融合语义特征和分布特征的跨媒体关联分析方法研究
2021-06-14刘忠宝赵文娟
刘忠宝,赵文娟
(1.北京语言大学语言智能研究院,北京 100083;2.泉州信息工程学院云计算与物联网技术福建省高等学校重点实验室,泉州 362000)
1 引 言
随着大数据时代的到来,互联网上涌现了海量的文本、图像、视频、音频等多种媒体数据。这些数据来源广泛、结构各异,从而导致“语义鸿沟”问题的出现,严重地影响和制约了多种媒体数据语义一致性的学习和表示。事实上,人类通过语言、听觉、视觉等多感官认识世界,如何借鉴人类认识世界的方式实现多种媒体数据的语义理解,是进行跨媒体一致性表示的关键。解决该问题的常见做法是建立一个统一的语义空间,将各种媒体数据映射到该空间得到一致性表示,通过比较各种媒体数据之间位置、距离来确定数据之间的关联关系。
目前,现有文献采用的方法中大多数是针对文本和图像两种媒体数据展开的研究。尽管可以通过“两两组合”的方式将面向两种媒体数据的跨媒体关联分析研究扩展到多种媒体数据,但这种做法忽略了各种媒体数据之间的共存性和互补性,导致利用现有方法获得的语义信息不够完备,这直接影响了跨媒体关联分析的效率[1]。此外,现有方法往往是通过最大化成对各种媒体数据之间的关联关系建立优化问题,并未考虑各种媒体数据的上下文信息,这些媒体数据的统一表征缺乏丰富语义信息的支持[2]。因此,本文融入多种媒体数据的语义特征和分布特征,来对跨媒体关联分析方法进行深入研究,以期在一定程度上提高多种媒体数据的语义表征能力,并有效地提高跨媒体关联分析的效率。
2 研究进展
现有跨媒体关联分析方法的基本思路是通过降低各种媒体数据之间的异构性差异,进而度量数据之间的语义相似性。具体做法是为各种媒体数据找到一个统一的语义空间,并将这些数据映射到该空间,通过测量统一语义空间下这些数据之间的语义距离,来判断数据之间的关联关系。目前,跨媒体关联分析方法可以分为两类:一类是基于统计学习的方法,另一类是基于深度学习的方法。
基于统计学习的方法是指利用统计学习方法来建立映射矩阵,将各种媒体数据映射到统一语义空间。典型相关分析(canonical correlation analysis,CCA)最早被应用于跨媒体关联分析,该方法建立优化问题的基本思路是最大化两类媒体数据之间的关联关系。一些后续研究基于CCA展开,典型代表有:Rasiwasia等[3]利用CCA对文本和图像进行联合学习,得到一个统一的语义空间,并基于此分析两类媒体数据之间的相关性。Ballan等[4]利用核典型相关分析(kernel canonical correlation analysis,KCCA)建立交叉视图检索方法来分析文本和图像之间的相关性。Gong等[5]在CCA得到的统一语义空间中增加了高层语义特征,提出三视角典型相关分析(three view canonical correlation analysis,TVC‐CA),用于提高相关性分析效率。除CCA之外,Chen等[6]利用偏最小二乘法(partial least squares,PLS)将视觉特征转化为文本特征,在统一语义空间中比较各种媒体数据之间的相关性。
基于深度学习的方法和深度学习模型强大的学习能力,研究者利用深度网络来统一表征多种媒体数据的语义特征。Andrew等[7]融合CCA和深度学习的优势,提出深度典型相关分析(deep canonical correlation analysis,DCCA),该方法能够为成对的不同媒体数据分别构建深度网络,通过比较两者输出的相似性来建立优化问题。Feng等[8]为不同媒体数据构建相应的自编码器,通过分析自编码器输出的深层语义特征,获得不同媒体数据之间的关联关系。Wei等[9]为了深入挖掘不同媒体数据之间的关联关系,通过引入卷积神经网络(convolutional neural networks,CNN)模型来对图像数据进行建模,进而提出深度语义匹配(deep semantic match,Deep-SM)方法。Peng等[10]在深度网络模型的基础上提出跨媒体多层深度网络(cross-media multiple deep network,CMDN)模型,该模型融合各种媒体数据内部及数据之间的关联信息来构建面向各种媒体数据的深度网络,利用层次化的学习方法对各种媒体数据进行联合学习,进而在统一语义空间中表征各种媒体数据。此外,Peng等[11]还提出了跨媒体关联学习(cross-modal correlation learning,CCL)方法,该方法引入多任务学习思想来学习各种媒体数据的高层语义特征。Huang等[12]将迁移学习模型引入到跨媒体关联分析中,提出跨媒体混合迁移网络(cross-modal hybrid transfer network,CHTN)模型,该模型包含两类子网络:一类是跨媒体共享迁移子网络,用于在源域和目标域之间传输各种媒体数据共享的知识;另一类是层级关联子网络,用于分析各种媒体数据之间的语义相关性。该模型在一定程度上实现了从单一媒体源域到跨媒体目标域的知识迁移。
近年来,图书情报领域的学者在跨媒体关联分析方面也取得了一些进展。李广丽等[13]综合图像和音频标注文本的相关性,以及媒体数据低层特征的相关性,建立了跨媒体一致性表示。明均仁等[14]利用关键挖掘技术得到多种媒体数据之间的关联关系,并基于此生成跨媒体本体库,以期在统一语义空间中表征多种媒体数据的语义特征。张兴旺等[15]指出,跨媒体关联分析聚焦于语义特征提取、语义内容发现、语义关联推理以及多模态信息融合等方面,并对这些方面的研究进展进行梳理。刘忠宝等[16]认为,跨媒体关联分析要支持数据类型上的跨越、同构多媒体数据在语义上的跨越,以及异构多媒体数据在语义上的跨越。李爱明[17]引入语义关联挖掘技术,通过挖掘多种媒体数据之间存在的关联关系,得到多种媒体数据之间存在的语义关系。彭欣[18]基于本体的多层次结构特性,建立面向多种媒体数据的语义关联树,利用深度学习模型逐层挖掘各种媒体数据之间的关联关系。徐彤阳等[19]借助跨媒体本体库,利用语义挖掘技术得到多种媒体数据的语义特征,通过建立跨媒体语义关联图对跨媒体数据的语义特征进行关联分析。黄微等[20]认为,跨媒体关联分析应以深度学习模型为主、其他机器学习算法为辅,综合利用统计学、情报学、心理学等学科的理论和方法,对多种媒体数据进行语义分析,将非线性、高维度的图像、视频、音频数据转化为文本数据进行处理,实现语义密度由低到高的转化。熊回香等[21]提出基于跨媒体数据的语义相关分析模型,该模型利用多种媒体数据的语义标签信息,在提取同类媒体数据的基础上,挖掘各种媒体数据之间的关联关系。鉴于多模态深度置信网络擅长发现异构特征之间的非线性相关性,李广丽等[22]引入该模型挖掘异构媒体之间的跨模态相关性。
由上述研究的进展可以看出,现有研究的方法大多数是利用传统研究框架建立映射关系,这种做法难以充分挖掘多种媒体数据之间的关联关系;同时,这些方法仅考虑各种媒体数据内部的语义信息,往往忽略了各种媒体数据之间多样的、复杂的关联关系。为了解决上述问题,本文利用多种媒体数据的上下文信息,融入各种媒体数据的语义特征和分布特征,对跨媒体关联分析方法进行研究,以期进一步提高跨媒体关联分析效率。
3 研究方法
本文的研究框架如图1所示。首先,对图像、文本、视频、音频等多种媒体数据进行向量化表示,并输入模型;其次,利用双向长短期记忆网络(bidirectional long short-term memory,BiLSTM)[23]挖掘输入数据的上下文信息,得到各种媒体数据的特征向量;最后,融合特征向量的语义特征和分布特征进行跨媒体关联分析,得到跨媒体的一致性表示。
3.1 输入数据向量化表示
对于图像数据,将其尺寸裁剪为224×224×3,并 输 入 到ResNet(residual network) 模 型[24],ResNet模型的层数可以是18、34、50、101、152等,在综合考虑模型的特征表示能力和计算能力的基础上,选用ResNet50模型。模型训练的学习率为1e-4,批大小为32,迭代次数为8000次。该模型输出的图像特征为512维;对于文本数据,利用结巴分词工具对文本数据进行分词处理,并引入word2vec(word to vector)模型得到文本数据的词向量表示,词向量为50维。将词向量输入DCNN(dynamic convolutional neural network)模型[25],得到的文本数据特征为256维,其中,DCNN模型的卷积核尺寸为7和5,最大池化数为4,批大小为50,迭代次数为10次;对于音频数据,选用帧长为256个采样点,帧移为128个采样点,将音频数据切割成片段,加窗过程采用汉明窗。将音频数据输入1-D CNN(1-dimensional convolutional neural network)模型[26],该模型的结构包括1层卷积层、1层采样层和1层全连接层,其中,卷积层的卷积核的数量为10,采样层采用最大值采样,输出层采用softmax分类器。模型训练的学习率为1e-3,批大小为16,迭代次数为100次。每一帧提取128维MFCC(mel frequency cepstral coefficients,MEL频率倒频系数)特征;对于视频数据,在提取每个视频帧的基础上,利用ResNet模型[24]提取视频特征。类似于图像数据,视频数据处理选用ResNet50模型,其参数设置同图像数据。
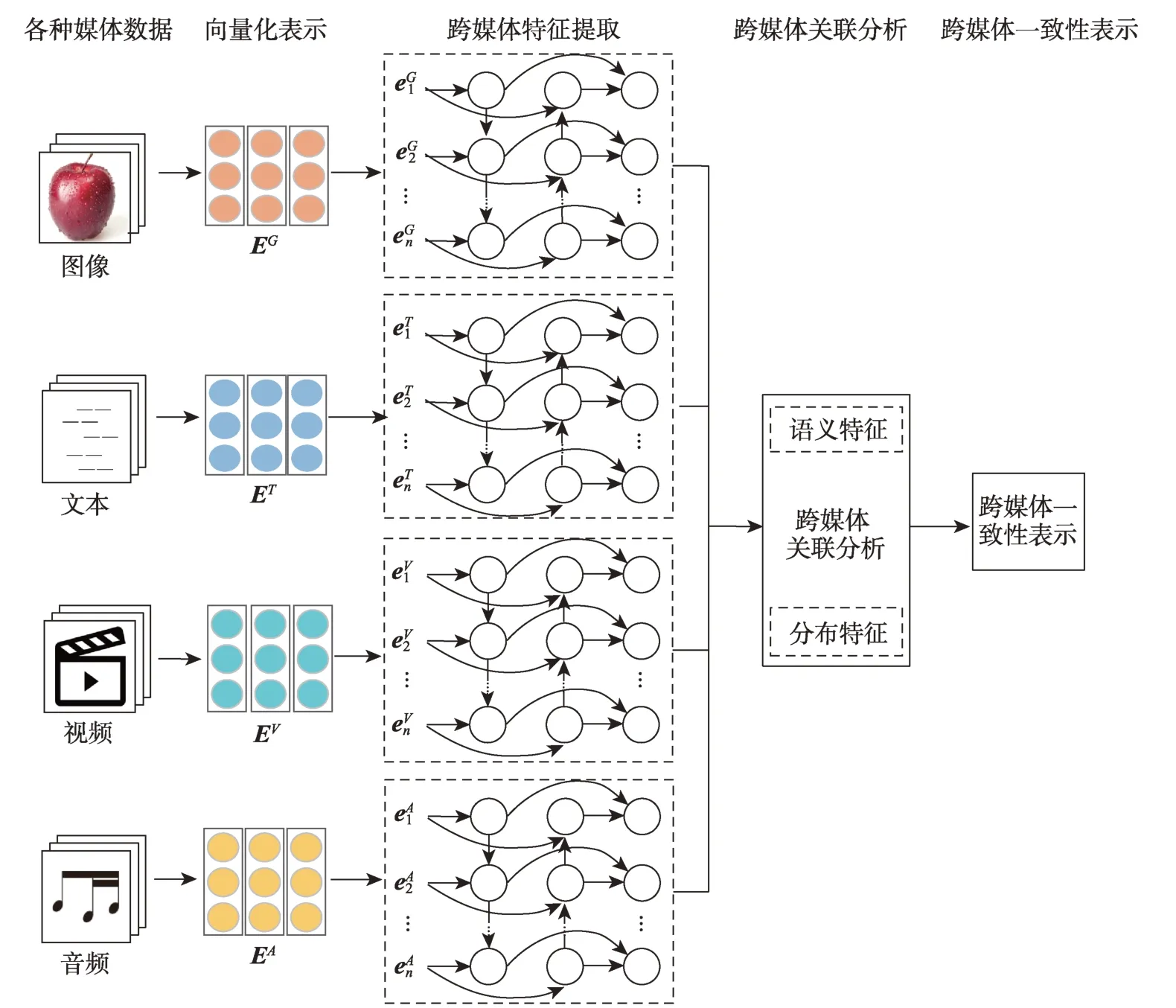
图1 研究框架
3.2 BiLSTM
为了充分利用多种媒体数据的上下文信息,本文在引入BiLSTM[23]的基础上,设计了多路BiLSTM模型,将每一种媒体数据输入模型,以获得其特征向量。BiLSTM是一种改进的循环神经网络(recur‐rent neural network,RNN)模型,其工作原理与RNN基本相同,两者的区别在于BiLSTM引入了门结构,该结构能对从输入层传来的输入向量进行更深层次的特征提取。该模型包含输入门、遗忘门、输出门等门结构。输入门和遗忘门分别控制隐藏层神经元需要更新和遗忘的信息,输出门则决定隐藏层神经元输出的信息。在t时刻,该模型的工作原理可由以下五个公式表示:
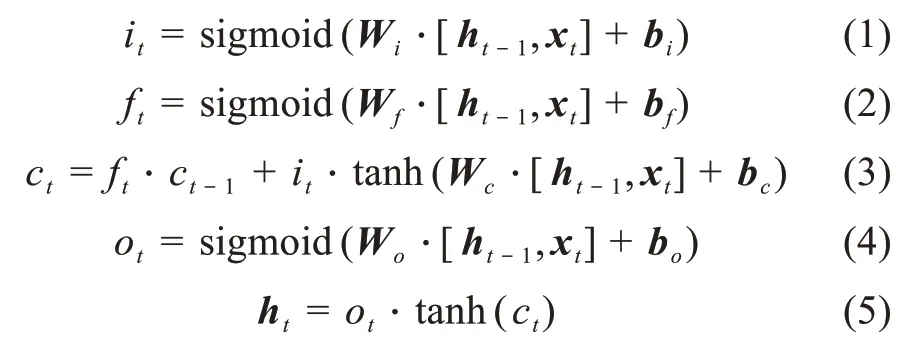
其中,x t为t时刻的输入向量;it、ft、ot分别表示当前时刻的输入门、遗忘门和输出门;W i、W f、W o和b i、b f、b o分别表示输入门、遗忘门和输出门对应的权重矩阵和偏置向量;ct表示当前时刻的记忆单元;sigmoid和tanh表示激活函数;h t为当前时刻的输出向量。
3.3 跨媒体关联分析
在得到各种媒体数据的特征向量之后,如何能将其投影到统一的语义空间是跨媒体关联分析的关键。各种媒体数据的特征向量在统一语义空间中的一致性表示,主要体现在语义特征和分布特征两个方面。语义特征是指各种媒体数据所指代语义内容的特征提取与向量化表示;分布特征是指各种媒体数据在统一语义空间中的位置关系及其分布态势。本文在融合上述两类特征的基础上,提出跨媒体关联分析方法。该方法利用各种媒体数据的类别信息来增强模型的语义学习能力,通过引入不同媒体数据在统一语义空间的相对位置关系来提高模型的分布特征刻画能力。
首先,考虑特征向量的语义特征。特征向量在统一语义空间的语义特征体现了各种媒体数据之间的语义关系。语义特征由语义特征矩阵L S表示。本文利用word2vec模型对类别信息进行向量化表示和特征提取,得到类别语义向量。在统一语义空间中,通过比较各种媒体数据的特征向量与类别语义向量之间的相似性来建立面向语义特征的优化问题。在该优化问题中,确保各种媒体数据的特征向量与其对应的类别语义向量之间的距离尽可能地近,而与该特征向量不同的类别语义向量尽可能地远。基于上述分析,可以得到如下优化问题。
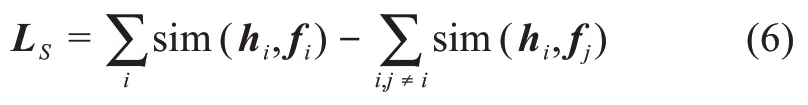
其中,sim(x,y)是用于比较x和y的相似度函数;h i为各种媒体数据的特征向量,i∈{1,2,3,4};f i为类别语义向量;sim(h i,f i)表示各种媒体数据的特征向量与其对应的类别语义向量之间的相似度;sim(h i,f j)(j≠i)表示特征向量与其不同类别语义向量之间的相似度。通过最大化公式(6)能够确保各种媒体数据的语义一致性。
其次,考虑特征向量的分布特征。特征向量在统一语义空间中的分布特征体现了各种媒体数据之间的位置关系。分布特征由分布特征矩阵L D表示。在统一语义空间中,衡量各种媒体数据之间相似性的指标是数据之间的距离,即同类媒体数据之间的距离尽可能近,不同类媒体数据之间的距离尽可能远。基于上述分析,建立如下优化问题。
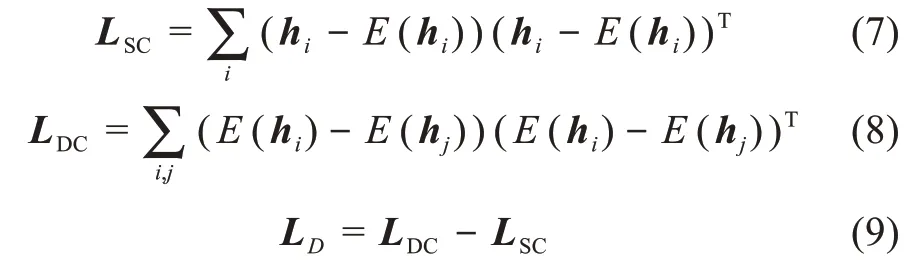
其中,i、j表示任意两种媒体数据;E(h i)表示第i种媒体数据特征向量的中心;LSC表示每种媒体数据的特征向量与其类中心之间的距离;LDC表示不同媒体数据特征向量中心之间的距离。通过最大化公式(9)可以提高同类媒体数据之间关联的紧密度,以及异类媒体数据之间关联的松散度。
综合各种媒体数据的语义特征和分布特征,可得到融合语义特征和分布特征的跨媒体关联分析方法:
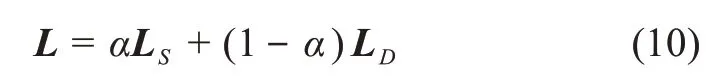
其中,α为平衡因子,用于平衡语义特征和分布特征在跨媒体关联分析中的重要性。通过最大化公式(10)能够准确刻画各种媒体数据在统一语义空间中的语义特征和分布特征,以增强跨媒体一致性表示的语义分析能力。
4 实验结果与分析
4.1 跨媒体数据集
目前,常用于多媒体和跨媒体研究的数据集主要有Wikipedia Dataset、NUS-WIDE Dataset、Pascal VOC 2007 Dataset、Clickture Dataset、PKU XMedia等。其中,Wikipedia Dataset用于跨媒体研究,但该数据集仅包含图像和文本两种数据;NUS-WIDE Dataset、Pascal VOC 2007 dataset包含图像及其类别信息,且类别信息可视为文本数据;Clickture Data‐set规模较大,但该数据集没有提供任何类别信息;PKU XMedia可用于跨媒体研究,该数据集包含5种媒体数据,其提供的20个语义类别(如鸟、小提琴、狗、火车等)区分度大,无法利用该数据集验证本文所提方法在相似语义场景下的有效性。
基于上述分析,目前常用的数据集无法满足本文跨媒体关联分析需求。因此,本文构建了新的跨媒体数据集。与已有数据集相比,新构建的跨媒体数据集包括图像、文本、音频和视频四种媒体数据及其类别信息,该数据集提供的虎、猫、狗、狮和狼五个语义类别具有一定的语义相似性。该数据集的具体情况是:以哺乳动物中具有较大相似性的虎、猫、狗、狮和狼五种动物为研究对象,从Wikipedia下载动物描述文本300篇,从Flickr下载动物图像300张,从YouTube下载动物视频300个,从音效素材网站下载与动物相关的音频300段,利用文本抽取技术从Wikipedia抽取与上述五种动物相关的类别信息。为了保证数据的平衡性,本文规定各种动物的文本、图片、视频、音频规模均为60。将上述下载的各种媒体数据作为跨媒体数据集。
4.2 评价指标与比较方法
各种媒体数据之间的相似性,可由统一语义空间中各类媒体数据特征向量之间的距离来表征,本文引入余弦函数来计算各种媒体数据之间的语义距离。本文将平均准确率(average precision,AP)作为实验结果评价指标,该指标能够反映出跨媒体关联分析方法的平均性能。通过比较本文的方法与现有方法(如CCA[1]、KCCA[3]、Deep-SM[9])的实验结果来验证本文的方法的有效性。其中,CCA是最早应用于跨媒体关联分析的经典方法;KCCA将CCA的适用范围由线性空间扩展到非线性空间,其具有更好地适用性和鲁棒性,这两种方法均可直接应用于跨媒体关联分析;Deep-SM是一种深度学习方法,该方法利用卷积神经网络提取深层语义特征,并进行跨媒体关联分析。上述三种方法具有一定的代表性,前两种是基于机器学习的方法,而Deep-SM是基于深度学习的方法。
4.3 对比实验结果
本文用到的参数主要是公式(10)中的平衡因子α,采用网格搜索策略得到该参数的最优值。平衡因子α在网格{0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9}中选取。任意选取部分多媒体数据集,如选取五种动物的文本、图片、视频和音频规模均为30,运行本文方法,得到平衡因子α的最优值为0.4。KCCA中的核函数选用高斯核函数。
在多媒体数据集上,分别运行CCA、KCCA、Deep-SM和本文方法,得到如表1所示的实验结果。
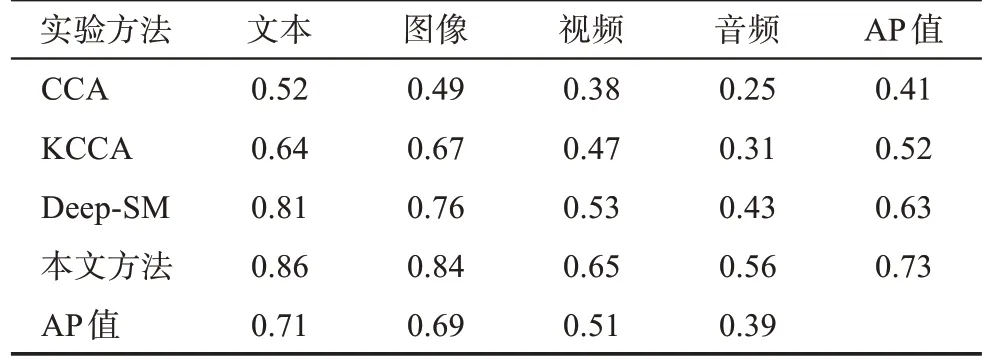
表1 各种媒体数据的比较实验结果
由表1可以看出,CCA在文本数据集上的表现最优,但是在图像、视频、音频等多媒体数据集上表现较差,特别是在视频和音频数据集上的准确率均低于0.4,该模型不适合处理具有非线性结构的多媒体数据。KCCA是CCA的改进版本,核函数的引入使其能够处理具有非线性结构的多媒体数据。从实验结果来看,KCCA在各种媒体数据集上的准确率均得到一定程度的提升。Deep-SM是基于CNN深度学习模型提出的,与基于机器学习的方法相比,其具有更强的特征学习能力。该模型在文本、图像、视频和音频等多媒体数据集上的准确率分别比KCCA提高了0.17、0.09、0.06、0.12。本文方法借鉴了深度学习模型在特征学习方面的优势,与CNN相比,BiLSTM能够提取各种媒体数据的上下文信息,融入语义特征和分布特征使之具有更优的准确率,特别是在图像、视频和音频等多媒体数据集上的表现明显优于CCA、KCCA、Deep-SM。跨媒体数据集上的实验结果表明,本文方法的准确率分别比CCA高0.34、0.35、0.27、0.31,比KCCA高0.22、0.17、0.18、0.25,比Deep-SM高0.05、0.08、0.12、0.13。从模型的平均性能看,本文方法的平均准确率最高,达到0.73,之后依次是Deep-SM、KCCA、CCA。从各种媒体数据集上的平均性能看,文本数据集上的平均准确率最高,其次是图像数据集,音频数据集最低。
由表2可以看出,CCA对于“猫”“狼”具有较高的准确率,该模型对“虎”和“狮”的关联分析效果较差,这与这两种动物具有较大的相似性有一定关系。上述结论对于KCCA同样成立,但适用于处理非线性多媒体数据的KCCA具有更高的准确率。Deep-SM较之CCA、KCCA对于各种动物的关联分析准确率均有不同程度的提升,特别是对“狗”“狼”的关联分析效果更优,接近或达到0.7,这与其引入CNN深度学习模型,能够提取各种媒体数据的深层次语义特征密切相关。与上述三种方法相比,本文方法对于五类动物的关联分析准确率均最高,分别比CCA高0.3、0.25、0.32、0.28、0.28,比KCCA高0.22、0.18、0.23、0.21、0.17,比Deep-SM高0.11、0.19、0.07、0.04、0.03。从模型的平均性能看,本文方法平均准确率最高,达到0.71,其次是Deep-SM,CCA最低。从各种动物关联分析的平均性能看,“狗”和“狼”具有较高的平均准确率,均达到或超过0.6,其他几种动物的平均准确率也达到0.5以上。
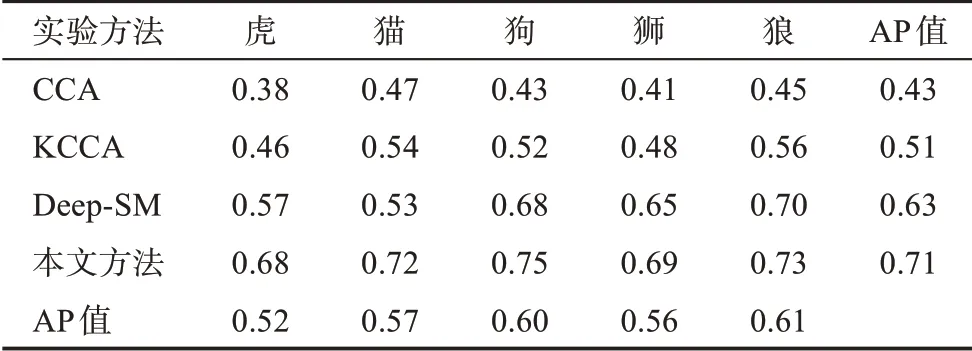
表2 研究对象的对比实验结果
针对本文方法,通过构造研究对象的混淆矩阵来统计分析本文方法的错分结果。表3给出研究对象的混淆矩阵,表中的行表示每一种动物被划分为各类的数量,列表示各种动物被划分为该类的数量。
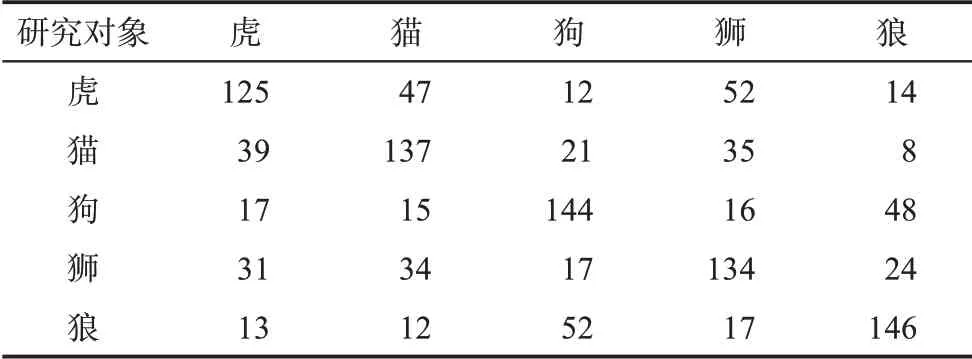
表3 研究对象的混淆矩阵
由表3的行可以看出,错分情形主要包括两方面:一方面,“虎”主要被错分为“狮”和“猫”,“猫”主要被错分为“虎”和“狮”,“狮”主要被错分为“虎”和“猫”;另一方面,“狗”主要被错分为“狼”,“狼”亦误识为“狗”。出现上述情形的主要原因是“虎”“狮”“猫”以及“狗”“狼”不论是相关的描述文本,还是图像、视频、音频等多媒体数据,从语义上存在较大相似性。从本文方法的工作原理看,出现错分的原因体现在两方面:一方面,是BiLSTM模型提取上述两类动物语义特征的能力还有待于进一步加强;另一方面,由于这两类动物存在较大的语义相似性,本文方法得到的各种动物的语义特征区分度不明显,这导致统一语义空间中各种动物特征向量的分布特征与实际情形存在较大偏差。
5 结 语
本文对融合语义特征和分布特征的跨媒体关联分析方法进行研究。首先,对文本、图像、视频和音频等多种媒体数据进行向量化表示,并输入模型;其次,利用双向长短期记忆网络提取各种媒体数据的上下文信息,并得到各种媒体数据的特征向量;最后,融合语义特征和分布特征,建立跨媒体关联分析的优化问题,各种媒体数据的类别信息有助于关联分析过程中发现各种媒体数据的语义特征,“同类近、异类远”的原则有利于表征统一语义空间中各种媒体数据的分布特征。自建数据集上的比较实验结果表明,本文方法较之CCA、KC‐CA、Deep-SM等现有方法具有更高的准确率。将无标记数据引入到现有研究框架,对融合标记数据和无标记数据的半监督关联分析方法进行研究。此外,能否将已有的知识库引入到现有研究框架,以提高跨媒体关联分析能力,亦值得研究者的关注。
