基于融合数据和生命周期的技术预测方法:以病毒核酸检测技术为例
2021-06-14林宇航侯剑华
张 洋,林宇航,侯剑华
(中山大学信息管理学院,广州 510006)
1 引 言
在全球化加剧的大背景下,人口流动愈加频繁,一些传染性极强的病毒迅速蔓延。在与病毒的抗争中,人类及时地破译病毒核酸序列、升级检测技术成为取胜的关键。情报分析方法为学者们提供了一种强有力的技术数据解析与运用的工具。借助当前已有的病毒核酸检测技术数据,预测未来技术升级的前沿趋势,对于调整产业结构和提高产业创新能力具有十分重要的意义。
随着科学论文和专利数据库的不断完善和发展,基于文本的技术挖掘方法逐渐成为开展技术预测的主流手段。一方面,已有研究多是以论文或者专利文本为数据源,通过专利的IPC(International Patent Classification)引证关系或论文的关键词共现关系挖掘未来技术前沿趋势,将论文和专利文本融合作为数据源开展技术预测的研究较少。另一方面,在确定预测基础数据的时候,如果时间范围选定过广,预测基础过于宽泛,难以保证准度;如果时间选定过窄,可能出现网络稀疏,漏掉关键节点等问题。目前,人们缺乏一套系统的基础数据选定标准。以往研究在选取训练集时,往往忽视技术内部的客观演化规律,导致预测效果具有较大的随机性。因此,本文遵循技术演化的规律,从数据来源、词共现关系、技术生命周期等方面对链路预测模型进行优化,以更准确识别技术前沿趋势,具体研究包括:①使用融合数据作为技术演化趋势分析的依据,提取专利与科学论文的主题词,共同构建主题词共现加权网络。使用加权指标的链路预测算法识别新技术演化趋势,证明融合数据源具备更好的预测效果。②根据技术生命周期理论,提出一种在有限的数据条件下,快速定位最优预测基础数据的方法,有效提升预测模型的效率。
2 文献回顾
1959年,Lenz最早提出了技术预测这一概念[1]。技术预测是指在具体的框架内,分析技术发展的条件和潜力。由于专家评议的主观性和高昂的社会成本[2],现阶段的技术预测中,专家咨询更多地作为一种辅助和补充手段[3]。而以定量分析为基础的技术预测方法,凭借其高效和客观,得到了学术界和产业界的广泛使用和传播。
2.1 技术预测的数据基础
目前,以单一数据源作为技术预测的基础数据是主流方法,如基于专利的社会网络分析法[4]、基于文献计量方法[5]等。当数据量不够丰富时,以单一数据所构建的预测网络难免遗漏个别关键节点或关系,给预测效果带来不利影响。
随着单一数据效果显现出来的不足,有研究者尝试采用多源异构数据作为预测基础。例如,融合专利与论文两种数据来源[6],结合相似度计算识别技术演化趋势;融合社交媒体数据与专利数据[7]拟合新兴技术出现的趋势。以上研究考虑到了多源数据对预测模型的贡献,解决了数据融合同构化的问题,但是忽略了技术演化的时序性差异。
在为预测模型(特别是链路预测模型)选择训练集时,主流的数据选取方式多为全网络数据[8]、十字交叉验证[9]或随机百分比划分[10]。前期研究[11-12]认为以3~5年作为一个网络的时间跨度进行预测较为合适,但是并未结合技术演化规律,为数据集选定提供依据。
2.2 技术预测的方法
目前,技术预测的方法可以分为定性与定量两大类。在定量方法中,主流方法有两种:基于知识单元重组的预测方法、基于链路预测和机器学习的方法。
2.2.1 基于知识单元重组的预测方法
1986年,Swanson[13]提出将两个完全独立的知识单元放在一起,则很有可能产生新的知识组合。技术融合是原本不相交的两个领域出现界限上的模糊[14],同时也是寻找技术的突破点,通过跨领域的知识重组实现技术的升级、替换过程[15]。因此,预测技术的融合在一定程度上可以等同于预测新技术的产生。
基于引用和耦合分析是表征技术知识融合的重要方式。文献的引用可以抽象为知识流动的过程[16]。文献耦合通过测算不同文献之间的相关性,表征知识融合路径[17]。此外,专利引证与共类同样反映了技术知识的重组[18-19]。除引用与耦合关系之外,专利转让[20]、产学研合作[21]等也是技术知识流动的表征方式。
2.2.2 基于链路预测和机器学习的方法
链路预测是根据节点的属性和网络结构的特征,预测未知的边和未来可能产生的边[22-23]。近年来,该方法被众多学者运用于新兴技术的预测。例如,翟东升等[24]以专利IPC引用网络结合链路预测指标预测未来技术机会;黄璐等[25]运用链路预测对专利的手工代码和加权词项进行共类分析,以此来预测不同技术的融合趋势。
自动化文本处理是数据驱动环境下高效、准确预测的重要前提[26]。而自动化文本处理所涉及的自动分区、科技信息提取、情感分析等手段均要借助机器学习才能高效完成。目前,已有研究通过使用K-means算法[27]、图神经网络[28]等取得了较好的预测效果。
2.3 研究述评
从技术预测使用的数据源来看,基于单一数据是目前的主流方法。从相关方法研究来看,可以大致分为基于知识单元重组、基于链路预测算法和机器学习等。
使用链路预测方法时,出于增加网络密度的考虑,多数研究将收集到的所有数据用于构建训练网络。这种方法较为稳妥且简单,但是当数据量较小时,会受到一定的局限,且带有主观色彩。leavein-and-out方法、十字交叉验证等方法的好处在于能够充分利用现有数据,但是忽视了时间动态因素。而随机百分比抽取这一方法,具备了一定的盲目性。罕有研究通过多角度的检验和论证,探索一套高效的数据划分和选定标准,以保证预测效果,并且揭示数据划分对预测效果的影响。
当前的研究成果存在三点不足:一是相关研究多数通过计算主题词相似度,进而以聚类算法来预测技术趋势;二是以单一数据源作为主流预测依据容易造成重要节点的遗漏,影响预测效果;三是构造基础数据时缺乏科学选取的依据,多数研究并未考量所得到的预测效果是否达到最佳。
3 预测模型构建
针对现有研究的预测数据源单一,未将技术演化因素纳入考虑范畴等不足,本文基于数据源选取和构建,以病毒核酸检测技术为例,提出了一种技术预测改进模型。首先,深入分析已有的病毒核酸检测技术特征;其次,借鉴Swanson[13]的知识流动思想,以技术主题字段的共现关系定义新技术的产生;再次,引入专利文本和科技文献,共同作为预测数据的来源;最后,结合技术生命周期理论,为模型的训练网络提供选择依据,通过以上优化手段提升链路预测的效果。将新模型与单一数据网络、不同生命阶段网络的效果进行比较,以此来检验改进的模型效果。本文设计的模型分析框架如图1所示。
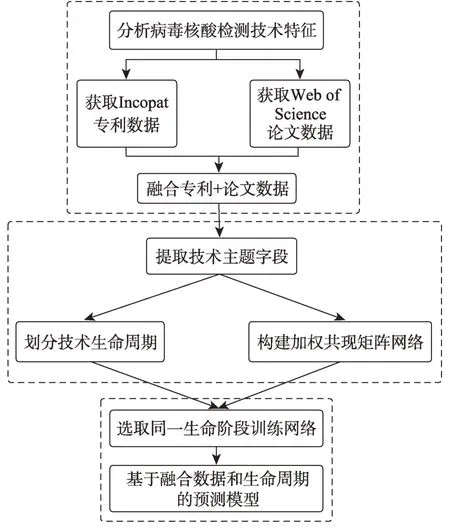
图1 基于融合数据和技术生命周期的技术预测模型分析框架
3.1 病毒核酸检测技术的特征分析
最早的病毒核酸检测技术是20世纪80年代初的核酸分子杂交法。随后,科学家发现一些工具酶具有特异性的序列识别能力,以及高效的生物催化活性[29]。在此之后,许多新发明的分子检测技术都是在使用工具酶放大信号的基础之上实现的,例如,1985年首次被发明的聚合酶链式反应(poly‐merase chain reaction,PCR)和20世纪90年代初的连接酶链扩增技术(ligase chain reaction,LCR)。其中,PCR是核酸检测的“金标准”,已经相当成熟[30]。2010年以后,较先进的核酸检测技术包括生物芯片、基因测序等。
在发展和演化的过程中,该技术的某些主题字段是一脉相承的,如荧光标记、聚合酶、扩增技术等。这些字段频繁地出现在专利和科技论文中,新技术往往带有上一代技术的痕迹。只有出现某些颠覆性技术时,才可能消除某些老一代的技术主题字段,例如,第四代基因测序技术实现了单分子测序,彻底摆脱了核酸扩增环节。由此可见,时序性对核酸检测技术发展产生一定的影响,同一时期的技术主题字段往往联系紧密。因此,在预测时,技术生命周期应当作为一个重要的数据因素,不可简单地忽视。
3.2 二源数据的加权网络融合
专利和科学论文都是技术的重要载体,二者之间存在许多契合的字段。同时,二者间也存在不同的字段。同一时期字段所关联的技术较为贴近,因此二者能够形成有效互补,增加原有网络稠度,避免因使用单一数据源造成字段遗漏。本文将两种数据源进行技术主题字段提取之后,融合形成字段共现矩阵,测试训练结果,与单纯的文献或专利矩阵的训练结果进行横向比较,检验融合数据的预测提升效果。
在以往的链路预测研究中,部分忽略了网络连边的权重问题。事实上,连边权重也是网络拓扑结构的重要组成因素,对节点间二次连接,以及周边节点关系有较大的影响。Zhao等[31]研究验证了在复杂网络中,节点间发生连接的概率与节点所涉及关联边的权重存在线性关系。翟东升等[24]对多个链路预测指标进行加权计算,验证了兼顾权重方法的科学性和合理性。考虑到已有技术融合的次数在促成未来的新技术诞生上存在一定的影响作用,本文使用加权链路预测指标,将比无权指标更加具有说服力。
使用AUC(area under curve)检验指标的预测性能,对未知边和不存在边进行随机重复抽样。每次抽取时,当测试集边得分高于训练集边时,分子加1;测试集边等于训练集边时,分子加0.5,以此类推。分母n为总的抽取次数。AUC的计算公式为
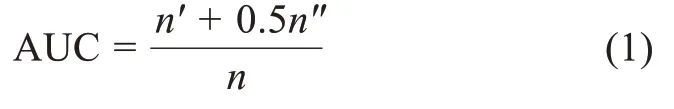
3.3 技术生命周期识别
时序性演化是技术的一个重要特征,技术生命周期可表征不同阶段的发展规律。S型曲线不同阶段的斜率能够较准确地贴合技术萌芽期、生长期、成熟期和衰退期的发展速率变化。Logistics曲线是S曲线中的一种,其公式[32]为

其中,l为饱和点的值;α代表斜率;e为自然常数;β代表各个不同时期的转折点。
本文将使用Logistics曲线来拟定技术生命发展的历程,探究不同阶段对链路预测模型效果的影响,为选取最优训练数据提供参考。不论是专利指标分析法还是S曲线法,都是将各阶段专利的数量作为唯一的参照指标。由于专利和论文对技术的演化均具有重要贡献,同时具备反映技术生命阶段的意义,本文使用融合矩阵网络中每年新增的共词对数量代替专利新增数量,作为生命周期拟定指标。
3.4 基于生命周期的模型构建
在识别技术生命周期的基础上,为了利用生命周期改进预测模型,本文须结合技术自身的客观演化规律,确定同一阶段与跨阶段技术的关联特征。
不同的技术小类间存在内生联系[33],而技术的网络具备小世界性[34],表现为大部分节点间并不直接相连,但是通过少数的几步路径就可以到达。相邻时间段内出现的技术主题字段不是跳跃发展的,而是随着新旧技术更迭,高频字段经历一个逐渐淡化的过程,逐渐被其他字段取代。技术随着时间推移,相关主题字段呈现一定的过渡演变,相邻时期或同一时期发生大幅度跃迁的可能性较低。相比之下,不同时期的技术主题字段间则差距较大。
本文通过一个简单的拓扑结构,来拟定不同生命阶段的训练网络对模型效果的影响,如图2所示。假设初始网络由A、B、C、D点和其间的一些连接构成(图2a)。对初始网络进行训练集与测试集划分(图2b)。实线边为实际存在的边,即训练集。在虚线边中,AB边为测试集,CD边为不存在边。根据链路预测算法,本文基于该拓扑结构,计算测试集AB边的得分,将其与CD边的得分进行比较。若AB边得分高于CD边的概率越大,则说明预测模型效果越好。以加权的共同邻居指标(weight‐ed common neighbor)为例:

其中,SXY为X、Y两点间出现连边的概率得分;节点Z表示X与Y的共同邻居;WXZ表示节点X与Z连边的权重;WYZ表示节点Y与Z连边的权重。在图2b中,AB边有共同邻居C、D,且分别与C、D点均存在一条连接,故SAB=(1+1)/2+(1+1)/2=2。同理,SCD=2。在这种情况下,根据AUC评价算法,预测的准确率为50%。
假如使用与预测目标不同生命阶段的数据来补充训练网络(图2c),因与测试边AB较为疏远,可以假设补充的点为P。那么P点与AB直接发生关系的可能性较小。相反地,其存在增加了CD边的权重。在该网络中,SAB=2,因为P点加入,SCD=3>SAB。使用极限思想,当所有补充的点特征都与P点相似时,则该网络的AUC=0。这种情况下预测效果将大打折扣。
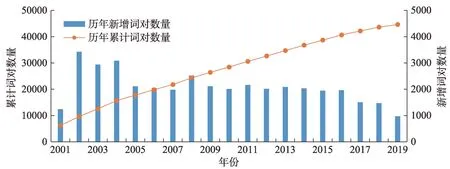
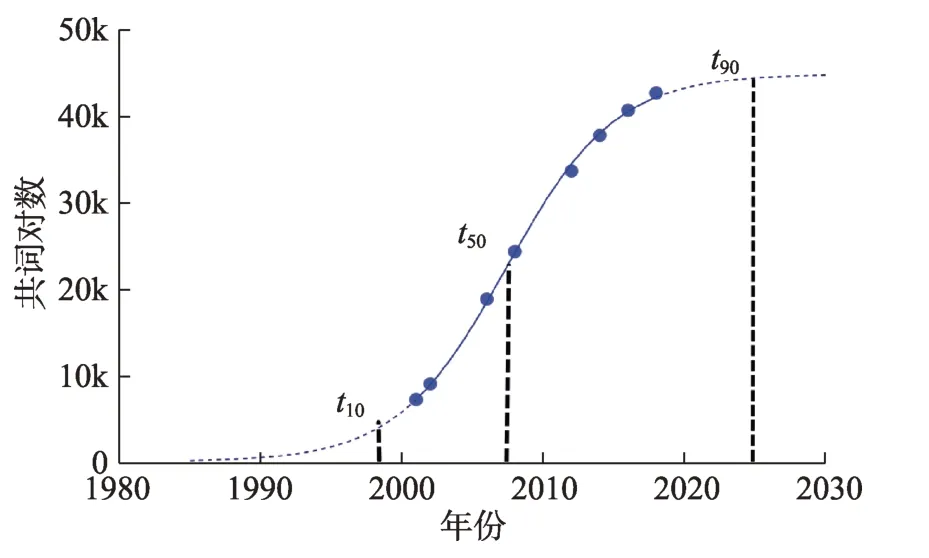
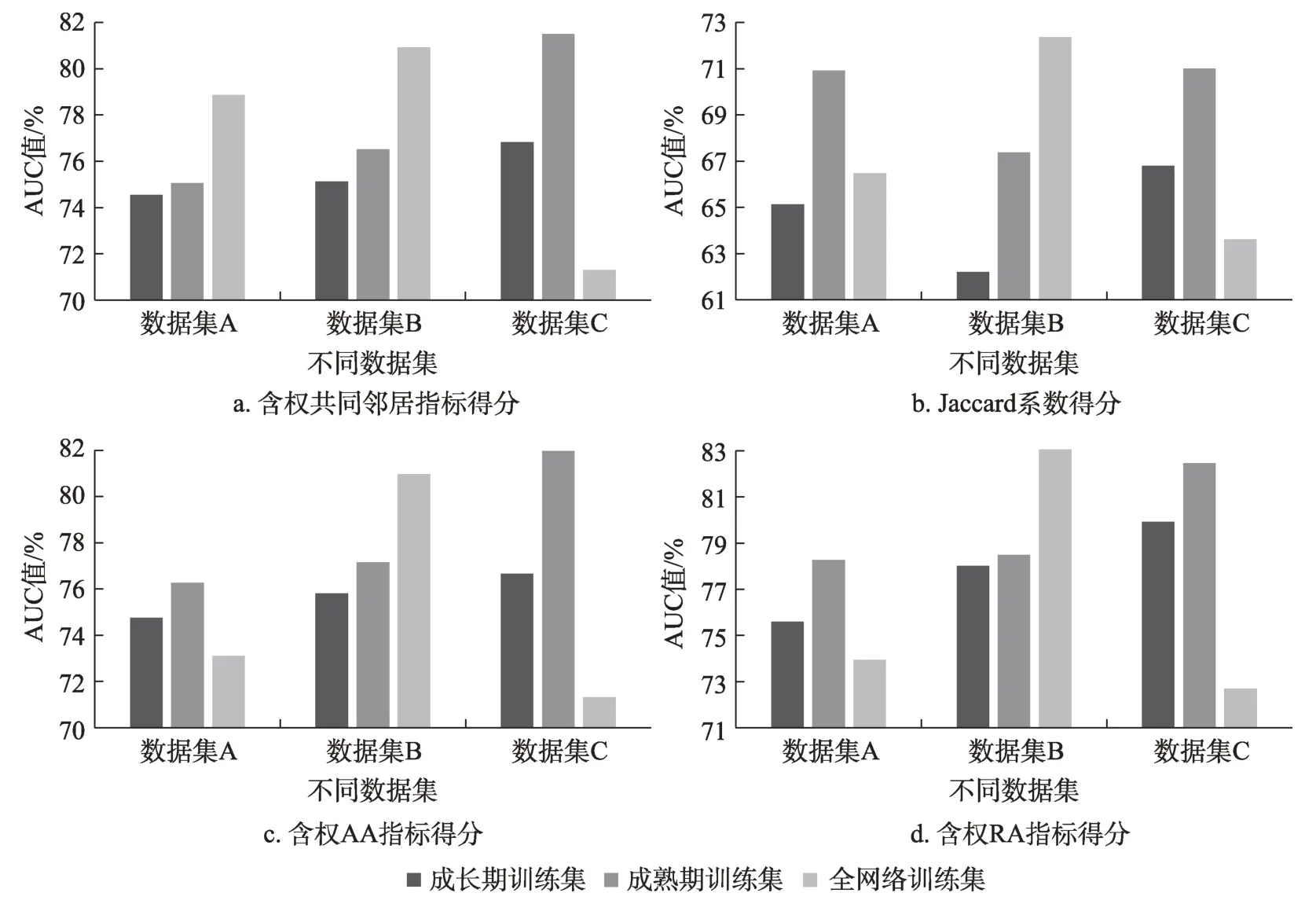
假如使用与预测目标同一生命阶段的数据来补充训练网络(图2d),因同一时期内技术更迭出现大幅度跃迁的可能性较低,可以假设补充的点为P,那么P点有较大的可能会与AB直接发生关系,结果增加了AB边的权重。在该网络中,SAB=3,SCD=2 经过图2a~图2d拟定,可以推断,当使用全网络数据集(即囊括所有不同生命阶段的数据)训练时,补充进来的节点既可能出现在图2c的P点位置,也有可能出现在图2d的P点位置。当全网络中,技术的主题字段大部分与预测目标节点较为贴近时,此时技术主题跃迁较小,更有利于增加目标节点的连边得分;而当多数技术主题字段与目标节点较疏远时,此时预测目标与总体网络存在较大的跃迁,结果稀释了目标节点的连边得分。由于涉及具体技术在不同层面的延伸,技术小类的数量不一,方向也各异,全网络中技术节点的分布难以预料,总的训练网效果存在较高的不确定性。因此,为了保证训练效果,同时减少检验数据的实验成本,在有限的数据条件下,选取与预测目标同一生命周期阶段的基础数据是最优选择。 图2 不同生命阶段的训练网络对模型效果的影响 经过上述步骤,本文建立起了一个新的链路预测改进模型。该模型融合专利与论文数据,并参考技术生命周期的不同阶段以选取训练网络,优先以同一生命阶段的训练网络作为预测基础。下面以病毒核酸检测技术2001—2019年数据为样本,对此模型进行实证检验。使用链路预测对病毒核酸检测进行技术预测时,网络中不同节点代表不同的技术主题字段,连边则表示不同技术主题间发生共现,产生了知识融合,意味着新技术的萌生。 在Incopat网站上,以检索式“病毒AND核酸检测”进行检索,检索日期为2020年1月30日,设置专利公开年份为2001-2019,得到28259条专利数据。在Web of Science网站上检索病毒核酸检测技术相关文献,检索式为TS=((virus OR viral)AND nu‐cleic acid AND(detection OR test OR assay)),检索年份设置为2001-2019,共得到6678条文献数据。 提取所有文本的标题,创建3个数据集,分别为论文标题数据集、专利标题数据集、论文与专利标题融合数据集(以下分别简称为数据集A、数据集B、数据集C)。为了尽可能地排除预测过程中的偶然性,使结果更加客观,将三个数据集各分为4个阶段:2001—2005年数据、2006—2010年数据、2011—2015年数据、2016—2019年数据(下文分别简称为阶段1、阶段2、阶段3、阶段4),最后得到一个3×4的总数据集合。利用BibExcel软件提取所有标题数据中的技术主题字段,设置字频阈值为10以上,剔除无关字段和冗余字段,构建技术主题字段共词矩阵。在此过程中,共产生12个共词矩阵,如表1所示。 在数据集A中,分别以阶段1、阶段2、阶段3的矩阵网络作为训练集,以阶段4作为测试集检验训练效果。为了降低实验误差,需要对多个指标的预测效果进行横向对比。同时,考虑到已有节点连接的次数同时是拓扑结构的一部分,直接关系到相关节点的中介度和中心性,对新连接的产生具有较大的潜在影响,对每个指标进行加权处理,能够更好地反映实际情况。本文参照翟东升等[24]对链路预测指标的加权方法,使用含权共同邻居、Jaccard系数、含权Adamic-Adar(AA)指标、含权resource allocation(RA)指标计算连边得分。最后,以AUC表征的百分比来衡量模型的效果。 同样地,在数据集B、数据集C中进行类似的训练和测试。最后,分别得出三个数据集中,不同阶段、不同指标的预测效果,如图3所示。 为了检验融合数据是否比单一数据更有优势,本文横向对比A、B、C三个数据集中,同一指标且相同阶段的预测效果。由图3可见,在Jaccard系数(图3b)与含权AA指标(图3c)的阶段3,数据集B效果优于其他。除Jaccard与含权AA的阶段3以外,在横向对比中,由数据集C得出的训练效果AUC值均为最高。这说明了融合专利与论文技术主题字段的共词网络相较于单一数据网络,链路预测性能得到一定程度的提升。 表1 数据集各阶段的技术主题字段共词矩阵大小 图3 不同数据集预测效果对比 将每年专利与论文融合网络中,新增技术主题字段的共词对数抽取出来,绘制成折线图,如图4所示。 由图4可见,在2008年之前,每年新增共词对数量在1000~3500内波动,但是总体上每年新增数量有所上升。说明在2001—2008年,技术生长速度有所加快;而2008年之后,每年新增词对数量呈现出下滑的趋势,说明技术生长的速度在逐渐放缓。 本文使用Logistics曲线来拟合病毒核酸检测技术发展的不同阶段。把累计专利公开数量替换成专利与论文融合矩阵中累计技术主题字段共词对数量,将2001—2019年的病毒核酸检测技术融合数据输入Loglet Lab 4软件,经过多次调整参数进行拟合,结果得到如图5所示的S曲线。 拟合结果显示,技术生命周期各阶段的转折点时间t10、t50、t90分别为1998年、2007年和2025年。即1998年以前,为病毒核酸检测技术的萌芽期;1998—2007年为技术生长期;2007—2025年为技术的成熟期预测;预测2025年以后将进入技术的衰退期。 图4 历年新增与累计共词对数量趋势 图5 技术生命周期拟合曲线 为了验证不同技术生命周期阶段的训练网络对结果的影响,本文对数据集时间段重新划分,分别是2001—2007年(即成长期训练集)、2008—2015年(即成熟期训练集)、2001—2015年(即全网络训练集),对这三个网络进行训练,同样使用2016—2019年作为测试集来检测训练效果。 利用BibExcel软件提取所有标题数据中的技术主题字段,设置字频阈值为10以上,剔除无关字段和冗余字段,构建出每个阶段的技术主题字段共词矩阵。 根据第4.3节的分析,2008—2015年的训练集与测试集数据同属于技术成熟期内;而2001—2007年的训练集则在相邻的成长期内;2001—2015年的训练网络则同时囊括了成长期与成熟期。训练得出的指标效果如图6所示。 图6 不同生命阶段的训练集预测效果对比 在数据集A、B、C当中分别进行纵向对比,考察不同生命阶段的网络预测效果。在数据集B(专利技术主题字段)中,全网络训练集的效果最佳。根据第3.4节的分析,推测是因为对于专利来说,全网络时段的技术主题字段分布与预测目标较为贴近,意味着在长时间内,技术主题较为集中,未产生较大的跃迁,这使得全网络有更佳的预测表现。而在数据集A(论文技术主题字段)和数据集C(融合技术主题字段)当中,以成熟期数据(橙色柱体)作为训练网络的所有参数,几乎均取得了最优效果。由此可见,全网络的预测效果存在较大的不确定性,未必是最好的。这说明在选取训练网络时,优先考虑与预测目标同一生命阶段的数据,能够较大限度地保证预测效果。 本文提出了一种使用融合多源数据来改进技术预测效果的方法,针对病毒核酸检测技术的特征,结合技术演化规律,并检验了提出的新模型效果。研究发现,相较于原有模型,新模型在预测效果上得到了有效提升。 研究结论主要包括:①融合多源数据的训练网络比单一数据有更好的预测效果。多源数据间互为补充,克服技术主题字段完整性不足的问题,更加客观真实地刻画实际技术的发展状况,有助于提升预测性能。②技术生命周期与预测模型的效果关系密切。由于技术的内生演化,不同阶段的网络较为疏远,因而跨阶段的网络稀释了预测目标的得分,影响了预测的效果。实验发现,在使用同一生命阶段数据进行预测时,大部分效果优于不同阶段和全网络数据,能够较大程度地保证模型的预测效果。选定正确高效的数据集,不仅能够提升模型性能,而且能够减少运算负荷,达到事半功倍的效果。针对以往研究选取基础数据的随机性缺陷,本文提供了一种快速定位高效基础数据的方法,在保障预测效果的同时有助于减少实验成本。 随着科学大数据和人工智能技术的快速发展,更加客观有效的技术预测模型将不断地被改进。本文的局限性在于实验部分仅比较了病毒核酸检测技术成长期与成熟期两个阶段。在涵盖完整的技术生命周期数据下,将提出的模型拓展至其他技术领域,还有待进一步研究。未来,整合包括专利与论文在内(如图书、标准、行业报告等)的多源异构数据,对技术前沿进行预测的方法将逐渐取代单一数据源方法。此外,结合机器学习对大规模文本的高效处理能力,将有更多的算法被开发出来。将文献计量、专利分析、链路预测以及机器学习等多种方法综合起来,通过对比效果衡量出最佳标准,将成为技术预测的未来方向。
4 实证分析
4.1 数据来源与处理
4.2 加权指标下融合数据矩阵预测效果


4.3 技术生命周期分析
4.4 不同生命阶段的预测效果
5 研究结论与讨论
