基于数据挖掘技术的影视智能推荐算法
2021-06-18王小青蔡传根
王小青,苏 锋,蔡传根
(1.东北大学秦皇岛分校 管理学院,河北 秦皇岛 066004;2.安徽理工大学,安徽 淮南 232001)
0 引 言
近年来,随着移动通信技术和无线网络技术的发展,它们已经渗透到人们生活的各个领域,移动通信已经影响到了人们生活的各个方面[1]。在新媒体技术的影响下,人们将一些历史题材改编成了电视、电影,影视数据的数量大幅度增加,随着人们生活水平的不断提高,对精神生活要求越来越高,而影视推荐网站层出不穷,人们要在短时间内找到自己喜欢的影视作品十分困难,故出现了“影视过载”问题[2]。为了解决“影视过载”问题,出现了影视智能化推荐系统,而影视推荐算法是最为核心的内容[3⁃5]。
为了获得理想的影视智能推荐效果,本文提出了基于数据挖掘技术的影视智能推荐算法,并与其他方法进行影视推荐对比测试,结果表明,本文方法是一种精度高、速度快的影视智能推荐方法,相对其他方法,本文影视推荐方法具有十分明显的优越性。
1 影视智能推荐算法的相关研究
针对影视推荐问题,国内外学者进行了大量深入的研究,当前存在许多影视推荐系统[6]。一个影视推荐系统大致包括:用户使用影视的历史记录、影视推荐算法、影视推荐结果的服务决策信息,其中影视推荐算法是核心,也是最为关键的部分。当前推荐算法大致可以划分为4类:基于协同过滤的影视推荐算法、基于内容的影视推荐算法、基于关联规则的影视推荐算法、基于知识的影视推荐算法[7]。其中,协同过滤的影视推荐算法是最早的算法,可以细化为基于内存的影视推荐算法和基于模型的影视推荐算法,在实际中该类算法不关心用户历史行为记录,因此存在冷启动和稀疏性问题,同时,影视推荐时间长,无法进行在线影视推荐[8⁃10]。基于内容的影视推荐算法模拟信息检索和过滤的过程,根据用户的偏好和影视内容之间的匹配度进行影视推荐,该类算法的自学习能力差,无法发现潜在的用户;基于关联规则的影视推荐算法工作过程简单,影视推荐实时性强,但是存在冷启动和稀疏性问题,同时一旦规则太多,那么影视推荐效率就比较低;基于知识的影视推荐算法是针对特定领域的影视制定推荐算法,因此通用性比较差[11⁃13]。
综合当前影视推荐算法的研究现状可以发现,每一种影视推荐算法或多或少存在一定的不足和局限性,因此影视推荐算法研究面临巨大的挑战[13⁃16]。
2 基于数据挖掘技术的影视智能推荐算法
2.1 影视数据的采集与保存
随着计算机网络的不断发展,许多公司将一些影视数据发送到网络上,使得影视数据急剧增加,当前影视数据呈现大规模、海量特征,采用传统单机平台进行影视推荐效率极低。本文首先采集大量的影视数据,然后对影视数据进行预处理,并将预处理的影视数据保存在云平台的分布式文件系统中。
分布式文件系统具有速度快、处理能力强等优点,可以存储海量的影视数据。一个分布式文件系统包括一个NameNode和多个DataNode,其中NameNode是主服务器,它可以接收用户请求,并对文件进行管理,而DataNode是多个计算机,主要用来存储数据,分布式文件系统的基本结构具体如图1所示。
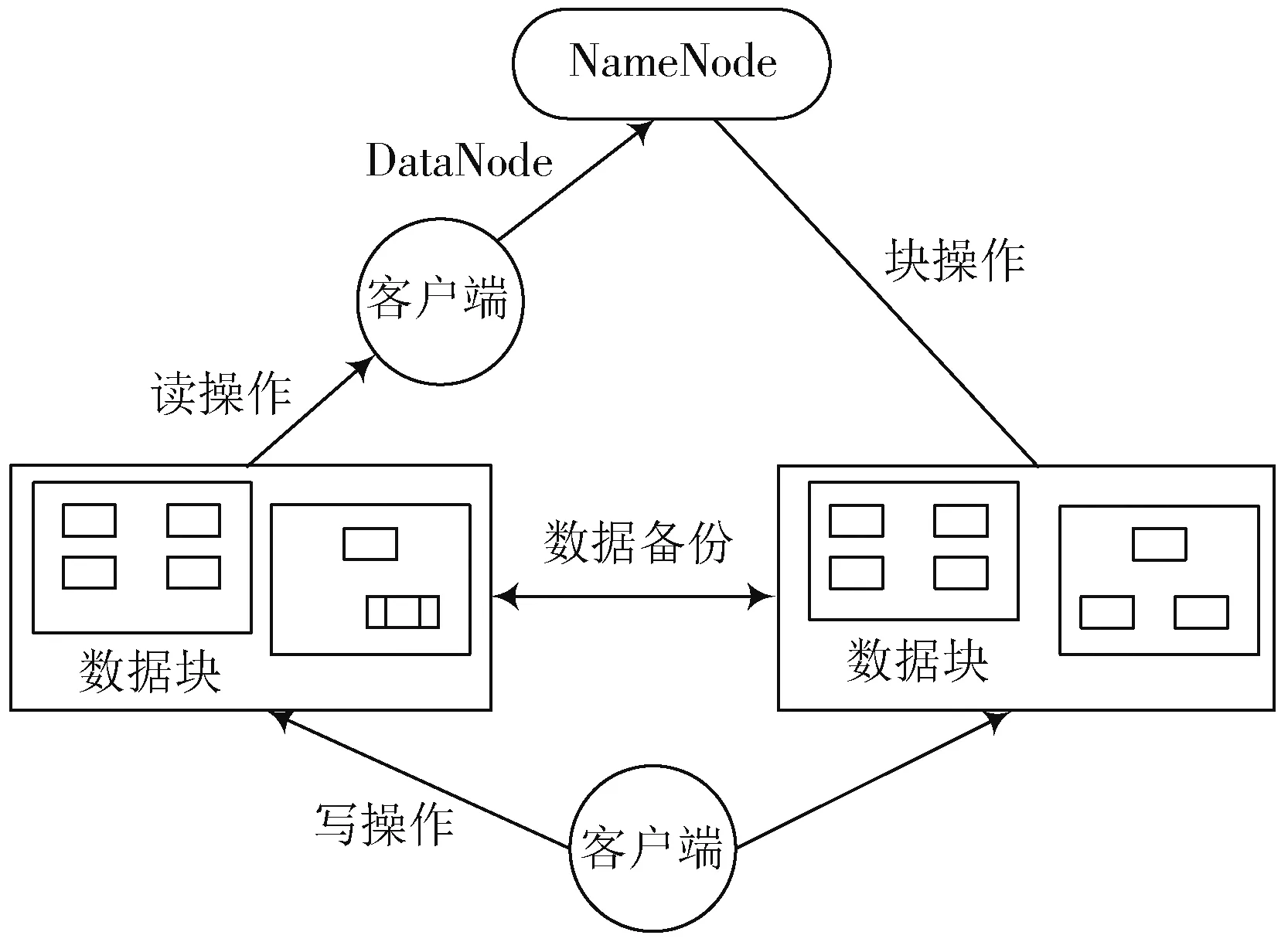
图1 分布式文件系统的基本结构
2.2 影视数据的预处理
由于影视数据保存在分布式文件系统中,因此需要生成用户对影视的评分数据。用户对影视的评分数据由三部分组成:用户编号(U_ID)、影视编号(M_ID)、用户对影视的评分(Score),本文采用云计算技术中的Map/Reduce实现,生成用户向量和影视向量,其中用户向量是一个用户对所有影视的评分,影视向量是所有用户对一个影视的评分。
2.2.1 用户向量生成步骤
Step1:从分布式文件系统中读取影视数据,并计算用户的影视评分。
Step2:通过Map将用户对影视的评分分为两部分:U_ID和M_ID、Score,其中,U_ID作为Map的key,M_ID、Score作为Map的value,它们组成
Step3:根据key进行排序,将key相同的用户的影视评分放在一起。
Step4:Reduce对相同用户的影视评分数据进行整合,得到一个用户对所有电影评分的集合。
Step5:构建用户⁃影视评分矩阵,并计算它们的平均值,从而产生用户评分向量。
具体步骤如图2所示。

图2 用户向量生成的过程
2.2.2 影视向量的生成步骤
Step1:将用户评分向量作为Map的输入,对用户评分向量进行分解,将M_ID作为key,将U_ID、Score作为Map的value,形成
Step2:根据key进行排序,将key相同的用户数据放在一起。
Step3:Reduce对用户数据进行整合,将得到的key作为M_ID,vU_ID、Score作为value,即为所有对影视评过分的用户集合。
Step4:将生成的数据保存在分布式文件系统中。具体如图3所示。
2.3 用户⁃影视评分的构建
用户对影视的评分主要通过兴趣程度描述,假设有m个用户,对n部影视进行评价和打分,第i个用户对第j部影视的评分分值为r ij,本文采用Movielens的5分制作为评分标准,分值越高表示用户对该部影视越感兴趣,那么用户⁃影视评分矩阵可以表示为:
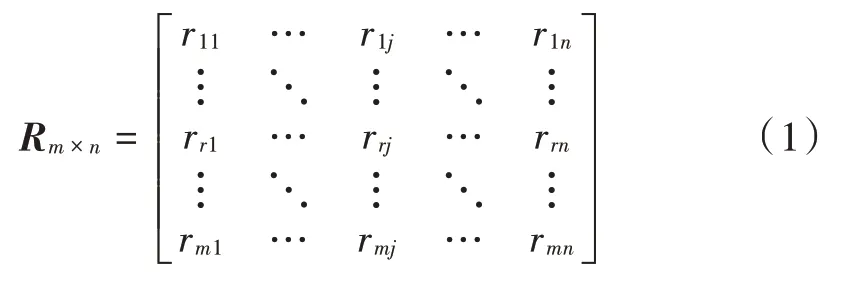
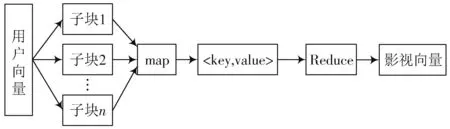
图3 影视向量生成过程
2.4 相似度计算
对于用户⁃影视评分矩阵,根据用户向量之间的距离估计用户之间的相似度,用户向量之间的距离越近,表示用户的相似度越高,当前相似度的计算方式主要有:
1)基于欧氏距离的相似度
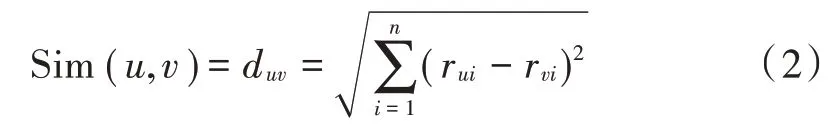
2)基于余弦的相似度

3)基于皮尔逊相关系数的相似度
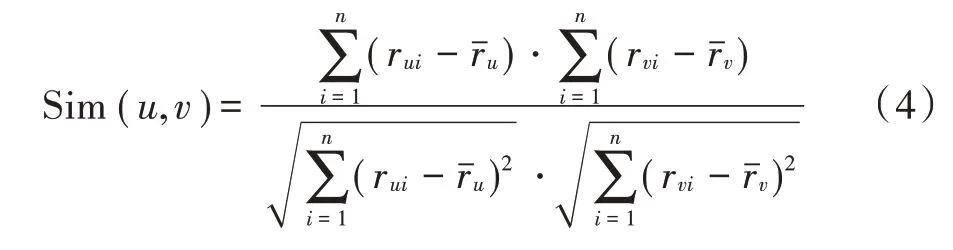
本文采用皮尔逊相关系数计算用户相似度。
2.5 最近邻算法查找到前k个最近邻“邻居”
对于给定的训练样本集,最近邻算法根据样本之间的距离找到最近的k个邻居样本,将k个邻居频率最高类别作为待识别类别。本文采用皮尔逊相关系数计算用户的相似度,然后根据相似度值进行排序,选择前k个最近邻“邻居”生成目标用户的最近邻用户集合。
2.6 计算预测评分并产生推荐
计算用户预测评分,并根据用户预测评分产生影视推荐结果,采用中心加权平均值的方法计算用户u对未评分影视i的预测评分,具体如下:
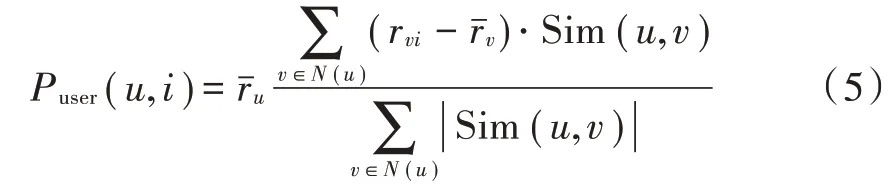
3 影视智能推荐算法的性能测试与分析
3.1 影视智能推荐实验数据集
为了测试基于数据挖掘技术的影视智能推荐算法的性能,采用影视推荐经典数据集——Movielens数据集作为测试对象,从中选择Movielens⁃100k进行具体仿真实验,选择80%的数据作为训练样本集合,20%的数据作为测试样本集合,Movielens的三组不同规模的数据集具体如表1所示。
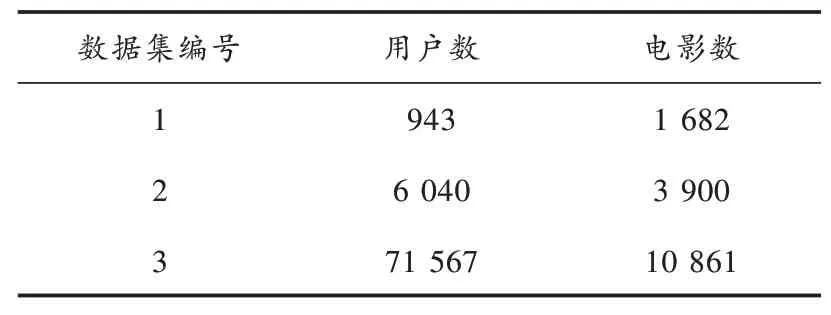
表1 影视智能推荐的数据集
3.2 影视智能推荐实验环境
影视智能推荐实验平台包括5个节点、1台服务器、4台普通计算机,具体配置如表2所示,采用Java语言实现影视智能推荐算法。在相同条件下,选择文献[12⁃13]的影视智能推荐算法进行对比实验,选择影视智能推荐精度和时间作为实验结果的评价指标。
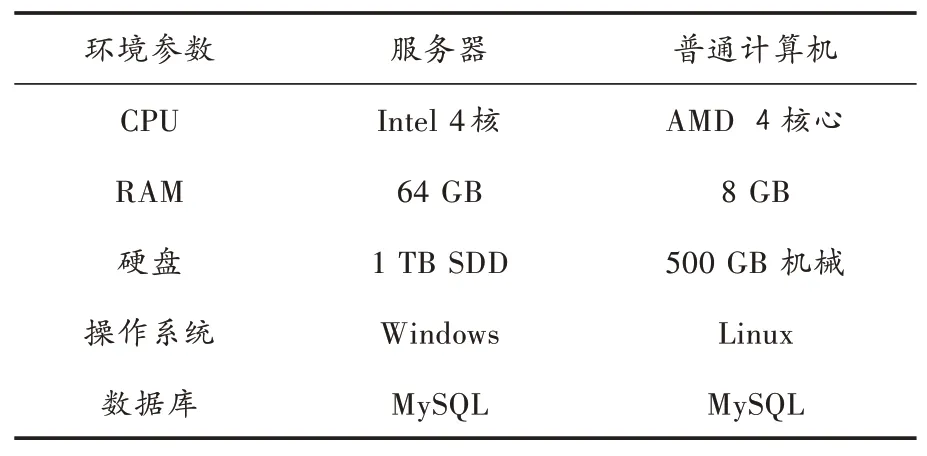
表2 影视智能推荐的实验环境
3.3 影视智能推荐精度对比
采用三种方法对训练样本集合进行学习,建立影视智能推荐模型,然后对测试样本集合进行分析,统计每一种方法对每一个数据集的推荐精度,结果如图4所示。从图4可以看出,相对于文献[12⁃13]的影视智能推荐算法,本文算法的影视智能推荐精度大幅度提升,减少了影视智能推荐误差。
3.4 影视智能推荐效率对比
采用单机平台的影视智能推荐算法进行对比实验,统计两种方法的影视智能推荐时间,结果如图5所示。从图5可以发现,相对于单机平台,本文算法的影视智能推荐时间明显减少,这是因为本文引入了大数据分析的云计算平台,提高了影视智能推荐效率。
3.5 影视智能推荐算法的通用性测试
为了测试影视智能推荐算法的通用性,通过移动网络采集大量的影视数据,将它们划分为100类,统计本文算法对100类影视的推荐精度,结果如图6所示。从图6可以看出,本文算法的平均影视智能推荐精度超过了95%,获得了令人满意的推荐结果,能够适应移动环境下的影视推荐应用要求。
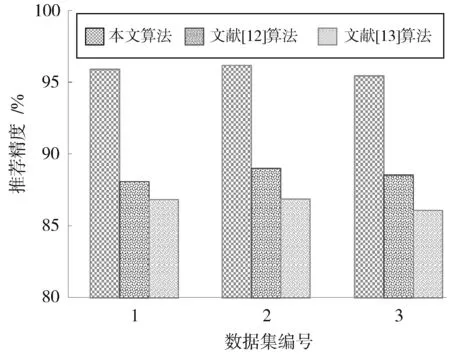
图4 不同方法的影视智能推荐精度对比
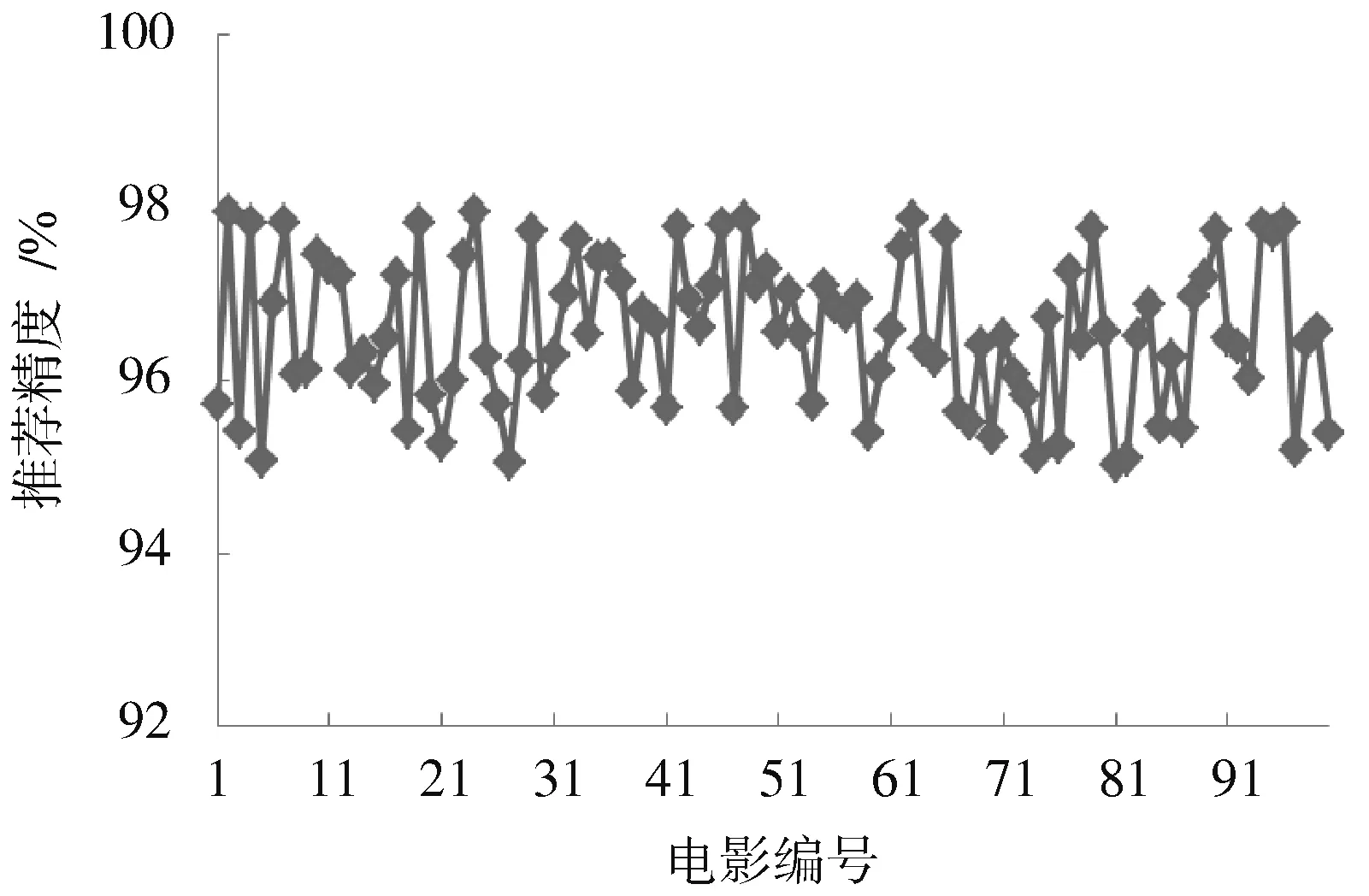
图6 本文算法对不同类型的影视智能推荐精度
4 结 语
影视智能推荐是当前人工智能技术中的研究热点,针对传统影视智能推荐算法存在的弊端,为了提高影视智能推荐的精度,本文提出基于数据挖掘技术的影视智能推荐算法。采用多个影视数据集合进行仿真测试,结果表明,相对于其他影视智能推荐算法,本文方法获得了较高精度的影视智能推荐结果,影视智能推荐效率得以改善,具有十分广泛的应用前景。
