学术文摘创新点挖掘的认知分析方法
2021-06-14何茜茹
温 浩,何茜茹
(西安建筑科技大学信息与控制工程学院,西安 710055)
1 基于文摘创新点的知识问答服务
如何有效利用海量文本学术资源为人类提供最直接的内容知识问答服务,而不仅仅是信息检索服务,一直是人工智能在自然语言处理领域研究的目标。目前的科技学术文摘是以文本方式组织而成的,如果想要利用人工智能技术解决知识服务问题,就需从科技学术文摘内容中挖掘出具有独立存在的创新点事实单元,将其分解为问题、方法、结果的实体和语义关系,建立以创新点事实为知识单元的知识库。文献[1]对《计算机学报》文摘进行数据统计分析,研究了文摘创新点中特征词汇的句子分布规律,对文摘创新点中名词-动词的语义关系进行了聚类分析,构建了期刊文摘创新点的语义本体模型,建立了文摘创新点的对象名词与语义动词部分词库。实验结果表明,研究具有很好的语义识别与分类准确率,但是这一基于统计学习的方法受到词库数量、领域变化、写作者风格等因素的限制,严重地影响着从中文科技期刊文摘中挖掘表达创新点的“问题、方法、结果”三元组知识单元的挖全率,影响着基于三元组建设智能化知识创新点问答服务系统需求的急迫性。
在前期研究的基础上,本文对科技文摘创新点的报道性、词汇语义分布的一致性、谓语动词的语义理解性、语用功能的分类性和句法模型的隐含性五种认知分析方法进行了深入的研究,期望找到科技文摘创新点挖掘的认知分析方法,对基于创新点知识库的建设和智能问答系统的服务提供理论和方法的指导作用。
2 学术论文文摘报道创新点的认知分析
为了规范文摘编写和便于国际化信息交流,国际标准化组织颁布了国际标准ISO 214-1976(E)(Documentation-Abstracts for Publications and Docu‐mentation)[2];我国也公布了相应的国家标准《文摘编写规则》(GB 6447-86)[3]和国家标准《科学技术报告、学位论文和学术论文的编写格式》(GB 7713-87)[4]。
国际标准ISO 214-1976(E)指出,文摘是对原文献内容准确、扼要而不附加解释或评论的简略表述,其规定:文摘应包括目的、方法、结果与结论以及附带信息。国家标准(GB 7713-87)规定,摘要是报告、论文的内容不加注释和评论的简短陈述。摘要应具有独立性和自含性,即不阅读报告、论文的全文,就能获得必要的信息,要便于检索。摘要应说明研究工作的目的、方法、成果和结论,要突出本论文的新见解,语言精练。
国家标准(GB 6447-86)还规定了文摘编写详细规则的5个要素:①目的(研究、研制、调查等的前提、目的和任务,所涉及的主题范围);②方法(所用的原理、理论、条件、对象、材料、工艺、结构、手段、装备、程序等);③结果(实验的结果、研究的结果、数据,被确定的关系,观察结果,得到的效果,性能等);④结论(结果的分析、研究、比较、评价、应用,提出的问题,今后的课题,假设,启发,建议,预测等);⑤其他(不属于研究、研制、调查的主要目的,但就其见识和情报价值而言也是重要的信息)。
对于文摘研究的文章有很多,文献[5]把科技文摘的形式分为4类:报道性(informative)、指示性(indicative)、混合性(indicative-informative)和评论性(review abstract)。并强调报道性文摘概述原文内容的要点,特别是创新点,向读者提供定量和定性信息,反映原文的技术内容,包括研究对象、工作目的、结果、性质、方法和条件等有关的各种资料,适用于学术论文和技术报告。
本文对学术文摘的认知分析方法可以归纳为:①学术文摘是论文内容要点的概括;②报道创新点是学术文摘的核心;③文摘具有与原文的独立性和自含性;④文摘的功能便于信息检索;⑤文摘报道创新点的核心内容便于今后用于知识发现。
目前,文摘的信息检索功能已经被普遍使用,但由于受到技术的制约,利用文摘的创新点进行知识发现还未实现,本文的研究目的就是对自然语言表述的文摘的创新点语句进行词汇特征统计,语义关系识别,语用功能分类、句法模式挖掘,建立以“问题方法-结果”为三元组结构的知识库,基于三元组知识库开展知识问答服务、加速新知识的发现。
3 文摘创新点词汇语义分布的认知分析
3.1 文摘动词和名词的词汇数量分布
虽然国际标准和国家标准均对文摘的写作规范给出了明确的规定,但作者写作的语言表达风格却是不一样的,因此,智能挖掘文摘创新点首先需要进行语义识别。语言学家认为,作为语义分析的基本单位是从词(比语素高一层的语言单位)开始的,因为词是语言中能够独立运用的最小单位,所以要找出语义的基本单位必须先从词入手[6]。为揭示学术文摘中作者表达创新点的词汇语义分布特征,需要了解文摘的语言特点,包括高频词汇的分布信息。本文从北京万方数据股份有限公司获得的3410篇《计算机学报》文摘和8235篇《电子学报》文摘,对这些文摘进行动词和名词的统计分析工作。统计方法有:①利用ICTCLAS分词工具对文摘进行分词;②统计文摘动词的词频和名词的词频;③统计两种学报文摘的高频动词和高频名词分布的一致性;④统计文摘动词在句子中的分布特征。
统计结果表明,3410篇《计算机学报》文摘的总字数为226111个,动词的数量为30944个,平均每篇文摘有9.07个动词,词频最高的动词是“提出”,词频高达到5284次,占总动词30944的17.1%,平均每篇文摘有1.55个“提出”这个动词。8235篇《电子学报》文摘的总字数为1681116个,动词的总数为224048个,平均每篇文摘有27.02个动词,频率最高的动词是“提出”,频率高达到8423次,占动词总数224048个3.8%,平均每篇文摘有1.023个“提出”这个动词。
《计算机学报》文摘和《电子学报》文摘的部分高频动词和高频名词统计结果如表1所示。
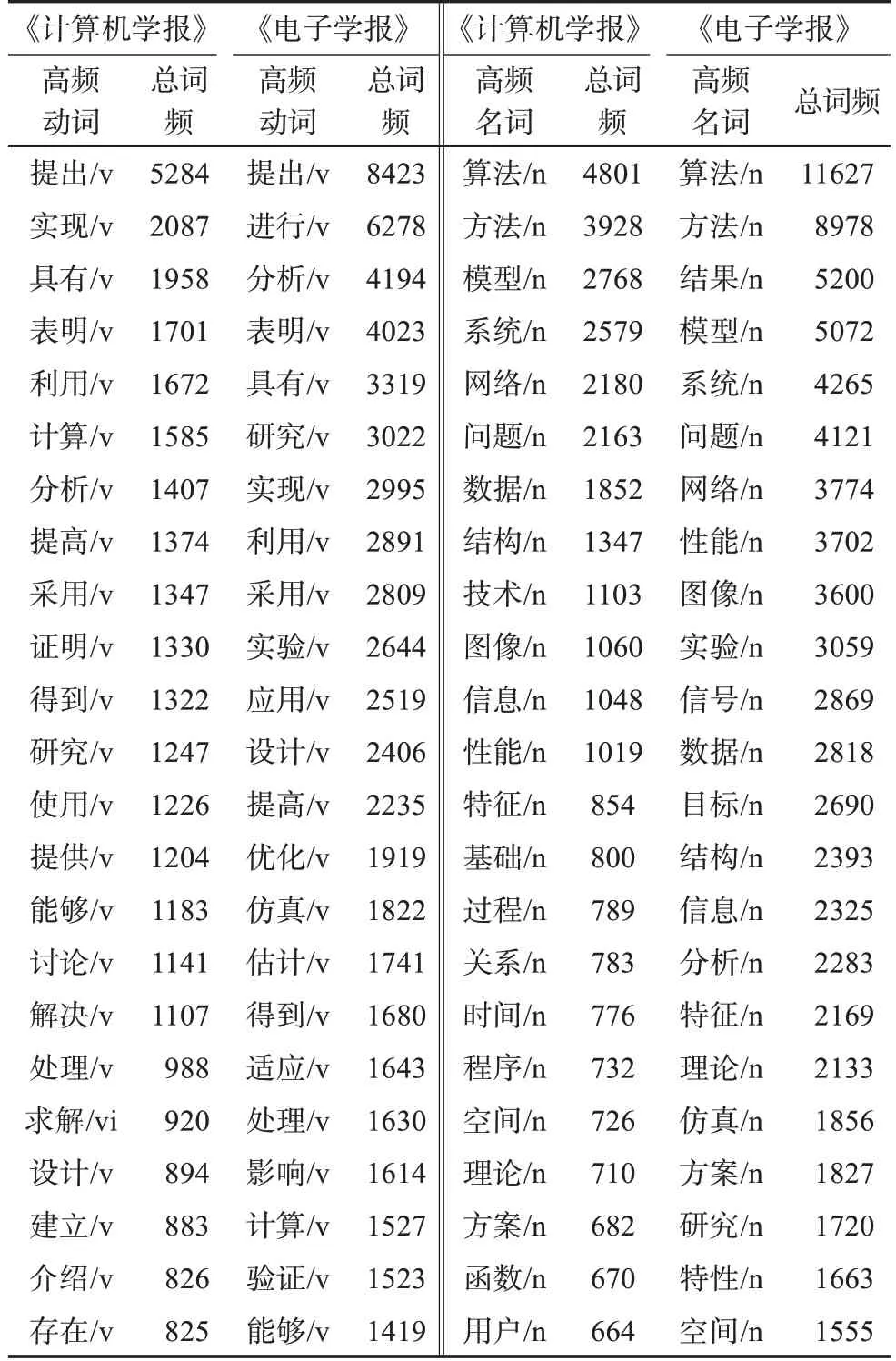
表1《计算机学报》文摘和《电子学报》文摘的高频动词和名词
3.2 两种文摘高频动词和高频名词一致性分布
取两种学报文摘动词词频最高的前2286个动词进行分析。其中,两种学报共有的动词为1403个,平均一致性为0.61。两种学报文摘共有的动词词频最高的是“提出”,两者前10个动词共同有的为7个,前50个动词共同有的为31个,前100个动词共同有的为61个,前500个动词共同有的为326个,前1000个动词共同有的为650个,前2000个动词共同有的为1262个。两种学报文摘的高频动词一致性分布如图1所示,横坐标为对数坐标。
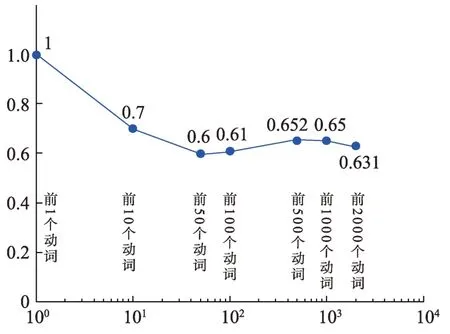
图1 两种学报文摘的高频动词一致性分布
取两种学报文摘名词最高的前2949个名词,两种学报最高词频共同有的名词为1076个,平均一致性为0.36。两种学报文摘共有的最高词频名词为“算法”,两者前10个名词共同有的为7个,前50个名词共同有的为34个,前100个名词共同有的为54个,前500个名词共同有的为263个,前1000个名词共同有的为477个,前2000个名词共同有的为810个。两种学报文摘的高频名词一致性分布如图2所示,横坐标为对数坐标。
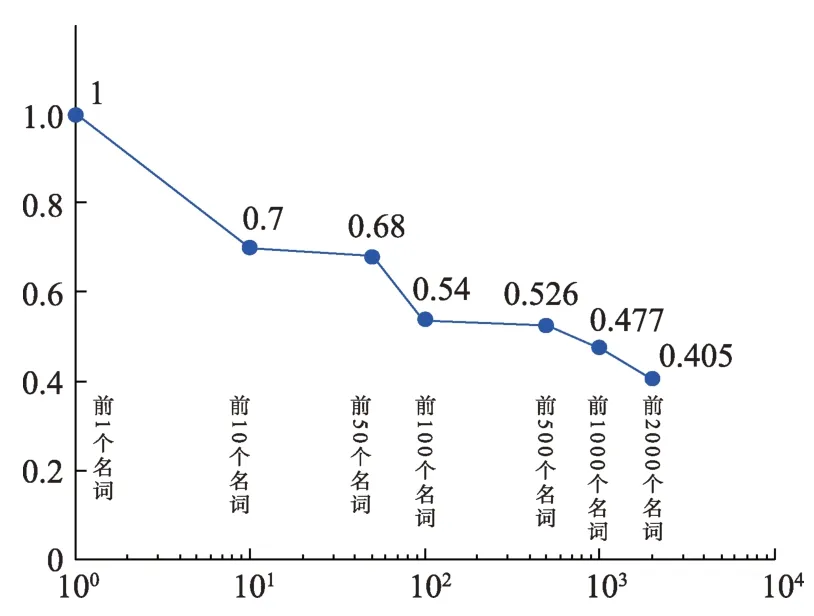
图2 两种学报文摘的高频名词一致性分布
统计结果表明,两种学报文摘的动词一致性为0.61,名词的一致性为0.36。这说明了高频动词的变化规律比较平稳,而高频名词随着专业的不同和数量的增大变化比较大。这一结果说明,建立动词库比建立名词库更具有分析文摘创新点特征的价值。然而,实验结果表明,仅使用高频动词的分类,效果不够理想,因为一个句子中的动词有多个,有的分词工具会将名词分为动词,只采用动词对文摘进行问题、方法和结果分类的准确率只能达到0.36,因此,还需要考虑动词在句子中的位置分布特征。
3.3 高频动词的句子位置分布特征
动词的词频变化规律对于文摘创新点的分析具有重要意义,同时,高频动词的句子位置分布特征信息也具有重要价值。为了寻找高频动词的句子位置分布规律,本文对《计算机学报》文摘中的高频动词句子位置分布特征进行统计分析。《计算机学报》文摘的句子最多为10句、最少为3句。部分高频动词的句子位置分布如表2所示,表中列出了前23个高频动词在文摘的每个句子中的分布数量。
从表2可以看出,动词不仅有频率的分布信息,还有位置的分布信息。动词主要集中分布在文摘句的第1~4句上,每个动词在句子的分布上具有其一定的位置特征。例如,“提出,利用,分析,提高,证明,得到,研究,解决,处理,建立,介绍”在第1句上分布较多,“实现,具有,采用,使用,能够,求解,设计,存在”在第2句上分布较多,“表明”在第4、3、5句上较多,“提供”在第4、5句上分布较多。因此,通过动词在文摘句的位置分布信息可以掌握动词表达句子的语义信息,但由于位置信息的分布还比较广泛,通过动词的词频和位置信息还难以对文摘创新点进行有效分类。
为了进一步对文摘的动词进行深入分析,本文把文摘句进一步细分为以句号结尾的句子和以分号与逗号结尾的子句,分析文摘中的动词在某个句子的某个子句中的位置信息。表3给出了前10个高频动词在前4个句子中的子句位置上的分布特征。表3中用x表示句子,y表示子句,如x1y2表示每个文摘中第1个句子中的第2个子句中的动词位置数量。
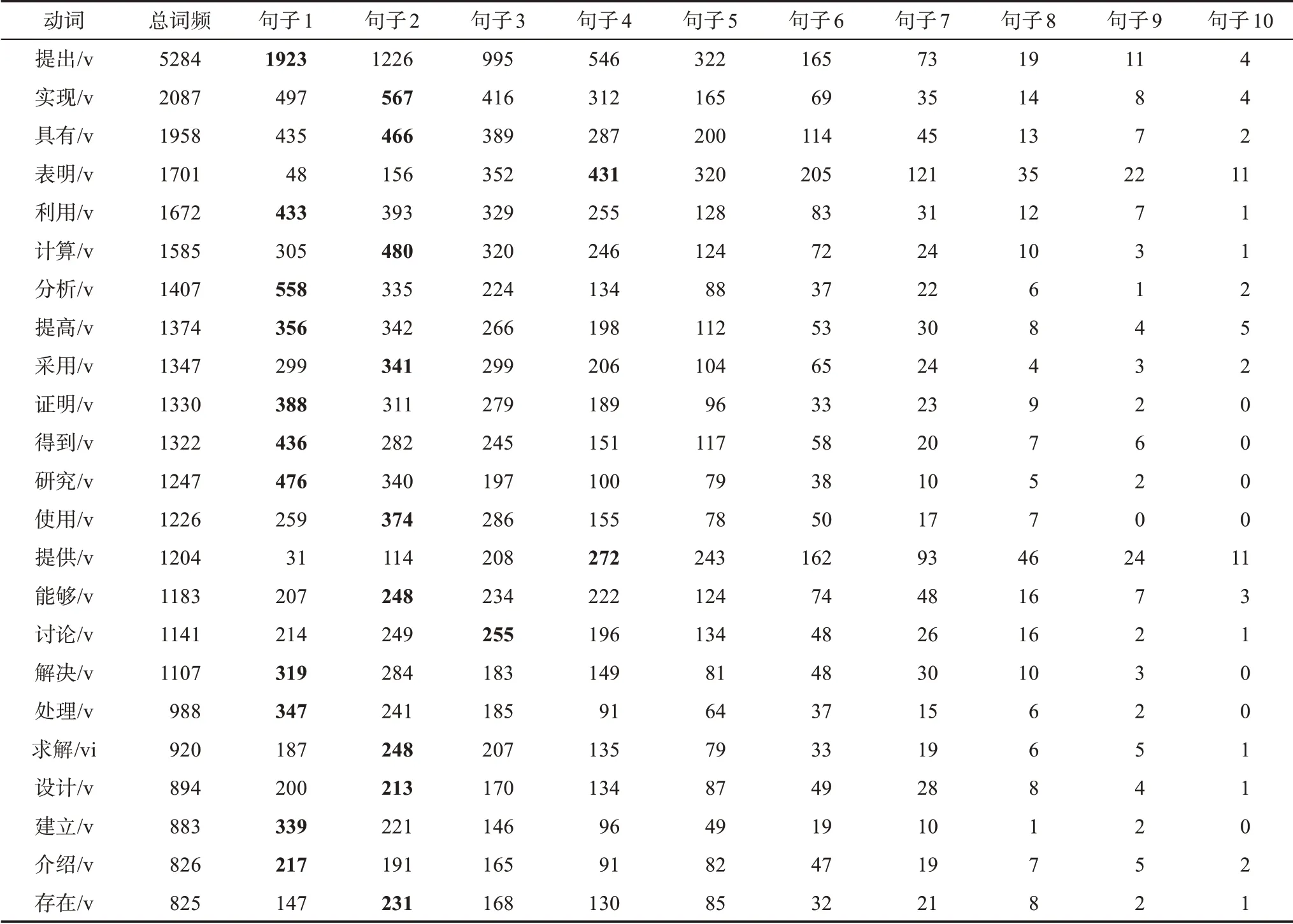
表2 高频动词的句子位置数量分布特征
从表3可以看出,高频动词在每个句子和其子句的分布上表现出明显的个性化分布特性。例如,“提出”在1个句子上出现的次数最高(1932次),在第1句的子句上出现次数分别是:1047、518、196、92、34、14、5、8、6、3。又如,“表明”在第4句上出现的次数最高(431次),在第4句的子句上出现的次数分别是:351、44、23、9、2、0、1、1、0、0。
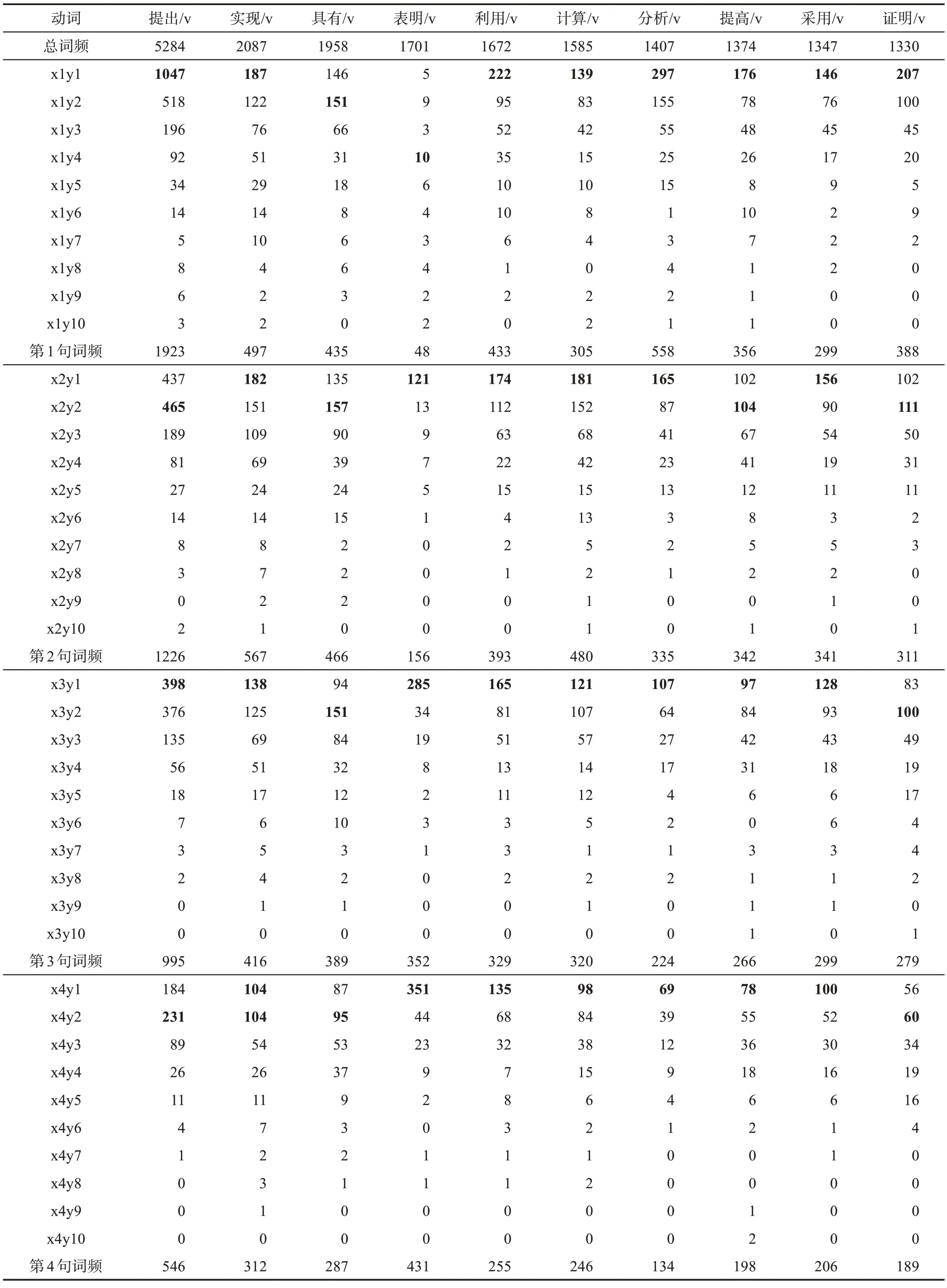
表3 高频动词在子句中的位置数量分布特征
本文利用表2和表3文摘中动词在句子和子句中的分布特性,可以为建立创新点的本体结构图的语义关系提供理论依据和技术方案。例如,通过问题类的动词{针对、存在},方法类的动词{提出,利用,采用},结果类的动词{表明,提高,得到,解决}。问题类的名词{问题,不足,热点,瓶颈,难题},方法类的名词{模型,定义,模式,性质,误差,算法,方法,理论},结果类的名词{策略,效率,优点,冗余度,指标,稳定性},建立文摘创新点的语义本体结构。
考虑了动词的位置分布特性后,本文对文摘的问题、方法、结果分类的准确率可达到78%,比未考虑动词位置的准确率提高了1倍。
研究结果表明,统计分析的挖掘方法操作起来比较简单,但从表1和表2可以看出,同一个词汇被标记成动词和名词,如“研究、分析、设计、应用、仿真、影响”,这不仅表现出目前的分词工具质量不高的问题,还在于缺乏对句子的谓语动词的语义识别,也是影响文摘创新点准确分类的本质问题。
4 文摘创新点谓语动词语义理解的认知分析
4.1 中文分词工具会扭曲句子的语义理解
目前,中文分词工具的准确性不高会造成中文句子语义理解的困难。本文采用了三种分词工具对《电子学报》文摘进行分词实验,下面给出一条文摘(8089号)的分词结果。选择这条文摘是因为这条文摘只有两句话,第一句话为一条独立的句号句的句子;第二句话是含有14个逗号句的句子。这类文摘在以后的分类中也会带来很多分类处理上的麻烦。表4~表6分别给出了三种分词工具对这条文摘部分内容的分词处理结果:表4为采用ICTCLAS分词工具的分词结果,表5为采用Stanford Parser分词工具的分词结果,表6为采用哈工大-SecureCRT.rar分词工具的分词结果。展示的(8089号)文摘部分内容带有6个逗号、分号和句号。比较几个分词工具可以看出,ICTCLAS分出20个动词,Stan‐ford Parser分出8个动词,哈工大-SecureCRT.rar分出18个动词。其中,哈工大-SecureCRT.rar依存树工具对这条两个句号的文摘句只给出了一个句子的谓语动词,另一句话没有识别出来。

表4 ICTCLAS分词处理后的文摘句

表5 Stanford Parser分词处理后的文摘句

表6 哈工大-SecureCRT.rar分词处理后的文摘句
通过表4~表6的分词结果可以看出,Stanford Parser分词工具分词的准确性相对较高,对逗号句也能给出谓语动词,但仍然有分错的地方。例如,在这一例子中,Stanford Parser分词处理结果中的“支持/VV,并行/VV,存在/VV,面临/VV”,这4个动词都不是谓语动词。在ICTCLAS分词处理结果中的“构/v,计算/v,构/v,编程/v,支持/v,应用/v,构/v,构/v,构/v,并行/v,优化/v,构/v,存在/v,面临/v,挑战/v”,这15个动词都不是句子的谓语动词。在哈工大-SecureCRT.rar分词处理结果中的“异v,计算v,发展v,支持v,应用v,发展v,并行v,编程v,优化v存在v,面临v,挑战v”,这12个词也不是句子的谓语动词。
目前,常用的分词工具虽然取得了很大的进展,但还存在一些问题:①准确率还需要进一步提高;②对名词等不起语法和语义作用的词进行了过细的划分。例如,“提出了一种能够解决现有问题的方法。”经过分词系统的划分之后,能够/解决/有/都被标定为动词,那么这些词就有可能被误判为这句话的谓词。然而,这句话的谓语应该是“提出了”。所以对名词再进行细分有时候是得不偿失的;③有些介词虽然不是句子的核心成分(谓语),但是却起到了引导特定类别句子、短语的引导词的作用。例如,“针对这个问题,提出了一种算法。”在这句话中,“针对”是个介词,当然也不是这句话的谓语,然而这个词却引出了问题句的短语,相应的该问题句应该被分离出来。所以综合这三个问题,现有的分词工具还不能被用于进行语义单元的提取。
因此,利用目前的分词工具进行分词和词性处理后的句子,仍然达不到机器语义理解的要求。
4.2 文摘句谓语动词语义识别与主谓宾结构转换
在对句法、语义关系这个语法学中心问题的研究上,中外许多语法学家和语法流派都十分强调动词是叙事句的中心。文献[7]认为,“从语义结构探讨句子的形式与意义的关系,有益于正确认识句子的表层结构(形式结构、结构模式)和深层结构(语义模式)之间的相互联系,加深理解句子形式与意义的关系。”文献[8]认为,“动词是句子的中心、核心、重心,别的成分都跟它挂钩,被它吸引。”文献[9]认为,“以动词谓语句而言,谓语动词是语义结构的核心(动核),而句中的名词性成分都是这一核心的种关系(动元)。”文献[10]认为,“动词跟受其支配的语义成分可以构成一个最小的语义结构。这些最小的语义结构,都具有一定的表述性,能表达一个相对完整的命题或意义,能投射成一个具有相对独立表述功能的意义自足的最小主谓句。”
更为重要的是,因为一个汉语句子可以有多个动词,每个逗号短语句都可包含有谓语成分的语义关系。文献[11]认为,“汉语多动词谓语句是汉语句子基本结构的一个重要特点。理解这类句子时,必须分析这些动词之间的语义联系,译成英语时,常常只将其中的一个动词译成英语谓语动词,而将其他动词转换成非谓语动词或其他形式。”文献[12]认为,“在确定一个句子和基本单元时,把句点显性标识的一个语言片段称为句子,以逗号分隔的语言片段称为小句,认为小句对应于句子关系的基本单元。”因此,本文认为对于科技文摘创新点句子的谓语动词分析,不仅仅是句子结构的分析,还要从最小的逗号句进行分析,所以识别句子的谓语动词,挖掘句子的主谓宾结构是文摘创新点句子理解的关键。由此汉语文本语言的语义识别的核心问题可以看作是寻找句子和逗号子句(或小句)准确的谓语动词的难题。
因此,本文提出了通过句子的谓语动词的识别来解决语义理解的认知分析方法结构,开发了一套《中文科技文摘句谓语动词识别与句子的主谓宾结构转换软件工具》,这个软件工具能够将中文科技文摘句很好的转换为机器理解所需要的语义关系结构,并且这种语义结构的句子在后续建立知识库和谓词的语义推理中将发挥重要作用。
为了建立高准确率的文摘句的谓语动词的语义识别率,为今后的谓词推理建立可靠的基础,本文研究了句子谓语动词的智能识别问题,先利用ICT‐CLAS分词工具对《电子学报》文摘句进行了分词;然后对分词后的文摘句进行谓语动词识别,并将句子的其他标记成分取掉,把句子改造成为主谓宾结构。表7给出用中文科技文摘句子谓语动词识别与主谓宾转换软件对文摘(8089号)处理的结果。

表7 句子谓语动词识别与主谓宾转换后的文摘句
由表7可以看出,文摘(8089号)为2个句号句子,14个逗号子句,共识别出16个谓语动词。每个由“逗号、分号、句号”组成的句子都包含有谓语动词,这些谓语动词准确的表达了句子的语义和语用关系,去掉了其他多余的词性标记会更能清晰的表达句子的语用功能,这对机器理解中文文本的语义和语用功能带来了更大的好处。
5 文摘创新点语用分类的认知分析
5.1 文摘语用功能的句子分类数量分布
按照文摘中句子所表达语用功能的特征,本文把文摘句子分为6种语用类型:第1类(问题句)、第2类(方法句)、第3类(结果句)、第4类(问题句、方法句)、第5类(方法句、结果句)、第6类(问题句、方法句、结果句)。先进行第一次6分类,然后将6分类中的第4、5、6类混合类进行二次单一类分类,最后与第一次分出的第1、2、3类句合并,完成三种语用功能的分类任务。
本次研究对象来自万方数据库提供的文摘,经过预处理后为8235条(32686个句号句),平均每条文摘3.48句,最长的一条文摘为13个句号句子。表8是本文对8235条文摘进行第一次6分类结果的统计数据。
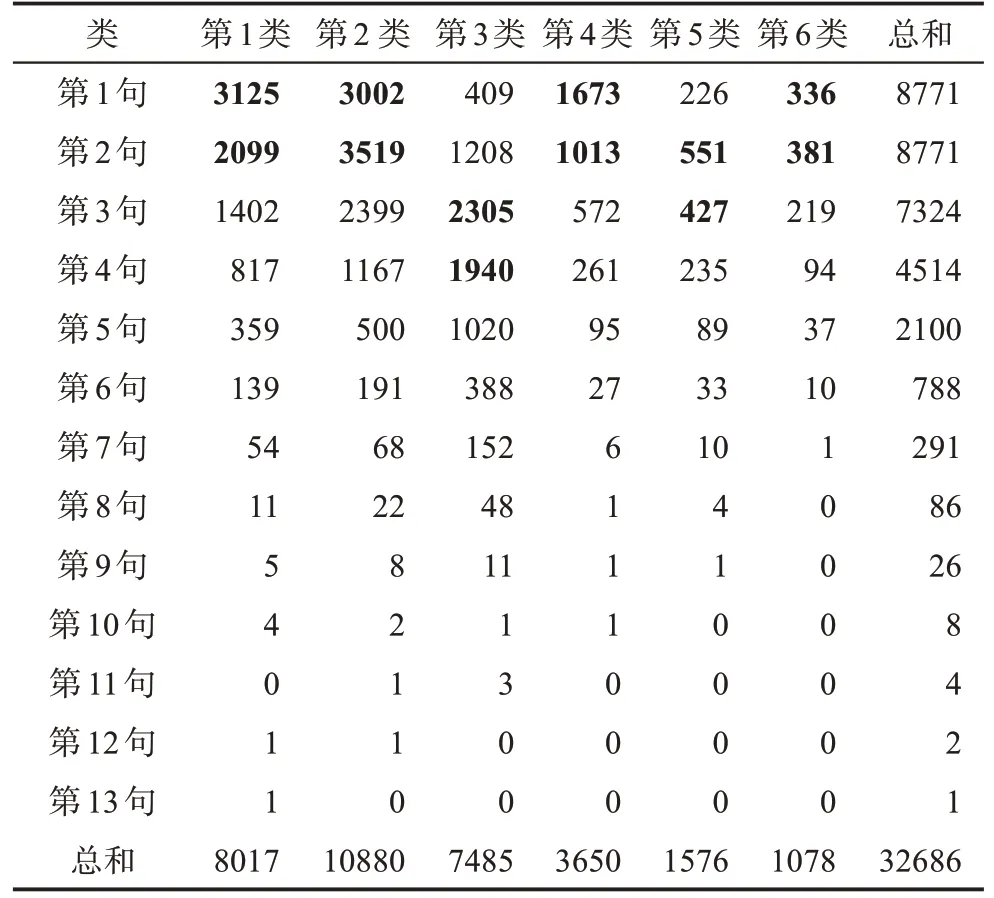
表8 语用功能的文摘句子6分类数量分布
我们把表8分为两部分,第一部分为可直接分类为第1、2、3类的单一类句子,这类句子表达的语用功能单一。第1、2、3类的句子数为26382,占总句子32686的81%。此外,从表8可以看出,第1类主要分布在第一句、第二句、第三句上,第2类主要分布在第二句、第一句、第三句上,第3类主要分布在第三句、第四句、第二句上。第二部分为第4、5、6类句子,这类句子的语用功能结构复杂、有多个语用关系,不能直接分为第1、2、3类。第4、5、6类句子数量为6304,占总句子32686的19%。第4、5、6类句子属于混合类句,需要进行二次分类。此外,第4类主要分布在第一句、第二句上,第5类分布在第二句、第三句上,第6类分布在第一句、第二句上。
5.2 二次分类与合并的数量分布
第4~6类句子的二次分类结果如表9所示。
由表9可以看出,“句子大序号”是本文对《电子学报》8235条文摘按逗号分句后建立的数据库顺序号;“文摘号”是数据库的文摘编号;“文摘内句子号”是对每条文摘中句子的编号,其中,1、2分别表示这条文摘的第1个句号句和第2个句号句,这条文摘只有2个句号句子;“原分类号”指的是经过第一次6分类后给出的分类结果,其中,6表示这个文摘的第2句被分为第6类;“新分类号”是经过二次分类后给出的分类号,文摘号为8098文摘的第2句话被第二次分类分成了1、2、3类,并分成了14个逗号句。
经过二次分类与一次分类的1、2、3类合并后,全部文摘分类的1、2、3总分类句的数量分布如表10所示。一次分类的句子(句号句)数量为32685,二次分类合并后的句子(逗号、分号、句号)为43999。
由表10可以看出《电子学报》文摘创新点的1、2、3类的分布有两个特点:①第1类占总句(包括逗号、分号、句号)的31.1%,第2类占总句的45%,第3类占总句的24%,说明了文摘表达第2类的句子数量比较多。②第1类主要分布在第1、2、3、4句,第2类分布在2、1、3、4句,第3类主要分布在第3、2、4、5、1句。
通过人工抽查验证,本文提出的按照文摘句的语用功能进行6分类,再二次分类方法操作简单,且取得的分类准确率较高。经过人工对300条文摘检验,准确率高到达96%以上。
6 文摘创新点隐含句法模型的认知分析
6.1 文摘中第1类数量缺少问题
参与实际分类的《电子学报》文摘数为8235条,经过二次分类合并后每条文摘同时含有第1、2、3类的文摘数量为6505条,占84%;同时,含有第1、2、3类的句子数为37399句(包括逗号,分号,句号),占85%。如表11所示。

表9 二次分类(新分类)与一次分类的对比举例
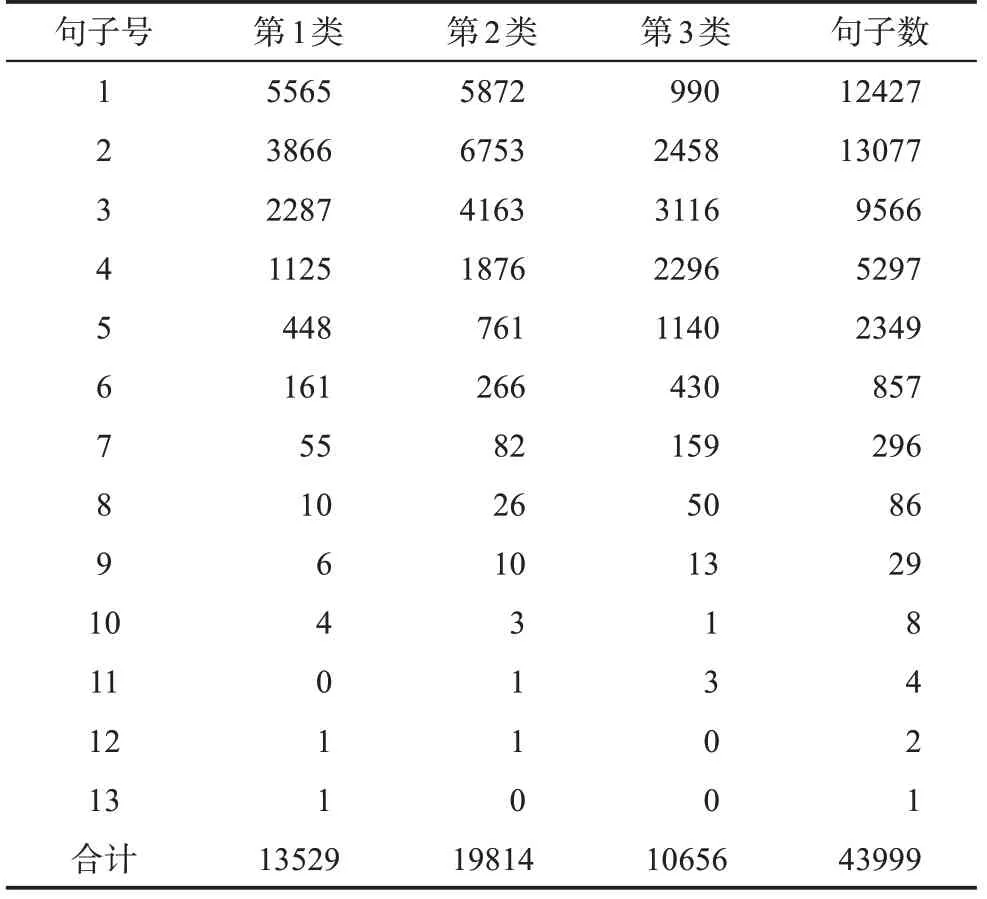
表10 全部文摘的1、2、3类句数量分布
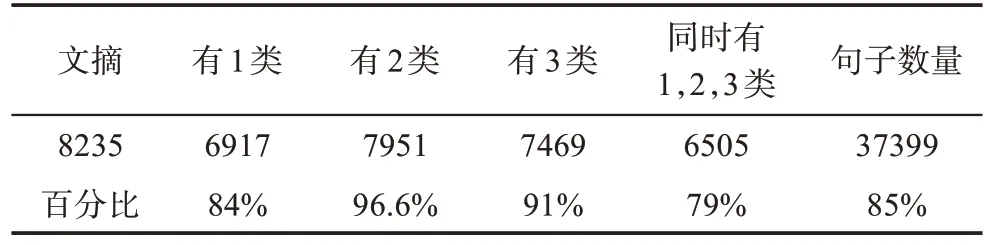
表11 同时含有第1、2、3类的文摘数量
由表11可以看出,①第1类占总文摘的84%,第2类占总文摘的96.6%,第3类占总文摘的91%。②每篇文摘中同时都含有第1、2、3类的文摘只到达到84%。因此,寻找第1类句子缺失的问题就变成为文摘写作语言模式的深度认知分析方法的任务。
6.2 文摘中隐含结构的特征分析
经过大量统计分析发现《电子学报》文摘不直接给出表达问题句和结果句的概率很高。这一特点表现在《电子学报》文摘的第一句为第2类的文摘达到25615条,占总文摘8235条的31.1%,而且此类文摘没有直接的显性问题句,这是《电子学报》文摘的特点,也是提取问题句的难点。为了方便研究,本文把这类文摘句称为“问题隐含特殊句”。经过二次分类合并后《电子学报》文摘的这种“问题隐含特殊句”有1571条,占总文摘数8235的19.0%。
“问题隐含特殊句”的举例:本文/r提出了/V一种在相控阵雷达回波数据序列中用高斯混合体模型(GMM)检测与跟踪运动目标的在线算法/n。
为此,本文从语言学的角度对这类文摘句进行语法结构分析。语言学文献[13]指出,“谓词特别是谓语动词是整个句子的中心,与谓语动词左侧最近的名词短语邻居即为主语,与名词左侧最近的形容词或形容词性短语邻居即为定语,与动词左侧最近的副词或副词短语邻居为状语,与动词右侧最近的副词短语、介宾短语、动词短语、孤立形容词邻居(不修饰名词)为补语,除此之外的名词或名词短语为宾语。”对于宾语来说,在很多情况下,宾语的核心词并没有包含太多的信息,而宾语前的定语却包含了很多信息。因此就会出现,“问题隐含特殊句”这种情况,即“问题隐含特殊句”是由宾语前的定语包含了要解决的问题的信息的句子。例如,将一个文摘的例句表达成下面的结构:
{[主语]本文/r}||{[谓语]提出了/V}||{[定语]一种在相控阵雷达回波数据序列中用高斯混合体模型(GMM)检测/v与跟踪/v运动目标的}||{[宾语]在线算法/n}。
在上述的例子中,“一种在相控阵雷达回波数据序列中用高斯混合体模型(GMM)检测与跟踪运动目标的”是“在线算法”的定语。在这个定语中,指明了直接宾语“在线算法”的适用范围、前提条件和适用目的。也就表明了“在线算法”所要解决的问题。因此,把这类“问题隐含特殊句”的写作方式可归纳为如表12所示的模板。

表12“问题隐含特殊句”的句法结构
按照表12处理“问题隐含特殊句”的模板结构,本文对“问题隐含特殊句”进行模式识别,并把定语中的“在XXXXXX中”和“处理对象ZZZZZZ”等抽取出来,为该文摘补充两条第1类短语。这样上述举例文摘的第1类可以补充为:在相控阵雷达回波数据序列中,运动目标的检测与跟踪。
通过对“问题隐含特殊句”的处理,使得总文摘的第1类的数量由84%提高到92%,第1、2、3类全有的文摘数量由80%提高到89%,有效的解决了由于科技文摘写作语言表述的丰富性带来的分类和挖掘的困难,大大提高了科技文摘创新点的准确分类和有效挖掘的目标。为建立“问题(p)”“方法(M)”“结果(R)”三元组知识库的问答服务系统提供了知识挖掘的理论和方法。
通过对本文提出的学术文摘创新点挖掘的5个认知分析方法的实验,验证了这5个认知分析方法在文本挖掘过程中具有明显的阶段性和递增性现实特点,其是实现科技文摘创新点挖掘需要考虑的5个认知分析方法。经过5个阶段的实验,验证了科技文摘中的创新点具有一定的事实性和动词分布的一致性,谓语动词的语义对语用分类的理解具有重要的决定性作用,科技文摘为了突出其创新点的表达,常常会采用复杂的句子和隐含的表达方式。下面将几个认知阶段的研究结果汇总在一起,如图3和图4所示。
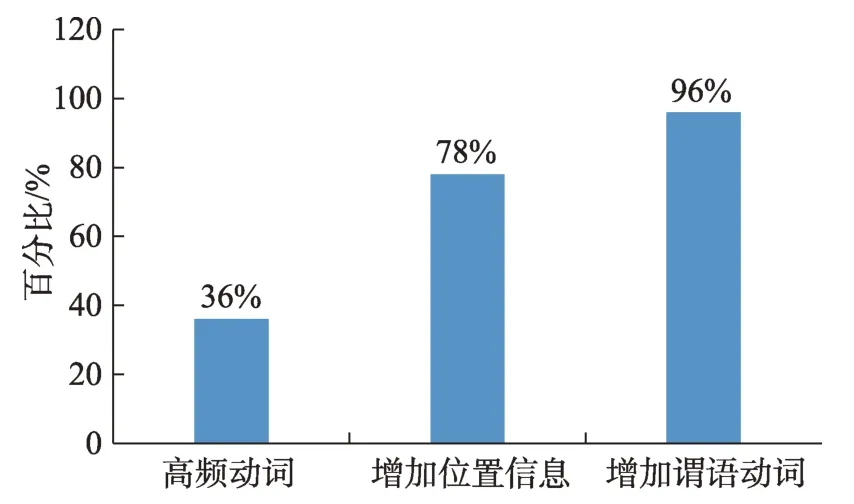
图3 识别率改善的几个阶段
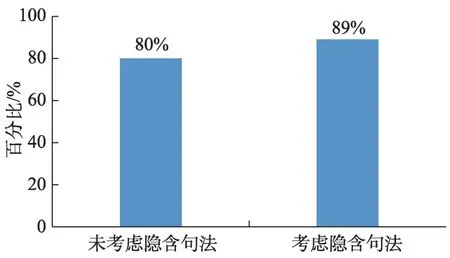
图4 考虑隐含句法的第1、2、3类全有的文摘数量
7 结束语
科技文摘最初设置的目的不仅是为了快速检索,其有标题和关键词的检索功能,更重要的是表达文章创新点的核心功能。经过上百年来的发展,科技文摘的核心功能并没有变,但承载科技文摘的介质从纸质形式上升到了数字化形式,数字化的形式使得人们对科技文摘的利用方式已不再只是人工阅读的方式了,借助计算机技术和人工智能技术可能使科技文摘成为智能化的问答方式为人们服务。但是科技文摘创新点内容的表现方式不是结构化数据,而是人类使用的自然语言形式。目前的计算机技术和人工智能技术使用的是机器语言形式,自然语言形式和机器语言形式不能直接交流,需要将人类自然语言形式通过智能的模式转换为机器可以理解的模式。本文对科技文摘的创新点做了认知分析方法的研究,从创新点的报道功能、词汇语义分布的一致性、谓语动词的语义理解性、语用功能的分类性和句法模型的隐含性五个方面进行了深入研究,期望能够为机器处理自然语言的研究提供智能认帮助,对基于创新点知识库建设和智能问答系统建立提供理论和方法的认知分析方法。后续的工作将建立创新点知识库,进一步研究智能问答系统的推理技术,探索文摘创新点的智能化服务。
