许多学者的研究都借鉴了这种方法,并取得了不错的效果。Tay等人[32]将自注意力机制应用于双向注意连接器(Bidirectional Attention Connectors,BAC),BAC能够建立整个网络的链接,有助于信息的流动。其中,自注意力机制将与问题相关段落中的每个单词与所有其他单词进行建模,从而使每个单词都可以从全局上下文中建立联系。该方法在NewsQA数据集上达到了53.1%的EM值和66.3%的F1值,是当时性能最好的模型。姚澜[33]在BiDAF的基础上加入自注意力机制,提出了self-BiDAF,解决了现有模型文本编码能力不足这一问题。自注意力机制可以增强模型对文本编码的能力,使得模型能够更准确地表达文本。李童俊[34]针对BiDAF模型训练的文本内部语义信息易丢失问题,提出了BiDAF+模型。BiDAF+利用自注意力机制实现对文本语义信息的更深层次建模,并弥补了使用LSTM所导致的出现遗忘语义信息的缺点。BiDAF+能够更加有效地融合和提取全局信息,提升模型的计算效率。该模型训练效果较好,在SQuAD1.1数据集上训练的F1值比BiDAF提升了6.47%,训练时间也大幅度减少。
层次注意力机制与基于注意力机制的RNN模型在MRC中同样取得了不错的成绩。Wang等人提出了多粒度层次注意力融合网络模型SLQA+[35],首先用细粒度的词嵌入对问题和文本进行编码,以更好地捕捉语义级别的相应表示;然后提出一种多粒度融合方法,以完全融合来自全局和局部的表示信息;最后,引入层次注意力网络逐步找到正确答案。层次注意力网络由具有浅层语义融合的协同注意力层和具有深层语义融合的自注意力层组成,协同注意力层可以粗略地找到潜在的答案域,自注意力层可以进一步定位该域中有可能成为答案的部分。该模型通过计算不同粒度水平和垂直分层上的“文本-问题”注意力,更好地捕捉文本中的特征,在TriviaQA Wikipedia上达到了66.6%的EM值和71.4%的F1值。熊宗杨[36]提出了基于层次注意力机制的机器阅读理解模型HANet。HANet将自注意力、协同注意力以及双向注意力流三种注意力机制分别应用于三个网络层中。利用自注意力机制获取文本和问题各自内部序列之间的长距离依赖关系;利用协同注意力机制捕获文本和问题之间的共现关系;利用双向注意力流对文本和问题进行深层次的理解。通过三个网络层获得不同的粒度级别上的“文本-问题”注意力权重,逐步细化,最终定位到正确答案。该模型在数据集SQuAD1.1上达到了79.4%的F1值,优于传统的Match-LSTM模型与RNet模型。
3.2 基于预训练模型的抽取式机器阅读理解
基于预训练模型的研究方法属于迁移学习的一种,目前NLP领域基本采用预训练加微调的模式。预训练指预先训练模型的过程,微调指将已预训练好的模型作用于自己的数据集,并使参数适应自己数据集的过程,不是从零开始学习,可以把它看作是“站在巨人的肩膀上”。
通过在大规模文本数据上以无监督的方式预训练文本中的语言知识、信息,并将其应用于下游相关任务,如:文本分类、MRC等相关任务。
3.2.1 传统的预训练语言模型
预训练语言模型可以分为两类,分别是自回归语言模型,如ELMO(Embedding from Language Model)[37]、GPT(Generative Pre-Training)[38];和自编码语言模型,如BERT[13]。下面将详细介绍这两类模型以及它们之间的关系。
自回归语言模型训练方向自左向右,导致其在语言生成任务中具有先天优势,同时也导致其不能同时利用上下文信息,对文本的表示能力较弱。Peters等人[37]针对word2vec不能利用上下文信息解决一词多义的问题,提出一种独立方向的BiLSTM语言模型,其使用两个独立模型分别获取上下文信息,并利用简单的向量拼接方式将两个模型关联起来,在一定程度上解决了word2vec的问题。但是,其在本质上仍然是单向自回归语言模型,存在上下文信息特征提取不充分,训练时间长等缺点。Radford等人[38]针对上述问题,提出了GPT模型。该模型采用Transformer架构,在无监督条件下进行训练,利用Transformer中的Decoder模块捕捉更长范围的信息,其效果优于RNN。且由于Transformer是并行运算,可以在训练过程中提升模型的训练速度。
自编码语言模型在训练过程中将文本数据中的某个词随机遮蔽,并根据上下文信息预测被遮蔽的词。自编码语言模型的训练过程需要利用上下文建模语境信息,并预测遮蔽词,文本表示能力大大加强,更能够表示文本的有效信息以及上下文信息。
Devlin等人[13]提出了BERT。BERT是一种利用双向语言模型(Transformer中的Encoder模块)获取词向量表示,利用大规模未标记训练数据生成丰富上下文表示的自编码语言模型。为了更好地将当前词和上下文信息融合在一起,BERT模型通过遮蔽语言方法(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)两个任务分别捕获词级和句子级表示。通过MLM任务用无监督学习的方式预测当前词,能够有效地利用上下文信息;使用NSP任务预测两个句子是否为上下句的关系,Transformer可以捕获到输入语句的全部特征。
针对自回归语言模型与自编码语言模型各自的优劣,Yang等人[39]提出一种泛化自回归方法XLNet。XLNet不使用传统自回归语言模型中固定的前向或后向因式分解顺序,而是将序列进行因式分解,得到所有可能的排列方式,最大化所有可能排列顺序的期望对数似然,由于对因式分解顺序的排列操作,每个位置的语境都包含来自上下文的信息,因此,每个位置都能学习来自所有位置的语境信息,即捕捉双向语境。作为一个泛化自回归语言模型,XLNet不依赖残缺数据,因此,XLNet不存在BERT的“预训练-微调”差异问题。
假设有一组包含n个词的序列文本数据m=[x1,x2,…,x n],存在n!种词排列顺序。在训练过程中,利用自回归语言模型以及输入不同排列顺序的句子预测词的概率;加入位置信息,通过双向流自注意力机制,实现单个词的上下文信息表示。
传统的注意力机制将位置等信息全部编码,而自回归语言模型无法获得当前预测词的位置编码。通过将位置编码拆分提出双向流自注意力机制,即内容流自注意力机制与查询流自注意力机制,其示意图如图3所示[39]。
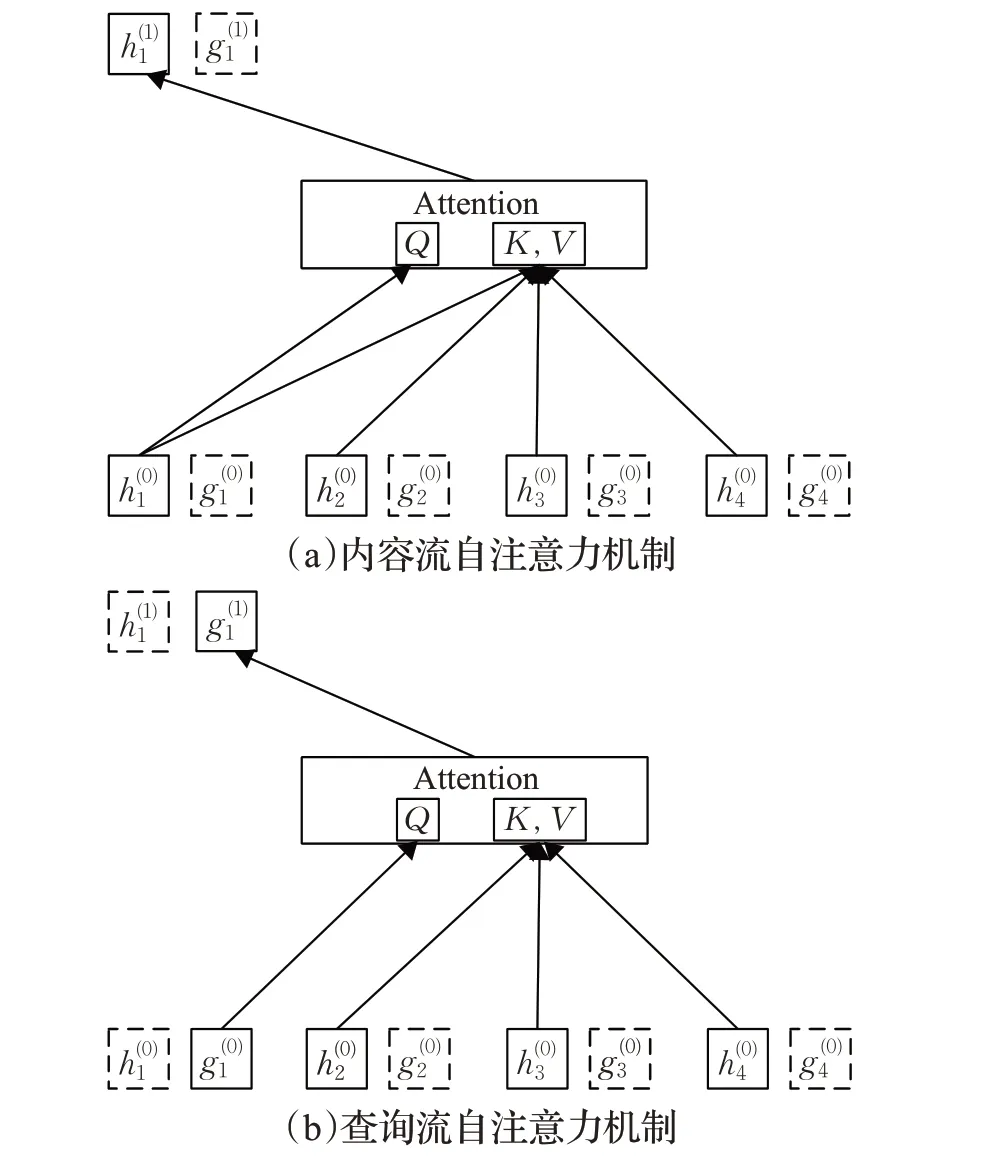
图3 内容流自注意力机制与查询流自注意力机制
内容流:传统自注意力机制,对当前词镜像编码[39]:
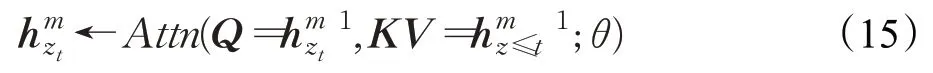
查询流:只看到当前位置编码,无法获得词编码[39]:
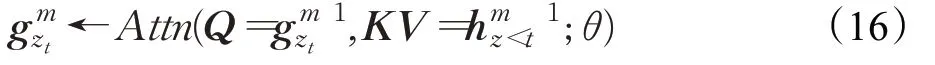
其中,Q、K、V表示查询(query)、键(key)和值(value)。XLNet在训练阶段引入Transformer-XL中的分割循环机制和相对编码范式,从而提升模型的长距离依赖捕获能力。
XLNet模型训练过程如图4所示[39],将内容隐状态h和查询隐状态g分别初始化为词嵌入e(x i)和变量w,通过掩蔽双向流自注意力机制计算每一层输出h(i)和g(i)。在训练过程中将上一片段的结果引入下一片段中:
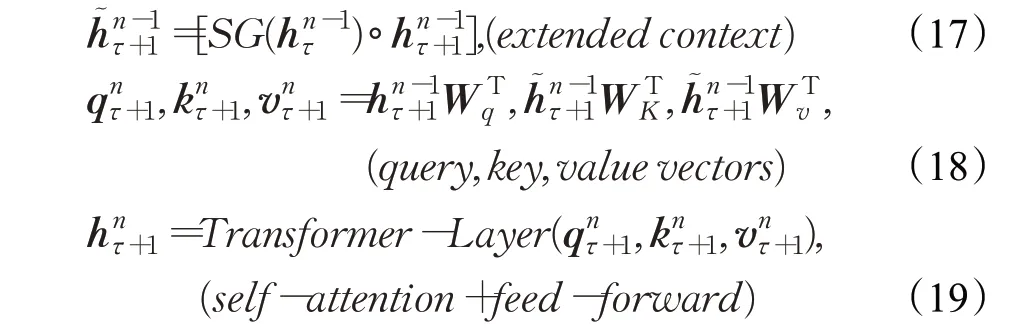
其中,τ表示上一个片段,τ+1表示下一个片段,将τ缓存,并将其直接和τ+1进行拼接,这里SG表示Stop-Gradient。引入上一片段的隐层表示仅用于key和value,query仅代表查询词,而key,value代表查询词的相关表示信息,因此只需在key,value中引入上一片段信息即可。
XLNet模型结构庞大且复杂,但是其在长文本阅读理解任务上效果提升明显。目前,预训练模型在抽取式MRC任务中获得了大幅的性能提升,实验表明预训练模型可以显著增加目标任务的预测准确度,同时缩短模型的训练时间,预训练语言模型有很大的发展空间。
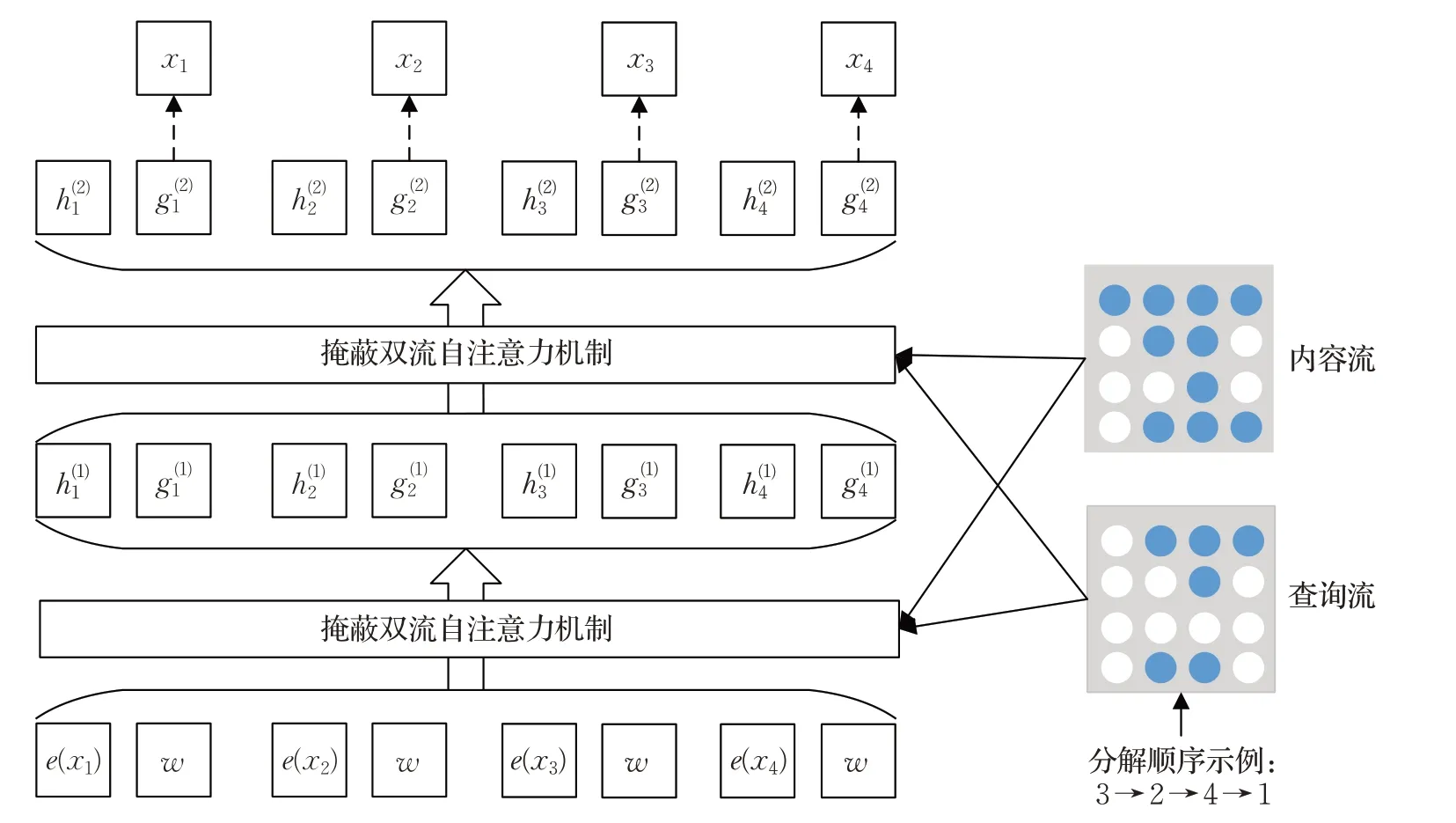
图4 XLNet模型框架图
3.2.2 其他扩展模型
BERT是一个强大的自编码语言模型,其一经提出,就刷新了NLP领域的11个任务的当前最优结果,后续许多学者在其基础上进行改进。Liu等人[40]在BERT的基础上做了精细化调参,改变其预训练的方法,提出了RoBERTa模型。相比于原始的BERT模型,RoBERTa使用了更大的Batch-Size和更大规模的训练数据(160 GB),因此也需要更长的训练时间。RoBERTa去掉了下一句预测任务,并在遮蔽语言方法中使用动态掩码以代替静态掩码。RoBERTa在各类任务中的表现均超越了BERT模型。
在中文领域,Cui等人[41]对RoBERTa模型进行了改进,得到了MacBERT。MacBERT使用同义词,而不是[MASK]作为掩盖词,这样能够减缓预训练和微调阶段的差异,从而提高下游任务的表现。MacBERT在中文MRC数据集上表现优异,在CMRC2018挑战集中达到了60.2%的F1值。接着,Cui等人[42]提出了基于全词遮掩(Whole Word Masking)技术的中文预训练模型BERTwwm,原BERT模型是用[MASK]标记替换一个字,而在BERT-wwm中,如果该字被掩盖,则同属该词的其他字也会被掩盖。预训练过程中,模型能够学习到词的语义信息,训练完成后字嵌入就具有了词的语义信息,有利于各类中文NLP任务。在CMRC2018数据集上的实验结果表明,BERT-wwm性能优于BERT。贾欣针对BERT模型对不同语义层捕获能力不足的问题,提出了基于迁移学习的BERT-wwm-MLFA模型[43]。BERTwwm-MLFA将单向注意力机制和双向注意力机制融合构成全注意力模块,全注意力机制可以在各个层面更好地对“问题-文档”进行编码与交互。在BERT-wwm预训练模型的基础上加入多层全注意力机制,并将其迁移到数据集上重新进行训练,实验表明该模型性能高于基准BERT模型。Cui等人[44]提出了跨语言MRC模型Dual BERT,用于解决在中文领域由于缺乏大规模训练数据而导致的模型稀缺问题。Dual BERT将中文的(数据资源匮乏的目标语言)“文本-问题”对翻译为英文(数据资源丰富的源语言),并使用英文领域性能较好的MRC模型生成答案,最后将生成的答案翻译回中文。该模型在CMRC 2018数据集上达到了90.2%的F1值,取得了当时的最好成绩。
3.3 加入推理机制的抽取式机器阅读理解
人类在做阅读理解时,需要对文章内容进行推理,通过推理判断,人类能够更加准确地理解文章内容,正确回答相关问题。机器也是如此,利用推理机制对MRC模型进行文章内容的理解,使得机器更加准确地回答相关问题。目前,相对困难的问题由于其答案分布在不同位置,寻找问题的答案需要在文章的几个线索中进行综合推理。利用传统模型解决此类问题准确率较低,通过加入推理机制对文章内容进行推理分析,能够更加准确地把握文章内容,提升答案的准确性。
2015年,Sukhbaatar等人[45]提出记忆网络模型,该模型是一种基于循环注意力机制的神经网络模型,是最早引入推理机制的模型,对后续其他推理模型产生了重要影响。其推理过程如下:根据原始问题表达与原始文本表达,利用f函数计算文本中词的注意力权重;利用g函数与原始文本表达以及注意力信息计算新文本表达;利用t函数,根据新文本表达以及原始文本表达推理出问题和文本最终的新表达。这样就通过隐式的内部更新文本表达和显示的更新问题表达实现了一次推理过程,后续每层网络推理过程就是多次重复这个过程。通过多层网络计算完成整个推理过程,记忆网络推理过程如图5所示。
单层推理过程如图6所示[45],推理过程如下:将给定输入集合x1,x2,…,x i存储于存储器中,使用大小为d×V的嵌入矩阵A将每个x i均嵌入到连续空间中,将整个集合{x i}转换为维度d的存储向量{mi}。同样,查询Q也被嵌入以获得内部状态u。在嵌入空间中,取内积后,利用softmax函数计算u和每个存储器m i之间的权重[45]:
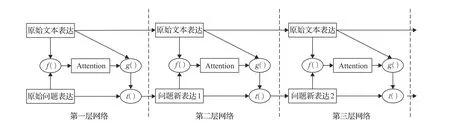
图5 记忆网络推理过程图
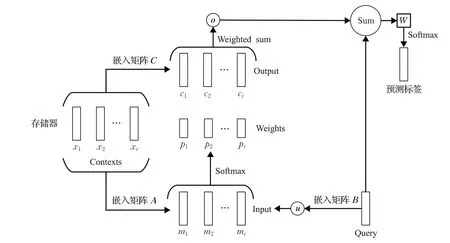
图6 单层推理过程图

c i为输入x i的对应输出向量,存储器的输出向量ο计算公式如下[45]:

计算输出向量ο和输入嵌入u的和,通过大小为V×d的最终权重矩阵W和softmax函数生成预测标签[45]:

AMRNN模型(Attention-based Multi-hop Recurrent Neural Network)[46]的推理过程受记忆网络影响,其基本架构与记忆网络相同,唯一的区别是:记忆网络在拟合文本或问题表示时通过词嵌入方式简单叠加,而AMRNN则是采用双向门控递归单元(Gated Recurrent Unit,GRU)网络从输入问题和文本中顺序取词,将前向GRU网络的隐含层输出和后向GRU网络的隐含层输出连接起来,形成问题和文本的向量表示。
Shen等人模仿人类推理过程,提出推理网络ReasoNet[47]。人类在做阅读推理时,会反复阅读文本,并且每次将注意力集中在文本的不同部分,直到找到答案,ReasoNet的推理过程也是如此。此外,不同于以往模型中使用固定的迭代次数,ReasoNet引入了终止状态,终止状态可以决定ReasoNet是在消化中间结果后继续还是终止推理过程。ReasoNet在抽取式MRC数据集SQuAD1.1上取得了卓越的成绩。
张禹尧等人结合多跳结构和注意力机制,提出了基于多重联结机制的注意力模型MCA-Reader[48]。在最后一次编码时将多轮迭代的全部中间计算结果联结,考虑到了所有的注意力权重,得到更多更全面的特征信息,从而提升模型性能。
3.4 结合外部知识的抽取式机器阅读理解
在人类阅读理解的过程中,当问题不能仅仅通过上下文得到答案时,人类还会运用常识知识。能否运用外部知识(External Knowledge)是MRC与人类阅读理解之间产生巨大差距的直接原因。近年来,随着知识图谱(Knowledge Graph)等概念的出现,将外部知识引入MRC模型成为学者们的研究热点,形成了基于外部知识库的机器阅读理解(Knowledge-Based Machine Reading Comprehension,KBMRC)。KBMRC与MRC的主要区别在于输入,MRC的输入是文本和问题序列,而KBMRC的输入除此之外还有从知识库中提取出的额外相关知识[2]。
Chen等人认为,现有模型虽然获得了很高的准确率,但是它们只关注文本表层信息,在深层语义挖掘上还有待提高,所以提出更有效的模型DrQA[49]。DrQA主要面向开放域阅读理解,首先从维基百科中检索出问题相关段落,然后从段落中找到对应答案,利用Wikipedia作为知识源,在数据集上进行训练。DrQA在SQuAD1.1上的F1值比BiDAF提升了1.7%。姜文超等人[50]针对现有模型缺乏外部基本常识支撑这一问题,提出了结合外部知识的动态多层次语义抽取网络模型。引入外部先验知识层,缩小指针网络定位答案范围,从而对候选答案进行精准排序,从而提升模型的语义匹配度和答案提取精度。Yang等人[51]在BERT模型的基础上融入了外部知识库(Knowledge Base system,KBs),提出了KT-NET模型。KT-NET引入了一种基于注意力机制的知识网络,该网络利用注意力机制自适应地从知识库中选择所需知识,然后将所选知识与BERT融合,实现了基于上下文和知识的预测。该模型在SQuAD1.1数据集上取得了85.94%的EM值和92.43%的F1值。
Wang等人探索了如何将MRC神经网络模型与常识相结合,并基于常识数据的扩展,实现了一个端到端的知识辅助阅读器(Knowledge Aided Reader,KAR)[52]。如图7所示,KAR是由五层架构组成的端到端MRC模型[52]。
词嵌入层使用GloVe分别预训练文本和问题词向量,并将其送入全连接层,得到文本词嵌入L P∈Rd×n和问题词嵌入L Q∈Rd×m,其中n表示文本数,m表示问题数,d表示输出维度数。上下文嵌入层将词嵌入映射到参数共享的BiLSTM中,通过将前向LSTM输出和后向LSTM输出连接起来,得到文本上下文嵌入C P∈Rd×n和问题上下文嵌入C Q∈Rd×m。粗略内存层使用知识辅助的互注意力机制将C Q融合到C P中,输出表示为G͂∈Rd×n,使用BiLSTM对G͂的表征进行编码得到粗略记忆G∈Rd×n。精细内存层使用知识辅助的自注意力机制将G进行信息聚合,使用BiLSTM进行编码,得到文本的新表征将H∈Rd×n。跨距答案预测层经上述层操作得到的信息送入全连接层,得到输出开始位置的概率分布o s[52]:
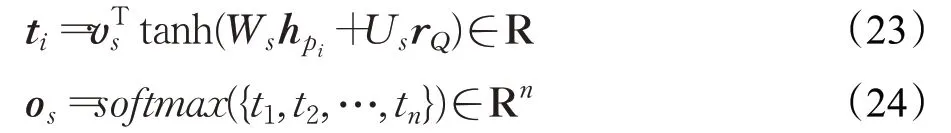
其中,v s、W s和U s为可训练参数;h p i为每个段落单词p i的精细化记忆;r Q为问题摘要;t i为开始位置在文本中每个位置的概率。得到输出结束位置的概率分布o e[52]:
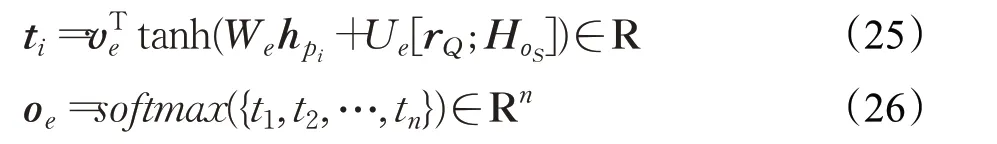
其中,ve、We和U e为可训练参数;[;]表示向量连接;H O S为输出开始位置的表示向量;对两个概率分布o s和o e乘积后选出值最大的[a s,a e]组合,作为最终的预测答案;t i为结束位置在文本中每个位置的概率。KAR在性能上可与最新的MRC模型相媲美,并且抗噪能力更佳,具有较强的鲁棒性。
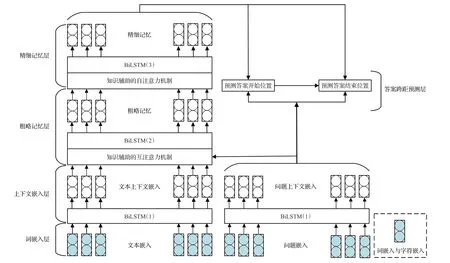
图7 KAR模型框架图
4 总结与展望
本文总结了目前抽取式MRC的四种方法,即基于注意力机制的方法、基于预训练模型的方法、结合外部知识的方法以及加入推理机制的方法。抽取式MRC任务相较于其他MRC任务更贴合生活实际,得到越来越多研究者的青睐。
大规模数据集的建设是促进模型发展的必要前提。自2016年以来,伴随着抽取式MRC数据集的发展,抽取式MRC模型同样出现了井喷式的发展。每个新数据集都提出了新的问题,并且这些问题是当前方法无法有效解决的,新问题启发研究人员不断探索新模型进而促进该领域的发展。
本文针对当前抽取式MRC发展中存在的难点提出以下几点未来研究方向:
(1)随着抽取式MRC数据集的快速发展,数据集文本规模越来越大,这就要求模型从更广泛的文本空间中寻找答案。对于需要从多个文档中进行联合推理才能得到答案的问题,可以考虑将图神经网络应用于推理。通过构建图结构,可以将散落在不同语义粒度(段落、句子等)的信息聚合起来,有利于问题解答[53]。
(2)现有抽取式MRC模型应对迷惑性答案的能力还远远不足,尽管现有模型在一些简单数据集上的表现超越了人类,但它们大多依然停留在简单的文本匹配层面,没有进行更深层次的语义推理。因此,利用深层网络挖掘高层语义信息,设计更深层次、更有效的抽取式MRC模型是当前的迫切需要。同时,可以在数据集中添加高质量对抗性问答对,在给定文本中添加分散注意力的句子,使模型不是通过简单文本匹配就可以得到正确答案,促使研究者们增强对模型鲁棒性的研究,以应对对抗环境的挑战。
(3)目前训练结果较好的模型普遍比较庞大且复杂、训练时间久、对设备要求高、代价大,因此,如何对大型模型进行精简且不降低模型性能是一个值得研究的问题。另外,可以运用模型蒸馏技术[54],即采用迁移学习,通过预先训练好的复杂模型的输出作为监督信号去训练另外一个简单网络。
(4)针对中文数据集的抽取式MRC模型较少,且多数中文模型是在英文模型基础上进行的改进,但中英文语法结构、语序等方面存在巨大差异,因此多数中文模型效果并不理想。构建中文MRC模型需要考虑到一词多义等问题,同样的单词或句子在不同语境下可能表达了不同的含义,所以如何构建更加符合中文语法结构的MRC模型是研究者们需要深入思考的问题。
