混合遗传算法求解含机器可利用约束的HFSP
2021-06-21张慧贤
轩 华 王 晶 张慧贤 李 冰
(郑州大学管理工程学院 河南 郑州 450001)
0 引 言
带机器可利用约束和阻塞的混合流水车间调度问题(Hybrid Flowshop Scheduling Problem with Machine Available Constraint and Blocking,HFSP-MACB)同时考虑了机器故障和机器阻塞。由于机器故障或维护等使机器在一定时间内无法用于正常工作。在实际生产过程中,机器故障是常见的不确定因素,会对生产计划和结果产生偏差,甚至可能会引起配送等环节的混乱。因此在制定生产计划时考虑机器故障干扰,减少机器故障对调度性能的影响。此外,在相邻生产阶段的缓冲区能力有限或不存在,当工件完成前道工序的加工后,如不能进入缓冲区等待则需停留在加工它的机器上直至下游机器释放,从而导致了该机器的阻塞。这类问题在工业生产中有着较广泛的应用。例如,在船舶平面分段制造模式下,平面分段的重量和体积较大等导致难以储存,考虑到经济性,工序之间一般不设置缓冲区,当前道工序的任务完成后,需要下道工序的工位释放后才能继续进行加工,此时就形成了阻塞。同时,分段从前道工序运送到后道工序的运输时间不可忽略。因此,这就形成了考虑运输时间的HFSP-MACB。Hall等[1]已证明当机器数多于两台时不考虑运输时间的阻塞流水车间是强NP-hard,故所研究的带运输时间HFSP-MACB也是强NP-hard。
运输时间有两类,一类是与工件相关,即运输时间取决于工件自身;另一类是工件无关的,即运输时间由相邻生产阶段之间的距离决定。针对带运输考虑的两阶段HFSP,为最小化makespan,文献[2]假定运输时间取决于工件,每阶段有多台同构并行机,提出了一种两阶段启发式和一种分支定界精确方法;文献[3]针对阶段1含多台批处理机而阶段2有多台离散机的情况,考虑与工件无关的运输时间,提出一种混合多种启发式规则的差分进化算法。针对带运输考虑的多阶段HFSP,文献[4]还考虑了可能返工时间、不同准备时间和预期顺序相关调整时间,提出了一种增强入侵杂草优化算法以最小化makespan;文献[5]针对初始阶段有串行批处理机的情况,提出了改进遗传算法以最小化总加权完工时间;文献[6]则针对可重入HFSP,提出了两种拉格朗日松弛算法以最小化总加权完工时间。
为解决带阻塞的混合流水车间makespan问题,在中间缓冲能力有限的条件下,文献[7]提出了启发式算法,该方法也可用于求解阻塞HFSP;文献[8]以表面贴片技术线为背景,提出了一种精确算法和一种启发式方法;文献[9]提出了一种禁忌搜索算法。在无中间缓冲的条件下,文献[10]提出了一种启发式算法;文献[11]基于禁忌搜索和优先级规则提出一种方法;文献[12]结合嵌套变邻域搜索提出了一种memetic算法;文献[13]提出了混合粒子群优化算法;文献[14]假定并行机为无关机,提出了一种改进离散布谷鸟搜索算法;文献[15]假定每阶段有不同加工速度的并行机,相邻阶段间由一个单爪机器人运送零件,每个零件在每个阶段只能由指定机器集中的一台进行加工,提出了基于模拟退火的求解方法;文献[16]考虑了无关并行机和机器合格性约束,利用机器人卸载、运送和装载零件,每个零件有释放时间,其运输时间取决于工件,基于蚁群优化和遗传算法提出了两种超启发式算法。
上述文献均默认机器在所有时间连续可用,然而,这种假设在实际工业生产上并不成立。目前关于机器可用性与生产集成调度的研究多为单机[17-18]、并行机[18]、流水车间[19-20]和混合流水车间环境[21]。对于较为复杂的阻塞HFSP的研究较少,文献[22]探讨了两阶段阻塞HFSP,假设机器不能连续可用,提出了遗传算法最小化makespan。但是缺乏关于同时考虑阻塞和机器可利用约束的研究。研究的目标多为makespan,而总加权完成时间问题有助于降低在制品库存和加强工序间的时间衔接等。为此,本文以考虑运输的多阶段HFSP-MACB的集成调度为研究对象,以最小化总加权完成时间为目标,建立基于故障时间窗的集成优化模型,提出一种混合启发式和局域搜索的自适应混合遗传算法以有效求解该问题。
1 问题描述与建模
n个工件通过s个工序进行加工,至少存在某个工序p的同构并行机数Mp≥2,一台机器一次只能加工一个工件,一个工件一次只能在一台机器上加工;工件在相邻两个工序之间传送都需要运输时间;相邻两个工序之间无中间缓存区;由于机器长时间加工导致磨损、老化等,机器有一定发生故障的概率,当机器发生故障时,对机器进行维修,维修期间机器无法用于工件加工。通常机器发生故障的准确时间是无法预知的,因此采用机器故障统计相关数据的概率分布代替,计算公式如下:

n∈{1,2,…,N},z∈{1,2,…,Z}
(1)
式中:Pn(z)表示机器n在时刻z出现故障的概率;Zn表示机器n的运行时间。
1) 已知参数。工件集为J(J=1,2,…,n),j表示工件序号,n表示工件总数;工序序号为p,总加工工序为s;工序p的机器数为Mp,机器序号为m,总机器数为TM;工件j从工序p到p+1的运输时间为Tj(p,p+1);工件j在工序p的机器m上加工时间为Wjpm;Z表示计划时间范围,z为时间段序号,z∈{1,2,…,Z};hj表示工件j的权重。
2) 决策变量。若工件j在工序p使用机器m加工,Xjpm值为1,否则为0;若工件j在时刻z正在工序p上加工或阻塞,Yjpz值为1,否则为0;时刻z第p道工序可用的机器数为apz;工件j在工序p的开始加工时间为bjp,完成加工时间为cjp;工件j的完工时间为Cj。
3) 目标函数。以最小化总加权完工时间为目标:
(2)
4) 工序优先级约束。工序优先级约束要求工件在每道工序只有在前一工序加工完成并运输至后一工序,才可开始该工序的加工:
Tj(p,p+1)+cjp+1≤bj,p+1j∈J,p∈{1,2,…,s-1}
(3)
5) 机器能力约束。
(4)
p∈{1,2,…,s},z∈{1,2,…,Z}
(5)
式(4)表示工件在各工序只能在一台机器上进行处理;式(5)表示机器能力约束要求z时刻在工序p上加工被占用工件数不能超过工序p可利用的机器总数。
6) 工序加工时间要求。工件j在第p道工序的加工时间表示为:
cjp=bjp+Wjpm-1j∈J,p∈{1,2,…,s},m∈{1,2,…,TM}
(6)
7) 机器占用时间约束。工件j在工序p上占用机器时间等于工件在p+1阶段的开工时间减去在p阶段的开工时间及工序p到p+1之间的运输时间:

j∈J,p={1,2,…,s-1}
(7)
2 自适应混合遗传算法
由于HFSP-MACB是强NP-hard问题,因此提出基于启发式规则的自适应混合遗传算法(Heuristic Rules Based Adaptive Hybrid Genetic Algorithm, HR-AHGA)求解上述模型。遗传算法是基于生物进化原理提出的一种智能搜索算法,有较好的鲁棒性,但容易陷入局部最优。设计多种启发式规则对初始种群进行改进,并采用自适应交叉和变异一定程度避免算法早熟。利用局域搜索 (Local Search, LS)对GA解的邻域空间作进一步搜索,改善解的质量。
2.1 基于启发式规则初始化种群
采用自然数编码方式,每个染色体为n个工件的排序,即μ={μ(1),μ(2),…,μ(n)},其中μ(k)表示染色体上第k个位置工件的工件号,工件个数即为染色体长度。
初始化种群,采用启发式规则(Heuristic Rules, HR)和随机产生程序相结合的方式。基于五种启发式规则HRl(l=1,2,…,5)产生解集{Ω1,Ω2,Ω3,Ω4,Ω5},30%的初始种群从解集{Ω1,Ω2,Ω3,Ω4,Ω5}中均匀重复选取,剩余的70%个体采用随机生成的方法,从而构成最终的初始种群。其中启发式规则设计如下:
(1) 权重越大越优先加工规则HR1。将工件按权重Wh的降序排序,依次将工件分配到可利用的机器上,得到可行解Ω1。


(4) 总阻塞时间越小越优先规则HR4。随机产生多个可行解,计算相应的总阻塞时间,得到最小阻塞时间对应的可行解Ω4。
(5) 最大完工时间越小越优先规则HR5。对若干个随机生成的可行解分别计算最大完工时间,得到最大完工时间最小的可行解Ω5。
2.2 适应度函数及选择

2.3 自适应交叉与变异算子
交叉算子采用单点交叉的方式,将选择后的染色体顺序打乱,取相邻的两个父代个体配成一组,随机选择一个基因位,交换该基因位之前的染色体片段,形成新的子代染色体,若交换后出现基因重复,则修正重复点,从而形成两个可行的子代。
变异算子有利于提高种群的多样性,防止算法陷入早熟。采用两点倒置变异,随机选择染色体上的两个基因位并交换这两个基因,形成新的子代,如图1所示。

图1 两点倒置变异
传统GA的交叉和变异概率通常是个常数,而遗传进化本身是一个动态的过程,这种设定可能不利于有效求解。因此,设计了随迭代进程动态变化的交叉概率pc和变异概率pm,来增强GA的搜索能力及更新速度。

(8)

(9)

设置pcmin=0.35,pmmax=0.15。
当1≤g≤G/4时,pmmin=0.006,pcmax=0.65;
当G/4≤g≤3G/4时,pmmin=0.045,pcmmax=0.5;
当3G/4≤g≤G时,pmnin=0.09,pcmax=0.3。
2.4 应用LS更新GA解
为进一步提高GA当前解,引入局域搜索,在GA解的邻域中继续寻优。邻域解由交换GA解染色体的两个基因位产生,将染色体上第k(k=1,2,…,n-1)个位置的基因分别与第k+1,k+2,…,n位置的基因交换,将得到的适应度值最大的染色体对应的序列作为最佳邻域解。
2.5 算法流程
基于上述描述,得到HR-AHGA的流程,如图2所示。

图2 HR-AHGA流程
3 算例实验及实验分析
3.1 算例实验
设工件数n=7,工序数s=3,每道工序上的并行机数分别为2、3、2。工件加工时间Wjpm、权重hj和相邻工序之间的运输时间Tj(p,p+1)如表1所示,运行HR-AHGA得到最佳调度方案为1→2→4→5→7→6→3,调度解如图3所示,其中:M表示机器;J表示工件,b表示相应工件在机器上阻塞。

表1 算例数据
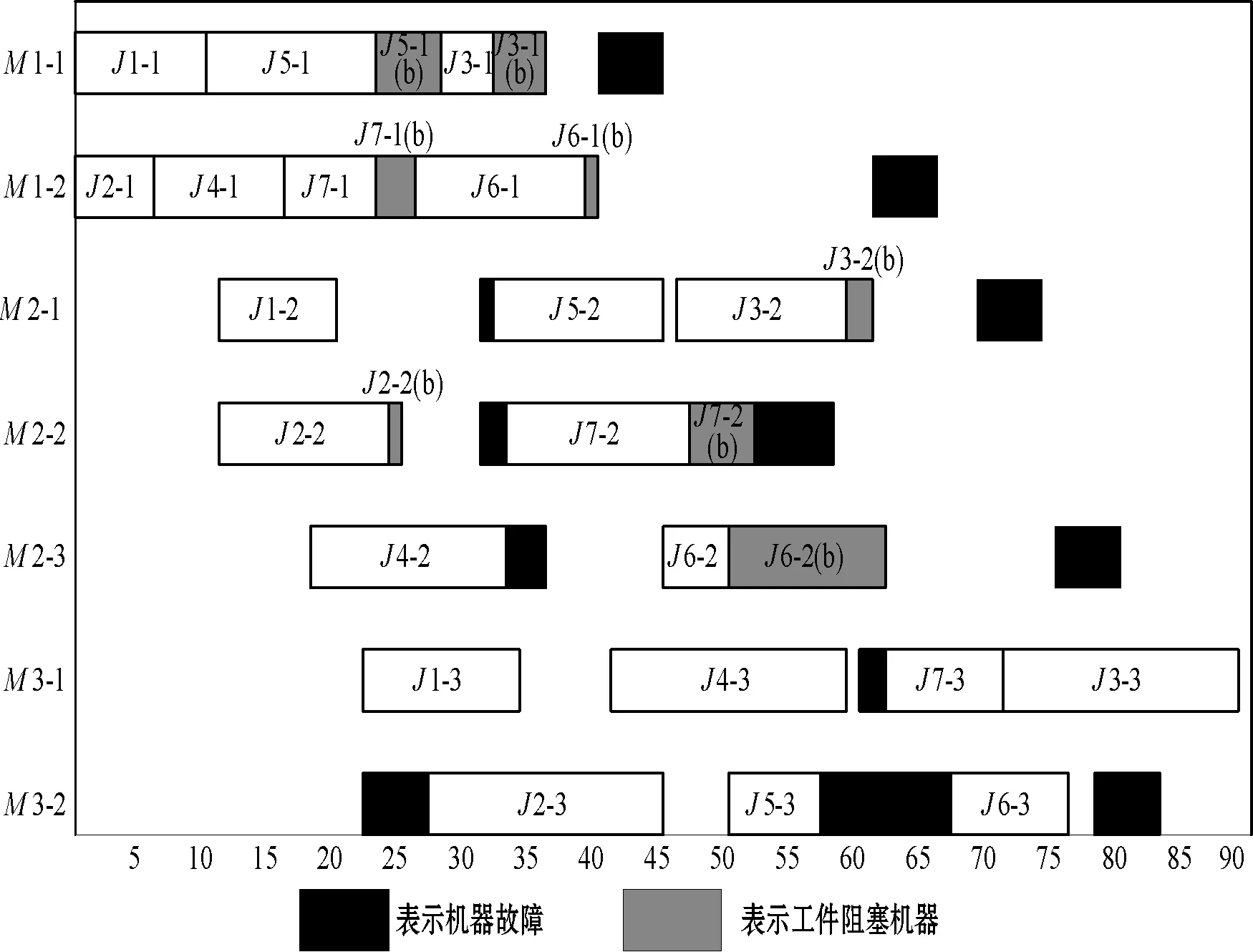
图3 算例甘特图
因此,最终的总加权完工时间为:

3.2 算法测试
为了验证算法的有效性,对HR-AHGA进行编译,并与传统GA进行比对,两种算法均在CPU为2.60 GHz,内存为4.00 GB的Lenovo G480微机的MATLAB R2014a上实现。种群规模PopSize设为80,最大迭代次数G设为160。通过对不同遗传参数设置的仿真测试,设置传统GA的交叉概率设为0.8,变异概率设为0.06。实验场景设置如表2所示。

表2 参数设置
算法性能通过改进率L和计算时间CPU衡量,其中目标值改进率L[9,12]和时间增加率R定义为:
L=(TWCGA-TWCHR-AHGA)/TWCHR-AHGA×100%
R=(CPUHR-AHGA-CPUGA)/CPUGA×100%
TWC表示由相应算法得到的目标值,CPU为计算机运行时间。
每种组合{n,s,Mp}随机产生9个实例,共测试6×2×2×9=216组实验。实验结果如表3所示,表中数据均为同一规模的9组实例的均值(除最后一行)。

表3 两种算法的结果比对
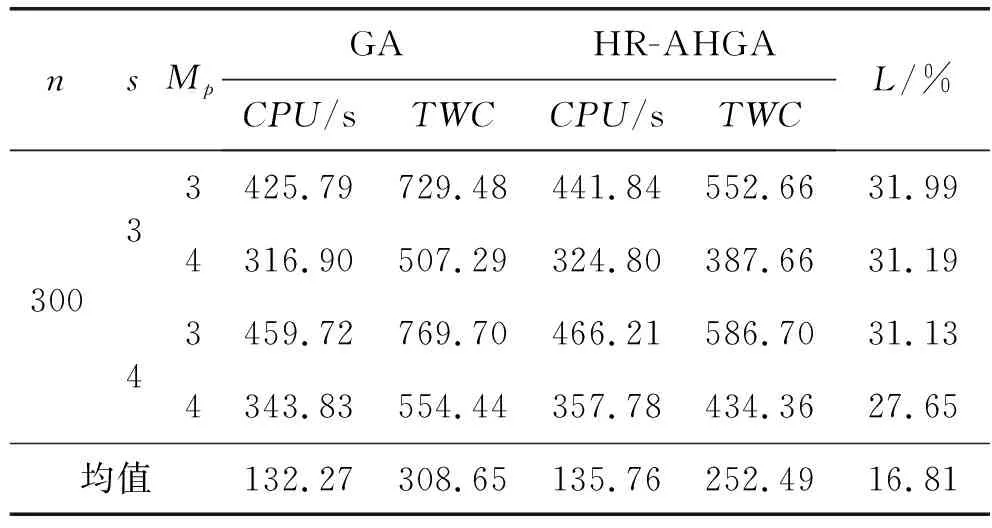
续表3
对于不同规模问题,GA和HR-AHGA在相同迭代次数内得到的平均目标值分别为308.65和252.49,与GA相比,HR-AHGA平均运行时间仅增加了1.96%,由HR-AHGA得到的平均目标值改进了16.81%。中小规模(n={30, 60, 90})和大规模(n={150, 200, 300})问题的平均改进率分别为7.55%和26.07%,这说明了HR-AHGA相对于GA,在求解大规模问题时改进效果更好。
表4表明了不同工件规模的平均改进率,工件规模为30时,平均改进率为1.85%,当工件规模达到300时,改进率达到30.49%;而平均增加运行时间仅从0.35%增加到2.93%。可以看出,随着工件规模增大,HR-AHGA相对于GA的改进率也逐渐增大。因此,整体来看,HR-AHGA在合理的计算时间内能够得到更好的近优解,在求解大规模问题时更显著。此外,本文测试问题规模为n={30,60,90,150,200,300},s={3,4},Mp={3,4},根据测试结果,采用HR-AHGA求解300个工件4个阶段的各实例中所需的最长运行时间为506.25 s ,能够在较短时间内求出近优解。根据表4,相比GA,引入LS后的HR-AHGA求解所有规模问题的平均时间增加率为1.96%,故该算法也可以求解其他甚至更大规模算例。

表4 不同规模问题的平均改进率
4 结 语
本文考虑了机器故障、无缓存区、运输时间等实际生产约束条件的混合流水车间调度问题,以最小化总加权完工时间为目标,建立了MIP模型,提出一种自适应混合遗传算法求解带运输时间的HFSP-MACB。设计了五种启发式规则改进初始种群,一定程度上弥补了不确定性规则搜索的不足;引入LS对GA产生的解的邻域空间进一步地搜索来寻优。对不同规模问题的仿真测试证明HR-AHGA的可行性和有效性,相比传统遗传算法求解效率更好,在求解大规模问题时,本文算法更具优越性,对于实际生产效率的提高有很大意义。
本文考虑中间无缓存区的混合流水车间问题,可将本文模型推广至有限缓存区调度问题。采用LS规则对GA解进行改进的策略,进一步研究可以采用其他启发式算法对GA改进或者将LS嵌入GA迭代过程中,或者采用其他超启发式算法进行求解,如粒子群算法、萤火虫算法等。
