改进的小脑模型神经网络及其在时间序列预测中的应用
2021-06-15乔俊飞董敬娇李文静
乔俊飞,董敬娇,李文静
(北京工业大学信息学部计算智能与智能系统北京市重点实验室,北京 100124)
小脑的功能是指挥肢体运动,在控制肢体运动的过程中不假思索就能做出条件反射. 小脑模型神经网络(cerebellar model neural network,CMNN)就是一种模拟条件反射快速做出联想的网络,它原本是一种控制装置,被用于控制机器人的运动[1],满足研究人员初期对一种在实时性上表现良好的网络的需求,由此引起人们的关注. 近年来,CMNN除被应用于控制领域外,还逐渐被应用于系统辨识、机器学习等建模领域. 在建模领域中CMNN的一个重要的应用场合便是非线性系统的时间序列预测. 从统计学方面看,时间序列预测是某一状态变量或某一指标在不同时间点所观察到的数值按时间前后排列成的数列;从系统方面看,时间序列是所观测的系统在不同时刻上的响应值的排列,其中,观测数据之间的时间间隔是相同的[2]. 研究时间序列的主要目的是进行预测,更准确地控制和干预动态系统未来实况. 时间序列中涵盖了观测的状态变量或研究的系统的历史信息,根据这些历史数据的变化规律来得知系统未来的变化情况,从而可以有预见性地改善系统的性能,达到预测效果. 预测的时间序列如果取自线性系统,则可以用线性方法解决,但实际场景中获得的时间序列基本是非线性的,因此,其数据信息也具有随机不确定、时变性的特点,此时,再利用一些经典的线性方法进行预测显然不是很有效. 于是,非线性方法引起了众多学者的重视,神经网络便是其中方法之一. 在人工神经网络中,反向传播(back propagation,BP)网络虽然具有良好的非线性映射能力,但是该网络在收敛性能上表现较差[3]. 而CMNN与其他神经网络相比,其优势明显:CMNN非线性逼近器对数据出现的次序不敏感,并且具有良好的实时性,收敛速度较快. 这些特性使它比一般的神经网络具有更好的非线性逼近能力,非常适合解决非线性动态系统的时间序列预测问题.
但是CMNN进行学习时,不能对一些定性的基本知识进行表述,并且网络权重的初始条件设置具有随机性,这就可能会使网络陷入局部极值. 其次,CMNN存在的一个主要问题是泛化能力和存储单元容量之间的矛盾. 具体而言,存储容量会随输入维数的增加而呈指数增长[4],存储空间容量的大小也可通过量化级数这个参数来反映,量化级数表示输入变量激活的存储单元的层数. 理论上,增加网络输入变量的分级个数就会相应地增加量化级数,最终会提高CMNN的泛化能力;实际上,CMNN接收域函数是零阶的,即接收域是矩形的,网络的映射输出表达易出现不连续,因此,通过增加量化级数来提高网络的泛化能力,会导致CMNN最终无法有效学习,称之为泛化能力与存储容量之间存在矛盾. 因此,当输入变量维数增加,量化级数相应增大,网络仍然可达到一个良好的逼近精度,对CMNN的建模研究具有很大意义.
针对上述CMNN存在的问题,许多专家学者提出了在网络中加入模糊逻辑的思想. 模糊逻辑相对可以很好地表述定性知识,跟人对事物的认知模式相似,但是模糊逻辑学习性差,只能根据专家经验或知识产生的模糊规则对它们进行修改,试凑地选择隶属度函数. 综合CMNN和模糊逻辑两者的特点,可以在一定程度上将它们进行结合. 邓志东等[5]基于Takagi型推理思想,构建了一种与CMNN相似的模糊网络,具备模糊性质,一定程度上弥补了CMNN的不足,但是该网络删减了CMNN的地址映射方式,致使网络的响应能力大大减弱. Wang等[6]、王琳等[7]和Guo等[8]基于测量相近的程度和学习的竞争性,构建了一种具备组织性质的模糊CMNN,有效应对了模型在选取存储空间单元参量时的复杂程度,但是由于利用了竞争学习,学习过程比较复杂. 周旭东等[9-10]将原始CMNN与模糊逻辑融为一体,构建了一种模糊CMNN,该网络保留了CMNN的寻址方式,在响应上不仅表现迅速,而且在逼近性上表现也较佳,缺陷在于网络仿真前需要设定好隶属度函数数值的大小,网络应用具有局限性. 因此,构建一种网络,使其在保留CMNN地址映射的基础上,将接收域函数改用模糊隶属度函数并使网络具有普遍意义,是一个需要解决的问题.
基于以上研究背景的分析,本文构建了一种改进的CMNN模型,即模糊隶属度小脑模型神经网络(fuzzy membership cerebellar model neural network, FM-CMNN). FM-CMNN保留CMNN特有的寻址方式,在CMNN的联想存储单元中引入具有普遍意义的铃型模糊隶属度函数,作为感受野的激励函数,使CMNN变成一种带隶属度的查表方法,网络的映射输出具有连续性,从而使FM-CMNN在量化级数增大时仍具有较好的学习能力,克服了经典网络中泛化能力与存储空间容量的冲突. 本文选用非线性系统辨识和有关污水处理中的参量作为预测实验,证实该网络具有较高的测试精确度.
1 CMNN结构
CMNN的结构由输入层、存储空间、输出层3层组成,如图1所示. 它的结构本质是一种使用地址映射的具备搜索特性的表格系统.

图1 传统CMNN结构Fig.1 Structure of traditional CMNN
输入层是训练神经网络的输入变量的集合,用于对输入变量进行划分与量化,目的是将其映射到下一层的存储空间. 存储空间由联想和实际2个子存储空间构成,主要用于存储输入向量的映射值和网络的权值[11-13]. 输入向量被量化后首先映射到联想存储空间(lenovo storage space,LSS),LSS中分散存储着输入向量,距离较近的输入向量所激活的LSS中的存储单元会有重叠现象,反之,存储单元互相独立,输入变量激活的LSS中的存储单元的个数称为泛化系数C. 然而,大部分存储单元中并不会包含输入层中所有的可能状态,需要删减一部分存储单元[14],因此,通过压缩编码的方式将输入变量激活的LSS中的C个存储单元映射到实际存储空间(actual storage space,ASS)中的C个存储单元,实际存储区域对应存放激活单元的权重. 输出层用于计算网络的输出值,输出值的大小等于激活单元的权值之和,此外,因为CMNN权重的初始条件设置的随机性并不会影响网络学习的收敛情况,所以具有自适应性[15].
为充分考虑已学习知识的可信程度,首先要对现有的传统CMNN进行分级量化[16-17].分级量化的操作是:不同变量的同一级的不同块组合成存储空间,存放变量映射值.以二维输入变量为例,假设二维输入变量x1和x2分别分成3个量化级,每级又由3块组成,变量x1每一级的块组合分别为:{A,B,C}、{D,E,F}、{G,H,I}.变量x2每一级的块组合分别为:{a,b,c}、{d,e,f}、{g,h,i}.块的长度不等,但每级长度相等.不处于同一级的块则不能合成存储空间单元[18].以第1级为例,它可以组成的存储空间单元是Aa、Ba、Ca、Ab、Bb、Cb、Ac、Bc、Cc.其余每级的存储单元构成过程同理.设m为状态变量的量化级数,N为存储单元的个数,所以该例中m=3,N=27,并可知,每个输入变量存储在m个存储空间中,用aj表示第j个存储单元的激活情况,当第j个存储单元被激活时,其值为1,反之为0,即
2 改进的CMNN结构及其学习算法
2.1 FM-CMNN模型
改进的CMNN共由5层组成,分别是输入空间、模糊化空间、LSS、ASS和输出空间,FM-CMNN的结构如图2所示.

图2 FM-CMNN结构Fig.2 Structure of FM-CMNN
输入变量与LSS之间的地址映射先后由2步完成,分别是输入空间到模糊化空间的映射和模糊化空间到LSS的映射.LSS的激励函数选择铃型隶属度函数,由于只调整被激活单元的权值,所以,只确定相应激活存储单元的函数值,这在一定程度上减少了函数的计算量.
2.1.1 输入单元的划分与量化
输入层中接收到的输入变量可能是数字量,也可能是模拟量,当输入变量是数字量时,可以直接映射到存储空间,但输入变量如果是模拟量,需要进行量化处理后再映射到存储区域,下面对输入变量为模拟量的情况进行说明.假设一组输入变量X=[x1,x2,…,xn]T,输入变量是一个有限的空间,定义为:Xi={xi:xi,min≤xi≤xi,max},可将该区间进一步划分:xi,min≤xi,1≤xi,2≤…≤xi,N≤xi,max,分别对应模糊语言变量负大、负中、负小、零、正小、正中、正大.当输入变量为模拟量时,需要对变量x进行相应的量化处理,将其量化为0~n-1的一个整数,这个处理操作与输入变量映射到哪个存储区域有关,其中关键一步是选定量化函数,量化函数有线性和非线性之分,为方便计算,在此取量化函数是线性的,公式为
(1)
式中:xmin和xmax分别为量化变量的最小值和最大值,一般设置为-1和1;M为量化系数,其大小取决于激活的区域单元的量化级数和每级包含的块数.
在此,定义输入变量的分辨率为
(2)
由此可知,输入分辨率与输入变量量化的最大值、最小值和量化系数有关.
2.1.2 模糊化空间
1) 计算状态变量映射单元的地址
模糊化层不可能包含所有的输入状态,输入状态变量激活的单元的地址映射方法有很多种,比如传统CMNN中LSS到ASS的地址映射方法采用Hash编码的方式[19],本文综合分析后选择的模糊化层被激活单元的地址计算方法为
(3)
式中:m为输入变量的量化级数,等于激活单元的个数;nb为每级包含的块数.
2) 模糊隶属度函数的选择
模糊集合的隶属度函数有数值表达和函数表达2类表达方式,由于数值表达方式适用于输入变量为离散、变量个数为有限的情况,并且基于非线性系统建模的研究背景,本文采用函数表达方式.模糊隶属度函数的表现形式也有很多种,最常见的有正态函数、铃型函数(也称三角形函数)和梯形函数[20].曾有研究者引用过径向基函数,然而当输入变量维数较大时,它每一步的计算量也大大增加,难以实时控制,三角形高斯函数则可实现在线实时控制[21].因此,考虑到实时性,FM-CMNN的模糊隶属度函数引用三角形函数.本文中引入的三角形模糊隶属度函数为

(4)
式中:ci,j为模糊隶属度函数的中心;δi,j为模糊隶属度函数环绕中心位置的宽度.根据专家经验知识及前人的研究成果,δi,j值的确定可由2个相邻的隶属度函数的相互重叠计算得出,计算过程为
(5)
式中μc在计算前需人为设定一个0~1的值.
2.1.3 LSS
LSS又称规则层,考虑到为减小函数计算量,只确定被激活单元的函数值,需要对模糊化层进行压缩,然后将被激活单元的输出值合成到LSS,在LSS中对前一层的输出进行逻辑“与”运算,即
(6)
与传统CMNN不同的是权值空间的维数不再与输入变量的维数相关,而是使权值空间的维数等于规则个数,允许连续信号的输入和输出,从而在量化级数增加、存储单元容量相应增加的情况下,网络具有更高的泛化能力和逼近精度.
2.1.4 ASS
FM-CMNN的权重储存在ASS中,先求出含有网络权重的存储空间的位置,才能获得网络权值.存储区域位置的计算过程为
Adj=j+m·Ai·nbn-1
i=1,2,…,n;j=1,2,…,m
(7)
由此可知,确定了模糊化层被激活单元的地址后也就确定了ASS中存储单元的地址.
2.1.5 输出空间
根据CMNN输出表达式的原理,计算FM-CMNN输出层的输出,即

(8)
2.2 FM-CMNN的学习算法
FM-CMNN使用梯度下降的学习算法对网络的权值进行调整.首先定义误差函数为
(9)
使用梯度下降算法完成权重的修正,修正过程为
(10)
式中η为网络的学习率.权值调整后得到的新的权值为
wi=wi+Δwi
(11)
3 实验仿真
本文提出的FM-CMNN,由于在存储单元中引入了模糊隶属度函数,使权值空间的维数等于规则个数,并采用CMNN特有的寻址方式,从而在不受状态变量量化级数和存储容量限制的情况下,增强了网络的泛化性能,降低了网络的学习误差.选用非线性系统辨识、加利福尼亚大学尔湾分校(University of California Irvine,UCI)公开发表数据集、污水处理过程水质参数预测实验,对FM-CMNN的性能进行评价,检测网络解决预测问题的高效性.以均方根误差(root mean square error,RMSE)为模型的评价指标,其表达式为
(12)
式中L为样本总数.
3.1 非线性系统辨识
用非线性系统辨识实验作为基准实验,验证FM-CMNN的有效性,实验表达式为
(13)
式中:σ(t)=sin(2πt/25),t∈[1,600];设初始值为y(0)=0,y(1)=0;y(t)、y(t-1)、σ(t)为输入向量.样本集共600个数据,从中选用400个用作训练样本,其余200个用作测试样本,迭代200次.FM-CMNN参数设置为:量化级数m=6,分辨率D=0.330,μc=0.9.
为使CMNN的泛化能力保持良好,量化级数根据经验值设置m=7,分辨率D=0.286.网络训练的RMSE曲线变化如图3所示.
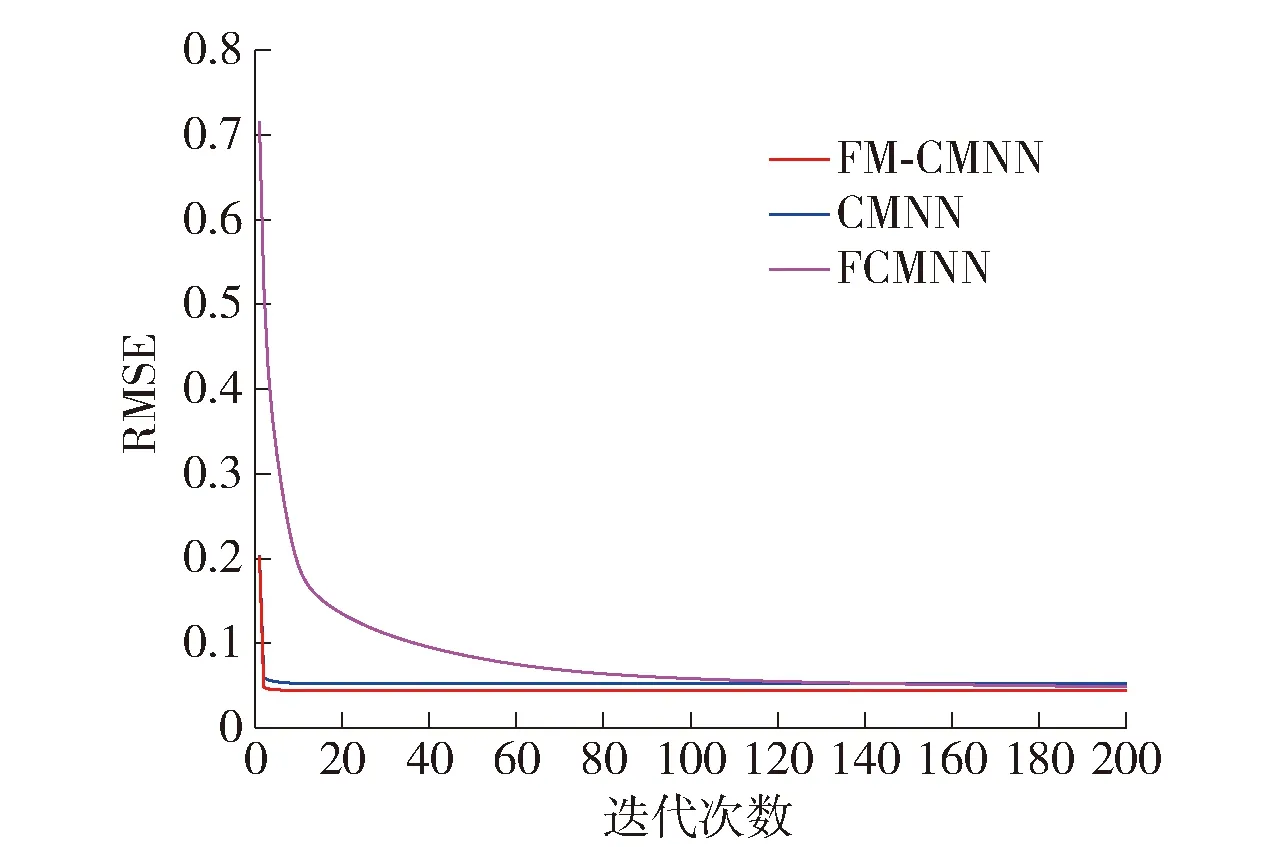
图3 非线性系统辨识训练样本RMSEFig.3 RMSE of training samples for nonlinear system identification
通过训练RMSE变化曲线可知,由于FM-CMNN结合了CMNN和模糊逻辑二者的优点,所以跟CMNN以及未采用寻址方式的一般的模糊小脑模型神经网络[3](fuzzy cerebellar model neural network,FCMNN)相比,FM-CMNN的RMSE指标值更低.图4、5分别是FM-CMNN、CMNN和FCMNN对非线性系统的预测输出和预测误差,由图4、5可知,由于FM-CMNN的接收域函数改用三角形模糊隶属度函数,所以在对非线性系统进行辨识时能取得较小的预测误差,实际测试输出曲线与期望测试输出曲线吻合,网络具备较强的辨识可靠度和稳定度,弥补了传统CMNN在量化级数改变时无法有效学习的不足,提高了传统网络的泛化能力.

图4 非线性系统辨识预测输出Fig.4 Prediction output of nonlinear system identification

图5 非线性系统辨识预测误差Fig.5 Prediction error of nonlinear system identification
FM-CMNN、CMNN与FCMNN的RMSE性能对比结果如表1所示.
表1中,训练样本的RMSE和测试样本的RMSE的数值是将训练样本和测试样本分别分成了15组,独立实验了15次后求得的平均值.各个网络的量化级数的大小根据各实验中输入变量的个数而定,根据专家经验及前人的研究成果,量化级数大小通常取输入变量个数的1~3倍.该实验中,取输入变量维数的3倍为FCMNN的量化级数,FM-CMNN的量化级数大小是输入变量维数的2倍.

表1 不同网络性能对比结果
表中黑体是FM-CMNN的实验结果,由表可知,FM-CMNN训练样本和测试样本的RMSE平均值分别是0.044 1和0.033 7,因此,当CMNN比FM-CMNN的量化级数高一级时,前者的逼近精度已明显不如后者,而未采用寻址方式的一般的FCMNN,即使增加量化级数,其泛化能力也不如其余2个网络.
3.2 UCI公开数据集
本实验选取了UCI中一组公开数据集作为网络的学习样本,验证FM-CMNN性能的优越性.该数据集是基于定量构效关系(quantitative structure-activity relationship,QSAR)非线性模型生成,输入状态变量为分子特征、信息指数、原子型计数器值、自相关性、矩阵描述符等6个属性,状态响应为:水体中化学成分导致实验鱼在96 h内死亡50%的浓度.学习样本共1 000个,使用前已归一化到[-1,1],从中抽取500个用作训练,其余500个用作测试,迭代1 000步.
FM-CMNN参数设置为:量化级数m=8,分辨率D=0.25,μc=0.9.为使CMNN能够有效学习,其量化级数m=7,学习率D=0.286.训练样本的RMSE曲线如图6所示.通过训练样本的RMSE变化曲线可知,由于CMNN继续增加量化级数会导致存储单元容量的剧增,最终导致网络无法有效学习,所以其逼近精度低于FM-CMNN,而FM-CMNN由于在存储单元中加入了隶属度函数,所以其泛化性能不受存储容量的影响,量化级数增大仍可达到良好的逼近效果.一般的FCMNN由于没有采用寻址方式,所以增加量化级数后其泛化能力不但没有提高,反而加剧了响应的迟钝性.

图6 UCI公开数据集训练样本的RMSEFig.6 RMSE of training samples for UCI open dataset
图7、8分别是FM-CMNN、CMNN、FCMNN对UCI数据集的预测输出和预测误差,由图7、8可知,利用FM-CMNN解决水体对鱼类毒性的预测问题时,网络有很强的实时性和很高的逼近准确性,量化级数增加时网络仍具有较好的学习效果.

图7 UCI公开数据集预测输出Fig.7 Prediction output of UCI exposes dataset
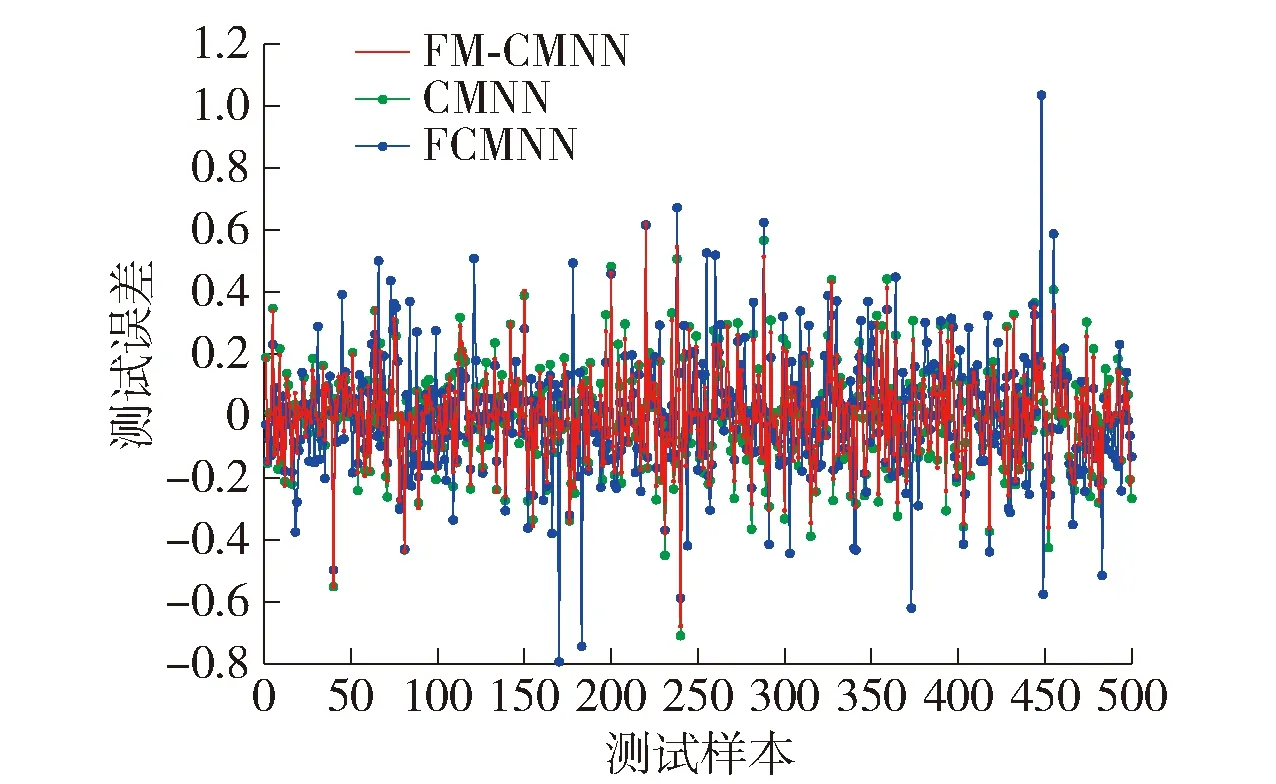
图8 UCI公开数据集预测误差Fig.8 Prediction error of UCI public dataset
CMNN和FM-CMNN与一般的FCMNN的RMSE性能对比结果如表2所示.

表2 不同网络性能对比结果
表2中,训练样本的RMSE和测试样本的RMSE的数值是将训练样本和测试样本分别分成15组,独立实验15次后得到的平均值.FCMNN的量化级数取输入变量维数的2倍,FM-CMNN量化级数可稍大于CMNN,以证明在存储容量增加时,FM-CMNN比CMNN有较好的泛化能力.表中黑体是FM-CMNN的实验结果,该网络训练样本和测试样本的RMSE平均值分别为0.155 5和0.149 2.由此可知,FM-CMNN的逼近精度要高于CMNN和FCMNN.
3.3 污水处理过程中出水生化需氧量(biochemical oxygen demand,BOD)预测
本实验通过污水处理过程中的关键水质参数出水BOD[22]来验证FM-CMNN性能的优越性.数据集共有10个输入变量:出水总氮质量浓度、出水氨氮质量浓度、进水总氮质量浓度、进水BOD质量浓度、进水氨氮质量浓度、出水磷酸盐质量浓度、进水磷酸盐质量浓度、进水化学需氧量(chemical oxygen demand,COD)质量浓度、生化池溶解氧质量浓度、生化池混合液悬浮固体质量浓度.共有365个样本,其中选取265个作为训练样本,其余100个作为测试样本,迭代500次.
FM-CMNN参数设置:量化级数m=9,分辨率D=0.220,μc=0.9.为保证CMNN的学习能力,量化级数最大设为7,因此,分辨率最大为0.286.网络的训练样本的RMSE曲线如图9所示.通过训练样本的RMSE变化曲线可知,设置FM-CMNN的量化级数大于CMNN,存储容量相应增加时,FM-CMNN的逼近精度仍保持最高.

图9 污水处理出水BOD训练样本的RMSEFig.9 RMSE of training samples for sewage treatment effluent BOD
FM-CMNN、CMNN和FCMNN对污水处理出水BOD的预测输出和预测误差分别如图10、11所示.由网络的测试输出结果图可以看出,FM-CMNN对污水处理过程的真实数据进行预测时,网络的测试输出值与理想的测试输出值相差不大,体现出FM-CMNN在存储容量增加时仍具有良好的泛化性能.
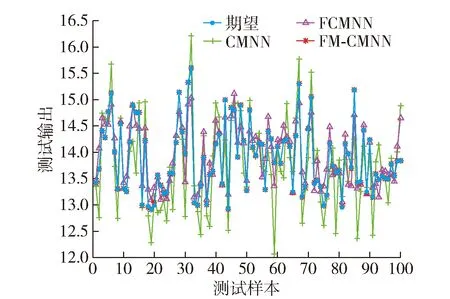
图10 污水处理出水BOD预测输出Fig.10 Prediction output of sewage treatment effluent BOD
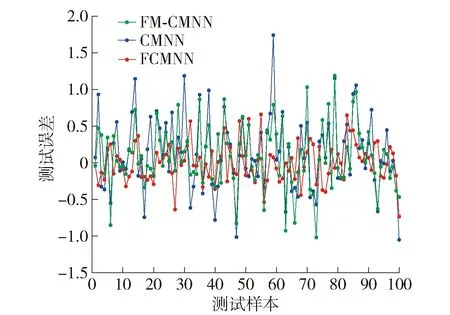
图11 污水处理出水BOD预测误差Fig.11 Prediction error of sewage treatment effluent BOD
CMNN、FM-CMNN与一般的FCMNN的RMSE性能对比结果如表3所示.

表3 不同网络性能对比结果
表3中,RMSE数值是将训练样本和测试样本分别分成了20组,独立实验了20次后求取的平均值.FCMNN的量化级数同输入变量维数,FM-CMNN量化级数可稍大于CMNN,并经过多次学习确定其值,以证明在存储容量增加时,网络仍具有较好的泛化能力.由结果可知,FM-CMNN训练和测试的RMSE的平均值分别为0.101 0和0.312 0,均低于传统网络,因此,FM-CMNN的泛化能力不受存储容量影响,可通过增大量化级数来提高逼近精度,解决了传统CMNN泛化能力与存储容量之间的冲突.一般的FCMNN虽然增加量化级数,但是逼近精度仍低于其余2个网络.因此,对于污水处理过程的水质参数实验,FM-CMNN更具有明显的优异性.
4 结论
1) 传统CMNN虽然能够实时控制,但其泛化能力受到存储容量的限制.为此,在保留传统CMNN地址映射方式的基础上,在存储空间中加入三角形模糊隶属度函数,构建一种基于模糊隶属度的小脑模型神经网络FM-CMNN,使网络输出更具有连续性,在存储容量增加时网络仍具有较强的泛化能力.但由于FM-CMNN构建时没有考虑其计算复杂度,所以网络学习误差的收敛速度慢于传统网络,针对这个问题,下一步计划采用一种可行的优化算法进行改善.
2) 利用对比实验,验证了所提出的FM-CMNN性能的有效性.通过对比训练RMSE变化曲线可知,CMNN虽然具有更快的收敛速度,但是在输入变量维数增大时,由于该网络量化级数设置具有局限性,导致其逼近精度较低.FM-CMNN因其接收域函数采用模糊隶属度函数,所以在输入变量维数增加、存储容量增大时,网络具备更高的逼近精度;FM-CMNN与传统FCMNN相比,FCMNN的量化级数较大时,其逼近精度和收敛速度均低于FM-CMNN.
3) 通过FM-CMNN对非线性系统辨识、UCI公开数据集、污水处理过程出水BOD预测实验可知,FM-CMNN的实际预测输出曲线与期望预测输出曲线基本接近.FM-CMNN弥补了传统网络不能通过增大量化级数来提高泛化能力的不足,解决了传统CMNN中泛化能力与存储容量之间的矛盾问题,网络具有较强的自适应性,更适用于非线性系统的预测.
