基于机器学习动态简化的明尼苏达多相个性调查表*
2021-06-23孙启科董问天马义斌崔飞环冯超南李毓明于淏岿俊1
孙启科 董问天 迟 锐 贺 勇 马义斌 王 克 崔飞环 冯超南 李毓明 于淏岿 于 滨 石 川 纪 俊1,
Hathaway SR与Mckinley JC[1]于1942年配合拟定的明尼苏达多相个性调查表(Minnesota Multiphasic Personality Inventory,MMPI)是国内外使用最普遍的精神疾病检测量表。并且MMPI在人格检测和心理测评中有很好的信效度[2,3]。随着竞争压力的日趋增加[4,5],精神疾病已成为危害我国人民身心健康的重要疾病之一。因此,一套简捷高效的心理健康评估工具对国民身心健康起着至关重要的作用。宋维真等[6]于1985年翻译修订的MMPI是我国目前使用的版本,总共566道题目,其中,用于精神疾病与症状筛查的是前399道题目,包括10个临床测评题组和4个效度题组。据统计,MMPI平均完成时间是42 min[7],测试者很难有耐心全部做完,所以在某些场景使用时,例如体检时进行心理测评,有必要对原始的MMPI做简化,在保持结果一致性的基础上尽量减少题目以提升量表的完成率。目前已有的MMPI简化版本,例如:MMPI-168[8]和MMPI偏见量表的简化[9,10]等,已经被证明其在筛查方面的信效度,但都采用因子分析法生成简化版本的量表,筛查过程中无法保证筛查的针对性和全面性。近些年来,多位学者为简化量表提出了利用机器学习建立模型的新想法。例如,自闭症诊断观察量表(Autism Diagnostic Observation Schedule,ADOS)[11]和社交反应量表(Social Responsiveness Scale,SRS)[12],还有本课题之前的研究成果:中文双相情感障碍诊断清单(Bipolar Diagnosis Checklist in Chinese, BDCC)[13],均是利用机器学习算法分析大量临床测评数据生成分类器将情感障碍评估量表进行简化,并通过对照简化前后结果的敏感性和特异性以验证其一致性。本研究采用ID3(Iterative Dichotmizer 3)算法[14],在上述研究的基础上,计算7 410例患者MMPI测评数据的10个临床测评题组信息增益构造决策树并根据题组的阴阳性实现动态人群分组,再通过6种经典机器学习算法对不同的人群分组进行建模分析,以挖掘满足结果一致性的可缩减题组,进而动态简化MMPI。
1 对象与方法
1.1 对象 数据集来自北京大学第六医院的7 410例患者,所有研究对象有效完成全部399道题目。由于不同性别的测评标准不同,所以首先把数据集分为男3 144例和女4 266例。根据测评标准计算出每例患者10个题组的相应得分,采用机器学习算法将前置题组的得分作为特征预测当前题组的得分。
1.2 方法
1.2.1 实验数据 患者的性别对临床测评题组疑病(Hs)、抑郁(D)、癔症(Hy)、男性-女性倾向(Mf)、精神分裂症(Sc)、轻躁狂(Ma)、社会内向(Si)比较差异均具有统计学意义(P<0.05);年龄因素对临床测评题组各因子比较差异均具有统计学意义(P<0.05)。见表1。

表1 7 410例患者关于MMPI临床测评题组阴性、阳性的人口统计学分析
1.2.2 机器学习算法 本研究采用梯度提升回归树(GBRT)、随机森林(RF)、支持向量回归(SVM)、逻辑回归(LR)、最小绝对收缩和选择算子(LASSO)以及线性判别分析(LDA)6种经典的机器学习算法针对特殊人群分组进行训练和验证以获得相对精准的模型,并选择最优结果模型作为最终结果。
1.2.3 简化过程 步骤1:前置分组划分。如图1所示,首先,计算7 410例测评者每个题组的信息增益,按信息增益大小排序进行数据分组:从10个题组中选择第1个题组作为目标题组,其余9个题组作为特征,通过ID3决策树算法求出9个特征的信息增益,选择最大的特征作为决策树的根节点,根据该节点的阴阳性划分为2个分组,再计算对应该节点的阴性分组或阳性分组剩下8个特征的信息增益,选择最大的特征作为决策树的节点,根据该节点的阴阳性继续划分分组,直到9个特征都作为决策树的节点或分组人数小于100。步骤2:机器学习分类预测建模。将上述划分好的人群分组采用6种经典机器学习算法训练模型,自变量是决策树中各个分组所对应题组数据,因变量是目标题组的结果,并计算分类器的敏感度和特异度,若敏感度和特异度达到75%,则当前人群分组可删除该目标题组。步骤3:迭代计算。再从10个题组中选择第2个题组作为目标题组,其余9个作为特征,重复上述步骤,直到10个题组都当过目标题组后结束。以上述方法排列组合遍历全部分组情况,得到1 707个分组,其中大于100例的分组有938个。
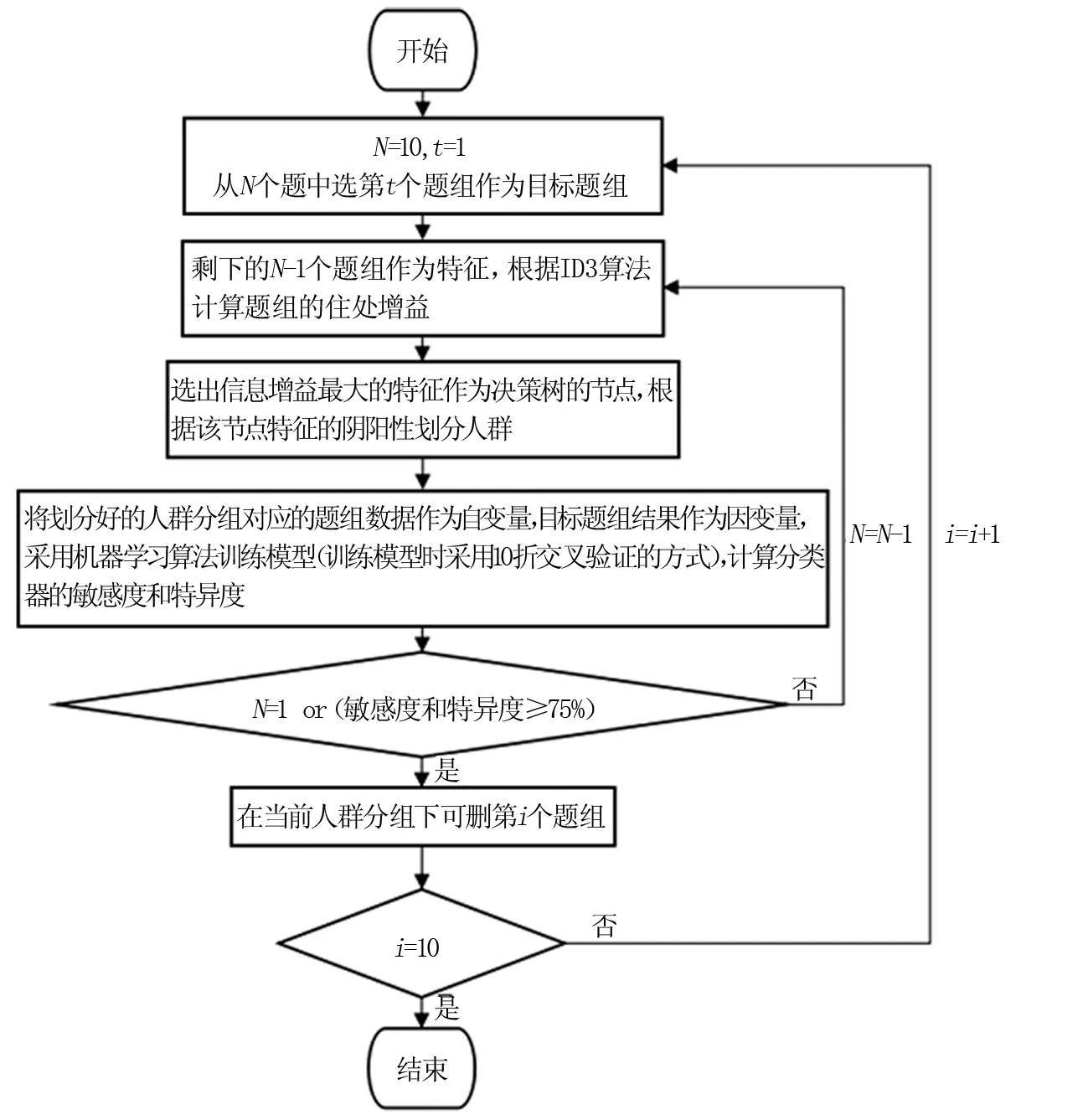
图1 量表简化流程图
1.2.4 评价指标 根据中国常模标准[15],将真实得分与预测得分划分阴阳性,得到混淆矩阵,MMPI简化以敏感度与特异度作为衡量标准。此次研究,以动态删减后的结果保持删减前结果75%的敏感度与特异度为阈值。
1.2.5 统计学方法 采用梯度提升回归树(GBRT)、随机森林(RF)、支持向量回归(SVM)、逻辑回归(LR)、最小绝对收缩和选择算子(LASSO)以及线性判别分析(LDA)统计方法。对数据划分采用了卡方检验,以原量表75%的敏感度与特异度作为检验标准对题组进行删减。
2 结果
图2~4可见,男性通过ID3算法生成疑病(Hs)、精神衰弱(Pt)和癔症(Hy)题组的决策树时,根据决策树节点题组的阴阳性划分100例以上且删除目标题组后敏感度与特异度超过阈值的人群分组。表2可见,针对男性受试者的癔症(Hy)题组为阴且精神分裂症(Sc)、精神衰弱(Pt)题组为阳的分组,抑郁(D)、癔症(Hy)题组为阴且精神分裂症(Sc)、精神衰弱(Pt)题组为阳的分组,男性-女性倾向(Mf)、病态人格(Pd)、精神分裂症(Sc)、社会内向(Si)、精神衰弱(Pt)、妄想(Pa)为阴且抑郁(D)、癔症(Hy)为阳的分组,可删除疑病(Hs)题组;针对男性受试者的精神衰弱(Pt)、精神分裂症(Sc)、抑郁(D)、轻躁狂(Ma)、男性-女性倾向(Mf)、社会内向(Si)题组为阴且疑病(Hs)题组为阳的人群分组,可删除癔症(Hy)题组;针对男性受试者的精神分裂症(Sc)为阴且抑郁(D)为阳的人群分组可删除精神衰弱(Pt)题组。图5、6可见,女性通过ID3算法生成轻躁狂(Ma)和精神衰弱(Pt)题组的决策树时,根据决策树节点题组的阴阳性划分100例以上且删除目标题组后敏感度与特异度超过阈值的人群分组。表3可见,针对女性受试者的精神分裂症(Sc)、病态人格(Pd)、抑郁(D)、疑病(Hs)、社会内向(Si)、妄想(Pa)、轻躁狂(Ma)、男性-女性倾向(Mf)题组为阴且癔症(Hy)题组为阳的人群分组,可删除精神衰弱(Pt)题组;针对女性受试者的社会内向(Si)、抑郁(D)、癔症(Hy)题组为阴且精神分裂症(Sc)、精神衰弱(Pt)、妄想(Pa)题组为阳的人群分组,可删除轻躁狂(Ma)题组。

图2 通过ID3算法生成决策树,删减Hs题组后与删减前结果比较,敏感度和特异度≥75%的男性人群分组
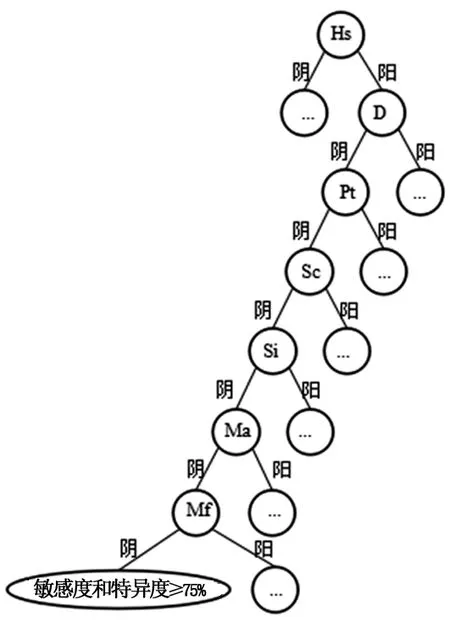
图3 通过ID3算法生成决策树,删减Hy题组后与删减前结果比较,敏感度和特异度≥75%的男性人群分组
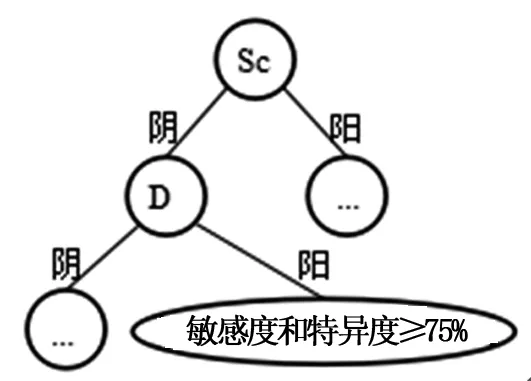
图4 通过ID3算法生成决策树,删减Pt题组后与删减前结果比较,敏感度和特异度≥75%的男性人群分组

表2 男性患者不同前置题组预测优化题组的敏感度、特异度

图5 通过ID3算法生成决策树,删减Pt题组后与删减前结果比较,敏感度和特异度≥75%的女性人群分组

图6 通过ID3算法生成决策树,删减Ma题组后与删减前结果比较,敏感度和特异度≥75%的女性人群分组

表3 女性患者不同前置题组预测优化题组的敏感度、特异度
3 讨论
近些年来,随着机器学习算法的迅猛发展,其在各个领域中都得到了广泛应用,并取得了显著成果。目前,许多典型的研究早已把机器学习算法应用到了精神科量表的简化过程中,并取得了显著的效果。
Hardt J和Gerbershagen HU[16]2001年采用机器学习中的因子分析和主成分分析算法将自评量表SCL-90-R从90个题目简化至27个题目,10个因子简化至6个因子,并在518个样本上分析验证发现因子间的相似性低而因子的内部一致性高,达到了较好的简化效果。Wall DP等[17]在2012年通过对比16种经典机器学习算法简化效果后选择最优的交替决策树算法将孤独症诊断观察量表(Autism Diagnostic Observation Schedule,ADOS)中模块1的29个条目简化为8个,并采用两个不同数据集对简化版本的量表进行验证,得到的分类器准确率接近100%,而完成测评所需要的时间较原始版本减少70%。Kosmicki JA等[18]于2015年通过后向特征选择方法比较8种机器学习算法对ADOS量表的简化效果,将用于筛查孤独症的ADOS量表中的模块2与模块3分别进行简化,将原有的模块2与模块3中的28个行为条目分别简化至9个和12个行为条目,条目数量均减少了55%以上,而准确率分别为98.27%和97.66%。Abbas H等[19]在2017年将传统的问卷调查与手机视频文件相结合,提出了一种采用机器学习算法诊断孤独症儿童的新方法,该方法相比于传统修正的儿童孤独症筛查量表(M-CHAT)更加准确。2016年,Duda M等[20]通过四种机器学习算法将社会反应量表(Social Responsiveness Scale, SRS)由65个题目简化至5个题目,简化后的量表用于区分孤独症谱系障碍与注意缺陷多动障碍的AUC达到0.965的准确率。Duda M等[21]于2017年在之前研究的基础上提出了一个新的分类算法,利用机器学习算法在一个新的数据集上,通过SRS衍生出一个仅有15个题目的新简化版本,其AUC为0.89±0.01,这一简化版本的稳定性更高。Halim A等[22]在2018年提出采用机器学习算法,将半结构化的标记儿童的家庭短视频与结构化的父母报告调查问卷相结合,使用创造性的特征选择方法,简化出一个用来检测儿童是否患有孤独症的测评工具。通过对162个样本数据的研究发现筛查时间仅为原来的25%,且筛查工具的准确性得到了提高。Tariq Q等[23]于2018年通过8种机器学习算法,从两个不同标准的诊断仪器的记录中,构建出用于诊断孤独症儿童的分类器,并且具有较高的分类准确率和很强的可解释性。其中,8种机器学习算法中的Logistic回归算法仅用了8个特征,其AUC就能够达到0.92。
在国外,使用机器学习算法来简化精神科诊断量表已经有了较多相关的研究,并且得到了较多的研究成果,但在国内,相关的研究还比较缺乏。2019年,Ma Y等[13]通过对5种机器学习算法的比较,采用前向特征选择,对情感障碍评估量表(Affective Disorder Evaluation, ADE)进行了简化,并且根据随机森林计算的题目重要性开发出了中文双相情感障碍诊断清单(Bipolar Diagnosis Checklist in Chinese, BDCC),BDCC仅用原来15%的条目就能够区分双相情感障碍患者、重度抑郁患者和健康人群,且准确率可分别达到96%、93%和99.6%。
在国内,Ma Y等[13]于2019年的研究是在我国人口基数较大的背景下,探求一个适用于体检中心的简化量表。本研究是在此基础上,将机器学习算法应用于MMPI的简化过程中,并根据MMPI不同题组的特点,通过区分前置题组的阴阳性,探求一个能够动态简化的MMPI。
MMPI作为世界上被使用次数最多的人格测验量表之一,它的简化具有重要的意义,能减少测评者的测试时间,提高咨询效率,为有需要的患者提供便利。本研究在进行MMPI简化时,针对不同人群分组,以动态删减后的结果保持与删减前结果75%的敏感度与特异度为阈值,采用6种经典机器学习算法预测题组的敏感度和特异度,针对男性测试者的癔症(Hy)为阴性且精神衰弱(Pt)、精神分裂症(Sc)为阳性的分组,癔症(Hy)、抑郁(D)为阴性且精神衰弱(Pt)、精神分裂症(Sc)为阳性的分组,精神分裂症(Sc)、精神衰弱(Pt)、妄想(Pa)、男性-女性倾向(Mf)、病态人格(Pd)、社会内向(Si)为阴性且癔症(Hy)、抑郁(D)为阳性的分组,可删除疑病(Hs)题组,减少8.3%的题目;针对男性测试者的抑郁(D)、精神衰弱(Pt)、精神分裂症(Sc)、社会内向(Si)、轻躁狂(Ma)、男性-女性倾向(Mf)为阴性且疑病(Hs)为阳性的分组,可删除癔症(Hy)题组,减少15.0%的题目;针对男性测试者的精神分裂症(Sc)为阴性且抑郁(D)为阳性的分组,可删除精神衰弱(Pt)题组,减少12.0%的题目;针对女性测试者的精神分裂症(Sc)、抑郁(D)、病态人格(Pd)、社会内向(Si)、疑病(Hs)、妄想(Pa)、轻躁狂(Ma)、男性-女性倾向(Mf)为阴性且癔症(Hy)为阳性的分组,可删除精神衰弱(Pt)题组,减少12.0%的题目;针对女性测试者的抑郁(D)、社会内向(Si)、癔症(Hy)为阴性且精神分裂症(Sc)、妄想(Pa)、精神衰弱(Pt)为阳性的分组,可删除轻躁狂(Ma)题组,减少11.5%的题目。
综上所述,机器学习在精神科量表中的应用具有很广阔的前景,简化后的MMPI不仅节省了心理测评时间还能够帮助医生进行有效的筛查和辅助诊断。基于本研究提出的机器学习模型,继续扩大数据量,能够挖掘出更多的可简化分组。由于在划分人群分组时,100例以下的分组数据量少容易过拟合,因此不考虑少于100例的人群分组。然而因为男性-女性倾向(Mf)量表的阳性数据量不足,只有114例,在机器学习中模型无法学习到足够多的阳性数据,存在数据偏移问题,预测结果不够准确,因此还需要尽量收集更多的男性-女性倾向(Mf)阳性数据,进一步得到更高精度、具有更高效率的简化量表。
