维度变化的不完备混合型数据增量式属性约简
2021-06-23刘桂枝
刘桂枝
山西大同大学 物理与电子科学学院,山西 大同037009
属性约简[1-2]又称为维度约简或特征选择,是粗糙集理论的重要应用,其目的是为了删除数据集中对分类不相关的属性,提高数据的知识发现性能,目前属性约简已广泛用于模式识别和数据挖掘等领域。由于实际工程应用环境下,数据集是不断动态变化的,传统的属性约简方法面临着一定的局限性,为了改善这一问题,学者们进一步地提出了增量式的属性约简方法,极大地提升了属性约简的适用范围[3-5]。
增量式属性约简是属性约简领域的热点研究内容。信息系统的属性变化又称为维度变化,是信息系统的一种常见的变化形式,例如在医疗诊断系统中,病人的各项生理指标被采集获取,那么信息系统的属性便发生了增加。对于这类变化形式,学者们提出了多种的增量式属性约简算法,例如对于传统的离散型信息系统,Qian等[6]学者利用正区域加速增量运算的方法,提出了一种高效快速的属性约简算法;Wang等[7]学者基于信息系统的维度变化,提出信息熵的增量式属性约简算法;Qian等[8]学者利用决策正区域的方法提出了属性变化的增量式属性约简算法;Jing等[9]学者利用知识粒度作为属性约简的方法,并构造了知识粒度随属性变化时的增量式计算,同时进一步地设计了相应的增量式属性约简算法;Wei等[10]学者基于区分矩阵的方法,构造了一种属性变化时的增量式属性约简算法;Ni等[11]学者针对决策正区域构造出了一种加速器,提出了大规模数据的快速属性约简算法;Liu等[12]学者针对融合决策表利用不可区分矩阵提出了一种高效的快速增量式属性约简算法。对于优势信息系统,Li等[13]学者在优势粗糙集模型中,研究了优势近似集随属性变化的增量式更新,同时进一步地提出了对应的增量式属性约简方法。对于集值信息系统,Lang等[14]学者提出了属性变化时的增量式属性约简,在Lang的基础上,Luo等[15]学者进一步地提出了集值序信息系统的增量式属性约简算法。在概率粗糙集模型中,Liu等[16]学者提出了一种属性变化时的高效增量式属性约简算法。在完备型的混合型信息系统中,Shu等[17]学者针对邻域粗糙集模型研究了条件信息熵的增量式计算,并设计出了一种增量式属性约简算法。在不完备信息系统方面,Shu等[18]学者给出了决策正区域随属性变化时的增量式更新,同时提出了对应的增量式属性约简;在Shu的基础上,李成等[19]学者和刘吉超等[20]学者分别提出了对应的改进算法;基于不完备信息系统条件信息熵的视角,Wang等[21]学者提出了条件信息熵随属性变化的增量式更新,并提出了一种增量式属性约简算法。
然而,实际中存在着较多的离散型属性和连续型属性混合的不完备信息系统,目前关于这类信息系统的增量式属性约简研究却比较少。在文献[22]中,王映龙等学者提出了不完备混合型信息系统下对象变化的增量式属性约简,因此在本文,将针对不完备混合型信息系统属性变化时,研究其增量式属性约简的问题。受文献[8,18]的启发,本文首先提出了不完备混合型信息系统下邻域粗糙集正区域随属性增加和减少时的增量式更新,理论证明了更新方式的高效性,然后利用这种增量式更新对传统的正区域属性约简进行拓展,提出了一种增量式属性约简算法。实验分析证明了所提出算法的有效性和优越性。
1 基本理论
主要介绍不完备混合型信息系统下的邻域粗糙集模型。
设一个不完备混合型信息系统表示为S=(U,C⋃D),其中U称为信息系统的论域,即数据集样本的集合;C和D分别称为信息系统的条件属性集和决策属性集,其中条件属性集C可分成两部分,即C=C a⋃C n,这里的C a称为条件属性集C的离散型属性集,C n称为条件属性集C的连续型属性集。在不完备混合型信息系统中,∃x∈U,a∈C使得a(x)=*,其中a(x)表示对象x在属性a下的属性值,“*”表示属性值为缺失的值。
定义1[23]给定不完备混合型信息系统S=(U,C⋃D),邻域半径δ,设属性子集A⊆C,并且A=Ac⋃An,其中Ac和An分别表示属性子集A中的离散型属性集和连续型属性集。那么属性子集A在信息系统S下确定的邻域容差关系定义为:
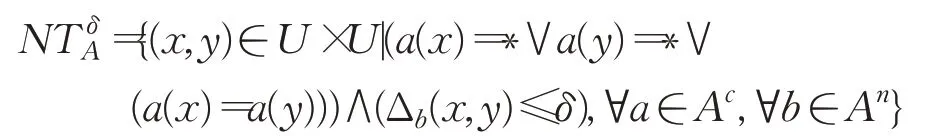
这里的Δb(x,y)表示对象x与对象y之间的距离度量。
定义2[23]给定不完备混合型信息系统S=(U,C⋃D),邻域半径δ,设属性子集A⊆C确定的邻域容差关系为,那么对于∀x∈U关于的邻域类定义为:
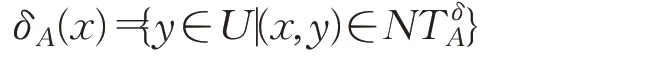
同时对于论域U在邻域容差关系下确定的邻域粒化定义为
定义3[23]给定不完备混合型信息系统S=(U,C⋃D),邻域半径δ,设属性子集A⊆C确定的邻域容差关系为,对于近似对象集X⊆U关于的下近似集和上近似集分别定义为:
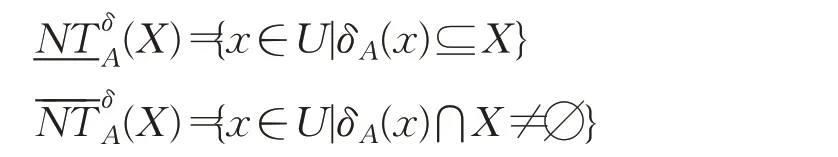
定义4[23]给定不完备混合型信息系统S=(U,C⋃D),邻域半径δ,近似对象集X关于邻域容差关系的正区域表示为:

特别地,对于决策属性集D关于论域的划分U/D={D1,D2,…,D m},那么D关于邻域容差关系的正区域表示为
在粗糙集理论中,正区域是一个很重要的概念,通过它可以直接度量信息系统属性集之间的依赖程度,进而定义出信息系统的属性约简。
定义5[23]给定不完备混合型信息系统S=(U,C⋃D),邻域半径δ,若属性子集red是该信息系统的正区域属性约简,那么当且仅当
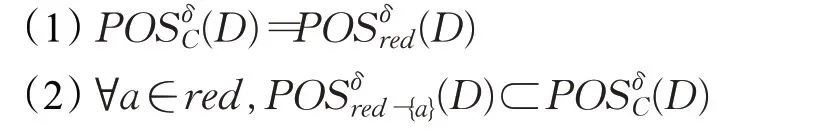
基于定义5所示的属性约简定义,文献[23]提出了一种不完备混合型信息系统的属性约简算法。
2 属性变化时邻域粗糙集正区域的增量式更新
信息系统属性的增加和减少是信息系统最为常见的一种更新变化形式,对于正区域属性约简的更新,如何进行正区域的增量式计算是其中的关键。本章将针对不完备混合型信息系统属性变化的情形,提出正区域的增量式更新,为正区域增量式属性约简的构造提供理论铺垫。
定义6给定不完备混合型信息系统S=(U,C⋃D),对于对象集X⊆U,定义X的决策值域为∂(X)={D(x)|x∈X},其中D(x)表示对象x在决策属性集D下的属性值。
利用定义6中关于决策值域的定义,接下来可以进一步得到正区域的一种等价表达。
定理1给定不完备混合型信息系统S=(U,C⋃D),对于邻域半径δ和属性子集A,那么有:

证明根据定义4中关于正区域的定义,对于∀x∈U,若|∂(δA(x))|=1,说明δA(x)中对象的决策值是一致的,即所以
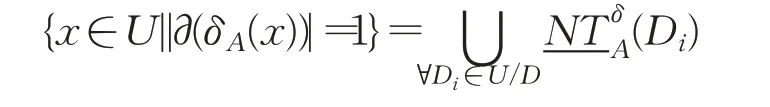
即定理1成立。
定理1提供了一种不完备混合型信息系统正区域的快速便捷计算方法。
给定不完备混合型信息系统S=(U,C⋃D),邻域半径为δ,对于属性集P,Q⊆C和∀x∈U,那么满足关系:
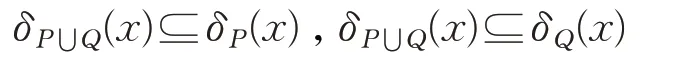
证明根据定义1中关于邻域容差关系的定义,可以得到,再根据邻域类的定义,可以直接得到成立。
定理2给定不完备混合型信息系统S=(U,C⋃D),邻域半径为δ,对于属性集P,Q⊆C满足关系:
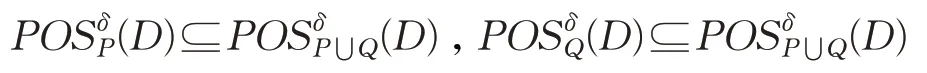
证明根据定义4中关于正区域的定义,可以直接得到定理2成立。
根据上述得到的定理,接下来将分别给出不完备混合型信息系统属性增加和减少时,正区域的增量式更新计算。
定理3给定不完备混合型信息系统S=(U,C⋃D),邻域半径为δ,属性子集P,Q⊆C且P⋂Q=∅,决策类划分为U/D={D1,D2,…,D m},决策属性D关于P的正区域为,当增加属性集Q,新的正区域增量式计算为:
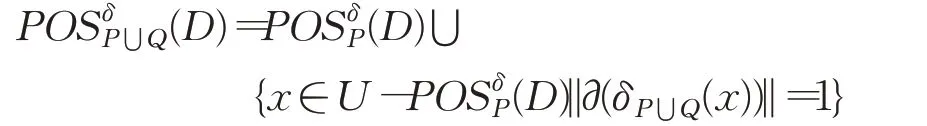
证明对于,根据定义4中关于正区域的定义,满足δP(x)⊆D t(1≤t≤m)。而根据定理1有δP⋃Q(x)⊆δP(x),同样满足δP⋃Q(x)⊆D t(1≤t≤m),即
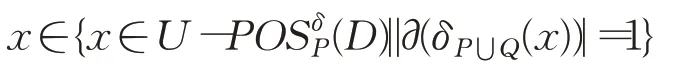
那么δP⋃Q(x)⊆Dt(1≤t≤m)。根据邻域类的定义,那么有由于P,Q⊆P⋃Q,那么显然有:

即δP⋃Q(x)=δP(x)-Y,其中Y={y∈δP(x)|y∉δQ(x)}。
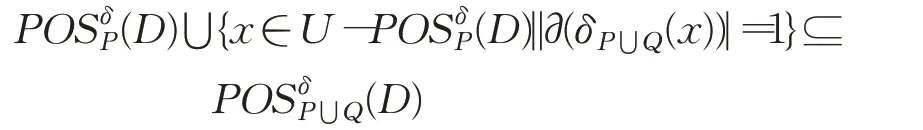
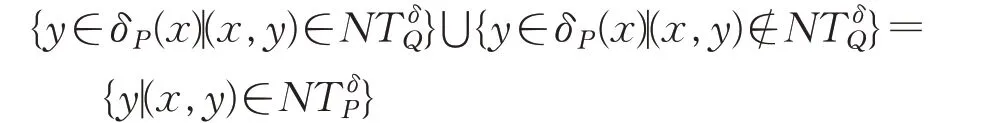
即δP⋃Q(x)=δP(x)-Y,其中Y={y∈δP(x)|y∉δQ(x)}。
通过定理1可得到:
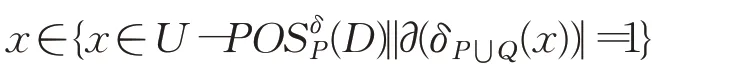
因此
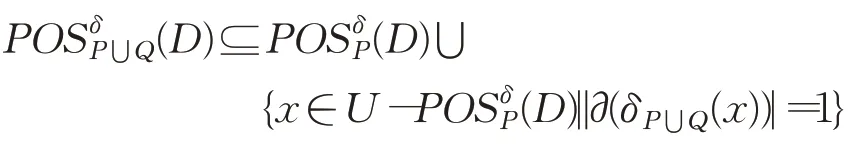
综上所述有:
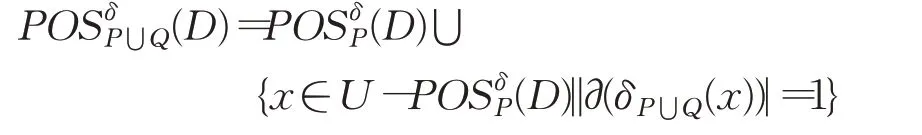
定理3证明完毕。
定理4给定不完备混合型信息系统S=(U,C⋃D),邻域半径为δ,属性子集Q⊂P⊆C,决策类划分为U/D={D1,D2,…,D m},决策属性D关于P的正区域为,当从P删除属性集Q后,新的正区域增量式计算为:
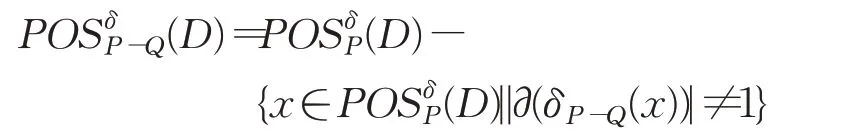
证明由于P-Q⊆P,那么根据定理2有:

由于
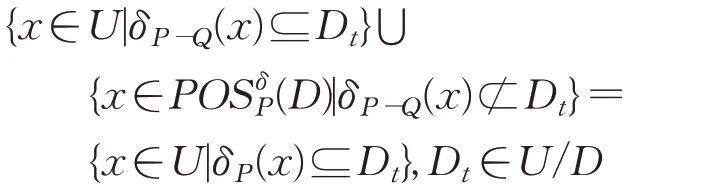
因此
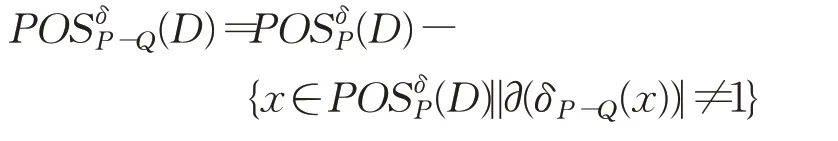
因此定理4成立。
定理3和定理4分别给出了当不完备混合型信息系统增加和减少属性集时,决策正区域的增量式更新计算方法,该计算方法表明当属性发生变化后,不必重新计算论域中每个对象的邻域类,进而计算每个决策类的下近似集,只需在旧决策正区域的基础上,进行进一步地相关计算,便可以快速地完成最终新决策正区域的更新,大幅度提高了计算效率,满足数据集实时更新时的计算速率需求。
3 基于正区域的增量式属性约简算法
本章将在传统的正区域属性约简算法基础上,利用第2章中关于决策正区域的增量式计算方法,分别提出不完备混合型信息系统属性增加和减少时的增量式属性约简算法,具体如算法1和算法2所示。
算法1不完备混合型信息系统属性增加时的正区域增量式属性约简算法
输入:不完备混合型信息系统S=(U,C⋃D),邻域半径为δ,信息系统S的属性约简集red,决策正区域,新增加的属性集ΔC,新信息系统记为S+=(U,C+⋃D),其中C+=C⋃ΔC。
输出:新信息系统S+的属性约简结果red+。
步骤1初始化red+=red。
步骤2根据决策正区域增量式计算//定理3。
步骤3如果,那么直接进入步骤6,否则进入步骤4。
步骤4计算C+-red+中每个属性a的属性重要度
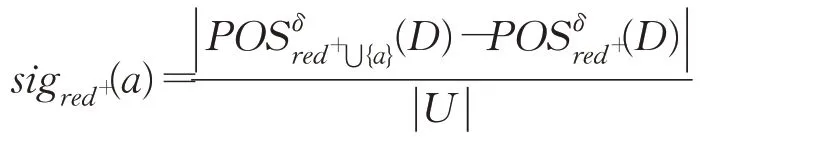
步骤5找出C+-red+中属性重要度sigred+(a)最大的属性,记为amax,若sig red+(amax)>0,那么red+=red+⋃{amax},并重新进入步骤4,否则进入步骤6。
步骤6返回属性约简结果red+。
在算法1中,步骤2在原先正区域结果上进行增量式计算,如果新信息系统的正区域和原先约简集的正区域一致,那么说明原先的约简结果依然可以作为新信息系统的属性约简,则直接返回终止算法。如果不一致,那么需要在剩余的属性中进行进一步地启发式搜索,例如步骤4至步骤5,直到满足正区域的一致性,最终完成属性约简的搜索。整个算法1的时间复杂度可表示为O(|ΔC|⋅|C⋃ΔC|⋅|U|)。
算法2不完备混合型信息系统属性减少时的正区域增量式属性约简算法
输入:不完备混合型信息系统S=(U,C⋃D),邻域半径为δ,信息系统S的属性约简集red,决策正区域,属性集C中减少的属性集ΔC,新信息系统记为S-=(U,C-⋃D),其中C-=C-ΔC。
输出:新信息系统S-的属性约简结果red-。
步骤1初始化red-=red。
步骤2根据决策正区域增量式计算,根据决策正区域增量式计算//定理4。
步骤3如果,那么red-=red--ΔC并直接进入步骤6,否则进入步骤4。
步骤4计算C-red--ΔC中每个属性a的属性重要度
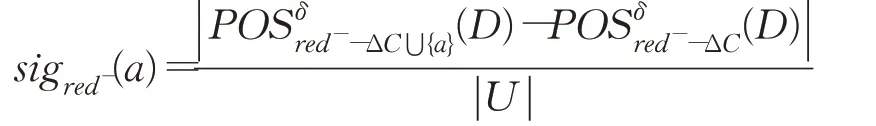
步骤5找出C-red--ΔC中属性重要度sig red-(a)最大的属性,记为amax,若sig red-(amax)>0,那么red-=red-⋃{amax},并重新进入步骤4,否则进入步骤6。
步骤6返回属性约简结果red-。
在算法2中,与算法1类似,步骤2在原先正区域结果上进行增量式计算,如果新信息系统的正区域和原先约简集剔除属性后的正区域一致,那么说明原先约简集剔除相关属性的结果依然可以作为新信息系统的属性约简,则直接返回终止算法。如果不一致,那么需要在剩余的属性中进行进一步地启发式搜索,例如步骤4至步骤5,直到满足正区域的一致性,最终完成属性约简的搜索。类似于算法1,整个算法2的时间复杂度可表示为O(|ΔC|⋅|C-ΔC|⋅|U|)。
4 实验分析
本章将通过实验的方法验证所提出的增量式属性约简算法的有效性和优越性。表1所示的是实验数据集,其中均下载至UCI机器学习数据集库,并且均为混合属性类型的数据集,部分完备型的数据集随机选择了4%的条件属性值进行删除。所有的实验均在Intel®CoreTMi5-6500 CPU 3.2 GHz和8 GB内存的Windows 10操作系统个人PC机上,算法采用Matlab2015b进行编程实现和运行。
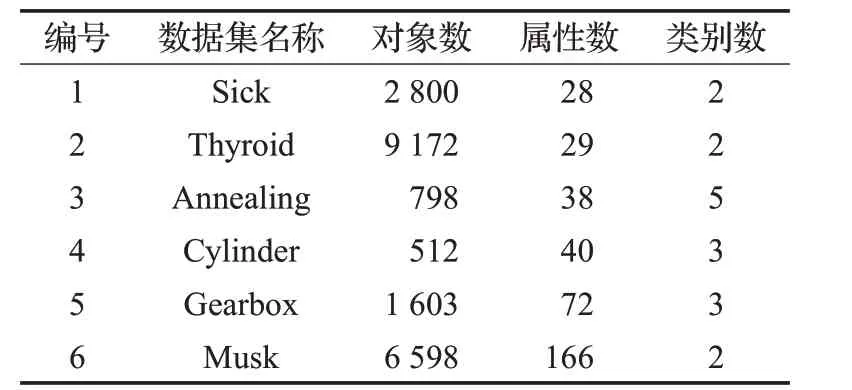
表1 实验数据集
本实验分为三个环节,第一个环节主要是通过实验获得本文算法的合适参数,为后面实验以及本文算法的实际应用提供参考。第二部分是将本文所提出的增量式属性约简算法与传统的非增量式算法对同一组数据集进行动态属性约简,从而验证本文增量式算法的有效性。第三部分将本文算法与其他的增量式算法进行实验比较,以此证明本文算法的优越性。
本实验中所有实验流程均为动态数据集环境下的属性约简,为了实现这一数据环境,这里采用大多数学者的处理方式[18-21],即通过对完整数据集进行分割,然后不断地将分割的各个部分进行融合,从而达到了数据集的增加情形,通过将完整的数据集依次移除每个部分,从而达到了数据集的减小情形。这里将各个数据集的属性大致平均分割成10个子集,随机选择某个属性子集开始不断进行融合,实现了9次属性增加,将各个数据集的属性从属性全集开始,依次删除各个属性子集,从而实现了9次属性减少。接下来的所有实验算法均以此实现方案进行。
为了选择出本文算法中合适的入参邻域半径δ,这里将邻域半径在0.02至0.3之间以0.02为间隔分别取值,将对应邻域半径作为入参进行增量式属性约简,每个取值在每次属性约简下都会得到对应的约简结果,然后利用SVM分类器和NB分类器分别计算约简结果的分类精度,将同一个邻域半径得到的所有分类精度结果求取平均值,其中包含了属性增加和属性减少的两种情形,绘制成图像如图1所示,由于篇幅的限制,这里只列举了部分数据集的结果。
观察图1各个数据集的实验结果可以发现,无论是属性的逐渐增加还是属性的逐渐减少,随着邻域半径的逐渐增大,其约简结果的平均分类精度都是先增大然后逐渐大致减小的,因此说明过大和过小的邻域半径都不能得到较好的实验结果。综合实验结果,将邻域半径选取为δ=0.12较为适宜。
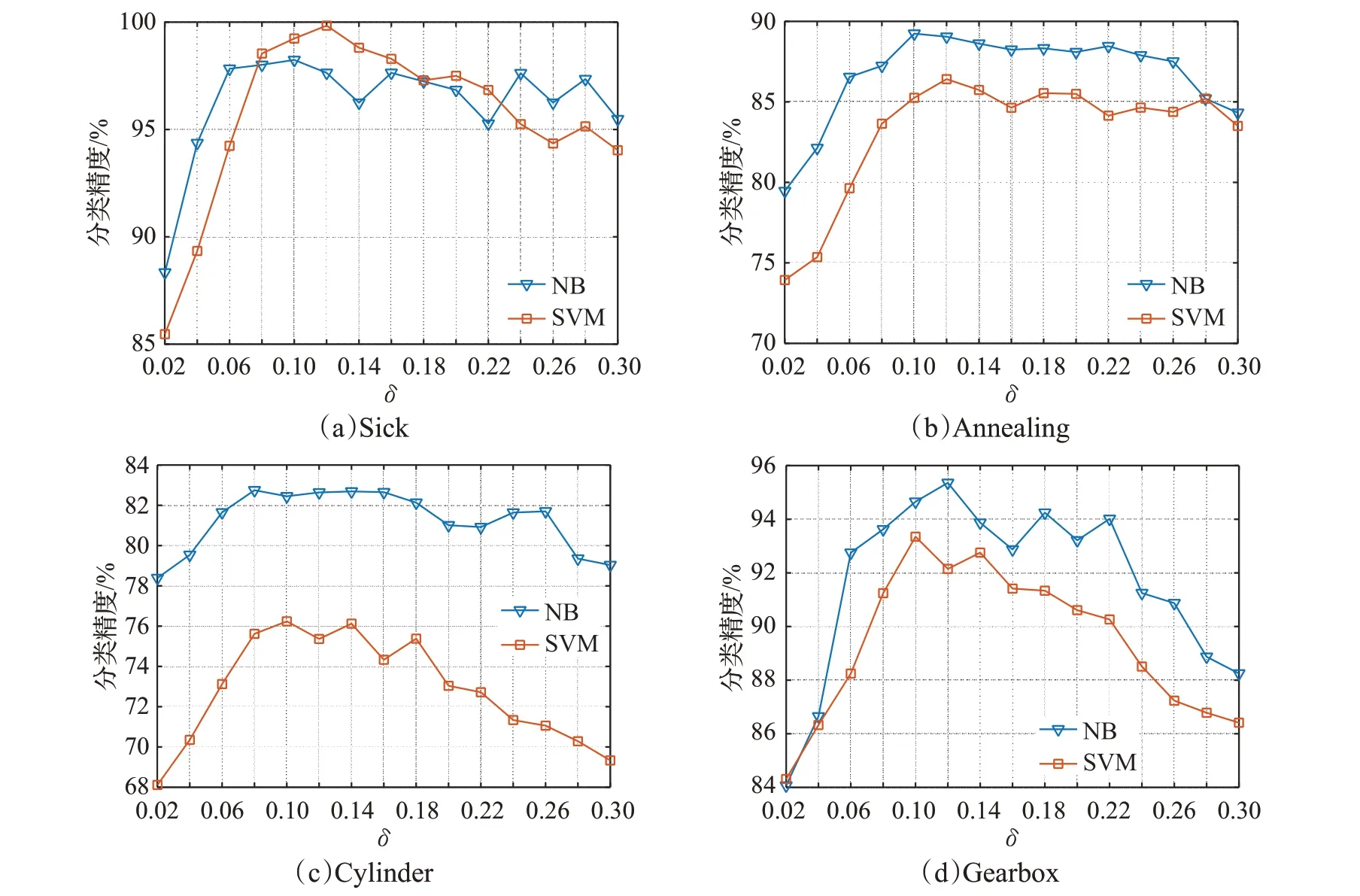
图1 部分数据集不同邻域半径下的分类精度
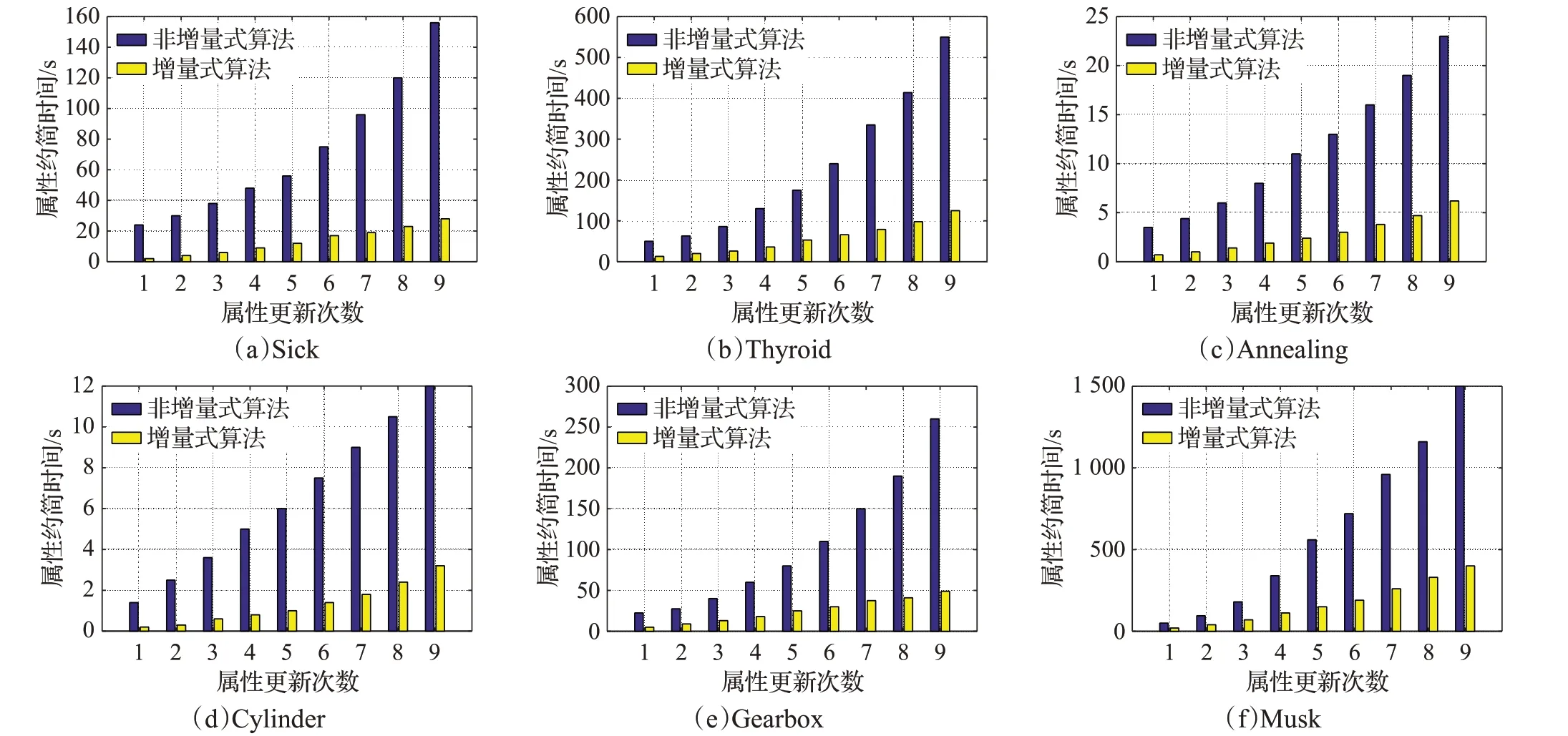
图2 属性增加时增量与非增量算法的约简时间比较
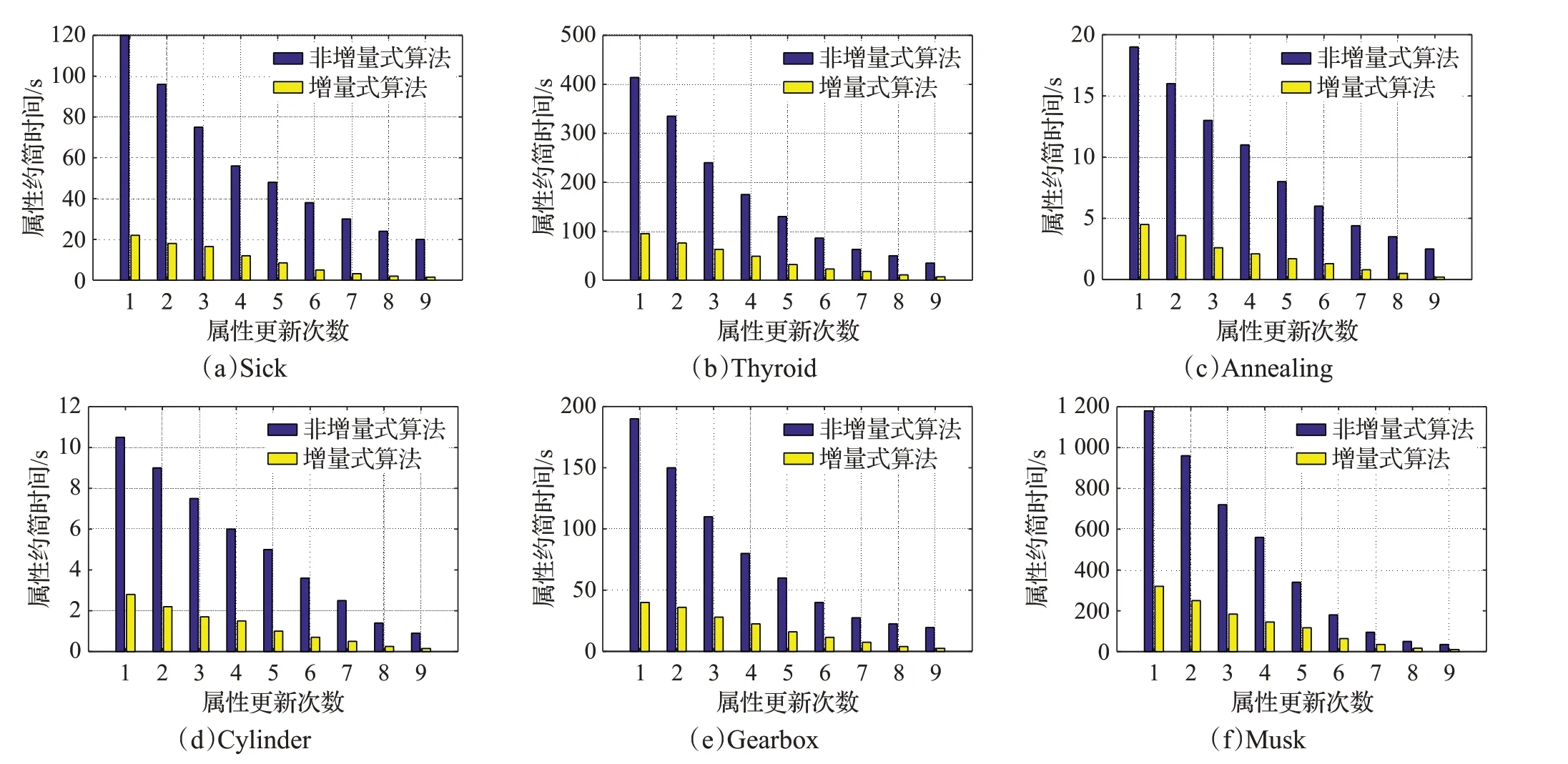
图3 属性减少时增量与非增量算法的约简时间比较
图2 和图3分别所示的是本文的两种增量式属性约简算法与非增量式算法进行动态属性约简的用时比较结果,其中图2展示的是属性增加时的属性约简比较,图3展示的是属性减少时的属性约简比较。每幅图的横坐标代表数据集属性增量更新次数,纵坐标代表属性约简用时。
观察图2中各个数据集的结果,可以看出随着数据集属性的不断增加,本文所提出的增量式属性约简算法的计算用时大幅度小于非增量式算法,并且随着更新次数的增加,这种差距愈加明显。产生这一现象的主要原因是由于随着属性的增加,其数据集的规模逐渐增大,而传统的非增量式属性约简算法需要对完整的数据集进行正区域的相关计算,因此计算量会越来越大,对于增量式算法,随着数据集属性的增加,该算法通过增量式的计算形式,利用前一次的计算结果进行后一次计算,对原先旧数据集的依赖程度较低,因此计算量大幅度小于非增量式属性约简算法。
观察图3中各个数据集的结果,可以看出随着数据集属性的不断减少,本文所提出的增量式属性约简算法的计算用时同样大幅度小于非增量式算法,与图2不同的是,图3中各个数据集刚开始增量式更新时,其增量式算法与非增量式算法的时间差距较大,随着更新次数的增多,两者差距逐渐减小。产生这一现象的原因与图2的原因相反,即刚开始增量式更新时,数据集的规模比较大,因此非增量式算法的用时比较多,随着数据集属性的不断减少,数据集的规模在减小,因此非增量式算法的约简用时也在减小,逐渐与增量式算法缩小了差距,最终更新结束时,非增量式算法与增量式算法的用时比较接近。
综合非增量式属性约简算法与增量式属性约简算法的动态属性约简效率结果,可以看出本文设计的增量式属性约简算法大大提高了对动态数据集的属性约简效率,证明了该算法的有效性。
为了验证本文所提出增量式算法的优越性,本实验选取了三种对比算法。
(1)基于不完备信息系统的条件信息熵增量式属性约简算法[21](记作:对比增量式算法1)。
(2)基于不完备信息系统的正区域增量式属性约简算法[18](记作:对比增量式算法2)。
(3)基于改进的不完备信息系统增量式属性约简算法[20](记作:对比增量式算法3)。
其中这三种对比算法均只适用于离散型的信息系统,因此这三种算法进行实验前需要将表1中的数据集进行离散化处理。
将本文所提出的增量式算法与参与对比的增量式算法对表1中的数据集分别进行动态属性约简,其中图4和图5分别所示的是属性增加和属性减少时各个算法的动态属性约简用时比较结果图。表2和表3分别所示的是属性增加和属性减少时各个算法属性约简的属性数量结果,其中平均属性数量通过每次更新时的属性约简结果求取平均值得到。表4和表5分别所示的是属性增加和属性减少时各个算法属性约简的分类精度结果,其中分类精度也通过每次更新时的属性约简分类精度求取平均值得到。
通过图4和图5可以发现,无论是数据集属性的增加还是属性的减少,其中对比增量式算法1有着最高耗时,对比增量式算法2的用时次之,本文的增量式算法均具有最少的属性约简用时,这主要是由于对比算法1基于条件信息熵进行属性约简,因此约简的过程中计算量比较大,而本文的增量式算法以正区域作为属性约简的启发式函数,并且本文提出了一种等价形式的正区域计算方法,其计算量大幅度降低,因此进行增量式属性约简时具有很高的计算效率。
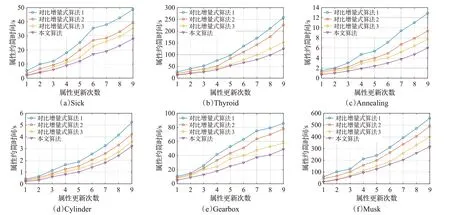
图4 属性增加时各个增量式算法的约简时间比较
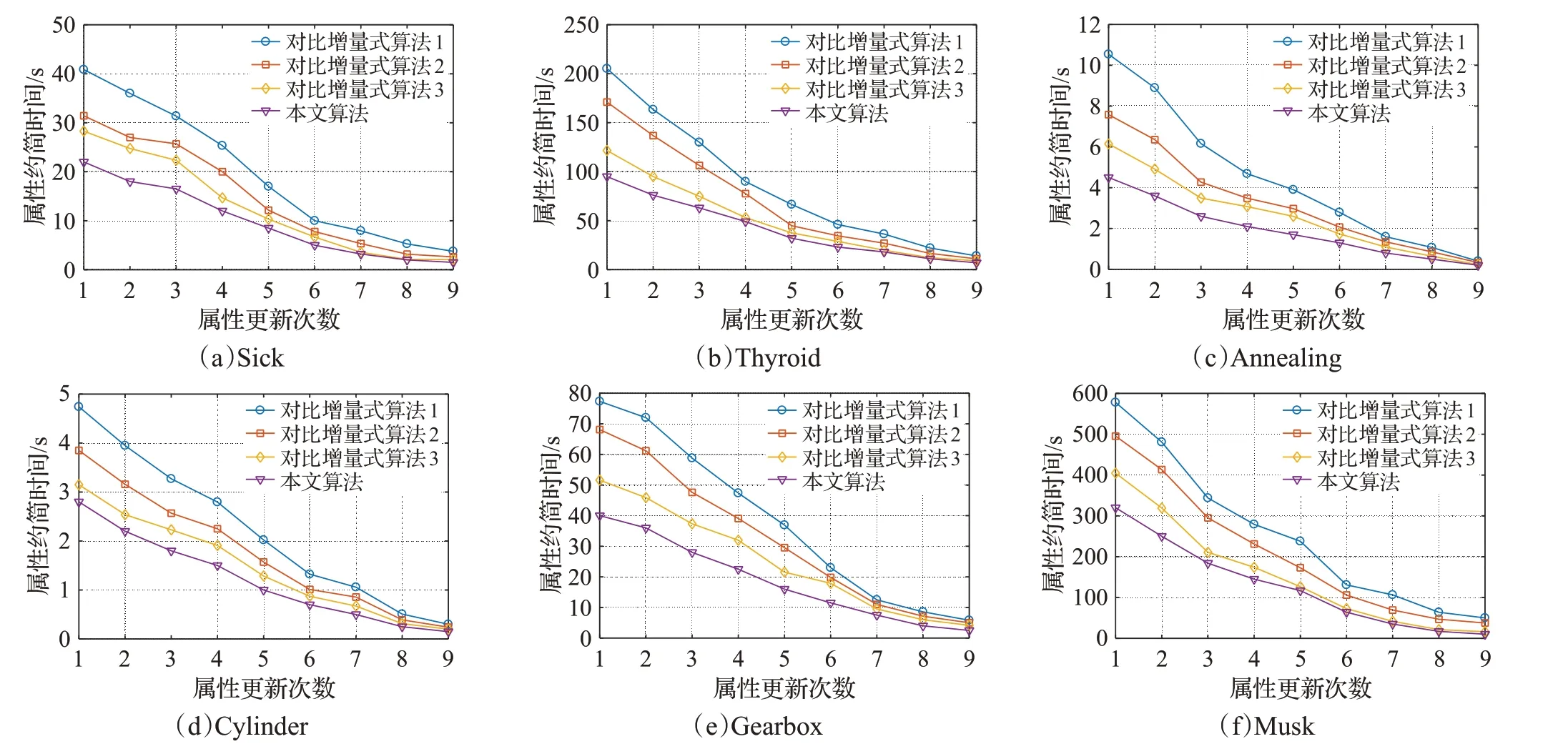
图5 属性减少时各个增量式算法的约简时间比较
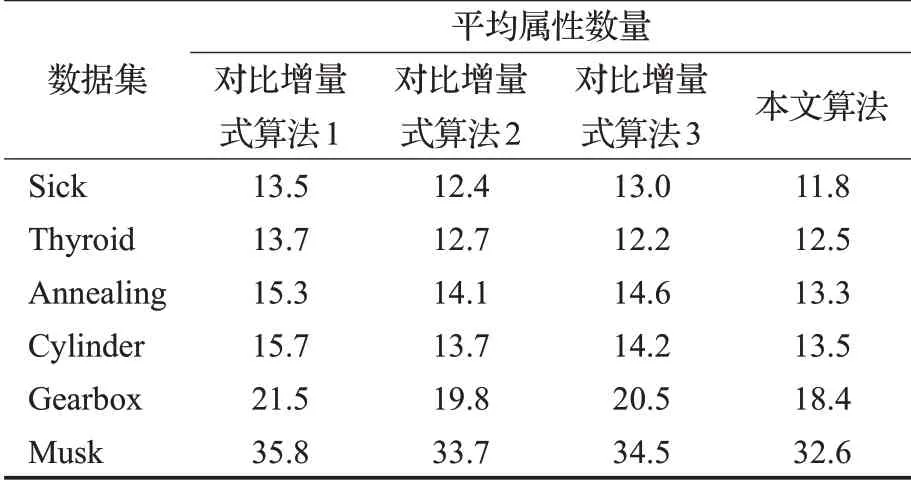
表2 属性增加时各个算法约简结果属性数量比较
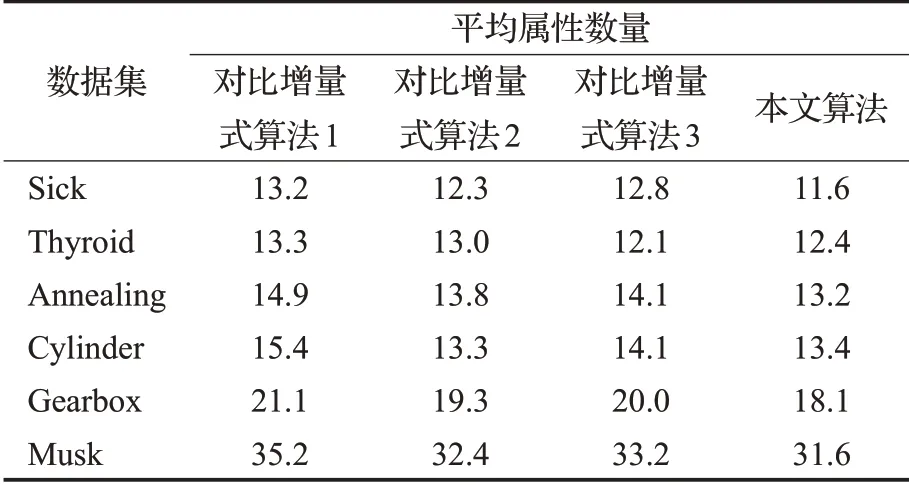
表3 属性减少时各个算法约简结果属性数量比较
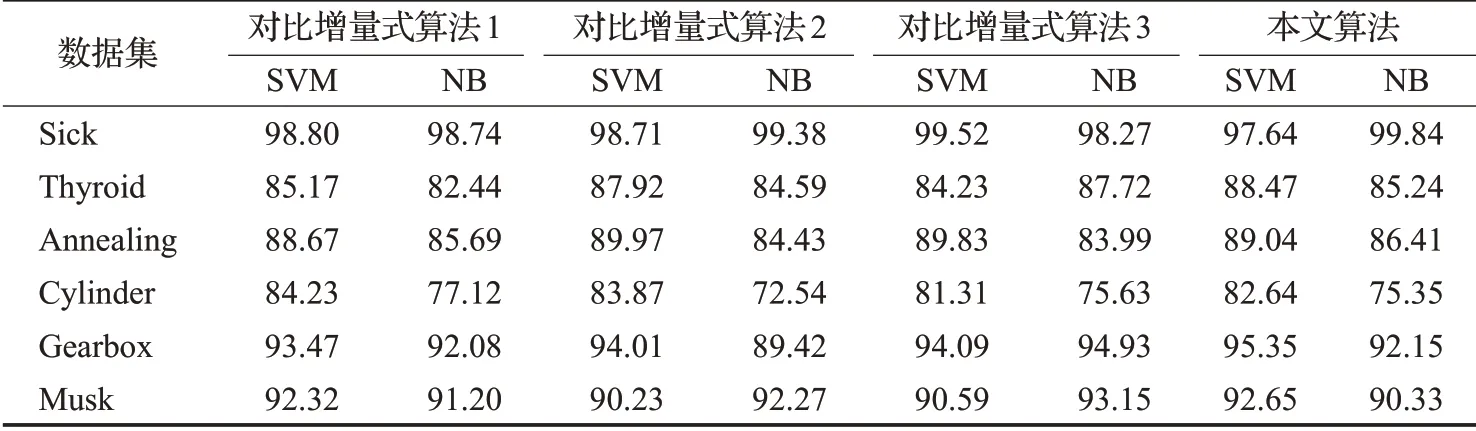
表4 属性增加时各个算法约简结果分类精度比较%
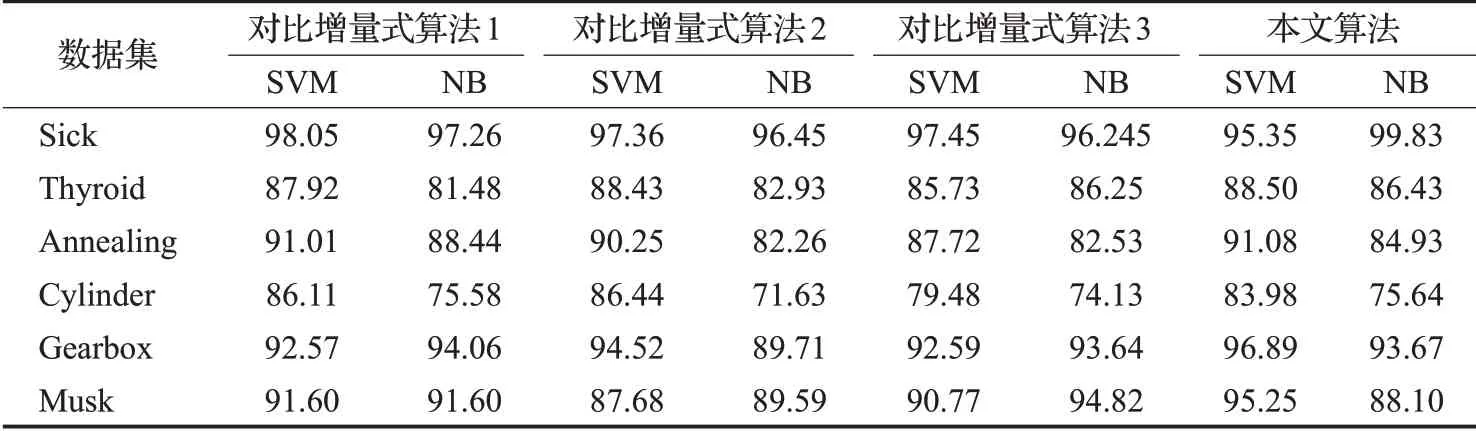
表5 属性减少时各个算法约简结果分类精度比较%
在表2和表3所示的平均属性数量结果中,本文所提出的增量式算法在大部分数据集有着最少的平均属性数量,这一方面得益于正区域度量在属性约简中发挥的作用,正区域作为一种经典的属性约简方法,能够很精准地鉴别出信息系统的关键属性,并且约简结果中很少有包含冗余属性,另一方面由于参与比较的算法需将数据集进行离散化,这一过程丢失了连续型属性的分类信息,因而约简得到的属性会增多,所以本文算法得到的平均属性数量会更少。对于表4和表5所示的分类精度结果,可以发现在表4中,本文的增量式算法在数据集Thyroid、Gearbox和Musk下有着较高的SVM分类精度,在数据集Sick和Annealing下有着较高的NB分类精度。在表5中,本文的增量式算法在数据集Thyroid、Annealing、Gearbox和Musk下有着较高的SVM分类精度,在数据集Sick、Thyroid和Cylinder下有着较高的NB分类精度,综合可以说明本文算法的约简结果在多数数据集下有着较高的分类精度。
5 总结
属性约简是粗糙集理论的重要研究内容,然而实际环境下数据集是不断动态更新的,如何设计出高效的增量式属性约简算法是目前该领域的研究重点。在本文,提出一种不完备混合型信息系统的正区域增量式属性约简算法,其中分别包含了属性增加和属性减少时属性约简的增量式更新。首先文中提出了一种不完备混合型信息系统正区域的等价表达形式,理论分析表明这种计算的高效性,然后利用该正区域的表达形式,分别构造出了属性增加和属性减少时正区域的增量式更新,并证明了这种更新计算方式主要依赖于新加入的数据信息或者减少的数据信息,最后基于这种正区域的增量式计算,分别设计出了属性增加和属性减少时的增量式属性约简算法。通过进行一系列的实验,证明所提出的增量式属性约简算法比非增量式的算法具有高效的动态属性约简性能,同时,与同类型的增量式属性约简算法相比,本文算法也表现出了一定的优越性能。在本文基础上,接下来可以进一步研究对象和属性同时变化以及属性值变化时的增量式属性约简问题,从而进一步扩大增量式属性约简的适用范围。
