融合知识特征与协同属性的创新用户群发现研究
2021-06-14唐洪婷李志宏张沙清
唐洪婷,李志宏,张沙清,3
(1.广东工业大学,广州 510520;2.华南理工大学,广州 510641;3.惠州市广工大物联网协同创新研究院有限公司,惠州 516025)
1 引 言
随着用户参与创新(user-engaged innovation)在产品创新流程中占据越来越重要的作用[1],众多企业都设立了自己的开放创新社区,以吸纳用户智慧、谋取创新灵感。研究表明,这种企业创新社区的设立对企业的产品创新、口碑传播、品牌建设和市场营销等活动均具有显著的正向促进作用[2]。其中,用户作为企业创新社区的关键组成部分,是社区生存的保证和价值的体现。聚集在社区中的用户既是创意的传播者,更是创意的生成者。对社区用户进行合理的组织和利用,一方面,有利于提升用户的归属感和参与度,保持社区活力;另一方面,也可以促进用户内容生成,保证社区的创意输出。
然而,企业创新社区中的用户作为独立个体参与社区知识活动,其对产品的改进需求和创新痛点的看法常常局限于某个角度,用户之间的知识碰撞与交互合作也存在较大的随机性。已有文献在开展用户识别研究时,往往聚焦于独立用户以及其个体属性[3]。研究表明,用户在协作过程中的交互与讨论能促进观点的碰撞,通过品鉴和吸收他人的经验,可以激发用户产生更具创意的想法[4]。因此,本文提出根据用户的活动轨迹对社区中的用户进行组群发现,为用户协同提高决策参考,激发群体智慧的涌现。
已有文献对用户的知识特征与行为属性进行了一系列探索。为了最大化用户群的协同效应,对企业创新社区这一知识密集型社区而言,创新用户群的发现研究存在以下四个问题:其一,知识度量的局限性,即在知识度量时,常常利用知识存量等统计指标来表征知识特征[5],未对用户的具体知识属性进行深入探索;其二,用户属性考量的局限性,即在研究中聚焦于考查用户个体的知识属性[6],忽略了对用户意愿及用户间的协同属性进行考量;其三,没有考虑用户行为的时变特征,企业创新社区是基于互联网的用户交互系统,用户流动及知识更替[7]适势发生,进而干扰协同效果;其四,缺乏合理的用户知识组织框架和量化工具,即面对企业创新社区中庞大的用户群和海量的知识集,如何整合异质要素并实现用户属性量化,也是课题研究中需要面临的一大挑战。
基于上述问题,本文提出在创新用户群发现研究中,针对具体知识创新需求,利用超网络这一表达与分析工具,充分考察动态情景下用户的具体知识组成(知识质量及创新潜力)与参与动机,并兼顾用户间的协同潜力(知识互补性与知识协作能力),从而发现企业创新社区中的最具知识潜能与协同潜能的创新用户群。本文对超网络方法、用户识别体系和知识量化方法的完善与融合具有重要的推动意义。同时,本文的研究成果对用户组织、协同创新等社区运营实践具有较好的指导意义。
2 相关研究介绍
2.1 企业创新社区
随着互联网社区的日益成熟,学者们对企业创新社区的相关特征的认识已然定型,具体包括:由企业出资设立并主导、由产品用户及潜在用户参与、社区中的主要活动为经验分享和信息交互[8]。企业创新社区作为以商业创新为导向的虚拟社区,其创造价值的定位与能力一直都是学者们热切关注的对象。研究表明,成功的企业创新社区在产品创新、口碑营销、品牌建设和市场营销等活动中均具有良好的表现[2]。其中,辅助产品创新作为社区设立的主要目的,其表现尤为亮眼[9]。不少社区实践也佐证了这一点,如星巴克在经营惨淡的瓶颈期,及时推出MyStarbucksIdea用户交互平台,通过“聆听”用户需求,最终实现革新、成功破局;小米借助MIUI社区与用户“保持通话”,利用用户反馈持续改进产品,使其保有日益庞大且活跃的用户群。
鉴于企业创新社区中用户参与创新表现出的巨大潜力,许多学者针对社区中的用户及其知识等要素进行了多方探索,以期获取用户及其生成内容的关键特征,为创新实践提供决策参考。例如,相关文献对用户角色进行了识别与分析,如领先用户、领域专家和意见领袖等[10-11]。然而,上述研究在衡量用户的知识情况时,局限于简单的统计指标及网络分析,并没有对知识内容进行深度度量。同时,上述研究主要专注于利用抽离式思维获取用户特征,没有对用户及其知识间的碰撞的可能性进行研究。即便有部分文献提出对社区中的社群进行挖掘,但相关研究更多的聚焦于同质性高活用户的发现[12]。为此,本文系统地考虑用户的知识特征及用户间协同属性,以发现满足协同创新任务需求的用户群。
2.2 用户特征
企业创新社区中,用户基于自身的观点、需求及偏好生成相应的活动轨迹。对这些活动轨迹进行挖掘与梳理,有助于企业制定科学的用户管理策略,进一步促进用户智慧的聚集与生产。目前,已有研究对用户活动轨迹的挖掘可概括为5种用户特征:①网络位置;②活动特征;③内容特征;④情感;⑤邻接点得分[13-15]。其具体度量指标如表1所示。由表1可知,已有研究将用户在社区中的活动轨迹刻画得相对完整。但是,从用户创新理论[16]及协同创新理论[17]的视角来看,上述指标尚未针对用户参与协同创新的关键特征进行考察。
首先,基于用户创新理论,用户有效参与创新的关键特征在于:①对产品功能的需求处于市场趋势前沿;②有强烈的动机去寻找满足新兴需求的解决方案[18]。结合本文的企业创新社区实践,为了取得可观的协同创新成效,用户必须具备足够的产品知识和经验,以及参与创新的积极意愿。因此,在上述特征度量的基础上,本文提出对用户的具体知识特征(知识质量与知识结构)及参与动机特征进行度量。
其次,协同创新理论强调个体协作以实现“1+1>2”。在企业创新社区中,彼此独立的用户通过线上交互创造和获取价值[19],实现协作。与传统意义上的协作不同,这些用户不一定彼此了解,而是“隐式”地“碰撞”以产生高质量的创意[20]。然而,并非所有的“碰撞”都有意义,低效的交互不仅不利于创意的产生,还会引起用户反感,甚至离开社区。因此,如何根据已有的用户活动轨迹评价用户间的协同可能性是本文要解决的问题。
2.3 超网络
超网络作为一种由多类型节点与关系构成的复杂网络,为复杂系统的表达与分析提供了十分便利的工具。因此,超网络在通信、交通、物流等诸多领域得到了广泛的推广和应用[21]。随着线上平台的发展和知识管理研究的推进,超网络作为知识网络的延伸,开始应用在知识管理领域[22]。
近年来,超网络的相关研究主要包括:①用户识别与分析。即通过对社区中的主要要素进行系统建模,发现其中的关键用户[23]。如田儒雅等[24]通过构建包括社交子网、环境子网、心理子网和观点子网的舆论超网络,利用测度指标对舆论领袖进行了识别与分析。②知识研究。即利用超网络对社区中的知识及知识载体进行系统建模,借助可视化分析发现知识特征。如迟钰雪等[25]通过构建基于超网络的线上线下舆情演化模型及其仿真框架,探索了同步率及速度对舆情演化的影响。由此可见,上述研究充分体现了超网络表达及处理复杂关系的能力,也为本文利用超网络进行用户及其知识的表达及测度提供了依据。
本文拟利用超网络的拓扑结构特性捕捉企业创新社区中用户的知识特点、关联、结构及其变化,对用户的知识特征、用户间的协同属性等多种复杂异构关系进行探索,以发现具备知识能力与协作潜质的创新用户群。

表1 在线社区用户属性及其度量指标
3 融合知识特征与协同属性的创新用户群发现方法
3.1 用户知识超网络模型
为了给后续的用户知识特征及协同属性挖掘提供工具与素材,本文参考已有文献,将企业创新社区中的异质要素集成建模为用户知识超网络模型[26]。其中,节点包括用户、帖子和知识点。同时,鉴于原有用户知识超网络模型将超边直接表达为不同节点之间连线,容易丢失“用户-帖子-知识点”间的对应关系等关键信息。因此,本文将三种不同节点之间的相互联系(社区中用户的主要知识行为)用超边予以表达,构成发帖超边与评论超边[27]。相应的用户知识超网络可以表达为如图1所示,图1a为企业创新社区中的节点关系,图1b为构建的用户知识超网络的示意图。
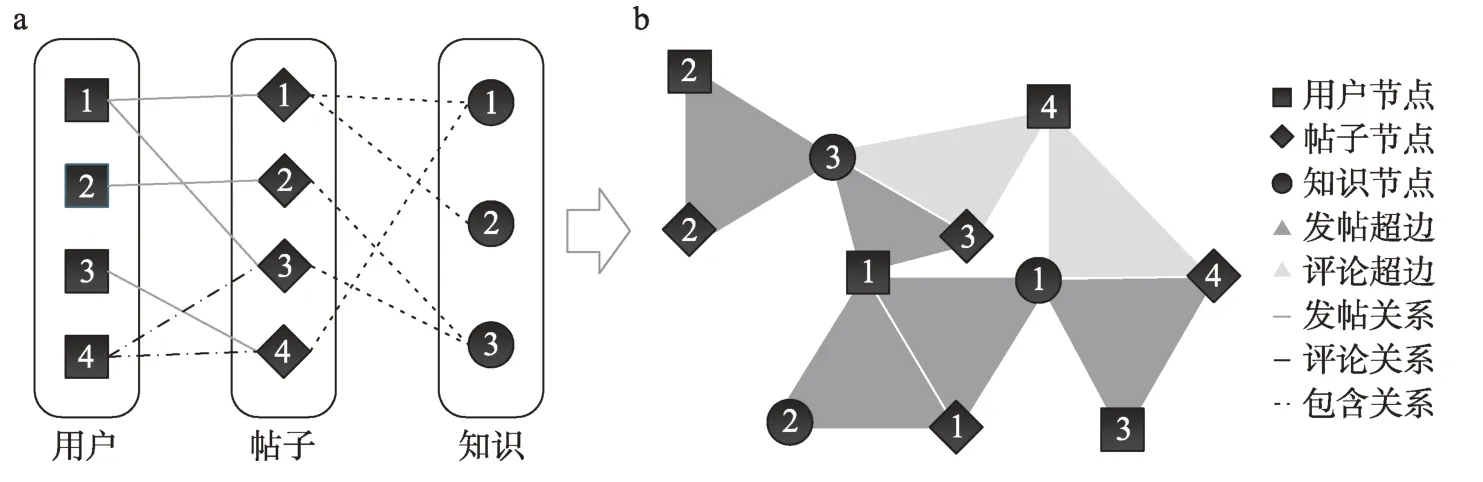
图1 用户知识超网络
为了捕捉社区中用户行为的时变特征,本文将时间维度纳入了用户属性考量。据此,本文构建新的用户知识超网络模型(user knowledge super-net‐work model,UKSNM,)及其具体组成(表2):
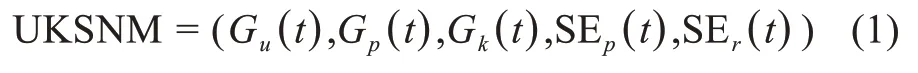
其中,t∈T表示时间;用户Gu(t)、帖子Gp(t)和知识Gk(t)节点在模型中通过数学符号唯一标识,使其权重在不同时段内彼此各异;发帖超边SEp(t)与评论超边SEr(t)均由三种不同的节点组成,其权重均为帖子p j隶属于知识kz的概率θjz。

表2 用户知识超网络模型的要素组成
在已有文献的超网络构成中,知识节点kz常常由关键词表示。本文为了从语义层面度量用户的知识特征,将知识节点kz∈K表示为用户生成内容的知识主题,如图2所示,利用LDA(latent Dirichlet allocation)主题模型[28],通过概率生成过程,生成S个知识主题,并确定每个帖子p j隶属于不同知识主题的概率θj,以及每个知识主题kz的关键词的概率组成φz。
通过将社区中的关键要素进行集成表达,本文构建的用户知识超网络模型可为后续的要素分析提供科学的工具,有效避免了用户特征挖掘时指标映射困难、要素联动迟钝的现象。
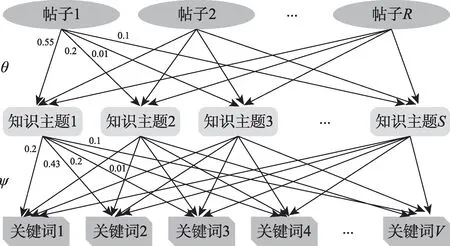
图2 LDA主题模型的生成逻辑与结果
3.2 用户特征分析
在第2节的分析中,本文基于用户创新理论提出用户有效参与创新在于是否具备:①超前需求;②创新动机。因此,下文是对用户的知识质量、知识结构以及参与动机进行考量。
3.2.1 知识质量评价
为了评价文本的知识质量,Dong[29]结合知识的多维特征设计了情景知识质量、可操作知识质量和内在知识质量三个评价维度。Valaei等[30]在此基础上加入可访问知识质量并构建了一套四维指标体系。然而,这些评价大多数基于问卷的方式进行,其量化路径不适用于数据科学研究。本文综合考虑企业创新社区的知识特征与协同创新需求,提出从情景知识质量、内在知识质量和可访问知识质量三个方面考察用户的知识情况,即用户应当具有与协同任务相关、准确且足够的知识存量。
3.2.2 知识结构评价
在企业的产品创新实践中,知识创新任务包括两种:设计型任务与技术型任务[31]。前者是指存在大量潜在解决方案的非结构化任务,这需要参与者具有更为广泛的知识面以产生跨领域创新;后者是指具有明确操作流程的结构化任务,其需要参与者拥有相关领域下深入的专业知识以完成常规性挑战。本文利用知识广度和知识深度来评价用户的知识结构,以应对不同知识创新任务的需要。
3.2.3 参与动机评价
基于自我决定理论,用户的参与动机可以分为:内在动机、外在动机和内化的外在动机[32]。在社区研究中,考虑到数据量化需求,学者们聚焦于量化内化的外在动机。内化的外在动机是行为外部的结果,但用户可以将其内化,常常表现为社区中设置的积分及其他互动机制。在理论研究中,这些机制被学者概化为:互惠、自我形象和声誉。其中,互惠是用户参与社区活动的重要决定因素,其表示收到帮助的用户更愿意参与合作[33];自我形象描述用户在社区中的自我感知,这种感知能积极推动用户参与[34];声誉表示用户从外界获取的反馈,其对用户的知识参与行为具有较低的预测能力[35]。因此,这里对社区中的互惠和自我形象机制进行考虑。
在协同创新任务中,除了用户的知识特征与参与动机,用户之间的配合情况也会影响到最终的协同效果。基于协同创新理论,协同创新是一个“沟通-协调-合作-协同”的过程,包括各种知识资源的交互[17]。因此,对用户间的知识互补情况及协作潜力等协同属性进行考察十分必要。
3.2.4 知识互补性评价
在一般知识创新任务中,研究者常常选择具有最多知识储备的用户。但在协同创新任务中,盲目追求知识存量最大化不利于创新工作的开展。若创新用户群的知识过于相似,则知识的重叠将阻碍用户间的思维碰撞,难以产生创新成果;若创新用户群的知识差异过大,则将会增加用户协商成本,甚至阻碍用户间的知识沟通。因此,合理的知识互补特征十分重要。
3.2.5 知识协作能力评价
研究表明,人们在建立协作关系时,更倾向于选择历史合作伙伴[36]。而在企业创新社区中,用户间的协作主要表现为评论行为。这种行为既反映了用户的知识兴趣,又反映出用户间的知识交互能力。因此,本文通过用户间的共同兴趣程度与知识交互能力来度量用户的知识协作能力。
创新用户群发现研究的属性特征可总结为如表3所示,其具体衡量指标将在下文中予以说明。
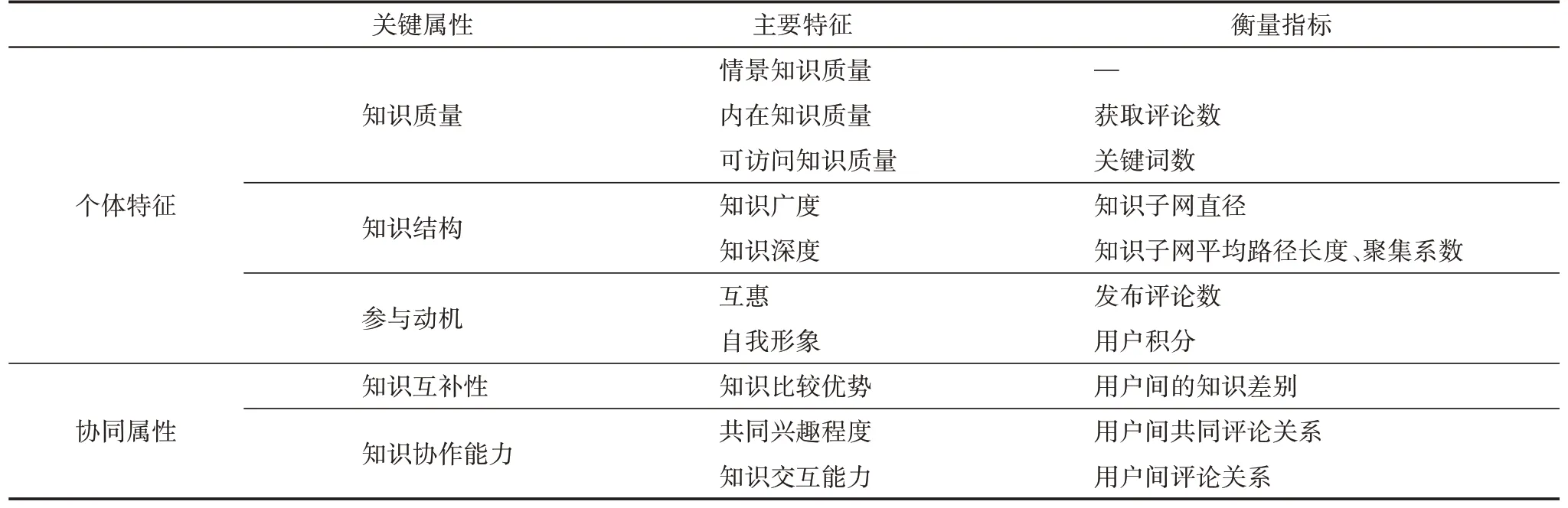
表3 协同创新用户群发现的关键属性特征
3.3 用户的个体特征评价
3.3.1 知识质量
协同创新任务的知识需求与用户的知识储备的匹配程度是决定协同成效的关键因素。本文将用户生成内容的知识主题作为具体知识领域。为了捕捉情景知识质量特征,帖子p j与知识领域kz的匹配程度可以表示为

除了知识间的匹配程度,用户知识的内在质量作为知识质量的基础,是为创新活动提供信息的根本源泉。为了量化内在知识质量,本文参考Matei等[37]的研究,利用第三方评估指标(即评论数)表示用户ui的内在知识质量。其中,帖子的评论数为
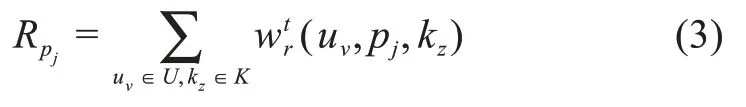
那么,结合具体知识领域kz,用户ui在时间t的内在知识质量可表达为
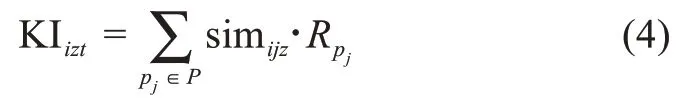
此外,研究表明,用户生成内容的增加,能够提高创意生成的概率[38]。因此,考察用户生成内容的体量(即可访问知识质量)十分重要。针对企业创新社区的数据特征,本文拟利用用户发帖内容的知识存量,即有效词组数予以衡量。那么,在时间t内用户ui在知识领域kz的可访问知识质量表达式为
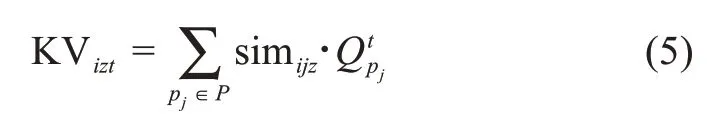
根据衰退理论[39],在决策实践中,用户行为的参考价值会随着时间流逝而减小。本文在衡量用户知识质量时,引入知识衰退系数D,并用知识衰退率e-t/D表征其时间价值变化。基于上述评述,用户ui在相应情景下的知识质量可以表示为
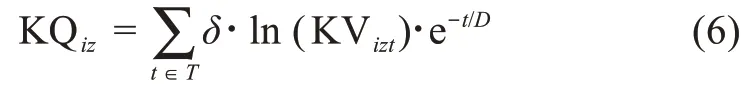
其中,δ=ln(KIizt)表示价值系数。
为了保证用户的知识质量在区间[0,1]内,将其进行归一化处理:
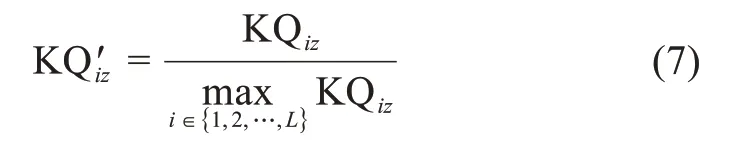
3.3.2 知识结构
针对知识结构(知识广度与知识深度)评估,目前最具代表性的指标包括知识多样性、Herfindahl指数等[40]。然而,这些指标大多为专利等线下知识的评估而设立。针对线上知识,本文借鉴巩军等[41]的研究,利用知识网络的拓扑特征进行结构评价。具体来说,本文利用知识点之间的相似关系构建用户知识子网(相似度计算利用图2所示的φ矩阵,即各个知识主题的关键词概率分布向量,并取相似阈值为0.01)。进而,本文利用直径刻画用户的知识广度,利用节点的平均路径长度和度中心性评估用户的知识深度。其中,直径描述了网络中任意两点的最远距离;平均路径长度和度中心性表征某节点与周边节点的紧密程度。那么,用户ui的知识广度可以表示为
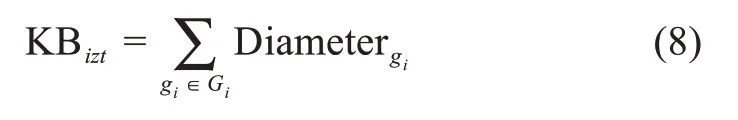
其中,gi为知识子网Gi的连通图。
知识深度可以表示为

用户ui在时间t的知识结构水平可以表达为
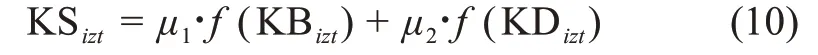
其中,μa为调节参数,且在评价用户的知识结构时,本文根据创新任务的实际特征(设计或技术型任务)给定不同的参数比例。同时,为了统一知识广度与知识深度的量级,f(x)表示对x进行归一化处理。
考虑知识的时间衰退特征,用户ui的知识结构水平可以表达为
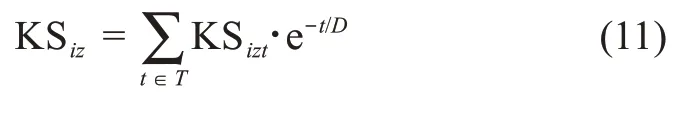
3.3.3 参与动机
本文利用互惠规范和自我形象来评价用户的参与动机。首先,在企业创新社区中,若用户获取了其他用户的知识,那么其更愿意在社区中参与知识贡献,本文通过用户的评论行为表征其知识获取事实,其计算公式为
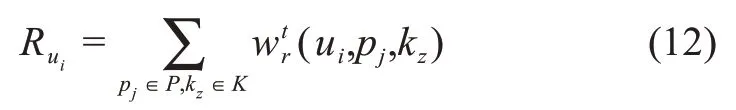
其次,社区中用户参与行为的奖励信号机制主要是积分,本文用积分值表征用户的自我形象描绘,那么用户ui在时间t的参与动机可以量化为
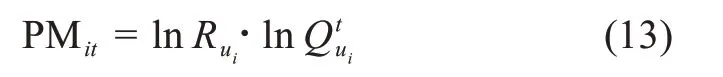
考虑知识的时间衰退特征,用户ui的参与动机可以表达为
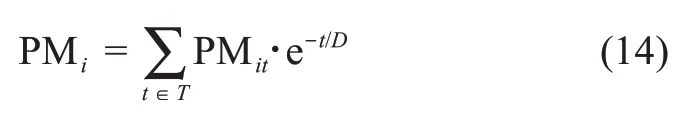
3.4 用户的协同属性评价
3.4.1 知识互补性
为了最大限度地激发用户间的协同潜能,本文对协同用户之间的知识情况进行对比考察。本文参考苏加福[42]研究结果,首先,衡量用户ui与用户uj在时间t的知识比较优势:
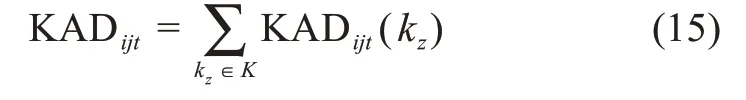
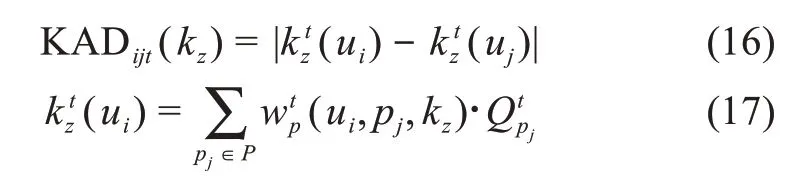
其中,KADijt(kz)为知识主题kz下用户ui与用户uj在时间t的知识比较优势;k tz(ui)为用户ui在相应知识领域下的知识存量。
用户ui与用户uj的知识互补性可以表达为
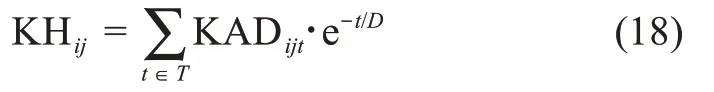
3.4.2 知识协作能力
目前,对用户知识协作能力的评价方法主要有指标法和社会网络分析。本文主要利用上述方法对用户的共同兴趣程度与知识交互能力进行评价。首先,参考学者Newman[43]的研究成果,利用回帖共现情况度量用户间的共同兴趣程度,即用户ui与用户uj在时间t的共同兴趣程度可以表示为
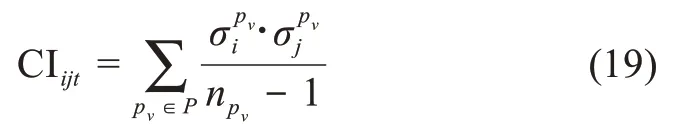
同样地,可获得排除时间因素影响的用户共同兴趣程度为:
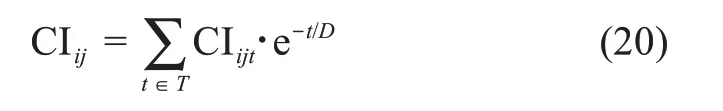
为了将用户间的共同兴趣程度落在区间[0,1]内,进行归一化处理:
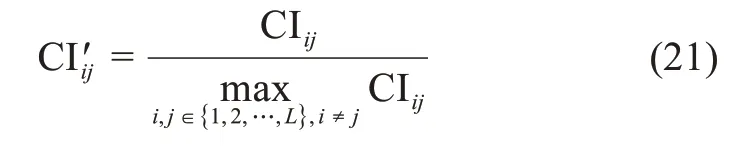
针对用户间的知识交互能力,本文通过用户对之间的交互情况予以评价。知识交互能力既体现为用户生成内容能够引起他人共鸣,又体现为用户能够对其他人的贡献内容进行反馈。本文将用户间的知识交互能力表示为

综上,结合用户间的共同兴趣程度与知识交互能力,用户间的知识协作水平可以定义为

3.5 创新用户群的发现
为了发现企业创新社区中的协同用户群,本文综合考量用户的知识特征及用户间的协同属性。具体包括:用户的知识质量、知识结构、参与动机、用户间的知识互补性和知识协作能力。为了简化问题,本文提出对用户群的知识质量与知识协作能力进行最优化求解,并将待选用户的知识结构水平、参与动机及用户间的知识互补程度控制在有效区间内,即

针对满足上述特征区间的用户,聚焦用户的知识质量与用户间的知识协作能力,构建协同用户群发现的多目标决策模型:
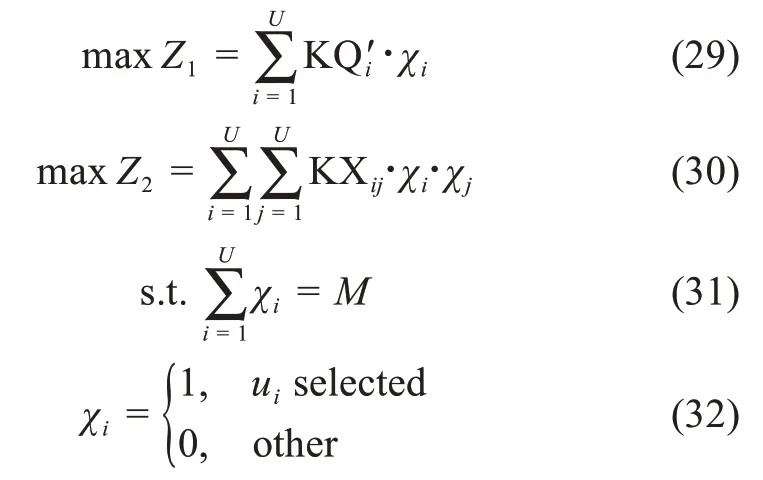
其中,公式(29)和公式(30)为优化目标,即选择用户的知识质量总和最高、用户间的协作能力最佳。公式(31)和公式(32)为约束条件,表示从待选用户集合中选择M个用户作为协同创新任务的成员。值得注意的是,本文结合企业创新社区知识协同任务的具体需求构建了相应的用户属性特征及求解模型。在其他知识系统中,本文可以根据实际需求调整目标函数及约束条件,构建适用于特定情景的协同创新用户群发现模型。
上述多目标决策模型显然是一个0-1整数规划问题,为了解决这一问题,这里利用遗传算法进行求解(其流程如图3所示)。具体来说,本文利用理想点法将两个目标函数进行总体评价,使各个目标尽可能接近“理想值”。那么,其适应度函数可以表达为
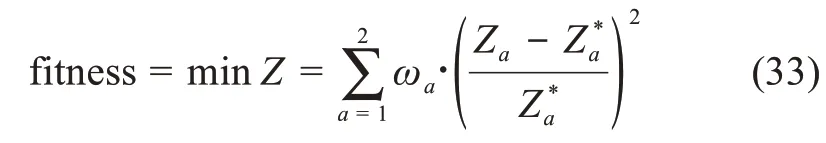
其中,Z*a表示为第a个目标函数的理想值,即相应单目标函数的最优值;Za为第a个目标函数的当前值;ωa为调节参数,且有
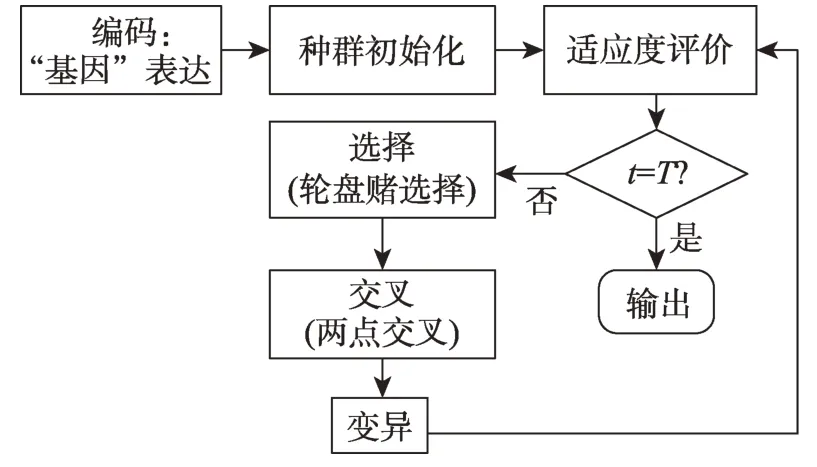
图3 遗传算法求解流程
在此基础上,本文对用户进行“基因”表达,并通过选择、交叉和突变,实现多目标问题求解。由于遗传算法的应用不是本文的创新内容,故这里不予赘述。Goldberg等[44]对遗传算法的遗传搜索机制进行了全面的介绍,读者可以参阅。
4 实例分析
4.1 数据介绍
为了验证本文的有效性与可行性,本文选取了国内典型的企业创新社区——MIUI社区(现已更新至小米社区)中的用户数据进行了实例分析。MIUI社区是小米科技为其产品MIUI系统设立的用户交互平台,并以此将用户内化到小米的产品创新流程中。本文选取MIUI社区中最具创新代表的“新功能建议”板块中的数据进行研究,具体采集字段信息与相关统计信息如表4和表5所示。

表4 实例数据的字段信息
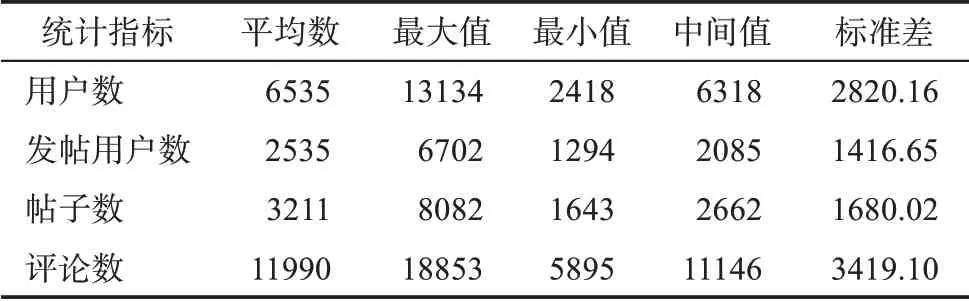
表5 实例数据的统计信息(按月统计)
4.2 超网络模型的构建及用户特征统计
基于上述数据,本文利用LDA主题算法识别社区中存在的知识主题,其具体参数设置为:α=0.1,β=0.01。结合困惑度[45]的变化情况,将主题数设定为60,最终构建用户知识超网络模型。
为了评价用户的不同属性特征,首先,本文确定目标知识领域。通过统计不同知识主题的用户关注度,这里选取用户关注度较高、且当前热门的知识主题K31(即“小爱同学语音助手”,用户关注度为4630)作为目标知识领域。该领域下,发表过相关帖子的有效用户共2196位。其次,在知识结构评价部分,本文暂不考虑知识创新任务的具体属性,将知识广度与知识深度的比重设定为0.5∶0.5。而在知识协作能力部分,本文将共同兴趣程度与知识互动能力的重要性等同,并将其比重设定为0.5∶0.5。此外,参考已有文献,本文将用户行为的时间衰退系数设置为1。相关用户的属性特征的统计信息如表6所示。
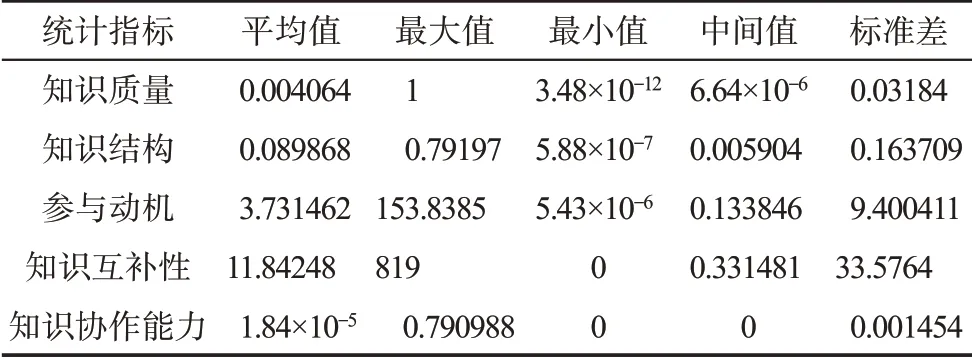
表6 相关用户的协同创新属性的统计信息
4.3 创新用户群的发现与分析
为了切实描述用户属性和用户间属性的变化情况,并且确定用户知识结构等指标的取值范围,在图4中展示出了相应的指标分布情况(降序排列),各指标值均呈长尾分布,这与已有研究结论一致:社区中极少数的用户承担了绝大多数的内容贡献任务[37];同时,用户间的协同指标的快速下降进一步表明了用户间匹配的必要性。为了保证选取创新用户群的协同效果,本文将用户知识结构的取值下界确定为0.2,参与动机的取值下界确定为20,知识互补性的取值区间确定为(200,400)。最终获得满足上述属性的目标用户集,共计92位用户。
在实例研究中,本文设定创新用户群的目标成员数为8。基于模型(29)~模型(32),本文可以得到MIUI社区的创新用户群发现模型,并利用遗传算法对其进行求解。为了确定求解过程中各类参数设置,本文给出了相关文献的常用取值范围,并根据以往经验确定本文的参数,具体设置如表7所示。
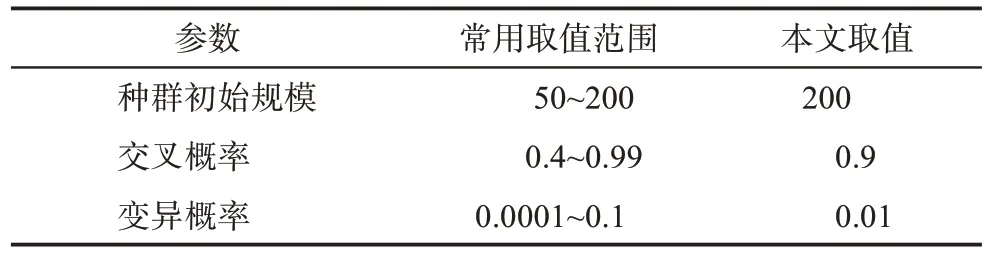
表7 遗传算法求解的部分参数
本文分别计算公式(29)和公式(30)的两个目标函数的最优值,并将其作为多目标求解的理想点,这里理想点为:(Z*1,Z*2)=(2.76,2.25)。
综上所述,本文利用遗传算法进行最后求解,具体操作流程见图3,其运行结果如图5所示。从图5可以看出,当迭代次数达到250次左右时,可获得参与协同的创新用户群的最佳组合方案,相应的用户群组合为[U27,U94,U247,U1039,U924,U1,U2634,U296]。该组合方案下,创新用户群的各属性特征的具体情况如图6所示。在图6中,选中集表示最终的创新用户群;有限随机集为限定知识结构等指标的随机用户集合;随机集为发表过相关帖子的随机用户集合。从图6还可以发现,创新用户群在各个指标上较原有用户群和随机用户群均有更好表现,表明了该方法的有效性。
为了进一步表征创新用户群选择的有效性,本文利用用户知识超网络截取了部分用户特征。首先,利用超边关系构建了协同创新用户群之间的评论关系,如图7所示。图7中创新用户群之间的互动非常频繁,且随着时间的推移,其关系愈加紧密。同样地,本文对用户之间的共同兴趣程度进行了表达。即若两位用户在评论了同一帖子,那么用户对之间存在一条边。如图8所示,创新用户群的知识兴趣存在较高的一致性,且其随着时间的推移愈加明显。
针对选择用户群的具体知识情况,本文基于其生成内容给出了相应的词云图,如图9所示。从图9中可以看出,用户之间的知识具有一定的相似性,如“小爱同学”“通知”等。同时,用户之间的知识也存在一定的差异性。基于上述分析,本文发现的创新用户群在知识互补及互动潜能方面均有较好的表现。
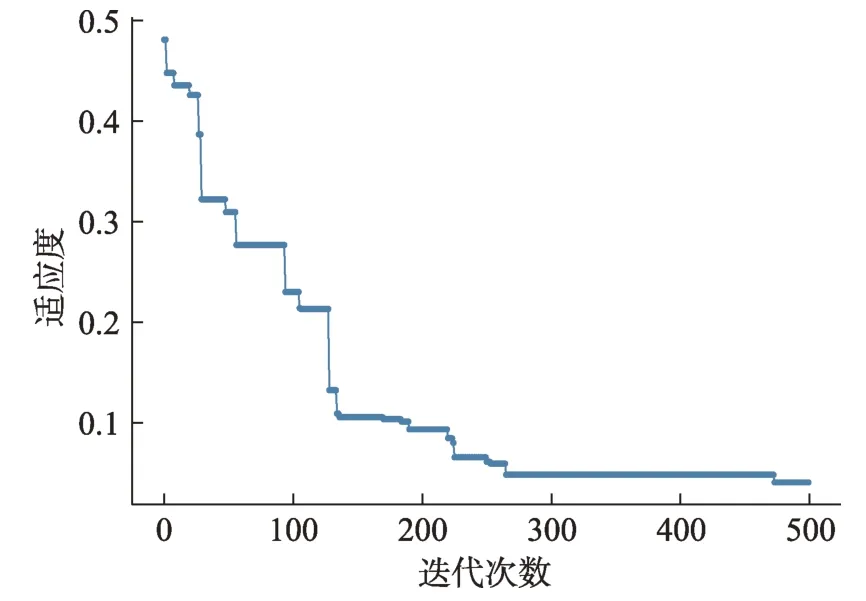
图5 多目标识别模型求解的迭代收敛情况
5 讨论与结论
随着市场环境的转变,将用户置于研发中心,与用户交流创新需求,成为企业寻求产品解决方案的最佳途径。然而,也正是因为市场环境的快速变化,企业创新社区中的用户交互行为与用户生成内容也应适时更迭变化。现有的用户识别常常聚焦于某个时间截面的静态数据开展,这种研究结果难以适应后续的工作需求。同时,针对参与协同的创新群体的组建,已有研究常常聚焦于用户的交互行为,而忽略了对用户的具体知识内涵、用户间知识异同、协作潜能等协同属性的考量。因此,本文提出综合考虑用户行为的动态变化、并融合用户的知识特征与用户间协同属性,发现对产品创新卓有助益的创新用户群,为社区中的协同创新实践提供决策支持,加速群体智慧的有效聚集与涌现。
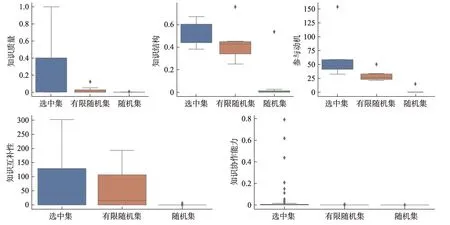
图6 选取用户群与随机用户群的指标特征
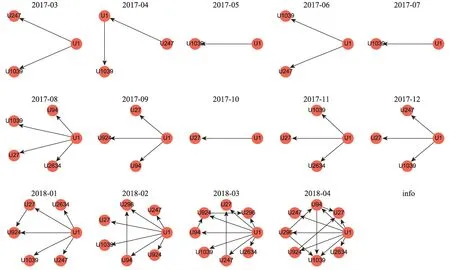
图7 用户评论关系时变图
具体来说,本文构建了用户知识超网络模型,将企业创新社区中的异质要素进行集成表达,为后续研究提供有效的表达工具与分析素材。利用这一网络模型,本文对用户的个体属性(知识质量、知识结构和参与动机)与协同属性(知识互补性和知识协作能力)进行分析与量化,并将不同时段下用户行为对当前决策的参考价值纳入考量。最后,结合具体创新需求构建并求解协同创新用户群发现的多目标决策模型。通过实际数据分析,验证了本文提出方法的可行性和有效性。
另外,本文针对协同创新用户的属性度量提出了一套完整的指标体系,包括知识质量评估、知识互补性度量等,并结合超网络模型给出了利用客观数据的指标量化方法。本文的研究对超网络方法、用户识别体系和知识量化方法的完善与融合具有重要的推动意义。结合实践场景的实际需求,本文的研究成果可以为社区中的用户组织及推荐提供决策参考;通过帮助决策者获取更符合创新任务需求的创新用户群,对协同创新等社区运营实践具有重要的指导意义。与此同时,本文提出的方法对其他知识系统中协同创新团队的组建也具有一定的参考意义。
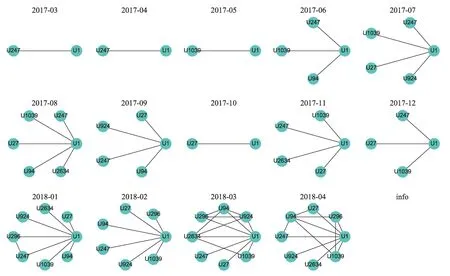
图8 用户共同兴趣时变图

图9 创新用户群的发帖关键词分布
诚然,本文尚存在一些不足之处,有待在未来工作中进一步完善。其一,由于自然语言处理技术的有限发展,本文在知识主题发现和用户知识衡量中的准确性有待进一步提升。其二,虽然超网络为本文的表达与分析提供了很好的工具,但其应用具有相对的局限性,超网络中有许多拓扑特性值得进一步研究,这将更为有效地辅助复杂知识系统的表达与分析。
