基于改进模糊C均值的能量均衡LEACH算法
2021-06-18王宗山保利勇李艾珊丁洪伟
王宗山,李 波,保利勇,李艾珊,丁洪伟
(1.云南大学 信息学院,云南 昆明 650504;2.复旦大学 电子工程系,上海 200433)
0 引 言
无线传感器网络(Wireless Sensor Network,WSN)是由很多廉价的微型传感器节点以无线通信方式组成的多跳自组织网络,主要用于监测指定区域并获取数据,但节点能量有限且无法更换电池[1⁃3]。针对上述问题,国内外提出了多种路由算法。文献[4]最早提出了经典的分簇路由LEACH算法,显著提升了网络性能,但LEACH随机选取簇首导致网络分簇不均匀,加大了网络能耗。文献[5]对LEACH算法进行改进,提出LEACH⁃C。LEACH⁃C在选择簇首节点时,考虑节点剩余能量,使簇首选举更加合理,但没有考虑簇首的位置且过于依赖基站。文献[6]提出一种基于Fuzzy C⁃Means聚类的改进LEACH算法(NEW LEACH),首先利用Fuzzy C⁃Means进行分簇,在每个簇内考虑剩余能量的LEACH算法选举簇首,但没有考虑簇首到基站的距离。文献[7⁃10]通过改进阈值、引入分区或动态分簇等方式对LEACH算法进行改进。
本文在研究LEACH、NEW LEACH的基础上,提出一种基于遗传算法和模糊C均值聚类的改进LEACH算法(GFCR⁃LEACH)。仿真结果表明,相比于LEACH和NEW LEACH,GFCR⁃LEACH成簇效果理想,显著延长了网络生命周期,提高了网络吞吐量。
1 LEACH协议概述
1.1 LEACH协议简介
LEACH协议是一种经典分簇路由协议,网络按轮进行,周期性轮换簇首,每轮分为簇的构建和数据传输两个阶段。
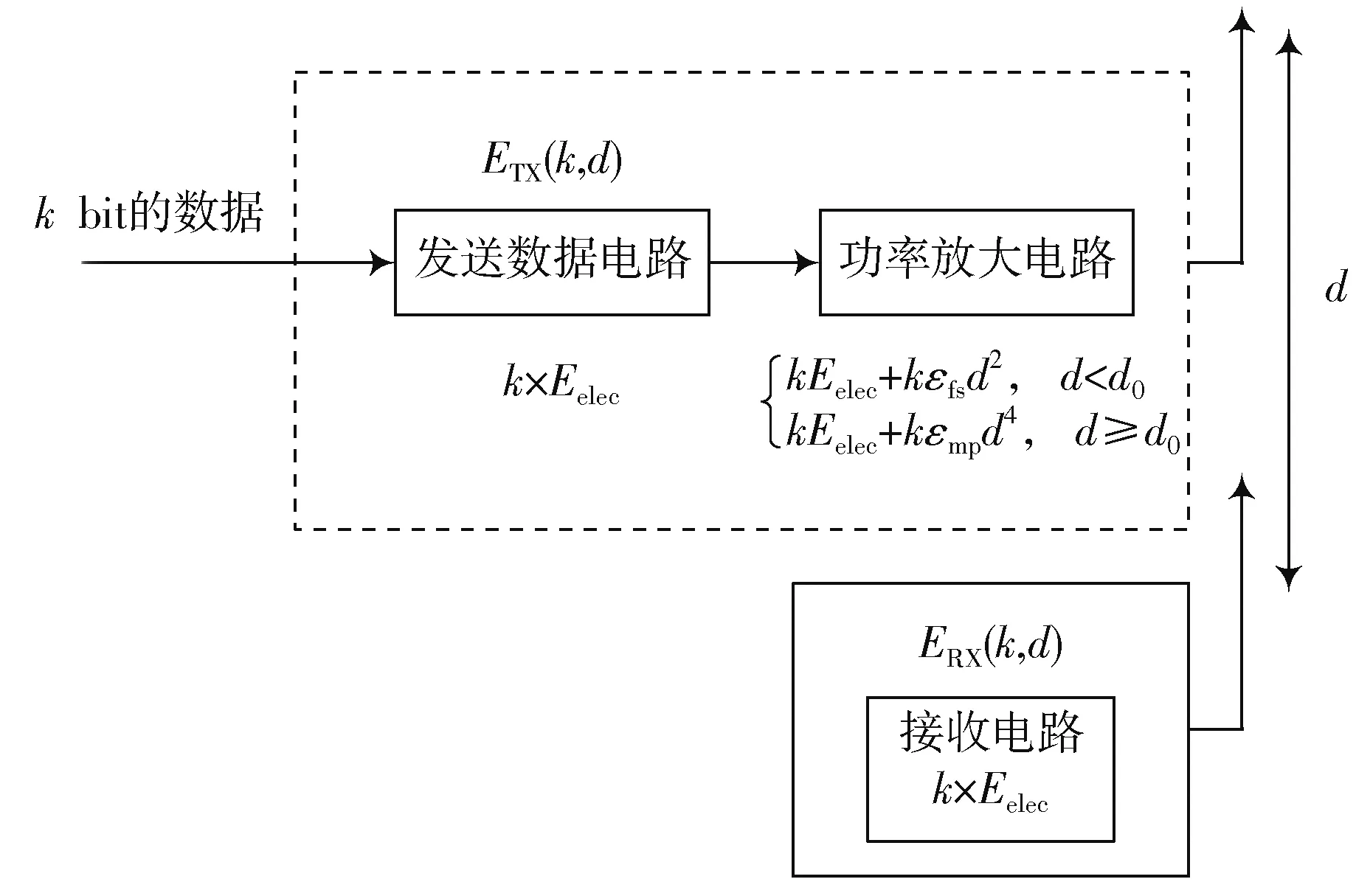
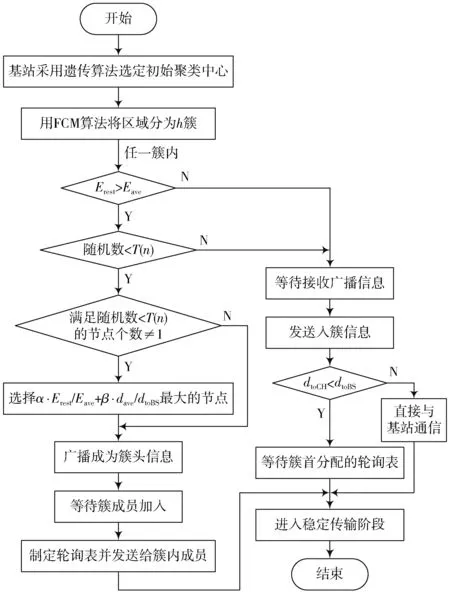
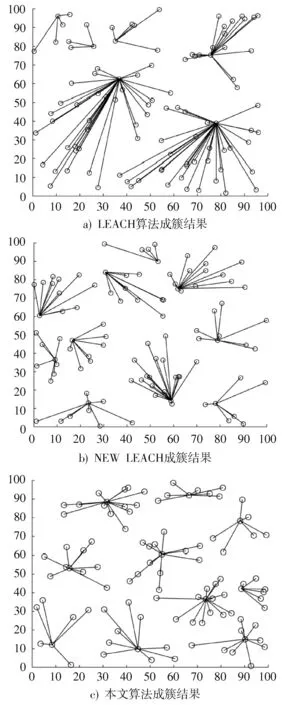
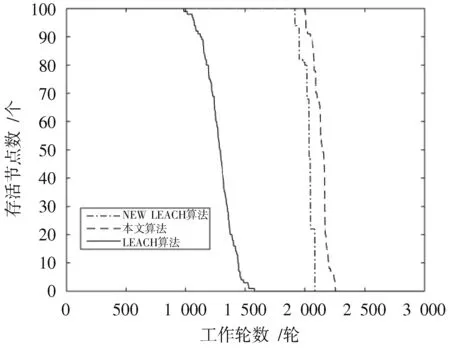
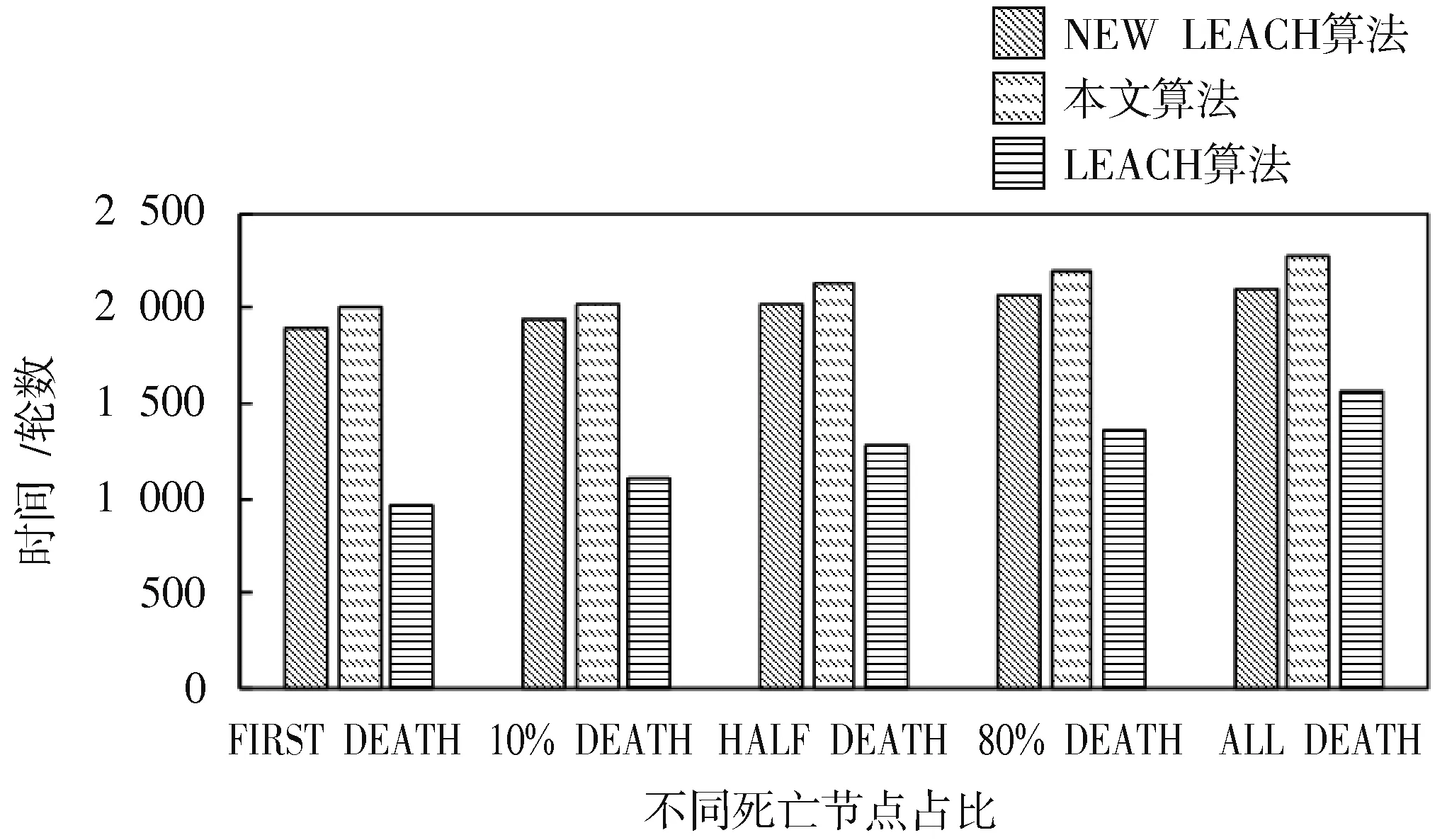
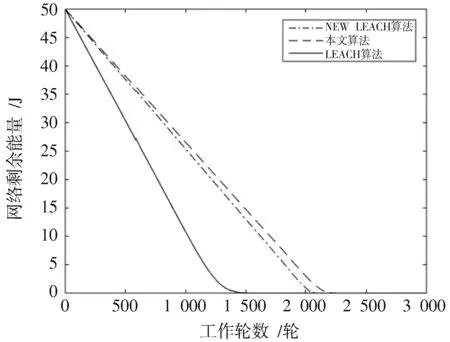
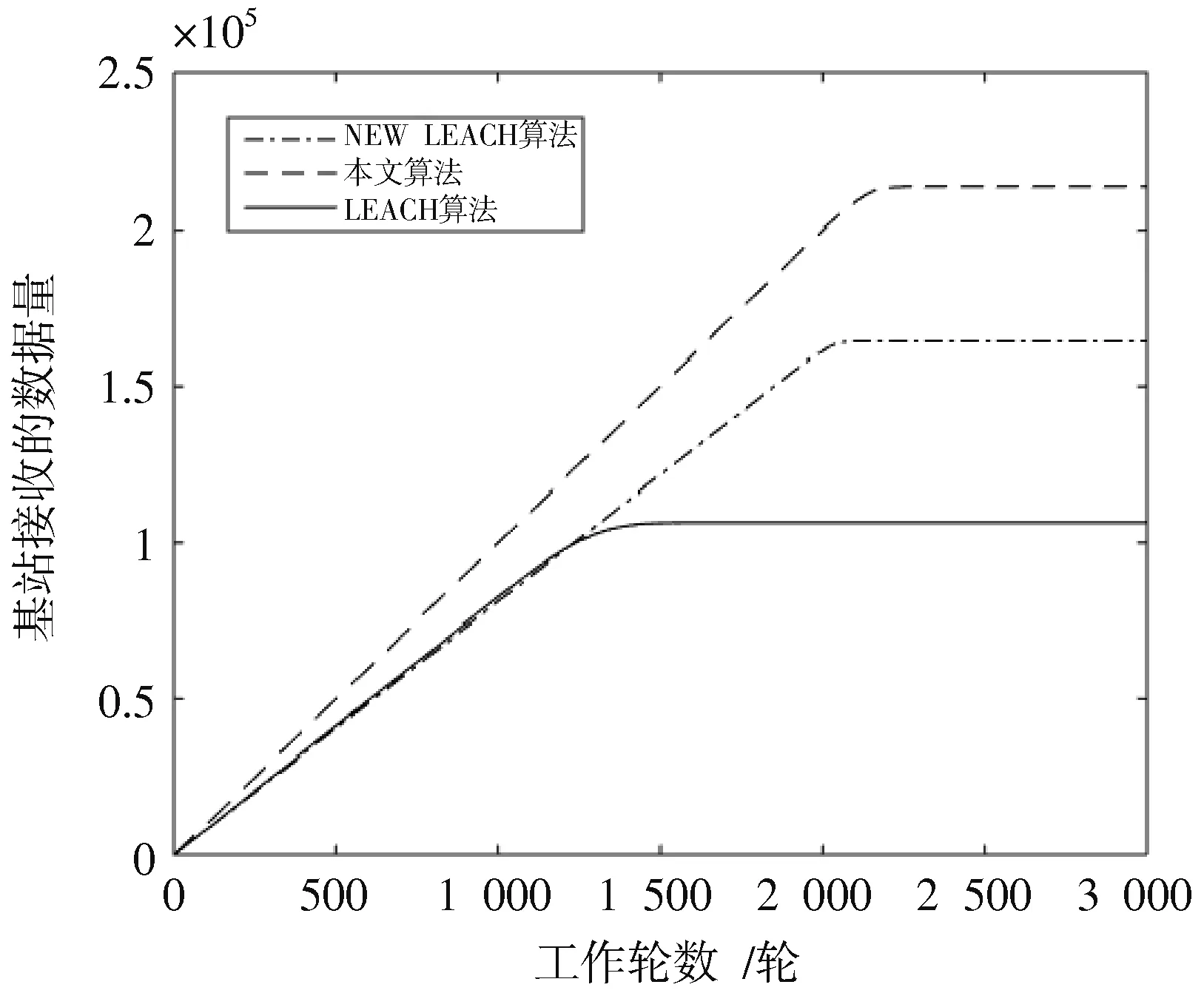
簇构建阶段:每个节点生成一个0~1之间的随机数μ并和阈值T(n)作比较。若满足μ 式中:p是成为簇首的理想概率;r是当前轮数;G是1p轮内未当选过簇首的节点集。 数据传输阶段:簇首创建TDMA时隙表,簇内成员在自己的时隙与簇首通信。簇首将接收到的数据融合之后单跳发至基站。至此,本轮结束。 LEACH算法中,数据传输的流程与能耗过程如图1所示[11]。 图1 数据传输过程与能耗模型 节点发送数据的能量消耗主要考虑发射电路能量消耗和节点功率放大器能量消耗。节点经距离d发送kbit数据包的能耗为[12]: 接收端消耗的能量为: 式中:Eelec表示发送单位比特电路消耗的能量;d0是一个距离常量,当传输距离d大于阈值d0时,采用多路径衰减模型,否则,采用自由空间信道模型[13];εmp和εfs分别表示两种信道模型下功率放大所需能量。 LEACH算法随机选举簇首使分簇不均匀,加大了网络能耗。本文提出一种改进的LEACH算法。网络初始化阶段,基站根据节点坐标,采用遗传算法优化的模糊C均值算法将网络分割成h个区域,在每个区域内,利用优化的LEACH协议完成簇首的选举和数据的传输。 为研究GFCR⁃LEACH对网络的影响,对网络节点和网络模型作出如下假设: 1)M×M的监测区域内随机不均匀散布N个传感器节点; 2)传感器节点的初始能量相同且位置固定,部署完成之后再无人为干涉; 3)任意节点的处理能力和通信能力相等,均可感知自身剩余能量; 4)节点都能够与基站通信,可以融合数据,具备担任簇首的能力; 5)节点拥有唯一的网络ID。 2.2.1 最优簇数 模糊C均值算法对网络节点进行分类时需指定分类数。基于上述网络模型和一阶无线电能耗模型,网络运行一轮的能耗为[14]:式中:DtoBS为节点到基站的距离;EDA为簇首融合1 bit冗余信息的能耗。 对分类数h求偏导,满足偏导数为零时的h,即为当前网络状态下的最优簇数。求得的最优簇数为: 2.2.2 模糊C均值聚类算法 模糊C均值聚类算法[15](FCM)通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的类属。假设样本集合为X={x1,x2,…,x N},将其分为h个模糊组,FCM聚类损失函数为: 式中:x i是第i个样本点;m是模糊因子;h j是第j簇的中心;u ij表示样本i对聚类中心j的隶属度。u ij和h j分别满足下式: 迭代的终止条件为: 式中:k是迭代步数;ε是误差阈值。 2.2.3 遗传算法优化FCM初始聚类中心 FCM的性能依赖于初始聚类中心,容易得到局部最优值。因此,本文利用遗传算法确定初始聚类中心。遗传算法[16]是模拟自然界遗传机制和生物进化论而形成的一种过程搜索最优解算法。遗传算法优化FCM的步骤为[17⁃19]: 1)初始化参数:确定种群规模、交叉概率、变异概率,设置终止进化准则和聚类个数h;采用二进制编码,染色体χ={χ1…χi…χ2h}中的每两个等位基因代表一个聚类中心的坐标。 2)随机产生初始种群,设置进化代数计数器t=0。 3)评价个体适应度并记录。其中,适应度函数为f=1J m。 4)种群进化(选择、交叉、变异)。依据适应度选择新一代种群P(t+1),并判断是否满足终止进化准则。 5)若满足终止进化准则,终止计算并输出聚类结果;否则,t=t+1,转至步骤3),继续迭代。 2.3.1 候选节点 簇首选举阶段,节点i将自身剩余能量Erest(i)和所在第j簇的平均剩余能量Eave(j)按下式比较: 若式(11)成立,则节点i成为本轮候选节点,否则,置为普通节点。每个候选节点生成一个0~1之间的随机数μ,与改进后的阈值T(n)作比较。如果满足μ 2.3.2 改进阈值公式 本文考虑节点的剩余能量、与基站之间的距离,对LEACH算法的阈值公式进行改进,改进后的阈值公式为: 式中:p表示每个区域内的簇首节点比例;Erest表示当前节点的剩余能量;Eave表示当前节点所在簇的平均剩余能量;dtoBS表示当前节点到基站的距离;dave表示当前节点所在簇内所有节点到基站的平均距离;α和β是调节因子,满足α+β=1。 根据式(12)可知,节点的剩余能量越少、距离基站越远,该节点得到的阈值T(n)就越小,要成为簇首节点,需要生成相对较小的随机值。相反,节点的剩余能量越多、距离基站越近,该节点得到的阈值T(n)就越大。在相同的随机数生成机制下,该节点有更大概率当选簇首。这样就保证了剩余能量多、距离基站近的节点有更大概率当选为当前轮次的簇首节点。 改进后的阈值公式特点如下: 1)簇首比例:每簇只选一个簇首,故p等于每个簇内节点个数的倒数。随着网络的运行,簇内节点不断死亡,p值动态增大,阈值公式相应改变,以适应当前网络状态。 2)调节因子:α和β的取值影响整个网络的性能。网络初期,节点的剩余能量普遍较高,任意两个节点之间的能量相差不多,簇首选举时,节点的剩余能量及到基站的距离两个因素重要程度基本相当,将α置为0.6,β置为0.4。随着网络的运行,节点的剩余能量参差不齐,能量因素所占比重增大。因此,在超过半数节点死亡时,将α置为0.8,β置为0.2。对多组取值进行仿真实验对比,当前取值效果良好。 3)改善有资格竞选簇首的节点集:不同于LEACH,本文算法在簇首选举时,并不考虑节点在最近的1p轮中是否担任过簇首。担任过簇首的节点,只要满足上述簇首选举的条件,便可再次当选。因为有些节点虽担任过簇首,但剩余能量较多,距离基站较近,相比于其他节点,更适合当选为当前轮次的簇首。 2.3.3 特殊情况 每轮每簇只选一个簇首,因此,簇首选举时会有两种特殊情况: 1)簇内任意候选节点生成的随机值均大于阈值,即没有节点能够担任当前轮次的簇首; 2)簇内多个候选节点生成的随机值均小于阈值,即多个候选节点均可担任当前轮次的簇首。 上述两种特殊情况下,选择α⋅ErestEave+β⋅davedtoBS最大的节点担任簇首。其中,α和β根据存活节点个数取相应的值。这样保证了剩余能量大且距离基站近的节点有更大概率当选为当前轮次的簇首。 2.3.4 选择通信对象 每轮簇首更新之后,簇首节点根据终端节点的坐标计算其到基站的距离dtoBS和到自身的距离dtoCH,并按下式进行比较: 若式(13)成立,代表节点i到基站的距离小于到簇首的距离,簇首将节点i从时隙表中删除。在当前轮次,节点i直接与基站通信,否则,仍与簇首通信。这样显著减少了数据传输带来的能耗。 LEACH算法的簇内通信采用TDMA机制[7]。成簇之后,簇首建立TDMA方案,节点在自己的工作时间内履行信息采集等工作,其余时间处于休眠状态。这样就会出现空闲时隙,造成能量浪费。为解决这一问题,本文算法的簇内通信介质访问控制(Medium Access Control,MAC)机制采用轮询控制机制[20⁃21]。成簇之后,簇首根据节点的反馈信息生成轮询表,轮询顺序和节点ID相对应。当簇内节点处于休眠状态、能量耗尽或直接和基站通信时,簇首将其从轮询表中删除,后面节点的轮询顺序依次提前。这样不但可以充分利用时隙,又可以避免节点发送数据包时产生的碰撞,从而减少网络能耗,提高网络吞吐量。一个轮询周期结束后,簇首对收集到的数据进行去冗处理,采用CSMA机制单跳发至基站。 改进的LEACH算法流程如图2所示。 本文在Matlab R2014b上对LEACH、NEW LEACH和本文算法进行仿真,初始参数见表1。遗传算法参数设置为[22]:种群大小为50,交叉概率pc=0.25,变异概率pm=0.05,最大迭代次数T=110,FCM的终止阈值ε=10-6。 1)成簇均匀性 LEACH、NEW LEACH、本文算法的成簇结果如图3所示。传统LEACH算法随机选取簇首,导致成簇不均匀,分簇数量不合理。NEW LEACH采用FCM聚类算法形成网络分簇,簇首分布均匀,分簇数量合理,但FCM算法的性能受初始聚类中心的影响,易收敛到局部最优,导致簇的大小不均匀。本文算法引入遗传算法,有效地解决了这一问题,使成簇更加理想。 图2 改进的LEACH算法流程图 表1 仿真参数 图3 成簇结果对比 2)网络生命周期对比 与LEACH、NEW LEACH相比,本文算法均衡了网络能耗,显著延长了网络生命周期。三种算法的生命周期对比如图4所示,节点死亡时间对比如图5所示。 图4 生命周期对比 图5 节点死亡时间对比 3)网络能耗对比 与LEACH、NEW LEACH相比,本文算法有效降低了网络能耗,使网络剩余能量始终多于另外两种算法。三种算法的网络剩余能量对比如图6所示。 图6 网络剩余能量对比 4)网络吞吐量对比 LEACH、NEW LEACH、本文算法的吞吐量对比如图7所示。由于本文算法生存期长,簇内通信阶段引入轮询机制,使得吞吐量自始至终高于其他两种算法。 图7 吞吐量对比 针对LEACH算法和NEW LEACH算法分簇不均匀、能耗不均衡等问题,提出一种改进的LEACH算法。通过更加均匀的分簇,引入候选节点,优化阈值公式,选择最佳通信对象,改进通信机制等方式,在均衡网络能耗的同时延长了网络的生命周期,提升了网络的吞吐量,使本文协议在相同条件下可以获取更多的监测区域信息。因此,本文算法在传感器节点和基站位置固定的监测环境下,有更好的监测效果。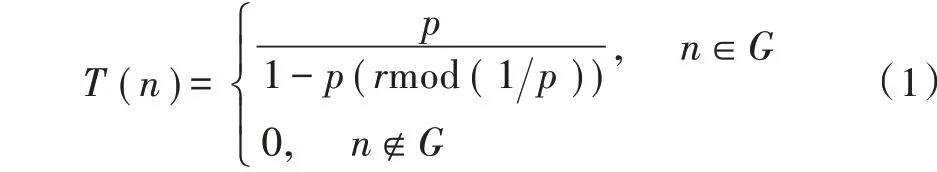
1.2 能耗模型
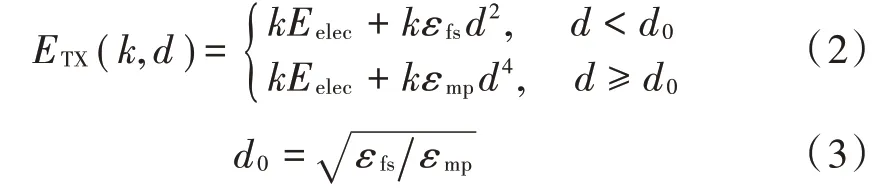

2 GFCR⁃LEACH协议
2.1 网络模型
2.2 区域分割
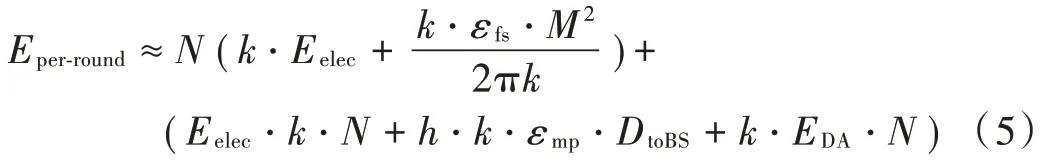
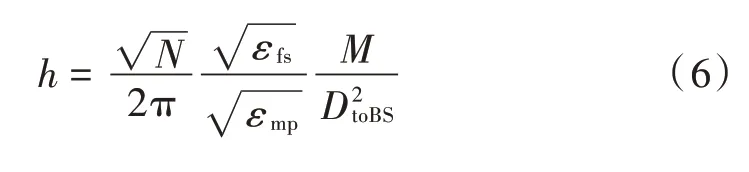
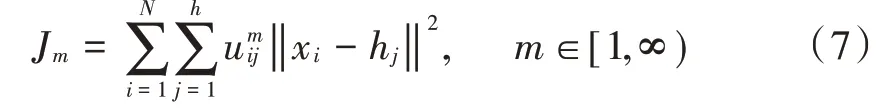
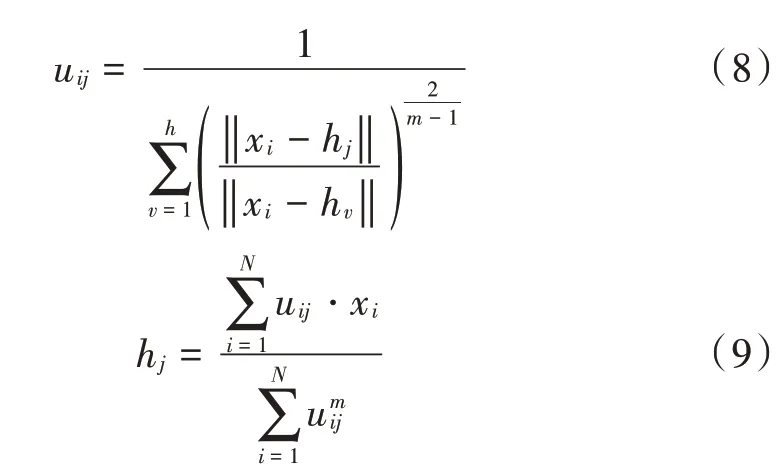
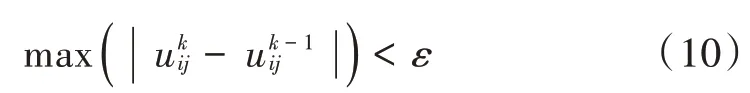
2.3 簇首选择

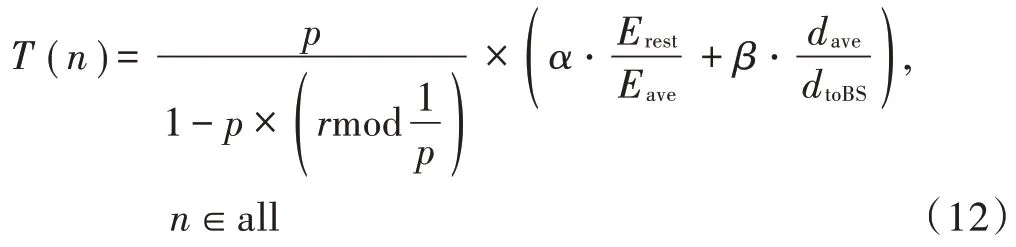
2.4 数据传输
3 仿真实验及性能分析
3.1 仿真参数设计
3.2 实验结果及分析

4 结 语
