基于计算语言方法的95598工单分类优化分析
2021-06-17杨柳林吴柯蓉李宇李娟娟
杨柳林,吴柯蓉,李宇,李娟娟
(1.广西大学电气工程学院,广西南宁,530004;2.广西电网公司客户服务中心,广西南宁,530004)
1 95598工单分类优化模型
■1.1 工单标签构建
将以投诉类为例将工单分类标签形式进行统一,都采用“业务子类”综合描述方式,从而得到32个唯一分类标识,如表1所示。
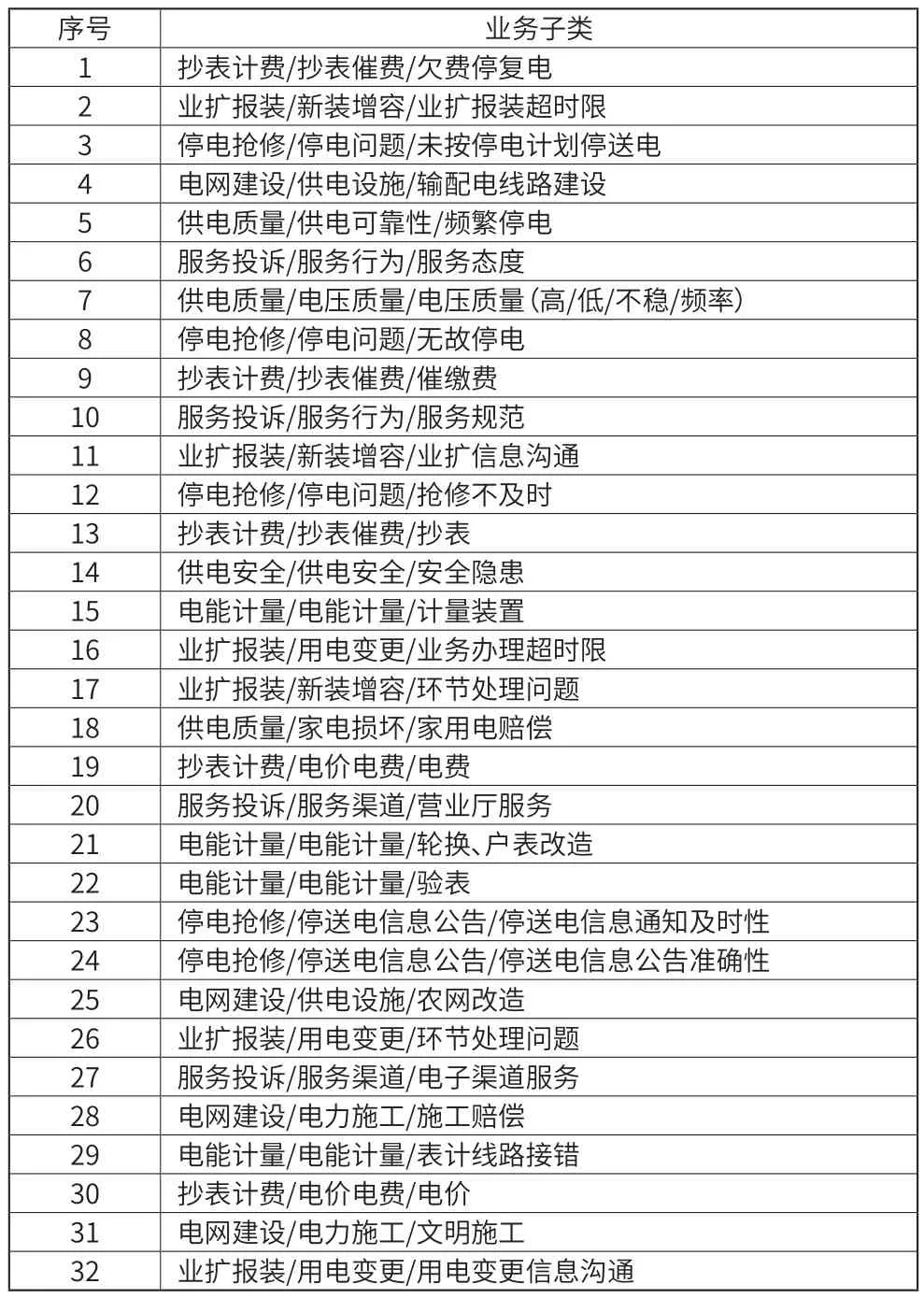
表1 投诉工单的分类研究
■1.2 中文分词
构建模型前要对文本内容即来电内容进行数据分词处理,对电力客户投诉工单的“来电内容”进行深度挖掘,将工单中的受理文本信息和处理文本信息切割成单个词汇,将文本转化为了数学语言[1]。 斯坦福中文分词工具[2]是由斯坦福大学自然语言处理组所提供,他们也提供了一系列开放源码的Java文本分析工具。
■1.3 特征词提取
构建词库后需要构建特征矩阵,常见的文本特征提取方法就是TF-IDF[3](term frequency-inverse document frequency)。TF-IDF是一种基于统计的计算方法,常用来评估在一个文档中一个词对某份文档的重要程度[4]。在一份给定的文件里,词频(term frequency,TF)表示指定的词汇ti在文件中出现的次数,计算公式为:

其中,ni,j为在文件中指定词出现的次数。
IDF(inverse document frequency)是逆向文件频率,计算公式为:
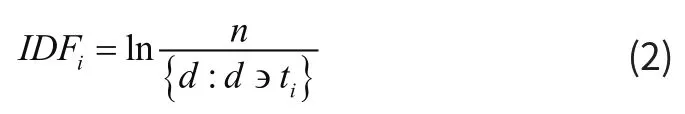
其中,n为文件总数。
{d:d∋ti}为含有词汇ti的文件总数。
对词汇的重要性进行权重计算,计算公式为:

IDFi通常被归一化以避免它偏向长的文件,则权重计算公式为:
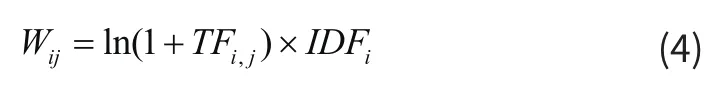
■1.4 聚类算法
这里用来构建工单分类优化模型的聚类算法为无监督聚类算法K-means算法[5]。
能把文本相似程度转变为文本之间的距离的常见的方法有三种,即距离函数法、余弦法与内积法[6]。采用夹角余弦相似度的计算模型,余弦相似度利用夹角的余弦值即方向来刻画相似度,更注重维度间相对层面的差异[7]。首先通过文本的向量表示,将文本转化成为向量集合X= {x1,x2,…xn}。对于欧氏空间中的任意两个向量x= {x1,x2,…xn}和y={y1,y2,…yn},它们的余弦相似度(Cosine)定义为两个向量夹角的余弦:
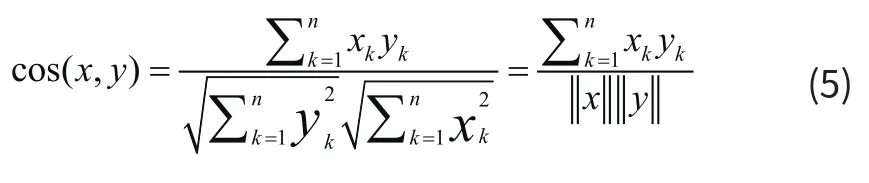
采用K-means算法计算出不同投诉类型间的距离。其中,距离=1-cosine(相似度),从而由该距离值来判断投诉工单分类的相似度,由此模型进行95598工单分类优化分析。工单分类优化分析流程如图1所示。
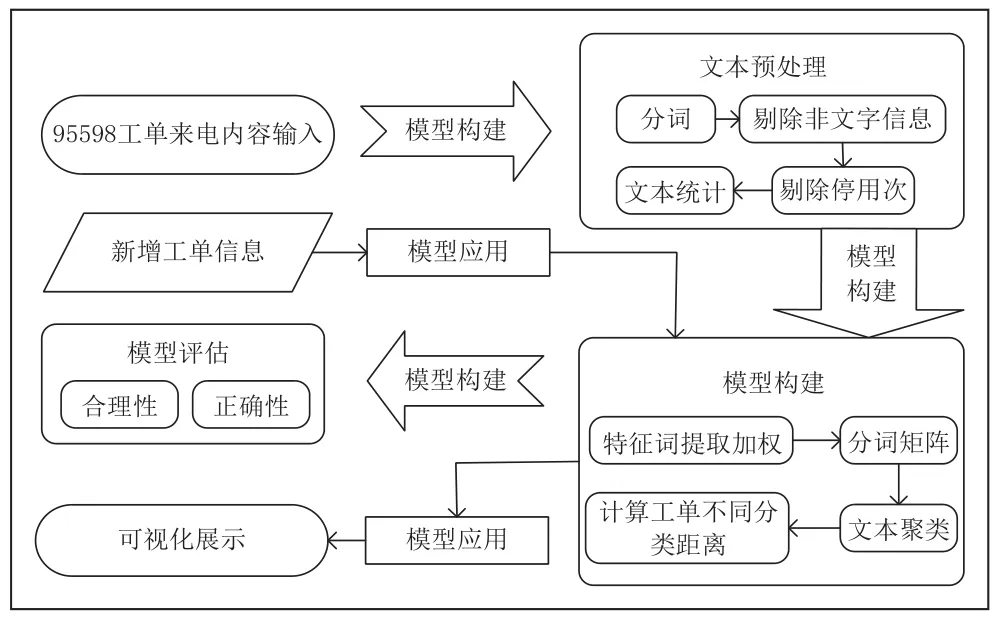
图1 工单分类优化分析流程
2 实例分析
■2.1 分词处理
本实例以95598投诉工单数据为对象进行研究分析,采用斯坦福中文分词工具,对投诉工单的“来电内容”进行分词处理。
部分原始工单如表2所示。

表2 原始工单(部分)
将其分词,分词完成后,去除数字、标点、英文字符、特殊符号,针对剩余的词库,再移除停用词,共得到3510个有效词语。部分结果如表3所示。

表3 分词结果(部分)
完成各工单的“来电内容”分词后整合成一个文本。在python中利用TF-IDF构建分词矩阵。分词矩阵的行为特征词,列为所有工单样本,部分分词矩阵如图2所示。
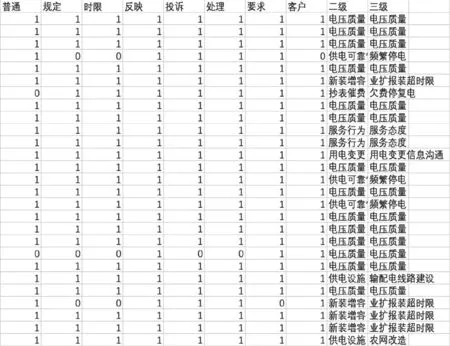
图2 分词矩阵(部分)
如图2所示,特征词对应为“1”代表所属分类那条工单中有该特征词。“0”即没有。
■2.2 投诉类型相似度分析
形成分词矩阵后将同一投诉类型的所有来电内容整合成一个文本,然后利用不同投诉类型的TF-IDF特征值在python中调用K-means算法计算不同投诉类型间的距离。其中,距离=1-cosine(相似度),从而由该距离值来判断投诉工单分类的相似度,距离越小相似度越高。结果如图3所示。
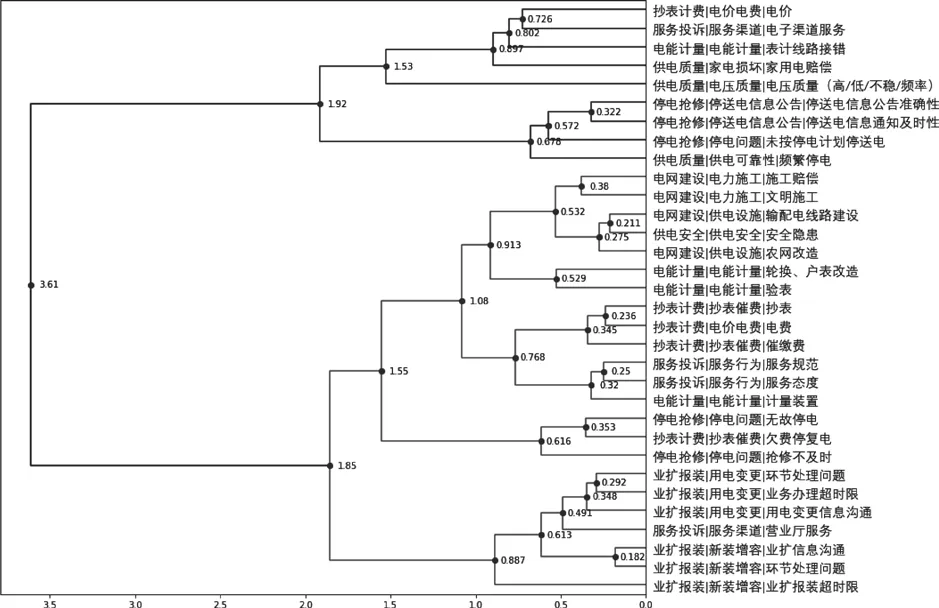
图3 投诉工单分类相似度结果
由图3可见,取部分距离较小的投诉工单分类汇总如表4所示。
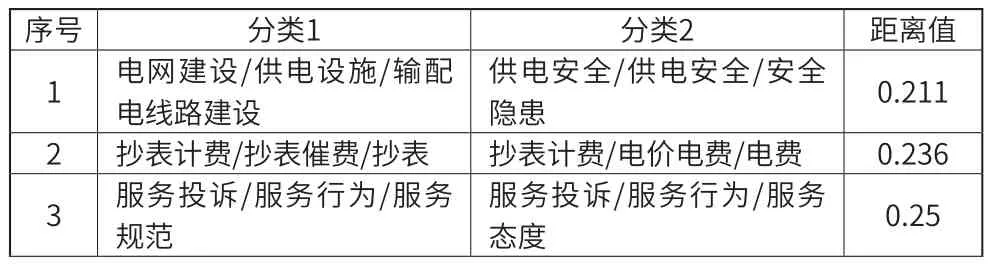
表4 距离较小的工单分类

4 业扩报装/新装增容/环节处理问题业扩报装/新装增容/业扩信息沟通 0.1 8 2
由上述图表分析可知:
(1)有可能是设置的分类冗余导致类别间来电内容反应的问题类似,可以考虑后期合并标签。比如“业扩报装/新装增容/环节处理问题”和“业扩报装/新装增容/业扩信息沟通”,两者之间的距离为0.182,距离较小,说明分类基本相同。
(2)有可能是不同类别设计冗余导致类别之间反应的问题相似,可以考虑后期重新整合。比如“抄表计费/抄表催费/抄表”和“抄表计费/电价电费/电费”的来电内容基本相似,甚至相似度比同一类型的“抄表计费/抄表催费/催缴费”还高。
(3)有可能是类别设计所覆盖的问题本身特点导致在语言描述本身具有相似度,但确实针对的是不同的问题,这些需要考虑后期重新设计类别或者利用“来电内容”以外的其他信息辅助判断。比如“电网建设/供电设施/输配电线路建设”和“供电安全/供电安全/安全隐患”。
■2.3 根据来电内容的聚类分析
针对所有的来电内容记录,计算它们的TF-IDF特征值,然后进行无监督聚类分析。在所有的聚类分析结果中,聚类类型的个数设置与投诉类型相同,为32个。对投诉类型分布进行统计,其中每一聚类类型都是由距离聚类中心的前几个词语代表主题,同时统计当前聚类类型中的原投诉类型分布及其数量。统计的部分结果如表5所示。

表5 投诉类型分布统计(#0)
在表5中,分类号#0的聚类类型主题为:“停电,频繁,客户,变压器”。其中大部分来电内容分布在“供电质量/供电可靠性/频繁停电”中,仅有一条分布在“电网建设/供电设施/农网改造”中。而由原投诉类型相似度分析结果可知两者距离为3.61,投诉类型距离较大,不属于相似投诉类型。
另外的少数来自其他类别的来电内容则需要考虑以下因素:
(1)聚类预测结果错误;
(2)来电内容原标签错误;
(3)来电内容所讲述的需求比较广泛,属于多个类别;
(4)其他可能。
这些因素都可以在后期继续详尽分析,用来提高聚类分析结果或者改进投诉类型结构设计。
3 结语
工单分类的优化始终是电力公司客户服务工作的重要内容,本文结合广西电力业务需求,打破原来对工单数据处理的分析方法,以客户服务工单的大量数据为基础,基于计算语言方法深入挖掘95598工单,对其进行工单分类优化分析。利用Python进行大数据分析操作,完成分词、词频统计、关键词提取等,实现了对数据的精确分析,可为客服工作提供准确的辅助信息,有助于提升客户服务水平。
