基于数据挖掘的冷藏陈列柜的负荷预测研究
2021-06-15雷正霖曾庆辉武宜霄吕彦力胡朝龙
袁 培,雷正霖,曾庆辉,武宜霄,吕彦力,胡朝龙
(1.郑州轻工业大学,郑州 450000;2.山东小鸭冷链有限公司,济南 250000)
0 引言
目前食品冷藏陈列柜的电能消耗约占超市总电能消耗的50%~60%[1-2],特别是敞开式冷藏陈列柜,由于其直接与环境接触,产生高耗能和柜内温度波动等现象。所以,在保证食品品质的前提下,如何降低食品冷藏陈列柜的能耗是一个研究热点。食品冷藏陈列柜的能耗与负荷有关,如何对食品冷藏陈列柜负荷进行准确预测,是实现科学运行的前提,是节能降耗的基础工作。
陆继翔等[3]采用CNN-LSTM混合神经网络模型对电力系统的短期负荷进行预测,并与ARIMA、随机森林、LSTM模型进行比较。结果表明:相同条件下,CNN-LSTM混合神经网络模型的LSTM模型层数为4、训练次数为500,模型的绝对百分比误差在0.35%至2.81%,预测准确度最高。李晨亮[4]采用EEMD-LSTM模型对沪深300指数进行预测研究。结果表明:对比BP、EEMD-BP、LSTM模型,EEMD-LSTM预测性能最优,模型的绝对百分比误差为0.294%,指数方向的预测准确性达到63.93%。WANG等[5]采用LSTM模型对搭建的制冷系统平台进行能耗预测。结果表明:相比传统预测方法,LSTM模型具备更好的预测精度,LSTM的根均方误差比BPNN低19.7%,比ARMA低54.85%,比ARFIMA低64.59%,LSTM模型能很好的预测能耗。
食品冷藏陈列柜的负荷与环境温度、湿度、人流量、结霜融霜、压缩机功耗、制冷剂等多种独立因素相关,准确计算较为困难。这些独立因素具备时间序列性和非线性的特点,数据挖掘在处理这类数据具备独特优势。本研究引入LSTM神经网络模型,将制冷剂质量流速、膨胀阀功率、制冷剂气液压力、蒸发器进出口温度、制冷剂气液焓值、测试时间作为输入数据,通过对数据预处理、训练数据确定LSTM模型层数和训练次数、导入模型中进行预测,最终与实际负荷进行对比,实现对冷藏陈列柜负荷的预测目的。
1 研究方案
1.1 试验样本点获取
本研究采集的样本点来自某公司提供的立式冷藏陈列柜测试数据,所采集的样本点包括(制冷剂质量流速、膨胀阀功率、制冷剂气液压力、蒸发器进出口温度、制冷剂气液焓值、测试时间),测试时间为2019年11月18日8:00:03~2019年11 月 19 日 8:00:03,时间步长为 10 s,共计 8 641组样本点,80%的样本点数据划分为训练集,20%的样本点数据划分为测试集。
1.2 预测数据处理
1.2.1 异常值处理
由于采集数据过程中可能出现问题,采集的数据难免会出现缺失、异常等情况,影响模型预测精度,首先要用python中pandas和numpy模块采用过滤缺失值、补全缺失值、数据转换等操作。
1.2.2 数据归一化
本研究采用的模型对输入数据有一定的要求,需要将输入数据进行归一化处理,将不同范围的数据特征统一规范,统一到[0,1]。
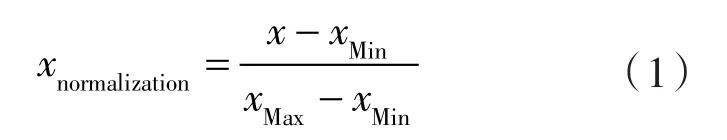
式中 xmormalization——归一化后的输入数据;
x ——输入数据;
xMin——输入数据的最小值;
xMax——输入数据的最大值。
1.3 LSTM神经网络
相较于传统的预测方法,LSTM网络模型对非线性和时间序列的数据具备较好的逼近能力,负荷这类数据具备非线性和时间相关性的特点,因此针对负荷这类时间序列数据LSTM模型具备较好的预测适应性。LSTM由Hochreiter &Schmidhuber(1997)提出[6],是一种特殊的递归神经网络(RNN)。LSTM网络包含三个门(遗忘门、输入门、输出门),其网络基本单元如图1所示[7]。三个门的功能如下:输入门控制流入存储单元的当前信息量;输出门控制流入网络其余部分的当前信息量;遗忘门选择前一时刻的单元状态,并自适应地将部分信息保留到当前时刻。

图1 LSTM基本单元结构Fig.1 LSTM basic unit structure
遗忘门通过sigmoid层决定什么信息通过记忆单元,会根据上一时刻输出值ht-1和当前输入值xt产生一个0-1的ft值,来决定上一时刻学到的信息Ct-1通过或部分通过,数字1保留信息,数字0舍弃信息;输入门中的xt通过sigmoid和tanh函数产生候选值、it,二者作用产生中间值 Ct;输出门通过sigmoid层来得到一个初始输出ot,tanh函数将 Ct缩放,并与 ot相乘得到输出 ht[8-10]。
本研究在深度学习工具TensorFlow基础上[11],利用 python 中 pandas、Keras、Numpy、matplotlib 等模块来构建LSTM模型,并通过读取数据、数据预处理、训练数据、测试数据和数据可视化等操作完成负荷的预测。LSTM神经网络模型将时间序列数据作为输入数据,其中蒸发器进出口温度、压力、焓值、流量、膨胀阀功率都是相互独立的时间序列数据,为了耦合影响冷藏陈列柜负荷的影响因素,需要将所有的因素聚合到一起并转换成数组类型的数据,并将数据设置成以时间序列索引,以此形成了一个以时间序列为索引的新的时间序列数据,每个影响因素和负荷组成特征值,方便模型导入数据和快速计算。
2 结果与讨论
2.1 评价指标
为了验证LSTM神经网络的预测效果,采用三大评价指标均方误差(MSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)[12]。

式中 n ——数据样本点数量;
actual(t)——t时刻的真实负荷值;
forecast(t)——t时刻的预测负荷值;
MAE ——平均绝对误差;
MSE ——均方根误差;
MAPE ——平均绝对百分比误差。
平均绝对误差MAE范围[0,∞],当预测值与真实值完全吻合时为0,即完美模型,误差越大,该值越大;MSE均方根误差,又称为平均损失,本研究采用MAE评价损失函数和MAPE作为模型性能评价指标,MAE在数据上比较直观;MAPE平均绝对百分比误差,表明模型的误差百分比。
2.2 结果分析
本研究将样本点80%数据8用于训练集,20%用于测试集,并将数据设置成按时间索引。本研究通过采用控制变量法来逐步调整模型的精度。通过控制设定LSTM模型的层数,通过改变训练次数来逐渐提高模型预测精准度,达到不断优化模型的效果。本研究采用平均绝对误差MAE作为损失函数来衡量模型的精确度,损失函数是可以很好得反映模型与实际数据差距的工具。首先固定LSTM模型的层数,逐步增加训练次数,接着固定训练次数,逐步增加LSTM模型的层数,来验证LSTM模型的层数和训练次数对预测精度的影响。表1给出了不同LSTM层数和训练次数对应的训练集和测试集的损失函数和平均绝对百分比误差。由图2(a)~(f)可以看出,损失函数随着训练次数的升高呈下降趋势,所以训练集和测试集的损失函数最大差距在开始处,训练集和损失集最开始的损失函数差值从图2(a)~(d)是减小,从图2(e)~(f)是增大。由表1可以看出,6组对照实验训练集的最终的平均绝对误差MAE分别为 0.207 9,0.190 1,0.176 7,0.181 1,0.193 2,0.204 6,MAE随着训练次数的增加逐渐减小,从训练次数为250时开始逐渐增加,测试集MAE变化趋势和训练集一致。网络层数一定时,增加训练次数可以降低损失函数,当训练次数超过200时,出现测试集损失函数的误差增大的现象;再结合表1可以看出在保持LSTM模型的训练次数不变,增加模型层数能有效提高模型预测精度,但层数过高会出现过拟合的现象,如表中层数为5是MAE和VAL_MAE反而出现提高的现象。

表1 模型结构优化试验结果Tab.1 Model structure optimization test results
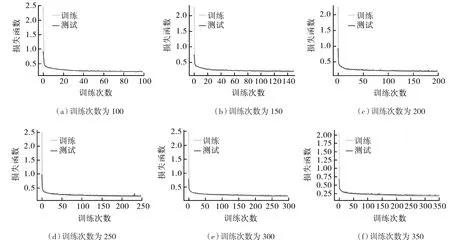
图2 训练次数100~350的损失函数Fig.2 Loss function with training times 100~350
经过上述试验,可以确定LSTM模型的层数为4及200训练次数,将训练好的训练集和测试集导入模型,输出预测结果并与实际结果对比来具体显现模型预测的精度,图3所示为实际数据和预测数据的折线图,图4是2019年11月18日20:00:03前后的预测数据放大图。图3,4中竖直黑线是区分训练集和测试集的分割线。

图3 制冷负荷预测曲线和实际曲线的对比Fig.3 Comparison of cooling load forecast curve and actual curve
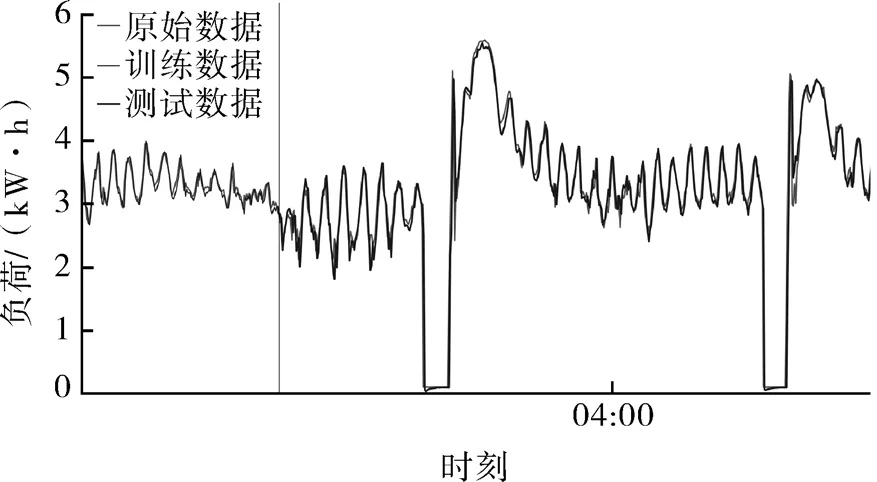
图4 2019/11/19 04:00:03前后的预测数据放大图Fig.4 An enlarged view of the forecast data before and after 2019/11/19 04:00:03
可以看出绝大部分的预测数据基本上与实际数据一致,但是在融霜阶段和融霜后负荷大幅上升阶段预测值和实际值出现较大的偏差,预测值和实际值的最大差值为4.447 7 kW·h,占比为10.27%,最小差值为5.4×10-5;虽然个别的数据点上出现较大但是总体上预测效果还是不错的,预测的数据变化趋势是与实际数据是一致的,模型在训练集的绝对百分比误差为1.836 2%,测试集的绝对百分比误差为1.982 7%,测试集的绝对百分比误差略微提高,是因为测试集在训练集基础上预测负荷,误差积累导致测试集的绝对百分比误差提高。
3 结论
(1)LSTM模型层数为2,训练次数分别为100,150,200,250,300,350的平均绝对误差分别为0.207 9,0.190 1,0.176 7,0.181 1,0.193 2,0.204 6,经过对比测试,最终确定LSTM模型层数为4,训练次数为200,MAE为0.162 7,VAL_MAE为0.182 3,整个模型平均的MAPE为1.909 4%,为最优模型。
(2)将数据导入训练好的模型,得到模型在训练集的平均绝对百分比误差达到1.836 2%,测试集的平均绝对百分比误差达到1.982 7%,预测值在融霜阶段和融霜后的短期内出现较大的误差,预测值和实际值的最大差值为4.447 7 kW·h,占比为10.27%,最小差值为5.4×10-5kW·h。
下一步本研究准备采集超市等场所的实际状况,引入人流量、商品数量等影响因素,结合调整的LSTM模型更加贴近实际生活的预测负荷,为下一步为冷藏陈列柜的科学运行和节能打好基础。
